Journal of Computing and Security
Training-Free Object Matching and Retrieval Using Speeded Up
Robust Features
Reza Nasiripour
a, Hassan Farsi
a,∗, Sajad Mohamadzadeh
aaDepartment of Electronics and Communications Eng., University of Birjand, Birjand, Iran. A R T I C L E I N F O.
Article history:
Received:21 October 2015
Revised:10 January 2016
Accepted:16 February 2016
Published Online:08 May 2016 Keywords:
Object retrieval, Speeded Up Robust Features (SURF), Training-Free.
A B S T R A C T
Traditionally, object retrieval methods require a set of images of a specific object for training. In this paper, we propose a new object retrieval method using a single query image, without training, for a global object. The query image could be a typical real image of the object. The object is constructed based on Speeded Up Robust Features (SURF) points acquired from the image. Information of relative positions, scale and orientation between SURF points are calculated and constructed into an object model. The ability to match partially affine transformed object images results from the robustness of SURF points and the flexibility of the model. Occlusion is handled by specifying the probability of a missing SURF point in the model. Experimental results show that this matching technique is robust under partial occlusion and rotation. The obtained results illustrate that the proposed method improves efficiency, speeds up recovery and reduces the storage space.
c
2015 JComSec. All rights reserved.
1
Introduction
Object retrieval is an important part of image pro-cessing and computer vision. Object retrieval aims at searching the images containing the same object or scene as the given query region. It has a wide variety of applications, such as LOGO detection [1], object re-identification [2], near-duplicate detection [3], image and video annotation [4], etc. This task is very chal-lenging because the imaged object appears differently due to occlusion, background clutter and changes of camera viewpoint. Recently, the problem of retrieving a certain object from an image database has attracted high interest. In other words, by selection of a partic-ular object in a given query image, an object retrieval system should return a set of representative images
∗ Corresponding author.
Email addresses:[email protected](R. Nasiripour),[email protected](H. Farsi), [email protected](S. Mohamadzadeh)
ISSN: 2322-4460 c2015 JComSec. All rights reserved.
containing that object. Object detection is a very im-portant task in computer vision which includes surveil-lance, image retrieval, and intelligent transportation systems. Object detection has attracted much atten-tion in recent years with a large number of studies on object tracking, object recognition, and other object-based approaches. Object retrieval is essentially cate-gorized into two classes: classification and detection. The aim of object classification retrieval is to orga-nize desired objects into different pre-specified groups whereas the aim of object detection is to extract de-sired objects from the background in a target image [5].
regis-tration are some examples in this area. The search for the desired image could be divided into three stages. In first stage, the interest points such as blobs, corner and T-junctions are selected at individual positions in the image. One of the most important and valuable characteristic of an interest point detector is reliabil-ity to find the similar interest points under different conditions. In second stage, a feature vector is used to describe the neighbors of every interest point. This descriptor is required to be distinct and also robust against detection errors, noise, and geometric distor-tions. The feature vectors are matched between differ-ent images in third stage. The process of matching is often performed using a distance between the feature vectors, such as Euclidean or Mahalanobis distance. The feature vector size has a main role on required cal-culation time, and therefore a lower size is needed [6]. Up to now, although much research has been per-formed on this issue, most object detection methods are training-based methods using a set of sample im-ages belonging to the target object class [7]. Some-times, images without the target object are used as negative samples for discriminative learning to obtain better performance against background clutter. How-ever, the performance of training-based methods is limited by the samples. Generally, the target object for object detection is defined by the samples and human experience, which is rarely incorporated into training-based methods. Unlike the classification is-sue, there is no “background class” in object detection, or we can say that the “background class” is much larger than the “object class”. Therefore, there are not enough training samples to adequately model the target object. However, in many cases, collecting and aligning the samples is not possible. This seriously affects the performance of training-based detection methods. Moreover, training-based methods are not suitable for immediate tasks, because the task of col-lecting the samples and training the models should be performed beforehand, and therefore they must be re-performed when the target class changes.
There are other methods including appearance-based and contour-appearance-based approaches [8]. Appearance-based methods use image features such as texture, color and gradient information to find interest points and extract their patch descriptors [9–11]. In these methods, a feature vector of each image in the database is computed and stored in a feature database. Then, the feature vector of a query image is computed when a query is made. The feature vector of the query image is compared to the stored feature vectors, and then similar images are obtained [12, 13]. On the contrary, contour-based methods investigate the relationship between contour points and the constructed shape by these points [14–16].
Figure 1. Object detection using only one query image
Many recent studies have addressed object retrieval based on the Baseline approach [17]. These methods emphasize some key issues, including feature detection and quantization [18], component weighting [19], sim-ilarity metrics [20] and spatial constrains [21]. Other methods use VLAD (Vector of Locally Aggregated Descriptors) [22] and FV (Fisher Vector) [23] which are more effective. One of the most popular methods is Bag-Of-visual-Words (BOW) model [24]. In this model, an image is represented by a set of local descrip-tors. The BOW model consists of three steps. First, a visual vocabulary is built, using, for instance, by k-means. Second, the local descriptor is quantized as its nearest visual word from the visual vocabulary. Fi-nally, the similarity between two images is determined. However, this BOW-based model is limited, because the similar local descriptors which do not correspond to the same part of an object may be quantized into the same visual words and therefore they are falsely matched.
We evaluate the proposed model on two databases. The first is the building database including 5K images of Oxford landmarks where “landmarks” means a particular part of a building. We use a set of images containing 11 different landmarks. The images for each landmark are retrieved from Flicker1. In addition, we use the Corel database2 to evaluate the proposed method. This database includes 1000 different images. The images are divided into 11 classes, including native Africans, elephants, flowers, buses, horses, etc., from which we used only three classes, including planes, buses and dinosaurs. Some examples of the images from these databases are shown in Figure 2.
This paper is structured as follows: In Section 2, the related works are explained. In Section 3, the proposed object retrieval system is introduced. The proposed system can be divided into two parts. The first part is object retrieval and second part is object detection. In Section 4, experimental results are explained. Finally, the conclusion is drawn in Section 5.
2
Related Works
For object recognition, traditional machine vision methods acts mostly on correlation based template matching for inspection, registration and manipula-tion. While these methods act efficiently in an engi-neered environment where object pose and illumina-tion are strictly controlled, it is no longer feasible un-der slight positions or illumination variations because of the limited computation power and nearly infinite possible combinations of pose and lighting.
To overcome this problem, it is proposed to use fea-ture based methods instead of searching all possible model positions throughout the image. Feature based methods extract object features which are mostly in-variant against different positions, orientations and lightings. Scale Invariant Feature Transform (SIFT) [25] is an efficient method which is widely used in ob-ject recognition, image stitching, stereo vision and var-ious computer vision researches. Another solution is to use Histogram of Oriented Gradients (HOG) model. In [26], the HOG model of pedestrians is learned from a dataset using Support Vector Machine (SVM). A window is then slide through the test image in dif-ferent scales to detect pedestrian. The HOG model gives a rough sketch of the object; therefore it can de-tect different pedestrians with slightly different poses. However, it only acts fast enough for single orienta-tion and provides a wrong result when the pedestrian changes his pose.
1 http://www.flickr.com
2 http://wang.ist.psu.edu/docs/related
(a) 25 randomly sampled images from Oxford dataset
(b) 25 randomly sampled images from Corel dataset
Figure 2. Example Images from the Datasets
User-created queries are often simple and cannot contain sufficient information for object retrieval.
To deal with these problems, several general ap-proaches have been proposed over the past decade [27]. In the object retrieval system proposed in [27], a user first selects an example (query) image and then draws a bounding box around the object of interest in that image to specify the search intent. Local features are then extracted from the region surrounded by the bounding box and then quantized into visual words. While object retrieval based on the visual words is generally effective, it may not achieve reliable search results in cases where the visual words extracted only from the bounding box are unable to reliably reveal the search intent of the user. Firstly, the bounding box is typically only a rough approximation of the region of interest (ROI) representing the query object. Sec-ondly, in some cases where the ROI is too small, the number of visual words in the bounding box may be insufficient to perform reliable relevance estimation, with the consequence that irrelevant images may be returned.
Many works have used the bag-of-words (BOW) model. In this approach, images are represented as term frequency inverse document frequency (TF-IDF) weight vectors and then ranked by their dot product similarity to a query image [24].
model is introduced to combine appearance, shape, scale and occlusion of feature points into a probabilis-tic model. These models construct additional relation-ships on top of previous methods and provide better results in real tasks. However, these algorithms do not meet the need of differentiating specific objects. For example, the methods using only the HOG feature are unable to distinguish two different bottles. However, SIFT points contain much more information about specific object details and would more likely overcome this task. In some recent researches by [30, 31], a Prob-abilistic Grammar Markov Model (PGMM) was intro-duced for object recognition. In PGMM, the relation between SIFT points are used to construct a chain of triangles which can be learned, and made inference using dynamic programming. This paper is based on a modified version of this method to learn and match the probabilistic model of a general object.
3
Materials and Methods
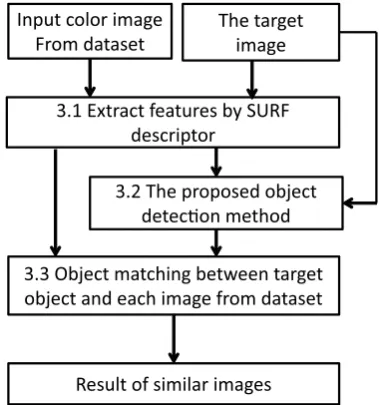
The proposed method detects the objects with a sin-gle query image. The key problem is to represent the target class from the query image, which could be typi-cally a real image. The detection process is very similar to “template matching”. The query image is used as a standard “template”, with the test images matched to this “template” to find the query objects. A block diagram of the proposed object retrieval method is illustrated in Figure 3. The proposed method acts in a different way using only one query image to detect the object without training. We extract features from the query image and dataset images. This is achieved using the SURF descriptor which is detailed in Sec-tion 3.1. Since target image requires object detecSec-tion,
Input color image From dataset
3.1 Extract features by SURF descriptor
3.2 The proposed object detec on method
3.3 Object matching between target object and each image from dataset
Result of similar images The target
image
Figure 3. Block diagram of the proposed Object Retrieval method
the proposed object detection for the extraction of the target object is detailed in Section 3.2. In Sec-tion 3.2.2, the details of object matching using the proposed object retrieval method are described.
3.1 SURF Algorithm
This section reviews the SURF algorithm which was proposed by Bay. This algorithm is similar to SIFT algorithm, but it is faster than SIFT in terms of cal-culation speed.
SURF uses a hessian matrix to find interest points [32]. The determinant of a hessian matrix is an expres-sion of the local change over the whole area. Suppose (x, y), is a point in an image, I. Then, the hessian matrix,H(X, σ), at scale,σ, inX is defined as:
H(x, σ) =
Lxx(x, σ) Lxy(x, σ)
Lxy(x, σ) Lyy(x, σ)
(1)
WhereLxx(x, σ),Lxy(x, σ) andLyy(x, σ) denote the
convolution of the image at point X = (x, y) with second order derivative of a Gaussian ∂2∂xg(2σ),
∂2g(σ)
∂xy , ∂2g(σ)
∂y2 , respectively.g(σ) is given by:
g(σ) = 1 2πσ2e
−(x2 +y2 )
2σ2 (2)
The convolution is very time-consuming. Hence, it is approximated and speeded-up by using integral images and box filters. Using the box filters, the hessian determinant can be approximated by:
∆(H) =DxxDyy−(0.9Dxy)2 (3)
Dxx,Dxy andDyy denote the convolution of the box
filters with the image at pointX = (x, y).
To extract a descriptor, the first step is to con-struct a square window along the dominant orienta-tion with the size of 20σ. This window is subsequently divided into 4×4 equal sub-regions. Then, for each sub-region, Haar wavelet responses with size of 2σ
at 5×5 equally spaced sample points are calculated. As shown in Figure 4, assumedxanddy denote the
Haar wavelet responses in horizontal and vertical di-rections, respectively.|dx|and|dy|represent the
ab-solute values of the Haar wavelet responses in hor-izontal and vertical directions, respectively. Hence, each sub-region has a 4-dimensional descriptor vec-tor,v= (P
dx,P|dx|,Pdy,P|dy|). For the window
Figure 4. Compute Features at 5×5 Regular Spaced Sample Points
3.2 The Proposed Object Detection Method
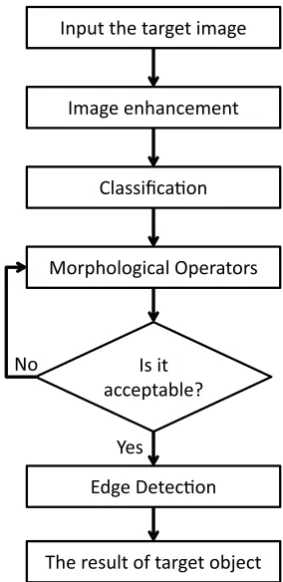
A block diagram of the proposed object detection method is depicted in Figure 5. The first step is image enhancement or in other words increasing the image quality. Usually, this step is performed to enhance the image resolution in order to allow better interpreta-tion of the obtained image, or to remove the noise and improve extraction of information from the im-age. The next step is image segmentation. In image segmentation, there are several methods, for instance, thresholding, area extraction and zero-crossing. This step is detailed in subsection 3.2.1. After segmenta-tion, morphological operators such as erosion, dilasegmenta-tion, opening and closing are used to remove lines and extra points [33]. We finally perform edge detection opera-tions to obtain a clear view of the object. In this step, a powerful edge detection algorithm such as Canny, Prewitt, LOG, Sobel and Roberts can be used. In this paper, we use Canny algorithm which is described in subsection 3.2.2. Figure 6 shows an illustration of tar-get object (shape) extraction enhancement with the proposed object detection method.
3.2.1 Classification and Segmentation
Normally, the segmentation is considered as a key step for image interpretation, after the image is pre-processed to remove artifacts and noise. In fact, image segmentation identifies and groups regions or features containing similar characteristics. Image segmenta-tion is a technique in which region detecsegmenta-tion, thresh-olds, edge detection, statistical classification or even a combination of these methods is used. This technique results in a set of classified elements. Most segmenta-tion techniques are either edge based or region-based. In region-based techniques, common patterns hav-ing nearly similar intensity values are considered within a cluster of neighboring pixels. The cluster refers to the region, and as mentioned, the aim of the segmentation algorithm is to group the regions. In edge-based techniques, the discontinuities in image
Input the target image
Image enhancement
Classifica on
Morphological Operators
Edge Detec on
The result of target object Is it
acceptable? No
Yes
Figure 5. Block Diagram of the Proposed Object Detection Method
values between different regions are measured, and the boundary which splits these regions is accurately determined. Therefore, segmentation extracts and represents image information to group pixels together into similar regions. The selection of the segmentation method is very important in elimination of any extra information. In this paper, the K-means algorithm is used [34]. This algorithm uses the following distance measure:
J =
k X
j=1
n X
i=1
kx(ii)−cjk2 (4)
wherekx(ij)−cjk2is the Euclidian distance between
the cluster center,cj, and a data pointx
(j)
i and ‘J’
indicates the aggregate distance of the data points from their relevant cluster centers.
3.2.2 Edge Detection of the Target Object
(a) Example Image
(b) Segmentation
(c) Extracted Contour
Figure 6. The Resulting Shape of Target Object by the Proposed Object Detection Method
function. A two dimensional first-derivative operator is then applied to the smoothed image to highlight the image regions. In the gradient magnitude of the image, the edges are located on the top of the ridges. These ridges are then tracked and all pixels which are not actually on the ridge top are set to zero by the algorithm and a thin line is resulted in the output. This process is called non-maximal suppression. The tracking process can be considered as a hysteresis curve controlled by two thresholds: TH1 and TH2, where TH1>TH2. The starting point for tracking process is a point on a ridge with gradient magnitude higher than TH1. The tracking continues in both directions from that point until the elevation of the ridge becomes lower than TH2. Hysteresis property guarantees that noisy edges are not propagated into multiple remaining edges.
3.3 Object Matching using the Proposed Ob-ject Detection System
As an example, Figure 7 shows object matching be-tween two images, where the right image is the query
Figure 7. Example of Object Matching
image and left image is the matched image. We first acquire all the SURF points in the target image. In other words, each image is represented as isolated SURF points.
A model is defined by a set ofNmnodes. The set of
nodesM ={ma}is indexed byα= 1,2, . . . , Nmand
eachmawill correspond to a SURF point in the image.
Each node has attributes of (zα, sα, θa, Aα) wherezα
denotes the spatial location,sαindicates the feature
size,θa indicates the orientation, andAαrepresents
the appearance. In addition, a binary variable, uα,
specifies whether a node in the model could be found in the image [36].
There areNm−2 triplet-cliquesCin a model; each
triplet-clique is also labeled by αand is a set of 3 nodes,Cα={mα, mα+1, mα+2}.
We define the model parameters asω = (ωA, ωS),
whereωA={ωAα}andωS ={ωαS}are the appearance and the shape parameters, respectively. The model parameters, ω, can be decomposed into Nm nodes
m1, . . . , mNM and NM −2 cliques C1, . . . , CNM−2; each node represents an appearance vectoruA
a,α=
1, . . . , mand each clique represents a shape vectoruS a.
To match the model to the image, first we match the SURF points in the target image to the first clique in the model. To reduce the enormous possible combi-nations of any 3 SURF points in the image, for each SURF point, we first find the nearest neighbor of its appearance vector among the appearance vectors of the first 3 nodes (m1, m2, m3). We restrict them to only match to the closest one. We then store those 3 SURF points that matches (m1, m2, m3) in the model as the chain,Hk, and its chain probabilities given as
the model parametersPhk.Phk is defined as the clique probabilityPc times the observed probabilityP0.
For the first iteration, every SURF point in imageI1 is added to one of the available cliques that results in maximumPc
i among the images,I2· · ·IN I. ThePicin
imageIiis calculated by assuming the model
param-etersuAanduS are equal to the appearance vector and shape vector of the corresponding SURF points inC1aj; and the model parametersP
AandP
probabil-ity inIi is the maximum among all combinations of
SURF points inIi.
Adding a new node to the clique will create a new clique which is composed of one new node and two previous nodes. In next iterations, new SURF points inI1 will be added to this new clique instead of the previous ones; each SURF point is added to the clique which gives the highest product of maximum clique probabilities among imagesI2· · ·IN I times the chain
probabilityPh
kt. The iteration is stopped when none
of the chain probabilities is higher than a threshold. In addition to 3 SURF points stored as the chain, we also store an additional point in case a SURF point is lost. We generate a virtual SURF point for which the appearance vector and the location vector result in the maximumPc, and store two actual SURF points
and one virtual SURF point into a chain Hk with
chain probability Pk
h =PcP0. The only restriction
is that only one node in a clique could be a virtual SURF point. For each iteration, we match one of the SURF points in the image to one of the chains from the last iteration which corresponds to the maximum
Pk
h. The iteration ends when all nodes in the model are
matched. The chainHk containing the highestPhk is
the most probable location of the object in the image.
4
Results
4.1 Evaluation Measures
There are many measures for evaluation of retrieval methods. In this paper, we use three general measures, i.e. ANMRR, precision and recall. The performance of most object retrieval methods has been measured by precision and recall.
The Average Normalized Modified Retrieval Rank (ANMRR) is an objective measure which summarizes and computes the performance of system into a scalar value. ANMRR has been defined by MPEG-7 research group [37].
Rank(k) =
(
R(k) ifR(k)≤K(q)
1.25K otherwise (5) WhereR(k) is equal to rank of the imagekin retrieval results andK(q) = min[4N G(q),2 max{|N G(q),∀q}] whereN G(q) is the number of the ground truth images for the query imageq.
Average Rank, AVR(q), for queryq, is given by: AVR(q) =hRank(k)i. (6) However, for ground truth sets with different sizes, the AVR(q) value depends on N G(q). To minimize the influence of variations inN G(q), Modified Retrieval
Rank, MRR(q), is obtained by:
MRR(q) = AVR(q)−0.5[1 +|N G(q)|] (7) The upper bound of MRR(q) depends onN G(q). To normalize this value, Normalized Modified Retrieval Rank, NMRR(q), is obtained by:
NMRR(q) = AVR(q)−0.5[1 +|N G(q)|] 1.25K(q)−0.5[1 +|N G(q)|] (8) NMRR is zero for best performance and one for worst performance. The ANMRR of the dataset is finally given by averaging the NMRR(q) over allq’s
ANMRR =hNMRR(q)i. (9) Precision is the fraction of returned images that are relevant to the query image. Recall is the total number of relevant images with respect to the total number of relevant images in the dataset according to a priori knowledge. If we denoteTas the set of returned images andRas the set of all images relevant to the query image, then the precision and recall criteria are given by Equations (10) and (11), respectively [38?].
Precision =|T∩R|
|T| (10)
Recall =|T R|
|R| (11)
The number of relevant images is computed and the precision and recall for retrieved images for each query image are obtained. We next consider the average of these precisions and recalls as the precision and recall of each method [38].
To evaluate the proposed system we use the method proposed by Montagna and Finlayson. They proposed a method using the combination of precision and recall criteria as the performance measure for object retrieval method [39]. According to Montagna and Finlayson method, the following measures have been adopted:
P(0.5), precision at 50% recall (i.e. precision after retrieving 12 of the relevant documents).
P(1), precision at 100% recall (i.e. precision after retrieving all of the relevant documents).
We use these values because precision and recall are considered in relation to each other and they are not meaningful if taken separately [38].
4.2 Indexing Results
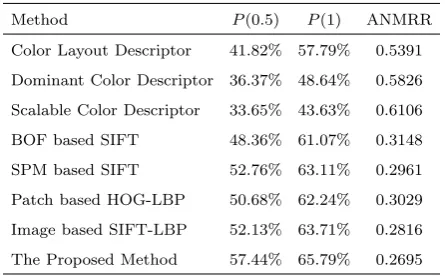
Table 1. P(0.5), P(1) and ANMRR of different in Corel dataset
Method P(0.5) P(1) ANMRR
Color Layout Descriptor 41.82% 57.79% 0.5391
Dominant Color Descriptor 36.37% 48.64% 0.5826
Scalable Color Descriptor 33.65% 43.63% 0.6106
BOF based SIFT 48.36% 61.07% 0.3148
SPM based SIFT 52.76% 63.11% 0.2961
Patch based HOG-LBP 50.68% 62.24% 0.3029
Image based SIFT-LBP 52.13% 63.71% 0.2816
The Proposed Method 57.44% 65.79% 0.2695
images. These images are divided into 11 classes, in-cluding early humans, elephants, flowers, buses, horses, etc. that we use only three of them, including planes, buses and dinosaurs.
4.2.1 The Corel Dataset
We compare the proposed method with color layout descriptor [40] dominant color descriptor [41], Scal-able color descriptor [40], BOF based SIFT [42], SPM based SIFT [43], Patch based HOG-LBP [44] and Im-age based SIFT-LBP [45] using Corel dataset. We apply the proposed method to retrieve related images. As an example, Figure 8 shows the query image and the retrieved images using the proposed method. This figure shows sixteen retrieved images using the pro-posed method. As observed, there are two errors in sixteen images. TheP(0.5),P(1) and ANMRR of the proposed method, color layout descriptor, scalable color descriptor and dominant color descriptor, BOF based SIFT, SPM based SIFT, Patch based HOG-LBP and Image based SIFT-HOG-LBP on Corel dataset are obtained and represented in Table 1. As shown in Table 1, the best score for each metric is in bold face. As observed, theP(0.5),P(1) and ANMRR for the proposed method is 57.44%, 43.63% and 0.2695, re-spectively. According to Table 1, the proposed method provides better values ofP(0.5),P(1) and ANMRR than other methods. For example, the value ofP(0.5) of the proposed method, color layout, dominant color, scalable color descriptor, BOF based SIFT, SPM based SIFT, Patch based HOG-LBP and Image based SIFT-LBP are 57.44%, 41.82%, 36.37%, 33.65%, 48.36%, 52.76%, 50.68% and 52.13% respectively. Therefore, the proposed method results in the best performance in Corel dataset.
4.2.2 The Oxford Landmarks Datasets
In order to compare the proposed method with other methods, the proposed method is applied on Oxford landmarks dataset. The results demonstrate the
effec-Figure 8. Retrieval Images by Using the Proposed Method in Corel Dataset
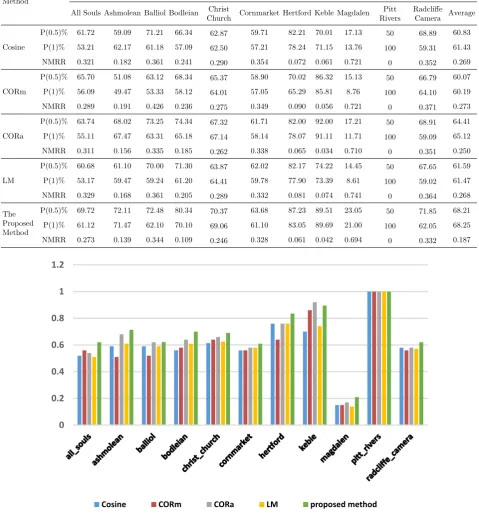
tiveness of the proposed method. The compared meth-ods are cosine model [46], general (content-unaware) language modeling approach (LM) [47] and two vari-ants of the matting-based COR model [48]. The per-formance of the proposed method, Cosine, CORm, CORa and LM methods for 11 landmarks on the Ox-ford 5K dataset is shown in Figure 9. As observed, the performance of the proposed method in “All Souls” is better than other mentioned methods. After the pro-posed method, CORm, CORa, Cosine and LM have better performance, respectively. As depicted, in each landmark, the proposed method, except in “Balliol” and “Keble” landmark, has better performance than other methods.
Table 2 summarizes the test results on the Oxford 5K dataset. TheP(0.5),P(1), ANMRR and average of these parameters for the proposed method, CORm, CORa and LM methods are represented in this table. Once again, in Table 2, the best score for each metric is in bold face. For example, the value ofP(1) for the proposed method in “Bodleian” is 70.10%, however
Table 2.P(0.5),P(1) and ANMRR for Different Methods in Oxford 5K Dataset
Method Datasets
All Souls Ashmolean Balliol Bodleian Christ
Church Cornmarket Hertford Keble Magdalen Pitt Rivers
Radcliffe Camera Average
P(0.5)% 61.72 59.09 71.21 66.34 62.87 59.71 82.21 70.01 17.13 50 68.89 60.83
Cosine P(1)% 53.21 62.17 61.18 57.09 62.50 57.21 78.24 71.15 13.76 100 59.31 61.43
NMRR 0.321 0.182 0.361 0.241 0.290 0.354 0.072 0.061 0.721 0 0.352 0.269
P(0.5)% 65.70 51.08 63.12 68.34 65.37 58.90 70.02 86.32 15.13 50 66.79 60.07
CORm P(1)% 56.09 49.47 53.33 58.12 64.01 57.05 65.29 85.81 8.76 100 64.10 60.19
NMRR 0.289 0.191 0.426 0.236 0.275 0.349 0.090 0.056 0.721 0 0.371 0.273
P(0.5)% 63.74 68.02 73.25 74.34 67.32 61.71 82.00 92.00 17.21 50 68.91 64.41
CORa P(1)% 55.11 67.47 63.31 65.18 67.14 58.14 78.07 91.11 11.71 100 59.09 65.12
NMRR 0.311 0.156 0.335 0.185 0.262 0.338 0.065 0.034 0.710 0 0.351 0.250
P(0.5)% 60.68 61.10 70.00 71.30 63.87 62.02 82.17 74.22 14.45 50 67.65 61.59
LM P(1)% 53.17 59.47 59.24 61.20 64.41 59.78 77.90 73.39 8.61 100 59.02 61.47
NMRR 0.329 0.168 0.361 0.205 0.289 0.332 0.081 0.074 0.741 0 0.364 0.268
The Proposed Method
P(0.5)% 69.72 72.11 72.48 80.34 70.37 63.68 87.23 89.51 23.05 50 71.85 68.21
P(1)% 61.12 71.47 62.10 70.10 69.06 61.10 83.05 89.69 21.00 100 62.05 68.25
NMRR 0.273 0.139 0.344 0.109 0.246 0.328 0.061 0.042 0.694 0 0.332 0.187
0 0.2 0.4 0.6 0.8 1 1.2
Cosine CORm CORa LM proposed method
Figure 9.P(1) for Different Landmarks on Oxford Dataset
Figure 10 shows the object matching of the pro-posed method on 11 landmarks of Oxford dataset. Fig-ure 10a-10k are Oxford All-Souls, Ashmolean, Balliol, Cornmarket, Bodleian, Hertford, Keble, Magdalen, Pitt Rivers, Radcliffe Camera, Christ Church, respec-tively. In this figure, each sub-figure has two images where right image is the query image and left image
(a) Oxford All Souls (b) Ashmolean (c) Balliol
(d) Cornmarket (e) Bodleian (f) Hertford
(g) Keble (h) Magdalen (i) Pitt Rivers
(j) Radcliffe Camera (k) Christ Church
Figure 10. Object matching on the Oxford landmarks database. Right image is the query image and left image is the image matched
10g indicate robustness against rotation. In addition, Figure 10h and 10k show that the proposed method is robust when the query image is selected from part of the image (e.g. objects).
The proposed method is also tested for face detec-tion, generic object detecdetec-tion, and logo detecdetec-tion, as represented in Figure 11. Figure 11a and Figure 11b indicate the results of the proposed method on logo detection and face detection, respectively. Figure 11c and Figure 11d show the object matching for generic object. The obtained results show that the proposed matching technique is robust under partial occlusion, rotation and scaling in different images.
Therefore the proposed method provides better per-formance than other methods in Corel and Oxford landmarks dataset. Thus, the proposed technique can be considered as a more effective method than the other methods. Meanwhile, the proposed method re-sults in the best performance in object matching and retrieval. Due to using SURF model to extract features
of images with 64 dimensions, the complexity of the proposed method is also lower than the other methods [49]. Reduction of dimension decreases the required time for feature matching, decreases the complexity of system and increases the robustness, simultaneously.
5
Conclusions
con-(a) (b)
(c) (d)
Figure 11.P(1) for different landmarks on Oxford dataset
vince that the proposed matching technique is robust under partial occlusion, rotation and scaling. This method is very useful for generic or immediate object detection tasks, because of using single query image.
References
[1] Jerome Revaud, Matthijs Douze, and Cordelia Schmid. Correlation-based burstiness for logo re-trieval. InProceedings of the 20th ACM interna-tional conference on Multimedia, pages 965–968. ACM, 2012.
[2] Jiejun Xu, Vignesh Jagadeesh, Zefeng Ni, Santhoshkumar Sunderrajan, and BS Manju-nath. Graph-based topic-focused retrieval in dis-tributed camera network. Multimedia, IEEE Transactions on, 15(8):2046–2057, 2013.
[3] Zhong Wu, Qifa Ke, Michael Isard, and Jian Sun. Bundling features for large scale partial-duplicate web image search. InComputer Vision and Pat-tern Recognition, 2009. CVPR 2009. IEEE Con-ference on, pages 25–32. IEEE, 2009.
[4] Wan-Lei Zhao, Xiao Wu, and Chong-Wah Ngo. On the annotation of web videos by efficient near-duplicate search.Multimedia, IEEE Transactions on, 12(5):448–461, 2010.
[5] Shivani Agarwal, Aatif Awan, and Dan Roth. Learning to detect objects in images via a sparse, part-based representation. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 26 (11):1475–1490, 2004.
[6] Bo Wu and Ram Nevatia. Simultaneous object detection and segmentation by boosting local shape feature based classifier. InComputer Vi-sion and Pattern Recognition, 2007. CVPR’07.
IEEE Conference on, pages 1–8. IEEE, 2007. [7] Ashish Kapoor and John Winn. Located hidden
random fields: Learning discriminative parts for object detection. In Computer Vision–ECCV 2006, pages 302–315. Springer, 2006.
[8] Peter Kontschieder, Hayko Riemenschneider, Michael Donoser, and Horst Bischof. Discrimi-native learning of contour fragments for object detection. InBMVC, pages 1–12, 2011.
[9] Xianglin Meng, Zhengzhi Wang, and Lizhen Wu. Building global image features for scene recogni-tion. Pattern Recognition, 45(1):373–380, 2012. [10] Bastian Leibe, Konrad Schindler, Nico Cornelis,
and Luc Van gool. Coupled object detection and tracking from static cameras and moving vehi-cles.IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(10):1683–1698, 2008. [11] Liming Wang, Jianbo Shi, Gang Song, and I-Fan
Shen. Object detection combining recognition and segmentation. InComputer Vision–ACCV 2007, pages 189–199. Springer, 2007.
[12] Chen Xianqiao, Yan Xinping, and Chu Xiumin. Research on image content retrieval with color features. InComputational Intelligence and Nat-ural Computing Proceedings (CINC), 2010 Sec-ond International Conference on, volume 2, pages 141–144. IEEE, 2010.
[13] Shao-Hu Peng, Khairul Muzzammil, and Deok-Hwan Kim. Robust feature detection based on local variation for image retrieval. InImage Pro-cessing (ICIP), 2010 17th IEEE International Conference on, pages 1033–1036. IEEE, 2010. [14] Jamie Shotton, Andrew Blake, and Roberto
vol-ume 1, pages 503–510. IEEE, 2005.
[15] Hayko Riemenschneider, Michael Donoser, and Horst Bischof. Using partial edge contour matches for efficient object category localization. InComputer Vision–ECCV 2010, pages 29–42. Springer, 2010.
[16] Xingwei Yang, Hairong Liu, and Longin Jan Late-cki. Contour-based object detection as domi-nant set computation. Pattern Recognition, 45 (5):1927–1936, 2012.
[17] James Philbin, Ondˇrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman. Object re-trieval with large vocabularies and fast spatial matching. InComputer Vision and Pattern Recog-nition, 2007. CVPR’07. IEEE Conference on, pages 1–8. IEEE, 2007.
[18] Xiaolin Tian, Licheng Jiao, Xianlong Liu, and Xiaohua Zhang. Feature integration of eodh and color-sift: Application to image retrieval based on codebook. Signal Processing: Image Commu-nication, 29(4):530–545, 2014.
[19] Liang Zheng, Shengjin Wang, Ziqiong Liu, and Qi Tian. Lp-norm idf for large scale image search. InProceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition, pages 1626– 1633, 2013.
[20] Cai-Zhi Zhu, Herv´e J´egou, and Shin Satoh. Query-adaptive asymmetrical dissimilarities for visual object retrieval. InProceedings of the IEEE Inter-national Conference on Computer Vision, pages 1705–1712, 2013.
[21] Yannis Avrithis and Giorgos Tolias. Hough pyra-mid matching: Speeded-up geometry re-ranking for large scale image retrieval.International jour-nal of computer vision, 107(1):1–19, 2014. [22] Relja Arandjelovic and Andrew Zisserman. All
about vlad. InThe IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), June 2013.
[23] Florent Perronnin and Christopher Dance. Fisher kernels on visual vocabularies for image catego-rization. InComputer Vision and Pattern Recog-nition. CVPR . IEEE Conference on, June 2007. [24] Fei Li, Qionghai Dai, Wenli Xu, and Guihua Er. Weighted subspace distance and its applications to object recognition and retrieval with image sets. Signal Processing Letters, IEEE, 16(3):227– 230, 2009.
[25] David G Lowe. Object recognition from local scale-invariant features. In Computer vision, 1999. The proceedings of the seventh IEEE in-ternational conference on, volume 2, pages 1150– 1157. Ieee, 1999.
[26] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In
Computer Vision and Pattern Recognition, 2005.
CVPR 2005. IEEE Computer Society Conference on, volume 1, pages 886–893. IEEE, 2005. [27] Xiang Sean Zhou and Thomas S Huang.
Rele-vance feedback in image retrieval: A comprehen-sive review. Multimedia systems, 8(6):536–544, 2003.
[28] Pedro Felzenszwalb, David McAllester, and Deva Ramanan. A discriminatively trained, multiscale, deformable part model. InComputer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, pages 1–8. IEEE, 2008.
[29] Robert Fergus, Pietro Perona, and Andrew Zis-serman. Object class recognition by unsuper-vised scale-invariant learning. InComputer Vi-sion and Pattern Recognition, 2003. Proceedings. 2003 IEEE Computer Society Conference on, vol-ume 2, pages II–264. IEEE, 2003.
[30] Long Zhu, Yuanhao Chen, and Alan Yuille. Un-supervised learning of a probabilistic grammar for object detection and parsing. Cambridge, MA: MIT Press, 2007.
[31] Long Zhu, Yuanhao Chen, and Alan Yuille. Un-supervised learning of probabilistic grammar-markov models for object categories. IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, 31(1):114–128, 2009. ISSN 0162-8828. doi: 10.1109/TPAMI.2008.67.
URLhttp://doi.ieeecomputersociety.org/
10.1109/TPAMI.2008.67.
[32] Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool. Speeded-up robust features (surf).Comput. Vis. Image Underst., 110(3):346– 359, June 2008. ISSN 1077-3142. doi: 10.1016/j. cviu.2007.09.014. URLhttp://dx.doi.org/10. 1016/j.cviu.2007.09.014.
[33] Rafael C. Gonzales and Paul Wintz.Digital Image Processing (2Nd Ed.). Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1987. ISBN 0-201-11026-1.
[34] Vance Faber. Clustering and the continuous k-means algorithm. Los Alamos Science, 22 (138144.21), 1994.
[35] John Canny. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. In-tell., 8(6):679–698, 1986. doi: 10.1109/TPAMI. 1986.4767851. URL http://dx.doi.org/10. 1109/TPAMI.1986.4767851.
[36] Yang Ku. A probabilistic model for object match-ing. Technical report, Computer Science Depart-ment, UCLA, 2009.
[37] Miguel Angel Veganzones and Manuel Gra˜na. A spectral/spatial cbir system for hyperspectral im-ages. Selected Topics in Applied Earth Observa-tions and Remote Sensing, IEEE Journal of, 5(2): 488–500, 2012.
and texture feature-based image retrieval by us-ing hadamard matrix in discrete wavelet trans-form.Image Processing, IET, 7(3):212–218, 2013. [39] Roberto Montagna and Graham D Finlayson. Padua point interpolation and L p-norm min-imisation in colour-based image indexing and retrieval. Image Processing, IET, 6(2):139–147, 2012.
[40] Raphael Troncy, Benoit Huet, and Simon Schenk.
Multimedia semantics: metadata, analysis and interaction. John Wiley & Sons, 2011.
[41] Ahmed Ibrahim, Ala’a Zou’bi, Raed Sahawneh, and Maria Makhadmeh. Fixed Representative Colors Feature Extraction Algorithm for Moving Picture Experts Group-7 Dominant Color De-scriptor. Journal of Computer Science, 2009. doi: 10.3844/jcssp.2009.773.777.
[42] Frederic Jurie and Bill Triggs. Creating efficient codebooks for visual recognition. InComputer Vision, 2005. ICCV 2005. Tenth IEEE
Interna-tional Conference on, October 2005.
[43] Jianchao Yang, Kai Yu, Yihong Gong, and Tao Huang. Linear spatial pyramid matching using sparse coding for image classification. In Com-puter Vision and Pattern Recognition, June 2009. [44] Jing Yu, Zengchang Qin, Tao Wan, and Xi Zhang. Feature integration analysis of bag-of-features model for image retrieval. Neurcomputing, 120 (1):355–364, 2013.
[45] Chuen-Horng Lin, Der-Chen Huang, Yung-Kuan Chan, Kai-Hung Chen, and Yen-Jen Chang. Fast color-spatial feature based image retrieval meth-ods. Expert System with Applications, 38(9): 11412–11420, 2011.
[46] James Philbin, Ondˇrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman. Object re-trieval with large vocabularies and fast spatial matching. InComputer Vision and Pattern Recog-nition, 2007. CVPR’07. IEEE Conference on, pages 1–8. IEEE, 2007.
[47] Bo Geng, Linjun Yang, and Chao Xu. A study of language model for image retrieval. InData Mining Workshops, 2009. ICDMW’09. IEEE In-ternational Conference on, pages 158–163. IEEE, 2009.
[48] Linjun Yang, Bo Geng, Yang Cai, Alan Hanjalic, and Xian-Sheng Hua. Object retrieval using vi-sual query context. Multimedia, IEEE Transac-tions on, 13(6):1295–1307, 2011.
[49] Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool. Speeded-up robust features (surf).
Computer vision and image understanding, 110 (3):346–359, 2008.
Reza Nasiripour was born in Torbat haidariah in 1990. He received the B.Sc. and M.Sc. degrees in electrical communication engineering from University of Birjand, Bir-jand, Iran in 2012 and 2014, respectively. His research interests include Image and image Processing, Pattern Recognition and Machine Learning.
Hassan Farsireceived the B.Sc. and M.Sc. degrees from Sharif University of Technol-ogy, Tehran, Iran, in 1992 and 1995, respec-tively. Since 2000, he started his Ph.D in the Centre of Communications Systems Research (CCSR), University of Surrey, Guildford, UK, and received the Ph.D degree in 2004. He is interested in speech, image and video pro-cessing on wireless communications. Now, he works as associate professor in communication engineering in department of Electrical and Computer Eng., university of Birjand, Birjand, IRAN.