Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2800
Study on Cleaning and Pre-Processing Of Large Scale Mobile Data
DEEPAK S/0 SAMPATH KUMAR
RESEARCH SCHOLAR DEPARTMENT OF COMPUTER SCIENCE OPJS UNIVERSITY CHURU
DR.YESPAL
DEPARTMENT OF COMPUTER SCIENCE OPJS UNIVERSITY CHURU
ABSTRACT
In this paper Crowdsensing for brilliant devices depends on automatized data gathering forms. Consequently, there is a probability for unsuccessful readings and blunders, for instance, in the event that the gadget itself is in an inadequate state, or the producer or system administrator limits gets to specific factors. A decent case of this sort of conduct can be seen when Apple shut access to the rundown of running procedures from outsider engineers on the IOS variant. The activity framework Sailfish in the Jolla phones is professed to help likewise Android applications with an emulator, yet in all actuality, the vast majority of the sensor readings however the emulator were unsuccessful. Rather than intelligible qualities, makers and system administrators may give distinctive default esteems, substitutions, or void fields. What's more, there is dependably a danger of programming bugs particularly in self-sufficient procedures.
I. INTRODUCTION
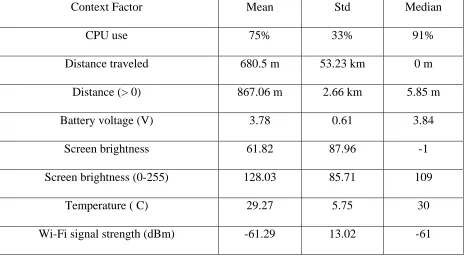
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2801 Table 1: Summary statistics of selected context factors previously published
Context Factor Mean Std Median
CPU use 75% 33% 91%
Distance traveled 680.5 m 53.23 km 0 m
Distance (> 0) 867.06 m 2.66 km 5.85 m
Battery voltage (V) 3.78 0.61 3.84
Screen brightness 61.82 87.96 -1
Screen brightness (0-255) 128.03 85.71 109
Temperature ( C) 29.27 5.75 30
Wi-Fi signal strength (dBm) -61.29 13.02 -61
II. NOMINAL AND ORDINAL ATTRIBUTES
Setting factors comprise of both ostensible and ordinal attributes. For ostensible factors we utilize the distinctive conceivable qualities as the classes, for example, organize type that shows data of Wi-Fi or mobile, and applications accompany their procedure names along other data, for example, the comprehensible name and data whether they are running foundation or closer view. The greater part of the setting factors, for example, screen splendor, battery temperature, and CPU utilize, are ordinal-esteemed. Overseeing distinctive data composes in the meantime requires preprocessing, for instance, discretization of the ordinal-esteemed factors.
Another test is set as a matter of course and missing qualities, that may appear to be dark, for instance, expansive negative qualities when thought about missing battery temperature or screen brilliance gave out of ordinary setting range. Some setting factors accompany conceivable figuring botches, for instance, separate went between two examples may appear to be thousand of kilo-meters in light of missing or default an incentive in the area data of another example.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2802 is partitioned into classifications containing
roughly a similar number of qualities. The quantity of classifications is resolved observationally and in light of perceptions detailed in past investigations identified with the field. Rundown measurements of chose setting factors are given in Table 4.1 and the diverse classes are next examined together with depictions of each factor.
III. USER CHANGEABLE SYSTEM SETTINGS
Framework settings are gathered by means of the Android programming interface. Distinctively, they are noticeable to the client by means of framework setting menus and the client has authority over them. This additionally sets the fundamental test for overseeing framework settings: there are no evidences that clients have balanced them
shrewdly. In the meantime, framework settings out of sensible range can without much of a stretch be considered as defaults, misreadings, or mistakes, since clients can just control them inside the permitted ranges.
IV. SUBSYSTEM VARIABLES
Subsystem factors are not specifically accessible as a client modifiable framework setting, however can give data about the condition of the cell phone. For instance, on the off chance that we see a diminished Wi-Fi connect speed or flag quality, we can prescribe that the client endeavor to utilize the mobile system rather than Wi-Fi in this unique situation. In the energy analysis, these factors give essential bits of knowledge into what occurs inside the cell phone.
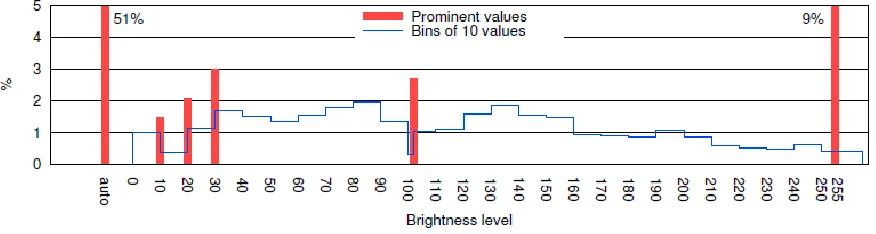
Figure 1: The frequency of all screen brightness settings
Misreadings, defaults, and missing data focuses set the most essential test while
overseeing and examining subsystem
factors. In any event, they should originate from a sensible range and match the given Android API portrayal. Since producers may set their very own defaults, missing
qualities or unsuccessful readings, for
instance, it isn't straightforward to
characterize "great" values.
V. ENERGY MEASUREMENTS
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2803 research field. To quantify the energy
consumption of the gadget, we consider timestamps and battery levels detailed via
Carat and create energy rates. These reffect standardized energy consumption per time unit, all the more formally characterized as:
Energy rate =∆ 𝑏𝑎𝑡𝑡𝑒𝑟𝑦𝑙𝑒𝑣𝑒𝑙
1 ∆𝑡𝑖𝑚𝑒 (4.1)
The methodology used to derive rates and the validity of using energy rates as a measurement for battery consumption has been validated and presented in previous work by Oliner et al. [6].
The energy rate distribution coarsely follows power distance: fewer rates of high
energy consumption, in other words, only hours of total battery life, and most of them indicating discharge level considerable normal. We compare discharge rates routinely as consumption per second, but they can also be interpreted to more human-readable format, as hours of battery life in the given system state, as follows:
ℎ =
100 𝑟𝑎𝑡𝑒
3600
(4.2)
The difference between two different system states can thus be denoted as battery life gain. It measures how changes in context factors influence the lifetime of a device on average. We usually give the battery life gain as percentages compared to the average, but also actual hours of battery lifetime left in the given combination of context factors might be considered.
VI. DETECTING COUNTRY
All the useful information is not possible to read directly from the Android API, but is derived from other collected factors. To protect user privacy, the Carat system does not gather any location information. Instead, Carat collects different attributes about the network usage, especially Mobile Country Code (MCC) as well as the current timezone. In our work, we propose a method to detect the country of the user
without exact location information, but only using the MCC and timezone attributes.
A mobile country code (MCC) is a three-digit value tied to a mobile network. Each MCC corresponds to a single two-letter IANA country code3. Unfortunately, the MCC is not available on Wi-Fi-only devices, such as tablets, and some CDMA networks. From the beginning of March 2016 until May 2017, the Carat dataset has 5.65 million samples with valid MCCs.
There are 69:7 million samples with the timezone information available in the Carat dataset. The Android devices follow the IANA timezone database format and give the timezones presented as the continent and
the closest big city, for example,
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2804 two-letter country codes (later referred to as
CC) similar to the MCC codes.
VII. DATA PRE-PREPARING
Data pre-preparing is essential in
Crowdsensing process. Certain data cleaning techniques more often than not was be not appropriate to a wide range of data. Duplication and data linkage are imperative tasks in the pre-preparing advance for some, Crowdsensing ventures. It is imperative to enhance data quality before data is stacked into data warehouse. Finding surmised copies in vast databases is an essential piece of data management and assumes a basic job in the data cleaning process. In this examination wok, a system is intended to clean copy data for enhancing data quality and furthermore to help any subject arranged data.
VIII. DATA CLEANING
This was comprise of applying this system on educated (like finish content records) and semi-organized data. The proposed system is relevant for social arranged data. The calculations proposed in this proposition for
choosing attributes, shaping tokens,
blocking records, record coordinating and disposing of copies are utilized for social
data warehouses. In future, extra
enhancements to area free quality
determination calculation, token
arrangement calculation, record blocking calculation, record coordinating calculation, and govern based copy identification and disposal approach was be investigated.
IX. OBJECTIVE OF THE STUDY
1. To examine the distinctive kinds of
exception recognition methods,
discordancy and marking.
2. To think about the vigorous relapse strategy for recognizing the outliers in multivariate data sets. These outcomes are contrasted and diverse separation measures for finding the exposing outliers.
3. To think about the data mining procedure of a few Nearest-Neighbor based exception identification and statistical based anomaly location methods are figured and contrasted and the execution outliers.
4. To consider the identification of outliers in time arrangement ARIMA displays have been utilized for ozone dataset.
X. RESEARCH METHODOLOGY
Machine learning calculations and
measurable tests are urgent to comprehend interdependencies and connections in the crowdsensed data. To produce real an incentive out of the examination yield, we need to consider how these outcomes are displayed in a comprehensible, justifiable and noteworthy way. The points of
expansive scale crowdsensed data
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2805 indicating supportive perceptions in view of
the data.
In the nonstop sensing procedure, better utilization proposals on the gadget side would likewise create back to the data and its investigation procedure. This wonder can
be known as the ceaseless criticism circle. Figure 1 presents a case of the persistent criticism circle, where data gathered from a crowd of mobile devices is assessed in the cloud back-end, and learning yield is sent back to the devices as proposals and input
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2806 Figure 1: Research questions and their matching publications along with the methodology
used
XI. RESULT
Mobile use reffects geographic,
demographic, and cultural limits and in the meantime, it can't be really clarified just by those societal and cultural factors. We propose mobile utilization as a novel societal factor to consider in future examinations that apply keen devices around the world.
XI. CONCLUSION
This proposition has displayed approaches to identify and take out copies in the data warehouse. Generally speaking, the work displayed in this proposition contributes
techniques prompting best in class
performance on the effective identification and end of copies and gives various valuable calculations for professionals in property choice, token based methodology, blocking records and govern based methodology for
copy location and disposal. This
examination exhibits the intensity of utilizing token based cleaning strategy to expand the speed of the data cleaning process. This examination work was inspire additionally explore in copy identification and disposal, and also support utilizing token based cleaning approach in different applications where separate gauges between occasions are required.
REFERENCES
1) Jianxiong Wang Tom Down “Tuning
Pattern Classifier Parameters Using A Genetic Algorithm With An Application In Mobile Robotics”, IEEE, 2013.
2) Tara Chand, Educational
Technology, New Delhi: Anmol Publication, 1990, pp. 1-2.
3) Jagannath Mohanty, Educational
Technology, New Delhi: Deep and Deep Publication, 1992, pp. 1-3.
4) C. Das, Education Technology,
NCERT New Delhi : Sterling Publication, 1993, pp. pp. 1-2.
5) B. D. Bhatt, and Prakash, Ravi,
Modern Encyclopeadia of Education Technology, New Delhi : Kanishka Publication, 1994, pp. 1-2.
6) K. C. Panda, and Guatam, J.N, Info Technology on the Cross road, New Delhi : Y.K. Publication. 1999, pp. 2-3.
7) S.K. Bansal, Information
Technology and Globalisation, New Delhi : APH Publication, 2001, pp. 1-3.
8) Nanda Kishore, Educational
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2807
9) V.K. Roa, Educational Technology,
New Delhi : Surya Publication , 2004, pp. 1-3.
10) Arun Babeja, Information
Technology, New Delhi : Isha book publication, 2009, pp. 1-3.
11) Marmar Mukhopadhyay,
Educational Technology, New Delhi : Shipra publication, 2008, pp. 1-3.
12) J. C. Agarwal, Educational
Technology and Management,
Meerut : Surya Publication, 2009, pp. 2-3.
13) Sharpies, M., Taylor, J., & Vavoula, Op.cit
14) L Naismith, et al, Literature review in mobile technologies and learning, London: Future Lab, 2004, p.37-39.
15) Catherine Fosnot Twomey, "Media and Technology in Education/1 , ECTJ, vol No.32.No.4,1984,pp. 195-205.
16) Robert Kozama B, “Will Media
i8nfluence learning”, Michigan, vol. No. 42, 1994, 00. 7-19.
17) Leidner Dorathy and S L Jarvenpaa, “The Use of Information and Technology to enhance Management School Education”, Mis Quaterly, Vol. 19. No. 3, 1995, pp. 265-288.