Synchronization of Data and Resources in
Distributed, Cooperative Virtual Data Centers
Eun-Kyu Lee
Dept. of Information and Telecommunication Engineering Incheon National University, Incheon, Korea
Abstract. The cooperation is to reduce both capital and operational expenditures in running a data center while providing a greener solution. In the aspect of performance in such a distributed solution, performance can be improved by replicating the server and subsequently dividing the work. But, the main concern is keeping all replicas up-to-date, and we have observed a variety of synchronous and consistency models. This paper investigates a few synchronous schemes for a cooperative virtual data center between multiple entities which is founded on the principal of fair resource sharing among the entities.
Keywords: Virtual data center, cloud computing, reliability, fault tol-erance, synchronization
1
Introduction
Existing data centers are each individually owned and operated by a single entity. This situation creates an excessive financial burden upon each entity through the need to over-provision for hardware. While this state of affairs enables a secure and an efficient maintenance scheme for the data center, the financial drawbacks are perhaps excessive. Instead, we propose the idea of a cooperative virtual data center between multiple entities which is founded on the principal of fair resource sharing among the entities.
Conceptually, each data center can reduce the amount of over-provisioning of resources by cooperatively sharing computing power with other data centers. Since data centers generally have transient and predictable periods of peak load, it is conceivable that a data center can borrow computing resources, in the form of virtual machines, from other data centers which have spare resources for short-lived periods. Moreover, this form of cooperative sharing of computing resources provides a level of topographically distributed fault tolerance as the cooperating data centers may be geographically separated from one another.
The reduced provisioning of servers has the added benefit of diminishing operating costs through abating energy requirements and minimizing required support personnel. Furthermore, cooperative VDC enable the active use of idle resources thereby creating a green computing solution [6]. According to [3], co-operative VDC have the potential to tackle 85% of the current costs associated Advanced Science and Technology Letters Vol.110 (ISI 2015), pp.13-18 http://dx.doi.org/10.14257/astl.2015.110.04
2 E.-K. Lee
with running a data center in terms of servers, infrastructure, and power draw. Cooperative VDC, nonetheless, suffer from reliability issues that come from the fact that the cooperation runs on a distributed, multi-ownership environment. The main goal of this paper is to promote the feasibility of a cooperative virtual data center among several independent entities which can still maintain data reliably under minimal assumptions.
The paper is organized as follows. Section 2 provides the motivation and background behind our work and Section 3 introduce our proposed architecture with challenges. Section 4 discusses the main approach of our solution. Finally, Section 5 presents our conclusions.
2
Data Centers
It is worth noting that there are very few giant-sized data centers comprised of tens to hundreds of thousands of servers [7]. Most data centers are much smaller, on the order of hundreds to thousands of servers instead, run by mid-sized to small companies. Even with a few hundred servers, the financial commitment becomes a large burden for these more constrained companies. Data centers, on average, use far less resources than which they are equipped for. This is in large part due to the over-provisioning by data centers in situations of peak workloads, which are transient and often predictable. The redundancy which is provided for by data centers is unnecessary in most situations, but the operators of the data center must pay the cost of supporting this redundancy year-long. Energy costs for powering and cooling idle servers cannot be avoided in such cases.
3
Cooperation among Multiple Data Centers
The cooperation is to reduce both capital and operational expenditures in run-ning a data center while providing a greener solution. The perception of the cooperative virtual data center operates around the notion that a data center is capable of utilizing heterogeneous idle resources form other private data centers when needed in periods of peak workload in order reduce over-provisioning. This allows for a reduction in capital, thereby propagating to reductions in operational expenditures.
This form of cooperative resource sharing provides for better data center cost effectiveness. It is currently envisioned that there would be an alliance of a group of small to mid-sized companies which each have non-conflicting periods of known peak load. The alliance membership size is perceived as being no more than 10 to 20 participants, perhaps even less. Moreover, an added benefit of this scheme enables fault tolerance if the members of the alliance happen to have their data centers geographically segregated. This reconstruction the virtual data center breaks sharply from one proposed by [6] in the sense that the physical data centers which form a virtual data center are each individually operated by a separate entity which originates as part of a corporation’s private cloud. This differentiation, while minor changes the fundamental dynamics of data
Advanced Science and Technology Letters Vol.110 (ISI 2015)
Synchronization in Cooperative Data Centers 3
Internet Company A
Company B
Company C
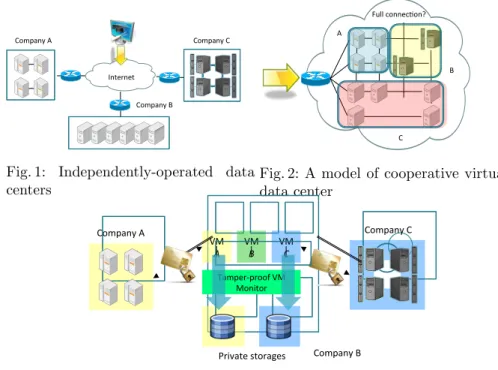
Fig. 1: Independently-operated data centers
Full connec)on?
C
B A
Fig. 2: A model of cooperative virtual data center
VM
A VM B VM C
Private storages
Company A Company C
Company B
Tamper-‐proof VM Monitor
Fig. 3: Realization of the cooperative virtual data center
center cost structures, financial risks, and utilization. Independently operated data centers will eventually move to a model of the cooperative virtual data centers where multiple data centers together build a single virtual computing platform by sharing their resources. Fig. 1 and Fig. 2 illustrate the transition.
Challenges. Cooperation among individual data centers while far more
ef-ficient than operating separate data centers does have a number of drawbacks. The most common issues with such distributed solutions range into the category of reliability. If a company needs to borrow resources from the collective pool and there are no resources available, then this can become a critical situation of under-provisioning. In such situations, the lack of reliability can have dis-astrous economic consequences. There must be a recovery mechanism in place when situations arise where communal resources are not available. Furthermore, synchronization issues between the data centers can also result in unreliable or unanticipated situations.
4
Synchronization of Replicated Data
The primary architecture underlying the cooperative virtual data center is shown in Fig. 3. Here we see three companies, A, B, and C, where company A and C are shown to be borrowing resources from company B through a leasing of virtual machines. Company A and C both store their private data on their own dedicated hard disks located within the storage area network (SAN) of
Advanced Science and Technology Letters Vol.110 (ISI 2015)
4 E.-K. Lee
companyB. It is expected that these disks would likely be placed into a more cost-effective iSCSI SAN connected to the physical servers using fibre channel host bus adapters, where each company is expected to provide their own hard disks. The choice here of using an iSCSI approach over that of fibre channel primarily involves the cost factor of deployment with commodity resources and the expected access patterns for the storage. Adoption of fibre channel can also be justified depending upon the expected needs of the system. Nonetheless, the actual underlying implementation of the SAN technology is up to the company hosting each private storage disk.
The virtual machine monitor (VMM) is responsible for ensuring that a run-ning virutal machine (VM) can only accesses disks which the VM owns. In this case,V MA, run by companyAcan only access the disk drives which companyA
has placed in companyB, henceforth,V MCwould not be able to access the disk
of companyA. In our proposed implementation, Xen1 is assumed to be the hy-pervisor used to perform these domain security validations and access checks to disk since it enables high performance buffered I/O transfers using asynchronous buffer-descriptor rings [1]. In the followings we focus on discussing our solutions to the reliability and synchronization issues with the solution.
Synchronization
Two primary reasons for replicating data among data centers are for reliability and performance. In the aspect of reliability, data centers can continue operating after one of their replicas crashes by simply switch to one of the other replicas; also, it becomes possible to provide better protection against corrupted data. In the aspect of performance, when the number of processes attempting to access data managed by a server increases, performance can be improved by replicating the server and subsequently dividing the work; additionally, a copy of data can be placed in the proximity of the process accessing the information to reduce the time of data access. However, main concern is keeping all replicas up-to-date.
Intuitively, a collection of copies is consistent when the copies are always the same, that is, a read operation performed at any copy will always return the same results. Consequently, when an update operation is performed on one copy, the update should be propagated to all copies before a subsequent operation takes place. Achieving such a tight consistency incurs high cost because updates need to be executed as atomic operations, and global synchronization is required. The synchronization scheme used in GFS [2] works this way with acceptable delay only because the replicas are stored within a local area of the primary copy which does not necessarily translate to the cooperative VDC case. The only real solution is to loosen the consistency constraints. Various consistency models have already been proposed and used for replication in distributed systems [8].
A simple synchronization scheme. Synchronization is done in two steps,
the first for detecting files that have been modified since the last run, and the second for propagating the updated data. In the worst case, i.e. when all nodes
1
http://www.xen.org
Advanced Science and Technology Letters Vol.110 (ISI 2015)
Synchronization in Cooperative Data Centers 5
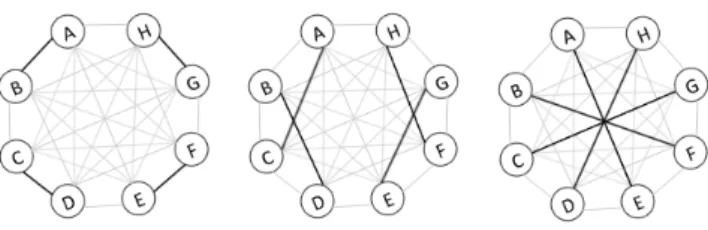
Fig. 4: Three rounds can synchronize eight nodes.
have updated files, an all-to-all communication is needed. In a naive approach, each node would send its updates to all partners, resulting in O(n(n−1)/2) updates. Each single connection would trigger an independent local disk access, provoking many updates concurrently and therefore resulting in a slow data transfer rate. To avoid this, [8] proposed an efficient synchronization scheme which uses only node-to-node (n2n) syncs. In this scheme, each node participates in at most one n2n sync at a time. Therefore, at most n/2 n2n syncs are run concurrently. Based on the fact that in each n2n sync a node propagates not only the modifications made to its own data, but also the modifications it received from other nodes in earlier rounds of the same sync. In [8], each node needs a maximum of log(n) n2n syncs in a complete graph. The sync process is given by a list of rounds of parallel n2n syncs. No barrier operation is executed between the rounds and therefore rounds may overlap. Fig. 4 depicts the synchronization of eight nodes. The process is split into three rounds. Each of them contains four parallel N2N syncs: {A → B, C → D, E → F, G → H}, {A → C, B → D, E→G,F →H},{A→E,B →F,C→G,D→H}.
Gossip in complete graphs. For optimal synchronization based on n2n
synchronization gossip algorithms [8] can be also used. The constant model takes only the startup cost of a connection into account. In the linear model the communication costcis proportional to the sizelof the data volume:c=β+lτ , whereβis the startup cost andτis the transfer time of a unit-length message.τ is assumed to be constant for all links. Determining a cost-optimal gossip plan for arbitrary graphs is an NP-hard problem [5]. We therefore simplify this problem by not supporting arbitrary graphs but only hierarchies of regular graph classes. Additionally, we treat network hubs like switches among data centers, thereby neglecting possible hub congestion. With these two restrictions, we can generates optimal plans for some classes of graphs, which are hierarchically composed by heuristics to allow for arbitrary networks. Complete homogeneous graphs can be used to model switched networks. For this purpose, we use the optimal algorithm described in [4]. It needs at most logn rounds in graphs with an even (resp. odd) number of nodes. Depending on the amount of updated repositories, the synchronization time varies between O(nlogn) for a one-to-all broadcast and O(n) for an all-to-all broadcast. Similar algorithms for other graphs like rings and busses are also known [4], but they are only optimal in the constant model where the link bandwidth is ignored.
Advanced Science and Technology Letters Vol.110 (ISI 2015)
6 E.-K. Lee
5
Conclusion
This paper proposed the idea of a cooperative virtual data center (CVDC) be-tween multiple entities, which is founded on the principal of fair resource sharing among the entities. This new architecture also enables a secure and an efficient maintenance scheme for the data center. To realize this novel architecture, we discussed the main reliability fault of a CVDC and corresponding agreement issues between data centers. From this, we proposed a new research direction to provide a certain level of resource availability and reliability. Therefore, based on our realization discussion, we believe that our architecture is feasible and will reduce capital and operational costs.
References
1. P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neugebauer, I. Pratt, and A. Warfield. Xen and the art of virtualization. InACM symposium on Operating systems principles, 2003.
2. S. Ghemawat, H. Gobioff, and S.-T. Leung. The google file system. InACM SOSP, 2003.
3. A. Greenberg, J. Hamilton, D. A. Maltz, and P. Patel. The Cost of a Cloud: Research Problems in Data Center Networks. ACM SIGCOMM Computer Communication Review, 39(1):68–73, January 2009.
4. J. Hromkovic, C. Klasing, B. Monien, and R. Peine. Dissemination of information in interconnection networks. InCombinatorial Network Theory, pages 125–212, 1995. 5. D. W. Krumme, G. Cybenko, , and K. N. Venkataraman. Gossiping in minimal
time. InSIAM J. Comput., pages 111–139, 1992.
6. E. M. Maximilien. Green Computing. University of California, Los Angeles, June 2009.
7. R. Miller. Who Has the Most Web Servers? http://www.datacenterknowledge. com/archives/2009/05/14/whos-got-the-most-web-servers/, May 2009. 8. T. Schutt, F. Schintke, and A. Reinefeld. Efficient synchronization of replicated
data in distributed systems. InPrentice-Hall Inc, 1995.
Advanced Science and Technology Letters Vol.110 (ISI 2015)