2017 3rd International Conference on Computer Science and Mechanical Automation (CSMA 2017) ISBN: 978-1-60595-506-3
A Robust Multi-Target Visual Tracking Method using TLD Framework
Yong-Feng HUANG
1,aand Zhen YANG
2,b1
Donghua Univ Shanghai, China
2
Donghua Univ Shanghai, China a
[email protected], [email protected]
Keywords: Multi-target, Long-term tracking, Semi-supervised learning, Posture change.
Abstract. This paper investigates a robust multi-target visual tracking method based on TLD framework. We propose a novel visual tracking method that divides the long-term tracking task into four parts: tracker module, learning module, weak-detector module and strong-detector module. Before the tracking, it is essential to sample some basic posture of targets and build several patterns by training. Then, a separate process is allocated for each target may appear in the video or not. The strong-detector module makes a global scanning on every frame. Once a target of interest is detected, the tracker module starts to follow it from frame to frame. The weak-detector module makes a local scanning around the position predicted by the tracker module. The learning module estimates the errors of weak-detector module and updates the weak-detector module to avoid these errors from coming up again. At the last, when the posture of some target has large change, it may result in the metal failure of tracker module and weak-detector module. At this time, the strong-detector module will relocate the target and initialize the others modules.
Introduction
Multi-target visual tracking refers to automatic estimation of the objects’ bounding boxes or indicate that whether the objects are visible in every frame. There are many problems need to be solved. One of the most significant problems is the detection of the objects when they reappear in the view of cameras. It aggravates the problem when the objects may change their appearance. Then there are also other problems need to be handled, like scale changes, illumination changes, background clutter and partial occlusions.
We should accept the fact that neither trackers nor detectors can handle the task of long-term tracking by themselves. At the same time, they may benefit from each other if they have good cooperation. Trackers can provide weakly labeled training data for training detectors and detectors can help minimize the trackers’ failures
A novel framework based on TLD framework [1] is proposed in this paper. TLD has a good performance at single-target long-term tracking but it is highly likely to fail when the appearance of object has large changes. Thus, we redesign the TLD framework to handle the problem.
The rest of the paper is organized as follows. Section 2 introduces several most closely related works of our framework. Then we provide the detailed information about our framework in section 3, including interior design of each single module. The experimental results are presented in Section 4. And finally, we conclude this paper in Section 5.
Related Works
The detector module scans each frame and generates both positive samples and negative samples. The learning module estimates detector’s errors and updates it if necessary.
Figure 1. Block diagrams of TLD.
The Proposed System
In this section, we build our framework incrementally, which will be discussed in detail in each of the following subsections.
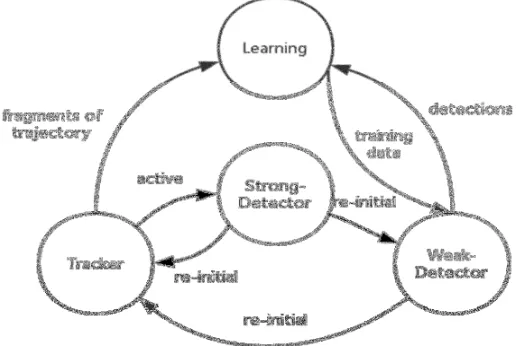
System Overview. Our system consists of four sub-modules: tracker, learning, weak detector and strong detector. Before the tracking, it is essential to sample some basic posture of targets. Then, the strong-detector module makes a global scanning on every frame. Once we detect a target of interest, the tracker module starts to follow it from frame to frame. The weak-detector module makes a local scanning around the position predicted by the tracker module. The learning module is in charge of estimating the errors of weak-detector module and updating the weak-detector module to avoid these errors from coming up again. At the last, when the posture of some target has large change, it may result in the metal failure of weak-detector module. At this time, the strong-detector module will relocate the target and initialize the others modules. Its block diagram is shown in Fig 2.
[image:2.612.186.444.532.705.2]Tracker Module. The tracker module is based on Median-Flow method [2]. It firstly uses Lucas-Kanade algorithm to predict the motion and then calculate the forward-backward error [3]. For simplifying the later calculations, more than half of feature points which are ineffective will be discarded.
Learning Module. The task of the learning module is to update the weak-detector module while the tracking is running by P-expert and the N-expert [4]. The P-expert discovers new appearances of the objects and generates positive samples by identifying the reliable parts of the trajectory provided by the tracker module. At the same time, N-expert discovers clutter from the background pixels and generates negative samples.
Weak-detector Module. The weak-detector scans each frame by a sliding window. It needs to decides whether the object is visible or where the object is for each patch.
In the beginning, all possible scales and shifts will be generated with some sliding windows. The specific parameters depend on the resolution and clarity of origin video.
[image:3.612.124.500.308.427.2]The weak-detector module consists of three classifiers which are in cascade structure. Fig 3 shows the block diagram of this structure.
Figure 3. Block diagrams of the weak-detector module.
Variance Filter Classifiers the first one. It calculates the variance of each patch and reject the patches whose variance is smaller than threshold. Most of them will be dropped.
The next one is Random Ferns Classifier [5]. This classifier is composed of 10 basic classifiers and each of them consists of 13-pixel comparisons on the patch. Every set of 13-pixel comparisons result in a binary code which indexes to an array of posteriors.
The last one is NN (Nearest Neighbor [6]) & LBP Classifier. Now only quite a few patches are left. It is obvious that most of them have a certain deviation compared with the real tracking object. In the origin TLD, they will be further classified by the NN classifier. In this paper, we improve it with LBP feature. The relatively similarity can be calculated by comparing the samples (the normalized LBP histogram) with the positive and negative samples. It is the assessing criteria of this classifier [7].
Experiments
The performance of the origin TLD has been demonstrated by a set of quantitative experiments in reference [1]. The author compared TLD with some other algorithms, like IVT (Iterative Visual Tracking [8]), ODV (Online Discriminative Features [9]), ET (Ensemble Tracking [10]), MIL (Multiple Instance Learning [11]), Co-trained Generative Discriminative Tracking [12], OB (Online Boosting [13]), ORF (Online Random Forests [14]), PROST (Parallel Robust Online Simple Tracking [15]) etc. The performance is evaluated using P, R and F. P represents the number of true positives divided by the number of all responses and R represents the number of true positives divided by the number of object occurrences that
should have been detected. F combines these two measures as 2(P+R)/PR [16]. A detection
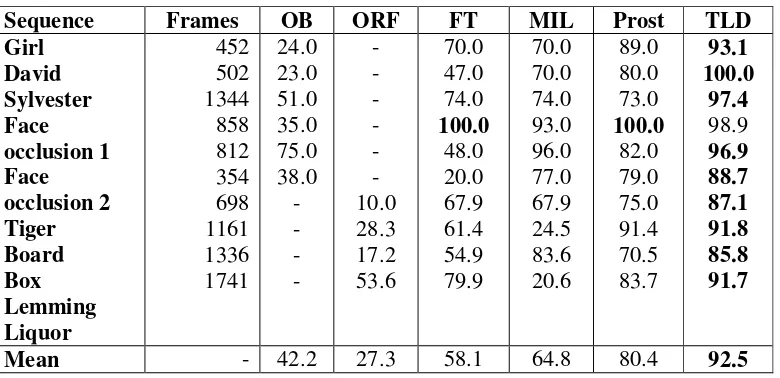
[image:4.612.114.504.295.484.2]whose overlap with ground truth bounding box is larger than 50% will be considered as correct. As shown in table 1, TLD performs better than other trackers. So, in this paper, we mainly compared the proposed algorithm with origin TLD. We use a more challenging data set. It contains a fragment captured from monitor video. Our system outperforms much better than origin TLD.
Table 1. The performance comparison between TLD and some other algorithms.
Sequence Frames OB ORF FT MIL Prost TLD
Girl David Sylvester Face occlusion 1 Face occlusion 2 Tiger Board Box Lemming Liquor 452 502 1344 858 812 354 698 1161 1336 1741 24.0 23.0 51.0 35.0 75.0 38.0 - - - - - - - - - - 10.0 28.3 17.2 53.6 70.0 47.0 74.0 100.0 48.0 20.0 67.9 61.4 54.9 79.9 70.0 70.0 74.0 93.0 96.0 77.0 67.9 24.5 83.6 20.6 89.0 80.0 73.0 100.0 82.0 79.0 75.0 91.4 70.5 83.7 93.1 100.0 97.4 98.9 96.9 88.7 87.1 91.8 85.8 91.7
Mean - 42.2 27.3 58.1 64.8 80.4 92.5
Experiments on Single-target Tracking. In this subsection we use a fragment captured from monitor video. It almost contains all scenes that may cause tracking errors, including scale and illumination changes, background clutter, partial occlusions, and of course, posture changes.
Table 2 shows the result of experiment. We can see that the proposed system performs much better than origin TLD.
Table 2. The performance comparison between TLD and the proposed system.
TLD Proposed System
P 58.6(1466/2500) 98.1(2452/2500)
R 59.1(1466/2480) 98.9(2452/2480)
F 58.8 98.5
Figure 4. Snapshot of the results.
Conclusion
In this paper, we studied the problem that the origin TLD framework cannot perform well when the target may have great posture changes. We redesigned the framework and decomposed the long-term tracking into four parts: tracker, learning, weak-detector and strong-detector. Compared with the origin TLD, we also improved the NN classifier with LBP feature. The experimental results show that our proposed algorithm can outperform the most advanced methods significantly.
There are also many improvements can be making to get a more reliable and effective system. For instance, our proposed system does not perform well on more complex scenes, especially there are too many similar targets appear at the same time. On the other hand, for the targets which do not have good texture features, it is hard for our proposed system to distinguish targets from background precisely.
References
[1] Kalal Z, Mikolajczyk K, Matas J. Tracking-Learning-Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2012, 34(7):1409-1422.
[2] Ojala T, Pietik, Inen M, et al. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns[M]//Computer Vision - ECCV 2000. Springer Berlin Heidelberg, 2000:971-987.
[3] Kalal Z, Mikolajczyk K, Matas J. Forward-Backward Error: Automatic Detection of Tracking Failures[C]//International Conference on Pattern Recognition. IEEE Computer Society, 2010:2756-2759.
[4] Kalal Z, Matas J, Mikolajczyk K. P-N learning: Bootstrapping binary classifiers by structural constraints[C]//Computer Vision and Pattern Recognition. IEEE, 2010:49-56.
[5] Rao C, Yao C, Bai X, et al. Online Random Ferns for robust visual tracking[C]// International Conference on Pattern Recognition. 2012:1447-1450.
[6] Adam A, Rivlin E, Shimshoni I. Robust Fragments-based Tracking using the Integral Histogram[C]//Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on. IEEE Xplore, 2006:798-805.
[8] Ross D A, Lim J, Lin R S, et al. Incremental Learning for Robust Visual Tracking[J]. International Journal of Computer Vision, 2008, 77(1):125-141.
[9] Collins R T, Liu Y, Leordeanu M. Online selection of discriminative tracking features.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2005, 27(10):1631.
[10] Avidan S. Ensemble tracking[C]//Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on. IEEE, 2005:494-501.
[11] Babenko B, Yang M H, Belongie S. Visual Tracking with Online Multiple Instance Learning.[C]//Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009:983-990.
[12] Yu Q, Dinh T B, Medioni G. Online Tracking and Reacquisition Using Co-trained Generative and Discriminative Trackers[C]//Computer Vision-ECCV 2008, European Conference on Computer Vision, Marseille, France, October 12-18, 2008, Proceedings. DBLP, 2008:678-691.
[13] Grabner H, Bischof H. On-line Boosting and Vision[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. DBLP, 2006:260-267.
[14] Saffri, C. Leistner, J. Santner, M. Godec, H. Bischof. Online Random Forests[C]// Conference on Computer Vision and Pattern Recognition. 2006:798-805.
[15] Santner J, Leistner C, Saffari A, et al. PROST: Parallel robust online simple tracking[C]// IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, Ca, Usa, 13-18 June. DBLP, 2010:723-730.