2543
Malicious Websites Classification Based On Web
Address Features
Shaik Irfan Babu, Dr.M.V.P.Chandra Sekhara Rao
Abstract:. In Cyber security, one of the major violations of cyber laws is due to propagation of malicious web sites for exploiting legitimate users. These malicious websites exploit the vulnerabilities in users systems. Also infect them by inducing malware such as phishing etc. Hence, Cyber security is an active research area where a given Uniform Resource Locator (URL) needs to be classified as either malicious or benign. In this research work, different machine learning supervised techniques are used for detecting malicious URLs with respect to 13 rules framed based on web address features. The dataset were collected from phish tank URL (https://www.phishtank.com/). Which consists of approximately 7000 URL’s. Experimental results obtained were satisfactory where Neural Network (NN), k-Nearest Neighbor (k-NN) and Support Vector Machine (SVM) classification techniques were applied on the given dataset. The empirical results shown the accuracy of the above techniques are 81.3%, 85.1% and 87.7 % respectively.
Keywords: Malicious Websites , Web Address Feature , Neural Network, k-Nearest Neighbor, Support Vector Machine
——————————◆——————————
1
INTRODUCTION
Malware is any kind of unwanted software that is installed without users’ consent on their computer system viz. malicious web sites, phishing, remote exploits and email worm etc. Malware Detection is the strategy and methodology for detecting any latent and hidden Malware present in users’ systems. A malicious executable is any piece of software program which eventually performs malicious intended functionality, viz. compromising systems security, damaging system or accessing user’s sensitive information without permission etc. In this proposed work, data mining techniques are used, which automatically build scanners that accurately detect malicious executables before they have been given a chance to run on host systems.Traditional research for malicious URL detection is called black listing which uses construction of manual list which lists all malicious URLs and their respective users observing the behavior of URL at the time of visiting. Every time a new URL is visited, lookup operation is performed on database. If that URL is available then it is warned to be malicious else it was declared to be benign. This blacklisting approach suffers from major drawbacks in two ways first as new URLs are created on daily basis and incorporating them into the database becomes very exhaustive, second as new threats are created by hackers on daily basis which may be cleverly fabricated as benign even though it is malicious by using various algorithmic strategies. Despite several problems faced by blacklisting, due to their simplicity and efficiency, they continue to be one of the most commonly used techniques by many anti-virus systems today. The disadvantage of Blacklisting approach is that it comprises of searching the database for presence of the entry. Also, the database cannot be kept up to date because of the continuous growth of malicious web link by the hour.
Heuristic approaches [2] are some kind of extensions of Blacklist based methods, wherein the idea is to create a “blacklist of signatures”. In this approach, signatures are attached for attacks based on their behaviors. This approach was successfully used by Intrusion Detection System (IDS) [2] where in web pages are scanned for the presence of the signatures. Intrusion Detection System (IDS) technique alarm the user when a suspicious web link is found. The major disadvantage of IDS technique is that, it cannot scale for all upcoming novel attacks. Moreover, using obfuscation techniques, it is not difficult to bypass them. Advances in heuristic approach analyze the inherent execution paradigms with in a web page. Here, the idea is to look for a signature of malicious activity such as unusual process creation, repeated redirection, etc. These approaches try to pull the user to visit the web page. Then it can push the attack from web page to the user. As a result, such techniques are often implemented in controlled environment like a disposable virtual machine. These techniques demand huge resources and computation time in execution of all the code at client and server side. Also Heuristic approaches cannot detect a passive attack mechanism of the intruder. Data mining methods detect patterns in large amounts of data, use these patterns to detect future instances in similar data, whose framework uses classifiers to detect new malicious executables. A classifier is a set of rules or any model for detection which is generated by any data mining algorithm that is trained on a given set of training data. A framework is designed using data mining techniques to train multiple classifiers on a set of malicious and benign executables to detect new examples. The binaries are first statically analyzed to extract properties of the binary, and then the classifiers trained over a subset of the data. For evaluation of proposed system, simulation is performed for detecting new malicious executables. Using standard statistical cross-validation techniques, proposed data mining-based method had more than double the detection rate of a signature-based scanner over a set of new malicious executables. At the time of this publication, this method was not in position to be compared with industry standards heuristics because of copy right issues. Moreover there was no equivalent or statistically comparable dataset to which both techniques are applied. However, the framework provided is fully ————————————————
•Shaik Irfan Babu is currently ANU College of Engineering, Acharya Nagarjuna University(ANU), Guntur, Andhra Pradesh E-mail: [email protected]
2544 automatic and could assist experts in generating the
heuristics.
2
LITERATURE REVIEW
S. Carolin Jeeva et al. [1] have focused on discerning the significant features that discriminate between legitimate and phishing URLs. These features are then subjected to associative rule mining—apriori and predictive apriori. Min-Sheng Lin et al. [3] propsed models which do filtering based on descriptive and lexical features and integrating their results. Learning algorithms were applied with trade off on using very large data sets and also short life cycle of malicious URL’s efficiently. Ankit Kumar Jain et al. [4] have proposed whenever users tries to open a malicious web site browser may warn for not disclose and compromise their personal information. This approach internally checks the genuineness of web page using hyperlinks and their features. To do this hyperlinks from the appropriate source code is extracted which is later applied to their proposed phishing detection strategy.Chia-Mei Chen et al. [5] presented blacklist model for malicious URL’s for social media based on user behaviours. Two types of anomaly features were proposed: domain anomaly and social anomaly features. Domain anomalies features were used to identify possible malicious domains based on lexical and reputation factors, whereas social anomaly features represent anomalous user behaviours in social communications. Asrian Stefan Popescu et al. [6] have proposed application of various machine learning strategies and also unsupervised learning algorithms to detect malicious websites using memory footprints as key consideration to address the problem. Amruta [7] defined malware is mostly propagated through malicious URLS’s with harmful intentions. These URLs sites having pernicious code which consist of malicious contents like worms, Trojan horses, backdoors etc. Hence for providing Web Security it is very much essential to detect and thward Malware using malicious Web Sites. B. B. Gupta et al. [8] have explains Phishing is common and serious attack on Internet for stealing financial information using malwares or even they can extend it to now most popular social engineering. Their paper addressed the phishing issues in two fold manner: phishing attacks and its motivation ; and taxonomy of various strategies to counter phishing attacks. Adrian-Stefan Popescu et al. [9] have presented a cloud-based mechanism that can be used to filter large amounts of network traffic with respect to both memory and response time limitations. The algorithms have been tested on data flows of more than 750 million of URLs/day. Mohammad[10] proposed light weight approach and also lexical analysis based on attacks and provided sufficient features on a data set over 111,000 URL’s.
3 DATA SET USED
The dataset of benign URLs is collected from the Alexa Top sites [12]. The dataset for malicious websites collected from benchmark sources, like Phish tank (a blacklist of phishing URLs), Malware Domain List (MDL) Web service which provides various kinds of the domain lists related to malicious Web sites. For experimental purpose, a balanced dataset is created consisting of 3536 benign URL and 3494 malicious URLs.
4 PROPOSED METHODOLOGY
This research methodology proposes and introduces various aspects involved for URL classification and eventually classifies the given web site as malicious or benign. The significant thrust of this research is for classification of any given URL using Machine Learning classification algorithm. Test their inherent performance based on selected efficient features extracted from URL’s address by using security authentication datasets which detects malicious URL’s with high accuracy. The application of this research is useful for all users using search engines and it will reduce financial losses at their individual levels based on severity of malware attack, for example Wannacry malware attack. Information presented in the following figure 1 illustrates a Framework for Malicious Web Based system. For the given URL set the researcher intends to apply Feature Extraction to retrieve 13 features. Further the dataset is divided into ratio of 90:10 for training and testing proportionately for design of classifier. This classifier will classify the new URLSs as either malicious or benign for the given data set.
Figure1. A Framework for Malicious Web Based system
1. Number of Dots: This feature counts the number of dots in the URL. Malicious URLs tend to use more dots than the legitimate sites. The Dots in host name of URL is greater than (T) that four of in malicious URL otherwise legitimate URL [1].
If (Dots in host name of URL) is greater than T →Malicious URL
else
Legitimate URL
2545 If (Domain Name Part Includes (-) Symbol) → Malicious
URL else
Legitimate URL
3. Length of URL: Malicious URLs can use long URL to hide the doubtful part in the address bar. The researchers calculated the length of URLs in the dataset and produced an average URL length. The results obtained show that if the length of the URL is greater than or equal to 54 characters then the URL is classified as phishing [3]. If (Length of URL) is greater than 54 → Malicious URL else
Legitimate URL
4. Presence of @: Using “@” symbol in the URL leads the browser to ignore everything preceding the “@” symbol and the real address often follows the “@” symbol [11].
If ( URL having ‘@’ symbol) → Malicious URL else
Legitimate URL
5. Presence of “//”: The existence of “//” within the URL path means that the user will be redirected to another
website. An example of
“http://www.legitimate.com//http://www.phishing.com”. During this process the researchers explores the location where the “//” appears. Further, it is found that if the URL starts with “HTTP”, which means the “//” should appear in the sixth position. However, if the URL employs “HTTPS” then the “//” should appear in seventh position [11].
If (‘//’ in the URL > 7) → Malicious URL else
Legitimate URL
6. Number of Subdirectories: It was observed that if the number of subdirectories is more than one , then given URL is malicious otherwise the given URL is Legitimate.
If (number of subdirectories are >= 2) → Malicious URL else
Legitimate URL
7. Number of sub domains: In the given URL having [ ‘luckytime.co.kr’, ‘mattfoll.eu.interia.pl’,‘trafficholder.com’, dl . baixaki . com . br ’ , ‘bembed.redtube.comr’, ‘tags.expo9.com’, ‘deepspacer.com’, ‘funad.co.kr’, ‘trafficconverter.biz’] the word then feature consider malicious and legitimate otherwise [1].
If (URL having above strings) → Malicious URL else
Legitimate URL
8. Length of Domain: Although the maximum length of domain name length is 63 characters, where as the average number of domain length is 12 to 15 characters [1]. If ( Length of domain is >= 15) → Malicious URL
else
Legitimate URL
9. Number of queries: It was observed that if the number of “?” are more than one then given URL is malicious otherwise the given URL is Legitimate.
If (URL having ‘?’ Symbol) → Malicious URL else
Legitimate URL
10. Is IP : If the given URL address consists of an IP address it is considered malicious URL otherwise it known as legitimate [1].
If (URL having IP address) → Malicious URL else
Legitimate URL
11. Presence of suspicious –TLD: In the given URL having ['zip','cricket','link','work','party','gq','kim','country','science','tk '] the word then feature consider malicious and legitimate otherwise [12].
If (URL having above strings) → Malicious URL else
Legitimate URL
12. Lengthy domain to hide suspicious part: Malicious URLs often contain IP addresses to hide the actual URL and domain of the website. For instance, a website URL may be extremely long and look
suspicious such as
“http://www.freewebhostingcompany.com/ . marks website/ today’s phishingpage.html” [11].
If (URL length is >= 75) → Malicious URL else
Legitimate URL
13. presence of delimiter: The string was processed such that each segment delimited by a special character (e.g. ”/”, ”.”, ”?”, ”=”, etc.) comprised a word. Based on all the different types of words in all the URLs, a dictionary was constructed, i.e., each word become a feature. If the word was present in the URL, the value of the feature would be malicious and legitimate otherwise.
If ( URL contain any special character) → Malicious URL else
Legitimate URL
Algorithm for Feature extraction using IF – THEN Classification Rules
1. Countdelim (URL): count=0
Delim = [‘;’,’_’,’?’,’=’,’&’]
For each in URL: count = count + 1
2. IsPresentHyphen (URL): return URL.count (‘-‘) 3. IsPresentAt (URL): return URL.count (‘@’) 4. IsPresentDSlash (URL): return URL.count (‘//’) 5. CountSubDir (URL): return URL.count (‘/’) 6. Get_ext (URL):
return the filename extension from URL 7. CountSubDomain (sub domain):
return Len (subdomain.split (‘.’)) 8. Count Queries (query):
return (query. Split (‘&’)) 9. Count dots (URL): return url.count (‘.’)
10. IsSuspicious_TLD (URL):
ext = tdeextrat.extrat (URL) return 1 if ext.suffix in Suspicious_TLD else 0
11. IsSuspicious_domain (URL):
return 1 if ‘.’ Join (ext [1 :]) in Suspicious Domain else 0 12. Isip (URL):
try: if ip.ip_address (URL): return 1 except: return 0
2546 5 DISCUSSION ON RESULTS
Phish Tank is an open API which enables researchers and developers to use and enable anti-phishing data in to their developed applications. The created data set have approximately 7029 websites. Neural Network classification achieved accuracy is 81.3% and 85.1% accuracy is received by using K-NN. By applying SVM Classification method using K-fold cross validation where K=10 to the above data set yielded 87.7% accuracy. To validate the present Research work the following metrics are used such as Accuracy, True Positive Rate(Sensitivity) and True Negative Rate(Specificity).
Accuracy is the ratio of TP+TN and Total.
TOTAL
TN
TP
Accuracy
=
+
Sensitivity is the ratio of True Positive and actual yes.
ActualYes
TP
y
Sensitivit
=
Specificity is the ratio of True Negative and actual no.
ActualNo
TN
y
Specificit
=
Table 1: SVM Classification Accuracy
SVM type Classification
Accuracy (%)
Linear SVM 81.7
Quadratic SVM 86.3
Cubic SVM 58.7
Fine Gaussian SVM 87.7 Medium Gaussian SVM 85.5 Coarse Gaussian SVM 81.5
The above Table 1 shows that when applied SVM family classifier is applied on the given data set using 90:10 training and testing data Fine Gaussian SVM has given high accuracy i.e. 87.7% . It is also found the Cubic SVM classifier has given low accuracy i.e. 58.7%.
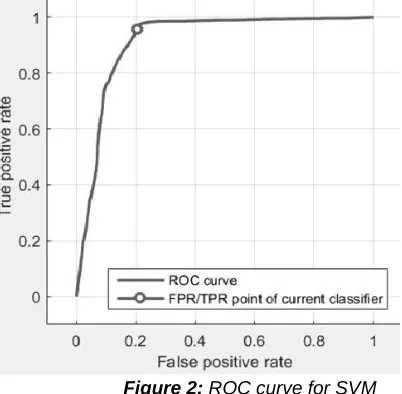
Figure 2: ROC curve for SVM
The ROC curve for SVM is given in Figure 2. SVM area under curve is 0.916758, False positive rate (FPR) classifier is 0.203205, True positive rate (TPR) classifier is 0.95731
and True Negative Rate (TNR) is 0.796 as showed in Figure 2. The Confusion matrix of SVM is given in Figure 3.
Figure 3: Confusion Matrix of SVM
Table 2: K-Nearest Neighbor Classification Accuracy
K-NN Classification Accuracy (%)
Fine KNN 61
Medium KNN 84.5 Coarse KNN 85.1 Cosine KNN 84.5
Cubic KNN 84.6
Weighted KNN 84.8
The above Table 2 shows that when applied K-Nearest Neighbor family classifier is applied on the given data set using 90:10 training and testing data Coarse KNN has given high accuracy i.e. 85.1% . It is also found the Fine K-Nearest Neighbor classifier has given low accuracy i.e. 61%.
Figure 4: ROC Curve for K-Nearest Neighbor
2547
Figure 5: Confusion Matrix of k-Nearest Neighbor
Figure 6: Training ROC of Neural Network
Figure 7: Validation ROC of Neural Network
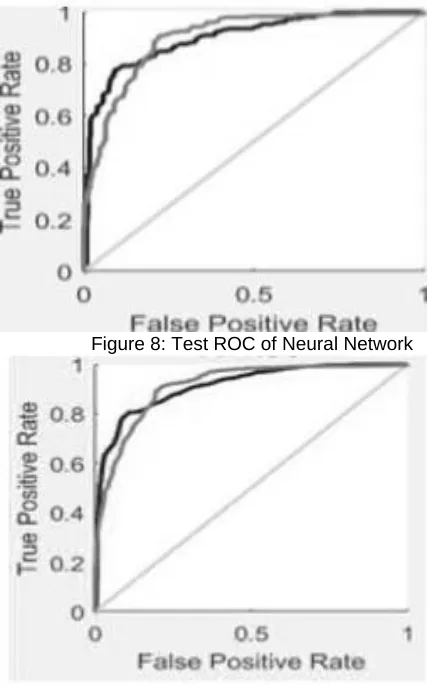
Figure 8: Test ROC of Neural Network
Figure 9: ROC of Neural Network
The figure numbered from 6 to 9 reveal that the ROC curves for FPR vs. TPR classifier using a neural network. The blue solid and gray solid lines represent the curves for training and testing sets, respectively.
6 CONCLUSION
In this paper, various machine learning supervised techniques were used for detecting malicious URLs. Features are extracted based on different 13 rules. Among SVM, NN, k-NN Classifiers, SVM have shown better results. SVM Classification method using K-fold cross validation where K=10 to the above data set of approximately 7000 URL’s yielded high accuracy i.e. 87.7 %. Future work includes collection of new dataset’s and the same proposed methodology can be applied on these different dataset’s. Further, in the future work it is proposed to work adding new features like HTML tags and content of HTML source code.
7 REFERENCES
1. S. Carolin Jeeva, Elijah Blessing Rajsingh, “Intellignet Phinshing URL Detection Using Association Rule Mining”, Springer Open, Humman-Centric Computing and Information Sciences, Jeeva and Rajasingh Hum Cent. Comput. Inf.Sci.(2016), DOI: 10.1186/S13673-016-0064-373.
2548 3. Min-Sheng Lin, Chien-Yi Chiu, Yuh-Jye Lee and
Hsing-Kuo Pao, “Malicious URL Filtering – A Big Data Application”, IEEE International Conference on Big Data, Page No.589-596, (2013)
4. Ankit Kumar Jain and B.B.Gupta, “A Novel Approah to Protect Against Phishing Attacks at Client side Using Auto-Updated White-List”, Springer Open, Eurasip Journal on Information Security, Jain and Gupta Eurasip Journal on Infromation Security, (2016), DOI. 10.1186/S1335-0160034-3
5. Chia-Mei Chen, D.J. Guan, Qun-Kai Su, “Feature Set Identification for Detecting Suspicious URLs using Bayesian Classification in Social Networks”, Elsevier, Information Scieces 289 (2014), PG:133-147.
6. Asrian Stefan Popescu, Dragos Teodor Gavrilut, Dumitru Bogdan Prelipcean, “ A Study on Techniques for Proactively Identifying Malicious URLs”, International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, IEEE (2016), DOI: 10.1109/SYNASC.2015.40
7. Amruta Rajeev Nagaonkar, Umesh L. Kulakarni, “Finding the Malicious URLs using Search Engines”, International Conference on computing for Sustainable Global Development, IEEE (2016)
8. B.B.Gupta, Aakanksha Tewari, Ankit Kumar Jain, Dharma P.Agarwarl, “Fighting against Phishing Attack: State of the Art and Future Challenges”, Springer(2016).
9. Adrian-Stefan Popescu, Dragos-Teodor Gavrilut, Daniel-Ionut Irimia, “ A Practical Approach for Clustering Large Data Flows of Malicious URLs”, J Comput Virol Hack Techm, Springer(2016), PG:37-47, DOI: 10.1007/S11416-015-0239-X
10. Mohamamad Saiful Islam Mamun, Arash Habibi Lashkari, Natalia Stakhanova, Ali A. Ghorbani, “Detecting Malicious URLs using Lexical Analysis”, Springer International Publishing(2016), pp.467-482. 11. Rami M. Mohammad, Fadi Thabtah, Lee Mccluskey,
“Phishing Websites Features”.
12. Piyush Anasta Rumao, “Using Two Dimensional Hybrid Feature Dataset to Detect Malicious Executables” , International Journal of Innovative Research in Computer and Communication Engineering, Vol.4, Issue 7,(2016), DOI: 10.15680/IJIRCCE.2016.0407158 13. Aaron Blum, Brad Wardman, Thamar Solorio, Gary Warner, “Lexical Feature Based Phishing URL Detection using Online Learing”, ACM (2010).
14. Ustin Ma, Lawrence K. Saul, Stefan Savage, Geoffrey M. Voelker, “Identifying Suspicious URLs : An Application of Large-Scale Online Learning”, International Conference on Machine Learning (2009). 15. Justin Ma, Lawrence K. Saul, Stefan Savage, Geoffrey
M. Voelker, “Beyond Blacklists: Learning to Detect Malicious Web Sites from Suspicious URLs”, KDD (2009).
16. Mehedy Masud, Latifur Khan, and Bhavani Thuraisingham, “Data Mining Tools for Malware Detection”, International Standard Book Number-13: 978-1-4665-1648-9, (2011).
17. https://www.alexa.com/topsites
18. https://github.com/surajr/url-classification /find/master
19. G. Kalyani, Dr. M.V.P.Chandra Sekhar Rao "Particle Swarm intelligence and Impact Factor-Based Privacy Preserving Association Rule Mining for Balancing Data Utility and Knowledge Privacy" Arabian Journal for Science and Engineering Issn 2193- 567x arab j sci eng doi 10.1007/s13369- 017-2834-2. 2017.