DERI Galway University Road Galway IRELAND www.deri.ie DERI Innsbruck Technikerstrasse 13 A-6020 Innsbruck AUSTRIA www.deri.ie
A Semantic Wiki approach
for integrated data access
for different workflow
meta-models
Eyal Oren
DERI Technical Report 2006-02-03 February 2006
A Semantic Wiki approach for integrated data access
for different workflow meta-models
Eyal Oren1
Abstract. Organisations commonly employ multiple workflow management systems, for various reasons. A multitude of employed workflow management systems leads to issues in data consistency and data retrieval, since organisational data is related but maintained in multiple systems and disparately available for the employees.
This paper outlines our research to address workflow data integration. Our integration of workflow data is based on our multi-meta model process ontology m3po. As unifying interface to the integrated data (for editing, adding, annotating, browsing, and retrieving workflow data) we introduce the paradigm of semantic wikis: easy to use collobarative editing systems.
1Digital Enterprise Research Institute, National University of Ireland, Galway.
Acknowledgements: This material is based upon works supported by the Science Foundation Ireland under Grant No. 02/CE1/I131.
Contents
1 Introduction 1
2 Workflow management 1
3 Related work 3
3.1 Enterprise-wide workflow management . . . 3
3.2 Data integration . . . 4
4 Approach 6 4.1 Architecture. . . 6
4.2 Implementation . . . 7
4.3 User Interface . . . 8
5 Wikis and Semantic Wikis 8 5.1 Limitations of Wikis . . . 8
5.2 Semantic Wikis . . . 9
5.2.1 Architecture Overview . . . 11
5.2.2 Annotation language . . . 12
5.2.3 Information access . . . 17
5.3 Semantic Wiki: Implementation. . . 19
5.3.1 System overview . . . 19 5.3.2 Writing . . . 20 5.3.3 Navigating . . . 20 5.3.4 Searching . . . 20 5.3.5 Storage . . . 21 5.3.6 Component interaction. . . 21
5.3.7 Addressing Wiki limitations . . . 22
1
Introduction
Workflow management systems are widely used in organisations. They provide automated sup-port for managing business processes; they operate on a schema definition of the processes in the organisation.
Organisations commonly employ multiple workflow management systems, for historical, func-tional, or technical reasons [6]. Each workflow management system manages a part of the organisa-tional processes and maintains a part of the organisaorganisa-tional data. A multitude of employed workflow management systems leads to issues in data consistency and data retrieval, since organisational data is maintained in multiple systems.
Data consistency issues arise since the data in the workflow management systems are related: they need to be (kept) consistent. Data retrieval issues arise since employees in the organisation need complete information, compiled from all workflow management systems.
This paper outlines our research to address the issues of data retrieval. We proceed as follows: first, in section 2, we give a detailed description of data management in workflow management; section3then outlines existing work that addresses these issues and explains where we position our work; section4describes our approach on an abstract and section5describes our concrete solution, based on Semantic Wikis.
2
Workflow management
Workflow management deals with supporting business processes in organisations, it involves man-aging the flow of work through an organisation. A workflow is a collection of coordinated tasks designed to carry out a well-defined process [20].
A workflow management system is a generic information system that supports modelling, execu-tion, management and monitoring of workflows. Such a system operates on a workflow specificaexecu-tion, a description of the business processes in the organisation that should be supported. A workflow management system can be compared to a database management system: it is a generic system that operates on a schema definition of the (processes in the) organisation. Workflow modelling is the task of creating workflow specifications, that are used as input to a workflow management system.
Different workflow management systems have been developed, focusing on different application domains and providing different functionality. Workflow management lacks a standardised theory that provides a theoretical background; despite standardisation efforts no consensus exits on the representation or conceptual model of workflows [22]. Jablonski and Busser [14] give a comprehen-sive overview of issues in workflow modelling, divided in five key aspects: functional, behavioural, informational, organisational, and operational.
An organisation can have several different workflow management systems deployed for manag-ing their business processes [6]. The reasons for such diversity can be historical (e.g. the result of business acquisitions or mergers) or functional (e.g. the result of different requirements in organisa-tional units). The information captured in these separate workflows is interrelated: the workflows belong to the same organisation and model related business processes.
However, the interrelation between these different workflows can not be captured in current workflow management systems, for two reasons. First, since each workflow management system
has a distinct meta-model and specification language, the workflows in one system are generally not understandable by the other systems: the representations of workflows differ across systems. Second, each workflow specification considers a closed world, it is not possible to refer to external entitities (defined in other workflow management systems): the workflows are disconnected.
In the current state-of-the art an organisation can thus not access its information completely: the relation between different sets of workflow data is lost. Organisations can not get a complete picture of their workflow data, and can not see and edit their information in the correct and complete context.
Example 1
An academic organisation has procedures in place for arranging the travels of its employees. Before each travel employees must request atravel permission from their superior; after travel employees canapply for expense refundsonly if permission was granted prior to the travel. An automated workflow, enacted with Microsoft BizTalk, is used to manage these travel requests and refunds.
Travel reservations are arranged centrally for each granted travel request. The employees do not arrange their own travels, instead a specific travel coordinator does so for all travels in the organisation. The travel coordinator uses travel agencies to find and make travel arrangements. The travel coordinator has a workflow to manage these reservations with the travel agencies, which is enacted using IBM WorkflowMQ.
The problem is that, although the data in these two workflow management systems are related (both deal with employees and their superiors, status of travel requests, university travel regulations, etc.), one can currently not easily retrieve this integrated information. Where this information is needed, it has to be collected and maintained manually:
In order to plan the ongoing work, the operations manager needs to know the current load and availability of all employees. He needs to go into the seperate workflow management systems and collect the information from these systems manually.
The financial officer needs to run queries that span data in both systems: she needs infor-mation about travel requests, the projects that they are charged, the travel agency that dealt with them, and the costs that they incurred. Again, she needs to go into the separate workflow management systems and collect this information manually.
The quality manager wants to document all processes in the organisation. All activities that are performed internally are described instandard operating proceduresand stored on the internal network. Each documentation should be linked to the relevant activities, so that employees can quickly find documentation on the process that they are involved in. But the workflow management systems do not allow the quality manager to annotate activities with documentation or to link them to external resources. And even if they would, there is no easy way for the quality manager to see all that documentation, and manage it. Again, he would need to go into all separate workflow management systems and collect the information manually.
Problem Business processes that are defined and enacted in different workflow management systems are disconnected. Organisations that deploy multiple workflow management systems find their workflow information dispersed. Users have to manually integrate related workflow data.
3
Related work
3.1 Enterprise-wide workflow management
Bussler [6] discusses the management and execution of enterprise-wide workflows based on a case study performed in Boeing. Enterprise-wide workflow execution is difficult to achieve because of the heterogeneity between workflow systems. Even within one enterprise workflow management systems are not homogeneous: the enterprise employs workflows in different functional domains (in Boeing workflows exist for airplane design, for stock management, for internal travel management, for human resource management, etc.), and it is common to use a different workflow manage-ment system in each domain (because the workflow requiremanage-ments are domain-specific and because workflow vendors offer domain-specific solutions).
To enable enterprise-wide workflow management the various workflow management systems should not run in isolation but exchange workflow information and share workflow execution. The case study identifies the need for (i) workflow data integration, and (ii) distributed workflow exe-cution.
Workflow data integration: workflow data integration provides a unified view of workflow data from the various workflow management systems; it is a special case of data integration, which we discuss in section 3.2.
We can distinguish three dimensions of workflow data integration: (i) integration of workflow models (type integration), (ii) integration of completed workflow instances (history integration), and (iii) integration of possible workflow executions (projective integration).
Type integration allows users for example to see all processes related to part XYZ. History integration allows users for example to see the execution time of all processes, related to part XYZ, that completed in the last tree weeks. Projective integration allows users for example to project the time it will take to complete all unfinished workflows related to part XYZ. Projective integration is only possible if the semantics of the workflow meta-models is captured in the integration.
Distributed workflow execution: distributed workflow execution is necessary as soon as cross-domain workflows are needed, as functional cross-domains inside the enterprise develop their own work-flow definitions and execute them in isolation.
Distributed workflow execution is constituted by either instance migration, instance distribu-tion, or instance replation [7]. Instance migration means that a workflow instance can migrate (move) from one workflow management system to another; this is only possible if the two workflow management systems implement the same execution semantics. Instance distribution means that a part of the workflow resides in another workflow management system. Instance replication means that an instace is replicated (continuously reflecting all changes) in two workflow management systems.
Distributed execution can be characterised on several dimensions [6]:
• direct vs. indirect distribution: if the workflows know each other they can execute each other directly. Otherwise external functionality is necessary for their cooperation, for instance coordination via shared databases or communication queues.
• objects of distribution: any object in a workflow management systems (e.g. subworkflows, resources, instance data, applications) can be distributed, i.e. reside on a different installation than the rest of the workflow.
• distribution transparency: workflow distribution is transparent if the location of objects is not visible in the workflow specification, i.e. if workflow designers do not see (and need to design) the distribution of the workflow objects.
Integration architectures Bussler [6] describes four possible architectures for workflow inte-gration:
• user interface collocation: the workflow management systems are not integrated, but the user interfaces of different workflow management systems reside at the user’s desktop together.
• user interface integration: one user interface is offered that accesses different underlying workflow engines. We can further classify this layer by whether the user interface integrates the workflow data from the source systems or stricly separates workflow objects from the various source systems.
• workflow logic integration: the workflow management systems know each other and can share executions.
• workflow database integration: the workflow management systems share one database. We can again differentiate whether the workflow management systems keep their objects separate, or share each other’s objects.
In each of these layers, true workflow integration is only possible if the workflow management systems are designed and built with integration in mind; if the workflow management systems are independent and do not recognise objects from the other systems native interoperation is not possible.
The case study demonstrates the heterogeneity in enterprise-wide workflows and the need for integrated user interfaces, workflow logic and workflow data. According to Bussler [6], current work-flow management systems do not support the necessary integration and distribution functionality; an encapsulating infrastructure is necessary.
3.2 Data integration
Data integration comprises problems in storing and manipulating heterogeneous data sources in a uniform way [19]. Data integration deals with combining data residing at different sources, and providing the user with an integrated view of these data [16]. Data integration systems provide a uniform query interface to a collection of autonomous data sources [9].
Data integration systems typically deal with one global (mediated) schema and a set of local (source) schemas, and offer transparent access to the local schemas through the global schema: queries and result sets are formulated in terms of the global schema.
A basic problem in integrating different data sources is heterogeneity, ranging from the hardware and software the database systems are running on, to the data schemas and data models that structure the data, to the kinds of data that are being stored [12]. Semantic data integration focuses on the heterogeneity between the data schemas of the sources.
Standardisation policy Trivially, standardising the source databases (hardware, software, and data schemas) solves the integration problem by preventing heterogeneity to appear. The source schemas are mandated to be the same as the global schema, and no semantic integration is neces-sary. Although such solutions are applied in practice (for example when using an enterprise-wide system such as SAP), we focus on autonomous data sources, where mandated standardisation is not possible.
Architectures We can distinguish three basic architectures for data integration [9, 12, 16]: fed-eration, mediation, and data warehousing. We first consider read-only access to integrated data; we will address read-write access later.
• federation: [HM85] a federated database system consists of source databases that agree to share partial data with other members of the federation. Each source database offer an interface for communication with the other source databases. Typically, members extend their own schema to incorporate subsets of the schemas of other members. A federation has neither a global query interface nor a global schema. To answer a query, a source can turn to others in the federation; it is the responsibility of the first source to integrate the results into a coherent answer.
• mediation: [Wie92] a mediated database system offers a single query interface to sources. Each source database is encapsulated by a wrapper that hides low-level protocols. A global mediator offers a common interface; it decomposes queries into subqueries that are sent to individual data sources, and integrates (mediates) their results into a coherent set. The mediated architecture offers a virtual view on the source data: the data is not collected in a database, but integrated on the fly for each query.
A critical element of this architecture is the description of the sources, and their relation to the global schemas; several approaches exist for managing these source descriptions, which we investigate in the next section.
• data warehousing: the data warehousing approach offers a materialised view on the source databases. It regularly collects and integrates data from sources, and maintains these data in its separate database; users can query the integrated database directly.
Data warehouses are typically faster than on-the-fly integration since the views are materi-alised in the warehouse. They also allow historical data analysis, since they can maintain temporal snapshots of data. Issues in data warehouses include the frequency of updates (changes in the source data are only represented in the warehouse after the next update step). Similarly to the mediated architecture, the source descriptions are critical in data warehouses.
Source descriptions Each source in the data integration system needs to be related to the common global schema used for integration. A source description, also called mapping, relates the local data schema of a source to the common global data schema.
Two basic approaches have been proposed for these mappings[16]: global-as-view (GAV) and local-as-view (LAV). Global-as-view considers the global schema as a view of local schemas; it requires that the global schema is expressed in terms of the local schemas. Local-as-view requires
the global schema to be defined independently, and then defines the source databases as views on the global schemas.
Query processing is easier in GAV, since in GAV query processing can be done by unfolding the query using the mappings. The mappings describe directly how to rewrite the query in terms of the sources. In LAV however, the mappings need to be reversed before they can be applied to the query; it is not directly clear how and which sources can be used to answer a query.
Data modelling is easier in LAV. In GAV the global schema is expressed as a view on all sources. If a source is changed or added, it can effect all the mappings in the system. In LAV each mapping is a relation between the global schema and one source; a change or addition of one source does not effect any other source mapping.
4
Approach
As discussed in section 2, organisations commonly find their business processes and their business data dispersed over different workflow management systems. Since these systems are disconnected, it is not possible to offer an integrated view over these data.
Our approach consists of two parts: our unifying ontologym3po[10] that represents all common workflow management metamodels from existing workflow management systems, and our semantic wikiSemperWiki[21] that allows ordinary users to easily browse, view, edit, and manage semantic information.
4.1 Architecture
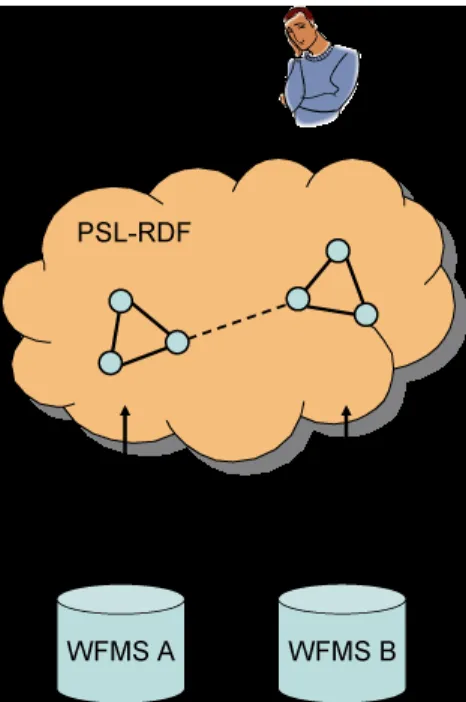
On the abstract level, we develop an integration architecture that offers transparent access to data from different workflow management systems. It allows integrated information management of business processes. Users can build connections between related data items and view, edit, and query workflow information. The architecture is shown in figure 1. It consists of a uniform workflow representation, a methodology for importing workflow management systems into this common format, and operations that users perform on the workflow data.
A uniform representation of workflow data addresses the syntactical and semantical differences between workflow management systems. All workflow models are represented in a common format and the semantics of all workflow constructs is specified. We use rdf as common format and we use m3po to define the used RDF terminology and its semantics.
rdf [18] is a datamodel for describing resource on the Semantic Web. rdf statements are triples, they state a property of a resource. All resources have a unique identifier, statements can be made about any resource. A set of rdfstatements corresponds to a directed graph of resources and literals, connected by predicates. An rdf graph does not necessarily conform to a schema (therefore it is called semi-structured); it can be queried using graph patterns.
rdf is suitable for information integration [8]: (i) its flexibility allows representing arbitrary data without a predefined schema, (ii) unique identifiers for each resource allow making statements about arbitrary objects and (iii) the graph-based model allows merging data from different sources without problems.
Our multi-meta model process ontologym3po[10] is an ontology that unifies existing metamod-els in the workflow domain. It is based on various reference modmetamod-els and standards: the workflow
Figure 1: Integration Platform
exchange format XPDL [24], the formal process ontology PSL [3], the workflow language YAWL [1], the web orchestration language WS-BPEL [23] and the choreography language WS-CDL [15]. Methodology The methodology to construct the m3po ontology is described in [10]. For our purposes it is important that the ontology is complete in the sense of the workflow management systems it can represent, and available in RDF.
A set of user operations on the common representation describes the tasks users need to perform on the workflow data. This set of tasks will be compiled from the requirements of the workflow domain.
4.2 Implementation
On the concrete level we implement this archictecture. We develop a set of tools that (i) store and retrieve m3po; (ii) transform between certain workflow management systems and m3po; and (iii) provide the defined user operations in a easy-to-use manner.
Storage: for storing and retrieving m3po we can use standard rdf stores such as Redland [2], YARS [11], Jena2 [25], or Sesame [4]. These differ mostly in storage space, query functionality, support for higher-level semantics, performance and scalability, and programming interfaces. We will choose a store based on our technical requirements.
Transformation: we will develop transformation tools between Microsoft BizTalk and m3po, and between IBM WorkflowMQ andm3po.
User operations To provide the identified user operations we use the SemperWiki platform and develop plugins that support specific workflow functionality. We thus utilise the generic data management functionality and provide extensions that add specific support for the workflow do-main.
4.3 User Interface
We base our user interface implementation on the paradigm of semantic personal Wikis [21], and specifically on our tool SemperWiki, as explained in the next section.
5
Wikis and Semantic Wikis
Wiki Wiki Webs are collaborative hypertext environments, focused on open access, ease-of-use, and modification [17]. Wikis are interlinked web sites that can be collaboratively edited by anyone. Pages are written in a simple syntax so that even novice users can easily edit pages. The syntax consists of simple tags for creating links to other Wiki pages and textual markups such as lists and headings.
Wikis can be regarded as editing environments for the web. They are manifestations of the “writable web” [13], enabling users to write web content with the same skills and tools used to read them. Anecdotal evidence1 suggests that the popularity of Wiki systems, compared to other collaborative hypertext systems, is due to their simplicity and their open and easy access [5].
The user interface of most web-based Wikis consists of two modes: in reading mode, the user is presented with normal web pages that can contain pictures, links, textual markup, etc. In editing mode, the user is presented with an editing box displaying the Wiki syntax of the page (containing the text and including the markup tags). During editing, the user can request a preview of the page, which is then rendered by the server and returned to the user. Some so-called desktop Wikis such as Tomboy2 or WikidPad3 have only one mode: pages are directly editable.
Wikis are used for various collaborative tasks, including collecting general encyclopedic knowl-edge, event organisation, and writing research proposals and papers. Many sites run a Wiki as a community venue, enabling users to discuss and write on topics, such as product support or project documentation. The burden of editing and maintenance is thus shared over the whole community. Popular Wikis such as Wikipedia can grow in size very quickly, since interested visitors can edit and create pages at will; this poses new requirements on information access and retrieval.
5.1 Limitations of Wikis
A shortcoming of large Wikis is lack of support for finding and maintaining information. The main reason is a lack of semantic structure in the Wiki content: almost all information is written in natural language, and has little machine-understandable semantics. For example, a page about John Grisham could contain a link to the page about “The Pelican Brief”. The English text would say that John Grisham wrote the Pelican Brief, but that information is not machine-understandable. This leads to the following consequences:
1
See e.g. http://twiki.org/cgi-bin/view/Main/TWikiStories. 2http://www.beatniksoftware.com/tomboy/.
3
Structured accessof a Wiki is not possible, which arises when one is browsing or searching for information:
One cannot currently query Wiki systems, because the information is not structured but rather is textual. For example, users looking for “How old is John Grisham?”, “Who wrote the Pelican Brief ?”, or “Which European authors have won the Nobel price for literature?” cannot ask these questions directly. Instead, they can navigate to the page that contains this information and read it themselves. They first have to locate the page, and then mentally process the information on that page. More complicated queries that require some background knowledge, such as “Find all the authors who are poets who are located in countries that are part of the European continent”, are not possible at all.
Another problem is in navigating the pages: Wikis allow users to easily make links from one page to other pages, and these links can then be used to navigate to related pages. But these explicit links are actually the only means of navigation4. If no explicit connection is made between two related pages, e.g. between two authors that have the same publishing company, then no navigation will be possible between those pages.
Information reuse of Wiki content is not possible. To reuse information is useful when it becomes necessary to provide translations or to create views (as known from databases) of content.
In current Wikis it is either assumed that people will speak a common language (usually English) or thattranslationsto other languages will be provided. But manually translating pages is a maintenance burden, since the Wiki system does not recognise the structured in-formation inside the page text. For example, a page about John Grisham contains structured information such as his birth date, the books he authored, and his publisher. Updates to this information have to be migrated manually to the translated versions of this page. Considering that for example Wikipedia has translations of pages in up to 189 languages5, synchronisation of page versions can become quite a burden.
For reusing information the creation ofviewsis often useful. As an example consider that, in general, books are written by an author and published by the author’s publisher. The books authored by John Grisham (on his page) should therefore also automatically appear as books published by Random House (on their page). But creating such a view is not possible, and therefore the information has to be copied and maintained manually.
5.2 Semantic Wikis
Generally speaking, a Semantic Wiki allows users to make formal descriptions of resources (“things”) by annotating the pages that represent those resources. Where a regular Wiki enables users to describe resources in natural language, a Semantic Wiki enables users to additionally describe resources in a formal language.
Using the formal descriptions, or annotations, of resources, Semantic Wikis offer additional features over regular Wikis. Users can query the annotations directly (“show me all authors”) or create views from such queries. Also users can navigate the Wiki using the annotated relations (“go
4except for “back-references”, appearing on each page, showing other pages that reference it. 5
to other books by John Grisham”), and users can introduce background knowledge to the system (“all poets are authors; show me all authors”).
In our vision, as Wikis are editing environments for the Web, Semantic Wikis will become editing environments for the Semantic Web. Finding the right balance between authoring effort and benefit is however crucial:
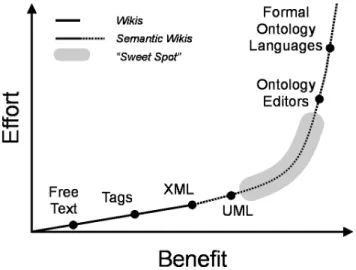
Different forms of knowledge authoring can be positioned on a continuum in invested effort and returned benefit. For example, knowledge written as free text requires little effort but provides also little benefit, the information is unstructured and cannot be retrieved and reused efficiently; tagging texts with keywords requires slightly more effort and provides slightly improved retrieval; and formal ontology languages require significant authoring effort (authors are restricted in their possibilities and have to follow specific rules) but also provides significant benefits: automated support for knowledge retrieval, reuse, and reasoning.
Figure 2: Effort and benefit in knowledge authoring
On this continuum, Wikis have a flexible position: they allow users different levels of authoring (from free-text to structure and layout markup). In our opinion that flexibility is key to their success: they do not force users into one single approach but can be used in various degrees of annotations. Each degree introduces an increased authoring effort but also an increased benefit: this gradual increase of effort and benefit allows users to adjust the authoring platform for their needs.
For Semantic Wikis to be adopted, this authoring continuum should be taken into account: we envision an evolutionary approach that offers different degrees of additional annotations with increasing effort and benefit. We therefore allow users to annotate their data, but we do not force them to do so.
The benefits of adding annotations to Wiki pages are better navigation and better information retrieval. The authoring effort is relatively low: the semantic annotations are very similar to the layout or structural directives that are already in widespread use in ordinary Wikis.
In designing a Semantic Wiki system several architectural decisions need to be taken. In this section, we explain the basic architecture and outline the design choices and their consequences.
5.2.1 Architecture Overview
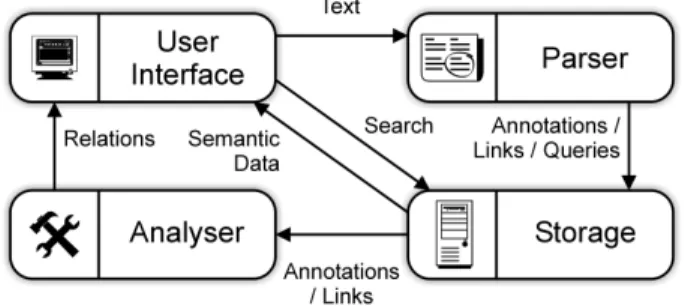
A Semantic Wiki consists (at least) of the following components: a user interface, a parser, a data analyser, and a data store, as shown in figure 3. First we introduce each component, then we discuss the information access, the annotation language, and the ontological representation of the Wiki.
Figure 3: Architecture of a Semantic Wiki
Users can browse, edit, and query pages via the user interface. When users edit a page, the user interface notifies the parser. The parser analyses the text, and extracts annotations and links. All data (text, annotations, etc.) are stored in the semantic storage. From the data in the storage, the analyser computes sets of pages that are related to the current page, which are displayed by the user interface. Queries are posed to the storage, and the results are displayed by the user interface. All these operations should happen unobtrusively in the background, as to provide the user a responsive application.
The user interfacecomponent is responsible for all user interaction. If the Wiki is web-based (the classical model), then the user interface is a server-based component that generates web pages to be viewed in a browser. The user interface can also be a desktop application; in that case the Wiki can be used for personal note-taking6, or collaboration functionality is offered through shared storage.
The user interface shows pages, their annotations, and navigation possibilities to related pages. It allows users to type text and annotations in a freely intermixed fashion. The user interface also shows available terms from shared ontologies, enabling users to browse for an appropriate term to use in their annotations7.
Theparsercomponent converts the text written by the user into objects: it parses the text for semantic annotations, layout directives, and links.
The data analyser is responsible for computing a set of related resources from a given page. In a regular Wiki, this means just to find all back-references, i.e. pages that link to the current one. In a semantic environment, the relations between resources are much richer. The data analyser uses the annotations about the current page, found by the parser, and searches for relevant relations in the data store (such as “other books by current author”, or “other persons that have the same parents as the current one”).
6
as has recently become quite popular, e.g. Tomboy or WikidPad.
7descriptions can be shared and understood if users write them in a common terminology; browsing ontologies helps users to find the appropriate common term for their annotations.
Thesemantic storageis responsible for storing and retrieving the semantic annotations. The location of the datastore determines collaboration features:
1. the datastore is hosted locally, on the same machine as the Semantic Wiki
(a) if the user interface is server-based and supports multiple users, collaboration is possible (b) if the user interface is desktop-based then the Semantic Wiki is limited to single person
usage
2. The datastore is hosted on a server; the user interface can still be desktop-based but users can collaborate using the same shared datastore.
3. The datastore is hosted locally with peer-to-peer connections to other stores on other machines (distributed).
5.2.2 Annotation language
The for the user of a Semantic Wiki most visible change compared to conventional Wikis is the modified annotation language. For Semantic Wikis the annotation language is not only responsible for change in text style and for creating links, but also for the semantic annotation of Wiki pages and for writing embedded queries in a page.
Annotation primitives As in conventional Wikis, internal links are written in CamelCase8 or by enclosing them in brackets; external links are written as full absolute URIs, or are abbreviated using namespace abbreviations. Internal Wiki links are expanded to absolute URIs using the usu-ally configurable Wiki base namespace, namespace abbreviations are expanded using configurable namespace definitions.
Semantic annotations are written on a separate line, and, following RDF conventions, consist of a predicate followed by an object. Predicates can only be resources, objects can be either resources or literals. Annotations are expanded to triples using the resource that the page is describingas the subject of the triple. To annotate the current Wiki page itself, instead of the resource that the page is describing, annotations have to be pre-pended with an exclamation mark (since annotations of resources are more common than annotations of pages).
An example page with annotations and an embedded query is displayed in figure4. It describes John Grisham, an author published by Random House. Information about John Grisham is mixed between natural text in English and formal annotations.
Page: JohnGrisham
John Grisham is an author and retired lawyer.
rdf:type foaf:Person dc:publisher RandomHouse
Figure 4: Example page
8
Wiki pages as resources Wiki pages often refer to real-world resources, and annotations may refer both to the page resource and to the resource that is described. For example, a triple “John-Grisham created on 1955-02-08” can refer to the creation date (or birth date) of the person John Grisham, or about the creation date of the Wiki page about that person. We discuss three possi-bilities to resolve this issue:
1. We may use the same URI to denote pages and resources, but duplicate the problematic predicates in different namespaces, as shown in figure 5. The predicate “semperwiki:date” refers to the creation of the page, the “birthdate” predicate refers to the creation of the person.
Figure 5: Duplicating predicates
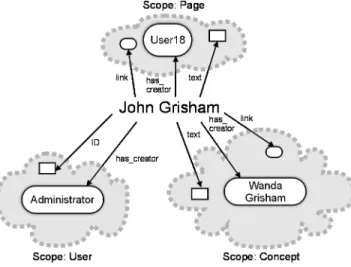
2. We may use the same URI and the same predicate for these statements, but represent the scope of statements in RDF contexts, as shown in figure 6. Users may create arbitrary scopes when the make a statement, for example the scope of JohnGrisham as a page, of JohnGrisham as a person, and of JohnGrisham as a user of the Wiki system. When consuming the information, the scope explains how to interpret the statements, i.e. whether we are talking about JohnGrisham as a page or as a person.
3. We may separate the resource into the “page” resource and the “real world” resource, as shown in figure 7. We have a resource that identifies the page about John Grisham, and we have another resource that identifies the person. The page has an “about” predicate, linking it to the resource it describes.
The approaches 1 and 2 have the disadvantage that the same URI is intentionally used for two different resources and mechanisms outside the shared understanding of the RDF graph are necessary to deduce the true meaning of the URI. Therefore the URI is not acting as an identifier identifying exactly one resource.
Therefore we are following approach 3 and introduce different URIs to denote the Wiki page and the resource that the Wiki page describes. Since we expect that annotation of the resource that the page describes will occur more frequently, it is justifiable to make it syntactically easier
Figure 6: Scoping statements
Figure 7: Separating page and resource
to annotate this resource instead of the Wiki page itself. In case the author of a Wiki page has naming authority it is often convenient to assume an automatic means to create the URI of the described resources, for example by a simple syntactic manipulation of the page URL.
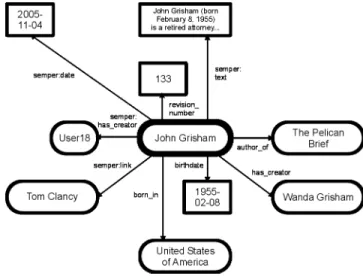
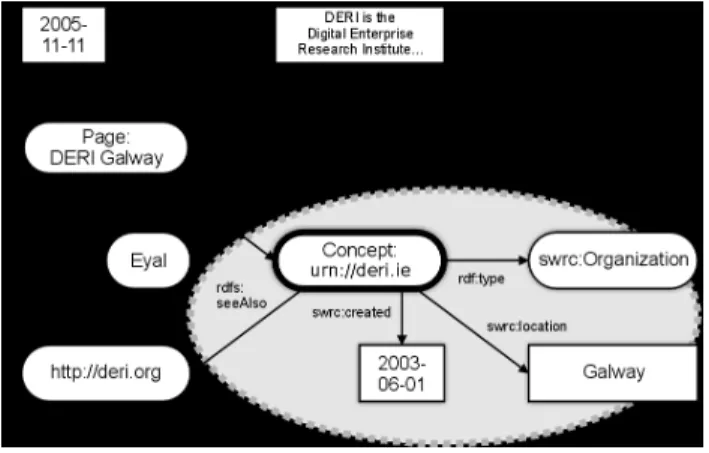
Advanced annotations In case a author of a Wiki page does not have naming authority over the resource it is necessary to explicitly specify the URI of the described resource. For example, figure8shows a page that describes the research institute DERI. The page uses the “semper:about” predicate to relate the page to the resource (DERI, identified byurn://deri.ie) that it is describ-ing. The annotations state, using the Semantic Web Research Community ontology, that DERI is a research institute, founded in June 2003, and located in Galway. The last annotation, prepended with an exclamation mark, refers to the page instead of the resource; it states that Eyal Oren is the creator of that page.
Page: DERI Galway
DERI Galway is one location of the Digital Enterprise Research Institute, researching Semantic Web technology; our main page is at http://deri.org. semper:about urn://deri.ie
rdf:type swrc:Organization swrc:location "Galway" swrc:created "2003-06-01" !dc:creator EyalOren
Figure 8: Annotating real-world resources
Galway” has a property text, it has a creator and creation date that are populated by the Wiki system, and it contains a navigational hyperlink to http://deri.org. The page “DERI Galway” contains information about the resourceurn://deri.ie. This resource is the actual subject of the annotations: it is a research organisation, it has a creation date and location, and it has a logical relation to thehttp://deri.org resource.
Figure 9: Corresponding RDF graph about DERI Galway
The annotation mechanism can be used to annotate arbitrary resources, including editing or creating existing ontologies. Figure10 for example shows how to describe a new class Cluster (an organisational structure) in the DERI ontology.
Arbitrary annotations The proposed annotation syntax is simple and direct, but users can only annotate the current page, which is a severe limitation. If one describes an address book for example, then each contact in the address book needs to be described on his own Wiki page. But if one just wants to make a list of contacts and their email addresses, then making a separate page for each contact is time consuming. Also it is not possible to make statements about unnamed resources (“blank nodes” in RDF), since each resource that is described has to have a named page.
Page: DeriCluster
semper:about deri:Cluster rdf:type rdfs:Class
rdfs:subClassOf swrc:Organization We have now created a new class Cluster in our DERI ontology. This class appears in the ontology browser, and can be used as any other class. We can add new properties to the ontology in the same way.
Figure 10: Editing ontologies
But unnamed resources are common in reality, see for example figure 11.
Figure 11: RDF graph of an address
A Semantic Wiki needs to offer a syntax for arbitrary RDF statements, that offers a shorthand for multiple values for a key, and allows to describe resources on arbitrary pages. In the Semantic Web similar issues have been worked on, leading to several compact syntaxes for RDF; we propose to use Turtle9 for the arbitrary annotations.
Representing Wiki pages in RDF We have developed a simple representation format for storing Wiki content and annotations in a triple store. Figure 9 shows the example of figure 8 and the additional metadata about the Wiki page that is stored in the datastore. The additional metadata about the page is capturing the creator, creation time, and links to other pages in order to provide the conventional hyperlink functionality.
Embedded queries Embedded queries (generating views) are written using triple patterns, se-quences of subject, predicate, object, that can contain variables (names that start with a question mark). A triple pattern is interpreted as a query: triples matching the pattern are returned. Patterns can be combined to form joins.
9
Figure 12 shows the earlier example page about John Grisham, including an embedded query at the bottom of the page. The query returns all books written by JohnGrisham; it creates a view on the data that is displayed below the page text.
Page: JohnGrisham
John Grisham is an author and retired lawyer.
rdf:type foaf:Person dc:publisher RandomHouse
this query shows all his books: ?book dc:creator JohnGrisham TheFirm dc:creator JohnGrisham TheJury dc:creator JohnGrisham
ThePelicanBrief dc:creator JohnGrisham
Figure 12: Page showing embedded query
5.2.3 Information access
Information access is offered through structured navigation and various querying facilities:
Navigation Navigation in ordinary Wikis is limited to explicit links entered by users. It is not possible to navigate the information based on structural relations. As explained, that is a severe limitation.
A Semantic Wiki provides the metadata necessary to navigate the information in a structured way. For example, knowing that John Grisham is an author, we can automatically show all other authors in the system, and offer navigation to them.
One approach for structural navigation is faceted meta-data browsing, or category-based brows-ing [26]. In faceted browsbrows-ing, the information space is partitioned usbrows-ing orthogonal conceptual dimensions (facets) of the data, which can be used to constrain the relevant elements in the infor-mation space. For example, a collection of art works can consists of facets such as type of work, time periods, artist names, geographical locations, etc.
Users can select a certain facets (e.g. 20th century) to constrain the visible collection to only the art works from that facet. Multiple constraints can be applied conjunctively: by selecting the facets book art form, 21st century period, located in USA, artist name “John Grisham”, the selection is restricted to the books written by John Grisham in the USA in the 21st century.
Using the structured metadata enables faceted browsing of the Wiki information space. We use the metadata of the pages to partition the information space into facets. Partitions (sets of resources) are created for each predicate, object pair in the knowledge base, as follows:
Rp,o={page|(page, p, o)∈KB},
where (s, p, o) denotes the triple (subject, predicate, object) and KB is the knowledge base consisting of all RDF statements in the datastore. Each set Rp,o is a partition of the space on
a particular object pair, and contains the resources that have that particular predicate-object pair. Together the sets Rp,o form the base partition of our information space.
For example, the setRdc:author,J ohnGrisham contains the Pelican Brief, the Firm, the Jury, etc.;
and the set
Rrdf:type,f oaf:P ersoncontains John Grisham, John le Carr´e, Joseph Roth, etc.
When the user is viewing some selection (e.g. all books by John Grisham) or a single item (e.g. The Pelican Brief), we display the related items based on the partitioning: for all partitions that have a non-empty intersection with the current selection navigational links are shown.
For example, if the user is looking at all books by John Grisham, then we would show links to (i) all books (since the current selection contains books), (ii) all books published by Random House (since the current selection contains books published by Random House), (iii) all books from 1995 (since the current selection contains books from 1995), etc. If the user is viewing for example the page about John Grisham, we would show: (i) all people (since John Grisham is a person), (ii) all authors, (iii) all authors published by Random House, etc.
The backlinks are computed in a similar fashion: each setBsel,pred contains the back-references
from a certain selection of pages sel, using a certain predicate pred. These back-references are computed by the union of all pages that point to some page in the current selection (p∈sel), using the predicate pred.
Bsel,pred= [ p∈sel
{page|(page, pred, p)∈KB}
.
This means that each setBsel,pred contains the pages that point to a page in the selection. For
example, the backlinks for the selection containing John Grisham and Madeleine Albright, would include books written by John Grisham (page with dc:creator John Grisham), friends of Madeleine Albright (page with foaf:knows Madeleine Albright), etc.
Querying We distinguish three kinds of querying functionality: keyword search, queries, and views:
1. A keyword-based full-text search is useful for simple information retrieval, and supported by all conventional Wiki systems.
2. Structured queries use the annotations to allow more advanced information retrieval. The user can query the Wiki for pages (or resources) that satisfy certain properties. We suggest to use triple patterns that include free variables as basic query statements. To retrieve for example all authors one can query for “?x type author”. Triple patterns can be combined to form database-like joins: “?x type author and ?x has-publisher ?y” retrieves all authors and their publishing companies.
3. Byembedding queries into the Wiki page, users can create persistent searches or views on the Wiki. A query included on a page is executed each time the page is visited, and continuously shows up-to-date query results. Embedded queries are further discussed in section 5.2.2.
Figure 13: SemperWiki user interface 5.3 Semantic Wiki: Implementation
This section presents SemperWiki, our prototype implementation of a Semantic Wiki [21]. It is a desktop application that follows the previously-discussed architecture; the architecture itself is equally applicable to Web systems.
SemperWiki is implemented in Ruby10, using the GTK11 windowing toolkit for the graphical programming. It is open source, consists of around 1500 lines of code, and can be downloaded at
http://semperwiki.org. 5.3.1 System overview
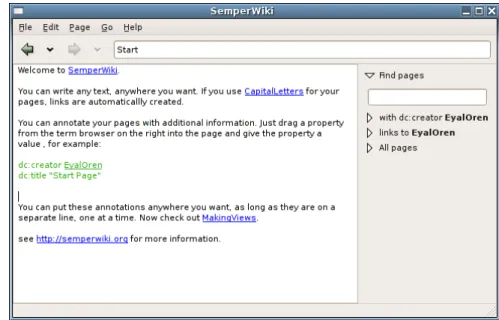
SemperWikiis a Semantic Personal Wiki that can be used for personal knowledge management. The main advantages compared to a normal Wiki are intelligent navigation, semantic search, and embedded queries. All information in SemperWiki can be annotated semantically, and all infor-mation can be exported and shared on the Semantic Web.
The user interface of SemperWikiis shown in figure13On the left-hand side the user can edit pages, and on the right-hand side the user can navigate. At the top, there is the menu bar, which gives access to all functions, and the location bar, showing the current page.
Navigating throughSemperWikiworks similar to a Web browser: the user navigates to a page by typing its address or by clicking a link to that page; one can also go back and forth through the browsing history.
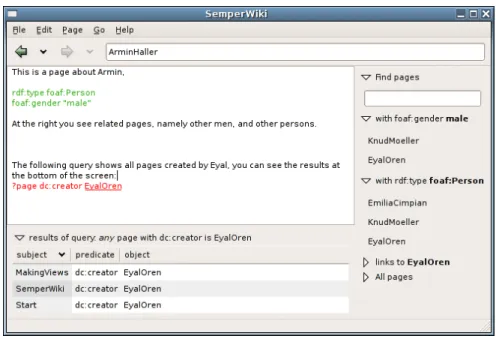
SemperWiki offers a sidebar with intelligent navigation links, which can be used to navigate to related pages. These links are based on the faceted browsing explained in section5.2.3: the links show related information categorised per facet. Ordinary Wikis only show pages that contain links to the current one; SemperWiki shows much richer related information.
10http://ruby-lang.org/. 11
In the top right corner, thesemantic searchfunctionality is visible: one can find pages by listing one or more properties, such as the author or the publisher of a book. Ordinary Wikis only offer full-text search.
The main text shows an example of embedded queries: a query can be embedded in any page; its results are displayed each time the page is visited. Each page can contain an arbitrary number of such queries. Ordinary Wikis do not offer such functionality.
5.3.2 Writing
A page in SemperWikican consist of arbitrary text, links to other pages or websites, and anno-tations. Links can be internal, to other pages in the Wiki, or external, to arbitrary Web pages. Clicking internal links navigates to them, clicking external links opens them in their default appli-cation.
SemperWiki aims for high usability: it should be easy and fast to use both for novice and experienced users. We adhere to the Gnome human interface guidelines12, a set of guidelines for consistent and user-friendly user interfaces. All functions are accessible through keyboard shortcuts. The interface provides instant response to all user actions: links are tagged instantly, correct annotations are colored green, and changing annotations changes the sidebar in real-time. After writing some pages, the user can just hit Escape to exit; all user changes are instantly saved to the data storage, andSemperWikiremembers each cursor position on each page: the next time SemperWiki is started, everything is exactly how the user left it.
To help users reuse existing terminology instead of inventing their own, and to thus enable better sharing of knowledge,SemperWikioffers a simple ontology browser. Users can browse terms from common ontologies, and import others by entering the URL for the ontology. We show the terms (classes and properties) in each ontology; the user can browse those terms and drag-and-drop them to the current Wiki page. When the user drags a class, we complete it to a full annotation by pre-pending it with “rdf:type”; otherwise we just insert the selected property; the user only needs to give an object value for the property.
5.3.3 Navigating
The navigation bar, on the right in figure 14, shows intelligent navigation options based on the annotations of the current page and the information in the knowledge base. The related pages are categorised per facet, computed by the data analyser. The data analyser returns several sets of related pages, representing different facets in which other pages relate to the current one. We display those sets in the order from most specific to most general, ending with the set of all pages.
5.3.4 Searching
Figure 14 also shows a query, embedded in the ordinary text. The query results are shown at the bottom of the screen. Each result can be clicked on, which navigates to the page where the statement was made; the user could then edit the statement. Any changes to the embedded query or the underlying data are reflected instantly on the result set: the results are continuously up-to-date.
12
Figure 14: Navigating and Information reuse
5.3.5 Storage
The storage component persistently stores and retrieves the pages and their annotations. We use RDF as the datamodel, and a standard RDF database for storing our data. All our data (page text, page annotations, user preferences) are stored in the RDF store.
We use Redland [2] for storing and retrieving RDF. Redland is a mature RDF store. It has a small footprint and can easily be embedded in an application. It has bindings for many different languages, including Ruby.
We do not yet use contexts of statements, since support for triple contexts in Redland is not complete (namely, contexts are not first-class citizens, and cannot be used in the same manner as subjects, predicates, and objects; in particular, it is not possible to directly find the context of a statement, other than by traversing all existing contexts).
5.3.6 Component interaction
To keep the system responsive, components cooperate via event notification: each component is subscribed to relevant events of other components; upon notification, components do their job in the background, and notify other components when they are done.
The parser is subscribed to the user interface, it gets notified on each text change (when the user adds or removes some text). It then parses the page in the background, updates the set of queries and annotations belonging to that page, and notifies the components subscribed to that change: the user interface, the storage, and the analyser.
The user interface looks for changes in the embedded queries, and if found, asks the storage for query results. The data analyser looks for changes in the annotations and computes the related pages (which the user interfaces displays); the storage is subscribed to changes in the annotations as well, and stores them persistently.
These actions are performed on each keystroke; to maintain responsiveness all components operate in the background, in idle CPU cycles. Currently this approach works very well, but we have to evaluate it with large datasets and network access; it might become infeasible to perform all these updates in real-time.
5.3.7 Addressing Wiki limitations
In section5.1several limitations of Wikis were discussed. In this section, we show how our Semantic Wiki addresses these limitations.
Users can find related information in the Semantic Wiki even without direct links, created by other users. The Semantic Wiki analyses the semantic relations in the data and provides related information categorised per facet. Navigational links to related pages are displayed on the sidebar, offering intelligent navigation based on the structural metadata.
Users cansearchfor information using structured queries. In addition to simple full-text search, users can discover information by querying the semantic annotations. Users can also writeembedded queries, creating saved searches or database views. The views can be revisited and reused later.
The semantic annotations also allow better translation and maintenance; the annotations are language independent13and can be understood and reused without barriers. One can offer versions of pages in different languages, and these can provide a consistent, shared, view of language-independent properties through embedded queries.
6
Summary
We have discussed issues in workflow data integration, namely data consistency and data retrieval. Our integration solution is based on the multi-meta model process ontology m3po, that can capture and represent arbitrary workflow data from different workflow management systems.
To edit, add, annotate, browse, and query workflow data, we have introduced the paradigm of semantic wikis and our implementation SemperWiki.
We have not yet adopted the Semantic Wiki paradigm specifically to the workflow domain. Further work is necessary to analyse the specific requirements (user operations) of this domain, and to adjust the SemperWiki system to these requirements.
References
[1] W. M. P. van der Aalst and A. H. M. ter Hofstede. YAWL: Yet another workflow language. Information Systems, 30(4):245–275, 2005.
[2] D. Beckett. The design and implementation of the Redland RDF application framework. Computer Networks, 39(5):577–588, 2002.
[3] C. Bock and M. Gruninger. PSL: A semantic domain for flow models. Software and Systems Modeling Journal, 2004.
13annotations are only language independent if ontologies contain translations for property label, but translating property labels is of course more manageable than translating general knowledge.
[4] J. Broekstra, A. Kampman, and F. van Harmelen. Sesame: A generic architecture for storing and querying RDF and RDF Schema. In I. Horrocks and J. Hendler, (eds.)Proceedings of the First International Semantic Web Conference, pp. 54–68. 2002.
[5] A. L. Burrow. Negotiating access within wiki: a system to construct and maintain a taxonomy of access rules. In HyperText ’04: Proceedings of the fifteenth ACM conference on Hypertext and hypermedia, pp. 77–86. ACM Press, New York, NY, USA, 2004.
[6] C. Bussler. Enterprise-wide workflow management. IEEE Concurrency, 7(3):32–43, 1999. [7] C. Bussler. The application of workflow technology in semantic b2b integration. Distributed
and Parallel Databases, 12(2-3):163–191, 2002.
[8] S. Decker et al. The semantic web: the roles of XML and RDF. IEEE Internet Computing, 4(5):63–74, 2000.
[9] A. Y. Halevy. Answering queries using views: A survey. The VLDB Journal, 10(4):270–294, 2001.
[10] A. Haller and E. Oren. A process ontology to represent semantics of different process and choreography meta-models. Tech. rep., DERI, 2006.
[11] A. Harth and S. Decker. Optimized index structures for querying RDF from the web. In Proceedings of the 3rd Latin American Web Congress. 2005.
[12] R. Hull. Managing semantic heterogeneity in databases: A theoretical perspective. In Proceed-ings of the Sixteenth ACM Symposium on Principles of Database Systems, May 12-14, 1997, Tucson, Arizona, pp. 51–61. ACM Press, 1997.
[13] A. D. Iorio and F. Vitali. From the writable web to global editability. In HyperText ’05: Proceedings of the sixteenth ACM conference on Hypertext and hypermedia, pp. 35–45. ACM Press, New York, NY, USA, 2005.
[14] S. Jablonski and C. Bussler. Workflow Management: Modeling Concepts, Architecture and Implementation. International Thomson Computer Press, 1996.
[15] N. Kavantzaset al.Web services choreography description language version 1.0, 2004. Available
fromhttp://www.w3.org/TR/2004/WD-ws-cdl-10-20041217/.
[16] M. Lenzerini. Data integration: A theoretical perspective. In L. Popa, (ed.) Proceedings of the Twenty-first ACM Symposium on Principles of Database Systems, June 3-5, Madison, Wisconsin, USA. ACM, 2002.
[17] B. Leuf and W. Cunningham. The Wiki Way: Collaboration and Sharing on the Internet. Addison-Wesley, 2001.
[18] F. Manola and E. Miller. RDF primer, 2004. Available from http://www.w3.org/TR/ rdf-primer/.
[19] S. Melnik. Generic Model Management: Concepts and Algorithms. Ph.D. thesis, University of Leipzig, 2004.
[20] S. Mukherjee, et al. Logic-based approaches to workflow modeling and verification. In J. Chomicki, R. van der Meyden, and G. Saake, (eds.) Logics for Emerging Applications of Databases, chap. 5, pp. 167–202. Springer-Verlag, Berlin, 2004.
[21] E. Oren. SemperWiki: a semantic personal Wiki.
[22] A. P. Sheth, W. van der Aalst, and I. B. Arpinar. Processes driving the networked econony. IEEE Concurrency, 7(3):18–31, 1999.
[23] S. Thatte et al. Business process execution language for web services, v1.1, May 2003. [24] XML process definition language v2.0. Workflow Management Coalition, 2005.
[25] K. Wilkinson, C. Sayers, H. A. Kuno, and D. Reynolds. Efficient RDF storage and retrieval in Jena2. In I. F. Cruz, V. Kashyap, S. Decker, and R. Eckstein, (eds.)Proceedings of SWDB’03, The first International Workshop on Semantic Web and Databases. 2003.
[26] K.-P. Yee, K. Swearingen, K. Li, and M. Hearst. Faceted metadata for image search and browsing. InCHI ’03: Proceedings of the SIGCHI conference on Human factors in computing systems, pp. 401–408. ACM Press, New York, NY, USA, 2003.