Effective Searching of Annotations in Web for
Composite Text using SVM
Pallavi Dutta Mr. Amit Saxena Dr. Manish Manoria
Scholar Associate Professor Professor
Dept. of Computer Science & Engg. Dept of Computer Science & Engg. Dept of Computer Science & Engg Truba Institute of Engg. & I.T. Truba Institute of Engg. & I.T Truba Institute of Engg. & I.T
Bhopal (M.P.) Bhopal , India Bhopal, India
Abstract— The projected attitude implemented at this time using learning approach such as SVM based clustering and classification of investigate records is compared with existing style implemented for the search records. The Result Analysis shows the performance of the future methodology.
The proposed methodology shows higher precision and recall as well as has high Accuracy for the prediction of annotated look for proceedings from the web databases.
I.INTRODUCTION
Formerly with the growth of web-based resources, including an explosion of user-generated content, has come parallel growth of research into web-based penetrating performance and forager experiences. Also simultaneous with improvements into web technologies and relevance ranking algorithms, search engines have achieved a towering level of trust and a discernment of the rummage around engine’s odd interior machinery that verges on clairvoyance: basically type in a stream of consciousness and the oracle-like search engine responds with a useful answer. After pressing search button, scan the results list, and select a few from the first page or two of results. However, this simplistic perspective may be contributing to a lack of sympathetic of the information environment, leaving students in a world of possible impediments to searching, without an understanding of ways to improve the process.
The Web has become the preferred medium for many database forms and usages use dto store information. Database-driven Web sites have their possess interface and right of admission forms for creating HTML pages on the soar. Web file technology describe the method that these forms can connect to and retrieve data from database servers.[2] The figure of database-driven Websites is rising and they fix not energy enquiries to Web databases. World Wide Web has caused in a huge quantity of material sources on the Internet. Web evidence springs, admittance to this enormous group of in order have been imperfect to browsing and searching.
Automatic Annotation
A widespread feature of habitual web semantic footnote is the make use of of ontologies to name proper semantics. Ontology be a formal, overt plan of a conceptualization [3]. Here are essentially two conducts to automatically annotate web data. One technique is to routinely cutting metadata and interpret grid leaves by means of the extracted metadata. This draw near faces the long-time complicated predicament of ontology making, and, and so,
especially few researchers achieve footnote effort in this approach One commissioner pattern of this type of annotation is SCORE (Semantic Content Organization and Retrieval Engine) [4]. Their experiments demonstrate so as to the system can achieve as high as near 90% accuracy for extracting correct metadata base resting on the Reuters-21578 text categorization dataset using as few as 320 training documents.
Automatic Annotation Approaches
Competence of penetrating and update in order increases by position and footnote of figures. Alignment of data can be referred to as arranging the data in such a way that data confidential the similar collection have the similar sense and accessing. He is a practice for addition material to a text sequencnces such as article. Data annotation [5] enables fast retrieval of information in the deep web.
Figure 1.Phases of automatic annotation solution [5]
Figure 2. Extracts (automatically) text from a web-page into a table [5]
Data unit and text node relationships:
1-to-1 Relationship: (mentioned as atomic text nodes). Manuscript node contains lone unique data component 1-to-Many Relationship: (referred as composite text nodes) a text node consists of multiple data units i.e. multiple data units are encodes into single text nodes. Many-to-One Relationship: (mentioned as decorative tags) manifold manuscript bulges are prearranged into single data component. This kind of manuscript bulges is mentioned as ornamental tags since they are secondhand for varying the entrance of portion of the transcript lump.
1-To-Nothing Relationship: (mentioned as template text nodes) Manuscript nodes are not fragment of one figures unit private SRRs. This affiliation for writing swellings and data pieces are denotes the relative in sandwiched amongst them.
There are five mutual structures communal by the statistics components Statistics content Presentation elegance Facts type Label trail Adjacency.
Data content [6]: Statistics unit or manuscript node of identical thought dividends positive keywords which are cast-off to pursuit the material fast. For e.g., keyword “machine” will return the information that are relevant to word machines.
Presentation style: Presentation feature describes how a data unit is displayed on a web.
Data alignment and labeling [6]: Current tasks when compared with automatic annotation approach. They are based on one or a few facilities. Automatic annotation alignment approach first data units and handles relations between text nodes and data unit do use variety of features the device is a cluster-based transfer algorithm and is used in the alignment process. Label assignment IIS (unified interface schema) and LIS (local interface schema). There are attributes in all LIS IIS and thus eliminates inadequacy and inconsistent labels label problems. In the coalition of some basic annotators groups started to annotate and combine multiple annotators a probability model is used for the results of this approach are called multiple-annotator approach.
Consider a set of SRRs that are extracted from a result page returned from the web database. The Automatic annotation approach has three major phases as shown in the [7].
Alignment phase [6]: Chief statistics arrangement phase in the SRRs components recognized and prearranged into dissimilar collections for all group agrees to a dissimilar idea (for example, all names of records are gathered composed). Number 1b crossways all SRRs stage 1 each column containing data unit with sane sense results. This step is to identify the patterns and features of data between units are used.
Annotation phase [6]: Annotation phase each with many basic annotators features one type of exploitation. Every annotator groups organized within data units of a label that is used to determine the most suitable probability models a used to label. Figure 1 shows the results of step 2 c where a meaning with each group assigned labels l.
Annotation wrapper generation [6]: Annotation wrapper generation phase one annotation rules for each identified entity or concept RJ has generated the data unit description, how to remove and what means should be labeled and collectively cover a cover forms a new queries for data retrieved from the Web database units are used to annotate and thus annotations quickly.
II.LITERATURE SURVEY
In this newspaper writer consumes [8] old-style hunt trains shadow relatives to the directory sheet on a place and then skulk from there to other sheets by following relatives. Hunt train sycophants will consequently have additional problems sighted a side that is not related to after any other page (unseen web sides).
Annotea [7] a collaborative client server system document annotation is a special they are stored on the server in such a way that anyone who has access to an annotation server for a given document to consult all related annotation and add your own annotations will be enabled for these annotations are divided into typing comments Improve projections, assumptions. This system was developed using W3C standards. Yet, only possible Committee on State annotation text; It is annotated by a picture or symbol. EXCOM [7] is an gloss locomotive internal/external glossing a text by a group of hay gen on aim uses a set of language plans. This engine is underneath growth, and at the contemporary period, a intergalactic levels and queries lets the manufacture of an spoken, since this skill is not entirely
Here in this paper author has proposed a new method [9] Acacia team allows annotation system developed by genes. Only few of them focus on the events annotation. Here in this paper they present, in the following, some of these works: The annotation of temporal information in texts [9]: The authors of this work tested the feasibility of this procedure on newswire articles with promising results. Before, they industrialized dual assessment events of the footnote: excellence and steadiness.
Annotating texts [10] features and relationships to determine the relative annotation scheme: This enables order and, if possible, absolute time events. A planning an annotated corpus can be used for building the corpus is usually producing such benefits associated with building resources. It also can be used to better understand the phenomena. Plus it training and adaptive algorithms for evaluating represents a source. It automatically shows the relationship of the features and interest. However, we observed that the relationship between the incidences of this work to determine based on temporal markers only. There are inherent differences with regard to events without using temporal markers which are accurate.
SyDoM [10] is a semantic footnote of Mesh sheets scheme. This allows the enrichment of these sheets so that they income explanation of their script deprived of linguistic find it with textual XML format is dedicated to manage documents stored [10].
their work in 2009, they collected and evaluated the state of the art in this field and published their final report in [11]. This survey showed several approaches – from a complete transformation of an existing relational database to an RDF database on one side, to on-demand mapping and query translations from SPARQL to SQL on the other side. When publishing data that has to be maintained and updated over time, it is impractical to have to publish the same information twice – once for humans and a second time for tools, especially if content is also provided by users of the site. In this case, it is not just a single effort when initially publishing the data, but results in consequently having to update and maintain two separate pieces of work. A practical and easy way to integrate semantic information into an existing document is to use annotations. A first solution for this was proposed by [11] who described the concept of miroformats. These are small sets of semantic data that can be embedded in a webpage, invisible to the user but visible for tools and search engines. By using this data, structured information about things like authorship or even cooking recipes can be given that can be extracted from the page. But these formats have to be agreed on by the community in order to understand the structure and the content.
III.PROPOSED METHODOLOGY
The alignment algorithm implemented here is for composite text nodes and other tags available in the HTML tags.
1. Merge Text nodes: Here detection and removal of the decorative tags can be identified to merge them into single text nodes or into multiple text nodes.
2. Align Text nodes: Here the HTML tags which
contain some meaningful labels can be aligned so that it can be used for efficient searching.
3. Split Text nodes: The multiple text nodes or the HTML tags containing composite nodes can be split here to provides and generate multiple search results.
4. Align Data units: The step is carried out for the separation of composite groups into multiple aligned groups.
The proposed methodology implemented here uses the following Alignment algorithm for the single or multiple text nodes and then uses SVM based clustering to cluster the similar text nodes which provide same set of search results from the HTML tags.
1. J 1
2. While true (means all the available text nodes from HTML tags provides labels)
3. For i 1 to number of search records 4. Gi SR[i][j]
5. If Gi contains empty labels
6. Exit
7. V Call_Cluster(G) 8. If |V| > 1
9. S=Call_Merge(SR[i][j]) 10. V[c]=Call_Similar_Cluster(V,S) 11. Shifting of SR and V.
Call_Cluster(G)
1. Input G contains all the search records along with the labels for each text node in the search record. 2. Repeat till G[i][j]==null
3. For each A in G and B in G
4. Compute Similarity(A,B) in G using
Sim(A,B)= precence(AUB)/
precence(A)+precence(B)- precence(AnB)
5. Best Sim(A,B)
6. Remove text node from L
7. Remove text node from Right R
8. Add LUR to V
9. Return V;
Call_Merge(SR)
1. Repeat till SR empty 2. For i=1,j=1 length (G) 3. S[i][j] SR[i][j]
4. Return S;
Call_Similar_Cluster(V,S)
1. Repeat till V empty || S empty
2. Sim(V,S) = Sim(VUS) / Sim(V) +Sim(S) –
Sim(VnS)
3. Check the minimum value for the cluster
4. V[c]=min (Sim(V,S)
5. Return V;
IV.RESULT ANALYSIS
The Experimental results are based on 90 Web Databases which are taken from web selected from various domains such as Games, electronic, auto, book, movie, music and Job. From the 90 Web Database from various domains it is divided into parts one contains training of 60 WDB and other contains testing WDB of 30 sites.
The dataset taken here in training and testing should be such that 60 WDB contains sites from every domain and same in case for testing WDB.
Domain Precision Recall F-Score Auto 92.56 91.37 91.961
Book 92.4 92.39 92.395
Electronics 94.29 95.23 94.758
Job 93.91 92.38 93.139
Movie 91.02 93.67 92.326
Music 95.78 94.39 95.08
Game 95.29 95.49 95.39
Table 1. Analysis of Existing Technique on WDB
result is analyzed on the basis of Precision and Recall and F-Score. Here Precision can be computed on the basis of correctly identified annotations to the total number of annotations fetched from the web databases. Recall is the computation of total number of annotations fetch from the web databases to the total number of annotated records present.
Domain Precision Recall F-Score Auto 96.45 95.93 96.189
Book 97.45 94.73 96.071
Electronics 96.19 94.83 95.505
Job 95.38 95.67 95.525
Movie 94.34 97.38 95.836
Music 97.39 95.38 96.375
Game 96.34 94.19 95.253
Table 2. Analysis of Proposed Technique on WDB
The figure shown below is the experimental analysis and comparison of Precision based on Existing and Proposed work. The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. Here Precision can be computed on the basis of correctly identified annotations to the total number of annotations fetched from the web databases.
Figure 3. Comparison Analysis of Precision on various domains
The figure shown below is the experimental analysis and comparison of Recall based on Existing and Proposed work. The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. Recall is the computation of total number of annotations fetch from the web databases to the total number of annotated records present.
Figure 4. Comparison Analysis of Recall on various domains
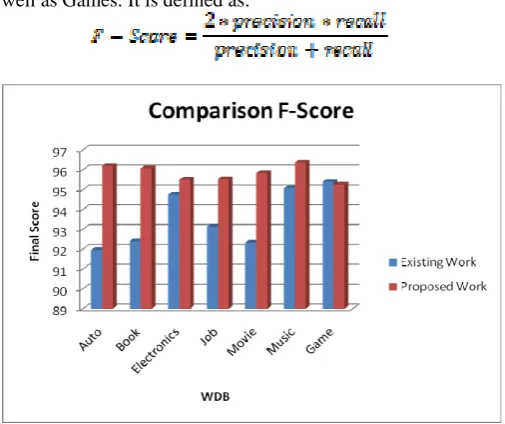
The figure shown below in 5.3 is the experimental analysis and comparison of F-Score based on Existing and Proposed work. The result is analyzed on various domains such as Book and Pen Drives and Music and Movies as well as Games. It is defined as:
Figure 5. Comparison Analysis of Final Score on various domains
V.CONCLUSION
The proposed methodology implemented here for the searching of the annotations from the web databases. Here the annotations can be identified on the various categories such as Book, Movies, Electronics, Pen Drives, Auto. The proposed methodology is applied on the these categories with different web pages and hence on the basis of search web records labels are assigned to these web pages After identification of annotations in the web databases accuracy can be computed and compared to the existing technique that is implemented for the efficient search of records from the web databases and the proposed methodology provides high precision and recall as compared to the existing technique.
REFERENCES
[1] Y. Lu, H. He, H. Zhao, W. Meng, C. Yu, “Annotating Search Result From Web databases” In IEEE Transaction on Knowledge and Data Engineering, Vol. 25, No.3, 2013.
[2] Y. Lu, H. He, H. Zhao, W. Meng, and C. Yu, “Annotating Structured Data of the Deep Web,” Proc. IEEE 23rd Int’l Conf. Data Eng. (ICDE), 2007.
[3] Tom R. Gruber. A Translation Approach to Portable Ontologies.
Knowledge Acquisition, 5(2):199-220, 1993.
[4] Amit Sheth, Clemens Bertram, David Avant, Brian Hammond, Krysztof Kochut, and Yashodhan Warke. Managing Semantic Content for the Web. IEEE Internet Computing, 6(4):80-87, July/August 2002.
[5] Priyanka P.Boraste “A Survey on Data Annotation for the Web Databases “ IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- e-ISSN: 2278-8727Volume 16, Issue 2, Ver. XI (Mar-Apr. 2014)
[7] J. Kahan, M-R. Koivunen, Annotea: an open RDF infrastructure for shared Web annotations. Proceedings of the 10th international conference on World Wide Web, 2001.
[8] L. Gravano, H. Garcia-Molina, A. Tomasic, "GlOSS: Text-Source Discovery over Internet", TODS 24(2), 1999.
[9] K. Khelif, R. Dieng-Kuntz, P. Barbry, An Ontology-based Approach to Support Text Mining and Information Retrieval in the Bio logical Domain, in J. UCS 13(12), pp. 1881-1907, 2007 [10] A. Setzer, R. Gaizauskas, TimeM L: Robust specification of
event and temporal expressions in text. In The second international conference on language resources and evaluation, 2000
[11] C. Roussey, S. Calabretto, An experiment using Conceptual Graph Structure for a Multilingual Information System, in the 13th International Conference on Conceptual Structures, ICCS'2005 [12] A Survey of Current Approaches for Mapping of Relational
Databases to RDF. Retrieved October 28, 2011 from www.w3.org/2005/Incubator/
rdb2rdf/RDB2RDF_SurveyReport.pdf, 2005
![Figure 1.Phases of automatic annotation solution [5]](https://thumb-us.123doks.com/thumbv2/123dok_us/7861609.1304069/1.595.313.544.576.656/figure-phases-of-automatic-annotation-solution.webp)