The Forest Convolutional Network: Compositional Distributional
Semantics with a Neural Chart and without Binarization
Phong Le and Willem Zuidema Institute for Logic, Language and Computation
University of Amsterdam, the Netherlands
{p.le,zuidema}@uva.nl
Abstract
According to the principle of composi-tionality, the meaning of a sentence is computed from the meaning of its parts and the way they are syntactically com-bined. In practice, however, the syntactic structure is computed by automatic parsers which are far-from-perfect and not tuned to the specifics of the task. Current re-cursive neural network (RNN) approaches for computing sentence meaning therefore run into a number of practical difficulties, including the need to carefully select a parser appropriate for the task, deciding how and to what extent syntactic context modifies the semantic composition func-tion, as well as on how to transform parse trees to conform to the branching settings (typically, binary branching) of the RNN. This paper introduces a new model, the Forest Convolutional Network, that avoids all of these challenges, by taking a parse forest as input, rather than a single tree, and by allowing arbitrary branching fac-tors. We report improvements over the state-of-the-art in sentiment analysis and question classification.
1 Introduction
For many natural language processing tasks we need to compute meaning representations for sen-tences from meaning representations of words. In a recent line of research on ‘recursive neural net-works’ (e.g., Socher et al. (2010)), both the word and sentence representations are vectors, and the word vectors (“embeddings”) are borrowed from work in distributional semantics or neural lan-guage modelling. Sentence representations, in this approach, are computed by recursively applying a neural network that combines two vectors into one
(typically according to the syntactic structure pro-vided by an external parser). The network, which thus implements a ‘composition function’, is opti-mized for delivering sentence representations that support a given semantic task: sentiment analysis (Irsoy and Cardie, 2014; Le and Zuidema, 2015), paraphrase detection (Socher et al., 2011), seman-tic relatedness (Tai et al., 2015) etc. Studies with recursive neural networks have yielded promising results on a variety of such tasks.
In this paper, we represent a new recursive neu-ral network architecture that fits squarely in this tradition, but aims to solve a number of difficulties that have arisen in existing work. In particular, the model we propose addresses three issues:
1. how to make the composition functions adap-tive, in the sense that they operate adequately for the many different types of combina-tions (e.g., adjective-noun combinacombina-tions are of a very different type than VP-PP combina-tions);
2. how to deal with different branching factors of nodes in the relevant syntactic trees (i.e., we want to avoid having to binarize syntac-tic trees,1 but also do not want ternary pro-ductions to be completely independent from binary productions);
3. how to deal with uncertainty about the correct parse inside the neural architecture (i.e., we don’t want to work with just the best or k-best parses for a sentence according to an external model, but receive an entire distribution over possible parsers).
1Eisner (2001, Chapter 2) shows that using flat rules is
linguistically beneficial, “most crucially, a flat lexical entry corresponds to the local domain of a headword-the word to-gether with all its semantic arguments and modifiers”. From the computational perspective, flat rules make trees less deep, thus avoiding the vanishing gradient problem and capturing long range dependencies.
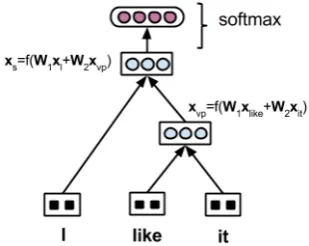
Figure 1: Recursive Neural Network. For simplic-ity, bias vectors are removed.
To solve these challenges we take inspiration from two other traditions: the convolutional neu-ral networks and classic parsing algorithms based on dynamic programming. Including convolution in our network provides a direct solution for is-sue (2), and turns out, somewhat unexpectedly, to also provide a solution for issue (1). Introduc-ing the chart representation from classic parsIntroduc-ing into our architecture then allows us to tackle issue (3). The resulting model, the Forest Convolutional Network, outperforms all other models on a senti-ment analysis and question classification task. 2 Background
This section is to introduce the recursive neural network (RNN) and convolutional neural network (CNN) models, on which our work is based.
2.1 Recursive Neural Network
A recursive neural network (RNN) (Goller and K¨uchler, 1996) is a feed-forward neural network where, given a tree structure, we recursively ap-ply the same weight matrices at each inner node in a bottom-up manner. In order to see how an RNN works, consider the following exam-ple. Assume that there is a constituent with parse tree (S I (V P like it)) (Figure 1), and that xI,xlike,xit ∈ Rd are the vectorial
representa-tions of the three words I, like and it, respec-tively. We use a neural network which consists of a weight matrixW1 ∈Rd×dfor left children and a weight matrixW2 ∈Rd×dfor right children to compute the vector for a parent node in a bottom up manner. Thus, we computexV P
xV P =f(W1xlike+W2xit+b) (1)
whereb is a bias vector and f is an (non-linear) activation function. Having computed xV P, we
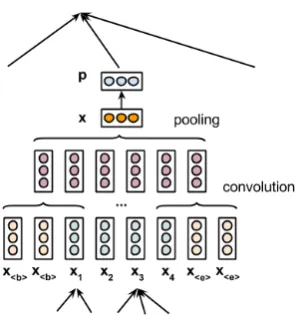
Figure 2: Convolutional Neural Network (one convolutional layer and one fully connected layer) with a window-size-3 kernel.
can then move one level up in the hierarchy and computexS
xS =f(W1xI+W2xV P +b)
This process is continued until we reach the root node.
For classification tasks, we put a softmaxlayer on the top of the root node, and compute the prob-ability of assigning a classcto an inputxby
P r(c|x) =softmax(c) = P eu(c,ytop)
c0∈Ceu(c0,ytop) (2)
where u(c1,ytop), ..., u(c|C|,ytop)T =
Wuytop + bu; C is the set of all possible
classes; Wu ∈ R|C|×d,bu ∈ R|C| are a weight
matrix and a bias vector.
Training an RNN uses the gradient descent method to minimize an objective function J(θ). The gradient∂J/∂θis efficiently computed thanks to the back-propagation through structure algo-rithm (Goller and K¨uchler, 1996).
Departing from the original RNN model, many extensions have been proposed to enhance its compositionality (Socher et al., 2013; Irsoy and Cardie, 2014; Le and Zuidema, 2015) and appli-cability (Le and Zuidema, 2014b). The model we are going to propose can be considered as an ex-tension of RNN with an ability to solve the three issues introduced in Section 1.
2.2 Convolutional Neural Network
[image:2.595.104.259.63.186.2]invented for computer vision. It then has been widely applied to solve natural language process-ing tasks (Collobert et al., 2011; Kalchbrenner et al., 2014; Kim, 2014).
To illustrate how a CNN works, the following example uses a simplified model proposed by Col-lobert et al. (2011) which consists of one con-volutional layer with the max pooling operation, followed by one fully connected layer (Figure 2). This CNN uses akernelwith window size 3; when we slide this kernel along the sentence “hsi I like it very muchh/si”, we get five vectors:
u(1) =W
1x<s>+W2xI+W3xlike+bc
u(2) =W
1xI+W2xlike+W3xit+bc
...
u(5) =W1xvery+W2xmuch+W3x</s>+bc
where W1,W2,W3 ∈ Rd×m are weight matri-ces, bc ∈ Rm is a bias vector. The max pooling
operation is then applied to those resulted vectors in an element-wise manner:
x= max 1≤i≤5u
(i)
1 , ...,1max≤i≤5u(ji), ...
T
Finally, a fully connected layer is employed
y=f(Wx+b)
whereW,bare a real weight matrix and bias vec-tor, respectively;f is an activation function.
Intuitively, a window-size-kkernel extracts (lo-cal) features fromk-grams, and is thus able to cap-turek-gram composition. The max pooling oper-ation is for reducing dimension, forcing the net-work to discriminate important features from oth-ers by assigning high values to them. For instance, if the network is used for sentiment analysis, local features corresponding to k-grams containing the word “like” should receive high values in order to be propagated to the top layer.
3 Forest Convolutional Network
[image:3.595.344.492.61.223.2]We now first propose a solution to the issues (1) and (2) (i.e., making the composition functions adaptive and dealing with different branching fac-tors), called Recursive convolutional neural net-work (RCNN), and then a solution to the third is-sue (i.e., dealing with uncertainty about the cor-rect parse), called Chart Neural Network (ChNN). A combination of them, Forest Convolutional Net-work (FCN), will be introduced lastly.
Figure 3: Recursive Convolutional Neural Net-work with a nonlinear window-size-3 kernel.
3.1 Recursive Convolutional Neural Network2
Given a subtreep → x1 ... xl, an RCNN
(Fig-ure 3), like a CNN, slides a window-size-kkernel along the sequence of children(x1, ..., xl)to
com-pute a pool of vectors. The max pooling operation followed by a fully connected layer is then applied to this pool to compute a vector for the parentp.
This RCNN differs from the CNN introduced in Section 2.2 at two points. First, we use a non-linear kernel: after linearly transforming in-put vectors, an activation function is applied. Sec-ond, we putk−1padding tokens<b>at the be-ginning of the children sequence andk−1padding tokens<e>at the end. This thus guarantees that all the children contribute equally to the resulted vector pool, which now hasl+k−1vectors.
It is obvious that this RCNN can solve the sec-ond issue (i.e., dealing with different branching factors), we now show how it can make the com-position functions adaptive. We first see what hap-pens if the window sizekis larger than the number of childrenl, for instancek= 3andl= 2. There are four vectors in the pool
u(1) =f(W
1x<b>+W2x<b>+W3x1+bc)
u(2) =f(W1x<b>+W2x1+W3x2+bc)
u(3) =f(W1x1+W2x2+W3x<e>+bc)
u(4) =f(W
1x2+W2x<e>+W3x<e>+bc)
whereW1,W2,W3 are weight matrices,bcis a
2While finalizing the current paper we discovered a
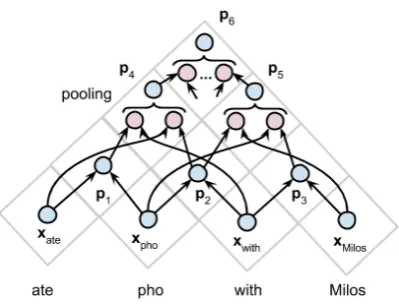
Figure 4: Chart Neural Network.
bias vector,f is an activation function. These four resulted vectors correspond to four ways of com-posing the two children:
(1) the first child stands alone (e.g., when the in-formation of the second child is not impor-tant, it is better to ignore it),
(2,3) the two children are composed with two dif-ferent weight matrix sets,
(4) the second child stands alone.
Now, imagine that we must handle binary syn-tactic rules with different head positions such as
S → NP V P (e.g. “Jones runs”) where the second child is the head andV P → V BD NP
(e.g., “ate spaghetti”) where the first child is the head. We can set those weight matrices such that when multiplyingW2by the vector of a head, we have a vector with high-value entries. And when multiplying W2 by the vector of a non-head, or when multiplyingW1 orW3 by a vector, the re-sulted vector has low-value entries. This is possi-ble thanks to the max pooling operation and that heads are often more informative than non-heads.
If the window sizekis smaller than the number of childrenl, the argument above is still valid in some cases such as head position. However, there is no longer a direct interaction between any two children whose distance is larger thank.3 In prac-tice, this problem is not serious because rules with a large number of children are very rare.
3.2 Chart Neural Network
Unseen sentences are always parsed by an auto-matic parser, which is far from perfect and task-independent. Therefore, a good solution is to give
3An indirect interaction can be set up through pooling.
the system a set of parses and let it decide which parse is the best or to combine some of them. The RNN model handles one extreme where this set contains only one parse. We now consider the other extreme where the set contains all possible parses. Because the number of all possible bi-nary parse trees of a length-n sentence is the n -th Catalan number, processing individual parses is not practical. We thus propose a new model work-ing on charts in the CKY style (Younger, 1967), called Chart Neural Network (ChNN).
We describe this model by the following exam-ple. Given a phrase “ate pho with Milos”, a ChNN will process its parse chart as in Figure 4. Be-cause any 2-word constituent has only one parse, the computation forp1, p2, p3is identical to Equa-tion 1. For 3-word constituent p4, because there are two possible productions p4 → ate p2 and
p4 → p1 with, we compute one vector for each production
u(1) =f(W
1xate+W2p2+b) u(2) =f(W1p1+W2xwith+b)
(3)
and then apply the max pooling operation to these two vectors to compute p4. We do the same to compute p5. Finally, at the top, there are three productions p6 → ate p5, p6 → p1 p3 and
p6 →p4 Milos. Similarly, we compute one vec-tor for each production and employ the max pool-ing operation to computep6.
Because this ChNN processes a chart like the CKY algorithm, its time complexity isO(n2d2 +
n3d) wheren and dare the sentence length and the dimension of vectors, respectively.4 A ChNN is thus notably more complex than an RNN, whose complexity is O(nd2). Like chart parsing, the complexity can be reduced significantly by prun-ing the chart before applyprun-ing the ChNN. This will be discussed right below.
3.3 Forest Convolutional Network
We now introduce the Forest Convolutional Net-work (FCN) model, which is a combination of the RCNN and the ChNN. The idea is to use an au-tomatic parser to prune a chart5, debinarize pro-ductions (if applicable), and then apply a ChNN
4In each cell, we apply the matrix-vector multiplication
two times and (if the cell is not a leaf) apply the max pooling to a pool of maximallyn d-D vectors.
5Pruning a chart by an automatic parser is also not
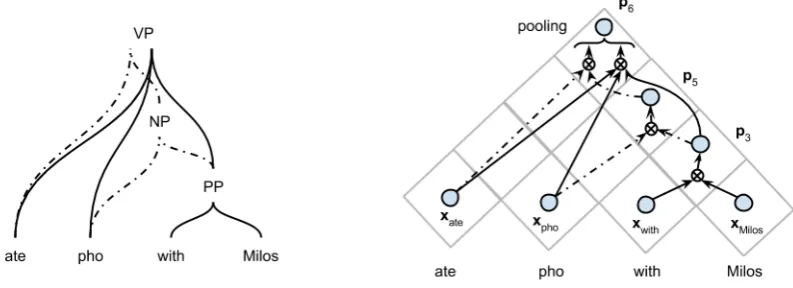
F-Figure 5: Forest of parses (left) and Forest Convolutional Network (right). ⊗denotes a convolutional layer followed by the max pooling operation and a fully connected layer as in Figure 3.
where the computation in Equation 3 is replaced by a convolutional layer followed by the max pool-ing operation and a fully connected layer as in the RCNN.
Figure 5 shows an illustration how the FCN works on the phrase “ate pho with Milos”. A forest of parses, given by an external parser, comprises two parses (V P ate pho (P P with Milos)) (solid lines) and (V P ate (NP pho (P P with Milos))) (dash-dotted lines). The first parse is the preferred reading if Milos is a person, but the second one is a possible reading (for instance, if Milos is the name of a sauce). Instead of forcing the external parser to decide which one is correct, we let the FCN network do that because it has more information about the context and domain, which are embedded in training data. What the network should do is depicted in Figure 5-right.
Training Training an FCN is similar to train-ing an RNN. We use the mini-batch gradient de-scent method to minimize an objective functionJ, which depends on which task this network is ap-plied to. For instance, if the task is sentiment anal-ysis,J is the cross-entropy over the training sen-tence setDplus an L2-norm regularization term
J(θ) =−|D|1 X
s∈D
X
p∈s
logP r(cp|p) + λ2||θ||2
where θ is the parameter set,cp is the sentiment
class of phrase p, p is the vector representation at the node coveringp,P r(cp|p) is computed by
score on section 23 of the Penn Treebank whereas resulted forests are very compact: the average number of hyperedges per forest is 123.1.
the softmax function, and λis the regularization parameter.
The gradient ∂J/∂θ is computed efficiently thanks to the back-propagation through structure (Goller and K¨uchler, 1996). We use the AdaGrad method (Duchi et al., 2011) to automatically up-date the learning rate for each parameter.
4 Experiments
We evaluate the FCN model with two tasks: ques-tion classificaques-tion and sentiment analysis. The evaluation metric is the classification accuracy.
Our networks were initialized with the 300-D GloVe word embeddings trained on a corpus of 840B words6 (Pennington et al., 2014). The ini-tial values for a weight matrix were uniformly sampled from the symmetric interval−√1n,√1n
wherenis the number of total input units. In each experiment, a development set was used to tune the model. We run the model ten times and chose the run with the highest performance on the devel-opment set. We employed early stopping: training is halted if performance on the development set does not improve after three consecutive epochs.
4.1 Sentiment Analysis
The Stanford Sentiment Treebank (SST)7(Socher et al., 2013) which consists of 5-way fine-grained sentiment labels (very negative, negative, neu-tral, positive, very positive) for 215,154 phrases of 11,855 sentences. We used the standard split-ting: 8544 sentences for training, 1101 for devel-opment, and 2210 for testing. The average sen-tence length is 19.1. In addition, the treebank
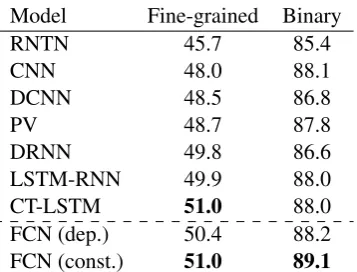
[image:5.595.102.499.71.215.2]Model Fine-grained Binary
RNTN 45.7 85.4
CNN 48.0 88.1
DCNN 48.5 86.8
PV 48.7 87.8
DRNN 49.8 86.6
LSTM-RNN 49.9 88.0 CT-LSTM 51.0 88.0 FCN (dep.) 50.4 88.2 FCN (const.) 51.0 89.1
Table 1: Accuracies at sentence level on the SST dataset. FCN (dep.) and FCN (const.) denote the FCN with dependency forests and with constituent forests, respectively. The accuracies of RNTN, CNN, DCNN, PV, DRNN, LSTM-RNN and CT-LSTM are copied from the corresponding papers (see text).
also supports binary sentiment (positive, negative) classification by removing neutral labels, leading to: 6920 sentences for training, 872 for develop-ment, and 1821 for testing.
All sentences were parsed by Liang Huang’s de-pendency parser8 (Huang and Sagae, 2010). We used this parser because it generates parse forests and that dependency trees are less deep than con-stituent trees. In addition, because the SST was annotated in a constituency manner, we also em-ployed the Charniak’s constituent parser (Char-niak and Johnson, 2005) with Huang (2008)’s for-est pruner. We found that the beam width 16 for the dependency parser and the log probability beam 10 for the other worked best. Lower values harmed the system’s performance and higher val-ues were not beneficial.
Our FCN has the dimension of vectors at inner nodes 200, a window size for the convolutional kernel of 7, and the activation functiontanh. It was trained with the learning rate 0.01, the regu-larization parameter10−4, and the mini batch size 5. To reduce the average depth of the network, the fully connected layer following the convolutional layer was removed (i.e.,p=x, see Figure 3).
We compare the FCN against other models: the Recursive neural tensor network (RNTN) (Socher et al., 2013), the Convolutional neural net-work (CNN) (Kim, 2014), the Dynamic convolu-tional neural network (DCNN) (Kalchbrenner et al., 2014), the Paragraph vectors (PV) (Le and
8http://acl.cs.qc.edu/∼lhuang/software
[image:6.595.93.272.61.197.2]Mikolov, 2014), the Deep recursive neural net-work (DRNN) (Irsoy and Cardie, 2014), the Re-cursive neural network with Long short term mem-ory (LSTM-RNN) (Le and Zuidema, 2015) and the Constituent Tree LSTM (CT-LSTM) (Tai et al., 2015).9
Table 1 shows the results. Our FCN using con-stituent forests achieved the highest accuracies in both fine-grained task and binary task, 51% and 89.1%. Comparing to CT-LSTM, although there is no difference in the fine-grained task, the dif-ference in the binary task is significant (1.1%). Comparing to LSTM-RNN, the differences in both tasks are all remarkable (1.1% and 1.1%).
Constituent parsing is clearly more helpful than dependency parsing: the improvements that the FCN got are 0.6% in the fine-grained task and 0.9% in the binary task. We conjecture that, be-cause sentences in the treebank were parsed by a constituent parser (here is the Stanford parser), training with constituent forests is easier.
4.2 Question Classification
In this task we used the TREC question dataset10 (Li and Roth, 2002) which contains 5952 tions (5452 questions for training and 500 tions for testing). The task is to assign a ques-tion to one in six types: ABBREVIATION, EN-TITY, DESCRIPTION, HUMAN, LOCATION, NUMERIC. The average length of the questions in the training set is 10.2 whereas in the test set is 7.5. This difference is due to the fact that those questions are from different sources. All questions were parsed by Liang Huang’s dependency parser with the beam width 16.
We randomly picked 5% of the training set (272 questions) for validation. Our FCN has the dimen-sion of vectors at inner nodes 200, a window size for the convolutional kernel of 5, and the activa-tion funcactiva-tiontanh. It was trained with the learn-ing rate 0.01, the regularization parameter 10−4, and the mini batch size 1. The vectors represent-ing the two paddrepresent-ing tokens<b>,<e>were fixed to0.
We compare the FCN against the Convolutional neural network (CNN) (Kim, 2014), the Dynamic convolutional neural network (DCNN)
(Kalch-9LSTM-RNN and CT-LSTM are very similar: they are
RNNs using LSTMs for composition. Their difference is that LSTM-RNN uses one input gate for each child where as CT-LSTM uses only one input gate for all children.
Model Acc. (%)
DCNN 93.0
MaxEntH 93.6
CNN-non-static 93.6
SVMS 95.0
LSTM-RNN 93.4
[image:7.595.115.249.62.158.2]FCN 94.8
Table 2: Accuracies on the TREC question type classification dataset. The accuracies of DCNN, MaxEntH, CNN-non-static, and SVMSare copied
from the corresponding papers (see text).
brenner et al., 2014), MaxEntH (Huang et al.,
2008) (which uses MaxEnt with uni-bi-trigrams, POS, wh-word, head word, word shape, parser, hypernyms, WordNet) and the SVMS(Silva et al.,
2011) (which uses SVM with, in addition to fea-tures used by MaxEntH, 60 hand-coded rules). We
also include the LSTM-RNN (Le and Zuidema, 2015) whose accuracy was computed by running their published source code11on binary trees from the Stanford Parser12(Klein and Manning, 2003). This network was also initialized by the 300-D GloVe word embeddings.
Table 2 shows the results.13 The FCN achieved the second best accuracy, only lightly lower than SVMS (0.2%). This is a promising result because
our network used only parse forests, unsupervis-edly pre-trained word embeddings whereas SVMS
used heavily engineered resources. The differ-ence between FCN and the third best is remark-able (1.2%). Interestingly, LSTM-RNN did not perform well on this dataset. This is likely be-cause the questions are short and the parse trees quite shallow, such that the two problems that the LSTM was invented for (long range dependency and vanishing gradient) do not play much of a role.
4.3 Visualization
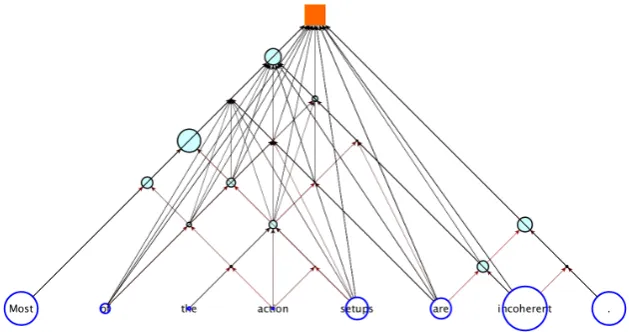
We visualize the charts we obtained in the sen-timent analysis task as in Figure 6. To identify how important each cell is for determining the fi-nal vector at the root, we compute the number of features of each that are actually propagated all the way to the root in the successive max pooling
op-11https://github.com/lephong/lstm-rnn
12http://nlp.stanford.edu/software/lex-parser.shtml 13While finalizing the current paper we discovered a paper
by Ma et al. (2015) proposing a convolutional network model for dependency trees. They report a new state-of-the-art ac-curacy of 95.6%.
erations. The circles in a graph are proportional to this number. Here, to make the contribution of each individual cell clearer, we have set the win-dow size to 1 to avoid direct interactions between cells.
At the lexical level, we can see that the FCN can discriminate important words from the others. Two words “most” and “incoherent” are the key of the sentiment of this sentence: if one of them is replaced by another word (e.g. replacing “most” by “few” or “incoherent” by “coherent”), the sen-timent will flip. The punctuation “.” however also has a high contribution to the root. This happens to other charts as well. We conjecture that the net-work uses the vector of “.” to store neutral features and propagate them to the root whenever it can not find more useful features in other vectors. Our fu-ture work is to examine this.
At the phrasal level, the network tends to group words in grammatical constituents, such as “most of the action setups”, “are incoherent”. Ill-formed constituents such as “of the action” and “incoher-ent .” receive little att“incoher-ention from the network.
Interestingly, we can see that the circle of “inco-herent” is larger than the circles of any inner cells, suggesting that the network is able to make use of parses containing direct links from that word to the root. This is evidence that the network has an ability of selecting (or combining) parses that are beneficial to this sentiment analysis task.
5 Related Work
simultane-Figure 6: Chart of sentence “Most of the action setups are incoherent .” The size of a circle is proposi-tional to the number of the cell’s features that are propagated to the root.
ously provides us with a solution to handle rules with different branching sizes.
Some approaches try to overcome the prob-lem of varying branching sizes. Le and Zuidema (2014b) use different sets of weight matrices for different branching sizes, thus requiring a large number of parameters. Because large branching-size rules are rare, many parameters are infre-quently updated during training. Socher et al. (2014), for dependency trees, use a weight matrix for each relative position to the head word (e.g., first-left, second-right). Le and Zuidema (2014a) replace relative positions by dependency relations (e.g., OBJ, SUBJ). These approaches strongly de-pend on input parse trees and are very sensitive to parsing errors. The approach presented in this pa-per, on the other hand, does not need the informa-tion about the head word posiinforma-tion and is less sensi-tive to parsing errors. Moreover, its number of pa-rameters is independent from the maximal branch-ing size.
Convolutional networks have been widely ap-plied to solve natural language processing tasks. Collobert et al. (2011), Kalchbrenner et al. (2014), and Kim (2014) use convolutional networks to deal with varying length sequences. Recently, Zhu et al. (2015) and Ma et al. (2015) try to intergrate syntactic information by employing parse trees. Ma et al. (2015) extend the work of Kim (2014) by taking into acount dependency relations so that long range dependencies could be captured. The model proposed by Zhu et al. (2015), which is very similar to our Recursive convolutional neural network model, is to use a convolutional network
for the composition purpose. Our work, although also employing a convolutional network and syn-tactic information, goes beyond them: we address the issue of how to deal with uncertainty about the correct parse inside the neural architecture. There-fore, instead of using a single parse, our proposed FCN model takes as input a forest of parses.
Related to our FCN is the Gated recursive con-volutional neural network model proposed by Cho et al. (2014) which is stackingn−1convolutional neural layers using a window-size-2 gated kernel (where n is the sentence length). Mapping their network into a chart, each cell is only connected to the two cells right below it. What makes this network special is the gated kernel which is a 3-gate switcher for choosing one of three options: directly transmit the left/right child’s vector to the parent node, or compose the vectors of the two children. Thanks to this, the network can capture any binary parse trees by setting those gates prop-erly. However, because only one gate is allowed to open in a cell, the network is not able to capture an arbitrary forest. Our FCN is thus more expressive and flexible than their model.
6 Conclusions
[image:8.595.141.456.64.230.2]and then choose or combine some of them. For more details, the two first issues are solved by em-ploying a convolutional net for composition. To the third issue, the network takes input as a forest of parses instead of a single parse as in traditional approaches.
Our future work is to focus on how to choose/combine different ways of computation. For instance, we might replace the max pooling by different pooling operations such as mean pool-ing, k-max pooling (Kalchbrenner et al., 2014), and stochastic pooling (Zeiler and Fergus, 2013). We can even bias the selection/combination to-ward grammatical constituents by weighing cells by their inside probabilities.
Acknowledgments
We thank our three anonymous reviewers for their comments. This work was funded by the Faculty of Humanities of the University of Amsterdam, through a Digital Humanities fellowship to PL and a position in the New Generation Initiative (NGO) for WZ.
References
Eugene Charniak and Mark Johnson. 2005. Coarse-to-fine n-best parsing and maxent discriminative reranking. InProceedings of the 43rd Annual Meet-ing on Association for Computational LMeet-inguistics, pages 173–180. Association for Computational Lin-guistics.
Kyunghyun Cho, Bart van Merri¨enboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014. On the properties of neural machine translation: Encoder–decoder ap-proaches. Syntax, Semantics and Structure in Statis-tical Translation, page 103.
Ronan Collobert, Jason Weston, L´eon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. The Journal of Machine Learning Re-search, 12:2493–2537.
John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. The Journal of Ma-chine Learning Research, pages 2121–2159. Jason Eisner. 2001.Smoothing a Probabilistic Lexicon
via Syntactic Transformations. Ph.D. thesis, Univer-sity of Pennsylvania, July. 318 pages.
Christoph Goller and Andreas K¨uchler. 1996. Learn-ing task-dependent distributed representations by backpropagation through structure. InInternational Conference on Neural Networks, pages 347–352. IEEE.
Liang Huang and Kenji Sagae. 2010. Dynamic pro-gramming for linear-time incremental parsing. In Proceedings of the 48th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 1077– 1086. Association for Computational Linguistics. Zhiheng Huang, Marcus Thint, and Zengchang Qin.
2008. Question classification using head words and their hypernyms. InProceedings of the Conference on Empirical Methods in Natural Language Pro-cessing, pages 927–936. Association for Computa-tional Linguistics.
Liang Huang. 2008. Forest reranking: Discriminative parsing with non-local features. InACL, pages 586– 594.
Ozan Irsoy and Claire Cardie. 2014. Deep recursive neural networks for compositionality in language. InAdvances in Neural Information Processing Sys-tems, pages 2096–2104.
Nal Kalchbrenner, Edward Grefenstette, and Phil Blun-som. 2014. A convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers), pages 655–665, Baltimore, Maryland, June. Association for Computational Linguistics.
Yoon Kim. 2014. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natu-ral Language Processing (EMNLP), pages 1746– 1751, Doha, Qatar, October. Association for Com-putational Linguistics.
Dan Klein and Christopher D Manning. 2003. Ac-curate unlexicalized parsing. InProceedings of the 41st Annual Meeting on Association for Computa-tional Linguistics-Volume 1, pages 423–430. Asso-ciation for Computational Linguistics.
Quoc Le and Tomas Mikolov. 2014. Distributed repre-sentations of sentences and documents. In Proceed-ings of the 31st International Conference on Ma-chine Learning (ICML-14), pages 1188–1196. Phong Le and Willem Zuidema. 2014a. The
inside-outside recursive neural network model for depen-dency parsing. In Proceedings of the 2014 Con-ference on Empirical Methods in Natural Language Processing. Association for Computational Linguis-tics.
Phong Le and Willem Zuidema. 2014b. Inside-outside semantics: A framework for neural models of se-mantic composition. In NIPS 2014 Workshop on Deep Learning and Representation Learning. Phong Le and Willem Zuidema. 2015. Compositional
Yann LeCun, L´eon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324.
Xin Li and Dan Roth. 2002. Learning question clas-sifiers. In Proceedings of the 19th international conference on Computational linguistics-Volume 1, pages 1–7. Association for Computational Linguis-tics.
Mingbo Ma, Liang Huang, Bowen Zhou, and Bing Xi-ang. 2015. Dependency-based convolutional neural networks for sentence embedding. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 174–179, Beijing, China, July. Association for Computational Linguis-tics.
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), 12.
Joao Silva, Lu´ısa Coheur, Ana Cristina Mendes, and Andreas Wichert. 2011. From symbolic to sub-symbolic information in question classification. Ar-tificial Intelligence Review, 35(2):137–154.
Richard Socher, Christopher D. Manning, and An-drew Y. Ng. 2010. Learning continuous phrase representations and syntactic parsing with recursive neural networks. InProceedings of the NIPS-2010 Deep Learning and Unsupervised Feature Learning Workshop.
Richard Socher, Eric H. Huang, Jeffrey Pennington, Andrew Y. Ng, and Christopher D. Manning. 2011. Dynamic pooling and unfolding recursive autoen-coders for paraphrase detection. Advances in Neural Information Processing Systems, 24:801–809. Richard Socher, Alex Perelygin, Jean Y Wu, Jason
Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep mod-els for semantic compositionality over a sentiment treebank. InProceedings EMNLP.
Richard Socher, Andrej Karpathy, Quoc V Le, Christo-pher D Manning, and Andrew Y Ng. 2014. Grounded compositional semantics for finding and describing images with sentences. Transactions of the Association for Computational Linguistics, 2:207–218.
Kai Sheng Tai, Richard Socher, and Christopher D. Manning. 2015. Improved semantic representa-tions from tree-structured long short-term memory networks. InProceedings of the 53rd Annual Meet-ing of the Association for Computational LMeet-inguistics and the 7th International Joint Conference on Natu-ral Language Processing (Volume 1: Long Papers),
pages 1556–1566, Beijing, China, July. Association for Computational Linguistics.
Daniel H Younger. 1967. Recognition and parsing of context-free languages in time n 3. Information and control, 10(2):189–208.
Matthew D Zeiler and Rob Fergus. 2013. Stochas-tic pooling for regularization of deep convolutional neural networks. arXiv preprint arXiv:1301.3557. Chenxi Zhu, Xipeng Qiu, Xinchi Chen, and Xuanjing