THE EFFECTS OF TRAINING AND VISUAL DETAIL ON ACCURACY OF
MOVEMENT PRODUCTION IN VIRTUAL and REAL-WORLD ENVIRONMENTS
Beverly K. Jaeger Virtual Environments Laboratory
Department of Mechanical, Industrial and Manufacturing Engineering Northeastern University
Computer-generated environments have been established as valuable training media for both proximal-field object manipulation and wide-area navigation performance. This study investigates the potential of virtual environments- based computer training for near-field navigation accuracy. Results of this investigation revealed significantly greater performance accuracy in a real-world setting for subjects that were first trained in a virtual environment. In addition, three levels of rendered visual detail were compared for precision of movement within a virtual hallway: (1) uutextured polygon surfaces, (2) untextured polygon surfaces with transverse floor gradient lines placed as visual cues, and (3) fully detailed textured surfaces. Significant effects were found for visual detail in accuracy of movement production. Within the virtual environment, performance error in the uudetailed setting was signifi- cantly higher as compared to the settings with visual cues and textures. Significant differences in real-world field performance were also found between the groups that were exposed to different levels of visual detail in computer training. Field performance was significantly superior for subjects trained with visual cues as compared to those trained in an uutextured virtual setting. Evidence suggests that for movement production accuracy both within a virtual environment and in the real world fully-detailed textured surfaces are not required in the rendered setting in order to obtain the best performance. Simple surface gradients serve as adequate visual cues for near-field navi- gation accuracy, while a lack of consistent visual cues can be detrimental to effective movement production.
INTRODUCTION
Presence Versus Spatial Knowledge Acquisition In virtual environments, many elements contribute to an operator’s sense of presence and immersion within the rendered setting. These elements typically engage the senses with visual detail, sound touch, and even motion providing a high level of multisensory fidelity with the actual world (Hendrix and Barfield, 1995; Wanger, Ferwerda, & Greenberg, 1992; Whi- taker, 1996; Williams, Wickens, & Hutchinson, 1994). For tasks possessing the objectives of accuracy in distance estima- tion, movement production, and performance transfer to the real world the required characteristics of the environment may differ from those contributing to the sensations of immersion, reality, and presence (Rolland, Gibson, & Ariely, 1995). In a study of fidelity and interactivity in navigational training Williams, et al., (1994) note that successful implementation of virtual environments technology requires careful analysis of the task and learning objectives. The considerations for transfer of training further extend to the magnitude and type of setting in which spatial knowledge acquisition occurs.
IVE Scales and Perception of Depth and Motion Because immersive virtual environments (IVES) provide the capabilities for interaction and viewer control, they have been used as training media for a variety of tasks (Wilson, Foreman, and Tlauka, 1997). Proximal-field applications in- clude direct manipulation tasks such as virtual surgery and training to operate hand controls. Aviation training and ship-
board navigation are examples of large-scale, or wide-area IVE applications. Driving simulators combine both such categories of scale. A third category termed near-jield virtual training incorporates IVl% for small-scale navigation accuracy in a local environment such as a room, building or small architec- tural complex. The value of virtual training systems for this scale and the necessary elements for transfer of training are yet to be determined
The human being utilizes a combination of sensory data to establish relative position within an environment. The primary sensory contributor for static distance estimation is visual input and associated cues of scale and depth (Gibson, 1986; Hendrix & Barfield 1997; Proctor & Van Zandt, 1994b; Surdick Davis, Ring, & Hodges, 1997). To detect and estimate auto- kinesthesis, or self motion, in any setting vestibular, proprio- ceptive, and kinesthetic feedback provide information about body motion and position and limb movement in space. In the absence of these internal dynamic spatial monitors, the visual system takes primacy as the leading source of relevant sensory information (James & Caird 1995; Piantanida, Boman, 62 Gille, 1995; Proctor & Van Zandt, 1994a). In an IVE, com- puter-generated visual input would be presented in the form of optic flow and combined with the existing scale and depth cues for movement production (James and Caird, 1995; Proctor & Van Zandt, 1994; Surdick et al., 1997; Williams et al., 1994).
Statement of the Problem
This study investigates the potential of virtual environ- ments-based computer training for near-jeZd navigation accu-
PROCEEDINGS of the HUMAN FACTORS AND ERGONOMICS SOCIETY 42nd ANNUAL MEETING-1998 1487
racy. The goals of this investigation were to (1) Determine whether training in a rendered 3-D environment significantly enhances performance in the actual near-field setting; (2) Iden- tify which level of visual detail results in the best performance accuracy in both the virtual and real-world settings.
While it is generally accepted that a virtual environment that is rich in sensory input and detail will lead to a more im- mersive experience, this is not necessarily true for the objec- tive of near-field spatial knowledge acquisition and navigation performance within the virtual setting. Since this multisensory impression of presence comes with a functional cost of ren- dering speed and its computational burden, our objective is to determine the minimally necessary and jointly sufficient char- acteristics of a near-scale training IVE in relation to transfer- ring the training to a real-world setting.
Spatial estimation in real-world settings is enhanced by the presence of texture gradients that form visual cues for depth and distance (Nagam1984; Proctor & Van Zandt, 1994b; Re- fan, Beverly, & Cynader, 1979; Warren & Riccio, 1985). Thus, we expect that spatial dis crimination within a virtual setting will be augmented by the perspective information provided by such cues. McGreevy & Ellis (1986) enhanced visual displays with similar spatial cues to facilitate depth perception. For this research, it is hypothesized that virtual environment experience will improve field performance. It is further hypothesized that parallel gradient lines on the ground surface will serve as vis- ual cues for the purposes of depth perception and spatial knowledge acquisition. We will investigate the performance outcomes for navigating within the virtual hallway and the transfer of this information to a real world setting.
METHOD Subjects
Sixty subjects, whose ages ranged from 19 - 40 years, par- ticipated in the study. The 39 male and 21 female subjects were graduate and undergraduate engineering students at Northeastern University. All participants had normal or cor- rected to normal vision. No special skills or background were required for participation in the study, however all subjects attested to having experience with computers.
Procedures
Through random assignment, one-half of the participants were tested on a computer-generated virtual environment first and then in the actual field setting. The other half were tested in the reverse order, training and performing in the real setting first and then in the virtual environment. The selected field setting was a specific hallway within the university campus tunnel system. The virtual hallway was constructed using dimensions, features, and colors matching those of the of the actual hall.
In both the IVE and field settings, subjects were asked to learn a predetermined distant% Galled the standard unit through practice sessions. During a practice session, each subject was given five trials to learn the standard unit. Alter the practice session, a run of 10 trials was conducted. In each run a subject was asked to travel 10 specific distances. The distances were requested in terms of the standard unit ranging incrementally from .5 to 5 standard units as distance prompts. To vary the
order of distance prompts, subjects were randomly assigned to one of six series. Each series contained all ten distances, but the order was different for each set of the 10 distances.
All subjects performed a total of 3 runs of 10 trials each: one run in the actual field setting, and two rum in the virtual environments setting. A practice session was conducted before every run. For each subject, all three rum were conducted using the same randomly-ordered series of distance prompts.
Field Environment Protocol. To learn the standard unit in the actual hallway, subjects walked from a specified starting point until the instruction to stop was given by the experi- menter. The experimenter had memorized the exact boundaries of the standard distance. There were no visibly-marked starting or ending points that were evident to the subjects. After five practice trials, the testing phase began. The subject was in- structed to travel the first of the requested distances in the assigned series. Subjects walked until they perceived that the requested distance had been traveled. They were allowed to adjust their position by moving forward and backward if de- sired A marker was placed at the resting location and the distance traveled was determined using a measuring wheel. This was repeated for each of the 10 trials within the field run.
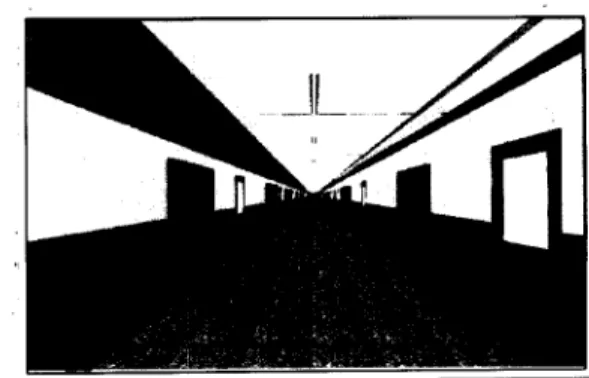
Virtual Environment prdocol. One-third of the subjects were exposed to a plain, uutextured setting; one-third navi- gated within a setting that had parallel gradient lines on the floor, and one-third moved within a detailed textured setting. The levels of detail are presented in Figures 1 and 2. To per- form in the computer-generated environment, subjects stood upright, viewed the hallway setting through an HMD (Figure 3) and traveled using a mouse as the method of advancement to simulate walking.
Figure 1. Virtual hallway: Gradient lines as visual cues. Horizontal gradients were absent in the untextured setting.
Figure 3. Subject navigating virtual hallway with walking simulator.
Experimental Design
The study used a 3 x 3 x 10 experimental design with one between-groups factor and two within subjects factors. Level of visual detail was a between-groups factor with three levels: untextured polygons, gradient lines, and textured polygons. The first within-subjects factor was type of run, VE Simulator Run 1, VE Simulator Run 2, or Field Run. The levels of the second within-subjects factor were the ten distances in stan- dard units that each subject was asked to ‘walk’. One standard unit equaled 20 feet (6.1 meters) but this was not revealed to the subjects.
Apparatus
The virtual hallway was constructed to scale using the Renderware@ 2.0 3-D graphics API, and viewed through a Virtual Research@ VR6 HMD. The display had a 60” hori- zontal FOV and 640 X 480 VGA resolution at 60 Hz. The scene was updated at a rate of 14-16 frames per second, pre- senting no perceptible display lag at the average walking ve- locity of 4.26 feet per second, The program was run on a system with a Pentium Pro 200 MHz Intel@ processor with 64MB of memory using the Windows@ NT 4.0 operating system. The application was configured to run at 800 X 600 resolution with 16-bit coloring, supported by an Imagine@ 128 II graphics acceleration card with 4 MB on-card memory.
Navigating Within the Virtual Environment
The rate of navigation was set at 4.26 feet per second, se- lected from the range of average walking velocities of normal male and female adults (Perry, 1992; Smidt, 1990). The HMD tracked head movement and the direction of navigation was controlled by aiming the mouse. Subjects could advance or reverse while depressing the left mouse button. The oontiuity of progression was controlled by pressing the left button to move and releasing it to stop. When the right mouse button was pressed, each estimate was entered and the experiment moved to the next trial. All navigation distances and times were automatically written to a data file by the computer.
RESULTS AND DISCUSSION General Analyses
A repeated measures (1 between and 2 within) ANOVA was computed on the measure of percent error for each dis- tance subjects were requested to travel. Raw error scores were transformed using the formula: 1% error1 = [(A-D)/AI, where D is the distance requested and A is the actual distance the sub- ject traveled in response to the distance prompt (Lampton, McDonald, Singer, & Bliss, 1995). Six different series were assigned to balance the order of distance requests presented to the subject in each run. In all analyses, there were no signifi- cant differences in performance on the basis of the randomly- assigned series number.
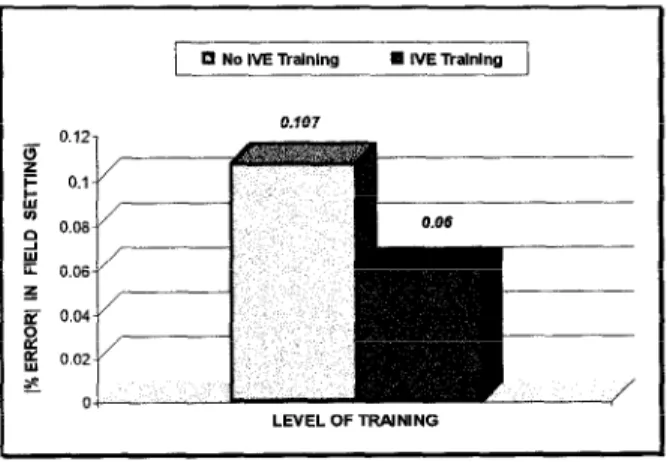
IVE as a Training Tool: The Effect of Order ANOVA found that the interaction of the two groups with order of exposure was highly significant, F(2, 98) = 5.304, ~~007). Sheffes post-hoc analyses revealed significantly supe- rior performance accuracy in the field setting for subjects that were first exposed to the virtual environment as compared to those who received no prior training (p<.Ol). Figure 4 com- pares performance accuracy in the field setting by order of exposure, where level of training represents the presence or absence of IVF, runs prior to the field trials.
0 No WE Tralnlng m WE Ralnlng 0.107 0.12 3 i= 0.1 L In 9 0.08 c 0.06 z H 0.04 8 6 002 D k
I
LEVEL OF TRBJNINGFigure 4. Percent error for IVE Training vs. No Training.
The error rate of the group that was tested in the field without any prior training was .107, while those who had VE Run #l and VE Run #2 before field testing had an error value of 06. This outcome suggests that the IVE training protocols contributed to improved field performance.
Level of Image Detail
Figure 5 shows percent error by level of visual detail for the first and second runs in the virtual environment. It was found that the main effect of rendered visual detail signifi- cantly influenced performance accuracy, both in the virtual environment and in the field setting, F(2,49) = 7.730, pCOO13.
The interaction of level of visual detail and type of run (VE Run 1 and VE Run 2) was significant, F(4,98) = 7.730, p<.OOOS. The percent error for the gradient lines condition was significantly lower than that of the untextured group for both VERun 1 andVERun2.
PROCEEDINGS of the HUMAN FACTORS AND ERGONOMICS SOCIETY 42nd ANNUAL MEETING-1998 1489
- 0 -VE Simulator Run 1 -C-E Simulator Run 2
04
“NTEXTVRED GRADIENT LINES TEXTURED LEVEL OF VISUAL DETAIL
L
- XV- Average Errorfor Wa NE Training -z+ NE Training
t
04
WTEXTURED GRAOIEW LINES TEXTURED
Figure 5. Performance in V!Z simulator runs: Percent error for three levels of visual detail.
In both the first and second W simulator runs, the groups that used visual gradient lines resulted in lower mean error measures than those of the textured group, but the differences were not significant.
A comparison of performance between the textured and untextured conditions revealed no significant differences. This suggests that in our WE, visual gradient cues were sufficient to generate movement accuracy that is equal to that of a fully- detailed textured setting. Note also that all groups exhibited a significant improvement in performance between the first and second VE run, providing strong support for progressive spa- tial learning within the virtual setting.
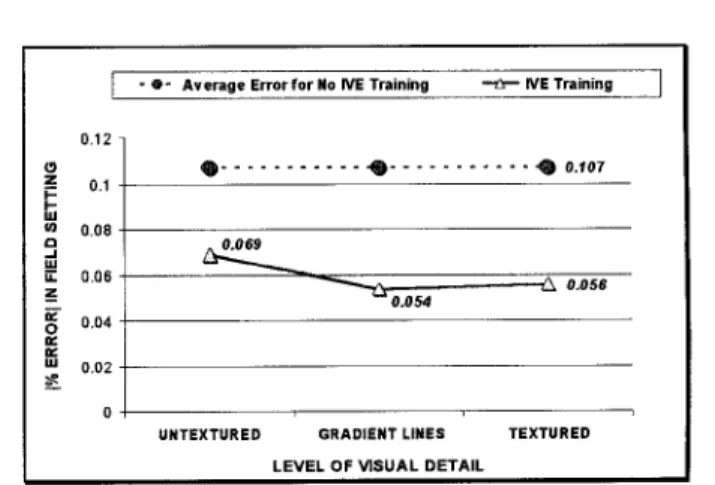
To determine whether the level of visual detail within the virtual training environment had a significant effect on subse- quent field performance, refer to Figure 6. The interaction effect of detail level by type of run was previously reported to be significant @ < .OOOS). The percent error in the field setting for each level of visual detail used in the preceding virtual training runs is presented in Figure 6. The error measures were ,069 for undetailed ,054 for gradient line cues and .056 for textured. This is compared to the average error of .107 for the group that was exposed to the field setting before the virtual runs. Post-hoc analysis of the interaction between level of detail and type of run verifies that errors in field performance were significantly lower for those who trained with visual gradients cues as compared to undetailed training, p < .05.
Performance differences between the group that trained with textured settings and the group with undetailed surfaces were not significantly different from one another at the 0.05 level. Finally, there were no differences in performance out- comes between the textured and visual gradient groups, sug- gesting that the horizontally-placed depth gradients serve as adequate visual cues to enhance training for field performance. James and Caird (1995) reported a similar outcome, reporting a difference between textured and polygonal worlds, but that neither was effective for conveying distance information within a 60 x 20 feet (18.3 x 6.1 meters) near-field setting. They concluded that the presence of texture gradient “may not be sufficient for accurate locomotion in virtual environments.” The results of this study support this conclusion for detailed surface texture, which is not more effective than the untextured condition. However, the presence of the visual gradient cues on the ground plane do appear to be more effective than the un- textured condition.
Figure 6. Performance in field setting: Percent error for IW training vs. no training and 3 levels of visual detail.
CONCLUSIONS
VE has the potential to be a valuable training tool for many performance-related tasks including way-finding, linear navigation, skill acquisition, and task-completion exercises (Bliss & Tidwell, 1994; Emhard< Semmler & Strothotte, 1993). If the salient features of sensory input can be identified, then these training methods and input dimensions may be included in spatial training exercises for tasks and procedures which involve operating in hazardous and risk-related envi- ronments. The potential beneficiaries and target population include: military personnel, law enforcement officers, fne- fighters, nuclear emergency teams, medical professionals and others who may need to acquire knowledge about a setting accurately and rapidly.
The initial phase of research in this project has revealed significant results supporting virtual environments training for distance estimation and movement production accuracy in the real world Results support the hypothesis that the level of visual detail affects movement accuracy within the IVE. For field performance accuracy as a result of IVE training evi- dence demonstrates that visual gradient lines in the horizontal plane are significantly superior to undetailed polygon surfaces within the virtual training media. However, no significant performance differences exist between gradient lines and com- plex textured settings. This finding suggests that the highest level of surface texture does not yield the most accurate dis- tance estimation within a near-field setting. These results are consistent with those of Surdick et al. (1997) who concluded that perspective cues of gradients, foreshortening and linear perspective were the most effective features for enhancing distance perception, and that adding additional depth cues did not necessarily enhance spatial perception. Note that textured settings did result in better field performance measures than the untextured settings at the . 10 significance level, suggesting that a high level of surface detail may be adequate for the purposes for spatial knowledge acquisition, but not necessary.
Since virtual environments computer training for accurate movement production does not require high levels of visual detail in the rendered environment, the case for IVE training is strengthened: Much time can be saved in the 3-D construction process; computer memory and thus computational power can be conserved, and smooth scene update and presentation will
More research is required to determine how the results of virtual environments training compare to the same number of training runs in the actual environment. This requires addi- tional training sets in the field setting. The process of data collection is currently under way to address this question.
While this study concentrated on linear navigation, previ- ous research has been done to assess the value of using IVE’s as a tool for transfer of training in geometric navigation in complex buildings and settings (Bailey, 1994; Bliss & Tidwell, 1994; Bliss, Tidwell, and Guest, 1997; Emhardt et al., 1993). Since spatial knowledge acquisition is shown to be enhanced by VE training further inquiries concerning the relevant input elements for this type of task should be investigated.
Finally, further research is recommended to explore the value of kinesthetic and vestibular input for movement- production fidelity. Provision of sensory information about the position of the head and limbs and the position of the body in gravitational space would assess the value of additional sen- sory modalities in IVE’s. These conditions may be applied to both linear and geometric navigation training protocols. Re- search is currently in progress to test the accuracy of real- world distance estimation and movement production conse- quent to VE training with a treadmill-based walking simulator. Virtual environments are a valuable tool for providing suffl- cient sensory input to assist in developing cognitive spatial models and facilitating psychomotor training. The precise nature and amount of input for a variety of task-specific objec- tives are still under investigation. Bliss, and Tidwell, (1994).
REFERENCES
Bliss, J.P., Tidwell, P.D., & Guest (1997). The effectiveness of virtual reality for administering spatial navigation training to firefighters. Presence, 6:I. 73-85.
Bailey, J.H. (1994). Spatial knowledge acquisition in a virtual environment. Dissertation #94267-45, Ann Arbor: UMI. Emhardt, J., Semmler, J., & Strothotte, T. (1993). Hyper-
navigation in virtual buildings. IEEE, 1,342-347. Gibson, J.J. (1986). The Ecological Approach to Visual Per-
ception. Hillsdale, NJ: Erlbaum.
Her&ix, C. & Barfield, W. (1997). Spatial discrimination in three-dimensional displays as a function of computer graphics eyepoint elevation and stereoscopic viewing. Human Factors 39:4,602-617.
Hem&ix, C. & Barfield, W. (1995). Presence in virtual envi- rormtents as a function of visual and auditory cues. IEEE,
1,74-82.
James, K.R. & Caird, J.K. (1995). The effects of optic flow, proprioception, and texture on novice locomotion in vir- tual environments. Proceedings of the 3Yh Human Factors and Ergonomics Society, 1405-1405.
Lampton, D.R., McDonald D.P., Singer, M., & Bliss, J.P. (1995). Distance estimation in virtual environments. Pro-
ceedings of the 3gh Human Factors and Ergonomics Soci- ety, 1268-1272.
McGreevy, M. W. & Ellis, S.R. (1986). The effect of perspec- tive geometry on judged spatial information instruments. Human Factors, 22,439-456.
Nagata, S. (1984). How to reinforce perception of depth in single two-dimensional pictures. Proceedings ofthe Soci- e&for Information Display, 2.5:3,239-246.
Perry, J. (1992). Stride Analysis. In Gait Analysis. New Jer- sey: Slack Inc., 431-441.
Piantanida, T., Boman, D.K., & Gille, J. (1995). Human per- ceptual issues and virtual reality. Virtual Reality Systems, 43-52.
Proctor, R. W. & Van Zandt, T. (1994a). “Sensory input” in Human Factors in Simple and Complex Systems. Boston Allyn & Bacon, 8 l-86.
Proctor, R. W. & Van Zandt, T. (1994b). “Perception of ob- jects in the world” in Human Factors in Simple and Com- plex Systems. Boston: Allyn & Bacon, 131-158.
Refan, D., Beverly, K., & Cyander, M. (1979). The visual perception of motion in depth. Scienti$c American, 24. Rolland J.P., Gibson, W., & Ariely, D. (1995). Toward
quantifying depth and size perception in virtual environ- ments. Presence, 4:1,24-49.
Smidt, G. (1990). Rudiments of Gait: Spatial and temporal factors. In Gait in Rehabilitation. NY: Churchill Living- stone, 9-19.
Surdick, R.T, Davis, E.T., King, R.A, & Hodges, L.F. (1997). The perception of distance in simulated visual dis- plays: A comparison of the effectiveness and accuracy of multiple depth cues across viewing distances. Presence, 6:5, 513-531.
Wanger, L.R., Ferwerda, J.A., & Greenberg, D.P. (1992). Perceiving spatial relationships in computer-generated im- ages. IEEE Computer Graphics &Applications, 5,44-58. Warren, R. & Riccio, G.E. (1985). Visual cue dominance
hierarchies: Implications for simulator design. Society of Automotive Engineers, Technical Paper #851946. War-
rendale, PA: Society of Automotive Engineers.
Whitaker, L. (1996). Getting arotmd in the natural world Er- gonomics in Design, July, 10-15.
Williams, H.P., Wickens, CD., & Hutchinson, S. (1994). Fidelity and interactivity in navigational tminin&$ A com- parison of three methods. Proceedings of the 38 Human Factors and Ergonomics Society, 1163-l 167.
Wilson, P.N., Foreman, N., & Tlauka, M. (1997). Transfer of spatial information from a virtual to a real environment. Human Factors 3914, 526-53 1.