DYNAMIC SUPPORTING:
AN EFFICIENT METHOD
FOR REPLICATED FILE SYSTEMS
Ping Hu
Thesis subm itted for the degree of P hD .
D epartm ent o f C om puter Science
U niversity College London
ProQuest Number: 10106648
All rights reserved
INFORMATION TO ALL USERS
The quality of this reproduction is dependent upon the quality of the copy submitted.
In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed,
a note will indicate the deletion.
uest.
ProQuest 10106648
Published by ProQuest LLC(2016). Copyright of the Dissertation is held by the Author.
All rights reserved.
This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC.
ProQuest LLC
789 East Eisenhower Parkway P.O. Box 1346
A b stra ct
In a d istribu ted com puting system, files can be replicated to im prove perform ance.
One-copy seriaJizabiHty is widely accepted as a correctness criterion for a repHcated
file system . In th e light of trade-off betw een consistency and availabihty, file replica
tion strategies can be classified into two groups: optim istic and pessim istic.
In this dissertation, a new pessimistic strategy is proposed for m aintaining the
m u tu a l consistency of repHcated file systems. UnHke m ost conventional voting algo
rithm s, votes are no longer attach ed to repHcas in th e proposed strategy. T he strategy
includes a basic algorithm , called dynamic supporting., which uses a poHcy Hke th e
available copies algorithm to m aintain repHcas and uses a modified dynam ic voting
algorithm to support those repHcas, and thus m aintains th e one-copy seriaHzabiHty in
th e presence of netw ork partitioning. The dynam ic supporting algorithm is extended
to dynam ic supporting algorithm with a greatest copy (dynam ic supporting(G ) algo
rithm , for short) to increase availabihty and other perform ance param eters.
These two algorithm s are hybrids of some existing algorithm s, and are designed to
com bine th e advantages of those algorithms. Since repHcas and votes are conceptu
ally separated, th e algorithms can achieve very good perform ance while stiU keeping
storage cost for file repHcation very low, especially only two repHcas for each logical
file. T he proposed algorithms are very efficient and simple to run. In th e algorithm s,
any operation on a logical file wifi never be blocked as long as all th e repHcas of this
logical file are available. If one or more repHcas are not accessible, th e votes for the
th a t th e one-copy seriaHzabiHty is ensured.
Availability and reliability are m ost widely used perform ance m easures for repH
cated file systems. B oth m easures for th e dynam ic supporting algorithm s and other
file repHcation algorithm s are evaluated and com pared in this dissertation. A system
m odel is proposed for stochastic analysis of such m easures. U nder this model, th e be
haviour of a given algorithm can be presented by a M arkovian chain or process so th a t
availabihty or reHabiHty can be evaluated by solving a set of Hnear equations or Hnear
differential equations, respectively. Sim ulation is conducted as a com plem ent and ex
tension to the stochastic analysis. T he system m odel for sim ulation is presented and
discussed as more reaHty is considered and p u t into th e m odel for stochastic analysis.
The system m odel for stochastic analysis can be viewed as an extrem e case of th e
system model for simulation. B oth of th e stochastic analysis results and sim ulation
results show th a t availabihty and reHabiHty for th e dynam ic supporting algorithm
and dynam ic supporting(G ) algorithm are m uch b e tte r th a n o th e r algorithm s, and
very close to th e available copies algorithm , which is usually regarded as th e best in
respect to these perform ance m easures. O th er perform ance m easures th a t affect th e
efficiency in a repHcated file system , such as netw ork traffic incurred by file repHcation
and transaction execution and processing tim e, are also analysed.
T he advantages of the proposed pessim istic stra teg y are shown in th e disserta
tion. T h e dynam ic supporting algorithm and th e dynam ic su pporting(G ) algorithm
are m ore a ttra ctiv e th a n other algorithm s because b o th of th em can achieve very
high availabihty and reHabiHty and also to lerate netw ork p a rtitio n failures while still
A ck n o w led g em en ts
Firstly, I would like to th a n k my supervisor, Professor Steve W ilbur, for his encour
agem ent, continuous support and guidance during my tim e working on this thesis.
My sincere th an k s also go to Ben Bacarisse and Sebnem Baydere for th eir help and
advice throughout this work.
Next, I am grateful to th e following people for their invaluable comments on
this thesis. Jo n Crowcroft and G raham K night carefully read earlier drafts of this
thesis and related research notes. Valerie Isham and Soren Sorenson courteously
offered their help and spent long hours discussing in depth th e system models and the
m athem atical deductions in this thesis. Chris M itchell and Tom Salkield volunteered
to read this thesis.
I would also hke to th a n k my p arents and my wife for their understanding and
encouragem ent during th e period of this work.
Lastly, I would Hke to express m y appreciation to th e B ritish Council and the
Chinese G overnm ent for th e financial support.
C o n te n ts
A b s tr a c t i
A c k n o w le d g e m e n ts iii
C o n te n t s v ii
L ist o f F ig u r es x iii
L ist o f T ab les x v
1 I n tr o d u c tio n 1
1.1 R eplicated File Systems ... 1
1.2 The D istributed E n v i r o n m e n t... 2
1.3 A tom ic C o m m itm e n t... 4
1.4 Correctness C r ite r ia ... 6
1.4.1 One-Copy S e ria liz a b ility ... 7
1.4.2 P artitio n ed Systems ... 8
1.4.3 O ther C r ite r ia ... 9
1.5 A bout This D i s s e r t a t i o n ... 11
1.5.1 O b je c tiv e s ... 11
1.5.2 W hy a New S t r a t e g y ... 12
1.5.3 O rganization ... 14
1.6 S u m m a r y ... 15
viii C O N T E N T S
2 F ile R e p lic a tio n S tr a te g ie s 17
2.1 Strategy C a te g o rie s ... 17
2.2 Available Copies ... 20
2.3 O ptim istic S t r a t e g i e s ... 20
2.3.1 Version V e c t o r s ... 21
2.3.2 O ptim istic P r o to c o l... 22
2.4 Voting S t r a t e g i e s ... 23
2.4.1 M ajority V o tin g ... 25
2.4.2 W eighted V o t i n g ... 25
2.4.3 Voting W ith W itn e s s e s ... 26
2.4.4 Vote A s s ig n m e n t... 27
2.4.5 Voting W ith Ghosts ... 28
2.4.6 Dynam ic Vote Reassignm ent P o H c ie s ... 29
2.4.7 Dynamic V o tin g ... 31
2.5 O th er Pessim istic S t r a t e g i e s ... 32
2.5.1 P rim ary S i t e ... 33
2.5.2 T o k e n s ... 33
2.5.3 Missing W rites ... 34
2.5.4 Rehable H is to r ie s ... 35
2.6 P e rfo rm a n c e ... 36
2.7 D is c u s s io n ... 38
2.8 S u m m a r y ... 39
3 D y n a m ic S u p p o r tin g A lg o r ith m s 41 3.1 Fundam entals of the A lg o rith m s ... 41
3.1.1 O bjectives and O r ig i n s ... 42
3.1.2 Algorithm F r a m e w o r k ... 44
3.2 D ynam ic Supporting A lg o r it h m ... 47
C O N T E N T S ix
3.2.2 Protocol for F a i l u r e s ... 51
3.2.3 C reate or Delete a F i l e ... 54
3.2.4 Protocol for R ead O p e r a tio n ... 54
3.3 An Extension— D ynam ic Supporting(G ) A l g o r i t h m ... 55
3.4 Correctness of th e A lg o r it h m s ... 57
3.5 Exam ples ... 59
3.6 D is c u s s io n ... 62
3.7 Sum m ary ... 64
4 A v a ila b ility A n a ly sis 65 4.1 Perform ance M e a s u r e s ... 65
4.2 System Models ... 67
4.2.1 A ssum ptions for Stochastic Analysis ... 68
4.2.2 A vailability E v a lu a tio n ... 70
4.2.3 S tate Transition D ia g r a m s ... 71
4.2.4 F u rth er A ssum ptions for S im u la tio n ... 72
4.2.5 D is c u s s io n ... 73
4.3 A vailability C o m p a r i s o n ... 75
4.3.1 A lgorithms C o n s id e r e d ... 76
4.3.2 A nalytical R esults ... 77
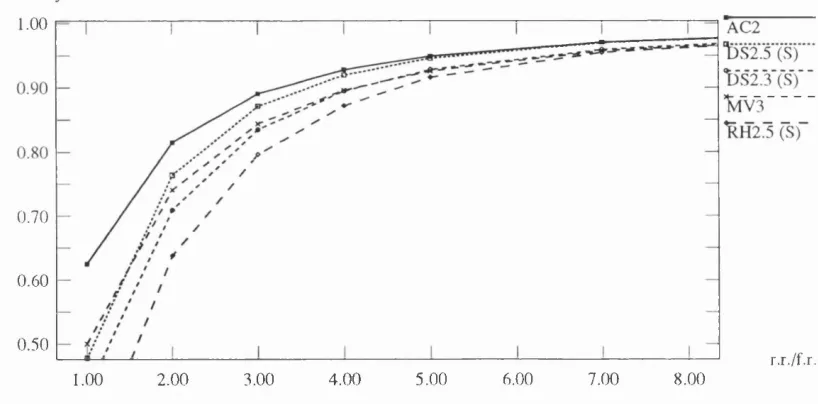
4.3.3 Com parison w ith Sim ulation R e s u l t s ... 82
4.4 S u m m a r y ... 87
5 R e lia b ility A n a ly sis 91 5.1 Stochastic A n a ly s is ... 92
5.1.1 From M arkovian Process to R e h a b i l i t y ... 92
5.1.2 Some A nalytical R e s u l t s ... 95
5.2 Features of ReHabiHty ... 98
X C O N T E N T S
5.2.2 M ean Tim e to Failure ... 101
5.3 R eliability S im u la tio n ... 102
5.3.1 S tatistical A n a ly s is ... 102
5.3.2 Linear R e g re s s io n ... 104
5.4 S u m m a r y ... . 107
6 F u rth e r P e r fo r m a n c e A n a ly sis 111 6.1 N etw ork Traffic A n a ly s is ... I l l 6.2 Efficiency C o n s id e r a tio n ... 116
6.2.1 Transactions E xecuted in Normal Environm ent ... 116
6.2.2 Transaction T e r m in a tio n ... 117
6.3 Average Transaction Execution T i m e ... 120
6.4 T ransaction Processing Tim e Analysis ... 123
6.4.1 F urth er A s s u m p tio n s ... 124
6.4.2 Stochastic A n a ly s is ... 126
6.4.3 Average Processing T i m e ... 127
6.5 S u m m a r y ... 129
7 C o n c lu sio n an d F u tu re W ork 131 7.1 G eneral S u m m a ry ... 131
7.1.1 T he Pessimistic File Replication A lg o r it h m s ... 132
7.1.2 Perform ance of Dynamic Supporting A lg o rith m s ... 134
7.2 F u tu re W o r k ... 137
7.2.1 F urth er Perform ance A n a ly s i s ... 137
7.2.2 A dapting Regeneration P o l i c y ... 138
7.2.3 Pilot Im p le m e n ta tio n ... 140
A G lo ssa r y 143
C O N T E N T S xi
C S t a te T ra n sitio n D ia g r a m 153
C l Functioning and H alted S t a t e s ... 153
C.2 Diagrams for Availability A n a ly sis... 154
C.3 Diagrams for Reliability A n a l y s i s ... 157
D P u b lis h e d W o rk 159
List o f F igu res
2.1 Conflict as version vectors in c o m p a tib le ... 21
2.2 Conflict betw een transactions executed in different p a r t i t i o n s ... 23
2.3 Logical stru c tu re of th e reliable histories algorithm ... 36
3.1 S tructure of dynam ic supporting s tr a te g y ... 45
3.2 Illustration flow diagram of transactio n execution... 47
4.1 Functioning states for th e dynam ic supporting algorithm ... 71
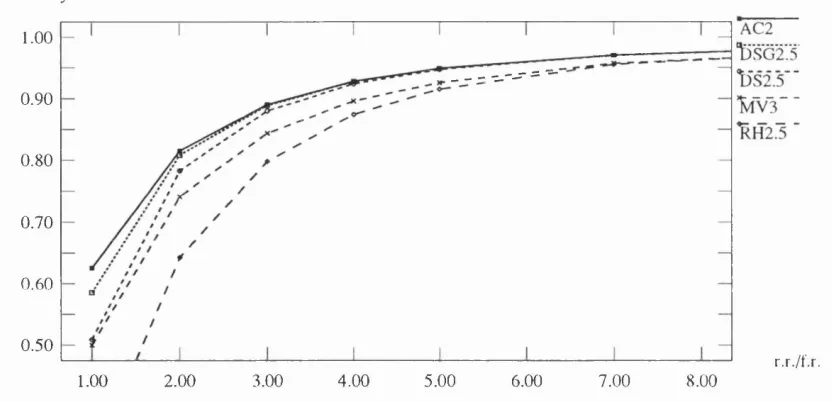
4.2 The analytical results com parison (availabihty versus 1 /p )... 78
4.3 As the ratio 1 /p goes large... 78
4.4 A vailabihty com parison when th e num ber of votes/histories increased. 79 4.5 The ratio 1//? goes larg e... 80
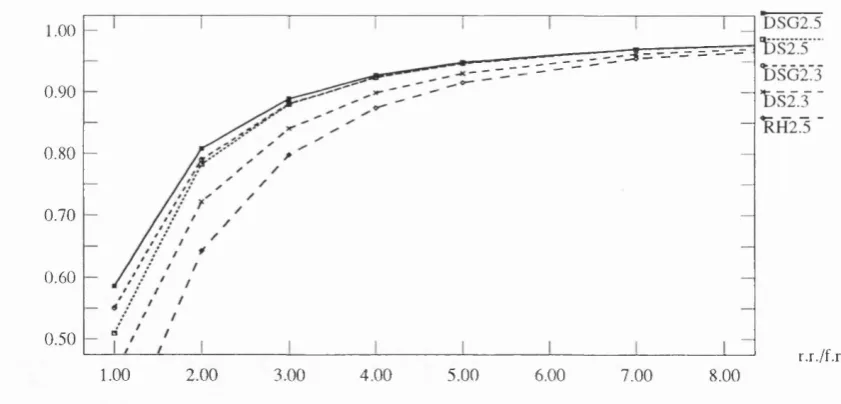
4.6 Compare DSG2, DS2 and RH2 w ith different num ber of votes/histories. 80 4.7 Compare DS2.3 and DSG2.3 w ith RH2.5 w hen I f p goes large... 81
4.8 The im pact of u p d a te to A C 2... 82
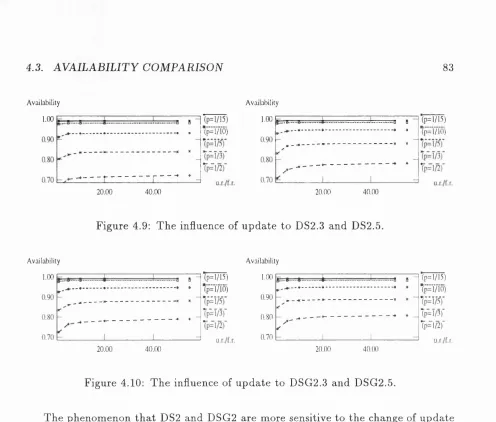
4.9 The influence of u p d a te to DS2.3 and DS2.5... 83
4.10 The influence of u p d a te to DSG2.3 and D SG 2.5... 83
4.11 Some sim ulation results DS com parison when 6 = 0.1... 84
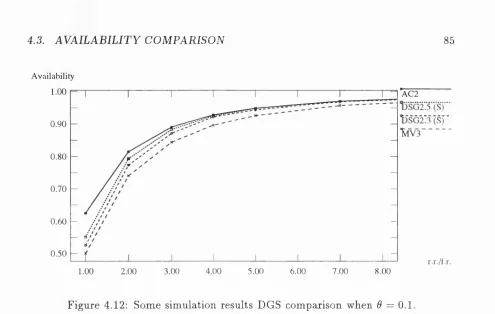
4.12 Some sim ulation results DGS com parison w hen 9 = 0.1... 85
4.13 Compare DS2.3 and DSG2.3 w ith RH2.5, sim ulation... 85
5.1 S tate transition diagram for th e dynam ic supporting(G ) algorithm . . 93
5.2 The analytical reh ab ih ty when p = 1 (log R {t)j versus X t)... 96
xiv L I S T OF F I G U R E S
5.3 The analytical reliability when p — 0.2... 97
5.4 The analytical rehability when p = 0.1... 97
5.5 The influence of 6 to rehability... 103
5.6 The rehabihty when p = 0.2 and 6 = 0.1... 104
6.1 M ulticast environm ent and n = 2 and p = 0.05... 114
6.2 Unique address environm ent and n = 2 and p = 0.05... 115
6.3 Several sites send messages to th e same destination... 120
6.4 Average tran sactio n execution tim e ... 123
6.5 S tate tran sition diagram for Q BD process... 126
C .l Groups Y = Q and y = 3 for dynam ic supporting algorithm ...154
C.2 G roups y = 1 for dynam ic supporting algorithm ... 155
C.3 Groups y = 2 for dynam ic supporting algorithm ... 156
C.4 Functioning state group for dynam ic supporting(G ) algorithm ... 156
C.5 Groups y = 0 for dynam ic supporting(G ) algorithm ... 156
C.6 G roups y = 2 for dynam ic supporting(G ) algorithm ... 157
C.7 S tate tran sitio n diagram for dynam ic supporting algorithm ... 158
List o f T ables
3.1 File state representation... 59
4.1 Notations of availability for various algorithm s... 77
4.2 Typical availability d a ta ... 79
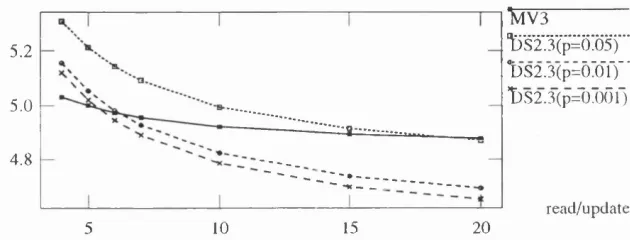
4.3 Simulation availability for m ore file copies in algorithm s... 86
5.1 The values of r i in the dom inant ite m s... 100
5.2 E stim ated values of Vi in th e dom inant item s for p = 0.2... 106
5.3 E stim ated values of r*i in th e dom inant item s for p = 0.1... 107
C h ap ter 1
In tro d u ctio n
A distributed system consists of a collection of independent com puters, called nodes oi
sites^ connected via com munication links. An often argued advantage of distrib u ted
system s is its graceful degradation. While one or m ore sites in th e d istrib u ted system
go down, th e rem ainder of th e system stays operable. In a distrib u ted h ie /d a tab a se
system , crucial resources can be repHcated at m any nodes in order to increase their
availabihty. By storing copies of critical hies at sites w ith independent failure modes,
th e probabihty th a t at least one copy of th e hie will be accessible increases. F u r
therm ore by storing copies of shared hies at sites where they are frequently accessed,
th e need for expensive, rem ote read accesses is decreased. In theory, hie repHcation
offers th e benehts of autonom y and perform ance, and makes it possible to provide
arbitrarily high hie availabihty.
1.1
R e p lic a te d F ile S y s te m s
A hie can be viewed as a set of logical data item s. T he g ranularity of these item s is
not very im p o rtan t in th e consideration in this dissertation. The state of a hie is an
assignm ent of values to the logical d ata items. A transaction is a process th a t issues
2 C H A P T E R 1. I N T R O D U C T I O N
are external to th e file system . T he files read by a tran sactio n co n stitute its read-set]
th e files w ritten by it co n stitu te its write-set. A read-only transaction neither issues
w rite requests nor has external effects [37].
Transactions in teract w ith one another indirectly by reading and w riting th e same
files. Two operations on th e sam e file are said to conflict if a t least one of th em issues
a w rite. Conflicts are often labelled either read-write^ write-read., or w rite-w rite,
depending on th e types of file operations involved and th eir order of execution [20].
Conflicting operations are significant because th eir order of execution affects th e final
file sta te or causes different ex tern al effects.
A d istrib uted file system usually means a file system im plem ented on a distributed
system . Users in teract w ith th e system by perform ing transactions. Of all kinds of
d istrib u ted file system s, a replicated file system , which is particularly relevant to this
dissertation, m eans th e value of each logical file is stored in one or more physical
files on sites of th e distrib u ted system . This dissertation deals w ith th e m anagem ent
strategies of such a replicated file system. In a replicated file system , each physical
file is referred to as a copy or replica. As a result of replication, each read and w rite
operation issued by a tran sactio n on some logical file m ust be m ap p ed by th e file
system to corresponding operations on physical copies. T he logic th a t is responsible
for perform ing this m apping is called either file replication algorithm or replica control
algorithm.
1.2
T h e D is tr ib u t e d E n v ir o n m e n t
In an ideal world, where sites and com m unication links never fail, th ere is a simple
way to perform th e replica control. W hen a tran sactio n wishes to read a file, th e
system reads any copy of it. W hen a transaction u p d ates a file, th e system applies
th e u p d a te to aU copies of it [42]. In practice, since sites or com m unication links are
subject to failure, realizing th e benefits of file replication is difficult since th e correct
1.2. T H E D I S T R I B U T E D E N V I R O N M E N T 3
link m eans th a t it does not perform according to its specification. Program m ing a
com puter system th a t is subject to failures is a difficult task. A m alfunctioning site or
com m unication link m ight perform arb itrary and spontaneous state transform ations
instead of th e transform ations specified by th e program s it executes. T hus even a
correct program cannot be counted on to im plem ent a desired in p u t-o u tp u t relation
when executed on a m alfunctioning processor. On th e oth er hand, it is alm ost im pos
sible to build a com puter system th a t always operates correctly in spite of failures in
its com ponents by using (only) a finite am ount of hardw are. T he goal of im plem ent
ing completely fault-tolerant com puting systems is u n attain ab le. Fortunately, m ost
apphcations do not require complete fault-tolerance. R ath er, it is sufficient th a t a
system work correctly provided th a t no more th a n some predefined num ber of failures
occur w ithin some tim e interval, or th a t certain types of failures do not occur. This
more m odest goal is attain ab le [142].
A general ty p e of failure th a t m ay exhibit a behaviour of sending conflicting
inform ation to o ther p a rts of th e system is ab stractly expressed as th e B yzantine
failure [92]. A fault-tolerant com ponent which copes w ith such failures often requires
a m eans by which an exact m utual agreem ent of some kind can be reached among
aU independent elem ents in th e component. As discussed in [130], some m ethods are
proposed to achieve interactive consistency, i.e. reaching agreem ent. To th e outside,
such a com ponent behaves m ore or less hke a fail-stop one. In th e following discussion,
only fail-stop failures will be considered. It is known th a t a failure occurs when th e
behaviour of th e com ponent (site or communication fink) is not consistent w ith its
sem antic definition. B ut a fail-stop com ponent is distinguished by its extrem ely simple
failure-m ode operating characteristics [142]. A fail-stop com ponent never perform s
an erroneous state transform ation due to a failure, instead it simply halts; and some
predefined portion of storage in th e component is defined to be stable or retrievable,
which m eans it is unaffected by any kind of fu rth er failures. In C h ap ter 2, besides
fail-stop failure, sometim es other types of com ponent failures are also involved in
fail-4 C H A P T E R L I N T R O D U C T I O N
stop, b u t also “knows” , while it re starts, th a t it failed so th a t it can in itiates a
recovery procedure. A detectable com ponent failure means th a t when it fails, o ther
com ponents in th e system can d etect this fact. B ut from now on, unless otherw ise
specified, only fail-stop is considered.
P artitio n failures are peculiar to d istrib u ted systems. A partitioning of a dis
trib u ted system occurs when th e sites in th e netw ork split into disjoint groups of
com m unicating sites due to site or com m unication fink failures. T he sites in each
group can com m unicate w ith each oth er, b u t no site in one group is able to com m u
nicate w ith sites in other groups. E ach of such group is referred to as a partition.
The design of a rephca control algorithm tolerating partitio n failures is a notoriously
hard problem . Typically, th e cause or ex ten t of a partitio n failure cannot be dis
cerned by th e sites themselves. A t b est, a site m ay be able to identify th e o th er sites
in its p artition; b u t, for th e sites outside its partitio n , it wiU not be able to d istin
guish betw een those sites which are sim ply isolated from it and those sites which are
down. In addition, slow responses from certain sites can cause th e netw ork to appear
partitioned even when it is not, fu rth er compHcating th e design of a fau lt-to leran t
algorithm. Unless p artitio n failures are detected and recognized by aU affected sites,
independent and uncoordinated u p d ates m ay be apphed to different copies of a file,
thereby compromising th e correctness of th e file. As a result, if a repHcated file system
is required to operate when it is p artitio n ed , th e com peting goals of availabihty and
correctness m ust somehow be m et. These goals are not independent; hence trade-offs
are involved.
1.3
A to m ic C o m m itm e n t
A tran sactio n on a repHcated file system typically executes at several sites sim ul
taneously. A tom ic com m itm ent m eans th e execution of each tran sactio n is “aU or
nothing” , i.e. either all of th e tra n sa c tio n ’s operations are perform ed or none are
1.3. A T O M I C C O M M I T M E N T 5
case it is said to be aborted. In order to ensure th e “all or nothing” pro p erty of th e
transaction, th e executing sites m ust unanim ously agree to com mit or to abort th e
transaction.
Preserving transaction atom icity in th e single-site case is a well-understood prob
lem [58, 93]. T he processing of a single transaction is simple. A t some tim e during
its execution, a “commit po in t” is reached where th e site decides to comm it or abort
th e transaction. A com m it is an unconditional guarantee to execute th e transaction
to completion, even in th e event of m ultiple failures. Similarly, an abort is an uncon
ditional guarantee to back out th e tran sactio n so th a t none of its effects persist. If
a failure occurs before th e com mit point is reached, th e n im m ediately upon recovery
th e site wiU abort th e transaction. B oth com m it and a b o rt are irreversible [148].
T he transaction atom icity in a distrib u ted system is an extension of th e single
site case. Viewed abstractly, in a com m itm ent protocol each p articip an t first votes
to accept or reject th e transaction according to its ability to process th e transaction
and th en decides w hether to commit or ab o rt based on th e voting. T he participants
m u st unanim ously agree to comm it or abort th e tran sactio n [37].
T he two-phase com m it protocol [58, 93] is a straightforw ard im plem entation of
this. The execution of a transaction consists of two phases. In th e first phase, a
designated participant, th e coordinator, sob cits th e votes from its cohorts. In the
second phase, it decides on th e basis of th e votes and th e n sends th e decision to aU
participants^. In th e course of th e protocol, each p articip an t voting “accept” goes
th ro u g h three distinct states: an uncom m itted state in which it has not voted, an in
doubt state in which it has voted bu t does no t know th e result of th e voting, and
a decision state in which it knows th e com m it/ abort decision. A p articip an t voting
“reject” does not occupy th e “in d o u b t” sta te since it knows th e eventual outcome.
Let us consider th e consequences of netw ork partitioning occurring during the
execution of th e two-phase com mit protocol. In each p a rtitio n th e p articipants,
act-^The com m it decision is m ade only if all cohorts unanim ously vote accept, otherwise abort is
6 C H A P T E R L I N T R O D U C T I O N
ing together, will a tte m p t to decide th e outcom e on th e basis of their states. If th e
partition contains th e coordinator, a decided p articip an t, or an uncom m itted p artici
pan t, a consistent decision can be reached (in th e case of an uncom m itted p articip an t,
abort win be chosen). However, a p a rtitio n containing only in-doubt p articip an ts and
lacking th e coordinator cannot safely decide: T he participants cannot com m it since
they do not know th e outcom e of th e voting, and th ey cannot abort since th ey m ay
contradict th e decision of th e coordinator. Hence these sites m ust w ait u n til recon
nection before deciding, and th e protocol (and associated transaction) is said to be
blocked at those sites.
Given th a t th e tw o-phase com m it protocol occasionally blocks, th e interesting
question th en is: Are th ere any nonblocking protocols for partitioning? T h e answer
is no. Even under th e m ost favourable, realistic partitioning assum ptions, th ere are
no nonblocking protocols [37]. This situation is even worse if sites can fail during a
partitioning; in this case th ere is no protocol th a t guarantees th a t even a single site
will be able to decide. Since it is impossible to elim inate blocking, it is desirable to
minimize it. Several protocols have been proposed th a t under appropriate p artitio n in g
assum ptions, block less th a n th e tw o-phase com m it protocol [146, 148].
1.4
C o r r e c tn e ss C r ite r ia
A generally accepted notion of correctness for a file system (not merely replicated file
system ) is th a t it executes transactions so th a t they appear to users as indivisible,
isolated actions on th e file. These properties, referred to as atomic execution^ are
achieved by guaranteeing b o th atom ic com m itm ent and serializability. T h e atom ic
com m itm ent has already been discussed in Section 1.3. T he serializability m eans th e
execution of several transactions concurrently produces th e same file s ta te as some
serial execution of th e sam e transactions.
T he first p ro p erty is established by th e com m it and recovery algorithm s of th e
1.4. C O R R E C T N E S S C R I T E R I A 7
tran sactio n exécution, together w ith the assum ption th a t transactions are correct,
implies by induction th a t the execution of any set of transactions transform s an
initially correct file state into a new, correct state. A lthough atom ic execution is not
always necessary to preserve correctness, m ost real d istrib u ted file system s im plem ent
it as th eir sole criterion of correctness. This is because atom ic execution is intuitive
and simple, an d can be enforced by very general m echanism s th a t determ ine th e
order of conflicting file operations. These mechanisms are independent of b o th th e
sem antics of th e file being stored and th e transactions m anipulating it.
1 .4 .1
O n e -C o p y S e r ia liz a b ility
T he following two criteria in com bination are m ost widely accepted as correctness
criteria for a replicated file system:
1. Replication control. T he m ultiple copies of file m u st behave like a single copy,
insofar as users can tell.
2. Concurrency control. The effect of a concurrent execution m ust be equivalent
to a serial one.
A replicated file system th a t achieves bo th th e replication control and th e concur
rency control has th e same in p u t/o u tp u t behaviour as a centralized, one-copy file
system th a t executes transactions one at a tim e [161]. Such behaviour is term ed
1-serializability or one-copy serializability [18]. As in a repHcated file system each read
and w rite operation on some logical file m ust be m apped to corresponding operations
on physical copies th e m apping (rephca control algorithm ) m ust ensure one-copy se
riaHzabiHty in order to keep th e file globally consistent. It is easy to see th a t th e
two term s, atom ic execution and one-copy seriaHzabiHty, are equivalent. The la tte r
is m ore Hkely used in th e area of file repHcation, and it puts m ore emphasis upon th e
repHcation control, which is of course not ju st tw o-phase com m itm ent, while assuming
8 C H A P T E R 1. I N T R O D U C T I O N
Some replicated file system s edlow additional correctness criteria to be expressed
in th e form of integrity constraints. Unlike one-copy seriaJizability, these are sem antic
constraints. T hey m ay range from simple constraints to elaborate co n strain ts th a t
relate th e values of m any files. In a file system enforcing in teg rity co n strain ts, a
transaction is allowed only if its execution is atom ic and its results satisfy th e in teg rity
constraints. To simplify th e discussion, throughout th e rest of th e dissertation, th e
integrity constraints are assum ed to be checked as p a rt of th e norm al processing of a
transaction.
1 .4 .2
P a r t it io n e d S y s t e m s
The m ain issue in designing a rephcated file system is th e degree to which global
consistency is required. In theory, a partition-processing strategy is com posed of
two algorithms: one to ensure correctness across partitions and a replica control
algorithm to ensure one-copy behaviour. In practice, m any strategies are designed as
a single algorithm th a t solves b o th problems. Most “single” algorithm s do not require
partitions to be d etected and to lerate m ore th a n ju st “clean” netw ork failures. Such
algorithm s are a ttra c tiv e for th eir additional fault tolerance.
In addition to solving th e problem of global correctness, a p artition-processing
strategy m u st solve tw o problem s of a different sort. F irst, w hen a p a rtitio n in g
occurs, th e rephcated file system is faced w ith th e problem of atom ically com m itting
ongoing transactions. T he com pfication is th a t th e sites executing a tran sactio n m ay
find them selves in different partitions, and thus unable to com m unicate a decision as
to w hether to com plete th e tran sactio n (com m it) or undo it (ab o rt). Second, w hen
partitions are reconnected, consistency betw een copies in different p artitio n s m u st
be reestabhshed. T h a t is, th e updates m ade to a logical file in one p a rtitio n m u st
be propagated to its copies in th e other partitions. Conceptually, this problem can
be solved in a straightforw ard m anner by ex tra bookkeeping w henever th e system
1.4. C O R R E C T N E S S C R I T E R I A 9
and very dependent on th e norm al recovery mechanisms employed in th e distributed
file system.
It is assum ed th a t a correct concurrency-control m echanism coordinates tran sac
tion execution w ithin a partition; hence transaction execution w ithin a p artitio n is
serializable, i.e. a tran sactio n , when executed alone, transform s an initially correct file
state into an o th er correct state. B u t, in general, copies of files m ay not be consistent
at p artitio n tim e because some have processed updates of a com m itted transaction
whereas others have not. T h a t m eans th e transaction is “blocked” , which has been
discussed in Section 1.3. Transactions at earher stages of processing can be aborted
and rerun in th e p artitio n containing th eir site of origin.
1 .4 .3
O t h e r C r it e r ia
Not all partition-processing solutions use one-copy serializabifity as th eir correctness
criterion, nor do all a tte m p t to m aintain correctness across p artitions, b u t such topics
will not be discussed thoroughly in this dissertation. For example, one correctness
criterion called E psilonserializability is proposed by P u and Leff [133], which offers
th e possibihty of m aintaining m u tu al consistency of rephcated files asynchronously. A
rephcated file system th a t guarantees Epsilon-seriahzability perm its tem p o rary and
hm ited differences among rephcas (inconsistency), but these rephcas are required to
converge to th e stan d ard one-copy seriahzabihty coherency as soon as all th e updates
messages arrive and are processed. O ther criteria can also be found in [7, 12, 19, 25,
37, 39, 49, 144, 166, 167]. Some interesting discussion can also be found in [24, 23,
38, 62, 89, 90, 140].
Based on a simple observation th a t a sufficient (b u t not necessary) condition for
m aintaining correctness is th a t no two partitions execute conflicting file operations,
one-copy seriahzabihty can be achieved simply by suspending operations in ah bu t
one of th e p artitio n groups and forwarding updates at recovery when th e distributed
apph-10 C H A P T E R 1. I N T R O D U C T I O N
cations in which partitions either occur frequently or occur when access to th e file
is im perative, this solution is not acceptable. O n th e other hand, availability can be
achieved simply by allowing aU sites to process transactions “as usual” . C orrectness
m ay be compromised, i.e. transactions m ay produce “incorrect” results, and th e file
copies in each group m ay diverge. In some applications, such “incorrect” results m ay
be acceptable in fight of th e higher availability achieved. W hen partitio n s are re
connected, th e problem s m ay be corrected by executing missing transactions in some
p artitions, and by choosing certain transactions to “undo” . If th e chosen tra n sac
tions have had no real-world effects, th ey can be undone by using stan d a rd datab ase
recovery m ethods. If, on th e oth er hand, th ey have had real-world effects, th e n ap
pro p riate compensating transactions m ust be run. A com pensating transactions not
only restores th e values of th e changed file b u t also issues real-world actions to nullify
th e effects of th e chosen transactions. A lternatively, correcting transactions can be
run, transform ing th e changed file from an incorrect state to a correct sta te w ithout
undoing th e effects of any previous transactions. Of course, in some applications
incorrect results are eith er unacceptable or incorrect able [37].
How th e p artitio n strategies tre a t blocked transactions depends on w hat file repli
cation strateg y is used. J u s t as discussed in Section 1.4.2, rephcated files at un d e
cided sites are simply rendered inaccessible u n til reconnection. This strateg y is quite
straightforw ard and can guarantee one-copy serializabifity, b u t availability is com
prom ised. A nother strateg y is m ore flexible. A p artitio n can ten tativ ely com m it or
abort a blocked tran sactio n . If its decision is inconsistent w ith o th er decisions, it can
resolve this in th e sam e way th a t it resolves other inconsistencies, viz. by rofiing back
th e offending tran sactio n and all dependent transactions. Since rolling back is fairly
expensive, a te n ta tiv e decision should be m ade only if it has a high probability of
being correct.
Since it is clearly im possible to satisfy b o th goals sim ultaneously, one or b o th
m ust be relaxed to some ex ten t, depending on th e application’s requirem ents. Re
1.5. A B O U T TH IS D I S S E R T A T I O N 11
at certain sites. Relaxing correctness, on th e other hand, usually requires ex ten
sive knowledge about w hat th e inform ation in the file represents, how apphcations
m anipulate th e inform ation, and how m uch undoing/correcting/com pensating incon
sistencies will cost.
1.5
A b o u t T h is D is s e r ta tio n
A lthough th e discussion in this dissertation is couched within a file system context,
most results have m ore general applications. In fact, th e only essential notion in m any
cases is th a t of a transaction. Hence these strategies are im m ediately apphcable to
database system s, m ail systems, calendar systems, object-oriented system s, and other
applications using transactions as th e ir underlying m odel of processing.
1 .5 .1
O b j e c t iv e s
M any file rephcation strategies use one-copy seriahzabihty as their criterion to m ain
tain rephcated files globally consistent. This dissertation discusses some of these
approaches and investigates b o th advantages and disadvantages of them . Based on
such analysis, a new hybrid approach is proposed, which is intended to inherit all
the advantages of underlying approaches. T he proposed approach includes a basic
file rephcation algorithm and an extension to it. The m ain purpose in proposing this
new hybrid approach is to provide very high and a ttra ctiv e perform ance features while
stiU keeping file rephcation levels very low, e.g. only two rephcas for each logical file.
The algorithm s are designed to m ake no m ore assum ptions about th e d istrib u ted en
vironm ent th a n conventional file rephcation algorithm s, such as th e m ajo rity voting,
and can even to lerate netw ork p artitio nin g failures. In other words th ey are simple
and efficient to run. The detailed specifications of th e algorithms are given, and th e
correctness of th e approach, i.e. m aintaining one-copy seriahzabihty, is proved.
12 C H A P T E R 1. IN T R O D U C T IO N
measures, availability and reliability, are emphasized. The advantages of th e p ro
posed algorithm s over o ther conventional algorithm s are shown in two ways. O ne is
stochastic analysis. Stochastic models are developed and corresponding M arkovian
chains/ processes are used to evaluate such perform ance measures. The intention is to
show th e significant perform ance im provem ent of th e proposed algorithms to others.
Such m easures of th e proposed algorithm s are much closer to th e so-called “b e s t”
algorithm th a n those of others. Sim ulation is also used to analyse these perform ance
measures as a com plem ent and extension to th e stochastic analysis. Sim ulation an al
ysis is necessary because for some more com plicated distributed environm ents, which
should be m ore appropriate to th e real world, it is very difficult or even impossible
to conduct stochastic analysis.
O ther perform ance m easures, such as netw ork traffic, transaction execution tim e
and transaction processing tim e, are thoroughly analysed as well. These param eters
represent th e m anipulation overhead of rephcated file systems, com pared to non-
repHcated ones.
The whole perform ance analysis gives a vivid picture of advantages of th e p ro
posed strategy. And, from th e analysis results, it is not difficult to conclude which
distributed environm ents are m ost suitable for im plem enting th e new hybrid algo
rithm s.
1 .5 .2
W h y a N e w S t r a t e g y
A lthough m any approaches have been proposed to m anipulate rephcated file system s,
quite a lot of them have various draw backs which prevent them from being easily
im plem ented or being widely used. This is p artly because some proposals are too
com phcated for present d istrib u ted technology and systems, such as most optim istic
strategies. Simple and efficient m ethods still need be developed for those strategies
to resolve th e possible inconsistencies, leaving alone th e conflict detection problem s.
1.5. A B O U T T H IS D IS S E R T A T IO N 13
whereas their other overhead costs, like decision m aking, netw ork traffic and ex tra
storage etc., are sometimes very heavy. Examples are th e missing writes algorithm
and some variations of th e m ajo rity voting algorithm s.
A lthough a few strategies th a t are simple and easy to u n d erstan d have been pro
posed and some of them are even im plem ented in some apphcations, such as the
available copies algorithm , th e prim ary copy algorithm and th e m ajo rity voting algo
rithm , they all inevitably have th eir own hm itations. T h ey are not too bad since each
of th em fits its own distributed environm ent and its perform ance is satisfactory for
th a t particular appHcation. However as th ey usually im pose strict requirem ents on
either th e distributed environm ent or transactions to be perform ed, one cannot expect
th em to be widely used in a more general distributed environm ent or apphcation.
One example is Kerberos database rephcation in th e Kerberos authentication ser
vice [153], p a rt of project A thena [30]. Each Kerberos realm has an authentication
database, and each record in th e database contains th e nam e, private key, and expi
ratio n d ate of a principal, along w ith some adm inistrative inform ation. The database
m ay be rephcated to increase its availabihty, reduce netw ork traffic and improve other
perform ance features. Among all database copies, only one of th em is nam ed as m as
ter] th e rest are nam ed as slaves. A ny change to th e K erberos database m ay only
be m ade to th e m aster copy and th e n the u p d a te propagates to th e slave copies at
given tim e intervals. If the m aster copy is down, au th en ticatio n , viz. read-only to th e
database, can still be achieved on any slave copy. It wül be seen in Section 2.5.1 th a t
this pohcy is a typical im plem entation of th e prim ary site strategy. In [153], Steiner et
al. claim th a t this rephcated database m anagem ent strateg y has not presented a prob
lem since adm inistration requests, e.g. changing passwords, are infrequent although
no perform ance analysis is given. Generally, it is quite possible th a t if updates to th e
rep hcated file are frequent th e prim ary site algorithm is im proper for an environm ent
th a t either th e netw ork is subject to p artitio n or of th e prim ary site’s availabihty is
not very high.
14 C H A P T E R 1. I N T R O D U C T I O N
easy to im plem ent and eilso achieves very satisfactory perform ance w ith low overhead
costs so th a t it can be used for a wide range of distributed environm ents and m any
apphcations.
1 .5 .3
O r g a n iz a tio n
The rem ainder of this dissertation is organized as following.
C hapter 2 introduces some common algorithm s. The discussion concentrates on
th e pessimistic algorithm s. T h e available copies algorithm is considered as th e best
one in respect of perform ance, b u t it cannot be used in th e distributed environm ents
where partition failures m ay occur. Voting is perhaps th e most common pessim istic
approach. There are m any variations of it, and vote assignment strategies are th o r
oughly discussed.
In C hapter 3, a new pessim istic algorithm , called dynamic supporting, and its ex
tension, called dynam ic supporting with a greatest copy (dynam ic supporting(G ) for
short), are proposed. T he correctness of th e algorithm s is proved. D etailed specifica
tion and some examples, w hich show how th e algorithm s work, are given. T he two
algorithm s also tolerate netw ork p artitio n failures.
Availability and reh ab ih ty of th e proposed algorithm s and some other algorithm s
are analysed and com pared in C h ap ter 4 and 5. File availabihty and rehabihty are
the m ost widely used perform ance m easures. In these chapters, stochastic analysis
is carried out. M arkovian chains and processes are used to analyse and com pare th e
availabihty and rehabihty of th e dynam ic supporting algorithm s and other common
algorithms. Sim ulation is also carried out as a com plem ent and extension to th e
stochastic analysis. Generally, b o th th e stochastic analysis and sim ulation results
show th a t availabihty and reh ab ih ty for th e dynam ic supporting algorithm s are very
close to the available copies algorithm , and b e tte r th a n other algorithm s.
F u rth er perform ance analysis is conducted in C hapter 6. Network traffic cost
1.6. S U M M A R Y 15
cost m ust be proportional to th e num ber of message transm issions for executing a
transaction. A nother perform ance m easure, average tran sactio n execution tim e, is
exam ined. T hen a quasi-birth-death (Q BD ) process m odel is created to characterize
th e behaviour of transaction processing tim e.
All th e analyses in C hapter 4, 5 and 6 lead to a conclusion th a t a rephcated file
system which employs th e dynam ic supporting strateg y can achieve very good and
a ttra c tiv e perform ance while overhead costs are minimal. It m ight be not proper to
claim th e dynam ic supporting strategy is th e best, b u t it is surely a very good choice
for m ost distributed environm ents.
Some general discussions, conclusions and possible fu tu re work are presented in
C h ap ter 7.
1 .6
S u m m a r y
In a distrib u ted file system, files are often rephcated to increase th eir availabihty, i.e.
th e probabüity th a t one or more rephcas are accessible in spite of node crashes. In a
rephcated file system, two transactions conflict if th ey b o th issue operations on the
sam e file and at least one of the operations is a w rite. A file rephcation algorithm or
rephca control algorithm is responsible for m apping each read and w rite operation on
some logical file to corresponding operations on rephcas.
Generally, a failure of a com ponent m eans it behaves arb itrarily instead of con
sistently w ith its sem antic definition. B ut in this dissertation only fail-stop failures
are considered in most cases. T he m ain featu re of a fail-stop com ponent is th a t it
never perform s an erroneous state transform ation due to a failure, instead it simply
halts. In addition, slow responses from certain com ponents behave hke a fail-stop
failure viewed by other sites. P artitio n failures are th e m ost disruptive of all failures
in a distrib u ted system. Typically, th e cause or ex ten t of a p artitio n failure cannot
be discerned by the sites them selves. A t best, a site m ay be able to identify th e other
16 C H A P T E R 1. I N T R O D U C T I O N
to to lerate th e p artitio n failures or to resolve th e problems caused by such failures.
The first problem in designing a file rephcation algorithm in a d istrib u ted sys
tem is th e “correctness criteria” . The final rephcated file state m ust be consistent
among all th e copies and m ake “sense” in th e face of concurrent tran sactio n exe
cutions or site/com m unication failures. The widely accepted correctness criterion is
called one-copy seriahzabihty, which guarantees a rephcated file system has th e same
in p u t/ o u tp u t behaviour as a centrahzed, one-copy file system th a t executes tra n sac
tions one at a tim e. T he one-copy seriahzabihty, which consists of rephcation control
and concurrency control, is chosen as th e sole correctness criterion in m ost cases of
designing file rephcation algorithm s because it is intuitive and simple, and can be en
forced by very general m echanism s th a t determ ine th e order of conflicting transaction.
T he m echanism s are also independent of bo th sem antics of rephcas an d transactions
C h a p ter 2
F ile R e p lic a tio n S tra teg ies
Various file replication strategies are proposed. This chapter presents some common
strategies and discusses th eir characteristics. In th e fight of th e trade-off betw een
consistency and availability, these partition-processing strategies can be classified
into two groups: optim istic and pessim istic. The m ain interest of this dissertation is
w ith th e pessim istic strategies. Some of th em are discussed in more details because
they wifi be used in th e following chapters.
2.1
S tr a te g y C a te g o r ie s
The basic ideas of th e file replication strateg y classification have been already dis
cussed in Section 1.4. Pessim istic strategies ensure th e global file consistency by
simply suspending transaction processing in all b u t one partition and forwarding
updates at recovery. O ptim istic strategies do it other way. All sites ju st process
transactions “as usual” . “Incorrect” file states caused by such strategies wifi be
u n d o n e/co rrected/co m p en sated when partitio n s are reconnected. W hich strategy is
chosen to im plem ent a replicated file system depends on th e application’s requirem ent.
In pessim istic strategies, when the underlying system is p artitioned or appears
to be p artitio n ed, each p artitio n m ust determ ine which transactions it can execute
18 C H A P T E R 2. F IL E R E P L IC A T I O N S T R A T E G I E S
w ithout violating th e correctness criteria. A ctually, this can be th o u g h t of as two
problems: ( l) each p artitio n m u st m ain tain correctness w ithin the p a rt of files stored
at the sites comprising th e p artitio n , and (2) each partitio n m ust m ake sure th a t its
actions do not conflict w ith th e actions of o ther partitions, so th a t th e distributed
file system is correct across all partitions. To keep th e exposition simple, th e n e t
work is assum ed “cleanly” p artitio n ed , i.e. any two sites in th e same p a rtitio n can
com m unicate and any two sites in different partitions cannot com m unicate.
If each site in th e netw ork is capable of detecting partition failures, th e first
problem , correctness w ithin a p a rtitio n can be m aintained by adapting one of the
stan d ard replica control algorithm s for n o npartitioned systems. T he difficult problem
is ensuring one-copy seriaHzability across p artitions. It is not sufficient to ru n a correct
rephca control algorithm in each p artitio n to ensure th a t overall tran saction execution
is one-copy serializable. Pessim istic strategies prevent inconsistencies by fimiting
availabihty. Each p artitio n m akes worst-case assum ptions about w hat oth er partitions
are doing, and operates under th e pessim istic assum ption th a t if an inconsistency can
occur, it wiU occur. These strategies differ prim arily in th e pohcy th ey use to restrict
transaction processing. C onsistency is enforced by perm itting files to be u p d ated
only in a single p artitio n at any tim e. (This p artitio n is often called th e m ajority
p artitio n .) As a consequence, any u p d ates th a t are p erm itted in a p artitio n do not
conflict w ith updates in oth er p artitio n s, assuring m u tu al consistency^ of files. Thus
it is straightforw ard to m erge th e results of individual partitions; u p d ates are merely
propagated from copies in one p a rtitio n to th eir counterparts in th e oth er partitions
at reconnection time.
O ptim istic strategies, on th e oth er hand, do not hm it availabihty. A ny tran sactio n
m ay be executed in any p artitio n th a t contains copies of th e item s read and
writ-^The m utual consistency m eans all copies of the sam e logical file m ust agree on exactly one
“current value” for the file. Furthermore, this value should “make sense” in terms of the transactions
executed on copies of the file. It is frequently used as a correctness criterion together w ith atom ic
2 .i. S T R A T E G Y C A T E G O R IE S 19
te n by th e transaction. Hence, although transaction processing w ithin each partitio n
is consistent, and no user staying w ithin a single p a rtitio n would detect an incon
sistency, global inconsistencies m ay be introduced. These strategies operate under
th e optim istic assum ption th a t inconsistencies, even if possible, rarely occur. At re
connection tim e, th e system m ust first detect inconsistencies and th en resolve them .
O ptim istic strategies differ prim arily in how th ey d etect and resolve inconsistencies.
These include undoing a set of th e transactions th a t have generated no significant
ex tern al actions, running compensating transactions to nullify th e effects of tran sac
tions generating external actions, and running corrective transactions th a t transform
th e file to a “self-consistent” , b u t not necessarily seriahzabihty, state. Obviously, th e
la tte r approach requires finding a suitable correctness criterion in hen of one-copy
seriahzabihty. Since coordinating th e undoing of transactions is a very difiicult task,
optim istic algorithm s are m ost useful in a situation in which th e num ber of files in
a p articu lar database is large and th e probabihty of conflicts among transactions is
small.
T h ere are algorithm s (see [139], for exam ple) th a t do not belong to either of th e
preceding tw o classes; however, they require a p n o n knowledge of th e kind of updates
to be m ade to th e file. They wiU not be discussed in this dissertation.
In th e foUowing sections, ah approaches use w hat has been discussed in Section 1.4
as th e correctness criterion and check seriahzabihty by com paring transactio n s’ read-
sets and w rite-sets. It is assumed th a t, at th e tim e of partitioning, ah copies are
m u tu a h y consistent and there are no in-progress transactions. N ote th a t this as
sum ption is not reahstic and is m ade to simphfy th e presentation. However such
“blocked” transactions are m entioned in Section 1.3 and 1.4, and th e problems are
20 C H A P T E R 2. F ILE R E P L I C A T I O N S T R A T E G I E S
2.2
A v a ila b le C o p ie s
T he available copies algorithm presented in [18] is only concerned w ith site failures,
so it is n eith er optim istic nor pessimistic^. This algorithm requires th e distributed
system m u st employ lower-level mechanisms to m ake site failures look clean and
d e tec ta b le , and m ust use a netw ork th a t never partitions.
For each file, th e algorithm m aintains a directory of th e copies of th e file th a t are
“available for use” . W hen a transaction reads it, th e algorithm consults th e directory
and reads some copy hsted there. W hen a transaction writes it, th e algorithm consults
th e directory and writes all copies. T he algorithm runs special status transactions to
keep directories up-to-date as sites fail and recover, and it requires th e distributed
system to provide a total failure facihty, which is able to determ ine w hether a ju st-
recovered site holds a current copy of th e rephcated file after all copies fail.
One v irtu e of this algorithm is th a t a transaction can operate on a file so long
as one or m ore copies are available. To tolerate k failures, th e system only needs
+ 1 copies. In particular, to tolerate single-site failures, th e system only needs two
copies. Secondly, a tran sactio n can read a file by accessing a single copy. If a user
has a copy of th e file at his local site, he can read it w ithout involving other sites.
T he m ain weakness is th a t th e algorithm handles a hm ited class of failures, namely,
clean, detectable site failures. It does not handle B yzantine failures, netw ork failures,
or netw ork p artitions.
2 .3
O p tim is tic S tr a te g ie s
As m entioned before, optim istic strategies are not em phasized in this dissertation.
Two strategies are shown in this section, bu t th ey are not analysed in depth.
^Conventionally, it is still treated as a pessim istic algorithm.
2.3. O P T IM IS T IC S T R A T E G IE S 21
2 .3 .1
V e r s io n V e c to r s
Version vectors [127, 128] were proposed for use in th e distributed operating system
LOCUS to detect w rite-w rite conflicts am ong copies of files. Each copy of a file has a
version vector associated w ith it, th a t consists of a sequence of n pairs, where n is th e
num ber of sites at which th e file is stored. T he %th vector en try pair (5,- : Vi) counts
th e num ber Vi of updates to th e file, m ade at site Si. In other words, th e version
vector counts th e num ber of updates to th e file originating at each site at which th e
file is stored. Conflicts th a t occur when m ore th a n one partitio n updates the file can
be detected by comparing version vectors.
Let V and v ' be version vectors for th e file. Vector v is said to dominate [37] vector
v ' if Ui > uj for aU 2 = 1 , . . . ,71. Intuitively, if v dom inates v ', th e copy with vector v
has seen a superset of the updates seen by th e copy w ith vector v '. A set of version
vectors are said to be compatible if th ere exists one vector th a t dom inates all other
vectors in th e set. A set of version vectors conflict if th ey are not com patible. In this
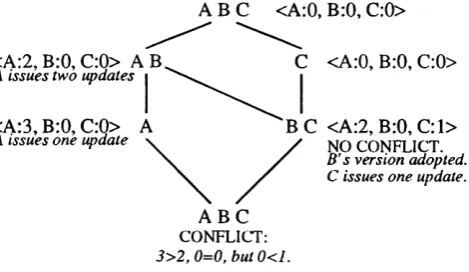
case, th e copies have seen different up d ates. Figure 2.1 shows an example of how a
conflict is detected by incom patible version vectors in a system which contains three
sites A , B and C. W hen it is discover th a t some version vectors for th e file conflict,
an inconsistency has been detected. How to resolve th e inconsistency is a complex
question and is left up to th e database ad m in istrato r (DBA).
A B C <A:0, B:0, C:0>
<A:2, B:0, C:0> A B A issues two updates
<A:3, B:0, C:Q> A A issues one update
C <A:0, B:0, C:0>
B C <A :2,B :0,C :1> NO CONFLICT. B ’s version adopted. C issues one update.
A B C CONFLICT: 3 > 2 , 0= 0, but 0 < L
Figure 2.1: Conflict as version vectors incom patible
22 C H A P T E R 2. F IL E R E P L I C A T I O N S T R A T E G I E S
detected because th e files read by a transaction are not recorded. Hence th e approach
works well for transactions accessing a single file, which are typical in m any file
system s, b u t not for multifile transactions, which are common in database systems.
2 .3 .2
O p t im is t ic P r o t o c o l
T he optim istic protocol [36] uses a precedence graph to detect inconsistencies. A
precedence graph models th e necessary ordering betw een transactions, and is used
to check seriahzabihty across partitions. T he precedence graphs are ad ap ted from
seriahzation graphs, which are used to check seriahzabihty w ithin a site. In order
to construct th e precedence graph, each p artitio n m aintains a log, which records the
order of reads and writes on a file. From this log, th e read-sets and w rite-sets of th e
transactions and a seriahzation order on th e tran sactio ns can be deduced.
T he nodes of th e precedence graph represent transactions. So node Tij represents
jth. tran sactio n in p artitio n i. The edges represent interactions betw een transactions.
T here are th ree types of interaction edges in th e precedence graph. A dependency
edge indicates th a t a transaction reads a file value produced by a previous tra n sac
tion, and a precedence edge indicates th a t a tran sactio n reads a file value which is
later changed by another transaction. These two types of edges model interactions
betw een transactions in the same partitio n . T he m eaning of an interference edge
is th e same as a precedence edge, b u t th e interference edges represents interactions
betw een transactions in different p artitions. This graph could lead to th e foUowing
result. T he precedence graph for a set of partitio n s is acyclic if and only if th e re
sulting file state is consistent [36]. A n exam ple of th e precedence graph is given in
Figure 2.2, in which th e read-sets of a tran sactio n is given above th e fine and the
w rite-sets below th e fine. A conflict is detected by a cycle in th e graph.
Inconsistencies are resolved by rolling back (undoing) transactions un til th e resu lt
ing subgraph is acycHc. The algorithm used to select which transactions to roU back