Design and Implementation of a POSIX Compliant Sporadic Server
for the Linux Kernel
∗
Dario Faggioli, Antonio Mancina, Fabio Checconi, Giuseppe Lipari
ReTiS Lab
Scuola Superiore Sant’Anna, CEIIC
via G. Moruzzi 1, 56124 Pisa (Italy)
{
d.faggioli, a.mancina, f.checconi, g.lipari
}
@sssup.it
Abstract
Increasing interest for real-time support in general purpose operating systems has driven a lot of development efforts inside the Linux kernel community. Thus, a Linux based system may be a suitable platform to run heterogeneous real-time and non real-time, periodic and aperiodic applications.
Linux is a POSIX/Unix-like system, so real-time tasks are supported by means of the well established and powerful techniques of fixed priority preemptive scheduling. When dealing with real-time aperiodic tasks under fixed priority scheduling, an effective mechanism that provides fast response time without affecting the scheduling of the periodic tasks is the Sporadic Server. Such an algorithm is also part of the POSIX real-time extensions, but it is not yet supported by the Linux kernel.
For all these reasons, we implemented the POSIX SCHED SPORADIC scheduling policy in the Linux
kernel, after having extended it to support hierarchical scheduling. Moreover, since we think this could be a useful feature, we are also submitting it to the community, asking for inclusion in the mainline kernel distribution. In this paper we describe our motivations, the implementation and some preliminary experimental results.
1
Introduction
All around us we can find a great number of real-time systems, silently running even right now, and even if we are unaware of them. For example, think about flight control and defense systems, that have to respect timing constraints dictated by the con-trolled environment and by the validity of the sensor-acquired data. Moreover, there also are systems where the timing constraints come from the need to provide the user with a good level of Quality of Ser-vice (QoS), for example multimedia and streaming applications, video games, entertainment systems, etc.
Real-time workloads are known to need pre-dictability rather than throughput or fairness. Thus, they need to run on computer systems where all, in-cluding the operating system behavior, is fully pre-dictable as well. There exist many commercial or research kernels where this is done at the maximum
possible extent, e.g., VxWorks or Erika, and SHaRK or MarteOS [5, 8, 4, 9]. The issue with them is that they provide a special execution environment, able to run only a small set, and sometimes even one sin-gle application for whom they have been configured. Conversely, especially because of the dramatical in-crease in the performances of microprocessors and other hardware devices, it is becoming common to integrate real-time support in the so-called general purpose operating systems. This way, the large num-ber of off-the-shelf available software can be used for user interface or other non real-time activities. In these cases, although full predictability of all kernel code paths is often impossible to guarantee, it is re-quired that the operating system introduces as low as possible overhead, so that the additional latency the real-time activities have to pay is reduced to its min-imum extent. If this is done, supporting soft, and perhaps also some of the hard real-time workloads could become possible.
∗This work has been partially supported by the European projects FRESCOR FP6/2005/IST/5-034026 and IRMOS
With this respect, Linux is becoming the pre-ferred choice, due to the fact it has an open source license, a huge base of enthusiastic programmers, it is available for an astonishing number of architectures and there are thousands of applications running on it. Furthermore, the Linux kernel is also being en-riched with more and more real-time capabilities [18], usually proposed as separate patches, that are pro-gressively being integrated into the main branch. For example, some developers are maintaining the rt−preempt patch, which greatly reduces the non preemptable code sections, thus lowering the worst-case latencies. Moreover, the support for priority in-heritance has been added and can also be extended to in-kernel locking primitives, and a great amount of interrupt handling code is moved to schedulable threads.
Alternatively, more invasive modification of the Linux kernel exists as separate projects, e.g., RTLinux, RTAI and Xenomai [11, 12, 14]. They all share a common approach, that is they introduce a layer between the OS and the hardware, with the aim of totally separating the time and the non real-time execution environments. Some more details on each of them follows.
RTLinux originally developed by Victor Yodaiken at the New Mexico Institute of Mining and Technology, it consists of a small real-time ker-nel running alongside an unmodified version of the Linux kernel which runs at the lowest pri-ority.
RTAI the Real-Time Application Interface born at the Politecnico of Milan. It adopts a similar approach to RTLinux, by means of the Adeos patch [27] and a slightly modified version of Linux.
Xenomai overtook RTAI since it provides a much cleaner and more elegant code structure and interface, but it suffers from a slightly higher worst-case latency when comparing IRQ dis-patching and syscalls. However, this is negligi-ble with respect to the advantages that come, as far as tracking problems and enriching the code with ports to new architectures are con-cerned.
Coming back to theoretical real-time issues, huge amount of research has been carried out on real-time scheduling, and it is now possible to design a sys-tem that is guaranteed to meet its timing constraints. The most analyzed theoretical model is made up of a set of periodic activities, i.e., tasks to be performed at some specified and usually constant rate. One well established framework, dating back to 1970 [29], that
has been proposed to tackle the issues raised by this situation is the preemptive fixed priority scheduling theory. Obviously, real-time systems, especially in embedded and control environments, may contain both periodic and aperiodic activities, and fixed pri-ority scheduling theory has been extended to also be able to deal with that.
The real-time extensions to the well known POSIX [3] standard support fixed priority preemp-tive scheduling too, when they come to real-time scheduling. Using the API provided by those exten-sions (POSIX.1b) it is possible to write complex real-time applications that will result in being portable to a large variety of different operating systems. The existence of the POSIX real-time extension and the fact that workstation operating systems (and among them, Linux) are supporting large chunks of it, is a clear example of successful efforts in pushing real-time into general purpose kernels.
Anyway, to deal with real-time aperiodic activities, the POSIX standard suggests to use a variant of the Sporadic Server algorithm, an effective solution that as been thoroughly studied and analyzed along years. However, this (optional) extension is supported only in few readily available operating systems that claim to be POSIX compliant, probably because of some concerns about implementation complexity and run time overhead.
The remainder of the paper is organized as fol-lows: Sec. 2 gives needed background on real-time systems and briefly goes through related works. Sec. 3 summarized the POSIX real-time extensions and the aim of Linux toward them. In Sec. 4 we describe in details our design and implementation work and, finally, in Sec. 5 we show some simulation results and illustrate our detailed test plan. Sec. 6 draws the conclusions and suggests some future works.
2
Background and
Related Work
In this section we provide what we believe it is a nec-essary background on real-time systems, especially w.r.t. fixed priority scheduling. We also talk about the related works and about the few other implemen-tations of Sporadic Server in general purpose and real-time operating systems.
2.1
Real-Time Systems Basics
A real-time system can be defined as a set of activ-ities with timing requirements: a computer system the correctness of which depends not only on the correctness of the computation results, but also on
on the time instant at which those results are pro-duced. Due to thistime consciousness characteristic the CPU scheduler of a real-time operating system (RTOS) is demanded to achieve predictability more than absolute throughput or any other performance metric.
In some more details there exist hard real-time systems, completely falling through if failing to re-spect the timing constraints they are subjected to.
Soft real-time systems, on the other hand, can toler-ate some guarantee miss to happen, considering these events only temporary failures.
Hard real-time systems are used in critical activities, nuclear power plants, flight control systems, etc. Soft real-time systems typically are non critical systems, such as multimedia, entertainment or communica-tion systems.
2.1.1 Real-Time Scheduling
In real-time scheduling literature each activity is usu-ally called a task1, and the
i-th task is called τi.
Each task consists of a stream of jobs, Ji,j (j =
1,2, . . . , n) and each job is characterized by an ar-rival time, ai,j, an execution time, ci,j, a finishing
time, fi,j, an absolute deadline, di,j, and a
rela-tive deadline, Di,j = di,j −ai,j. A hard real-time
task is also characterized by a worst case execu-tion time (WCET), Ci = max{ci,j}, and a
mini-mum inter-arrival time (MIT) of consecutive jobs,
Ti= min{ai,j+1−ai,j}. A task is periodic ifai,j+1 =
ai,j+Ti for any jobJi,j, otherwise it is called
spo-radic. For all the hard real-time tasks in the system
fi,j≤di,jmust hold for any jobJi,j, to avoid critical
failures. Usually, knowing a-priori (Ci, Ti) for each
hard-real time task i is sufficient to perform some kind of feasibility analysis and guarantee timely be-havior in all the possible situations. As said, for soft real-time tasks some deadline misses (fi,j≥di,j) are
tolerated. Usually hard real-time task are periodic activities, while soft real-time ones issue requests of job activation in an aperiodic or sporadic fashion.
Scheduling a real-time systems means trying to find an order of execution of all the jobs of all the tasks, even interlaced one with another if preemption is enabled, so that any of them meets its deadline. 2.1.2 Fixed Priority Scheduling
Real-time scheduling algorithms often use the con-cept of priority: a property assigned to each task to account for its relative importance in the system. The algorithm chooses which task to serve on the ba-sis of its assigned priority. We can distinguish fixed priority algorithms, where the priority assigned to
each task does not (automatically) vary along the task lifetime, and dynamic priority algorithms, where priority may vary from time to time.
An example of an on-line fixed priority schedul-ing algorithm is the Rate Monotonic (RM [29]) al-gorithm, where each task τi is given a priority pi
inversely proportional to its period: pi = T1i. Some
important results have been derived for the RM algo-rithm. For example it has been shown that RM pri-ority assignment is optimum. Furthermore, defined
Ui = CTii as the processor utilization factor for the
taskτi, it is guaranteed that a feasible RM schedule
exists if: U = n X i=0 Ui= n X i=0 Ci Ti ≤n·(2n1 −1) or if [25]: n Y i=1 Ui≤2
Since this worst case utilization bound decreases monotonically down to 0.693 (ln(2), asnapproaches infinity), this means that, with RM, the total uti-lization of the processor shall not overcome 69%. However, this is only sufficient condition and it is quite pessimistic, since such a worst-case task set is contrived and unlikely to be encountered in prac-tice. To know if a set of given tasks with utilization greater than the worst case least upper bound other tests exists and can be found in [31]. This is the ex-act schedulability criterion for independent periodic tasks under RM and it is less pessimistic than the previous one, but it is more complicated and time consuming if you want to implement it and run it on-line.
On the other hand, one of the most known dy-namic priority scheduling algorithm is the Earliest Deadline First (EDF [29]) algorithm. In EDF, the taskτi with the job with the earliest absolute
dead-linedi is assigned the highest dynamic priority. It is
well known that EDF, thanks to the dynamic priority assignment, is able to provide 100% CPU utilization, while RM only can guarantee a fraction of that.
Notice that also possible contention situations among the various tasks, e.g. for acquiring the lock on a shared resource, should be taken into account, and that there exist protocols and theoretical for-mulations for this. Examples are the Priority In-heritance or Priority Ceiling (PIP and PCP, [30]) protocols, but it is beyond the scope of this paper to describe them.
Even if comparing fixed and dynamic priority al-gorithm is not among our intents (if interested in, it can be found in [24]) it is worth saying that, even
if being less “utilization efficient”, Rate Monotonic is simpler to implement (the number of priority lev-els is bounded and usually low). For example, it can be implemented efficiently by splitting the ready queue into several FIFO queues, one for each priority level. On the other hand, implementing EDF could be quite complex, since absolute deadlines change from a job to the other and the new priority needs to be computed at each job activation, reordering the ready queue.
These could some of the reasons why the POSIX real-time extensions (IEEE Std 1003.1b-1993) only pre-scribes fixed priority scheduling to be implemented. 2.1.3 Hierarchical Scheduling
Hierarchical scheduling generalizes the capabilities of CPU schedulers, by allowing them to schedule not only tasks but also other schedulers. Within the greatest possible generality, each of the schedulers can be different from the others and able to enforce its own policy and rules for the entities, i.e., tasks and other schedulers, that it is in charge of.
However, it is also common to restrict these ca-pabilities a little bit, for example by the constraint that all the schedulers in the hierarchy have to act ac-cording to the same algorithm. This way the concept of hierarchical scheduling collapses into the so-called multiserver scheduling or group scheduling as well, as a scheduler collapses into a task group (or server). What happens is that each entity to be scheduled can be either a task or a group of tasks, and it still is provided with the characteristic parameters of the chosen scheduling algorithm. This means each entity will have a fixed priority if a group version of Rate Monotonic is being used, or alternatively a deadline, if EDF is in charge.
Whenever a scheduling decision has to be taken, we start from the root of the hierarchy and the rules of the algorithm are applied to chose one of the entity. As one can imagine, if the picked up entity come to be a task group, the same operation is performed recursively, until an entity which is a task is selected. Notably theoretical results exist for truly hierar-chical and group scheduling as well, for example the ones illustrated in [26]. Unfortunately, they are quite complex to describe, and going into their details is out of the scope of this paper.
2.1.4 Aperiodic Task Scheduling
As it can be easily seen, all the considerations of the previous Sections apply at their best if tasks are per-fectly periodic activities. This could be quite com-mon in hard real-time environments, but is an unac-ceptable constraint for soft time or mixed
real-time and non real-real-time systems. Furthermore, also in hard systems, sporadic or even aperiodic activities may be present, for example for servicing interrupt requests from hardware devices, or to handle non critical tasks, user interfaces and alike.
In those situations, the main concern is typically twofold:
1. guarantee that aperiodic/sporadic activities are not jeopardizing the guarantees provided to periodic tasks;
2. be able to execute the aperiodic/sporadic ac-tivities providing them with fast response time, either for each instance and on average. Actually, fixed priority scheduling suffers from some issues with respect to this, since it has been proved [15] that there is no algorithm that can minimize the response time of every aperiodic request and yet guarantee schedulability of the periodic tasks.
Anyway, since we are interested in fixed prior-ity scheduling of mixed periodic and aperiodic task sets, we describe, in the following paragraphs, some of the proposed algorithms and strategies that make it possible to integrate aperiodic task scheduling in the Rate Monotonic algorithm. For all of them (with the only exception of background service) the idea is to create anaperiodic server, i.e., a task that is sched-uled together with the periodic tasks of the system and that gives the aperiodic requests a chance to run. This usually is achieved by considering one or more new tasks with periodTsand abudgetQs(both
specified in time units). When a periodic or sporadic task wants to run, its execution request is queued, and it is satisfied only when the server is scheduled. Furthermore, as long as the aperiodic task execution proceeds, the budget of the aperiodic server is dimin-ished by the same amount, until it reaches zero. At that point in time the server usually is no longer con-sidered a ready to run task. The strategy with which the budget gets replenished and the server is reac-tivated is what characterizes the specific algorithm and what determines its properties, advantages and drawbacks.
Background Service A trivial solution is to only execute aperiodic tasksin background, i.e., when the CPU is idle because all the released periodic jobs already have been completed for their current execu-tion period.
This typically is very simple to achieve and does not affect scheduling guarantees provided to periodic tasks. Obviously, if periodic load is high, the uti-lization left for background service may be small, and background service opportunities relatively in-frequent.
Polling Server A Polling Server (PS) is a periodic task used to serve aperiodic requests. At regular in-tervals, the PS task is started and it services pending requests, if there are any. Otherwise it is suspended until the next period. Note that if requests occur while the task is suspended, they have to wait until the next activation of the PS.
The algorithm can be used without modifying the Rate Monotonic scheduling analysis, and we sim-ply have to add a new periodic task with the period of the PS and the worst case execution time equal to its budget. The main drawback is that aperiodic response times can still be quite long.
The closed formula that can be used to com-pute the response time of an aperiodic execution request, if arrived at ra with a computational
de-mand known to be Ca, and served by means of a
Polling Server with period Ts and budget Qs is:
ra+Ts+ (⌊CQas⌋+ 1)·Ts
Deferrable Server The Deferrable Server (DS [20]) algorithm is similar to Polling Server, the only difference being the fact that it preserves its budget even if no aperiodic requests are pending (bandwidth preserving property). Since DS retains the budget, aperiodic requests can be served anytime as long as the budget itself has not been exhausted. When this happens, the server is no longer eligible, and so further aperiodic requests have to wait until the budget is replenished, at the very beginning of the next period.
Thus, the DS algorithm can provide better ape-riodic responsiveness than PS, and it is also still easy to implement. However the price for this is a schedu-lability penalty, in terms of lower schedulable uti-lization bound. In fact, if a DS withUsutilization is
used to serve aperiodic requests, the Rate Monotonic asymptotic least upper bound the periodic load has to stay below varies toward:
ln( Us+ 2 2·Us+ 1
) which is worse than the previous one.
Sporadic Server Sporadic Server (SS [28]) is a variation on the Deferrable Server with a capacity planning mechanism that make it possible to con-sider an SS task as a supplementary periodic task with period and execution time equal, respectively to the period and the budget of the server.
Basically SS only replenishes its budget after ei-ther some or all of the execution time is consumed by aperiodic tasks, and its particular method of replen-ishment scheduling is what sets it apart from other algorithms. In more details, what it is important
to determine is the time at which a replenishment has to occur and how much of the budget should be recovered. This happens according to the following rules, for a Sporadic Server task SSS = QTSSSS with
prioritypSS:
1. if the server still has available budget and the priority of the running task is greater or equal to pSS, replenishment time RTSS is set. The
value ofRTSS is the current time plusTSS;
2. the amount to be replenished at RTSS is set
when the priority of the running task becomes lower than pSS, or when the budget is
ex-hausted. At that time the budget will be re-plenished by the time consumed from the last instant when the priority of the running task changed from lower to higher than pSS, and
the current time.
The main advantage of SS over PS is the band-width preserving property. In fact, SS is often able to provide immediate service to an aperiodic task. But that property also has some drawbacks, and the reason why SS is preferable to DS is that it is able to compensate for them, thanks to its replenishment strategy. So we can say that Sporadic Server has some clear advantages toward DS and PS, while the least upper bound of the sufficient schedulability re-gion is (n+1)·(2n1+1−1), where then+1 accounts for
the fact that the SS is considered a supplementary periodic task.
Furthermore, the performances of SS, as regard-ing the aperiodic tasks response time, are compara-ble with the ones provided by DS, as it is reported by many studies [28, 24]. SS also reduces replenishment overhead, since no replenishment is scheduled until the budget has been fully consumed.
2.2
Related Work
Since we are implementing the POSIX
SCHED SPORADICscheduling policy in the Linux ker-nel we are interested either in any other OS sup-porting it, or in prior works performed on the Linux kernel (or its variants) and dealing with sporadic servers.
Among commercial operating systems, support forSCHED SPORADICis claimed only by two of them: the QNX Neutrino Microkernel and the Real-Time Executive for Multiprocessor Systems (RTEMS). QNX is a POSIX-compliant RTOS aimed primar-ily at the embedded, especially automotive, systems market. It is microkernel-based and the OS runs in a number of small user-space servers.
real-time environment for embedded critical applica-tions. It exports many different API, among with one that adheres to POSIX 1003.1b.
Regarding previous attempts of implementing
SCHED SPORADICin Linux or any of its variants, we have been able to find out some work on RTLinux [1, 23]. Both of them describe the implementation of the scheduling policy in the RTLinux kernel, with [1] also considering many other fixed priority aperiodic server algorithms (Deferrable Server, Slack Stealer and Priority Exchange) but, despite that, the present RTLinux distribution still does not include POSIX
SCHED SPORADIC scheduling. Anyway, we are quite convinced that it is not possible to compare these two works with our one. In fact, the Linux kernel and the RTLinux hard real-time executive layer are com-pletely different environments, where different imple-mentation related solution have to be adopted and different behavior and performances can be achieved. there exist two recent works, regarding the imple-mentation of SCHED SPORADICin the standard Linux kernel: [16, 21]. This reinforces our persuasion that this is eventually becoming quite an interesting topic inside real-time community.
Anyway, we think our work is quite different from them two, mainly because of the following reasons:
• we are proposing a slightly extension of the se-mantic of the policy rules, so that they become applicable to a hierarchical system. In fact, our implementation affects the Linux group scheduling infrastructure and make it possible to create SCHED SPORADIC task groups (more on this in Sec. 4.1). Neither [16] nor [21] deal with this.
• Since Linux is a multiprocessor capable ker-nel, our code has been designed and tested to not interfere with how real-time multiprocessor scheduling is implemented in Linux, and to be fully SMP-safe.
Other minor differences are:
• the code provided by [16] and [21] are patches to be applied on top of some specific version of the kernel. Rather, we are tracking the current developing of Linux and continuously updat-ing our patch to be applicable to the very last status of the code.
• we have released our code and submitted it to the community on the Linux Kernel Mailing List (LKML), so to get useful comments and suggestions.
Indeed, our aim is to try to get theSCHED SPORADIC
scheduling policy merged in the mainline kernel
dis-tribution, if we are able to convince other developers that it could be an useful feature to have.
Finally, [10, 22] are research papers where, the support for SCHED SPORADIC in the Linux kernel is advised as a valid mean of fitting device drivers and hardware handling routines into analyzable schedul-ing framework. [17] reports some preliminary works on Sporadic Server algorithm used together with hi-erarchical scheduling.
3
The POSIX Standard
POSIX stands for Portable Operating System In-terface and is the collective name of IEEE 1003 (or ISO/IEC 9945) family of standards, jointly devel-oped by the IEEE Portable Application Standards Committee (PASC) and the Austin Common Stan-dards Revision Group (CSRG) of The Open Group. It dates its starting back to the mid-1980s.
The last version is, formally, The Open Group Base Specifications Issue 6, or IEEE Std 1003.1, 2004 Edi-tion, but it is also still referred to as POSIX as well.
3.1
POSIX Real-time Extensions
It was in 1998 that IEEE Std 1003.13-1998, the first POSIX real-time profile was published. More re-cently, in Std 1003.1-2001 the X/Open System In-terface (XSI) extensions, grouped together to form the so-called XSI Option Groups have been defined. Nowadays, a compliant XSI implementation has to support at least the following options:
• file synchronization,
• memory mapped files,
• memory protection,
• threads,
• thread synchronization,
• thread stack address attribute and size; and may also support a bunch of other option groups: Real-time asynchronous, synchronized and prior-itized I/O, shared memory objects, process and range based memory locking, semaphores, timers, real-time signals, message passing, pro-cess scheduling;
Advanced Real-time clock selection, process CPU-time clocks, monotonic clock, timeouts, typed memory objects;
Real-time Threads thread priority inheritance and protection, thread scheduling;
Advanced Real-time Threads thread CPU-time clocks, thread sporadic server, spin locks and barriers.
The SCHED SPORADICscheduling policy we have implemented is part of both theReal-timegroup and theReal-time Threads group, as an optional part of process scheduling and thread scheduling.
3.2
POSIX Scheduling
POSIX describes CPU scheduling by means of the concept of task lists. There shall be many different
priorities and one task list for each priority. There also shall be different scheduling policies, and for each of them, different handling of this set of lists can occur. Each policy is also associated with a pri-ority range.
A conforming implementation is required make the task which is at the head of the highest priority non-empty task list to become a running task. This means tasks can only be preempted by other tasks if the latter are in a task list of higher priority than the one where the former is.
The following scheduling policies are defined (SCHED SPORADICis optional):
• SCHED FIFO • SCHED RR • SCHED SPORADIC • SCHED OTHER
Below, we describe in some details the three real-time scheduling policies. The fourth policy,SCHED OTHER
is the one that is commonly used to schedule non real-time tasks and dealing with it is out of the scope of this work.
SCHED FIFO Tasks underSCHED FIFOare scheduled choosing them from a task list where they are or-dered by the time they arrived on it. Generally, the head of the list, for each priority, is the task that has stayed on that list for the longest time. When a
SCHED FIFO task is preempted, it becomes the head of its own task list; when it becomes blocked or yields execution, it becomes the tail.
All this means that the highest priority task hav-ing this schedulhav-ing policy is allowed to run undis-turbed until it blocks, voluntary relinquish the CPU or completes.
SCHED RR Tasks under SCHED RR are scheduled identically to SCHED FIFO ones. They only have to fulfil the additional constraints that, after having ex-ceeded a maximum execution quantum, the running
task becomes the tail of its task list, and the task at the head of it shall become the running one. The duration of the quantum is implementation defined. This guarantees that, if there are multiple
SCHED RRtasks at the same priority, one of them does not monopolizes the processor.
SCHED SPORADIC SCHED SPORADIC is particularly interesting to us, since it is the one that is missing in Linux and that we have implemented. For this reason we describe it with a little more details than the previous two.
For this policy to be implemented struct sched param, which accommodates the parameters of each scheduling policy, has to be enlarged. In fact, if only SCHED FIFO and SCHED RR policies are supported, it is sufficient for struct sched param
to contain a single integer fieldsched priority, be-ing the priority of the task. As we saw in Sec. 2.1.4 the Sporadic Server needs both a period and a bud-get, and so two parameters, sched ss repl period
and sched ss init budget have to be added. Moreover, SCHED SPORADIC also prescribes two more parameters to be within such structure:
sched ss low priorityandsched ss repl max. The scheduling of a SCHED SPORADIC task is controlled primarily by sched ss repl period) and sched ss init budget. Like SCHED RR, also SCHED SPORADIC is identical to SCHED FIFO, with additional conditions that causes priority to be switched between sched priority and
sched ss low priority.
The actual priority of aSCHED SPORADICtask is:
sched priority if the its current budget is greater than zero and the number of pending replen-ishment is less thansched ss max repl;
sched ss low priority otherwise.
The modification of the current budget of a task is done as follows:
1. when a task becomes running, its execution time shall be limited to at most its current bud-get;
2. each time a task is inserted in the
sched priority task list (because it became runnable or because of a budget replenishment) the time is posted as theactivation time; 3. when a task running atsched priorityis
pre-empted, the execution time it consumed is sub-tracted from its current budget;
4. when a task running at sched priority
blocks, the execution time it consumed is sub-tracted from its current budget and a replen-ishment operation is scheduled;
5. when a task running at sched priority ex-hausts its current budget, it becomes the tail of its sched ss low prioritytask list. Also, a replenishment operation is scheduled as well; 6. each time a replenishment is scheduled,
replenish amount is set to the execution time consumed since activation time and the replenishment is scheduled to occur at
activation timeplussched ss repl period
(or immediately if that instant already has passed).
7. a replenishment consists of adding
replenish amount to the current bud-get of a task. If it was running at
sched ss low priority, then it suddenly be-comessched priority.
Furthermore, consider that the number of replen-ishment simultaneously pending shall not be greater thansched ss max repl, and the current budget of a task shall not be neither lower than 0 nor greater thansched ss init budget.
All this means thatSCHED SPORADICbehaves ex-actly the same asSCHED FIFOtoward non real-time tasks, but it may affect which real-time task is se-lected to run, by continuously switching the priority of SCHED SPORADICones.
It is easy to see that, with some little dif-ferences due to the implementative perspective of the POSIX specifications (e.g., the limited number of replenishment), SCHED SPORADIC can be used to mimic the Sporadic Server algorithm described in Sec. 2.1.4. The only significant difference is that a
SCHED SPORADICthat exhausts its budget is not for-bidden to run until the next replenishment. Rather, it is requeued inside a different task list, the one cor-responding tosched ss low priority.
3.3
POSIX Support in Linux
Even if nobody has probably ever attempted to write a conformance document for it, Linux supports large chunks of the POSIX standards, as the following paragraphs tries to summarize, focusing on the fea-tures being part of the real-time option groups.
Automated tools to test the behavior of the Linux kernel, and of a GNU/Linux system as well, exists, for example the Open POSIX Test Suite (OPTS) or the NPTL Trace Tool [2, 19]. They
can be used to verify in great detail what is miss-ing or what is misbehavmiss-ing toward the specifica-tions. Here, what we are interested in pointing out is that Linux already supports almost all the features a POSIX compliant real-time system requires, with the
SCHED SPORADICscheduling policy being the biggest gap.
Real-Time Signals POSIX real-time extensions to standard Unix signals generation and delivery is fully supported in the standard Linux kernel with the following characteristics:
• signal number formSIGRTMINtoSIGRTMAX;
• they can accommodate a small piece of data;
• they can be queued and are delivered in FIFO order;
• it is possible to create a thread in response to a signal.
Asynchronous I/O AIO Although the most widely used I/O model in general purpose applica-tions is the synchronous one, issuing asynchronous operations could be quite useful in real-time con-texts. Linux supports such a model making it possi-ble to perform asynchronous I/O in all the following ways:
async. blocking I/O which means issuing multi-ple non-blocking requests and waiting for some of them complete;
sync. non-blocking I/O which means issuing a non-blocking request and start polling the ker-nel to know if it completed;
async. non-blocking I/O which means issuing non-blocking requests and being notified by the kernel (by a signal or a callback function) about their completion.
Memory Management Since typically a real-time task can not tolerate the unpredictable over-head introduced by virtual memory and paging POSIX requires that those features could be dis-abled, at least for a specified range of addresses. For that purpose, Linux coherently implements mlock
andmlockallsystem calls.
Furthermore, as shared memory is the most used communications paradigm in real-time applications, Linux support both POSIX.1b memory mapped files (mmap) and shared memory regions (shm{open, unlink}).
CPU Scheduling The Linux scheduler supports
SCHED FIFO,SCHED RR andSCHED OTHERscheduling policies, with SCHED SPORADIC still missing. there exist 140 priority levels, with 0..99 dedicated to real-time policies, and available only for users with suffi-cient capabilities.
As for SCHED OTHER the old heuristic based algorithm has recently, been replaced by a new one, the Completely Fair Scheduler (CFS). It avoids interactivity-guessing adopting a straightfor-ward mechanism which tries to ensure that all tasks at the same static priority level are treated equal, and that their dynamic priority vary depending on whether they are is getting theirs fair share of CPU or not.
Timers The Linux kernel supports both the interval timers (BSD itimers) in-terface and the 1003.1b real-time per-process timer functions (timer{create, settime, etc.}). Clock selection is possible among CLOCK REALTIME, CLOCK MONOTONIC and
CLOCK{PROCESS, THREAD}CPUTIME ID.
It is worth to note that, even if POSIX does not strictly specify any given timer resolution to be accomplished, the Linux kernel has recently gained support for high precision timers (high resolution timers, hrt). This means, for hardware platforms that include accurate enough time sources, that one can obtain tenth of microseconds precision time ac-counting either from within the kernel and in user space.
Threads Since the introduction of the Native POSIX Threads Library (NPTL[13]) the Linux ker-nel supports multithreading a lot better than how it did it by means of the old LinuxThreads implementa-tion. In particular, POSIX compliance has been im-proved, especially solving some odd issues happening inside signal handling.
The implemented thread model is 1-to-1, i.e., one “kernel thread” for each user level thread, with ei-ther low complexity and overhead. As required by POSIX, the scheduling policies a thread and a pro-cess can use are the same.
Thread Synchronization Synchronization and mutual exclusively executing of some code sections are key points of POSIX-like multithreading envi-ronment. The Linux kernel provides a variety in kernel synchronization primitives, such as spinlocks, mutexes, real-time mutexes, read-copy update, and so on. It also exports to user level the Fast Userspace muTEX synchronization object (futex [6, 7]), on top
of which the POSIX thread mutexes and condition variables are implemented.
Thread Priority Inversion Control Since the use of classical mutexes may be prone to the well known phenomenon of priority inversion, POSIX real-time extensions requires priority inheritance and variant of priority ceiling to be supported. In Linux,
PTHREAD PRIO INHERITfor POSIX mutexes is imple-mented by means of futexes and real-time mutexes (struct rtmutex). PTHREAD PRIO PROTECT is im-plemented in the GNU C Library, only using futexes.
4
SCHED SPORADIC
Design
and Implementation
In this section, we give a picture of the present Linux scheduler code architecture, and then provide all the details about our design and implementation activ-ity.
As regards to our motivations, i.e., the reasons why we decided to implementSCHED SPORADIC and try to get it merged, we can summarize them this way:
1. as shown in Sec. 2, there seems to be a lot of interest, especially coming from the research community, in both hierarchical fixed priority scheduling by means of Sporadic Servers, and in POSIXSCHED SPORADICsupport in Linux as well;
2. we think Linux would benefit of improved POSIX conformance (even this may not be achieved at its full extent, see Sec. 4.3.5), gain-ing even more interest than it now has, espe-cially from deeply embedded system designers; 3. since, as described in Sec. 4.1, real-time group scheduling is implemented, we think it would be positive thing to be able to make it more analyzable and theoretically well established. Anyway, whether it will be integrated or not in main-line Linux, we will use this implementation of hier-archical SCHED SPORADIC scheduling for our future research and implementation activities.
The code has already been sent to the LKML and so it is freely available therein. Anyway, it can also be downloaded fromhttp://feanor.sssup.it/ fag-gioli/, or by asking via e-mail to the authors.
4.1
Linux CPU Scheduler
As repeatedly said, Linux has, excepted for
with support for real-time and non real-time poli-cies. The only supported non real-time policy is
SCHED OTHER but, since Linux mainly is a general purpose kernel, it is by far the most used one. The code structure have quite recently been re-worked, and turned into the so-calledModular Sched-uler Framework, as well as provided with the group scheduling capability. The both of these features are briefly described in the following paragraphs. Modular Scheduler Framework Since kernel release 2.6.23 the monolithic scheduling core of the Linux kernel has been replaced by “an extensible hi-erarchy of scheduler modules” where each scheduling module ( scheduling class) is implemented in a dif-ferent source file. Currently, only two modules are present: the fair scheduler module insched fair.c, implementing SCHED OTHER scheduling policy, and the real-time module in sched rt.c, implementing
SCHED FIFOandSCHED RRpolicies.
The design is not that much flexible as it can ap-pear, e.g., there is no way to dynamically prioritize a scheduling class, and adding new classes is definitely not trivial at all. Obviously, in the module hierarchy, which is a simple linked list of scheduling classes, the real-time class appears at the first position.
The interface each class has to implement is rela-tively small, and it basically comprises the following functions:
• enqueue task() • dequeue task() • requeue task() • task tick()
• check preempt curr() • pick next task() • put prev task()
We think the name of the functions already explains what they are meant for, and we are not going in more details due to space reasons.
Either sched fair.c and sched rt.c provides the core scheduler with their own implementations of each and every of these functions. The core sched-uler, to deal with a specific scheduling event, invokes the correct implementation of the specific function depending on the scheduling class the involved task belongs to. The core scheduler is implemented in
sched.csource file.
Linux and Group Scheduling Another interest-ing recently introduced feature of the Linux kernel is group scheduling support, already described in Sec. 2.1.3. Both tasks and task groups are considered
scheduling entities, and a “task entity” can be moved underneath a “group entity” by means of the specific interface. Moreover, each group scheduling entity has a run queue, and a ready to run scheduling en-tity is always put in the run queue associated with its parent entity. When the scheduler goes to pick the next task to run, it chooses it within the top-level scheduling entities. If that entity is not a task the scheduler further looks inside its run queue, and this is iterated until a task is picked up.
In the domain of general purpose scheduling (in
sched fair.c), this feature is used to enforce fair-ness among different task groups instead than only among different tasks.
For real-time scheduling this is used to try to allocate some “guaranteed” run time to each task group over a given period. The way it this is handled, by means of a budget (runtime), consumed by the entities run-ning inside a group and periodically recharged, re-sembles an aperiodic request managing algorithm. Actually, it could be seen as mimicking a Deferrable Server but, indeed it is something different from all we have in theory.
Unfortunately, what we defined in Sec. 2.1.3 as group or hierarchical scheduling is not fully imple-mented yet. The problem is real-time task groups can not be provided with their own priority to be used for scheduling them under Rate Monotonic, as one would expect. By now, the priority of a task group is determined to be equal to the highest prior-ity of tasks and task groups it contains. This makes it possible to affect the POSIX CPU scheduling behav-ior as few as possible, but breaks hierarchical real-time theory, and makes all its results unusable.
Finally, an effective interface has been devised in order to make grouping and ungrouping possible. It is the process container interface, which is part of the more general Control Group subsystem and that fully works by means of standard file and directory operations on a specially mounted filesystem.
4.2
SCHED SPORADIC
in Linux
SCHED SPORADIC is one of the real-time scheduling policy specified by the POSIX standard, as well as
SCHED FIFO andSCHED RR. For this reason the best place where to place the code in the Linux scheduling framework, is inside the real-time scheduling class, withinsched rt.csource file.
The rules reported in Sec. 3.2 have to be enforced by modifying the implementa-tion of the scheduling class funcimplementa-tions, in
par-ticular dequeue task rt(), set curr task rt()
and update curr rt(), enqueue rt entity() and
dequeue rt entity(). Obviously some new func-tions to handle the budget accounting and the re-plenishment scheduling have to be added, as well as other source files are affected by minor modifications, mainly sched.c.
Below we show, throughout the diffstat out-put, some quantitative data about the amount of insertions, deletions and modifications introduced by our patch to the Linux kernel:
arch/x86/kernel/ syscall table 32 .S | 3 include/asm−x86/unistd 32.h|4 include/asm−x86/unistd 64.h|7 include/linux/sched.h | 79 init /Kconfig | 42 kernel/exit .c | 5 kernel/fork.c | 15 kernel/sched.c | 451 kernel/sched rt .c | 542
9 files changed, 1130 insertions(+), 18 deletions(−)
SCHED SPORADIC Group Scheduling Extending
SCHED SPORADIC to Linux task groups is straight-forward, since all the seven rules characterizing the scheduling policy described in Sec. 3.2 can be ap-plied to a task group as well.
The first thing we have to do is to provide each task group with the typicalSCHED SPORADIC param-eters, so that any of them has its own budget to con-sume, and its period for scheduling replenishments. Also, we think that the following semantic adapta-tions are sufficient:
accounting when a task executes for a given amount, the budget of all the groups encoun-tered ascending its hierarchy till the root are
diminished by the same amount;
blocking a task group is considered to be blocking
when it is being removed from a run queue be-cause it no longer has any task or task groups to run inside its own queue.
unblocking a task group is considered to be un-blocking when it is being added to a run ready queue because it again has some task or task group able to run inside its own queue. It is easy to see that, by means of these exten-sions, our implementation makes task groups behave like Sporadic Servers inside a Rate Monotonic based hierarchical scheduling framework, which is a well known and analyzable situation. Although this is not yet perfectly true, due to discrepancies between true hierarchical scheduling and Linux group scheduling one, i.e., the lack of task group independent priori-ties, we think it is at least a starting point.
Schedulability Test Finally, note we have not im-plemented any kind of schedulability admission test yet. This is because, as said in Sec. 2.1.3 it would not be simple to code and run it on-line. Rather, we think that the application designer, knowing in greater detail what he exactly needs, can implement its own task and group admission strategy.
Moreover, the present implementation of group scheduling in Linux, with group not having “their own” priority and deriving it by the tasks (and other task groups) they contain, does not fully adhere with what real-time theory calls a hierarchical system. For this reason, any of the existing scheduling anal-ysis results is directly applicable, unless we alter the scheduling test or we turn the model into a truly hi-erarchical one (that actually is in our future work list).
4.3
Implementation Details
Here we give the details of the implementation of
SCHED SPORADIC. We also we discuss some issues that raised concerning the interface, and explain why it may not be not a good idea to strictly adhere to what the POSIX standard prescribes.
4.3.1 SCHED SPORADIC Configuration
We make it possible, when configuring the Linux kernel after our patch has been applied, to choose if SCHED SPORADICscheduling has to be enabled, by means ofCONFIG POSIX SCHED SPORADIC. If that one is selected as ‘‘Yes’’ the SCHED SPORADIC policy becomes available for Linux tasks, while the spo-radic group scheduling and its interface is compiled iff alsoCONFIG RT GROUP SCHEDis enabled. As a de-pendency of CONFIG POSIX SCHED SPORADICthe nu-meric input fieldCONFIG SCHED SPORADIC REPL MAX
appears, to setup how big the maximum number of pending replenishment (SS MAX REPL) should be. Since we are aware of the fact that, along with a new feature, we also are introducing some overhead, the choice of making it configurable and tunable has been a key issue for our design.
Notice that all our code is written to not cause problem if compiled for and executed on a multipro-cessor machine, so no dependency on the kernel being UP is in place. If on a SMP system, standard Linux migration mechanisms to handle real-time schedul-ing in multiprocessors are let in place and are not affected at all by our patch.
4.3.2 SCHED SPORADIC Data Structures
The core of our implementation is the data struc-ture that stores the status of a SCHED SPORADIC
task or task group. As said in previous sections, each Linux task and task group has a scheduling en-tity. For tasks the scheduling entity is the basis of each and every scheduling decision, for task group this is not true, since group scheduling is based on the information stored in the group run queue and within the task group data structure itself. So, our
struct sched sporadic data field is stored inside the scheduling entity of SCHED SPORADICtasks, and inside the task group data structure for task groups. Our main concern was not to impose too much memory overhead to the system for implementing a scheduling policy which, especially for tasks, will probably would hardly be used. In fact, especially in a standard (non real-time) Linux installation, the tasks that use real-time policies (SCHED FIFO and
SCHED RR) are only few, and so it is natural to argue the number of tasks that are going to use
SCHED SPORADIC to be even less. The problem is worsened by the fact that we need some kind of buffer of pending replenishments. It can be implemented as an array, since its maximum size is specified by POSIX to be constant. The array solution is also superior, with respect for example to a linked list, since it does not require to dynamically create a new list element when we have to add one. In fact this may happen every time a task blocks, and dynam-ically allocating memory on all such events would have caused unacceptable overhead. Unfortunately, a data structure containing some integer (64 bit) fields for the task or the group status, a timer for the replenishment and an array of possible pending re-plenishments, each one with replenishment time and amount, tends to be quite a big piece of kernel mem-ory.
This given, our solution is to store only a pointer inside the real-time scheduling entity data struc-ture, and dynamically allocate the memory for our
struct sched sporadic datawhen a task chooses
SCHED SPORADIC as its scheduling policy. We still have to deal with dynamic memory allocation, but doing it at each scheduling policy change is by far more acceptable than at each task deactivation event. On the other hand, for task groups, we add our data structure to each task group. We think this could be a good solution since the number of task groups created in a system is much smaller than the number of tasks it is running.
Since we are dealing with dynamic memory allo-cations, it is difficult to evaluate the memory over-head imposed to the system as a whole. In fact, the total memory overhead SCHED SPORADIC is in-troducing fully depends on how many task groups are created in the system, and on how many tasks usesSCHED SPORADICas their own scheduling policy.
4.3.3 SCHED SPORADIC Tasks
Briefly going into little more details on the imple-mentation of theSCHED SPORADICfor tasks, we can say that we spent a lot of effort in integrating our code in the present Linux real-time scheduling class (sched rt.c) and keeping the modifications at min-imum extent.
The “normal” real-time Linux scheduling code path is only altered by calling one function for the scheduling entity of the current task,
rt se ss budget exhausted(), which checks if we are dealing with aSCHED SPORADICtask and if it is eventually running out of budget. This happens in-side the existing update curr rt() function which is the one that is responsible for the accounting to the task of its execution time and. For that reason it is called at each scheduler tick, and at each task deactivation or preemption. In our function, if the budget of the task is exhausted, we honor the POSIX prescribed behavior and post a recharge event as well as requeue the task inside a different run-list, since we have changed its priority to the low level value.
For recharge event to happen, we use one timer for each task, and so we wrote the
rt se ss repl timer()function, the handler of that timer. Having only one timer, this function has not only to perform the scheduled replenishment, but also to check if any other event already has been posted and to reprogram the timer to fire again at the right time instant. Since replenishment can only be requested in sequentially increasing time order, we prefer to adopt this design and avoiding having one timer for each replenishment event.
Again, considering the fact that the number of
SCHED SPORADICtasks in most of the configurations is probably going to be quite low, the overhead we are introducing in the system by adding a timer for each one of those task is not too high. Also, consider that thanks to the possibility of using the high resolution timers from within the scheduler related functions we are able to serve the replenishment events with as much precision as the hardware is able to provide. 4.3.4 SCHED SPORADIC Task Groups
When both SCHED SPORADIC and real-time group scheduling are configured by the user, what we de-scribed before for tasks also happens to task groups, with the semantic we already defined and explained in the previous sections. What we do is essen-tially the same, and it is also similar to what the present Linux kernel code does to make real-time group scheduling effective. We have another func-tion, calledrt rq ss is exhausted budget()which check if a task group is to be scheduled under our
SCHED SPORADICadaptation and, if yes, if it is run-ning out of budget. Obviously such a function is called for each task group into which the current task is enqueued, from its own parent group to the hier-archy root group.
We also have one timer for each task group for re-plenishment to happen at their scheduled time, and the handler function isrt rq ss repl timer. 4.3.5 SCHED SPORADIC Interface
POSIX is clear when talking about the sched-uler exported user interface: it is essentially made up of a couple of functions, the most important ones being sched setscheduer(),
sched getscheduler(), sched setparam() and
sched getparam(). As regard to data struc-tures the one of paramount importance is struct sched param, which necessarily contains an integer field calledsched priorityfor accommodating the priority of a task. If SCHED SPORADIC scheduling is supported, it also should contain some other fields:
sched ss low priority, sched ss init budget,
sched ss repl period and sched max repl, with which we already are familiar.
Unfortunately, the Linux kernel already im-plements and exports the struct sched param
data structure, and it only containing the int sched priority field. One would think that the best way to go is to extend such a data structure as well as (slightly) modify the previous listed func-tions in order to deal with the new scheduling policy and parameters. Actually, this is what we did in the first version of our implementation, but we soon dis-covered that this approach suffers from a so-called “binary incompatibility” issue. To figure out what this means, just consider what would happen to all the binary distributed applications, that have been compiled while struct sched param was only one integer size long, if we change it toward something so much bigger!
Moreover, there exist no trivial solution to this problem, and the only idea we have, that also resulted in being the most appreciated dur-ing discussdur-ing the problem in the LKML, is not to modify struct sched param nor the behav-ior of the already present functions and system calls. Instead, we introduce a new scheduling parameter data structure (struct sched param2) and new syscalls (sched{set,get}scheduler2(),
sched{set,get}param2) dealing with it.
This is how we are doing in our second (and present) patch since, even if being disappointed about the fact we are no longer fully implementing the POSIX in-terface. However, we think that breaking the binary compatibility of the Linux kernel with all the
pre-compiled application that use struct sched param
is, definitely, something that we do not want. Sum-marizing, to set the scheduling policy of a task to
SCHED SPORADIC, we almost provide what POSIX prescribes, unless the name of the functions and of the data structure to be used are slightly different.
With respect to groups, since POSIX does not cover the topic of group scheduling, we are follow-ing the way the Linux kernel is presently dofollow-ing, i.e., we exploit the cgroups filesystem interface. This means each task group is a directory that has to be created under the mount point of the special
cgroupsfilesystem. The files inside such directories we are interested in are calledcpu.rt ss period ns,
cpu.rt ss budget nsandcpu.rt ss max repl, and we think their name is enough to understand what each one of them is meant for. Notice that the group interface forSCHED SPORADICis nanoseconds based, as exactly the task interface is.
5
Experimental Evaluation
The code is still is at its early development stage. By now, we have only been able to run some behav-ioral simulation to test its correctness. Moreover, we think this work needs thorough experimental evalua-tion to prove its usefulness. Thus, we have identified many different test and simulations that we would like to perform, either concerning our implementa-tion or comparing it with the Linux native group scheduling solution.
So, what this section contains is the brief de-scription of the results of the simple tests we have performed, showing that the algorithms behaves cor-rectly in each scenario. We also describe what kind of tests, simulations and performance evaluations we think are useful to pinpoint the characteristics of our implementation. Thus, this will serve as our test plan for future works.
5.1
Functionality Tests
Here we show two traces of execution showing that ourSCHED SPORADICimplementation behaves as one would expect.
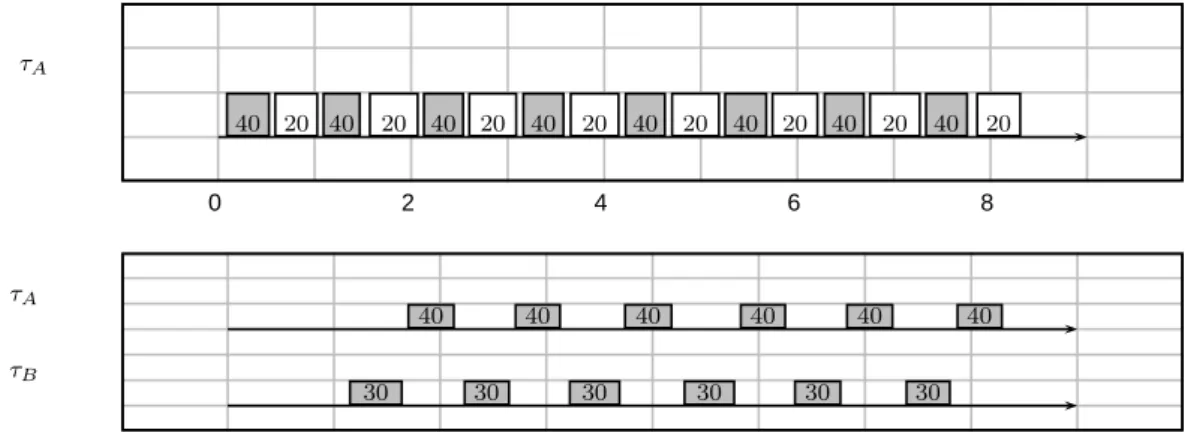
In the upper part of Fig. 1 we see the execu-tion trace drawn from aSCHED SPORADICtask (tauA)
with high priority and low priority equal to, re-spectively 40 and 20, replenishment period equal to 100msecand budget 50msec. The task is a greedy one, i.e., always has something to do. The label of the task is the priority at which it is running. As we can see,SCHED SPORADICpolicy is effective in throt-tling the task down to its low priority level when it exhausts the budget, and pushing it back to the high
one just after the replenishments.
In the lower part of the same figure, we can see the same task (tauA), running together with a
SCHED FIFO task (taub) with priority equal to 30.
As we expected, tauA is only allowed to run when
it has its high priority level, since during its staying at priority 20tauB is scheduled on the CPU.
5.2
Future Planned Tests
There are many aspects of our implementation that we are interested in evaluating thoroughly. The fol-lowing paragraphs give a glimpse to any of them, as long as our planned test and measurement method-ology and our expectations.
Execution Time Overhead Evaluation The first thing that we want to establish, is how much overhead we are introducing with respect to the stan-dard Linux kernel, both for task and task group scheduling. In order of doing this we will proceed this way:
• we prepare a version of our code instrumented by TSC reading at the beginning and at the end of the new functions we have implemented and, more important, of the existing functions that we have modified;
• we look at the output produced by ftrace, the Linux kernel tracer that is being integrated right at the time of our writing, in order to check if we are worsening the performances of the system with respect to worst case execu-tion latencies (priority inversions, preempexecu-tion and interrupts disabling, etc.).
For both of this analysis we are interesting in com-paring the results with the original Linux kernel, especially with respect to the group scheduling im-plementation. In fact, what we expect is that the scheduling of SCHED SPORADIC tasks will introduce some amount of overhead, but that this come back to some negligible extent if those tasks are removed. On the other hand, although the Sporadic Server pol-icy is more complex that the heuristic one that the kernel uses for handling the budget of the groups, we think that our group scheduling solution is not introducing so much overhead.
Memory Overhead Evaluation This is clearly highly depends on how heavily SCHED SPORADIC
tasks and groups are created and used, but still is an interesting aspect to be evaluated. This is particu-larly true if we think that our solution could be effec-tive for embedded systems developer, and they typ-ically have to deal with systems with tight
require-ments on kernel memory footprint. Here the idea is to define some meaningful set of randomly generated
SCHED SPORADICtask and group workloads and eval-uate the memory overhead introduced in the kernel for both the binary image and the up and running system. To make this even more interesting such an estimation could be repeated for as much hardware architectures as possible, with particular focus on the ones that typically runs embedded devices.
Response Time Analysis We think that a good estimation on how good our idea to implement the Sporadic Server on Linux is, could be to evalu-ate the response time of some (randomly gener-ated) aperiodic activities run under different sys-tem load conditions. In order of doing this, af-ter having generated the aperiodic tasks, we will run them as SCHED SPORADIC tasks and/or inside
SCHED SPORADICtask groups and check withftrace
how many of them fulfil the theoretical expectations and, if not, why and by how much. Comparison with the results we will achieve using the present group scheduling implementation of Linux is also worth-while.
Real World Applications As said, the vast ma-jority of Linux applications, at least in a standard installation, do not use the facilities provided by the POSIX real-time capabilities of the Linux ker-nel. However, we are thinking to modify a real soft real-time Linux application, so that it uses
SCHED SPORADIC. This way it can be provided with some time guarantees as well as do not starve the rest of the system.
6
Conclusions and
Future Works
In this paper, after giving an introduction on real-time computing, POSIX real-real-time extensions and on how well Linux supports them, we presented a slightly extended version of the SCHED SPORADIC
POSIX scheduling policy and its implementation in the Linux kernel. In recent past there have been made other attempts to implement such a policy, but any of them supports group scheduling, as Linux now ships with.
We think both standard and group Sporadic Server scheduling capabilities are valuable extensions to the Linux kernel, pushing it a bit further on the path of supporting real-time analyzable and pre-dictable applications.
Now, having the code fully functioning, as shown by a couple of synthetic experiments, we can devote
0 2 4 6 8 τ A 40 20 40 20 40 20 40 20 40 20 40 20 40 20 40 20 0 2 4 6 8 τ A τ B 30 40 30 40 30 40 30 40 30 40 30 40
Figure 1: SCHED SPORADICtasks running. Timescale on the axis issec−1
ourselves to more deep and thorough experimental evaluation of it.
Regarding future works, more than what is al-ready described in Sec. 5, we are working on a mod-ification of the fundamentals of the group scheduling in Linux to make it possible to turn it into what it is broadly known as a real-time hierarchal system. Moreover we will re-run all the tests after having adapted our implementation on thert-preempt vari-ant of the Linux kernel. Finally, some more effort is also needed to make our solution cope with SMP and task synchronization and priority inheritance.
References
[1] L. Burdalo, A. Espinosa, A. Garcia-Fornes and A. Terrasa.Framework fo the Development and Evaluation of New Scheduling Policies in RT-Linux. OSPERT Workshop 2006. July 2006 [2] http://posixtest.sourceforge.net/
[3] The Open Group Base Specifications, IEEE Std 1003.1-2004
[4] http://shark.sssup.it
[5] http://www.windriver.com/
[6] R. Russel, H. Franke and M. Kirkwood. Fuss, Futexes and Furwocks: Fast Userlevel Locking in Linux. Ottawa Linux Symposium 2002 [7] U. Drepper.Futexes Are Tricky. December 2005 [8] http://www.evidence.eu.com/content/view/27/254/
[9] http://marte.unican.es/
[10] M. Lewandowski, M. Stanovich, T. Baker, K. Gopalan and A. Wang. Modelling device driver effects in real-time schedulability anal-ysis: Study of a network driver. In Proc of
13th IEEE Real-Time and Embedded Technol-ogy and Application Symposium. April 2007 [11] http://www.rtlinuxfree.com/
[12] https://www.rtai.org/
[13] U. Drepper and I. Molnar.The Native POSIX Thread Library for Linux. February 2005 [14] http://www.xenomai.org/
[15] T.-S. Tia, J.W.-S. Liu M. and Shankar. Algo-rithms and optimality of scheduling aperiodic requests in fixed-priority preemptive systems. Journal of Real-Time Systems 10(1): 2343. 1996 [16] http://www2.cs.fsu.edu/ rosentha/cop5641/
[17] R.J. Bril and P.J.L. Cuijpers. Towards Ex-ploiting the Preservation Strategy of Sporadic Servers. Euromicro Conference on Real-Time Systems, Work-In-Progress Session. July 2008 [18] G. Lipari and C. Scordino. Current
Ap-proaches and Future Opportinities. Interna-tional Congress ANIPLA, November 2006 [19] http://nptl.bullopensource.org/
[20] J.K. Strosnider, J.P. Lehoczky and L.Sha.The Deferrable Server Algorithm for Enhanced Ape-riodic Responsiveness in Hard-Real-Time Envi-ronments. IEEE Transactions on Computers, 4, 1, 1995
[21] Mikael Bertlin. Proportional and Sporadic Scheduling in Real-Time Operating Systems. Master Thesis. March 2008
[22] T.P. Baker, A.A. Wang and M.J. Stanovich.
Fitting Linux Device Drivers into an Analyz-able Scheduling Framework. OSPERT Work-shop 2007
[23] W. Shi. Implementation and Performance of POSIX Sporadic Server Scheduling in RTLinux. Master Thesis. Summer 2001
[24] G. Buttazzo. Rate Monotonic vs. EDF: Judg-ment Day. Real-Time Systems, 29, 526, 2005 [25] E. Bini and G. Buttazzo. Schedulability
Anal-ysis of Periodic Fixed Priority Systems. IEEE Transactions on Computers. 53, 11, 1462-1473, 2004
[26] G. Lipari and E. Bini. A Methodology for De-signing Hierarchical Scheduling Systems. Jour-nal of Embedded Computing. 1, 2, 2004 [27] http://home.gna.org/adeos/
[28] B. Sprunt, L. Sha and J.P. Lehoczky.Aperiodic Task Scheduling for Hard-Real-Time Systems. Real-Time Systems, 1, 27-60, 1989
[29] C. L. Liu and J.W. Layland.Scheduling Algo-rithms for Multiprogramming in a Hard real-Time Environment. Journal of the Association for Computing Machinery.20, 1, 46-61, 1973 [30] L. Sha, R. Rajkumar and J.P. Lehoczky.
Prior-ity Inheritance Protocols: An Approach to Real-Time Synchronization. IEEE Transactions on Computers. 39, 9, 1990
[31] J. Mathai and P.K. Pandya.Finding Response Times in a Real-Time System. The Computer Journal. 29, 5, 390-395, 1986