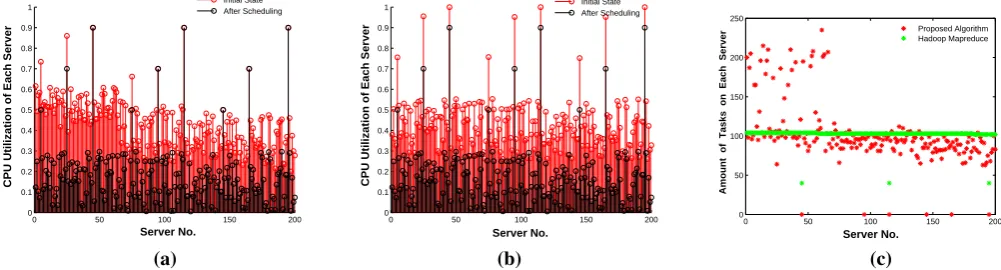
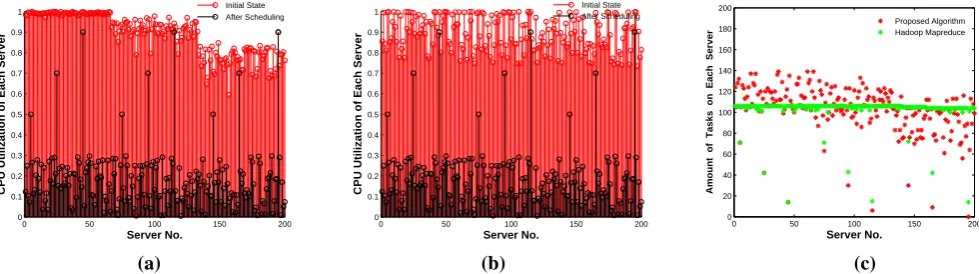
Energy-efficient task scheduling model based on MapReduce for cloud computing using genetic algorithm
Full text
Figure
Related documents
We find that most economic forces in our model, such as consumers’ price sensitivity, the scope for product di ff erentiation, and sunk costs of entry, are likely to induce
The aim of this paper is to present the findings from an initial study of the water levels and tidal properties derived from water level measurements made on various (15) islands
We tested two alternative hypotheses regarding the optimal conditions for inducing memory reconsolidation: (1) PE is necessary, but not suf- ficient: Reconsolidation is triggered by
The Dominican Republic has the responsibility to contribute to the international response to the Zika virus, not only by using traditional public health prevention measures such
Motivated by these results, our formulation of normal structure and its generalization can be applied to prove fixed point theorems for nonexpansive type mappings in normal
The experimental analysis shows that the multifractal features of return signals from three types of aircraft targets (including jet aircrafts, propeller aircrafts and helicopters)
quantum fields (Section 6), an extension of the local causal model of spacetime dynamics described in 408.. [ 7 ] and [ 4 ] and summarised in
The newly formed factor called "Sustainable corporate behavior focused on the satisfaction of employees" received a low score of -0.86 in this cluster analysis,
