C o p i n g w i t h S y n t a c t i c A m b i g u i t y
o r
H o w to Put t h e Block in t h e Box on t h e T a b l e 1
Kenneth Church
Ramesh Patil
L a b o r a t o r y f o r C o m p u t e r S c i e n c e M a s s a c h u s e t t s I n s t i t u t e o f T e c h n o l o g y
C a m b r i d g e , M A 0 2 1 3 9
Sentences are far more ambiguous than one might have thought. There may be hundreds, perhaps thousands, of syntactic parse trees for certain very natural sentences of English. This fact has been a major problem confronting natural language processing, especially when a large percentage of the syntactic parse trees are enumerated during semantic/pragmatic processing. In this paper we propose some methods for dealing with syntactic ambiguity in ways that exploit certain regularities among alternative parse trees. These regularities will be expressed as linear combinations of ATN networks, and also as sums and products of formal power series. We believe that such encoding of ambiguity will enhance processing, whether syntactic and semantic constraints are processed separately in sequence or interleaved together.
M o s t p a r s e r s f i n d t h e set o f p a r s e t r e e s b y s t a r t i n g w i t h t h e e m p t y set a n d a d d i n g t o it e a c h t i m e t h e y f i n d a n e w p o s s i b i l i t y . W e m a k e t h e o b s e r v a t i o n t h a t in c e r t a i n s i t u a t i o n s it w o u l d b e m u c h m o r e e f f i c i e n t t o w o r k in t h e o t h e r d i r e c t i o n , s t a r t i n g f r o m t h e u n i v e r s a l set (i.e, t h e set o f all b i n a r y t r e e s ) a n d r u l i n g t r e e s o u t w h e n t h e p a r s e r d e c i d e s t h a t t h e y c a n n o t b e p a r s e s . R u l i n g - o u t is e a s i e r w h e n t h e s e t o f p a r s e t r e e s is c l o s - er to t h e u n i v e r s a l s e t a n d r u l i n g - i n is e a s i e r w h e n t h e set o f p a r s e t r e e s is c l o s e r t o t h e e m p t y set. R u l i n g - o u t is p a r t i c u l a r l y s u i t e d f o r "'every way a m b i g u o u s " c o n s t r u c t i o n s s u c h as p r e p o s i t i o n a l p h r a s e s t h a t h a v e j u s t as m a n y p a r s e t r e e s as t h e r e a r e b i n a r y t r e e s o v e r t h e t e r m i n a l e l e m e n t s . S i n c e e v e r y t r e e is a p a r s e , t h e p a r s e r d o e s n ' t h a v e t o r u l e a n y o f t h e m o u t .
I n s o m e s e n s e , t h i s is a f o r m a l i z a t i o n o f a n i d e a t h a t h a s b e e n in t h e l i t e r a t u r e f o r s o m e t i m e . T h a t is, it h a s b e e n n o t i c e d f o r a l o n g t i m e t h a t t h e s e s o r t s o f v e r y a m b i g u o u s c o n s t r u c t i o n s a r e v e r y d i f f i c u l t f o r
1 This research was supported (in part) by the National Insti- tutes of Health Grant No. 1 P01 LM 03374-02 from the National Library of Medicine, and by the Defense Advanced Research Pro- jects Agency (DOD) monitored by the Office of Naval Research under Contract No. N00014-75-C-0661.
m o s t p a r s i n g a l g o r i t h m s , b u t ( a p p a r e n t l y ) n o t f o r p e o - p l e . T h i s o b s e r v a t i o n h a s l e d s o m e r e s e a r c h e r s t o h y p o t h e s i z e a d d i t i o n a l p a r s i n g m e c h a n i s m s , s u c h as p s e u d o - a t t a c h m e n t ( C h u r c h 1 9 8 0 , p p . 6 5 - 7 1 ) 2 a n d p e r m a n e n t p r e d i c t a b l e a m b i g u i t y ( S a g e r 1 9 7 3 ) , so t h a t t h e p a r s e r c o u l d " a t t a c h all w a y s " in a s i n g l e s t e p . H o w e v e r , t h e s e m e c h a n i s m s h a v e a l w a y s l a c k e d a p r e - cise i n t e r p r e t a t i o n ; w e will p r e s e n t a m u c h m o r e f o r - m a l w a y o f c o p i n g w i t h " e v e r y w a y a m b i g u o u s " g r a m - m a r s , d e f i n e d in t e r m s o f Catalan numbers ( K n u t h
1 9 7 5 , pp. 3 8 8 - 3 8 9 , 5 3 1 - 5 3 3 ) .
1. Ambiguity is a Practical Problem
S e n t e n c e s a r e f a r m o r e a m b i g u o u s t h a n o n e m i g h t h a v e t h o u g h t . O u r e x p e r i e n c e w i t h t h e EQSP p a r s e r ( M a r t i n , C h u r c h , a n d P a t i l 1 9 8 1 ) i n d i c a t e s t h a t t h e r e m a y b e h u n d r e d s , p e r h a p s t h o u s a n d s , o f s y n t a c t i c p a r s e t r e e s f o r c e r t a i n v e r y n a t u r a l s e n t e n c e s o f E n g - lish. F o r e x a m p l e , c o n s i d e r t h e f o l l o w i n g s e n t e n c e w i t h t w o p r e p o s i t i o n a l p h r a s e s :
2 The idea of pseudo-attachment was first proposed by Mar- cus (private communication), though Marcus does not accept the formulation in Church 1980.
Copyright 1982 by the Association for Computational Linguistics. Permission to copy without fee all or part of this material is granted provided that the copies are not made for direct commercial advantage and the Journal reference and this copyright notice are included on the first page. To copy otherwise, or to republish, requires a fee and/or specific permission.
0 3 6 2 - 6 1 3 X / 8 2 / 0 3 0 1 3 9 - 1 1 $ 0 3 . 0 0
K e n n e t h Church and Ramesh Patil Coping with Syntactic Ambiguity
(1) Put the b l o c k in the b o x on the table.
which has two interpretations:
(2a) Put the block[in the b o x on the table] (2b) Put [the b l o c k in the box] on the table.
T h e s e s y n t a c t i c ambiguities g r o w " c o m b i n a t o r i a l l y " with the n u m b e r of p r e p o s i t i o n a l phrases. F o r e x a m - ple, w h e n a third PP is added to the s e n t e n c e above, there are five interpretations:
(3a) Put the b l o c k [[in the b o x on the table] in the kitchen].
(3b) Put the block [in the b o x [on the table in the kitchen]].
(3c) Put [[the b l o c k in the box] on the table] in the kitchen.
(3d) Put [the block [in the b o x on the table]] in the kitchen.
(3e) Put [the b l o c k in the box] [on the table in the kitchen].
W h e n a fourth PP is added, there are f o u r t e e n trees, and so on. This sort of c o m b i n a t o r i c a m b i g u i t y has b e e n a m a j o r p r o b l e m c o n f r o n t i n g n a t u r a l l a n g u a g e processing. In this p a p e r we p r o p o s e s o m e m e t h o d s for dealing with syntactic a m b i g u i t y in w a y s that take a d v a n t a g e of regularities a m o n g the alternative parse trees.
In particular, we o b s e r v e t h a t e n u m e r a t i n g the parse trees as a b o v e fails to c a p t u r e the i m p o r t a n t g e n e r a l i z a t i o n t h a t p r e p o s i t i o n a l p h r a s e s are " e v e r y w a y a m b i g u o u s , " or m o r e precisely, the set of parse trees o v e r i PPs is the s a m e as the set of binary trees that can be c o n s t r u c t e d o v e r i terminal elements. N o - tice, for example, that there are t w o possible b i n a r y trees o v e r three elements,
(4a) [ ... b l o c k ... [ ... b o x ... table ... ]] (4b) [[ ... block ... b o x ...] ... table ... ]
c o r r e s p o n d i n g to (2a) and (2b), respectively, and that there are five binary trees o v e r four e l e m e n t s corre- sponding to ( 3 a ) - ( 3 c ) , respectively.
PPs, adjuncts, c o n j u n c t s , n o u n - n o u n m o d i f i c a t i o n , stack relative clauses, a n d o t h e r " e v e r y w a y a m b i g u o u s " constructions will be t r e a t e d as primitive objects. T h e y can be c o m b i n e d in various w a y s to p r o d u c e c o m p o s i t e constructions, such as lexical a m b i - guity, which m a y also be v e r y a m b i g u o u s but not nec- essarily " e v e r y w a y a m b i g u o u s . " L e x i c a l a m b i g u i t y , for example, will be a n a l y z e d as the sum of its senses, or in flow graph t e r m i n o l o g y ( O p p e n h e i m and Schafer 1975) as a parallel c o n n e c t i o n of its senses. Structural ambiguity, on the o t h e r hand, will be a n a l y z e d as the p r o d u c t of its c o m p o n e n t s , or in flow g r a p h t e r m i n o l o - gy as a series connection.
2. Formal P o w e r S e r i e s
This section will m a k e the linear s y s t e m s a n a l o g y m o r e precise b y r e l a t i n g c o n t e x t - f r e e g r a m m a r s to f o r m a l p o w e r series ( p o l y n o m i n a l s ) . F o r m a l p o w e r series are a w e l l - k n o w n device in the f o r m a l language literature (e.g., S a l o m a a 1973) f o r d e v e l o p i n g the alge- braic p r o p e r t i e s of c o n t e x t - f r e e g r a m m a r s . We intro- duce t h e m h e r e to e s t a b l i s h a f o r m a l basis f o r o u r u p c o m i n g discussion of processing issues.
T h e p o w e r series f o r g r a m m a r (5a) is (5b).
(5a) NP - , . J o h n I N P a n d N P (5b) N P -- J o h n + J o h n a n d J o h n
+ 2 J o h n and J o h n and J o h n
+ 5 J o h n a n d J o h n a n d J o h n a n d J o h n + 1 4 J o h n a n d J o h n a n d J o h n a n d J o h n
and J o h n + ...
E a c h t e r m consists of a sentence g e n e r a t e d b y the g r a m m a r a n d an a m b i g u i t y c o e f f i c i e n t 3 which c o u n t s h o w m a n y ways the s e n t e n c e c a n be generated. F o r e x a m p l e , the s e n t e n c e " J o h n " has o n e parse tree
(6a) [John] 1 tree
b e c a u s e the z e r o - t h c o e f f i c i e n t of the p o w e r series is one. Similarly, the s e n t e n c e " J o h n a n d J o h n " also has o n e tree b e c a u s e its coefficient is one,
(6b) [John and John] 1 tree
and " J o h n and J o h n a n d J o h n " has t w o b e c a u s e its coefficient is two,
(6c) [[John and John] and John], 2 trees
[John and [John a n d John]]
and " J o h n and J o h n and J o h n a n d J o h n " has five, (6d) [John and [[John and John] and John]], 5 trees
[John and [John a n d [John and John]]], [[[John and John], and John] and John], [[John and [John and John]] and John], [[John a n d John] a n d [John and John]]
a n d so on. T h e r e a d e r c a n v e r i f y f o r h i m s e l f t h a t " J o h n a n d J o h n a n d J o h n a n d J o h n a n d J o h n " has f o u r t e e n trees.
N o t e t h a t the p o w e r series e n c a p s u l a t e s the a m b i - guity r e s p o n s e of the s y s t e m ( g r a m m a r ) to all possible input sentences. In this way, the p o w e r series is a n a - logous to the impulse r e s p o n s e in electrical e n g i n e e r - ing, which e n c a p s u l a t e s the r e s p o n s e of the s y s t e m (circuit) to all possible input frequencies. ( A m b i g u i t y c o e f f i c i e n t s b e a r a s t r o n g r e s e m b l a n c e to f r e q u e n c y coefficients in F o u r i e r analysis.) All of these trans- f o r m e d r e p r e s e n t a t i o n s y s t e m s (e.g., p o w e r series, impulse r e s p o n s e , and F o u r i e r series) p r o v i d e a c o m - plete d e s c r i p t i o n o f the s y s t e m with no loss of i n f o r m a t i o n 4 ( a n d no heuristic a p p r o x i m a t i o n s , f o r e x a m p l e , s e a r c h s t r a t e g i e s ( K a p l a n 1 9 7 2 ) ) . T r a n s -
3 The formal language literature (Harrison 1978, Salomaa 1973) uses the term support instead of ambiguity coefficient.
Kenneth Church and Ramesh Patil Coping w i t h Syntactic Ambiguity
f o r m s are o f t e n v e r y useful b e c a u s e t h e y p r o v i d e a different point of view. C e r t a i n o b s e r v a t i o n s are m o r e easily seen in the t r a n s f o r m space t h a n in the original space, and vice versa.
This p a p e r will discuss several ways to g e n e r a t e the p o w e r series. Initially let us consider successive ap- proximation. O f all the techniques to be p r e s e n t e d here, successive a p p r o x i m a t i o n s m o s t closely r e s e m b l e s the a p p r o a c h t a k e n b y m o s t current chart parsers in- cluding EQSP (Martin, Church, and Patil 1981). T h e alternative a p p r o a c h e s take a d v a n t a g e of certain regu- larities in the p o w e r series in o r d e r to p r o d u c e the s a m e results m o r e efficiently.
Successive a p p r o x i m a t i o n works as follows. First we translate g r a m m a r (5a) into the equation:
(7) NP = J o h n + N P . a n d . NP
w h e r e " + " c o n n e c t s t w o w a y s of g e n e r a t i n g an NP and " . " c o n c a t e n a t e s t w o parts of an NP. In s o m e sense, we w a n t to " s o l v e " this e q u a t i o n f o r NP. This can be accomplished by refining successive a p p r o x i m a - tions. An initial a p p r o x i m a t i o n NP 0 is f o r m e d b y t a k - ing NP to be the e m p t y language,
(8a) NP 0 = 0
T h e n we f o r m the next a p p r o x i m a t i o n by substituting the p r e v i o u s a p p r o x i m a t i o n into e q u a t i o n (7), a n d simplifying a c c o r d i n g to the usual rules of a l g e b r a (e.g., a s s u m i n g distributivity, associativity, 5 i d e n t i t y element, and zero element).
(8b) NP 1 = J o h n -t- NP 0- a n d . NP 0 = J o h n + 0 . a n d . 0 = J o h n
We continue refining the a p p r o x i m a t i o n in this way.
(8c) NP 2 = J o h n + NP 1 • a n d . NP 1 = J o h n + J o h n and J o h n (8d) NP 3 = J o h n + NP 2 and NP 2
= J o h n + ( J o h n + J o h n and J o h n ) . a n d . ( J o h n + J o h n and J o h n )
= J o h n + J o h n and J o h n + J o h n and J o h n and J o h n + J o h n and J o h n and J o h n
+ J o h n and J o h n and J o h n and J o h n
4 This needs a qualification. It is true that the p o w e r series provides a complete description of the ambiguity r e s p o n s e to any input sentence. However, the p o w e r series representation may be losing some information that would be useful for parsing. In partic- ular, there might be some cases where it is impossible to recover the parse trees exactly, as we will see, t h o u g h this may not be too serious a problem for m a n y practical applications. That is, it is often possible to recover most (if not all) of the structure, which may be adequate for m a n y applications.
5 The careful reader may correctly object to this assumption. We include it here for expository convenience, as it greatly simpli- fies the derivations t h o u g h it should be n o t e d that m a n y of the results could be derived without the assumption. F u r t h e r m o r e , this assumption is valid for counting ambiguity. That is, I A " B I * I C I = I A I * IB " C I , where A , B , and C are sets of trees and I A I denotes the n u m b e r of m e m b e r s of A, and * is integer multi- plication.
= J o h n + J o h n a n d J o h n + 2 J o h n and J o h n and J o h n
+ J o h n and J o h n a n d J o h n and J o h n
Eventually, we h a v e NP e x p r e s s e d as an infinitely long p o l y n o m i n a l (5b) above. This expression can b e sim- plified b y i n t r o d u c i n g a n o t a t i o n f o r e x p o n e n t i a t i o n . L e t x i be an a b b r e v i a t i o n for multiplying x • x • ... • x, i times.
(9) N P = J o h n + J o h n and J o h n + 2 J o h n (and J o h n ) 2 + 5 J o h n (and J o h n ) 3 + 14 J o h n (and J o h n ) 4
-1- , . .
N o t e t h a t p a r e n t h e s e s are i n t e r p r e t e d d i f f e r e n t l y in a l g e b r a i c e q u a t i o n s t h a n in c o n t e x t - f r e e rules. In c o n t e x t - f r e e rules, p a r e n t h e s e s d e n o t e o p t i o n a l i t y , where in equations t h e y d e n o t e p r e c e d e n c e relations a m o n g algebraic operations.
3. Catalan N u m b e r s
A m b i g u i t y coefficients take on an i m p o r t a n t practi- cal significance w h e n we c a n m o d e l t h e m directly w i t h o u t r e s o r t i n g to successive a p p r o x i m a t i o n as above. This can result in substantial time and space savings in certain special cases where there are m u c h m o r e efficient ways to c o m p u t e the coefficients t h a n successive a p p r o x i m a t i o n ( c h a r t p a r s i n g ) . E q u a t i o n (9) is such a special case; the c o e f f i c i e n t s follow a w e l l - k n o w n c o m b i n a t o r i c series called the Catalan Numbers ( K n u t h 1975, pp. 3 8 8 - 3 8 9 , 5 3 1 - 5 3 3 ) . 6 This section will describe C a t a l a n n u m b e r s and their rela- tion to parsing.
T h e first f e w C a t a l a n n u m b e r s are 1, 1, 2, 5, 14, 42, 132, 469, 1430, 4862. T h e y are g e n e r a t e d b y the closed f o r m expression: 7
(10) C a t n = ( 2 n ) - ( 2n n - l )
This f o r m u l a can be explained in t e r m s of p a r e n t h e s - ized expressions, which are equivalent to trees. C a t n is the n u m b e r of ways to p a r e n t h e s i z e a f o r m u l a of length n. T h e r e are t w o conditions on p a r e n t h e s i z a - tion: (a) there m u s t be the s a m e n u m b e r of o p e n and close p a r e n t h e s e s , and (b) t h e y must be p r o p e r l y nest- ed so that an o p e n p a r e n t h e s i s p r e c e d e s its m a t c h i n g close parenthesis. T h e first t e r m c o u n t s the n u m b e r of
6 This fact was first pointed out to us by V. Pratt. We sus- pect that it is a generally well-known result in the formal language community, though its origin is unclear.
7 (~) is k n o w n as a binominal coefficient. It is equivalent to { a ! / [ b ! ( a - b ) ! ] } ,
where a! is equal to the product of all integers b e t w e e n 1 and a. Binomial coefficients are very c o m m o n in eombinatories where they are interpreted as the n u m b e r of ways to pick b objects out of a set of a objects.
Kenneth Church and Ramesh Patil Coping w i t h Syntactic A m b i g u i t y
sequences of 2n p a r e n t h e s e s , such that there are the s a m e n u m b e r of o p e n s and closes. T h e second t e r m subtracts cases violating condition (b). This e x p l a n a - tion is e l a b o r a t e d in K n u t h 1975, p. 531.
It is very useful to k n o w that the a m b i g u i t y coeffi- cients are C a t a l a n n u m b e r s b e c a u s e this o b s e r v a t i o n enables us to replace e q u a t i o n (9) with (11), where C a t i d e n o t e s the i th C a t a l a n n u m b e r . (All s u m m a t i o n s range f r o m 0 to oo unless n o t e d otherwise.)
(11) N P = E C a t i J o h n (and J o h n ) t
i
T h e i th C a t a l a n n u m b e r is the n u m b e r of binary trees t h a t c a n be c o n s t r u c t e d o v e r i phrases. This t h e o r e t i - cal m o d e l c o r r e c t l y p r e d i c t s o u r p r a c t i c a l e x p e r i e n c e with EQSP. EQSP f o u n d exactly the C a t a l a n n u m b e r of parse trees for each s e n t e n c e in the following se- quence.
1 It
1 It 2 It 5
was the n u m b e r .
was the n u m b e r of products.
was the n u m b e r of p r o d u c t s of products. It was the n u m b e r of p r o d u c t s of p r o d u c t s of products.
14 It was the n u m b e r of p r o d u c t s of p r o d u c t s of p r o d u c t s of products.
T h e s e p r e d i c t i o n s c o n t i n u e to hold with as m a n y as nine prepositional p h r a s e s (4862 parse trees).
4. Table Lookup
W e could i m p r o v e EQSP's p e r f o r m a n c e on PPs if we could find a m o r e efficient w a y to c o m p u t e C a t a - lan n u m b e r s t h a n chart parsing, the m e t h o d currently e m p l o y e d b y EQSP. L e t us p r o p o s e two alternatives: table lookup and evaluating expression (10) directly. B o t h are v e r y efficient o v e r practical ranges of n, say no m o r e t h a n 20 phrases or so. 8 In b o t h cases, the ambiguity of a s e n t e n c e in g r a m m a r (5a) c a n be d e t e r - mined b y counting the n u m b e r of o c c u r r e n c e s of " a n d J o h n " and t h e n retrieving the C a t a l a n of that n u m b e r . T h e s e a p p r o a c h e s b o t h take linear time ( o v e r practical r a n g e s of n), 9 w h e r e a s c h a r t p a r s i n g requires cubic time to parse sentences in these g r a m m a r s , a signifi- cant i m p r o v e m e n t .
So far we h a v e s h o w n h o w to c o m p u t e in linear t i m e the n u m b e r of a m b i g u o u s i n t e r p r e t a t i o n s of a s e n t e n c e in an " e v e r y w a y a m b i g u o u s " g r a m m a r . H o w e v e r , we are really i n t e r e s t e d in finding p a r s e trees, n o t just the n u m b e r of a m b i g u o u s i n t e r p r e t a - tions. We could e x t e n d the table l o o k u p algorithm to find trees r a t h e r t h a n a m b i g u i t y coefficients, b y m o d i f - ying the table to store trees instead of n u m b e r s . F o r parsing purposes, C a t i c a n be t h o u g h t of as a p o i n t e r to the i th entry of the table. So, for a s e n t e n c e in g r a m m a r (5a), for e x a m p l e , the machine could count
the n u m b e r of o c c u r r e n c e s of " a n d J o h n " a n d t h e n retrieve the table e n t r y for t h a t n u m b e r .
index trees
0 {[John]}
1 {[John and John]}
2 {[[John a n d John] a n d John], [ J o h n a n d [John a n d John]]}
T h e table would be m o r e general if i t did not specify the lexical items at the leaves. L e t us replace the table a b o v e with
index trees
0
{[x]}
1
{Ix x]}
2
{[[x x] x], [x [x x]]}
and assume the m a c h i n e c a n bind the x ' s to the a p p r o - priate lexical items.
T h e r e is a real p r o b l e m with this table l o o k u p m a - chine. T h e p a r s e t r e e s m a y n o t b e e x a c t l y c o r r e c t b e c a u s e the p o w e r series c o m p u t a t i o n a s s u m e d t h a t multiplication was associative, which is an a p p r o p r i a t e a s s u m p t i o n f o r c o m p u t i n g ambiguity, b u t i n a p p r o p r i a t e for constructing trees. F o r e x a m p l e , we o b s e r v e d t h a t p r e p o s i t i o n a l p h r a s e s and c o n j u n c t i o n are b o t h " e v e r y w a y a m b i g u o u s " g r a m m a r s b e c a u s e their a m b i g u i t y coefficients are C a t a l a n n u m b e r s . H o w e v e r , it is not the case t h a t t h e y g e n e r a t e e x a c t l y the s a m e p a r s e trees.
N e v e r t h e l e s s we p r e s e n t the table l o o k u p p s e u d o - p a r s e r here b e c a u s e it seems to be a speculative n e w a p p r o a c h with c o n s i d e r a b l e promise. It is o f t e n m o r e efficient t h a n a real parser, a n d the trees t h a t it finds m a y b e just as useful as the c o r r e c t o n e f o r m a n y practical purposes. F o r e x a m p l e , m a n y s p e e c h r e c o g - nition p r o j e c t s e m p l o y a p a r s e r to filter out syntacti- cally i n a p p r o p r i a t e h y p o t h e s e s . H o w e v e r , a full p a r s e r is n o t really n e c e s s a r y for this task; a r e c o g n i z e r such as this t a b l e l o o k u p p s e u d o - p a r s e r m a y be p e r f e c t l y a d e q u a t e for this task. F u r t h e r m o r e , it is o f t e n possi- ble to r e c o v e r the c o r r e c t trees f r o m the o u t p u t of the p s e u d o - p a r s e r . In particular, the d i f f e r e n c e b e t w e e n p r e p o s i t i o n a l p h r a s e s a n d c o n j u n c t i o n could b e ac- c o u n t e d for b y m o d i f y i n g the i n t e r p r e t a t i o n of the PP c a t e g o r y label, so that the trees would be i n t e r p r e t e d correctly e v e n t h o u g h t h e y are not exactly correct.
8 The table lookup scheme ought to have a way to handle the theoretical possibility that there are an unlimited n u m b e r of p r e p o - sitional p h r a s e s . The table l o o k u p r o u t i n e will e m p l o y a m o r e traditional p a r s i n g a l g o r i t h m (e.g., E a r l e y ' s a l g o r i t h m ) w h e n the n u m b e r of phrases in the input sentence is not stored in the table.
9 The linear time result depends on the a s s u m p t i o n that table lookup (or closed f o r m c o m p u t a t i o n ) can be p e r f o r m e d in c o n s t a n t time. This may be a fair a s s u m p t i o n over practical ranges of n, but it is not true in general•
Kenneth Church and Ramesh Patil Coping with Syntactic Ambiguity
T h e table l o o k u p a p p r o a c h w o r k s f o r primitive g r a m m a r s . T h e n e x t two sections show h o w to de- c o m p o s e c o m p o s i t e g r a m m a r s into series and parallel c o m b i n a t i o n s of primitive grammars.
(12a) G = G 1 . G 2 series
( 1 2 b ) G = G 1 + G 2 parallel
5. Parallel D e c o m p o s i t i o n
Parallel d e c o m p o s i t i o n can be v e r y useful for deal- ing with lexical ambiguity, as in
(13) ...to total with p r o d u c t s n e a r profits...
where " t o t a l " can be t a k e n as a noun or as a verb, as in"
(14a) T h e a c c o u n t a n t b r o u g h t the daily sales to total with products n e a r profits o r g a n i z e d according
to the new law. noun
(14b) T h e daily sales were r e a d y for the a c c o u n t a n t to total with p r o d u c t s n e a r profits o r g a n i z e d
according to the new law. verb
T h e analysis of these sentences m a k e s use of the additivity p r o p e r t y of linear systems. T h a t is, each case, (14a) and (14b), is t r e a t e d separately, and t h e n the results are added together. Assuming " t o t a l " is a noun, there are three prepositional phrases c o n t r i b u t - ing C a t 3 bracketings, and assuming it is a verb, there are t w o p r e p o s i t i o n a l p h r a s e s f o r C a t x ambiguities. C o m b i n i n g the two cases p r o d u c e s C a t 3 + C a t x = 5 + 2 = 7 parses. Adding a n o t h e r prepositional phrase yields C a t 4 + C a t 3 = 14 + 5 = 19 parses. (EQSP b e h a v e d as predicted in b o t h cases.)
This b e h a v i o r is generalized b y the following p o w e r series:
P N
(15) { t o V l ~ ( C a t i + l + C a t i ) ( P N)i
which is the sum of the two cases:
(16a) E Cati(P N) i = P N E Cati+i(P N) i noun
i>0 i
( 1 6 b ) to V E Cati(P N) i verb
i
This o b s e r v a t i o n can be i n c o r p o r a t e d into the table lookup p s e u d o - p a r s e r outlined above. Recall that C a t i is i n t e r p r e t e d as the i th index in a table containing all b i n a r y trees d o m i n a t i n g i leaves. Similarly, C a t i + C a t i + l will be i n t e r p r e t e d as an i n s t r u c t i o n to " a p p e n d " the i th entry a n d i + 1 th entry of the table, t0
(17) ( A D D - T R E E S
( C A T - T A B L E i) ( C A T - T A B L E ( + i 1)))
L e t us consider a s y s t e m where syntactic processing strictly p r e c e d e s s e m a n t i c and p r a g m a t i c processing. In such a system, h o w could we i n c o r p o r a t e s e m a n t i c
10 This can be implemented efficiently, given an appropriate representation of sets of trees.
and p r a g m a t i c heuristics o n c e we h a v e already p a r s e d the input s e n t e n c e and f o u n d that it was the sum of t w o C a t a l a n s ? T h e p a r s e r c a n simply s u b t r a c t the i n a p p r o p r i a t e interpretations. If the oracle says t h a t " t o t a l " is a verb, then (16a) would be s u b t r a c t e d f r o m the c o m b i n e d sum, and if the oracle says t h a t " t o t a l " is a noun, t h e n ( 1 6 b ) would be subtracted.
On the o t h e r hand, our analysis is also useful in a s y s t e m t h a t i n t e r l e a v e s s y n t a c t i c p r o c e s s i n g with se- m a n t i c a n d p r a g m a t i c p r o c e s s i n g . S u p p o s e t h a t we h a d a s e m a n t i c r o u t i n e t h a t could d i s a m b i g u a t e " t o t a l , " but only at a very high cost in e x e c u t i o n time. We n e e d a w a y to estimate the usefulness of executing the s e m a n t i c routine so t h a t we d o n ' t spend the time if it is not likely to p a y off. T h e analysis a b o v e provides a very simple w a y to estimate the b e n e f i t of disambig- uating " t o t a l . " If it turns out to be a verb, then (16a) trees h a v e b e e n ruled out, and if it turns out to be a noun, t h e n ( 1 6 b ) trees h a v e b e e n ruled out. We p r e f - er our declarative algebraic a p p r o a c h o v e r p r o c e d u r a l heuristic search strategies (e.g., K a p l a n 1972) b e c a u s e we do not h a v e to specify the o r d e r of evaluation. We can delay the binding of decisions until the m o s t o p - p o r t u n e m o m e n t .
6. S e r i e s D e c o m p o s i t i o n
Suppose we have a n o n - t e r m i n a l S that is a series c o m b i n a t i o n of two o t h e r n o n - t e r m i n a l s , NP and VP. By inspection, the p o w e r series of S is:
(18) S - - N P . V P
This result is easily verified w h e n there is an u n m i s t a k - able dividing point b e t w e e n the subject and the predi- cate. F o r example, the v e r b " i s " s e p a r a t e s the PPs in the subject f r o m those in the predicate in (19a), but not in (19b).
(19a) T h e n u m b e r of p r o d u c t s o v e r sales of ... is n e a r the n u m b e r of sales u n d e r ... clearly divided ( 1 9 b ) Is the n u m b e r of p r o d u c t s o v e r sales of ... n e a r
the n u m b e r of sales u n d e r ...? not clearly divided
In (19a), the total n u m b e r of parse trees is the p r o d u c t of the n u m b e r of ways of parsing the subject times the n u m b e r of ways of parsing the predicate. B o t h the subject and the predicate p r o d u c e a C a t a l a n n u m b e r of parses, and hence the result is the p r o d u c t of t w o C a - talan n u m b e r s , which was verified b y EQSP (Martin, Church, and Patil 1981, p. 53). This result c a n be f o r m a l i z e d in t e r m s of the p o w e r series:
(20) ( N X C a t i ( P N) i) ( i s X C a t j ( P N) j )
i j
which is f o r m e d b y taking the p r o d u c t of the two sub- cases:
(21a) N X Cati(P N) i subject
i
( 2 1 b ) is X. C a t j ( P N) j predicate J
Kenneth Church and Ramesh Patil Coping w i t h Syntactic A m b i g u i t y
T h e p o w e r series says that the a m b i g u i t y of a p a r - ticular sentence is the p r o d u c t of C a t i and Catj, where i is the n u m b e r of PPs b e f o r e " i s " and j is the n u m b e r a f t e r " i s . " This could be i n c o r p o r a t e d in the table lookup parser as an instruction to " m u l t i p l y " the i th e n t r y in the table by the jth entry. Multiplication is a c r o s s - p r o d u c t operation; L × R g e n e r a t e s the set of binary trees whose left s u b - t r e e 1 is f r o m L and whose right s u b - t r e e r is f r o m R,
- - m
(22) L x R = { ( l , r ) ll E L & r e R }
This is a f o r m a l definition. F o r practical purposes, it m a y be m o r e useful for the p a r s e r to o u t p u t the list in the f a c t o r e d form:
(23) ( M U L T I P L Y - T R E E S ( C A T - T A B L E i) ( C A T - T A B L E j))
which is m u c h m o r e concise t h a n a list of trees. It is possible, f o r e x a m p l e , t h a t s e m a n t i c p r o c e s s i n g c a n take a d v a n t a g e of factoring, capturing a s e m a n t i c gen- eralization that holds across all subjects or all predi- cates. Imagine, for e x a m p l e , that there is a s e m a n t i c a g r e e m e n t c o n s t r a i n t b e t w e e n p r e d i c a t e s a n d argu- m e n t s . F o r e x a m p l e , s u b j e c t s a n d p r e d i c a t e s might h a v e to agree on the f e a t u r e + h u m a n . S u p p o s e that we w e r e given s e n t e n c e s w h e r e this c o n s t r a i n t was violated by all a m b i g u o u s i n t e r p r e t a t i o n s of the sen- tence. In this case, it would be m o r e efficient to e m - ploy a f e a t u r e v e c t o r scheme ( D o s t e r t and T h o m p s o n 1971) which p r o p a g a t e s the f e a t u r e s in f a c t o r e d form. T h a t is, it c o m p u t e s a f e a t u r e v e c t o r for the union of all possible subjects, and a v e c t o r for the union of all possible VPs, and t h e n c o m p a r e s ( i n t e r s e c t s ) these vectors to check if there are a n y i n t e r p r e t a t i o n s t h a t m e e t the c o n s t r a i n t . A s y s t e m such as this, which keeps the parses in f a c t o r e d form, is m u c h m o r e effi- cient t h a n one that multiplies t h e m out. E v e n if se- mantics c a n n o t take a d v a n t a g e of the factoring, there is no h a r m in k e e p i n g the r e p r e s e n t a t i o n in f a c t o r e d form, b e c a u s e it is s t r a i g h t f o r w a r d to e x p a n d (23) into a list of trees ( t h o u g h it m a y be s o m e w h a t slow).
This e x a m p l e is relatively simple b e c a u s e " i s " helps the parser d e t e r m i n e the value of i and j. N o w let us return to e x a m p l e ( 1 9 b ) where " i s " does not s e p a r a t e the t w o strings of PPs. Again, we d e t e r m i n e the p o w - er series b y multiplying the two subcases:
(24) is ( N ~ C a t i ( P N ) i) (E. C a t j ( P N) j )
i j
= is N E E. C a t i C a t j ( P N ) l+J i j
H o w e v e r , this f o r m is not so useful f o r parsing b e c a u s e the parser c a n n o t easily d e t e r m i n e i and j, the n u m b e r of prepositional phrases in the subject and the n u m b e r in the predicate. It a p p e a r s the parser will have to c o m p u t e the p r o d u c t of t w o C a t a l a n s for each w a y of picking i and j, which is s o m e w h a t expensive, it
F o r t u n a t e l y , the C a t a l a n f u n c t i o n has s o m e special p r o p e r t i e s so t h a t it is possible algebraically to r e m o v e the r e f e r e n c e s to i and j. In the n e x t section we show h o w this expression c a n be r e f o r m u l a t e d in t e r m s of n, the total n u m b e r of PPs.
6.1 A u t o - C o n v o l u t i o n of Catalan G r a m m a r s
S o m e r e a d e r s m a y h a v e n o t i c e d t h a t e x p r e s s i o n (24) is in convolution form. We will m a k e use of this in the r e f o r m u l a t i o n . N o t i c e that the C a t a l a n series is a fixed p o i n t u n d e r auto-convolution ( e x c e p t f o r a shift); that is, multiplying a C a t a l a n p o w e r series (i.e., 1 + x + 2x 2 + 5x 3 + 14x 4 + ... Cati x i . . . ) with itself p r o d u c e s a n o t h e r p o l y n o m i a l with C a t a l a n c o e f f i - cients. 12 T h e multiplication is w o r k e d out for the first f e w terms.
1 + x + 2x 2 + 5x 3 + 14x 4 + ... × 1 + x + 2x 2 + 5x 3 + 14x 4 + ...
-t-
1 + x + 2x 2 + 5x 3 + 14x 4 + ... x + x 2 + 2x 3 -t- 5x 4 -t- ... 2x 2 + 2x 3 + 4x 4 + ... 5x 3 + 5x 4 -I- ... 14x 4 + ...
1 + 2x + 5X 2 + 14X 3 + 42X 4 -t- ...
This p r o p e r t y can be s u m m a r i z e d as:
(25) ~ C a t i x i y . C a t j x j = E C a t n + 1 x n
i j n
where n equals i + j .
Intuitively, this e q u a t i o n says t h a t if we h a v e t w o " e v e r y w a y a m b i g u o u s " ( C a t a l a n ) constructions, and we c o m b i n e t h e m in e v e r y possible w a y ( c o n v o l u t i o n ) , the result is an " e v e r y w a y a m b i g u o u s " ( C a t a l a n ) c o n s t r u c t i o n . With this o b s e r v a t i o n , e q u a t i o n (24) reduces to:
(26) is ( N E. C a t i ( P N ) i ) ( E C a t j ( P N) j )
l j
= is N ~ C a t n + l ( P N) n n
H e n c e the n u m b e r of parses in the auxiliary-inverted case is the C a t a l a n of o n e m o r e t h a n in the n o n - i n v e r t e d cases. As predicted, EQSP f o u n d the follow- ing i n v e r t e d s e n t e n c e s to be m o r e a m b i g u o u s t h a n their n o n - i n v e r t e d c o u n t e r p a r t s ( p r e v i o u s l y discussed on page 142) b y one C a t a l a n n u m b e r .
11 E a r l e y ' s a l g o r i t h m and m o s t o t h e r c o n t e x t - f r e e parsing algorithms actually work this way.
12 The p r o o f immediately follows from the z - t r a n s f o r m of the Catalan series ( K n u t h 1975, p. 388): zB(z) 2 = B(z) - l.
Kenneth Church and Ramesh Patil Coping with Syntactic Ambiguity
1 Was the n u m b e r ?
2 Was the n u m b e r of p r o d u c t s ?
5 Was the n u m b e r of p r o d u c t s of p r o d u c t s ? 14 W a s the n u m b e r of p r o d u c t s of p r o d u c t s
of p r o d u c t s ?
42 W a s the n u m b e r of p r o d u c t s of p r o d u c t s of p r o d u c t s of p r o d u c t s ?
1 It was the number.
1 It was the n u m b e r of products.
2 It was the n u m b e r of p r o d u c t s of products. 5 It was the n u m b e r of p r o d u c t s of p r o d u c t s
of products.
14 It was the n u m b e r of p r o d u c t s of p r o d u c t s of p r o d u c t s of products.
H o w could this result be i n c o r p o r a t e d into the table lookup p s e u d o - p a r s e r ? Recall that the p s e u d o - p a r s e r implements C a t a l a n g r a m m a r s b y returning an index into the C a t a l a n table. F o r e x a m p l e , if there were i PPs, the p a r s e r would return: (CAT-TABLE i). We n o w e x t e n d the indexing s c h e m e so t h a t the p a r s e r i m p l e m e n t s a series c o n n e c t i o n of two C a t a l a n g r a m - m a r s by returning one higher index t h a n it would f o r a simple C a t a l a n g r a m m a r . T h a t is, if there were n PPs, the p a r s e r would return (CAT-TABLE (+ n 1)).
Series c o n n e c t i o n s of C a t a l a n g r a m m a r s are v e r y c o m m o n in e v e r y d a y natural language, as illustrated b y the following two sentences, which have received c o n s i d e r a b l e a t t e n t i o n in the literature b e c a u s e the parser c a n n o t s e p a r a t e the direct o b j e c t f r o m the pre- positional c o m p l e m e n t .
(27a) I saw the m a n on the hill with a telescope ... ( 2 7 b ) Put the block in the b o x on the table in the
kitchen ...
B o t h e x a m p l e s have a C a t a l a n n u m b e r of ambiguities b e c a u s e the a u t o - c o n v o l u t i o n of a C a t a l a n series yields a n o t h e r C a t a l a n series. 13 This result c a n i m p r o v e parsing p e r f o r m a n c e b e c a u s e it suggests ways to re- organize (compile) the g r a m m a r so that there will be f e w e r r e f e r e n c e s to quantities t h a t are not readily available. This r e - o r g a n i z a t i o n will reap benefits that chart parsers (e.g., E a r l e y ' s algorithm) do not c u r r e n t - ly achieve b e c a u s e the r e - o r g a n i z a t i o n is taking a d v a n - tage of a n u m b e r of c o m b i n a t o r i c regularities, espe- cially
convolution,
that are not easily e n c o d e d into a chart. Section 9 p r e s e n t s an e x a m p l e of the re- organization.13 There is a difference between these two sentences because "put" subcategorizes for two objects unlike "see." Suppose we analyze "see" as lexically ambiguous between two senses, one that selects for exactly two objects like "put" and one that selects for exactly one object as in "I saw it." The first sense contributes the same number of parses as "put" and the second sense contributes an additional Catalan factor.
6.2 C h a r t Parsing
P e r h a p s it is worthwhile to r e f o r m u l a t e chart p a r s - ing in our t e r m s in order to s h o w which of the a b o v e results c a n be c a p t u r e d b y such an a p p r o a c h a n d which cannot. Traditionally, chart parsers m a i n t a i n a chart (or matrix) M, whose entries Mij c o n t a i n the set of c a t e g o r y labels t h a t s p a n f r o m position i to position j in the input sentence. This is a c c o m p l i s h e d b y find- ing a position k b e t w e e n i and j such that there is a p h r a s e f r o m i to k t h a t c a n c o m b i n e with a n o t h e r p h r a s e f r o m k to j. A n i m p l e m e n t a t i o n of the inner loop looks s o m e t h i n g like:
(28) Mij := { }
loop for k f r o m i to j do Mij := Mij u Mik * Mkj
Essentially, then, a c h a r t p a r s e r is m a i n t a i n i n g tlae invariant
(29) Mij = ~k Mik ° Mkj
where addition and multiplication of matrix e l e m e n t s is related to parallel and series c o m b i n a t i o n . Thus chart parsers are able to process very a m b i g u o u s sentences in p o l y n o m i a l time, as o p p o s e d to e x p o n e n t i a l ( o r C a t a l a n ) time.
H o w e v e r , the e x a m p l e s a b o v e illustrate cases where chart parsers are not as efficient as t h e y might be. In particular, c h a r t p a r s e r s i m p l e m e n t c o n v o l u t i o n the " l o n g w a y , " b y picking each possible dividing point k, and parsing f r o m i to k and f r o m k to j; they do not r e d u c e the c o n v o l u t i o n of t w o C a t a l a n s as we did above. Similarly, chart parsers do not m a k e use of the " e v e r y w a y a m b i g u o u s " generalization; given a C a t a - lan g r a m m a r , chart parsers will eventually e n u m e r a t e all possible values of i, j, and k.
7. C o m p u t i n g the P o w e r Series D i r e c t l y from t h e G r a m m a r
Thus far, m o s t of our derivations h a v e b e e n justi- fied in t e r m s of successive a p p r o x i m a t i o n . It is also possible to derive s o m e interesting (and w e l l - k n o w n ) results directly f r o m the g r a m m a r itself. Suppose, for the sake of discussion, that we c h o o s e to a n a l y z e ad- juncts with a right b r a n c h i n g g r a m m a r , t4 (By c o n v e n - tion, terminal s y m b o l s a p p e a r in lower case.)
(30) A D J S ~ a d j A D J S I A
First we translate the g r a m m a r into an e q u a t i o n in the usual way. T h a t
is,
ADJS is m o d e l e d as a parallel c o m b i n a t i o n of t w o s u b g r a m m a r s , adj ADJS a n d A. (A, the e m p t y string, is m o d e l e d as 1 b e c a u s e it is the14 A similar analysis of adjuncts is adopted in Kaplan and Bresnan 1981. This analysis can also be defended on performance grounds as an efficiency approximation. (This approximation is in the spirit of pseudo-attachment (Church 1980).)
Kenneth Church and Ramesh Patil Coping with Syntactic Ambiguity
identity element under series combination, i.e., multi- plication.)
(31a) ADJS -~ adj ADJS I A (31b) ADJS = adj . A D J S + 1
We can simplify (31b) so the right hand side is ex- pressed in terminal symbols alone, with no references to non-terminals. This is very useful for processing because it is much easier for the parser to determine the presence or absence of terminals t h a n of non- terminals. That is, it is easier for the parser to deter- mine, for example, whether a word is an adj, than it is to decide whether a substring is an ADJS phrase. The simplification moves all references to ADJS to the left hand side, by subtracting from both sides,
(31c) A D J S - a d j . A D J S = 1 factoring the left hand side,
(31d) (1 - adj)ADJS = 1
and dividing from both sides, (31e) ADJS = (1 - a d j ) -1
By performing the long division, we observe that (31) has unit coefficients.
adj adj 2
(31f) . 1 - 1 + - - = 1 + a d j + -
-1 - adj 1 - adj 1 - adj
= 1 + adj + adj 2 + adj3 - - ~ adj n
1 - a d j n
Grammars like ADJS will sometimes be referred to as a
step, by analogy to a unit step function in electrical engineering.
8. C o m p u t i n g t h e P o w e r Series f r o m t h e A T N
This section will re-derive the power series for the unit step grammar directly from the ATN representa- tion by treating the networks as flow graphs
(Oppenheim 1975). The graph transformations pres- ented here are directly analogous to the algebraic sim- plifications employed in the previous section.
First we translate the grammar into an ATN in the usual way (Woods 1970).
(32) A D J S - * a d j A D J S I A
(33)
ADJS: Cat adj ~_N..~Push ADJ .j...xpop
Jump
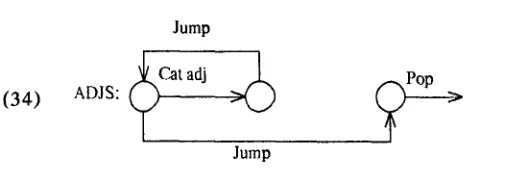
This graph can be simplified by performing a compiler optimization call tail recursion (Church and Kaplan 1981 and references therein). This t r a n s f o r m a t i o n replaces the final push arc with a jump:
Jump
+ C z t a d j ~ , ( ~ P o p
(34) ADJS: >
Jump
Tail recursion corresponds directly to the algebraic operations of moving the ADJS term to the left hand side, factoring out the ADJS, and dividing from both sides.
Then we remove the top jump arc by series reduc- tion. This step corresponds to multiplying by 1 since a jump arc is the ATN representation for the identity element under series combination.
(35)
ADJS:Cat adj ~ P o p
Jump
The loop can be treated as an infinite series: (36) 1 + adj + adj 2 + adj 3 + ...
where the zero-th term corresponds to zero iterations around the loop, the first term corresponds to a single iteration, the second term to two iterations, and so on. Recall that (36) is equivalent to:
(37) 1 1 --adj
With this observation, it is possible to open the loop:
(38) ADJS: Q1/(l-adj) ~ _ ~ P o p
After one final series reduction, the ATN is equivalent to expression (31e) above.
(38g) ADJS: Q . 1/(1-adj) e . . ~ P o p
Intuitively, an ATN loop (or step grammar) is a divi- sion operator. We now have composition operators for parallel composition (addition), series composition
(multiplication), and loops (division).
An ATN loop can be implemented in terms of the table lookup scheme discussed above. First we refor- mulate the loop as an infinite sum:
[image:8.612.312.565.55.147.2]Kenneth Church and Ramesh Patil Coping w i t h Syntactic Ambiguity
(39) 1 = ~ adji 1--adj i
Then we construct a table so that the i th entry in the table tells the parser how to parse i occurrences of adj.
9. An Example
Suppose for example that we were given the fol- lowing grammar:
(40a) S ~ N P V P A D J S
(40b) S --,. V NP (PP) ADJS ADJS (40c) VP -~ V NP (PP) ADJS (40d) P P - ~ P N P
(40e) NP -~ N I N P P P (40f) ADJS -~ adj ADJS ] A
(In this example we will assume no lexical ambiguity among N, V, P, and adj.)
By inspection, we notice that NP and PP are Cata- lan grammars and that ADJS is a Step grammar.
(41a) PP = ~ C a t i ( P N ) i i>0
(41b) NP = N ~ Cati(P N) i 1
(41c) ADJS = ~ adj i i
With these observations, the parser can process PPs, NPs, and ADJSs by counting the number of occurrenc- es of terminal symbols and looking up those numbers in the appropriate tables. We now substitute (41a-c) into (40c).
(42) VP = V NP (1 4- PP)ADJS
= V ( N .~ Cati(P N ) i ) ( . ~ Cati(P N ) i ) ( ~ adj i)
l l 1
and simplify the convolution of the two Catalan func- tions
(43) VP = V ( N ~. C a t i + l ( P N ) i ) ( . ~ adj i)
1 1
so that the parser can also find VPs by just counting coccurrences of terminal symbols. Now we simplify (40a-b) so that S phrases can also be parsed by just counting occurrences of terminal symbols. First, translate (40a-b) into the equation:
(44) S = N P V P A D J S + V N P ( I + P P ) A D J S A D J S
and then expand VP using (42)
(45) S = NP (V NP ( I + P P ) ADJS) ADJS + V NP ( I + P P ) ADJS ADJS and factor
(46) S = (NP + 1) V N P ( I + P P ) ADJS 2
That can be simplified considerably because
(47) NP (1 + PP) = N .E Cati(P N) i ~ Cati(P N) i
1 1
--- N .~ C a t i + l ( P N) i 1
and
(48) ADJS 2 = E adj i Y. adj i ___ ~ (i + 1)adj i
i i i
so that
(49) S = ( N . ~ C a t i ( P N ) i + 1) 1
V N .~ C a t i + l ( P N) i 1
Y. (i + 1)adj i i
which has the following ATN realization:
(50)
N " ~ Cati (p N)i V N " ~ C a t i + l (p N) i
Jump
" ~ (i + l)adj i
The entire example grammar has now been compiled into a form that is easier for parsing. This formula says that sentences are all of the form:
(51) S ~* ( N ( P N)*) V N (P N)* adj*
which could be recognized by the following finite state machine:
(52) S: Jump Jump
Jump
~M.J Jump " ~
Kenneth Church and Ramesh Patil Coping with Syntactic Ambiguity
F u r t h e r m o r e , the n u m b e r of p a r s e trees f o r a given input s e n t e n c e can be f o u n d b y multiplying three n u m - bers: (a) the C a t a l a n of the n u m b e r of P N's b e f o r e the verb, (b) the C a t a l a n of one m o r e t h a n the n u m - ber of P N's after the verb, and (c) the r a m p of the n u m b e r of adj's. F o r example, the s e n t e n c e
(53) T h e m a n on the hill saw the b o y with a tele- scope y e s t e r d a y in the morning.
has C a t 1 * C a t 2 * 3 = 6 parses. T h a t is, there is o n e w a y to parse " t h e m a n on the hill," t w o w a y s to parse " s a w the b o y with a t e l e s c o p e " ( " t e l e s c o p e " is either a c o m p l e m e n t of " s e e " as in ( 5 4 a - c ) or is a t t a c h e d to " b o y " as in ( 5 4 d - f ) ) , a n d t h r e e w a y s to p a r s e the adjuncts (they could b o t h a t t a c h to the S (54a,d), or t h e y could b o t h a t t a c h to the VP ( 5 4 b , e ) , or t h e y could split (54c,f)).
(54a)
(54b)
(54c)
(54d)
(54e)
(54f)
[The m a n on the hill [saw the b o y with a tele- scope] [ y e s t e r d a y in the m o r n m g . ] ]
T h e m a n on the hill [[saw the b o y with a tele- scope] [ y e s t e r d a y in the morning.]]
T h e m a n on the hill [[saw the b o y with a tele- scope] y e s t e r d a y ] in the morning.
[The m a n on the hill saw [the b o y with a tele- scope] [ y e s t e r d a y in the morning.]]
T h e m a n on the hill [saw [the b o y with a tele- scope] [ y e s t e r d a y in the morning.]]
T h e m a n on the hill [saw [the b o y with a tele- scope] y e s t e r d a y ] in the morning.
All and only these possibilities are p e r m i t t e d b y the g r a m m a r .
10. C o n c l u s i o n
We b e g a n our discussion with the o b s e r v a t i o n that c e r t a i n g r a m m a r s are " e v e r y w a y a m b i g u o u s " a n d suggested that this o b s e r v a t i o n could lead to i m p r o v e d p a r s i n g p e r f o r m a n c e . C a t a l a n g r a m m a r s w e r e t h e n i n t r o d u c e d to r e m e d y the situation so that the proc- essor can delay a t t a c h m e n t decisions until it discovers some m o r e useful constraints. Until such time, the p r o c e s s o r can do little m o r e t h a n n o t e that the input s e n t e n c e is " e v e r y w a y a m b i g u o u s . " We s u g g e s t e d that a table l o o k u p s c h e m e might be an effective m e - t h o d to i m p l e m e n t such a processor.
We then i n t r o d u c e d rules for c o m b i n i n g primitive g r a m m a r s , such as C a t a l a n g r a m m a r s , into c o m p o s i t e g r a m m a r s . This linear s y s t e m s view " b u n d l e s u p " all the parse trees into a single concise description c a p a - ble of telling us e v e r y t h i n g we might w a n t to k n o w a b o u t the parses (including h o w m u c h it might cost to ask a particular question). This a b s t r a c t view of a m b i - guity enables us to ask questions in the m o s t c o n v e n - ient order, and to delay asking until it is clear that the p a y - o f f will e x c e e d the cost. This a b s t r a c t i o n was
v e r y s t r o n g l y i n f l u e n c e d b y the n o t i o n of delayed binding.
We h a v e p r e s e n t e d c o m b i n a t i o n rules in three dif- f e r e n t r e p r e s e n t a t i o n systems: p o w e r series, ATNs, and c o n t e x t - f r e e g r a m m a r s , e a c h of which c o n t r i b u t e d its o w n insights. P o w e r series are c o n v e n i e n t f o r defining the algebraic o p e r a t i o n s , ATNs are m o s t suited for discussing i m p l e m e n t a t i o n issues, a n d c o n t e x t - f r e e g r a m m a r s enable the s h o r t e s t derivations. P e r h a p s the following q u o t a t i o n b e s t s u m m a r i z e s o u r m o t i v a t i o n f o r alternating a m o n g these three r e p r e s e n t a t i o n sys- tems:
A thing or idea seems meaningful only when we have several
different ways to represent it - different perspectives and differ- ent associations. Then you can turn it around in your mind, so to speak; however, it seems at the moment you can see it another way; you never come to a full stop. (Minsky 1981, p. 19)
In e a c h of these r e p r e s e n t a t i o n schemes, we h a v e i n t r o d u c e d five p r i m i t i v e g r a m m a r s : C a t a l a n , U n i t Step, 1, and 0, a n d terminals; and f o u r c o m p o s i t i o n rules: addition, subtraction, multiplication, and divi- sion. We h a v e seen t h a t it is o f t e n possible to e m p l o y these analytic tools in o r d e r to r e - o r g a n i z e (compile) the g r a m m a r into a f o r m m o r e suitable f o r processing efficiently. W e h a v e identified c e r t a i n situations w h e r e the a m b i g u i t y is c o m b i n a t o r i c , a n d h a v e s k e t c h e d a f e w modifications to the g r a m m a r t h a t ena- ble processing to p r o c e e d in a m o r e efficient m a n n e r . In particular, we h a v e o b s e r v e d it to be i m p o r t a n t f o r the g r a m m a r to avoid r e f e r e n c i n g quantities t h a t are not easily d e t e r m i n e d , such as the dividing point b e - t w e e n a n o u n p h r a s e and a p r e p o s i t i o n a l p h r a s e as in (55) Put the b l o c k in the b o x on the table in the
kitchen ...
We h a v e seen that the desired r e - o r g a n i z a t i o n c a n be achieved b y taking a d v a n t a g e of the fact t h a t the a u t o - c o n v o l u t i o n of a C a t a l a n series p r o d u c e s a n o t h e r C a - talan series. This r e d u c e d processing time f r o m O ( n 3) to almost linear time. Similar analyses h a v e b e e n dis- cussed for a n u m b e r of lexically and structurally a m b i - guous c o n s t r u c t i o n s , culminating with the e x a m p l e in s e c t i o n 9, w h e r e we t r a n s f o r m e d a g r a m m a r into a f o r m t h a t could be p a r s e d b y a single l e f t - t o - r i g h t pass o v e r the terminal elements. C u r r e n t l y , these g r a m m a r r e f o r m u l a t i o n s h a v e to be p e r f o r m e d b y hand. It ought to be possible to a u t o m a t e this process so t h a t the r e f o r m u l a t i o n s could be p e r f o r m e d b y a g r a m m a r compiler. We leave this p r o j e c t o p e n for future re- search.
11. A c k n o w l e d g m e n t s
We would like to t h a n k J o n Allen, Sarah F e r g u s o n , Lowell H a w k i n s o n , Kris H a l v o r s e n , Bill L o n g , Mitch M a r c u s , R o h i t P a r i k h , a n d P e t e r Szolovits f o r their v e r y useful c o m m e n t s on earlier drafts. W e w o u l d
especially like to thank Bill Martin for initiating the project.
R e f e r e n c e s
Church, K. 1980 On Memory Limitations in Natural Language Processing. M I T / L C S / T R - 2 4 5 , and IULC.
Church, K. and Kaplan, R. 1981 Removing Recursion from Natural Language Processors Based on Phrase-Structure Grammars. Paper presented at Conference on Modeling Human Parsing Strate- gies, University of Texas at Austin.
Dostert, B. and Thompson, F. 1971. How Features Resolve Syn- tactic Ambiguity. In Minker, J. and Rosenfeld, S., eds., Pro- ceedings of the Symposium on Information Storage and Retrieval.
Earley, J. 1970 An Efficient Context-Free Parsing Algorithm,
CACM 13:2.
Harrison, M. 1978 Introduction to Formal Language Theory. Addi- son Wesley.
Kaplan, R. 1972 Augmented Transition Networks as Psychological Models of Sentence Comprehension, Artificial Intelligence,
3:77-100.
Kaplan, R. and Bresnan, J. 1981 Lexical-Functional Grammar: A Formal System for Grammatical Representation. In Bresnan, J., ed., The Mental Representation of Grammatical Relations. MIT Press.
Knuth, D. 1975 The Art of Computer Programming. Vol. 1: Funda- mental Algorithms. Addison Wesley.
Liu, C. and Liu, J. 1975 Linear Systems Analysis. McGraw Hill. Malhotra, A. 1975 Design Criteria for a Knowledge-Based English
Language System for Management: An Experimental Analysis.
M I T / L C S / T R - 146.
Martin, W., Church, K., and Patil, R. 1981 Preliminary Analysis of a Breadth-First Parsing Algorithm: Theoretical and Experimental Results. M I T / L C S / T R - 2 6 1 .
Minsky, M. 1981 Music, Mind, and Meaning. MIT A.I. Memo No. 616.
Oppenheim, A. and Schafer, R. 1975. Digital Signal Processing.
Prentice Hall.
Sager, N. 1973 The String Parser for Scientific Literature. In Rustin, R., ed., Natural Language Processing. Algorithmic Press. Salomaa, A. 1973 Formal Languages. Academic Press
Woods, W. 1970 Transition Network Grammars for Natural Lan- guage Analysis, CACM 13:10.