A Performance Centric Introduction to Cloud Computing
Introduction
Cloud computing refers to Internet based development and utilization of computer technology. It is a style of computing, in which dynamically scalable (and often virtualized) resources are provided as a service over the Internet. The concepts behind cloud computing incorporate Software-as-a-Service (SaaS), Platform-as-a-Service (PaaS), and Infrastructure-as-a-Service (IaaS), respectively. In today’s rather challenging economical environment, the promise of reduced operational expenditure, green computing advantages, along with more reliable, flexible and scalable application services made cloud computing a rather sought-after technology.
To further illustrate, cloud computing basically focuses on managing data and applications on the Internet instead of keeping these entities on enterprise owned (in-house) server systems. Besides demand-driven performance, data security, and data availability are clear advantages of the cloud-computing concept/methodology. The implication of cloud computing is that data center capabilities can be aggregated at a scale not possible for a single organization, and located at sites more advantages (as an example from an energy point of view) than may be available to a single organization per se. Hence, some of the major reasons for a company not to operate and maintain their own server systems can be summarized as:
Inflexible computing power
Incalculable maintenance costs
Insufficient data security
Performance, capacity, and scalability issues
Limited data accessibility (such as via Android, iPad, iPhone, or Blackberry)
Some of these IT challenges can be addressed via external computing centers. To illustrate, the performance demand of a company’s application workload can be distributed (virtually) onto many server systems in order to quickly and flexibly react to ever-changing requirements. Similar to clouds in the sky, IT resources either meld into one another or are being re-arranged if the workload driven requirement structure requires it. This approach significantly reduces IT costs, and warrants the availability, performance, and capacity behavior in a more reliable manner. Another key advantage of cloud computing is that in larger data centers, servers are operated more efficiently in regards to energy usage (an actual green computing issue), and therefore are (1) cheaper to operate, and (2) are much more environmentally friendly (much smaller carbon footprint).
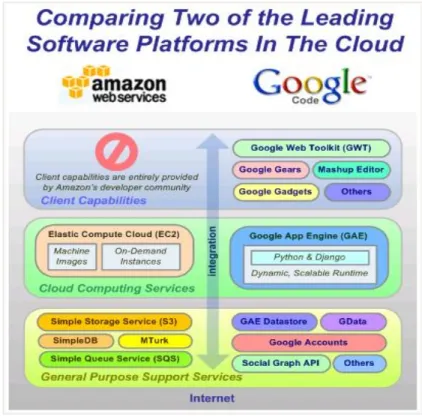
In the cloud computing paradigm, companies can access their data and applications, as well as re-assign IT resources (ad hoc) via the Internet 24/7. Therefore, cloud computing can be described as conducting business in an Internet based computing environment. The Internet reflects the cloud through which all business processes are controlled and executed. Some of the key contributors to cloud computing today are Amazon, AT&T, IBM, Microsoft, Google, Oracle/Sun, or Yahoo. All of these companies offer utilities, services, and application components to support the user community (see Figure 1). To illustrate, cloud services, such as Amazon’s Web Services and their Elastic Compute Cloud (EC2), are already providing scalability potential to environments such as Facebook, storage capabilities to support software downloads, or overflow compute capacity for websites around the globe.
Figure 1: Amazon and Google Cloud Computing Infrastructures
Cloud Computing & Performance Implications
It remains clear that improved operational competencies, 24/7 hardened environments, and accumulated economies of scale (facilities, power, compute capabilities, storage and bandwidth) will lead many enterprises to embrace the cloud computing model. Given the current economic backdrop, the need to reduce capital expenditure, and hence the need to support IT operations with limited budgets and personnel will lead more companies to closely evaluate cloud computing, and potentially migrate some of their application services to a cloud based environment. Some setups will resemble private clouds, in which a company’s data centers will be consolidated/replicated/outsourced (an approach more suitable for companies with high security & regulatory requirements), while other companies will embrace the more open service architectures such as the once offered by Amazon or Google (see Figure 1).
A major concern that has to be addressed to foster this migration is providing enterprise customers with the ability to understand and quantify how application performance will be impacted as services are moved into the cloud. The big question to be answered is how can development, performance, and test engineers ensure that their applications will be resilient and meet performance expectations in the unknown cloud environment. In most circumstances, it is a rather daunting task (due to the complexity of the cloud infrastructure) to assess cloud application performances via an empirical study (an actual benchmark). Therefore, as extensively discussed by the GRID and the cloud computing community, the most efficient and effective approach to quantify cloud application performance is via modeling. A model allows executing the necessary sensitivity studies to compare the status quo (the in-house IT solutions) to the cloud based (Internet) solutions/opportunities. Further, a model can be used to quantify the actual cloud application potential under different configuration scenarios.
It has to be pointed out that cloud services are rapidly maturing. Further, some management services are already available to requisition cloud systems with desired CPU power, memory, and storage requirements, respectively. Common cloud computing operations include installing an application environment, managing the access permissions, and executing the applications. Some cloud-computing
providers already offer APIs that allow companies to setup applications to execute in a specific geographic location (to place applications/data closer to the user community). The performance impact of this approach can be very effectively quantified via a cloud model as well.
A common question among companies that evaluate cloud computing (especially SaaS) is how SaaS differs from the application service provider (ASP) model. To some companies, the SaaS approach may appear similar to the better-known ASP model that basically failed after the dot-com era. The differences between the 2 models are actually striking. 1st, the ASP model focused on providing companies with the ability to move certain application processing duties to a 3d-party-managed server environment. Further, most ASP providers were not necessarily focused on providing shared services to multiple organizations. 2nd, most ASP supported applications were tailored towards the client-server paradigm, and only utilized rather simple HTML interfaces. Today’s SaaS solutions are specifically designed and implemented for the Web, substantially improving the performance, usability, and manageability behavior of the applications. In a nutshell, most ASP vendors were rather ill prepared, and rushed their offerings to market prior to addressing the actual performance, security, integration, and scalability issues. Today, most organizations are better prepared (much enhanced tools are available), and hence are normally better equipped to take advantage of SaaS. Ergo, the decrease in technical provisions, increase in user awareness, and all the cost saving measurements together provide the momentum for companies to (in general) successfully adopt a cloud computing approach.
In regards to actual performance management and capacity planning scenarios, what works in an IT data center (simply stated) just does not work in the cloud. While IT data centers are focused on CPU, memory, IO, and network (systems) utilization and throughput metrics, the ever-changing cloud environment renders collecting these metrics to isolate potential "performance problems" virtually impossible. The argument made is that focusing on the actual application business transactions is the only way to really quantify the performance behavior (or establish a performance baseline) in a cloud environment. Focusing on the business transactions further allows assessing the scalability potential of the application setup. Tracing the business transactions establishes the code-path that the application threads are taking through the cloud resources. The traces can further be used to establish the application workload profiles, and can be used to calibrate and validate any potential cloud application models. Further, assigning actual performance budgets to the individual business transactions allows quantifying aggregate application performance requirements, and determining the (potential) performance delta while running in a cloud setup.
Cloud-Computing – The WAN challenge
The value propositions promised by cloud computing are undeniable: Pay only for what you need.
Elastic capacity.
Lower entry cost and more efficiency.
While the market continues to be educated on how the cloud can deliver tremendous value, the concern about security and availability seem to always be the top considerations when it comes to taking advantage of what the cloud has to offer. In regards to security, how do you ensure that your company’s sensitive data is protected when you move it to the cloud? While security has been a top cloud computing concern, availability has stepped up the consideration list obviously driven by Amazon’s recent failure event with their EC2 platform. While security and availability are currently the top considerations for companies contemplating deploying cloud computing, WAN access performance can and should not be neglected. In a nutshell, the performance of cloud computing relies on the underlying network infrastructure. Irrespective of the type of service deployed, all cloud computing initiatives have one thing in common: data is centralized, while users are distributed. Such a set-up places an increased strain on the network, making cloud computing susceptible to bandwidth, latency and performance challenges. This in turn affects the delivery of the data, which can render cloud services impractical. Therefore, when it comes
to cloud computing in the enterprise, WAN optimization should not only be considered a priority, but the missing link that enables organizations to build and maintain a superior network.
Unfortunately, increasing the bandwidth connectivity between the users and the services in the cloud does not always help much. Bandwidth is normally shared among users accessing the cloud provider. Ergo, the biggest problem becomes latency. Applications such as Email or tasks like file-sharing require a significant amount of back and forth conversations to take place during the process of completing a data transfer operation. On a LAN with sub millisecond latency, these operations finish rather quickly. Over a high latency WAN link, each turn of the conversation incurs the penalty of the round trip time. Going cross-country, each turn could take a 10th of a second, and if there are thousands of turns, certain (application) operations may slow down significantly. As with LAN based latency concerns, WAN links can be mathematically abstracted to model and analyze the impact of WAN optimization techniques based on the actual physical infrastructure available and the company's workload at hand.
Cloud Computing – The Data Storage Challenge
The already discussed current proliferation of cloud computing and the associated growth of the user population comes with increasing and complex challenges of how to transfer, compute, and store data in a reliable (in actual real-time) fashion. Some of the challenges already discussed revolve around data transfer bottlenecks or performance variances. Some other issue to consider though is scalable (and reliable) storage (rapid scaling to varying workload conditions). Addressing these challenges of large-scale, distributed data, compute, and storage intensive applications such as social networks or search engines requires robust, scalable, and efficient data algorithms and protocols.
The Google File System (GFS) or the Hadoop Distributed File System (HDFS) are the most common (file system) solutions deployed today for Facebook, Amazon, Google or Yahoo. To illustrate, Apache's Hadoop project actually represents an entire framework for running applications on large cluster systems by utilizing commodity hardware. The Hadoop framework transparently provides applications with both, reliability and data motion, respectively. Hadoop further implements a computational paradigm labeled map/reduce, where the application is divided into n small fragments of work items, each of which may be executed (or re-executed) on any node in the cluster. In addition, Hadoop provides the already mentioned distributed file system (HDFS) that stores data on the compute nodes, providing high aggregate bandwidth capacity across the cluster nodes. Both, map/reduce and the distributed file system are designed so that any potential node failures are automatically handled by the framework.
Next to the data nodes, GFS and HDFS utilize a name node to store a list of all files in the cloud (as well as the file metadata). Further, the name node also manages most file related IO operations such as open, copy, move, or delete. Such a centralized file management approach may not scale very well, as the name node (under increased workload conditions) may become the bottleneck. If the name node reflects a single entity (such as for traditional HDFS), if the node goes down, the file system becomes unavailable. Hence, the suggestion made is to also consider/evaluate other distributed file systems such as Red Hat’s GFS, IBM’s GPFS, or Oracle’s Lustre while designing a ‘private’ cloud, or while offering cloud services to other users.
Cloud Computing – The Performance/Allocation/Capacity Evaluation Challenge
To assess (with a high degree of fidelity) the performance, resource allocation, or capacity behavior of a cloud environment is rather challenging. In general, addressing optimized resource allocation or task scheduling issues (both are paramount in a cloud environment) requires solving NP-Complete problems. NP-Complete problems are unlikely to be solvable in an amount of time that reflects a polynomial function. Further, cloud computing operates in a virtualized environment (to better utilize the available resources, and to minimize costs while at the same time optimize the profit). Having said that, it is a daunting task to accurately model (with a high degree of fidelity) virtualized systems (not only in a cloud
environment) to quantify/analyze performance, resource allocation, or capacity issues. The traditional modeling methods utilized to analyze non-virtualized environments normally do not provide a high fidelity in a virtualized systems setup. A virtualized systems setup utilizes some form of hypervisor (the hypervisor
basically runs on top of the HW, and is considered as firmware). The hypervisor allows the guest operating systems to run in an isolated fashion. Next to the hypervisor, in a virtualized environment, a virtual machine monitor (VMM), the virtual machines (VM) themselves, operating systems and applications installed on the VM's are present. Therefore, some of the major challenges faced while assessing the performance behavior of virtualized environments revolve around differences in the hypervisor implementations, resource inter-dependency issues, application workload variability's, as well as in disparity in collecting actual (accurate) performance data that can be used for the analysis.
To reiterate, virtualization adds several layers of complexity to the analysis process, as the VM's not only communicate with the HW, but also among themselves. The statement can be made that the performance and capacity models developed for non-virtualized environments generally cannot address the complexity and variability issues present in a virtualized setup. To illustrate, the commonly used regression or linear performance/capacity analysis techniques utilized in non-virtualized environments do not necessarily provide accurate models to quantify the application performance in a virtualized setup. To address these issues, the suggestion made is to use non-linear modeling techniques for cloud environments to achieve the high fidelity necessary to accurately determine the performance/capacity behavior. One possible approach would be to use Fuzzy Logic, whereas another approach could be the usage of artificial neural networks (ANN). Fuzzy logic, as well as ANN's can be used to design/develop cloud performance/capacity models that can accurately characterize the relationship between application performance and resource allocation.
(Open Source) Cloud Tools
In a cloud environment, the available tools are categorized as provisioning (installation),
configuration management (parameter settings, service & log maintenance), and monitoring (health check and alerts) solutions, respectively. For a cloud environment, in each category, there are several open source tolls packages available. Some of the provisioning tools are Cobbler or OpenQRM, while for configuration management, there are bcfg2, chef, or automateIT. On the monitoring side, some of the open source tools packages being utilized are Nagios (availability) or Zenoss (availability, performance, and event management).
One of the most popular performance monitoring tools for cloud installations is Ganglia. Ganglia represents a scalable, distributed monitoring system for high-performance computing systems. The toolset is based on a hierarchical design, targeted at federations of clusters. It leverages widely used technologies such as XML for data representation, XDR for compact, portable data transport, and the RRDtool for data storage and visualization. It uses sophistically engineered algorithms and data structures to achieve a very low (per-node) overhead and a high concurrency level. It is rather common in the cloud community to utilize actual open source tool-chains such as OpenQRM and Nagios or Nagios and Ganglia.
Summary & Conclusions
Cloud computing represents a very interesting architectural IT construct, provides some great potential from a monetary aspect, and reflects a very real option to deliver a more environmentally friendly computing platform. Cloud computing, while being very flexible from a resource perspective, provides additional challenges though (to any organization), which have to be taken into consideration while evaluating the new paradigm. The complexity of quantifying actual cloud application performance is much more challenging compared to an in-house IT solution.
The suggestion made is to utilize a (non-linear) modeling based approach (focusing on the actual business transactions) to address the performance questions/concerns in a proactive manner. These non-linear models (such as ANN's) can be used in the feasibility, design, as well as deployment phase to insure
the performance/scalability/availability goals can be met. Further, the models can be used in the maintenance phase to (pro actively) conduct capacity planning studies. With today’s technology, it is feasible for a company to model the platforms they will requisition in the cloud, load-test the solution(s) by simulating the actual user traffic (aka application business transactions) via the model, and to quantify the impact that the distributed, WAN-based setup (a.k.a. cloud computing) has on aggregate application performance.
Resources & References
The WWW in general
Cloud Computing Wiki, Wikipedia
Cloud blogs and discussion groups