Table of Contents
Legal Notice ...3
Executive Summary ...4
Purpose ...5
Understanding the Scale-Out Storage Model ...6
Common Scale-Out Architectures/Patterns ...6
Management ...7
Taxonomy ...7
Usage Scenario Mapping...8
Usage Scenarios ...9
Usage Scenario 1 – Request more on-demand cloud storage ...9
Usage Scenario 2 – Increase the capacity of the network-attached storage system for a network mount-point ...9
Usage Scenario 3 – Increase the performance of the direct-attached storage system for an in-memory database ...10
Usage Scenario 4 – Scale-out with multi-protocol support for heterogeneous workloads ...10
Lifecycle Model ...11
On-Demand Storage Capacity Cycle Model (Consumer Perspective) ...11
Scale-Out Storage Capacity (Direct- or Network-Attached) Cycle Model ...11
Scale-Out with Multi-Protocol Support for Heterogeneous Workloads Cycle Model ...12
Usage Requirements ...13
RFP Requirements ...15
Summary of Required Industry Actions ...15
Contributors
The following individuals from the Infrastructure Work Group contributed to the contents of this document: David Casper, UBS
Jason Davidson, EMC Karl Kohlmoos, HDS Freeman Ratnam, Intel IT Jeff Sedayao, Intel IT Aaron Sullivan, Rackspace Terry Yoshii, Intel IT
Legal Notice
© 2013 Open Data Center Alliance, Inc. ALL RIGHTS RESERVED.
This “Open Data Center AllianceSM Master Usage Model: Scale-Out Storage Rev. 1.0” document is proprietary to the Open Data Center Alliance (the “Alliance”) and/or its successors and assigns.
NOTICE TO USERS WHO ARE NOT OPEN DATA CENTER ALLIANCE PARTICIPANTS: Non-Alliance Participants are only granted the right to review, and make reference to or cite this document. Any such references or citations to this document must give the Alliance full attribution and must acknowledge the Alliance’s copyright in this document. The proper copyright notice is as follows: “© 2013 Open Data Center Alliance, Inc. ALL RIGHTS RESERVED.” Such users are not permitted to revise, alter, modify, make any derivatives of, or otherwise amend this document in any way without the prior express written permission of the Alliance.
NOTICE TO USERS WHO ARE OPEN DATA CENTER ALLIANCE PARTICIPANTS: Use of this document by Alliance Participants is subject to the Alliance’s bylaws and its other policies and procedures.
NOTICE TO USERS GENERALLY: Users of this document should not reference any initial or recommended methodology, metric, requirements, criteria, or other content that may be contained in this document or in any other document distributed by the Alliance (“Initial Models”) in any way that implies the user and/or its products or services are in compliance with, or have undergone any testing or certification to demonstrate compliance with, any of these Initial Models.
The contents of this document are intended for informational purposes only. Any proposals, recommendations or other content contained in this document, including, without limitation, the scope or content of any methodology, metric, requirements, or other criteria disclosed in this document (collectively, “Criteria”), does not constitute an endorsement or recommendation by Alliance of such Criteria and does not mean that the Alliance will in the future develop any certification or compliance or testing programs to verify any future implementation or compliance with any of the Criteria.
LEGAL DISCLAIMER: THIS DOCUMENT AND THE INFORMATION CONTAINED HEREIN IS PROVIDED ON AN “AS IS” BASIS. TO THE MAXIMUM EXTENT PERMITTED BY APPLICABLE LAW, THE ALLIANCE (ALONG WITH THE CONTRIBUTORS TO THIS DOCUMENT) HEREBY DISCLAIM ALL REPRESENTATIONS, WARRANTIES AND/OR COVENANTS, EITHER EXPRESS OR IMPLIED, STATUTORY OR AT COMMON LAW, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, VALIDITY, AND/ OR NONINFRINGEMENT. THE INFORMATION CONTAINED IN THIS DOCUMENT IS FOR INFORMATIONAL PURPOSES ONLY AND THE ALLIANCE MAKES NO REPRESENTATIONS, WARRANTIES AND/OR COVENANTS AS TO THE RESULTS THAT MAY BE OBTAINED FROM THE USE OF, OR RELIANCE ON, ANY INFORMATION SET FORTH IN THIS DOCUMENT, OR AS TO THE ACCURACY OR RELIABILITY OF SUCH INFORMATION. EXCEPT AS OTHERWISE EXPRESSLY SET FORTH HEREIN, NOTHING CONTAINED IN THIS DOCUMENT SHALL BE DEEMED AS GRANTING YOU ANY KIND OF LICENSE IN THE DOCUMENT, OR ANY OF ITS CONTENTS, EITHER EXPRESSLY OR IMPLIEDLY, OR TO ANY INTELLECTUAL PROPERTY OWNED OR CONTROLLED BY THE ALLIANCE, INCLUDING, WITHOUT LIMITATION, ANY TRADEMARKS OF THE ALLIANCE.
TRADEMARKS: OPEN CENTER DATA ALLIANCESM, ODCASM, and the OPEN DATA CENTER ALLIANCE logo® are trade names, trademarks, and/or service marks (collectively “Marks”) owned by Open Data Center Alliance, Inc. and all rights are reserved therein. Unauthorized use is strictly prohibited. This document does not grant any user of this document any rights to use any of the ODCA’s Marks. All other service marks, trademarks and trade names reference herein are those of their respective owners.
OPEN DATA CENTER ALLIANCE MASTER USAGE Model:
Scale-Out Storage Rev. 1.0
Executive Summary
This Scale-Out Storage Usage Model extends the “ODCA Compute Infrastructure as a Service (CIaaS) Master Usage Model”1 and specifies the common usage patterns and requirements for CIaaS storage, which have typically used a scale-out approach.
Essentially, a scale-out storage system is designed so that adding more capacity or increasing performance is relatively easy, efficient, and non-disruptive. Enterprises that contend with steadily increasing data demands can adopt a “just-in-time” supply-chain approach—useful in scenarios where it is difficult to predict upcoming storage needs. Instead of purchasing additional storage in anticipation of near-term needs, a out storage system can easily increase storage capacity as needed. Similarly, when storage needs decrease, the system can scale-in to reduce required capacity. Most importantly, a good scale-out architecture helps to prevent scenarios scale-in which large enterprise systems encounter growth barriers that cause expensive re-architecting and/or rebuilding when an existing system is outgrown.
Given the tremendous volumes of data handled in large-scale Internet services, companies such as Google and Facebook have come to rely on the capabilities of scale-out storage technology.
Scale-out storage systems are often implemented as object- and file-based systems. These systems present a unified namespace, appearing as one high-capacity repository to store billions of files or objects. Additionally, it is expected that many other core values of storage systems such as data retention, data protection, backup, failover, and elimination of single point of failures (SPoFs) should also scale with the solution. Scale-out storage effectively meets the requirements for cloud-storage providers and software-as-a-service (SaaS) providers. A hallmark of cloud-computing technology is the perception of infinite resources. Consumers can quickly gain access to whatever level of resources is needed. Having a well-designed scale-out storage system helps to enable storage providers to efficiently offer this type of service flexibility.
Purpose
This usage model describes typical usage scenarios for scale-out storage and their corresponding requirements in order to foster industry consistency.
For the storage consumer in the cloud-storage scenario, the highest-level requirement is that the perception of infinite storage resources be met. That is, the consumer can purchase as much storage as desired on-demand. It is equally important from the storage consumer perspective that they be able to order such storage from one or multiple providers in a consistent manner and also have the ability to easily move their data across providers. (Note that this usage model focuses on only scale-out storage; other ODCA usage models address service brokering as well as interoperability and portability.2)
The most common business driver from the consumer perspective for cloud-based scale-out storage is:
• On-demand capacity at service-level agreement performance. The ability to store as much content as required and never having to deal with actual low-level storage scaling, such as capacity planning, architecting, and engineering. Typical uses of such storage are for image repositories, content delivery, and business continuity.
For the storage provider, the highest-level requirement is that the storage must be simple, efficient, and non-disruptive to scale storage in and out.3
The two most common high-level business drivers from the provider perspective for scale-out storage include:
• Scale-Out Network-Attached Storage.4 Network “drives”—dedicated or shared—that can efficiently grow (or shrink) without encountering architecturally disruptive growth barriers. Some common usages for such storage include typical read/write network “shares,” WORM5 archiving/compliance, databases, and backup/data recovery.
• Scale-Out Direct-Attached Storage.6 Like network-attached storage, the requirement is to be able to efficiently grow (or shrink) without encountering architecturally disruptive growth barriers. Some common usages for such storage include in-memory databases, single or clustered file systems, and caches.
2 The specific details of service brokering are covered in the “ODCA Service Orchestration Master Usage Model.” 3 This scenario applies to cloud-storage providers as well as to traditional enterprise IT storage providers.
4 IP-based (that is, the common assumption is that scaling LUNs/FC and so on is typically less suited to true scale-out operations). 5 write once, read many (WORM).
Understanding the Scale-Out Storage Model
While it is not the goal of this usage model to define and describe out storage, a quick high-level description of what is meant by scale-out storage is provided as follows:
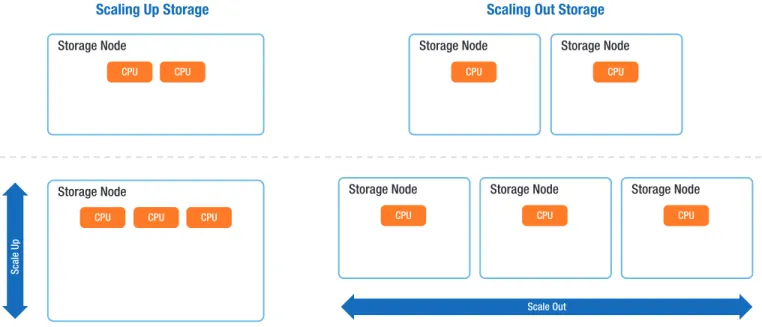
Figure 1 illustrates the concept of scale-out storage as compared to scale-up storage. In order to scale to accommodate increased performance demands, scale-up storage adds more disk drives and CPUs to deal with increasing user demand. In scale-out storage implementations, additional storage nodes are used to increase capacity.
Disk Disk Disk
CPU CPU
Storage Node
Disk Disk CPU Storage Node
Disk Disk CPU Storage Node
Disk Disk Disk Disk Disk Disk Disk
CPU CPU
CPU
Disk Disk CPU Storage Node
Disk Disk CPU Storage Node
Disk Disk CPU Storage Node Storage Node
Scale Up
Scale Out
Scaling Up Storage Scaling Out Storage
Figure 1. Scale-out storage compared to scale-up storage. Common Scale-Out Architectures/Patterns
The following scale-out architectures and patterns are commonly found, and scale-out designs should consider and support each:
• SAN array fronting multiple network-attached storage heads
• Shared-disk clustered file system
• Shared-nothing cluster
• Cross-node RAID
• Erasure coding
• Mirroring
• Low-latency, high-IOPS
Management
The following aspects need to be considered when designing scale-out storage systems:
• Absence of fixed or static control nodes
• Software aspects of scale-out
• Hardware aspects of scale-out
• Capacity scale-out
• Performance scale-out
• I/O scale-out
• Rapid, simple, dynamic/automated, and non-disruptive
• Unified namespace and volume
• Abstracted, dynamic virtual storage “pools”
• Control and interconnect plane aspects of scale-out
• Data plane aspects of scale-out
• Integration with CIaaS/virtualization
• Sustaining engineering
• API and programmability
• Synergies with SDN and software-defined storage7
Taxonomy
Table 1 lists the standard terms and definitions used in this document.
Table 1. Terms and definitions.
Actor Description
Control Node One or more nodes that (dynamically) implements the control plane of a storage system.
Namespace A storage presentation layer construct used to facilitate a consistent and normalized means to represent or de-reference storage location or content.
Node A unit of storage compute or capacity that can be added or removed easily from a storage system.
Scale-Out Typically involves adding more nodes to increase performance or capacity.
Scale-Up Typically involves making individual nodes larger (or replacing them with larger nodes) to increase performance or capacity.
Storage Consumer A person or organization that is using storage services. Typically agnostic to underlying scale-out storage architectures.
Storage Provider An organization providing storage services. Typically directly concerned with design, implementation, and operational details of scale-out storage.
Sustaining Engineering
Applying patches, vulnerability updates, firmware updates, and so on to a scale-out storage system in a dynamic manner that does not disrupt the storage consumer.
7 The storage must contemplate network virtualization. This is, in essence, a virtualized SAN. Generally, network virtualization is an IP-over-IP scheme where a mesh of point-to-point tunnels for a bottom substrate of any-to-any connectivity.
An end-user provisions a virtual network and is issued a subnet. Each time they attach a guest/vm (or any other end-point) they are issued an IP address via dhcp and behind the scenes a MAC that represents their virtual Ethernet device. There is an ARP Proxy function that intercepts all ARP requests, effectively shimming in between layers 2 and 3. We want to do the same thing for storage networking. Instead of an end-user, a storage administrator provisions a virtual storage network and is issued a subnet. They then attach storage nodes to this subnet to form a horizontally scaled, back-end storage tier.
Subsequently, end users will provision virtual block devices. This approach implies a volume manager residing between the virtual block device that the end user attaches their guest/vm to and the underlying virtual Ethernet device attached to the virtual storage network. This volume manager is integrated with a software virtual switch (that is, an OpenVSwitch).
Usage Scenario Mapping
Usage scenarios can be identified for each of the purposes identified in the Purpose section. One or more usage scenarios may apply to the purpose within a perspective.
The following are the described usage scenarios.
• Usage scenario 1. Request more on-demand cloud storage.
• Usage scenario 2. Increase the capacity of the network-attached storage system for a network “mount-point.”
• Usage scenario 3. Increase the performance of the direct-attached storage system for an in-memory database.
• Usage scenario 4. Scale out the storage environment (both performance and capacity) for intensive workloads such as Apache Hadoop. Table 2 describe the usage scenarios and associated business drivers. Table 3 lists the actors associated with scale-out storage.
Table 2. Usage scenarios and business drivers.
Business Driver Usage Scenario(s)
On-Demand Capacity 1 - Request more on-demand cloud storage.
Scale-Out Network-Attached Scenarios 2 - Increase the capacity of the network-attached storage system for a network “mount-point.”
Scale-Out Direct-Attached Scenarios 3 - Increase the performance of the direct-attached storage system for an in-memory database.
Scale-Out with Multi-Protocol Support for Heterogeneous Workloads
4 - Scale out the storage environment (both performance and capacity) for heterogeneous workloads such as the Hadoop Distributed File System combined with the Common Internet File System.
Table 3. Actors associated with scale-out storage.
Actor Scale-out Block Storage Scale-out File Storage Scale-out Object Storage
OS Images Yes
Application Images Yes
Application Data Yes Yes
Databases Yes
Temp Data Yes Yes
Log Data Yes Yes
Content Caching Yes Yes Yes
Active Content Repository Yes Yes
Content Sharing Yes
Content Distribution Yes Yes
Archiving Repository Yes Yes
Backup Repository Yes Yes
Image Repository Yes Yes
Usage Scenarios
Usage Scenario 1 – Request more on-demand cloud storage
Assumptions
• The cloud provider implements the Open Data Center Alliance “Service Catalog” Usage Model.8
• The consumer already has an existing account and storage capacity.
• The provider has made available an on-demand storage capacity request mechanism, such as a web-portal or API. Success Scenario 1
Upon consumer request, the provider can increase the total available storage capacity without disrupting any existing consumer storage and in time to accommodate additional consumer demand.
Failure Condition 1
The provider does not disrupt any existing consumer storage but is not able to increase its supply and is unable to fulfill new consumer storage requests.
Failure Condition 2
The provider is able to increase its supply, but inadvertently disrupts existing consumer storage.
Usage Scenario 2 – Increase the capacity of the network-attached storage system for a network mount-point
Assumptions
• An abstraction layer, such as a global namespace or clustered file system, is in place.
• The consumer already has network-attached storage mounted in one or more systems.
• The provider has a capacity management system in place that triggers a manual or automated workflow to increase capacity. Success Scenario 1
Upon a trigger for additional capacity, the provider can increase the total available storage capacity without disrupting any existing consumer storage; that is, no mount points needs to be re-mounted and no mounts points are disrupted during the capacity increase.
Failure Condition 1
The provider does not disrupt any existing consumer storage but is not able to increase its supply and is unable to fulfill new consumer storage requests.
Failure Condition 2
The provider is able to increase its supply but inadvertently disrupts existing consumer storage.
Usage Scenario 3 – Increase the performance of the direct-attached storage system for an in-memory database
Assumptions
• The consumer already has a running in-memory database (distributed across multiple hosts).
• The provider has a capacity management system in place that triggers a manual or automated workflow to increase performance.
• The database system has the ability to take advantage of additional resource nodes and spread the workload dynamically. Success Scenario 1
Upon a trigger for additional performance, the provider can increase the total available storage I/O performance without disrupting any part of the in-memory database.
Failure Condition 1
The provider does not disrupt the in-memory database but is not able to add nodes and therefore is not able to scale I/O performance as required. Failure Condition 2
The provider is able to add nodes but inadvertently disrupts the in-memory database.
Usage Scenario 4 – Scale-out with multi-protocol support for heterogeneous workloads
Assumptions
• An abstraction layer, such as a global namespace and clustered file system, is in place.
• The provider has a capacity management system in place that triggers a manual or automated workflow to increase capacity.
• The provider has a capacity management system in place that triggers a manual or automated workflow to increase performance.
• The consumer already has network-attached storage mounted in one or more systems.
• The consumer already has a policy in place to support multiprotocol access to data, for example reusing content from a mounted area via another common protocol, such as the Hadoop Distributed File System (HDFS), for processing.
Success scenario 1
When a consumer requests a second protocol to perform additional work on data, such as analytics, the scale-out storage solution will be able to fulfill this request without making redundant copies of the source data while scaling out both storage and performance needs to meet the analytical job. Upon completion it will return back to the lower performance and capacity environment.
Failure condition 1
Lifecycle Model
On-Demand Storage Capacity Cycle Model (Consumer Perspective)
The general theme of the lifecycle is that storage capacity can be non-disruptively increased or decreased on demand at any point in time. Figure 2 demonstrates the basic scenario.
Note that the analogous scenario for scaling I/O performance in and out would follow a similar lifecycle.
Request more capacity Initial Provision
Request more capacity Request less
capacity Request lesscapacity
Capacity N1 Capacity N2
Capacity N3 Capacity N4 Capacity N5
Figure 2. On-demand storage capacity lifecyle.
Scale-Out Storage Capacity (Direct- or Network-Attached) Cycle Model
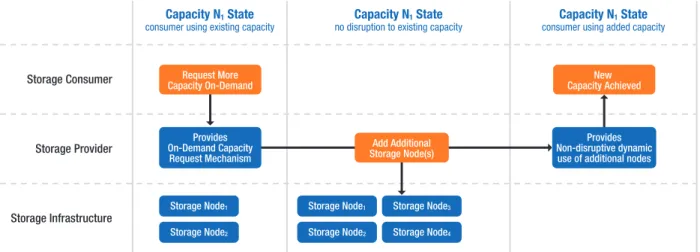
The general theme of the lifecycle is that storage capacity and/or IO can be non-disruptively increased or decreased without disrupting the existing storage usage. Whether it be direct-attached (host-based) or network-attached, the concept is that additional nodes can be efficiently and non-disruptively added. Figure 3 demonstrates the basic scenario.
Storage Consumer
Storage Provider
Storage Infrastructure
Capacity N1 State
consumer using existing capacity no disruption to existing capacityCapacity N1 State consumer using added capacityCapacity N1 State
Request More
Capacity On-Demand Capacity AchievedNew
Add Additional Storage Node(s) Provides
On-Demand Capacity Request Mechanism
Provides Non-disruptive dynamic use of additional nodes
Storage Node1
Storage Node2
Storage Node1
Storage Node2
Storage Node3
Storage Node4 Figure 3. Scale-out storage capacity lifecyle.
Scale-Out with Multi-Protocol Support for Heterogeneous Workloads Cycle Model
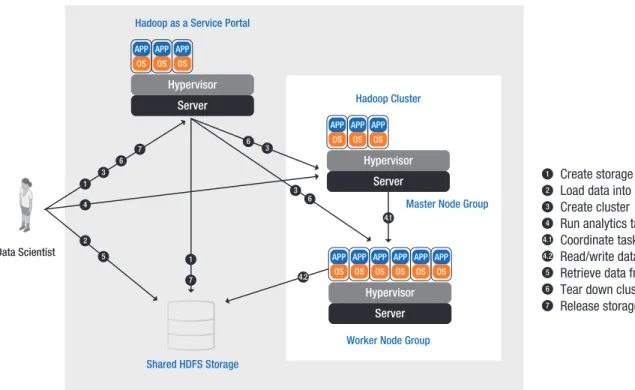
The scenario has three distinct roles: service provider admin, tenant admin, and data scientist. In this scenario the tenant admin has data stored with a service provider and needs to scale performance and capacity of their storage system to meet a data scientist’s request to utilize multi-protocol support to complete an analytics process. At the end of this scenario the system needs to return to the scale-in situation with lower performance and capacity needs.
As shown in Figure 4, in a non-scale storage solution there would be many copies of the same data replicated during the analytical job. In a scale solution there would be a single source of data used in all scenarios. Example workloads: Video surveillance files collected to a network share over Common Internet File System are duplicated into a HDFS area to support map-reduce jobs of web indexing, data mining, log file analysis, and machine learning.
Create storage pool Load data into storage pool Create cluster
Run analytics tasks Coordinate tasks Read/write data
Retrieve data from storage pool Tear down cluster
Release storage pool
1 2 3 4 4.1 4.2 5 6 7 Hypervisor Server APP OS APP OS APP OS APP OS APP OS APP OS Hypervisor Server APP OS APP OS APP OS Hypervisor Server APP OS APP OS APP OS Data Scientist
Hadoop as a Service Portal
Shared HDFS Storage
Hadoop Cluster
Master Node Group
Worker Node Group
1 3 2 4 1 7 5 6 3 6 4.1 4.2 6 3 7
Usage Requirements
The features in Table 4 are derived from the usage scenarios and lifecycle models in the previous sections and align with the ODCA “Standard Units of Measure for IaaS.”9 For this usage model, it is not intended that all of the features in a given column must be supported as a group. In practice, a given cloud service provider solution combines different service levels for different elements. For example, all Bronze performance feature requirements must first be met before combining features from any other performance level. For instance, Gold security features can be combined with Bronze.
Table 5 lists the service capabilities of a feature. Table 6 lists the common scale-out architectures and patterns for each service level. Table 7 defines the terms used in Table 6.
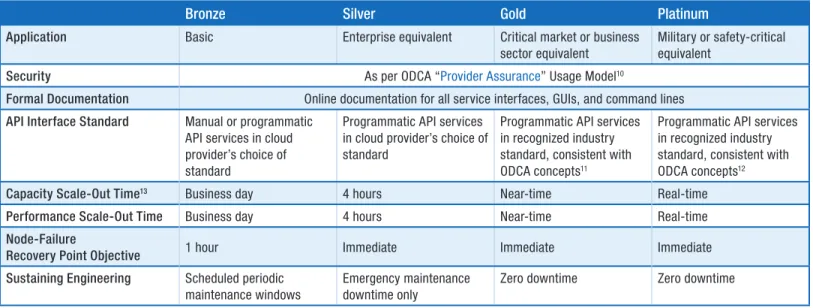
Table 4. Service levels.
Bronze Silver Gold Platinum
Application Basic Enterprise equivalent Critical market or business sector equivalent
Military or safety-critical equivalent
Security As per ODCA “Provider Assurance” Usage Model10
Formal Documentation Online documentation for all service interfaces, GUIs, and command lines
API Interface Standard Manual or programmatic API services in cloud provider’s choice of standard
Programmatic API services in cloud provider’s choice of standard
Programmatic API services in recognized industry standard, consistent with ODCA concepts11
Programmatic API services in recognized industry standard, consistent with ODCA concepts12
Capacity Scale-Out Time13 Business day 4 hours Near-time Real-time
Performance Scale-Out Time Business day 4 hours Near-time Real-time
Node-Failure
Recovery Point Objective 1 hour Immediate Immediate Immediate
Sustaining Engineering Scheduled periodic maintenance windows
Emergency maintenance downtime only
Zero downtime Zero downtime
Table 5. Service capabilities.
Must Have Feature would give value to the customer in a way that they feel would tightly influence their purchasing decision. Without this feature, it would gate the use of the product or service in the customer’s environment.
High Feature would be used by much of the customers’ environment or would be highly useful to the customer. Without this feature it may gate the use of the product or service in the customer’s environment.
Desired Feature desired to be in final product; does not gate shipment and will most likely not have a direct gate on the use of the product or service in the customer’s environment, but would be seen as a “nice to have.”
9 www.opendatacenteralliance.org/library 10 www.opendatacenteralliance.org/library
11 Same as SNIA Cloud Data Management Interface standard metadata. See http://www.snia.org/cdmi 12 Ibid.
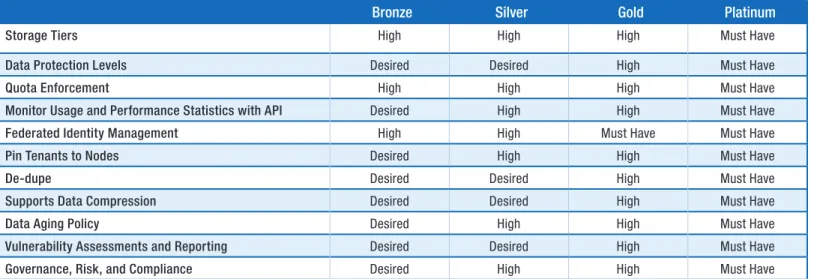
Table 6. Common Scale-Out Architectures/Patterns
Bronze Silver Gold Platinum
Storage Tiers High High High Must Have
Data Protection Levels Desired Desired High Must Have
Quota Enforcement High High High Must Have
Monitor Usage and Performance Statistics with API Desired High High Must Have
Federated Identity Management High High Must Have Must Have
Pin Tenants to Nodes Desired High High Must Have
De-dupe Desired Desired High Must Have
Supports Data Compression Desired Desired High Must Have
Data Aging Policy Desired High High Must Have
Vulnerability Assessments and Reporting Desired Desired High Must Have
Governance, Risk, and Compliance Desired High High Must Have
Table 7. Definitions.
Storage Tiers Ability to assign storage pools or tiers based on performance, data is moved between tiers by policy.
Data Protection Levels Data protection capabilities at file or individual object level (ability to set number of replicas and tolerate x number of disk or server failures).
Quota Enforcement Ability to set, enforce, and react to quotas by tenant or group, scaling the storage system to respond to quotas as needed.
Monitor Usage and
Performance Statistics w/API
Ability to monitor and report storage array components (such as arrays, LUN, capacity, configuration) for their usage and performance capabilities through APIs.
Federated Identity Management
A common set of policies, practices and protocols in place to manage the identity and trust into users and devices across organizations; for example, Lightweight Directory Access Protocol or Active Directory.
Pin Tenants to Nodes Ability to pin a tenant to a specific node of a cluster while supporting scale out. Each tenant can have its own authentication protocols.
De-dupe De-duplication of data across data arrays, with negligible impact to performance.
Data Aging Policy Ability to specify policies and procedures for infrequently accessed data, often moving older data into lower-cost storage.
Vulnerability Assessments and Reporting
Assessment of storage controller and networking switches for known vulnerabilities.
Governance, Risk, and Compliance
Audit level capabilities for definition, monitoring, and reporting of corporate and regulatory policies associated with specific tenants or applications.
RFP Requirements
The following are the requirements the Alliance suggests should be included in requests for proposal (RFP) to storage providers to confirm that proposed solutions support virtual machine Interoperability and consistency among management solutions.
The RFP questions are distilled from the parameters and models identified in the usage model and represent a conceptual evaluation base, instead of a specific technology analysis. The questions are intended to enable potential cloud subscribers to assist them in becoming aware of all of the relevant dimensions that they should consider in their evaluation of a proposed cloud service. These conceptual areas may lead to a potential cloud subscriber extending the questions with specific ones that pertain to their own organizations’ requirements.
The conceptual RFP questions for the “Scale-Out Storage” usage model are as follows:
• ODCA Principle Requirement. Is the solution open? Does it work on multiple virtual and non-virtual infrastructure platforms? Is it standards-based? Describe how the solution meets this principle and clarify any limitations it has in meeting these goals.
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Is the solution able to keep time in sync across nodes while adding, removing, or replacing nodes for scale out/in?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Is the solution able to auto-recover from adding or removing nodes? Will the system auto-sense when a node has been added, removed, or replaced and automatically recover the data integrity? Does this trigger a rebalance or other intensive operation that will impact performance?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Is the solution able to dynamically detect new storage resources and add them with minimal disruption to the available resource pool?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Does the software storage presentation layer for all storage products sufficiently abstract storage clients from growth and shrinkage in the underlying storage resources?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Is the solution able to dynamically scale capacity, performance, and I/O?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Does the solution provide single-plane-of-glass management framework for storage systems deployed across a variety of physical storage topologies including multiple vendor environments, at single or multiple locations?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Does the solution enable separate data into different tiers based on service-level agreement and performance (IOPS) requirements? The solution should enable data movement between tiers seamlessly to adjust for dynamic performance requirements and technology refreshes.
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Does the solution enable an online view of used and available storage capacity specific to each tenant?
• ODCA Scale-Out Storage Usage Model Rev. 1.0. Does the solution provide integrated storage platform for block and file access? The entire infrastructure should be managed by a common management interface.
Click here for an online assistant, Proposed Engine Assistant Tool (PEAT),14 to help you detail your RFP requirements.
Summary of Required Industry Actions
To give guidance on how to create and deploy solutions that are open, multi-vendor, and interoperable, the Alliance has identified specific areas where it suggests there should be open specifications, formal or de facto standards, or common IP-free implementations. Where the Alliance has a specific recommendation on the specification, standard or open implementation, it is called out in this usage model. In other cases, we plan to work with the industry to evaluate and recommend specifications in future releases of this document.
The following industry actions are required to refine this usage model:
1. The ODCA needs to engage with SNIA to align this usage model with the SNIA’s scale-out storage specification efforts.