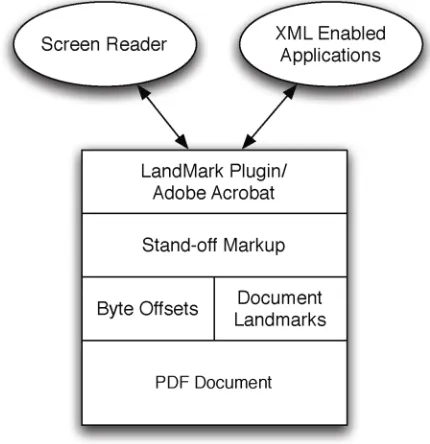
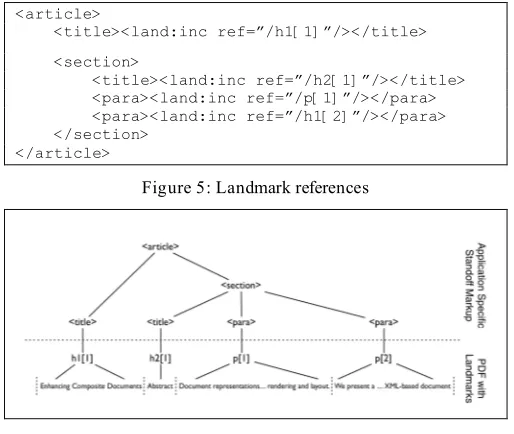
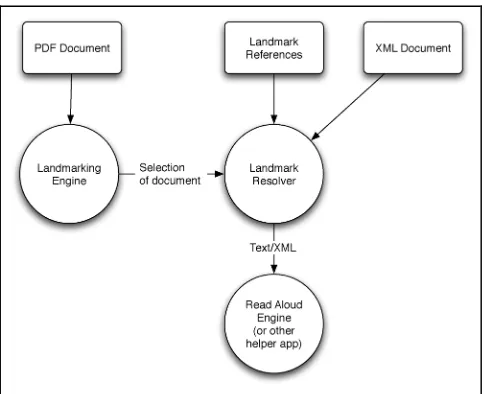
Enhancing composite Digital Documents Using XML based Standoff Markup
Full text
Figure
Related documents
Field experiments were conducted at Ebonyi State University Research Farm during 2009 and 2010 farming seasons to evaluate the effect of intercropping maize with
Experiments were designed with different ecological conditions like prey density, volume of water, container shape, presence of vegetation, predator density and time of
Applications of Fourier transform ion cyclotron resonance (FT-ICR) and orbitrap based high resolution mass spectrometry in metabolomics and lipidomics. LC–MS-based holistic metabolic
Private or personal libraries made up of written books (as opposed to the state or institutional records kept in archives) appeared in classical Greece in the 5th century BC. In
1) To assess the level of maternal knowledge about folic acid among women attending well baby clinic in ministry of health primary health care centers in
Функціонування Са 2+ /н + -обміну залежить від величини градієнта протонів та характеризується зворотністю, а саме в умовах залуження позамітохондріального
Since NCBI Viral Genomes contained only a small number endogenous nonretrovi- ral, endogenous retroviral, and LTR retrotransposon sequences, we further determined the extent to
