2017 2nd International Conference on Wireless Communication and Network Engineering (WCNE 2017) ISBN: 978-1-60595-531-5
A Package Recommendation Model Based on Credit and Time
Jing-jie ZHU
1, Ling-ling SHEN
1,2,*, Huai-gang WU
1,
Ting YUAN
1and Gang QIAN
31
School of Computer Science and Technology, NanJing Normal University,China 2
School of Business, NanJing Normal University,China 3
School of Government Audit,NanJing Audit University,China
*Corresponding author
Keywords: Package recommendation, Diversity, Credit, Time weight.
Abstract. Nowadays, reading has become increasingly important for people who want acquire knowledge for a better life all around the world. As a result, book recommendation systems are useful to these readers. However, many readers are confused about how to choose right books for themselves. In this paper we propose a model to recommend a set of book packages to readers, where each package contains different categories of books. Our Packages consider users’ credit, the popularity of books, intra-package diversity, and user preference which may change over time. Experimental results suggest that our method presents improvement on recommendation accuracy and diversity.
Introduction
Many readers are confused about how to choose suitable books for themselves. For example, some of them choose books appearing on the top-ranking lists. Some choose their favorite authors’ works or select books recommended by their friends. Their ways of choosing books are less accurate. In this paper, we propose an approach to recommend a set of book packages, where each package contains several different categories of books, e.g., fiction, literature, science, etc. As our goal is to recommend book packages to people that best suit them, so the selection of books in packages is determined by a set of factors including users’ credit, the popularity of books, intra-package diversity, and user preference which may change over time. [1] suggests that the popularity of items can improve the relevance of the recommended packages. However, some publishers may employ service to forge fake popularity of their books. Thus, we will consider user credit to reduce the possibility of counterfeiting popularity. What’s more, it has been proved that diversity can reflect users’ complete spectrum of interests [14]. In addition, the constraint in this paper is the money a user has for books in one purchase. The evaluation of our approach using data from DouBan, shows our approach can improve the diversity and accuracy of recommendations.
The rest of the paper is organized as follows: first, we review the related work in Section2. Then we formulate the recommendation problem into a constrained optimization problem. Furthermore, we calculate the popularity of books, intra-package diversity and user preference, and combine them into a package score. After that, we use an algorithm to generate top-k packages. Then we evaluate our approach using data from Douban. Finally, we conclude the paper.
Problem Formulation
Given a set B of books, a set U of users, an active user u ∈ U and a book i ∈ B. We denote the price of the book i as p(i). Given a set of books P∈B , we define Score(P) the score of a package P, which estimates the quality of a package,
b P
P P b
∈
=
∑
p( ) ( )the price for a package P. Given a price budget
Given a set B of books, an creditable and active user u with his preferences background, a price budget Bp and an integer k, a top-k package recommendation system has to determine the top-k
packages P, P,1 2 …, Pk such that each Pi has p P
( )
i ≤ Bp , and among all valid packages,…
1 2 k
P, P, , P have the k highest scores, i.e Score P
( )
≤Score P( )
i for all valid packages1 2 k
P∉{ P , P ,…, P }.
The Similarity of Books
TheGeneral Similarity.Our distance between books is based on a taxonomy of hierarchical topic categories organized in a tree structure. Formally, we used a domain ontology developed by [15] to represent these categories. Let be B the set of all possible books. Each books in B is associated to one category in the taxonomy, e.g. literature, fiction, Social Science, science & technology, etc.
We define the topical distance di stt between two books i and j as the length of the path between the two categories of i and j in the taxonomy:
( )
(
)
t i j
dist i, j =p c , c . (1)
where c , ci j are the categories of books i, j and p is the path function. The topical similarity evaluates in which measure two books i and j deal with similar topics. The similarity depends on the topical distance between the two books i, j:
( )
( )
(
t)
sim i, j
dist i, j
= +
1
1 . (2)
Time-based Weight Function. In fact, user preference may change over time. Thus, we introduce time weight to reflect this change.We assume Iu as a item set that user u has visited. We define a time
window T to get the item set IuT that the user u has visited in the last T period. To some extent, the IuT
reflects the recent preference of user u. For any item i∈Iu, no matter when user u visit i, if more items
in IuT share higher similarity with i ,the items hat u will be interested in in a near future may still be
similar with i. Thus, we define the time-based weight function as follows:
uT I j
I j i sim
i u
f uT
∑
∈=
) , ( )
,
( . (3)
Where IuT are the number of items in IuT. We can obtain different item sets IuT user u have visited
recently by changing the length of the time window T, which affect the recommend quality.
The Revised Similarity Considering Time Weight.Taking into account that user preference changes over time, we combine time weight into the general similarity. The revised similarity is defined as:
time
sim(i, j) =f (u, i) sim(i, j)× .
(4)
Package Quality Score
recommended package with only literature. The diversity of books in the same package is thus an important factor for the quality of the package.
Popularity.The overall popularity measures the popularity of a book i ∈ B :
( )
( )
( )
[
]
j Bpop i
opop i ,
max∈ pop j
= ∈ 0 1 . (5)
where j designates the books of B and pop represents a popularity indicator of a book. By extension, the overall popularity of a package P is:
( )
P opop ii P( )
[
]
opop P ,
P
∈
= ∈ 0 1 . (6)
Intra-Package Diversity.Most of book recommendation systems focus on the modeling of user preferences in order to get a ranking of the most pertinent books. However, the diversity of suggestions has seldom been the focus point. Nevertheless, it has been suggested that the diversity has a large positive effect on the satisfaction of the user [16]. So, we adapt the intra list diversity introduced by [13] for a package of books P, we define the intra package diversity :
( )
(
2( )
)
1 sim i, j ipd P
P
−
= . (7)
Prediction.The prediction evaluates to what extent a book i that a user has not yet rated would be interesting. The prediction of a user u ∈U for a book i ∈I is calculated using item-item
collaborative filtering :
( )
( )
( )
( )
i
i
j S u
u
j S
time
time
rating j sim i, j Pre i
sim i, j
∈
∈
∑ ×
= ∑ . (8)
where j designates books of the sample Si , the set of similar books rated by the user u, and
u
rating → 0, 1 associates for a books the rating given by the user u, divided by the maximum rate. By extension, the prediction for a user u for a package P is defined by the mean of the prediction for books forming the package :
( )
i P u( )
[
]
uPre i
Pre P ,
P
∈
∑
= ∈ 0 1 . (9)
Score of a Package.The score of a package evaluates the quality of books that form a package for a user u according to the overall popularity, the diversity and the prediction. The score for a package P for a user u is calculated by:
u Pre u opop div
Score (P) =C ×Pre (P)+C ×opop(P)+C ×ipd(P) (10)
where
C
Pr e,
C
opop,
C
di v are positive Coefficients that modulate the importance of the prediction, the overall popularity and the diversity respectively in the score function.Calculating Top-k Packages
the center, as far as the price budget constraints are satisfied. Once a candidate package is created, it is added to packages and its elements are removed from candidate books so that they won’t be used again.
Here is the description of our algorithm:
Input: a set of books B, price budget Bp, the number of packages N.
Step 1: Initialize Packages as ∅
Step2: Sort B in descending order by opop, and the new set is defined as Candidates. Step3: While Candidates≠ ∅ and |Packages|<N, go to Step 4. Otherwise, return Packages.
Step4: f←Candidates [0]
Step5: Remove f from Candidates. Step6: S←f, Actives←B-{f}
Step7: If not finish, go to Step 8. Otherwise, return S. Step8: i ← argm axi Actives∈ S coreu(S ∪{ } )i
Step9: if p f
( )
+p i( )
≤Bp, go to Step 10. Otherwise, finish.Step10: S ← S∪{ }i , p ← p f
( )
+ p i( )
Step11:Actives ← Actives − i. Then go to Step 7. Step12: Candidates←Candidates S−
Step13:
Packages
←
Packages
∪
S
. Then go to Step 3.Second, select top-k packages which satisfy budget constraints. Once the required number of packages has been created, they are ranked following their respective scores. Afterwards, we select the kpackages having the best scores.
Experiments and Analysis
Experiment Settings. The goal of our experiments were: (1) evaluate the precision of the packages recommended by our approach, and (2) evaluate the intra package diversity. In order to have a set of books constituting potential recommendations, we acquire users’ reading information from DouBan, which includes users’ ids, names and price of books users has read, and ratings the user gave to these books. Each book has a category organized in a tree structure, which allows us to construct our similarity measure. In addition, DouBan provides a book the number of users rating for it, and we used them as an indicator of its popularity, for estimating the function pop defined in Section 4.2.1. We exclude books that have very few or no ratings. Considering credit, we first acquire Douban users’ sesame credits and rank them in the descending order. Then we choose 20 most credible users’ sesame credits and normalize them to [0,1]. Relatively it is worth recommending things to people who have higher credit.
Evaluation Metrics. Precision: precision is calculated as the ratio of recommended books that are relevant to the total number of recommended books.
Diversity: we use the intra package diversity introduced by [1] to measure the diversity of a package. The Mean Intra-package Diversity (MIPD) is defined.
{
}
( )
k
i i 1
1 2 k
ILD P
diversity
MIPD P , P ,
, P
k
=
=
…
=
∑
. (11)PD
F : the F-measure is the harmonic mean of precision and diversity :
PD
2 precision diversity
F
precision
diversity
×
×
=
+
. (12)corresponding to different possible combinations of the factors of Cpr e,Copop,Cdi v . Each version corresponds to a different combination of the parameters. Versions we tested are summarized in the Table 1. The name of each version indicates the use or not of the different aspects when constituting the set of packages.
Table 1. Different versions of our system. Versions Ceapp Copop Cdiv
per 1 0 0
pop 0 1 0
div 0 0 1
pop+div 0 1/2 1/2
per+div 1/2 0 1/2
per+pop 1/2 1/2 0
per+pop+div 1/3 1/3 1/3
Experiment Results
In the experiments, we evaluate our method and compare it with the content-based book recommendation application.
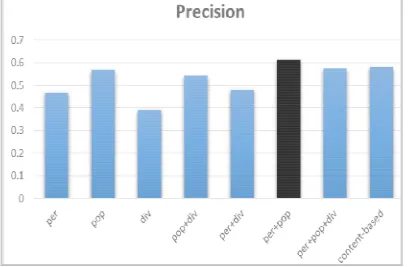
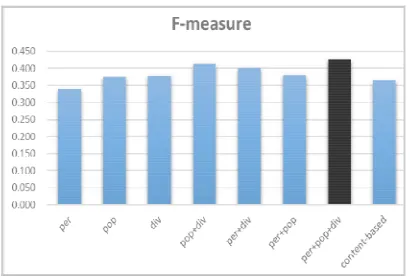
Experiment results are presented in Figure 1, Figure 2 and Figure 3. In Figure 1, the "per+pop" version performs the best precision. And in most cases, the "pop" version leads to a better precision than the "per" version and the "pop+div" version better than the "per+div" version, which highlights the importance of the popularity and its effect on the relevance of recommendations [17]. Figure 2 shows that the "div" version performs the best diversity compared to all others. Figure 3 presents the comparison of F-measure between precision and diversity. We can see that the "per+pop+div" realizes the best compromise, which means it is the best approach when considering both precision and diversity.
In addition, we interview users whether our recommendation brings a positive impact on their life by sending e-questionnaires to them, which includes options of ‘A. excellent, B. good, C. normal, D. worse , E. worst’. The result turns to be 5% of excellent, 80% of good, 15% of normal, 0% of worse , 0% of worst, which demonstrates that our model indeed bring good effect for their life.
[image:5.612.332.533.534.671.2] [image:5.612.79.283.536.670.2]
Figure 3. Comparison in F-measure.
Summary
Motivated by travel package recommendation, we apply package recommendation to recommending books. Our method generates top-k packages under constraints according to the score of packages, which mainly depends on user credit, the overall popularity, the intra diversity of packages and user preference which may change over time. The constraint is the money a user has for buying books in one purchase. We use an algorithm to calculate the top-k packages with best scores. Theexperiment of our method using data from 20 active and credible DouBan users, demonstrates its quality and its ability to improve both the accuracy and the diversity of recommendations. Meanwhile, our feedback shows that our model indeed bring good effect for users’ life.
References
[1] Idir Benouaret, Dominique Lenne, A Package Recommendation Framework for Trip Planning Activities, Acm Conference on Recommender Systems, 2016 :203-206.
[2] Celalettin Aygün, Oktay Yıldız. Development Of Content Based Book Recommendation System Using Genetic Algorithm, Signal Processing and Communication Application Conference, 2016:1025-1028.
[3] Z Ali, S Khusro, I Ullah. A Hybrid Book Recommender System Based on Table of Contents (ToC) and Association Rule Mining, International Conference on Informatics & Systems, 2016: 68-74.
[4] MS Pera, N Condie ,YK Ng. Personalized Book Recommendations Created by Using Social Media Data, Springer Berlin Heidelberg, 2011, 6724:390-403.
[5] Kumari Priyanka,Anand Shanker Tewari,Asim Gopal Barman ,Personalised Book Recommendation System based on Opinion Mining Technique, 2015 Global Conference on Communication Technologies (GCCT 2015).
[6] AS Tewari ,A Kumar, AG Barman. Book Recommendation System Based on Combine Features of Content Based Filtering, Collaborative Filtering and Association Rule Mining, Advance Computing Conference, 2014:500-503.
[7] Kumari Priyanka, Anand Shanker Tewari, Asim Gopal Barman. Personalized Book Recommendation System based on Opinion Mining Technique, Communication Technologies, 2015 :285-289.
[9] Roberto Interdonato, Salvatore Romeo, Andrea Tagarelli, George Karypis, A Versatile Graph-Based Approach to Package Recommendation, IEEE International Conference on Tools with Artificial Intelligence, 2013:857-864.
[10] Qi Liu, Enhong Chen, Hui Xiong, Yong Ge, Zhongmou Li, Xiang Wu , A Cocktail Approach for Travel Package Recommendation, IEEE Transactions on Knowledge & Data Engineering, 2013, 26 (2):278-293.
[11] Chang Tan, Qi Liu, Enhong Chen, Hui Xiong, Xiang Wu, Object-Oriented Travel Package Recommendation, Acm Transactions on Intelligent Systems & Technology, 2014, 5(3):43.
[12] Zhiwen Yu, Yun Feng, Huang Xu, and Xingshe Zhou ,Recommending travel packages based on mobile crowdsourced data, IEEE Communications Magazine, 2014, 52(8):56-62.
[13] Z Yu, H Xu, Z Yang, B Guo. Personalized Travel Package With Multi-Point-of-Interest Recommendation Based on Crowdsourced User Footprints, IEEE Transactions on Human-Machine Systems, 2016, 46 (1):151-158.
[14] Sihem Amer-Yahia, Francesco Bonchi, Carlos Castillo, Esteban Feuerstein, Isabel Mendez-Diaz, and Paula Zabala, Composite retrieval of diverse and complementary bundles. Transactions on Knowledge and Data Engineering, IEEE Transactions on Knowledge & Data Engineering, 2014, 26 (11):2662-2675.
[15] L. Castillo, E. Armengol, E. Onaind´ıa, L. Sebasti´a, J. Gonz´alez-Boticario, A. Rodr´ıguez, S. Fern´andez,J. D. Arias, and D. Borrajo. Samap: An user-oriented adaptive system for planning tourist visits. Expert Systems with Applications, 2008, 34(2):1318-1332.
[16] C.-N. Ziegler, S. M. McNee, J. A. Konstan, and G. Lausen. Improving recommendation lists through topic diversification. In World Wide Web, 2005, 50 (3):22-32.