Extracting Semantic Orientations of Phrases from Dictionary
Full text
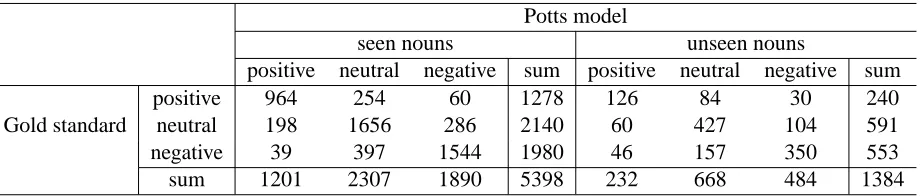
Figure
Related documents
proyecto avalaría tanto la existencia de una demanda real e insatisfe- cha de este servicio por parte de la población titular de derechos como la capacidad de ambos
For the poorest farmers in eastern India, then, the benefits of groundwater irrigation have come through three routes: in large part, through purchased pump irrigation and, in a
Following recent calls for a better understanding of public views of human enhancement (e.g., [ 8 ]), we exam- ined the role of the Dark Triad of personality (DT), trait
Patient-centric care network that evolve during inpatient stay in the hospital Our goal is to model the performance of coordination by analyzing the patient- centric
Therefore, this paper intends to share the Georgia Southern University Library’s (GSUL) experience of LibQUAL; specifically, how an academic library
The purpose of this mixed methods program evaluation was to identify the skills employers seek in current and future employees in three NAM Future Ready pilot internship sites,
The ethno botanical efficacy of various parts like leaf, fruit, stem, flower and root of ethanol and ethyl acetate extracts against various clinically
Experiments were designed with different ecological conditions like prey density, volume of water, container shape, presence of vegetation, predator density and time of
