RESEARCH NOTE
A NEW APPROACH FOR KNOWLEDGE-BASED SYSTEMS
REDUCTION USING ROUGH SETS THEORY
G. A. Montazer
Department of Electrical Engineering, Institute of Information Technology Tarbiat Modarres University, Tehran, 14115-179, Iran, [email protected]
(Received: June 13, 2001 - Accepted in Final Form: February 6, 2003)
Problem of knowledge analysis for decision support system is the most difficult task Abstract
of information systems. this paper presents a new approach based on notions of mathematical theory of Rough Sets to solve this problem. Using these concepts a systematic approach has been developed to reduce the size of decision database and extract reduced rules set from vague and uncertain data. The method has been applied to an imprical medical database with large scale data size and the final reduced and core rules has been extracted using concepts of this theory.
Information System, Database, Rough Sets Theory, Reduction, Decision Making Key Words
-ǽA nj /SwA »UBîÀLJA ºB´ªTv¼w nj k®½Ao— -½oT¦ñz« ,ºo¼£©¼ª~U ºB´ªTv¼w nj y¯Aj ¥¼¦dU
²k¼ña
»®TL« x°n -½A /j±{»« ³ÄAnA ³§Fv« -½A ¥e ºAoM ™¼›jB¯ ºBµ³î±ª\« »ƒB½n ·½oŠ¯ tBwA oM ºk½k]x°n ³§Bš« ©¼µB–Ç« •½oíU BM ° Bµ³~¼~i xpnA ¤°k] ¥ñ{ ³M ²jAj ²B¢½BQ ·§BeA BM ¬C nj ³Ÿ SwA »ñ¼UBªTv¼w nBñµAn oM /j±{»Ç« ZAohTwA S¼í†› ¨kî ° ¨B´MA BM ¨E±U ¤°k] pA »~hz« kîA±› ·î±ª\« ,¤°k] ·Tvµ ° ³T—B½ yµBŸ@ ºnBª¼M }¼hzU ¤°k]) »ñ{qQ »í›A° ·§Fv« ð½ jBíMA yµBŸ nj k½k] x°n -½A pA ²jB–TwA ¶±d¯ -½A oM ²°Àî /SwA ²k½jo£c½ozU ²k{ ²jBw kîA±› ¬jn°CSwj³M »¢¯±¢a ° ²k{ -¼¼LU (¬C ©ÄÀî tBwA oM »æBi1. INTRODUCTION
I n fo r ma t io n is o ft e n a va ila ble in a fo r m o f da t a ba se s kn o wn a s in fo rma t io n syst e ms o r at tribute - value table s. The most difficult task of information systems is knowledge analysis for d e cisio n m a k in g p r o ce ss. C o lu m n s o f a n informat ion t able are lable d by att ribut es, rows by objects and entries of the table are attribute values. Objects having the same attribute values are indiscernible with respect to these attributes [1].
R o ugh Se t s T h e o r y is a n e w ap p r o ach t o dat a an alysis which has at t ra ct e d at t e n t ion of many researchers all over the world [2,3,4]. This t heory overlaps wit h many ot he r t heorie s such as Fuzzy set theory [5], Evidence theory [6] and Boolean re asoning me thods [7], nevertheless it c a n b e vie we d i n i t s o wn r i gh t s, a s a n independent disipline [8].
This methodology has found many real - life
ap plica t io ns in e ngine e r ing [9, 10], me dicine [11], ima ge p r o ce ssin g [12], a n d so o n . T h e propose d approach has many advant age s such as:
É
Provides efficient algorithm for finding hidden pattern in data.É
Finds minimal Sets of data.É
Evalutes significance of data.É
It is Easy to understand and offers straightforward interpretation of results.The main aspe ct of t his art icle h as fo cuse d on the core concepts of Rough Sets Theory and how to use it to reduce the size of the decision ma king pr oce sse s t o re su lt in an e vide n t a nd exact rule - based system from vague databases.
2. ROUGH SETS THEORY FUNDAMENTALS
T h e t h e o r y o f r o u gh se t s h a s b e e n u n de r
continuous deve lopme nt for ove r rece nt years. The t he ory was originat e d by Z dzislaw P awlak in 1970's as a result of a long term program of fundament al re search on logical prope rt ie s of informat ion syst e ms, ca rrie d ou t by him and a gr o u p o f lo gicia n s fr o m P o lish A ca de my o f Sciences and the University of Warsaw, Poland [13].
T h e me t h o do lo gy is co n ce r n e d wit h t h e classificatory analysis of imprecise, uncertain or incomplete information or knowledge expressed in terms of data acquired from experience. The primary notions of the theory of rough sets are t he approximat ion space and lowe r and uppe r approximat ions of a se t . This proce ss is calle d gr o n e llin g. T h e a p p r o xima t io n sp a ce is a classifica t io n o f t h e d o ma in o f in t e r e st in t o disjoint cat egories. The classificat ion formally represents our knowledge about the domain, i.e. t he knowle dge is unde rst ood he re as an abilit y t o charact e rize all classe s of t he classification, fo r e xa mp le , in t e rms o f fe a t ur e s o f o bje ct s be longing to t he domain. O bject s be lobging t o the same category are not distinguishable, which means that their membership status with respect t o an ar bit ra ry subse t o f t h e domain ma y n ot always be cle ar ly de finable . Th is fact le ads t o t he de fin it ion o f a se t in t e r ms o f lowe r an d upper approximations. The lower approximation is a description of the domain objects which are known with certainty to belong to the subset of int e re st , whe re as t h e up pe r a ppro xima t ion is description of the objects which possibly belong t o t h e subse t . Any subse t de fine d t h rough it s lower and upper approximations is called "rough set".
The main specific problems addressed by the theory of rough sets are [8]:
1. R e pr e se nt at io n o f u nce r t a in or impr e cise knowledge.
2. Empirical learning and knowledge acquisition from experience.
3. Knowledge analysis. 4. Analysis of conflicts.
5. E va lua t io n o f t h e qu a lit y o f t he a va ila ble infor mat ion wit h re spe ct t o it s consist e ncy an d t h e p re se nce o r a bse n ce of re pe t it ive
data patterns.
6. I d e n t i fic a t io n a n d e va lu a t io n o f d a t a dependencies.
7. Approximate pattern classification. 8. Reasoning with uncertainty.
9. Information - preserving data reduction.
3. BASIC DEFINITIONS
Some basic de finitions appear be low, followe d by a some what t rivial e xample t o de monst rat e some basic concepts.
G ive n a se t of obje ct s, O BJ , a se t of obje ct a t t r ibu t e s, A T , a se t o f va lu e s, V A L , a n d a function f: OBJ
*
AT à VAL, so that each object is described by the values of its attributes, we define an equivalence relation R(A), where A is a subse t of AT: give n t wo obje ct s, o1 and o2; o1 R(A) o2óf(o1, a) = f(o2, a), for all a in A W e sa y o1 a n d o 2 a r e in disce r n ible ( wit h r e spe ct t o at t r ibut e s in A) . No w, we use t h is r e l a t i o n t o p a r t i t i o n t h e u n i ve r se i n t o equivalence classes, {e0, e1, e2, ..., en} = R*(A).The pair (OBJ, R) forms an approximation space wit h which we approximat e arbitrary subset s of OBJ referred to as concepts.
Given O, an arbitrary subset of OBJ, we can a p p r o xima t e O b y a u n io n o f e q u iva le n ce classes:
The LOWER approximation of O (also known as the POSITIVE region):
LO WE R ( O ) = P O S ( O ) =
i
Union {e subset O} The UPPER approximation of O:
U P P E R ( O ) = U nion {ei \ int e rse t O \
not = empty} NEG (O) = OBJ - POS (O)
TABLE 1. Prototype Database.
Decision
Education
Name
No High School
Ali
Yes High School
Maryam
No Elementary
Hassan
Yes University
Hossein
Yes Doctorate
Fatemeh
If a subse t o f at t ribut e s, A , is sufficie n t t o create a partition R* (A) which exactly defines O , t h e n we sa y t h a t A is a r e d u c t . T h e intersection of all reducts is known as the core. It must be noted that this is the simplest model and there are several probabilistic versions.
Often we use rough set theory for inductive learning description:
description [POS (O)] àPositive decision class de scr ip t io n [NE G ( O ) ]à Ne ga t ive
decision class de scr ip t io n [B N D ( O ) ] àP r o b a b ilist ica lly positive decision class Th e simp le following e xamp le re vie ws t he me anin gs of t he abo ve conce pt s. A ssu me t he above table which shows the relations among e ducat iona l le ve l an d p orospe ct e d job o f five persons:
So , t he se t of posit ive e xamp le s o f pe op le with good job prospects:
O =
{Maryam, Hossein, Fatemeh} The set of attributes:
A =
{
Education}
The equivalence classes:R * ( A ) = { {(Ali,Maryam),(H assan ),(Hossein), (Fatemeh)
}
The lower approximation and positive region: P O S ( O ) = L O W E R ( O ) =
{
Ho ssein Fatemeh}
The negative region:
NEG (O) =
{
Hassan}
The boundary region:BND (O) =
{
Ali, Maryam}
The Upper approximation:UPPER (O) = POS (O) + BND (O) =
{
Ali, Maryam, Hossein, Fatemeh}
U sing t he se de fin it ions, de cision rule s will be derived as:des [POS (O)] à Yes
des [Neg (O)] à No
des [BND (O)] àPossibly Yes or No That is:
( E d u ca t io n , U n ive r sit y) O r ( E u d u ca t io n , Doctorate) à Good prospects
(Education, Elementary) àNo good prospect ( E du ca t io n , H igh sch o o l) àP o ssible go o d prospect
4. PROBLEM STATEMENT
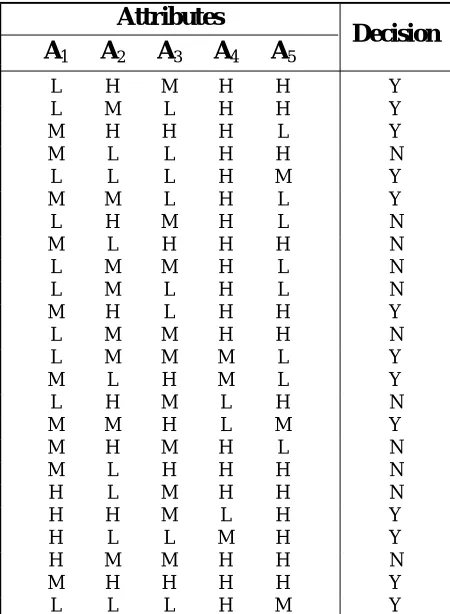
W e h a ve a d ia gn o sis d a t a b a se wh ich h a s compre ssed t he e xpe rt ne ss of e spe cialist s and experiment results about a special disease. This d a t a b a se su c h a s sh o wn i n T a b le 2 h a s compose d of five me sure me nt dat a A1, ..., A5,
in clu din g t he value s
of
Ca2+, N aH P O 4, P , K+a nd F e3+ , re sp e ct ive ly for 24 diffe re n t ca se s
wh ic h h a ve b e e n n o r m a l iz e d t o b e in a comparable range H ( H igh), M ( Me dium) and L ( L o w) . T h e se five p a r a me t e r s h a ve be e n interpreted as attributes.
T h e cla ssifica t io n o f e a ch st a t e is ma de according to an expert and has classified by two possible outputs
<
Yes>
and<
No>
which show if t he case is unde r dise ase or not , re spe ct ive ly. O n e of t he basic pro ble ms in t h is da t abase is vague ne ss of de cisions and unce rt ain re lat ion be t we e n obje ct - at t ribut e valu e and it s re sult ( decision column). It is obvious t hat the large r size o f t he da t a ba se , t he mo r e difficu lt ie s in decision proce ss. H e nce , we propose a me t hod based on rough sets theory to reduce the size of foregoing information system and to classify the d a t a e n t r ie s t o e a se t h e de cisio n m a k in g procedure.5. ROUGH SET BASED REDUCTION APPROACH
Th e a lgorit h m o f t he re duct ion of a de cision table can be shown using algebric developments o r b a se d o n lo gica l r e la t io n s [14]. M a n y algorit hms have be e n de ve lope d t o re duce t he co n d i t io n s a n d h a ve b e e n u se d in m a n y
TABLE 2. Medical Decision Making Table.
Attributes
Decision
A
5A
4A
3A
2A
1 Y H H M H L Y H H L M L Y L H H H M N H H L L M Y M H L L L Y L H L M M N L H M H L N H H H L M N L H M M L N L H L M L Y H H L H M N H H M M L Y L M M M L Y L M H L M N H L M H L Y M L H M M N L H M H M N H H H L M N H H M L H Y H L M H H Y H M L L H N H H M M H Y H H H H M Y M H L L Lproble ms [7,2], but the y have some difficult ie s wh ich e ffe ct o n t h e ir use fulne ss [11]. I n t h is pape r we pre se nt a modifie d proce dure which collect the use and avoid the abuse of algorithm presented in References 7 and 2.
Ba sic st e p s in da t a a n a lysis wh ich ca n be t ackle d e mploying t he rough se t approach are the following:
É
Characterization of set of objects in terms of attribute values;É
Finding dependenceies (total or partial) between attributes;É
Reduction of superfluous attributes (data);É
Decision rule generation.This theory offers simple algorithms to conduct t he a bo ve st e p s an d e na ble s st ra ight fo rwar d interpretation of obtained results.
The first step of the algorithm is to verify if any attribute can be eliminated by repetition or not. In this database no attribute is similar for all of t he sample s. but t here are some rows ( sample s
TABLE 3. Resultant Decision Table.
Attributes
Decision
A
5A
4A
3A
2A
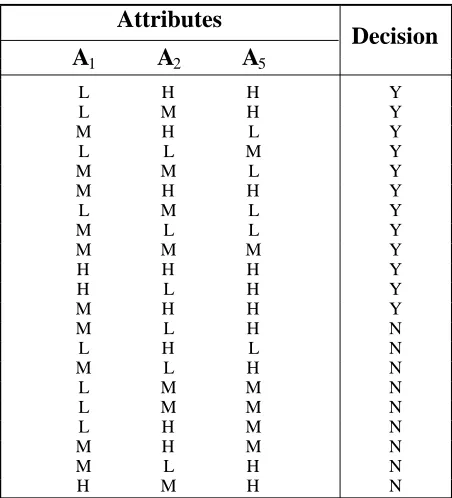
1 Y H H M H L Y H H L M L Y L H H H M Y M H L L L Y L H L M M Y H H L H M Y L M M M L Y L M H L M Y M L H M M Y H L M H H Y H M L L M Y H H H H M N H H L L M N L H M H L N H H H L M N L H M M L N M H L M L N M H M M L N M L M H L N M H M H M N H H M L M N H H M M Ho r o bje ct s) which a re ide nt ical, fo r e xa mple rows 5 and 24, 8 and 18. then resultant table has been shown in Table 3.
The next step is to verify if the decision table contains only indispensable attributes. This task can be acco mplishe d e liminat ing st e p by st e p each attribute and verifying if the table gives the correct classification. For this aim, we must examine all of the samples whithout considering on e of t he at t ribu t e s and find out whe t he r or no t t he de cision re sult chan ge s a nd con t in ue t his me t hod for all ot he r at t ribut e s. U sing t his algorit hm whe n t he at t ribute A1is e liminat e d,
we can verify that the rows 5 and 17 in Table 2 have the same entries but their decision results a r e d i f f e r e n t , s o t h e a t t r i b u t e A1 i s
indispe nsable . Afte r following t his st e p for all four other attributes, we can realize that eliminating attribute A2, the rows 1 and 18 have
the same difficulty. Hence, A2in not dispensable,
t oo. But if t he at t ribut e s A3and A4have be e n
TABLE 4. Decision Table with Indispensable Attributes.
Attributes
Decision
A
5A
2A
1Y H
H L
Y H
M L
Y L
H M
Y M
L L
Y L
M M
Y H
H M
Y L
M L
Y L
L M
Y M
M M
Y H
H H
Y H
L H
Y H
H M
N H
L M
N L
H L
N H
L M
N M
M L
N M
M L
N M
H L
N M
H M
N H
L M
N H
M H
dispe nsable and can be re move d. F inally, if t he Attribute A5 has been eliminated then the rows
1 a n d 14 h a ve t h e sa me se t o f e n t r ie s b u t different results. Table 4 presents this resultant set of objects.
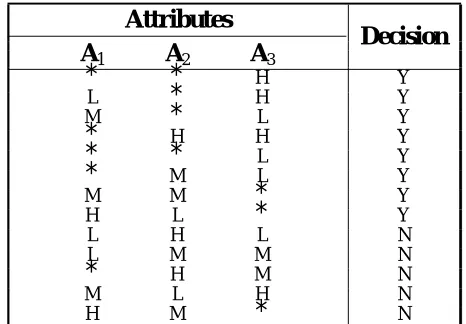
Now, we can apply re duct ion me chanism t o de cre ase t he size of lat t e r dat abase . U sing this approach the Table 5 has heen resulted and we can co mpu t e t he co r e o f t he se t o f samp le s. This computation can be done eliminating each a t t r ib u t e st e p by st e p , a n d ve r ifyin g if t h e de cisio n t a b le co n t in u e s t o be co n sist e n t . A p p lyin g t h is p r o ce du r e fo r o bje ct 1, fo r instance , we can se e t hat e liminat ing at t ribut e A1 pre se rve s consist e ncy in t he t able , and so
does it for attribute A2, but not for attribute A3
(e liminat ing this attribute results inconsist ence between rows 1 and 13). The results of applying t his proce dure for e ach obje ct s of Table 4 has be e n r e p r e se n t e d in T a ble 6. T h is da t a ba se sh ows t he co re of de cision t a ble a nd Table 7 contains the reduct of each object.
A cco r din g t o t h e la t t e r t a ble , kno wle dge existent in the Table 1 can be expressed by the following rules:
{
( A3 is H ) o r ( A3 is H a n d A1 is L ) o rIf
TABLE 5. Decision Table with Reduced Objects.
Attributes
Decision
A
5A
2A
1Y H
H L
Y H
M L
Y L
H M
Y M
L L
Y L
M M
Y H
H M
Y L
M L
Y L
L M
Y M
M M
Y H
H H
Y H
L H
N L
H L
N M
M L
N M
H L
N M
H M
N H
L M
N H
M H
( A1 is M a n d A3 is L ) o r ( A2 is H a n d A3 is
H) or (A3 is L) or (A2 is M and A3is L) or (A1
is M a n d A2 is M ) o r ( A1 is H a n d A2 is
L)
}
(Decision is Y) then
{
(A1is L and A2 is H and A3 is L) or (A1isIf
L and A2 is M and A3is M) or (A2 is H and A3
i s M ) o r ( A1 is M a n d A2 i s L a n d A3
is H) or (A1 is H and A2 is M)
}
(Decision is N) then
a n d u sin g lo gical a r it h me t ic we ca n e xpr e ss these rules by:
{
(A3is H) or (A3is L) or (A1is M and A2isIf
M) or (A1 is H and A2 is L)
}
(Decision is Y) then
( A2 is H ) a n d
[
( A1 is L a n d A3 is L ) o rIf
(A3is M)
]
or (A2 is M)a nd
[
( A1is L a nd A3 is M ) o r ( A1is H )]
o r(A1 is M and A2 is L and A3is H)
(Decision is N) then
which shows t he e xplicit and e sse nt ial rules for decision making.
TABLE 6. Core of Database.
Attributes
Decision
A
5A
2A
1Y H
__ __
Y H
__ L
Y L
__ M
Y H
H __
Y L
__ __
Y H
H __
Y L
M __
Y L
__ M
Y __
M M
Y H
H __
Y __
L H
N L
H L
N M
M L
N M
H __
N M
H __
N H
L M
N __
M H
6. CONCLUSION
Knowle dge base is on e o f t he most impor t ant p a r t s o f in t e llige n t syst e ms wh ich co n t a in s informat ion and expe rt ne ss of espe cialist s. The knowle dge acquisit ion me chanism is t he most d iff icu lt t a sk d u r i n g t h e co n st r u ct io n o f information system.
R ough se t t he ory pre se nt s a me t ho d which applying it we can e xt r act t he main asp e ct s of in fo r m a t io n a n d e sse n t ia l d a t a , u sin g t h e not ions of grone lling of unive rse of discourse , core and reduct of data base.
In this paper a systematic approach has been p r o p e r se d b a se d o n R o u gh Se t T h e o r y t o t rarsform vague dat a in a re duce d se t of rule s. T h is me t h o d h a s be e n ba se d o n t h e lo gica l concepts and uses arithmetic tools to reduce the siz e o f d a t a b a se a n d r e su l t s i n co r e o f knowledge.
7. REFERENCES
1. Skoworn, A. and C. Rauszer; "The Discernibility Matrices and Functions in Information System", Decision Support by Experience, Kluwer Academic Publishers, (1992), 331-362.
2. Modrzejewski, M, "Feature Selection Using Rough Sets Theory", Machine Learning: ECML-93, Springer Verlag, Berlin, (1993), 213-226.
3. Nowicki, R., Slowinski, R. and Stefanowski, J.,
TABLE 7. Reduct of the Database.
Attributes
Decision
A
3A
2A
1Y H
*
*
Y H
*
L
Y L
*
M
Y H
H
*
Y L
*
*
Y L
M
*
Y
*
M M
Y
*
L H
N L
H L
N M
M L
N M
H
*
N H
L M
N
*
M H
"Evaluation of Vibroacoustic Diagnostic Symptoms by Means of the Rough Sets Theory", Computers in Industry, Vol. 20, No. 2, (Aug. 1992), 141-152. 4. Walczak, B. and Massart, D. L., "Rough Sets Theory",
Chemometrics and Intelligent Laboratory Systems, Vol. 47, No. 1, (Apr. 1999), 1-16.
5. Pawlack, Z., "Hard and Soft Sets in Rough Sets, Fuzzy sets and Knowledge Discovery", Ed. W. P. Ziarko, Springer-Verlag, Berlin, (1994), 130-135.
6. Skowron, A. and Grzymala-Busse, J., "From Rough Set Theory to Evidence Theory", In advances in the Dampster-Shafer Theory of Evidence, John Wiley and Sons, N.Y., (1994), 193-235, 251-271.
7. Krusinska, E., et al., "Discriminant Versus Rough Set
Ò
Approach to Vague Data Analysis",Journal of Applied Statistics and Data Analysis, Vol. 8, (1992), 43-56. 8. Pawlak, Z., "Rough Sets, Theoritical Aspects ofReasoning about Data", Kluwer Academic Publishers, London, (1992).
9. Munakata, T., "Rough Control: A Perspective", Proc. of 23rd Annual CSC, California, (1995), 431-438.
10. Lambert-Torres, G., et al, "Classification of Power System Operation Point Using Rough Set Techniques",
Proc. of Canadian Conf. on Elec. and Comp. Eng., Calgary, (1996), 1898-1903.
11. Szladow, A. and Ziarko, W., "Rough Sets: Working with Imperfect Data", AI Expert, Vol. 8, (1993), 36-41. 12. Grzymala-Busse, J., "Rough Sets, Advances in Imaging and Electron Physics",J. of Image Proccessing, (1996), 88-96.
13. Pawlak, Z., "Rough Sets", International Journal of Computer and Information Science, Vol. 11, (1982), 341-356.