MINING WEB GRAPHS FOR RECOMMENDATIONS
USING COLLABORATIVE FILTERING AND QUERY
SUGGESTION TECHNIQUES
Toshi Patel
1, Dimpy Singh
2, Modassir Anis
3, Anjali Gangwar
41
M.Tech(S.E), SRMSCET, Bareilly, (India)
ABSTRACT
Now a day, web information is essential for every organization. So improving the functionality of web
information is required by everyone. Web Graphs are principally the combination of DESIGN & CODE. The
web graphs defines the linking & current of pages. For enhancing the recommendation on web pages we extract
the web graphs from database. Some of the techniques are used for mining such graphs. Collaborative Filtering
& Query Suggestion are the such techniques. We are given that the comparative study of these techniques.
Evaluate & analytical results are favouring the collaborative filtering techniques for mining web graphs in most
of the aspects.
Keywords
:
Recommendations, Web Mining, Query Suggestion, CF (Collaborative Filtering
I.
INTRODUCTION
With the varied and volatile growth of Web information, effective and efficient organisation and utilisation of
information has become more and more grave. This is particularly important for Web 2.0 related applications
since user generate information is further free-style and less planned, which increases the difficulties in mining
useful information from these data sources. In regulate to satisfy the information needs of Web users and
improve the user experience in many Web applications [3].
Now a day, we set up rapid intensification of web information as well as search engines also. But a small and
significant problem faced by the users is consumption of information effectively [1].
In general, Recommender systems are based on Collaborative Filtering. CF bring together rating information
from other comparable users or items and then involuntarily predict the interest of an active user. The
fundamental statement of collaborative filtering is that the active user will favour those items which other
similar users favour. Collaborative filtering has been extensively employed in some large, familiar commercial
systems, including product recommendation at Amazon, movie recommendation at Netflix etc. based on this
easy but effective instinct. Typical collaborative filtering algorithms require a user-item rating matrix which
contain user-specific rating preference to assume users characteristics. on the other hand, in most of the cases,
rating data are always occupied since information on the Web is less structured and more diverse [3].
The main objective of this paper is to contrast the collaborative filtering and query suggestion recommendation
techniques. Mining web graphs for recommendations can be utilize in many recommendation responsibilities on
The rest of the paper is organized as follows. We review recommendation techniques in Section 2. Section 3
presents the Collaborative Filtering. In Section 4, we demonstrate the Query Suggestion. Finally, conclusion is
given in Section 5.
II.
RECOMMENDATION
TECHNIQUES
Recommendation algorithms are best acknowledged for their use on e-commerce web sites where they use input
about a customer’s interests to produce a list of recommended things. Many applications use only the items that
customers pay for and overtly rate to represent their interests, but they can also use added attributes, as well as
items viewed, demographic data, subject interests, and favourite artists.
For different recommendation responsibilities, different recommendation algorithms are proposed in present
mining system. There are some methods linked to recommendation system, which comprise collaborative
filtering approach, query suggestion techniques, image recommendation methods and connect through data
analysis. G. Linden et.al. proposed conventional collaborative filtering algorithms that scales separately of the
number of customers and also to the number of items in the product listing. This algorithm produces
recommendations in real time, which can be balance to vast data sets, and engender high quality
recommendations. These recommendations are computationally luxurious. It is O (MN) in the worst case, Here
M is the number of customers and N give the number of product directory Items, since it examine M customers
and up to Ns items for each customer [4].
2.1 Collaborative Filtering
Collaborative filtering (CF) is a technique commonly used to build modified recommendations on the Web. A
range of fashionable websites that make use of the collaborative filtering technology includes Amazon, Netflix,
iTunes, IMDB, LastFM, Delicious and Stumble Upon. [7].
Collaborative Filtering is a practice that by design predicts the interest of an active user by collecting rating
information from other similar users or items [2].
In collaborative filtering by compiling preferences from several users, algorithms are used to make automatic
predictions about a user's interests. For example, a site like Amazon may recommend that the customers who
purchase books A and B purchase book C as glowing. This is done by comparing the historical preferences of
those who have purchased the same books [7].
2.2 Query Suggestion
Query recommendation aims to provide, users alternative queries, which can represent their information needs
more clearly in order to return better search results. Query suggestion is a valuable technique, in order to
recommend relevant queries to Web users and has been employed by some prominent profitable search engines,
such as MSN, Live Search, Ask and Google.
The goal of query suggestion is similar to that of query expansion, query substitution and query refinement,
which all focus on understanding users’ search purposes and improving the queries provided by users. Query
recommendation is closely associated to query development. Query Expansion extends the original query with
new search terms to slender down the possibility of the search. But query suggestion aims to recommend full
suggested queries, different from query expansion. Query refinement is another closely associated notion, since
the objective of query refinement is interactively recommending new queries related to a particular query [3].
2.3 Image Recommendation
Another interesting recommendation application on the Web besides query suggestion, is image
recommendation. Image recommendation systems, like Photoree focus on recommending interesting images to
Web users based on users’ inclination. Usually, these systems first put users to rate some images as they like or
dislike, and then based on the tastes of the users recommend images to the users. In the academia, a few tasks
are proposed to solve the image recommendation problems since this is a relatively new field and analysing the
image contents is a challenge job. Recently, in [8], by provide work for the Flickr data set, Yang et al. planned a
context-based image examine and approval method to improve the image search quality and recommend linked
images and tags. On the other hand, since it is a context-based method, the computational complexity is very
elevated and it cannot level to large data sets [8].
Ruling effective and efficient methods to search and recover images on the Web has been a widespread line of
research for a long time. The situation is even tougher in the research of Image Recommendation. [6]
2.4 Click Through Data Analysis
In, Web search logs are utilized to effectively organizing the clusters of search results by learning “interesting
aspects” of a topic and generating more meaningful cluster labels.
In the field of click through data analysis, the most familiar usage is for optimizing Web search results or
rankings [1]. In, a ranking function is cultured from the implicit feedback extracted from search engine click
through data to provide personalized search results for users. Besides ranking, click through data is also well
studied in the query clustering problem. Query clustering is a process used to discover frequently asked
questions or most popular topics on a search engine. This process is decisive for search engines based on
question-answering. Click through data has been analysed and applied to several interesting research topics,
such as Web query hierarchy building and extraction of class attributes [6].
III. COLLABORATIVE FILTERING
CF is widely employed algorithm in recommendation systems. It recommends products to the customer, based
on the rating of other customers who have similar product preferences.
Typically, recommender systems are based on Cooperative Filtering, which is a technique that automatically
forecasts the interest of an active user by gathering score information from other related users or items. The
fundamental statement of cooperative filtering is that the active user will prefer those items which other similar
users prefer. Collaborative filtering has been widely employed in some large, well-known profitable systems,
including product recommendation at Amazon movie recommendation at Netflix etc. Typical collaborative
filtering algorithms require a user-item rating matrix which contains user-specific rating preferences to infer
users’ appearances. Though, in maximum of the cases, score data are always inaccessible then information on
the Web is less organized and more different.
3.1 Overview of the Collaborative Filtering Progress
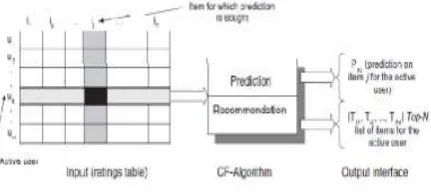
Collaborative filtering algorithm aims to suggest new items or to forecast the usefulness of a certain item for a
consequence, there is a list of m users U = {u1, u2,...um} and a list of n items I = {i1,i2,...in}. Each user Iui has
a list of items Iui, which the user has communicated his/her views. Views can be explicitly given by the user as
a score, usually within a positive mathematical scale, or can be implicitly derived from purchase records, by
analysing timing logs, by mining web hyperlinks and so on. Note that Iui ⊆ I and it is possible for Iui to be a
null-set. There exists a distinguished user Ua ∈ U called the active user for whom the task of a collaborative
filtering algorithm is to find an item likeliness that can of two forms [3].
3.11. Prediction
Prediction is a numerical value Pa,j , expressing the predicted likeliness of items ij ∉ Iu a for the active user ua .
This predicted value is within the same scale (e.g. from 1 to 5) as the opinion values provided by ua [3].
3.1.2 Recommendation
Approval is a list of N items Ir ⊂ I that the active user will like the maximum. Note that the Approved list must
be on items not already purchased by the active user i.e., Ir ∩Iu a = Φ
Fig 1: The Cooperative Filtering Method
Figure 1shows the schematic diagram of the cooperative filtering method. CF algorithms represent the entire m
n user-item data as a rating matrix, Each entry ai,j represents the preference score (ratings) of within a
numerical scale and it can as well be 0 indicating that the user has not yet rated that item [3].
Two types of cooperative filtering methods are widely studied: neighbourhood-based and model-based.
3.1.3 Neighbourhood Based Approach
P. Resnick et.al. [2] proposed user based approach that forecasts the ratings of active users based on the grades
of their related users. It uses Pearson Correlation Coefficient algorithm (PCC) and the Vector Space Similarity
algorithm (VSS) as the similarity computation methods. But, its disadvantage is accuracy of recommendation is
poor. It suffers with scalability problem. In item based item-to-item collaborative filtering matches each of the
users purchased and rated items to similar items, after that it combines those same items into a recommendation
list. In order to determine the most-similar match for a specified item, the procedure constructs a same items
table by finding the items that customers tend to purchase together. It is well with limited user data, producing
high quality recommendation [2].
3.1.4 Model Based Approach
In the based approaches to train a predefined model, training data sets are used. Examples of
model-based approaches include the clustering model, the aspect models and the latent factor model. Based on
hierarchical clustering Kohrs and Merialdo presented an algorithm for collaborative filtering, which tried to
balance robustness and accuracy of forecasts, particularly when limited data were accessible. Hofmann proposed
an algorithm based on a generalization of probabilistic latent semantic analysis to continuous-valued response
variables. Several matrix factorization methods have been proposed for cooperative filtering. These methods all
The premise behind a low dimensional factor model is that there is only a small number of factors manipulating
preferences, and that a user’s preference vector is determined by how each factor applies to that user. Although
collaborative filtering methods have been widely studied recently, maximum of these methods need the
user-item score matrix. Though, on the Web, in maximum of the cases, score data are always inaccessible since
information on the Web is less organized and more different. Later, cooperative filtering processes cannot be
directly applied to maximum of the approval tasks on the Web, like query recommendation and image
recommendation [1].
IV.
QUERY
SUGGESTION
Query suggestion is popular for web search engines. It refers to the process of suggesting associated queries.
While there are many works focusing on improving the relevance of associated queries, maximum of them
neglect to report the issue of providing different queries. Actually, the suggested queries should be both similar
to the original query and semantically different from each other so that they can cover broader latent topics.
Query recommendation, has been worked by some extended commercial search engines, such as MSN, Live
Search and Google in order to endorse applicable queries to Web users, a valuable technique. However, a few
public papers have been released to expose the methods they adopt due to commercial reasons. The goal of
query suggestion is similar to that of query expansion, query substitution, and query refinement, which all focus
on understanding users’ search intentions and improving the queries submitted by users [1].
Query suggestion plays an important role in improving the usability of search machines. Though some recently
suggested methods can make meaningful query suggestions by mining query patterns from examine logs, no one
of them are context aware - they do not take into account the immediately preceding queries as context in query
suggestion.
4.1 Query Sessions
A key aspect of data mining and its success in removing useful knowledge is the way in which the data is
represented. The context of a user query contains of the proximately prior queries issued by the same user. To
learn a context-aware query suggestion model, group of query contexts from user query sessions is needed.
Session data is constructed in three steps. First, from the whole search log extract each individual user's
behaviour data as a discrete stream of query/click events. Second, segment each user's stream into sessions
based on a widely-used rule: two consecutive events (either query or click) are segmented into two sessions if
the time interval between them exceeds 30 minutes. Finally, discard the click events and only keep the sequence
of queries in each session [9].
4.2 Concept Sequence Suffix Tree
Queries in the same session are often related. However, since users may formulate different queries to describe
the same search intent, mining patterns of individual queries may miss interesting patterns [9].
4.3 Online Query Suggestion
Differentiating query recommendations has developed recently, by which the suggested queries can be both
appropriate and different. Maximum main works expand suggestions by query log study, though, for organized
Typically, query suggestion is based on local and global document analysis, or anchor text analysis. Actually,
several different ranking methods using random walks can also be employed into the query suggestion tasks on
a query-URL bipartite graph, including PageRank, HITS, etc.. However, these traditional methods have
difficulty summarizing the latent meaning of a Web document due to the huge noise embedded in each Web
page which is not easily removed by machine learning methods. In order to avoid these problems, some
additional data sources are likely to be very helpful to improve the recommendation quality. In fact, click
through data is an ideal source for mining relevant queries [3].
Commercial search engines widely employs Query Suggestion technique to provide related queries to users
information need.
The objective of query suggestion is to provide a query suggestion feature in order to support the search engine
of a commercial web site. Starting from web server logs, our result makes a model analysing the queries
submitted by the workers. Specified a submitted query, the system examines the most satisfactory queries
to recommend.
V.
CONCLUSION
AND
FUTURE
WORK
Web information can be much improved by continuous efforts in development of new methods of mining web
graphs. Collaborative Filtering shows the better performance in accessibility of web information. Collaborative
Filtering techniques rely better efficiency in most of the factors. While Query Suggestion Technique is good but
not as Collaborative Filtering. In future we may perform such comparative studies for taking a decision
regarding choosing appropriate techniques. We may also work for improving these techniques by introducing
different processes of image recommendation & click through analysis.
REFERENCES
[1] Hao Ma, Irwin King et-al, "Mining Web Graphs for Recommendations", vol. 24, No.8, June 2012
[2] Shaik Moulali, Syed Abdul Haq, “Mining Web Graphs for Recommendations”, vol. 3, nov 2003
[3] K. Stephey Chrysolite, B. Krishna Sagar, “General framework on Mining Web Graph for
Recommendations”.
[4] G. Linden, B. Smith and J. York, “Amazon.com Recommendations: Item to Item Collaborative Filtering”,
IEEE Internet Computingpp.
[5] Shweta Shinde, Dr. V.H.Patil, “Mining Web Graph for Query Recommendation”.
[6] D. Thiyagarajan, N. Shanthi, M. Sathish kumar, “Graphic based Recommendation of Data for Mining the
Social Networking Sites”.
[7] http://www.techopedia.com/definition/1439/collaborative-filtering-cf
[8] Y.H Yang. P.-T. Wu. C. –W. Lee, K. –H Lin. W.H.Hsu and H.Chen, “ContextSeer: Context Search and
Recommendation at Query Time for Shared Consumer Photos,” Proc. 16th ACM Int’l Conf. Multimedia,
pp. 199-208, 2008.
[9] Huanhuan Cao, Daxin Jiang, Jian Pei et-al, “Context- Aware Query Suggestion By Mining Click Through