Themed Section: Science and Technology
An Overview of Artificial Intelligence and their Applications
towards Machine Learning
Paduchuri V R Akhil, Polu Yeswanth Saidu Sai
Bachelor of Technology, Mahatma Gandhi Institute of Technology, JNTUH, Hyderabad, Telangana, India
ABSTRACT
The issue of learning and basic leadership is at the center level of contention in organic and in addition artificial angles. So researcher presented Machine Learning as broadly utilized idea in Artificial Intelligence. It is the idea which instructs machines to identify diverse examples and to adjust to new conditions. Machine Learning can be both experience and clarification based learning. In the field of mechanical technology machine learning assumes a fundamental part, it helps in taking an improved choice for the machine which in the long run builds the productivity of the machine and more sorted out method for preforming a specific errand. Presently a-days the idea of machine learning is utilized as a part of numerous applications and is a center idea for clever frameworks which prompts the presentation imaginative innovation and more propel ideas of artificial reasoning.
Keywords: Supervised Learning, Machine Learning, Algorithms, Unsupervised Learning.
I.
INTRODUCTION
Learning is considered as a parameter for keen machines. Profound comprehension would help in taking choices in a more enhanced shape and furthermore help at that point to work in most effective strategy. As observing is intelligence, so learning is additionally turning into a key to the investigation of organic and artificial vision. Rather than building overwhelming machines with express programming now unique algorithms are being present which will help the machine to comprehend the virtual condition and in light of their understanding the machine will take specific choice. This will in the long run diminish the quantity of programming ideas and furthermore machine will end up autonomous and take choices all alone. Distinctive algorithms are presented for various sorts of machines and the choices taken by them. Planning the calculation and utilizing it in most fitting way is the genuine test for the designers and researchers. Example perceiving is additionally an idea in
machine learning. Most algorithms utilize the idea of example acknowledgment to settle on upgraded choices. As an outcome of this new enthusiasm for learning we are encountering another period in measurable and useful guess procedures and their applications to area, for example, PC dreams.
and deductively these algorithms relies upon the information structures utilized and additionally hypotheses of learning subjective and hereditary structures. Yet characteristic method for learning gives awesome exposures for understanding and great degree for wide range of kinds of conditions. Numerous machine learning calculation are by and large being obtained from current reasoning in intellectual science and neural systems. General we can state that learning is characterized as far as enhancing execution in light of some measure. To know whether an operator has learned, we should characterize a measure of accomplishment. The measure is generally not how well the operator performs on the preparation encounters, yet how well the specialist performs for new encounters. In this examination paper we will consider the two primary sorts of algorithms i.e. supervised and unsupervised learning.
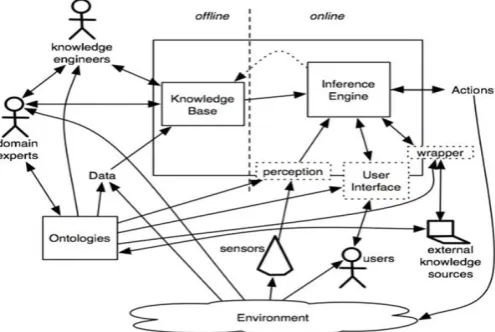
Figure 1. Diagram representing Machine Learning Mechanism
II.
RELATED WORKS
Sally Goldman et.al [1] proposed the down to earth learning situations where we have little measure of named data alongside an expansive pool of unlabeled data and displayed a "co-preparing" system for utilizing the unlabeled data to enhance the standard supervised learning algorithms. She accepted that there are two diverse supervised learning algorithms
which both yield a theory that characterizes a parcel of example space for e.g. a choice tree parcels the occurrence space with one identical class characterized per tree. She at long last inferred that two supervised learning algorithms can be utilized effectively mark data for each other.
Zoubin Ghahramani et.al[2] gave a short review of unsupervised learning from the point of view of factual demonstrating. As per him unsupervised learning can be inspired from data theoretic and Bayesian standards. He additionally checked on the models in unsupervised learning. He additionally presumed that insights gives a rational structure to learning from data and for thinking under vulnerability and furthermore he specified the sorts of models like Graphical model which assumed an essential part in learning frameworks for wide range of sorts of data.
Rich Caruana et.al [3] has considered different supervised learning techniques which were presented in a decade ago and give a substantial scale exact correlation between ten supervised learning strategies. These techniques include: SVMs, neural nets, calculated relapse, gullible bayes, memory-based learning, irregular backwoods, choice trees, packed away trees, helped trees and supported stumps. They likewise contemplated and look at the impact that adjusting the models through Platt Scaling and Isotonic Regression has on their execution. They had utilized different execution based criteria to assess the learning strategies.
Measure works, a confinement of current measure capacities is that they can just deal with two-dimensional case spaces. They introduce the outline and usage of a summed up multi-dimensional measure work and exhibit its utilization through an arrangement of analyses. The outcomes show that there are cases for which measure capacities might have the capacity to catch parts of execution that can't be caught by cross-approval tests. At last, they examine the effect of learning calculation parameter tuning.
Yugowati Praharsi et.al[5] had taken three supervised learning techniques, for example, k-closest neighbor (k-NN), support vector data description (SVDD) and support vector machine (SVM) , as they don't experience the ill effects of the issue of presenting another class, and utilized them for Data description and Classification. The outcomes demonstrate that element determination in view of mean data pick up and a standard deviation edge can be considered as a substitute for forward choice. This demonstrates data variety utilizing data pick up is an imperative factor that must be considered in choosing highlight subset. At last, among eight applicant highlights, glucose level is the most unmistakable element for diabetes recognition in all classifiers and highlight choice techniques under thought. Pertinence estimation in data pick up can deal with the most imperative element to the minimum huge one. It can be exceptionally helpful in medical applications, for example, characterizing highlight prioritization for manifestation acknowledgment. Along these lines the break down the exactness and working of all the three techniques.
III.
PROBLEMS FACED IN LEARNING
Learning is a mind boggling process as parcel of choices are made and furthermore it depends from machine to machine and from calculation to calculation, how to comprehends a specific issue and
on understanding the issue how it reacts to it. A portion of the issues make a mind boggling circumstance for the machine to react and respond. These issues not just make issue complex it likewise influences the learning procedure of the machine. As the machine is reliant on what it sees, the recognition module of the machine ought to likewise center around various kinds of difficulties and condition which it will confront, as various information can deliver diverse yields and the most proper and improve yield ought to be considered by the machine. A portion of the normal issues looked amid the learning procedure are as per the following:-
Inclination the propensity to lean toward one theory over another is known as a predisposition. Think about the operators N and P. Saying that a speculation is superior to anything N's or P's theory isn't something that is acquired from the data - both N and P precisely predicts the greater part of the data given - yet is something outside to the data. Without a predisposition, an operator won't have the capacity to make any forecasts on inconspicuous illustrations. The speculations embraced by P and N differ on every single further illustration, and, if a learning operator can't pick a few theories as better, the specialist won't have the capacity to determine this contradiction. To have any inductive procedure make expectations on concealed data, a specialist requires a predisposition. What constitutes a decent inclination is an experimental inquiry concerning which predispositions work best by and by; we don't envision that either P's or N's inclinations function admirably by and by.
One of the critical properties of a learning calculation is its capacity to deal with boisterous data in the majority of its structures.
Example Recognition-This is another sort of issue looked in machine learning process. Example acknowledgment algorithms for the most part intend to give a sensible response to every single conceivable information and to perform "nearest to" coordinating of the data sources, considering their factual varieties. This is not quite the same as example coordinating algorithms which coordinate the correct esteems and measurements. As algorithms have all around characterized esteems like for numerical models and shapes like distinctive esteems for rectangle, square, circle and so forth.
It ends up various for machine to process those information sources which have distinctive esteems e.g. Consider a ball the shape and example can be perceived by the machine, yet now when we keep a swelled ball then the example would be altogether extraordinary and the machine will confront issue in perceiving the example and the whole procedure comes to end. This is the significant issue looked by a large portion of the machine learning procedure and algorithms.
IV.
SUPERVISED LEARNING
Supervised learning is a calculation in which both the sources of info and yields can be seen. In view of this preparation data, the calculation needs to sum up with the end goal that it can accurately react to every conceivable info. This calculation is relied upon to deliver redress yield for inputs that weren't experienced amid preparing. In supervised learning what must be discovered is determined for every illustration. Supervised grouping happens when a mentor gives the arrangement to every case. Supervised learning of activities happens when the specialist is given quick criticism about the estimation of each activity.
With a specific end goal to take care of a give issue utilizing supervised learning calculation one needs to take after some specific advances:-
1)Determine the sort of preparing illustrations.
2)Gather a preparation set.
3)Determine the information include portrayal of scholarly capacity.
4)Determine the structure of learning capacity and relating learning calculation.
5)Complete the outline and run the learning calculation on the accumulate set of data.
Assess the precision of the educated capacity additionally the execution of the learning capacity ought to be estimated and afterward the execution ought to be again estimated on the set which is not the same as the preparation set.
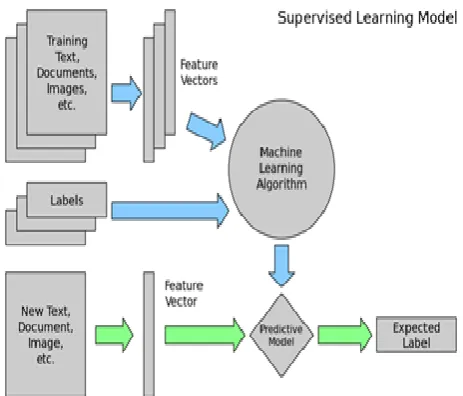
Figure 2. Diagram representing Supervised Learning Algorithm
Supervised Learning can be part into two general classifications:
1.Classification of reactions that can have only a couple of qualities, for example, 'genuine' or 'false'. Arrangement calculation applies to ostensible, not ordinal reaction esteems.
Attributes of Algorithm
SVM expectation speed and memory utilization are great if there are few support vectors, yet can be poor if there are numerous support vectors. When you utilize a bit work, it can be hard to translate how SVM characterizes data, however the default direct plan is anything but difficult to decipher.
Naive Bayes speed and memory utilization are useful for straightforward circulations, yet can be poor for part appropriations and extensive data sets.
Nearest Neighbor normally has great forecasts in low measurements, however can have poor expectations in high measurements. For straight inquiry, Nearest Neighbor does not play out any fitting. For kd-trees, Nearest Neighbor performs fitting. Closest Neighbor can have either nonstop or straight out indicators, however not both.
Discriminant Analysis is exact when the displaying suspicions are fulfilled (multivariate typical by class). Something else, the prescient exactness changes.
Figure 3. This block-diagram shows the working mechanism of Supervised Learning.
V.
SUPERVISED LEARNING
In unsupervised learning the machine essentially gets the info x1, x2… yet gets neither supervised target yields, nor rewards from its condition. Yet, it is conceivable to build up a formal structure for unsupervised learning
in light of the idea that the's machine will probably fabricate portrayals of the information that can be utilized for basic leadership, foreseeing future sources of info, proficiently conveying the contributions to another machine, and so forth. Case of unsupervised learning is grouping and dimensionality diminishment.
A few algorithms for unsupervised learning are as per the following:
1. Hierarchical grouping
This calculation constructs a multilevel progressive system of bunch by making a group tree.
Information sources: objects spoke to as vectors Yields: a chain of importance of affiliations spoke to as a "dendogram".
Calculation:
1.hclust(D: arrangement of occasions): tree 2.var: C,/* set of groups */
3.M/* network containing separations between sets of group */
4.for every d ∈ D} do 5.Make d a leaf hub in C 6.done
7.for each match a,b ∈ C do 8.Ma,b ← d(a, b)
9.done
10.while(not all occurrences in a single bunch) do 11.Find the most comparative match of bunches in M
12.Merge these two bunches into one group. 13.Update M to mirror the consolidation activity. 14.done
2. K-implies organizing
In this calculation we need to first choose the quantity of bunch ahead of time, they may meet to a neighborhood least. K-means can be viewed as a specialization of the desire amplification (EM) calculation. It is more productive (bring down computational multifaceted nature) than various leveled grouping.
Calculation:
1. K-implies ((X= {d1, . . . ,dn} ⊆ Rm , k): 2R) 2.C: 2R/*µ an arrangement of groups */
3.d = Rm x Rm - > R/*distance function*/ 4.µ: 2R - > R/* µ registers the mean of a bunch */ 5.select C with k starting focuses f1,… .fk 6.while halting standard not genuine do 7.for all groups cj ∈ C do
8.cj ← {di|∀fld(di, fj) ≤d(di, fl)} 9.done
10.for all methods fj do 11.fj <-µ(cj)
12.done 13.done 14.return C
Figure 4. This block-diagram shows the working mechanism of Supervised Learning
ANALYTICS: SUPERVISED VS UNSUPERVISED LEARNING
Machine learning algorithms are depicted as either 'supervised' or 'unsupervised'. The refinement is drawn from how the student arranges data. In supervised algorithms, the classes are foreordained. These classes can be considered as a limited set, beforehand touched base at by a human. By and by, a specific portion of data will be marked with these orders. The machine student's undertaking is to scan for examples and develop scientific models. These models at that point are assessed based on their prescient limit in connection to measures of fluctuation in the data itself. A large number of the strategies referenced in the documentation (choice tree acceptance, guileless Bayes, and so on) are cases of supervised learning systems.
Unsupervised students are not furnished with orders. Truth be told, the fundamental errand of unsupervised learning is to create arrangement marks naturally. Unsupervised algorithms search out comparability between bits of data with a specific end goal to decide if they can be portrayed as shaping a gathering. These gatherings are named groups, and there are entire groups of bunching machine learning systems.
In unsupervised arrangement, regularly known as 'bunch examination's the machine isn't told how the writings are gathered. Its undertaking is to touch base at some gathering of the data. In an extremely normal of bunch investigation (K-implies), the machine is told ahead of time what number of groups it should shape - a conceivably troublesome and subjective choice to make.
you. Furthermore, it has significant supportive power if its inward examinations of low-level semantic marvels prompt groupings that bode well at a higher interpretative level or that you had suspected however purposely withheld from the machine. In this way bunch examination is an exceptionally encouraging apparatus for the investigation of connections among numerous writings.
VI.
CONCLUSIONS & FUTURE SCOPE
The topic of how to quantify the execution of learning algorithms and classifiers has been researched. This is an unpredictable inquiry with numerous viewpoints to consider. The proposal settle a few issues, e.g., by dissecting current assessment techniques and the measurements by which they measure execution, and by characterizing a formal system used to portray the strategies in a uniform and organized way. One finish of the investigation is that classifier execution is frequently estimated in terms of order exactness, e.g., with cross-approval tests. A few strategies were observed to be general in the way that they can be utilized to assess any classifier (paying little mind to which calculation was utilized to create it) or any calculation (paying little heed to the structure or portrayal of the classifiers it produces), while different techniques just are relevant to a specific calculation or portrayal of the classifier. One out of ten assessment strategies was graphical, i.e., the technique does not work like a capacity restoring an execution score as yield, but instead the client needs to dissect a perception of classifier execution.
The appropriateness of measure-based assessment for estimating classifier execution has likewise been explored and we give observational examination comes about that fortify prior distributed hypothetical contentions for utilizing measure-based assessment. For example, the measure-based capacity executed for the examinations, could recognize two classifiers that were comparable as far as exactness yet extraordinary
as far as classifier intricacy. Since time is frequently of substance while assessing, e.g., if the assessment strategy is utilized as a wellness work for a hereditary calculation, we have investigated measure-based assessment as far as the time devoured to assess diverse classifiers. The conclusion is that the assessment of apathetic students is slower than for excited students, rather than cross-approval tests. Furthermore, we have exhibited a strategy for estimating the effect that learning calculation parameter tuning has on classifier execution utilizing quality traits. The outcomes demonstrate that parameter tuning is frequently more critical than the decision of calculation. Quantitative support is given to the declaration that a few algorithms are more vigorous than others as for parameter arrangement.
VII.
REFERENCES
[1]. Sally Goldman; Yan Zhou, "Upgrading Supervised Learning with Unlabeled Data", Department of Computer Science, Washington University, St.Louis, MO 63130 USA.
[2]. Zoubin Ghahramani,"Unsupervised Learning",Gatsby Computational Neuroscience Unit, University College London, UK.
[3]. Rich Caruana; Alexandru Niculescu-Mizil,"An Empirical Comparison of Supervised Learning Algorithms", Department of Computer Science, Cornell University, Ithaca, NY 14853 USA [4]. Niklas Lavesson,"Evaluation and Analysis of
Supervised Learning Algorithms and Classifiers", Blekinge Institute of Technology Licentiate Dissertation Series No 2006:04,ISSN 1650-2140,ISBN 91-7295-083-8
[6]. Andrew Ng,"Deep Learning And Unsupervised","Genetic Learning Algorithms","Reinforcement Learning and Control", Department of Computer Science,Stanford University,450 Serra Mall, CA 94305, USA.
[7]. Bing Liu, "Supervised Learning", Department of Computer Science,University of Illinois at Chicago (UIC), 851 S. Morgan Street, Chicago [8]. Niklas Lavesson,"Evaluation and Analysis of
Supervised Learning Algorithms and Classifiers", Blekinge Institute of Technology Licentiate Dissertation Series No 2006:04,ISSN 1650-2140,ISBN 91-7295-083-8.
[9]. Rich Caruana; Alexandru Niculescu-Mizil,"An Empirical Comparison of Supervised Learning Algorithms", Department of Computer Science, Cornell University, Ithaca, NY 14853 USA
[10]. Peter Norvig; Stuart Russell,"Artificial