Faculty of Humanities
Supervisor and 1st reader: Prof. Dr. N. O. Schiller
Second reader: Dr. L. Pablos Robles
Date: 06 June 2019
Selection of Chinese Classifiers in Noun Phrase
Production Involves a Competitive Process
Master Thesis for Theoretical and Experimental Linguistics
Declaration of originality
I hereby declare that this thesis was entirely my own work and that any additional sources of information have been duly cited.
I certify that, to the best of my knowledge, my thesis does not infringe upon anyone’s copyright nor violate any proprietary rights and that any ideas, techniques, quotations, or any other material from the work of other people included in my thesis, published or otherwise, are fully acknowledged in accordance with the standard referencing practices. Furthermore, to the extent that I have included copyrighted material, I certify that I have obtained a written permission from the copyright owner(s) to include such material(s) in my thesis and have included copies of such copyright clearances to my appendix.
I declare that this thesis has not been submitted for a higher degree to any other university or institution.
Acknowledgements
The completion of this Master’s thesis is creditable to a number of nice people to whom I will express my gratefulness in the following paragraphs.
First of all, I would like to thank my supervisor Prof. Dr. Niels. O. Schiller for his supervision throughout the entire process. He inspired me on the choice of this linguistic topic for my degree thesis and answered all my naïve questions with remarkable patience. Most importantly, during the seemingly-endless 11 months of working on my thesis, I have been receiving generous support from him as he swiftly responded to my reports and requests and made sure that I was on the right track. It has always been an incredible feeling to know that Dr. Schiller has more confidence in me than I do in myself, and as a newcomer to experimental linguistics I know I wouldn’t have been able to finish this thesis without his encouragement and empathy.
Also, I would like to extend my gratefulness to people in the electroencephalography lab. Dr. Leticia Pablos Robles as the lab manager introduced me to critical experimental software and was always a source of cheerfulness that broke into the stifling gloom pervading the lab; Mr. Jos. J. Pacilly was extremely reliable in troubleshooting technical issues and went to great lengths to write a Praat script for me, although in return I always poured questions at him and even kept him in the lab past dinner time; Ms. Sarah von Grebmer zu Wolfsthurn and Lisette Jager shared with me their precious experience with E-prime set up, experiment procedure and EEG data analysis; interns Luth and Lara helped me with electrodes attaching a few times before I became familiar with the process; besides, Ms. Roxanne Casiez and Tanja Westra were probably the people whom I spent most lab hours with and having them around was a soothing experience even though we were often just dealing with our own mess on different computers without exchanging a word.
My special gratitude also goes to Dr. Man Wang and Ms. Qiaoli Wang. The former is the main author of a comparative study concerned in this paper. Her research itself was already inspiring, not to mention that she kindly answered some of my questions through email correspondence; the latter helped me out with the intimidating process of residence permit extension so that I could run my analysis and write up the pieces in the Netherlands. Friends in Europe shall not be missed out from the acknowledgements. Ms. Amy Catling is my best friend at the university and our golden days together have given me so much relief of stress; Ms. Pingping Yu enlightened me on some basic German knowledge so that I gained a better understanding of literature on the language; Mr. Tom Denie freed me from the lab for weekly entertainment with his fun Dutch lessons; and Ms. Meng Zhang was absolutely my favorite food-hunting and rumble-exchanging buddy.
Lastly, I would love to send my appreciation to family and friends back home. My parents have always been my firmest supporter, even when I confessed my capricious wish for a degree in Linguistics. I would never have got this far without their unconditional love, and I hope that I have made them proud; my best friends Ms. Yuean Yu and Jiqiao Wang accelerated my progress to a large extent by repeatedly reminding me of how much I was missed in China. It is my greatest privilege ever to have all these wonderful people in my life!
Shaoyun Huang
Table of contents
Declaration of Originality...1
Acknowledgements...2
Abstract………...4
1. Introduction………..5
2. Literature Review………...5
2.1. Determiner and grammatical gender congruency effect……….5
2.2. Existing models for interpretation………..7
2.3. Classifier feature in Mandarin and its comparability to grammatical gender..9
2.4. Incorporation of picture-word interference paradigm and event-related potential………...10
2.5. Our predictions………..12
3. Methods……….15
3.1. Participants……….15
3.2. Materials………..15
3.3. Design and procedure………..……...15
3.4. Electrophysiological recording and data processing……….16
3.5. Comparison with the previous study………...17
4. Results………...….19
4.1. Behavioral data………..19
4.2. ERP data………..22
5. Discussion……….26
6. Conclusion……….30
References………..31
Appendix I….………...36
Abstract
In Chinese, when objects are named with their quantity, a classifier must be inserted between the number and the noun to produce the legitimate quantity * classifier * noun phrase. In the past few decades, research has proposed different models and interpretations for determiner or grammatical gender effect found in Indo-European languages, whereas the Chinese classifier congruency, despite its analogy to grammatical agreement, is relatively less studied in terms of activation process. In this study, we adopted a picture-word interference paradigm to examine participants’ naming latency of multiple objects and their electroencephalographic signals in 4 conditions by manipulating two factors: semantic relatedness and classifier congruency. Results show that in noun phrase production, naming latency is significantly longer in classifier-incongruent and semantically related conditions than in classifier-congruent and semantically unrelated conditions. Also, an N400-like effect was detected and found to be stronger in classifier-incongruent and semantically unrelated conditions. Together, the behavioral data and event-related potential analyses suggest that the use of classifier as a lexico-syntactic feature in Mandarin Chinese goes through a competitive selection process in noun phrase production. Findings are compared with an earlier study by Wang, Chen and Schiller (2018) that explored the same issues but in a bare noun naming setting where no significant difference by classifier congruency was found in naming latency. We therefore conclude that in accordance with Levelt’s model (Levelt, Roelofs & Meyer, 1999), classifier activation/selection takes place after the lemma retrieval process.
Keywords: Chinese classifier feature; event-related potential; overt speech production;
1. Introduction
The selection process of close-class items has been a topic of controversy for decades. Researchers debate over whether a special process takes place that differentiates the selection to that of open-class items (e.g. Dell, 1990; Stemberger, 1984). To peel the other potentially influential elements from the essence--the categorical status of close and open-class items, studies have been carried out to show that factors such as frequency and semantic relationship can have an impact on the speed of lexical access (see Mahon, Costa, Peterson, Vargas & Caramazza, 2007). Based on these findings, researchers proceed further to explore lexical access of close-class items in word-production scenarios. One of the subjects that has received much attention is the determiner, as its selection is often associated with grammatical gender, a lexico-syntactic feature of nouns in numerous languages. A less studied subject, however, is the selection of classifiers.
This paper therefore aims to place the selection of classifiers under the microscope. In Mandarin, the language under investigation here, it is mandatory to insert a classifier between an article/quantifier and the noun when a noun phrase is produced, and although studies have proved that the choice of classifier is based on properties of the noun object such as animacy, shape and usage (Shi, 1996; Tai, 1994; Tai & Chao, 1994; Tai & Wang, 1990), there is no single dominating rule that can decide which classifier to use for a certain category of nouns. In other words, classifier is a lexico-syntactic feature like grammatical gender but perhaps in a more predictable yet complex way. The question of how classifiers are activated and selected during speech production in Mandarin is therefore worth exploring as well. So far, a limited number of studies has focused on the topic, but research by Wang, Chen and Schiller (2018) has dug deep into the issue with both behavioral and electrophysiological means and concluded that the Mandarin classifier feature is automatically activated but not selected in bare noun naming. We thus build the current study following the same theoretical framework and adopting similar approaches, while making a few changes to the experimental design as well for the purpose of complementing the findings and extending the scope of the previous study.
2. Literature Review
2.1 Determiner and Grammatical Gender Congruency Effect
The facilitation or interference effects of those factors on determiner decisions have been tested in numerous studies. Lupker (1982) examined the effects from phonetically and orthographically similar distractors through a picture-naming task and observed facilitation from both types of distractors during the process of object name retrieval. The experiments by Schriefers (1993) left an important note in the history of determiner research as grammatical gender congruency was proved to have an impact on the speed of determiner in Dutch, reducing the naming latencies significantly when participants were asked to name pictures presented with words bearing the same gender. However, while Schriefers attributed the longer naming latencies in the incongruent condition to the competition of grammatical gender between target and distractor, this point was later disputed by researchers arguing that the effect lies in the selection of determiner forms, as it vanishes in the production of plural noun phrases (NP)--a situation where the need to distinguish determiners disappears while gender feature stays available (Schiller & Caramazza, 2003). The question of whether gender congruency effect truly exists in the selection of determiners and production of NPs has received attention from scholars conducting research in their respective language areas. Studies so far, however, have yielded cross-linguistic differences and hence diverse conclusions. In early studies on Dutch and German, the gender congruency effect was observed ( La Heij, Mak, Sander & Willeboordse, 1998; Schiller & Caramazza, 2003; Schriefers, 1993; Van Berkum, 1997), but since these are languages in which grammatical gender is the only decisive factor for determiner choice with singular form of noun, whether the finding can be generalized to other languages where gender is merely one of the cues is in question. This doubt seems to have been confirmed by studies in the Romance language family reporting absence of the effect (Costa, Sebastián-Gallés, Miozzo & Caramazza, 1999; Alario & Caramazza, 2002), as other features besides gender also have roles to play in the choice of determiner. For instance, Alario & Caramazza (2002) investigated potential gender congruency effect in French using the picture-word interference paradigm and found that although participants reacted to the manipulation of phonological resemblance of distractor words by reducing naming latencies in phonologically similar target and distractor scenarios, their performance nevertheless was not affected by grammatical gender congruency. It is therefore proposed that the observed “gender congruency effect” in Dutch and English should actually be interpreted as “determiner effect”. Observations from studies on German are also in line with the proposal, as participants took longer to produce masculine and neuter nouns in plural form that use a different determiner for their singular form (e.g. der Mund [the mouth],
die Münder [the mouths]; das Zimmer [the room], die Zimmer [the rooms]), as opposed to
the feminine nouns that keep the same determiner regardless of quantity (e.g. die Nase
[the nose], die Nasen [the noses]) (Schriefers, Jescheniak & Hantsch, 2002, 2005; Schiller & Caramazza, 2003). The phenomenon suggests that within the same grammatical gender, the production of NPs still goes through competition between determiners, indicating that determiner effect should be viewed as independent of gender congruency effect and that the naming latency differences attributed to the latter by previous research may actually be a result of the former.
congruency effect from another perspective. Findings from experiments within this new spectrum and the above-mentioned NP production studies somehow pointed to opposite directions. In a Dutch bare noun production task, La Heij and his colleagues (1998) failed to find the gender congruency effect, and the results were further attested by the study of Starreveld & La Heij (2004) that reported influence from phonological relatedness rather than gender congruency in the bare noun production experiment. On the contrary, Cubelli’s research team (Cubelli, Lotto, Paolieri, Girelli & Job, 2005) ran an experiment in Italian and found that, unlike what was seen in studies on Germanic languages, distractor words of the same gender actually displayed an interference effect on target pictures in bare noun naming tasks which disappeared when participants were asked to produce nouns with definite determiners. The inhibitory effect of gender congruency implies that grammatical gender is mandatorily selected in Italian and that the selection was competitive rather than automatic. Such contradictory patterns in Dutch/German and Italian were accounted for by the relative complex morphological structure of the latter (Scalise, 1994; Cubelli et al., 2005), since bare noun naming in Italian involves the inflectional paradigm specified by the ending vowel of the word, for example, a feature irrelevant in the production of bare nouns in Dutch. In other words, for bare noun production the selection of grammatical gender goes through a competitive process in morphologically complex languages like Italian but is of minor impact in languages like Dutch.
2.2 Existing Models for Interpretation
fixed direction and the activation spreads from one node to another until the most activated one is chosen for production.
Interestingly, the crucial differences among the various models may also suggest different statuses-- automatic or competitive, of grammatical gender selection in lexical access. For example, if parallel processing theories are adopted, simultaneous activation of multiple entries is possible, meaning that all other factors put aside, nouns of the same gender hyperactivate one single determiner while those of different genders activate their respective determiners. Following this logic, if grammatical gender selection is a competitive process, the NP production latency should be longer in the presence of incongruent genders; alternatively, if the selection is automatic, gender congruency effect should not be observed.
Explanation for the existence of determiner effect in Dutch and German NP production studies and lack of significant results in Romance family experiments is yet incomplete without taking into consideration the cross-language differences. Such differences are accommodated by late selection hypothesis (Miozzo & Caramazza, 1999) that offers a sound account of the flickering determiner effect. In Germanic languages, grammatical gender alone provides adequate information for determiner choice, hence overt influence on selection time; in Romance languages, however, selection is postponed till the release of phonological property of the noun since it can sometimes affect the determiner choice as well (e.g., in French: le chapeau (masc.) [the hat], la chambre (fem.) [the room], l’oiseau
(masc.) [the bird], l’étudiante (fem.) [the female student]). Therefore, according to this hypothesis, languages like Dutch and German can be classified as “early selection languages” whereas French and Italian as “late selection languages”.
Narrowing down the discussion to inspect determiner selection itself, models can be distinguished into the “unitized activation hypothesis” class and the “independent feature hypothesis” class (Alario & Caramazza, 2002). The former class posits that the retrieval of determiner form is held back until all elements of the “information chunk” including case, gender, and phonological representation are ready in place. The other class of hypothesis argues that all kinds of feature information independently activate candidates once they become available, so instead of waiting for the entire bundle of information to lead to an unambiguous answer, the candidates are selected based on the levels of pre-activation they each receive from existing feature information. Along with the other speech production models and hypotheses within the scope of determiner selection, implications can be derived from the two classes that for a late selection language, significant difference in the determiner selection speed or naming latency by a specific feature would only be possible under the prediction of the independent feature hypothesis. As was demonstrated by Alario and Caramazza’s study, the gender of the distractor word does not affect the naming latency in French NP production, yet standardness (whether the form of the determiner is used with consonant-initial or vowel-initial words of that gender) of the determiner does play a role.
2.3 Classifier feature in Mandarin and its comparability to grammatical gender
Indo-European family, Chinese does not have a grammatical gender division in its nominal system; rather, it employs a nominal classifier system that is in some ways comparable with the gender division and in others not. In Chinese noun phrases, classifiers are preceded by a numeral, a demonstrative or a quantifier and followed by the noun (Li & Thompson, 1989) (e.g., 一把椅子 “yibayizi”, [one * classifier * chair]). Classifiers as a nominal feature are similar to grammatical gender of nouns as both are an inherent property of the word and neither can be omitted or disregarded for NP production. However, while the assignment of gender to nouns is quite arbitrary and can differ even in closely related languages from the same family, nouns categorized by the same classifier do share some perceived similarities. Although no single rule can be imposed on the association of classifier and noun, it is more or less predictable from clues such as animacy, function, shape, size and texture (Allan, 1977; Croft, 1994; Lakoff, 1986; Tai, 1994;Tien, Tzeng, & Hung, 2002; Bi, Yu, Geng, Alario, 2010). For example, despite being widely different in function, texture, or semantic category in general, 手枪 “shouqiang” [gun]and 牙刷“yashua” [toothbrush] share the same classifier
把 “ba” due to the fact that they both have a handle. Another distinctive characteristic that discriminates Chinese classifier from grammatical gender is the absence of one-to-one correspondence between nouns and classifiers; in fact, it is not unusual for a noun to have multiple classifiers. For instance, the classifier for 邮票 “youpiao” [stamp] can be 张 “zhang” when it is mainly perceived as “flat and thin”, but another classifier, i.e. 枚 “mei”, can apply too if the feature “tiny” is also highlighted; meanwhile, 棉花“mianhua” [cotton] as fabric is in most cases associated with the classifier 团 “tuan”, but when the same noun is used to refer to the fruit of the plant, the classifier 朵 “duo” is also legitimate; finally, classifiers can also change for the same object in different amounts, hence 一条鳄鱼 “yitiaoeyu” for “a crocodile” and 一群鳄鱼 “yiquneyu” for “a pack of crocodiles”. The choice of classifiers for noun in Chinese therefore has a lexico-syntactic nature defined by ambiguous patterns that are flexible to cater for various factors. The major influence of semantic category on classifier assignment has already been attested, with implications that classifiers and nouns undergo similar semantic constraints (Bi et al., 2010), even though the relationship is in many cases opaque (Tzeng, Chen, & Hung, 1991). Nevertheless, even though the use of a classifier in front of a noun depends in general to a great extent on whether there is semantic overlap, it is the noun itself in the context that has a dominant effect on associable classifiers (Shao, 1993).
(2009), however, conducted a similar experiment and found classifier congruency effect through both bare noun naming and NP production tasks. One of the most recent studies on the topic is the research by Wang et al. (2018) using a 2 x 2 within-subject design on whether classifier choice is an automatically activated or competitively selected process. Behavioral analysis of data revealed a significant effect on naming latency of bare nouns from semantic relatedness, one of the two factors of the experiment. No effect, however, was detected from the other factor, namely the manipulated classifier congruency. The absence of classifier congruency effect is in accordance with the 2006 study, but since the new experiment only contained the bare noun naming task, the findings with NP production in former studies were not examined. Wang et al. also made an advanced step to approach the question with electroencephalography (EEG) analysis. The large negative wave observed in the semantically unrelated condition resembles an N400 effect and resonates with the behavioral data findings. More importantly, a significantly stronger N400 effect was also observed in classifier-incongruent condition than congruent condition, which Wang et al. interpreted as a result of the spreading activation from activated lemma. In short, the study concluded that the classifier feature in Chinese is activated automatically, but not selected.
2.4 Incorporation of picture-word interference paradigm and event-related potential
As is mentioned in 2.3, Wang et al. (2018) in their study on classifier congruency effect recorded both behavioral and event-related potential (ERP) data. Significant difference in naming latencies was found between the semantically related and unrelated conditions, as well as a classic N400 effect in the latter. Although the analysis of naming latencies revealed no significant influence from classifier congruency, the ERPs still pointed to a stronger negative wave within the N400 time window in the incongruent condition. It was based on this exact observation that Wang et al. drew the conclusion of automatic activation of classifier in bare noun naming. Similar results have also been seen in studies focusing on the grammatical gender congruency effect in Indo-European languages. For instance, Boutonnet and his colleagues (2012) tested bilingual English-Spanish speakers and monolingual native English speakers on an all-English semantic categorization task where half of the equivalent Spanish words are masculine and the other half feminine. Although the behavioral data analysis has shown no priming effects from semantic relatedness or gender congruency, the ERPs analysis demonstrated a more negative N400 effect in semantic unrelated condition for both participant groups, and less negative left anterior negativity (LAN) amplitudes in the gender-consistent condition within the bilingual group only, thus supporting the unconscious accessing of grammatical gender information in Spanish. Given such findings, ERP as a means of measurement of electrophysiological response to stimuli can make up for the missing piece in the outcome-dependent traditional object naming studies by capturing implicit brain activities for more comprehensive and better interpretation of data. In fact, since 1980s numerous production studies have already incorporated ERPs analysis in the discussion (e.g., Duncan-Johnson & Kopell, 1981; Liotti, Woldorff, Perez III & Mayberg, 2000), despite the fear of potential artifacts from facial muscle movement during overt speech production. Different time windows have been assigned to the respective stages of word production. In stimulus-locked scenarios, for example, the window between 150-250 ms is believed to reflect lexical activation (Indefrey & Levelt, 2004). Van Turennout, Hagoort, and Brown (1998) have conducted the ERP experiment with lateralized readiness potential (LRP) measurements that narrowed down the time range for the start of phonological encoding retrieval in Dutch to 40 ms after gender information is accessed. Koester and Schiller (2008), on the other hand, studied morphological priming in Dutch and found from ERP evidence that the encoding took place at around 350 to 400 ms after the presentation of picture onset. Findings also include the approximate 300-450 ms window for phonological encoding after picture onset for both passive viewing and in a PWI paradigm (Eulitz, Hauk & Cohen, 2000; Dell’Acqua, Sessa, Peressotti, Mulatti, Navarrete & Grainger, 2010; Sahin, Pinker, Cash, Schomer & Halgren, 2009), as well as the precedence of semantic processing over phonological encoding reflected by both LRP and N200 data (Schmitt, Münte & Kutas, 2000) and over syntactic processing by 80 milliseconds (ms) in tacit speaking shown by N200 data peak latency (Schmitt Rodriguez-Fornells, Kutas, & Münte, 2001).
Zhang & Min, 2012; Hsu, Tsai, Yang & Chen, 2014). However, apart from the classic N400 and simple classifier-noun relations, researchers have also explored the classifier feature in different situations with a broader scope of brain activities. In 2014, Chou, Huang, Lee and Lee looked into the use of classifier for the prediction of upcoming noun in classifier-noun agreement through manipulating constraint strength of classifier and cloze probability of noun. A less positive P200 effect, along with enhanced frontal negativity, was detected with weakly constrained classifiers, and an N400 effect was found to be subject to the interaction between the two factors. The P600, an index for structural re-analysis (e.g. Friederici, Hahne, & Mecklinger, 1996; Osterhout, Holcomb, & Swinney, 1994), on the other hand, was examined in long distance classifier mismatch processing experiments with object-gap relative clause inserted into the noun phrase (Chen, Xu, Tan, Zhang & Zhong, 2013; Hsu et al., 2014). All these findings have demonstrated benefits ERPs analysis can bring to linguistic research. Therefore, in the current paper we attempt to incorporate both behavioral data and ERPs analysis in the hope of generating more insights on classifier congruency effect in NP production.
2.5 Our predictions
Following the theoretical framework embedded in Wang et al.’s (2018) study (hereafter “the previous study”), we collect behavioral data (naming latencies) and ERP data while manipulating the two potentially influential factors, semantic relatedness and classifier congruency in a PWI paradigm. We will therefore make predictions of our results based on the empirical evidence regarding the two factors, respectively.
in naming latency, albeit no longer as reflection of lexical competition. With analysis of ERPs data, the semantic unrelatedness should evoke a larger negative wave in the time window around 400 ms post-stimulus that is especially robust in centro-parietal regions due to N400 effect, a common observation in many existing studies involving electrophysiological analysis on semantic category relatedness. Nonetheless, we should perhaps also bear in mind that the N400 effect is quite sensitive to repetition (Van Petten, Kutas, Kluender, Mitchiner & McIsaac 1991). Since each of the target pictures in the current study appears 8 times and each distractor word twice, we may possibly extract the negative wave with a reduced amplitude.
Putting semantic relatedness aside though, the most prominent difference of the current study and the comparable previous study lies in the nature of tasks: the former requires participants to perform NP production and the latter deals with simple bare noun naming. In other words, while classifiers for both target pictures and distractor words were implicit in the previous study, the requirements of our task have determined that participants must explicitly produce the right classifiers for the target pictures but not for the distractor words. Consequently, contrary to the previous study, we can first rule out the possibility of non-activation of classifiers for target concepts, which in turn means that highly comparable naming latencies and electrophysiological activities between classifier-congruent and incongruent conditions are not expected. The two possibilities left are automatic activation and competitive selection. If the former turns out to be the case, difference in naming latency would not be observed, but the electrophysiological activities in the two conditions should be different. Since the previous study found a stronger N400 effect in the classifier-incongruent condition compared to the congruent condition presumably due to the automatic activation of classifiers, in the present study we expect to also see an N400-resembling effect within a similar time window. The predicted electrophysiological observation under this possibility is supported by research of Barber & Carreiras (2005) that detected similar effects of gender disagreement for covert production of noun phrases. However, it is important to note that although the automatic activation of classifier in NP production is not unusual, null effects of congruency in both NP and bare noun production will make Chinese a unique language that is different from either the morphologically complex Romance family and the relatively more simple Germanic pair. Meanwhile, it will also contradict the findings from Wang et al. (2006) and Zhang and Liu (2009) studies. In the alternative case, if the classifier access is a rather selective process in NP production in Chinese, the dichotomy of classifier congruency for target pictures and corresponding distractor words would lead to significant difference in naming latencies. Specifically, the naming latency should be shorter in classifier-congruent condition than in incongruent condition. Likewise, we would also predict an N400-type effect that is stronger in classifier-incongruent trials than congruent ones. This together with findings from the previous study would support Wang et al.’s (2006) conclusion that classifier encoding in Chinese is only necessary in NP production. Moreover, the selection and by-passing of classifier in NP production and bare noun naming, respectively, suggest that Chinese resembles German and Dutch in terms of the encoding of lexico-syntactic features in speech production.
production represented by the WEAVER and Levelt’s model (Roelofs, 1992, 1993, 1997, 2003; Levelt et al. 1999) proposes that lexical selection and determiner choice takes place in an irreversible sequential order. Since the classifier feature, like grammatical gender, is dominated by individual nouns (Shao, 1993), its selection or activation cannot precede the processing of noun. Semantic relatedness would affect the speed of noun selection and thereby determiner selection because lemma selection happens in between semantic and phonological information activations. As a result, a significant effect from semantic relatedness on naming latency is expected, but without interaction with the classifier congruency factor. Another representative serial hypothesis, the Independent Network model (Caramazza and Miozzo, 1997) would also suggest no interaction between the two factors given that lemma selection follows a separate lexical node according to this theory and that activation of features like grammatical gender, or in this case classifiers, receive activation from phonological encoding. However, if speech production, as argued by parallel-processing models, is a cascading process that allows interactions and convergence in any direction in between nodes and levels of representation (e.g. Dell, 1994; also see Dhooge et al., 2016 for a summary), activation of a lexical unit would activate the corresponding classifier too, and the presence of distractor words would cascade activation to their respective classifier nodes. When the target picture and distractor word come from the same semantic group, the distractor has more levels of activation, hence more activation of its classifier as well. If classifier choice is competitive, the classifier-congruent condition would witness a facilitation effect on the target classifier from the distractor; in the classifier-incongruent condition though, extra activation of the non-target classifier would lead to more competition and slow down the selection process. On the other hand, when the target picture and the distractor word are semantically unrelated, both have lower levels of activation. Consequently, in the classifier-congruent condition there might still be spreading activation, but not as much as in the case of semantic relatedness; in the classifier-incongruent condition, there would be a smaller delaying effect as a result of less activation of the distractor.
3. Method 3.1 Participants
Twenty-five native Mandarin Chinese speakers (mean age = 24, SD = 2.9; 21 females) studying at Leiden University in the Netherlands as registered students or exchange students were recruited for the experiment. All of them are native Mandarin speakers who also speak one or more other languages. Notably, some of them were born and raised in southern regions of China where local dialects are spoken at home and in neighborhoods as dominant languages, which can have a consequence on their performance. Participants were given informed consent forms to sign before participating in the experiment. All of them had normal or corrected-to-normal vision and none reported a history of brain impairments or surgeries. Participants were paid for their participation, regardless of the level of performance.
3.2 Materials
rest were all bi-syllabic. Some of the target objects or their corresponding pictures were replaced with those that participants could more easily agree on, according to observations from pilot studies.
Four distractor words were chosen for each target, resulting in 120 combinations of target and distractor pairs in total. Distractors differed in whether or not they belonged to the same semantic category and whether or not they were associated with the same classifier as the targets. The distractors were strictly controlled for word frequency based on the Modern Chinese Frequency Dictionary (1986) and visual complexity determined by number of strokes (average strokes of distractor words are restricted to a narrow range from 14.7 to 16.6 across four conditions). Distractors do not bear phonological or orthographic relatedness to each other or to the targets.
3.3 Design and Procedure
The experiment has a 2 by 2 within-subject design. Classifier congruency (C) and semantic relatedness (S) are the two main factors with two levels each, so together they create four conditions for the target and distractor combination: C+S+, C-S-, C+S- and C-S+.
In each trial, either two or three identical pictures appear simultaneously on the screen. In other words, participants saw target pictures presented in both two or three in each condition, resulting in eight appearances of each target. Each participant therefore went through 240 recorded trials in total.
The Windows program Mix (Van Casteren & Davis, 2006) was used to assign a pseudo-random order to the trials. After each trial, a minimal distance of 10 other trials was inserted until the same target appeared again. No two targets associated with the same classifier or two identical conditions under different targets were allowed to appear in consecutive trials. Trials with the same number of pictures were made to appear at most twice in a row in order to prevent priming effects from preceding trials. The pseudo-randomization procedure was repeated once the same trial order has been used twice, so that potential ordering effects could be counterbalanced.
A complete experiment was made up of three sessions. Participants began with the familiarization session in which they were taught the intended names of the target items by slides containing a picture of the item and its name beneath. Each slide stayed on the screen for 3,000 ms. After all 30 slides had been played, participants were informed of the upcoming practice session by a slide announcing that they should now expect to see two or three identical pictures at the same time without the names. In the middle of the screen, the meaningless letter string “XX” would appear surrounded by the pictures. Participants were asked by the slide to ignore the “XX” and name the pictures with the name they had learnt in the familiarization session. An example was given before the 30 slides to make sure that participants knew the right way of naming-- that is, “number-classifier-item”. They got corrected by the end of the practice session if they used wrong names or unintended classifiers.
being that the picture in it was not one of the targets. This was to notify the participants that they should now expect distractor words to appear where “XX” used to be in the practice session. The experimenter then explained through microphone, along with instructions on screen, that the idea was to repeat what the participant did in the practice session regardless of the use of distractor words. The 240 trials were divided evenly into 4 sessions, with a break in between every two sessions (the length of which was determined by participants). Each trial started with the presentation of a fixation point “+” for 300 ms and then switched to a blank screen for another 300 ms. Then the slide with target pictures and distractors began to play for 3,000 ms and faded out no matter whether or not a response was given or not by the participants. The slide was followed by another display of a blank screen for 500 ms as the closure of the trial. One “warm-up” trial with non-target pictures were placed at the beginning of each section to acquaint (and re-acquaint) the participants with the task after the intermissions, without informing the participants that their responses in these trials would not be recorded.
Participants were sat in front of a computer in a soundproof recording booth that was dimly lit. At the beginning of the practice session as well as each of the four sessions in the experimental part, texts were displayed on the screen to emphasize that participants should respond in a fast and accurate manner. Recording was switched on for the entire period of the 3,000-ms slide in each trial for measurement of response time in Praat 6.0.49v (Boersma & Weenink, 2019) later. The electroencephalogram (EEG) was also recorded during the experimental session of the experiment.
3.4 Electrophysiological recording and data processing
Thirty-two Ag/AgCI electrodes on the standard scalp sites of the extended international 10/20 system were used to measure and record EEG data. A total of six flat electrodes were attached to each participant’s facial skin to record electrical potentials. Four of them were placed around the eyes to detect blinks and horizontal eye movements and two at the mastoid positions to be used for the purpose of re-referencing data.
some of these participants had an acceptable artifact rate, but when trials containing incorrect responses were also excluded, the number of remaining usable epochs were considered insufficient with more than 40% data loss or unbalanced available trials across conditions. In the end, a total of ten out of twenty-one clean datasets were left for ERPs data analysis.
3.5 Comparison with the previous study
As is stated in the introduction, this study adopted the theoretical structure and major assumptions of the previous study, but numerous things have been changed in the experimental design and procedure to make it not a mere replication, but an extension of the former research. Such changes allow us to modify some original settings that can be vulnerable to queries, while at the same time serve as verification of the obtained results. Therefore, being aware of these changes is crucial to understanding the ways in which the two studies correspond to and differ from each other.
The first and foremost difference between the two studies is of course the tasks themselves. In the previous study, participants were asked to perform a bare noun naming task; the current experiment, however, demanded a more complicated noun-phrase naming task, which involved counting numbers, selecting classifiers and accessing lexical items. By requiring participants to articulate the actual classifier, we were able to ensure that their choices of classifiers were in line with our intended ones and replace after pilot experiments those target nouns that were often associated with other classifiers and hence improper as stimuli. This could never have been done with the original task, for no matter how informative results from a bare noun naming task can be, participants’ actual preference of classifiers would not be traceable, thus posing a disadvantage in a study where classifier use is one of the most critical components.
Besides the change of task, the current study also differs from the previous one in that the classifiers chosen for the experiment were more widely and evenly distributed. The previous study employed 12 classifiers in total, and usage of the same classifier could mount up to 8 times out of 30 (26%), which significantly increased the risk of hyperactivation of or expectation for that particular classifier at some point of the experiment. To avoid this, the current study included 16 different classifiers and strictly controlled the maximal appearance of each classifier under 3 times (10%), reducing the variance of classifier use from as high as 3.90 in the previous study to 0.65 in the current one.
Moreover, the stimuli used in the current study look quite different from those that were used in the previous one. Despite the clear advantages of keeping the same stimuli for better comparison, we decided to replace some of the targets as well as the targets due to a number of concerns, which include1:
a) Targets to which a concept cannot easily be linked without attention to details of corresponding picture (e.g. 支票 “zhi1piao4”, [check]);
b) Stimuli associated with more than one commonly used classifier (e.g. 大 蒜 “da4suan4”, [garlic]); this is especially important for distractors whose classifiers
vary by shape/position/number(e.g. 画纸 “hua4zhi3”, [drawing paper]), since clues from the picture are not available;
c) Stimuli believed to be associated with a different classifier than the one used in the previous study were excluded (e.g. 梨 “li2”, [pear]);
d) Stimuli similar in meaning or form with one another (e.g. 鼓 “gu3”, [drum] with 大鼓 “da4gu3”, [big drum]).
Lastly, the potential inconsistency of target picture presentation has been taken care of. The way stimuli were revealed to participants in the previous study was to show pictures with distractor words superimposed on them. However, although this should have caused no problem for simple line drawings of large objects (i.e. cow), it remains unclear how texts could appear without overlapping part of the pictures for items with distinct shapes (i.e. pen) or complex details (i.e. church). On the contrary, in the current study distractor words were placed in the center of the screen and surrounded by the target pictures so that they never overlapped each other.
Table 1. Example of slides used in the experimental session in all the classifier congruency (C) and semantic relatedness (S) conditions.
Condition
Target picture- knife
C+S+ C+S- C-S+ C-S-
Classifier - /ba3/
把
distractor fork
/cha1zi0/ 叉子
plate
/pan2zi0/ 盘子
fan
/shan4zi0/ 扇子
cigar
/xue3jia1/ 雪茄
Classifier of
distractor
/ba3/ 把 /ge4/ 个 /ba3/ 把 /zhi1/ 支
4. Results
4.1 Behavioral data
seriously delayed responses due to unexpected external distractions; naming latencies exceeding 3 SDs around the participant’s average response time; 1.21%)
Given that both our participants and items only represented a random, trivial subset drawn from the vast population of potential participants and stimuli, we must control for the randomness and avoid the risk of increasing likelihood of Type I error due to the unaccounted variability of participant and item choice (for a detailed discussion, see Appendix II). Instead of the classic repeated measures ANOVAs test that only submits condition means across either subjects or items to analysis, the general mixed effects regression was employed in this study to control for potential random effects of both subject and item simultaneously2. The analysis was run in R (R core team, 2012) along with the “lme4” package (Bates, Maechler & Bolker, 2012) with response time (RT) as a function of classifier congruency (same classifier vs. different classifiers) and semantic relatedness (same category vs. different categories).
Figure 1. The means of naming latency achieved in 4 conditions. Naming latencies in the semantically related condition were significantly longer than those in the semantically unrelated condition. Similarly, naming latencies in the classifier-incongruent condition were significantly longer than those in the classifier-congruent condition. No interaction was detected between classifier congruency and semantic relatedness.
2 Nevertheless, ANOVA analysis was still performed for the sake of comparison with the previous
Figures 2a & b. Naming latency averaged across the classifier congruency conditions and separately across the semantic relatedness conditions.
The model turned out to draw significant results with classifier congruency and semantic relatedness as fixed effects and intercepts for participants and target objects as random effects. A main effect of classifier congruency was found on RT (χ2(1) = 4.189, p = 0.041),
reducing the naming latency by 9.899 ± 4.835 ms when the target and the distractor have the same classifier. Semantic relatedness also had a main effect on RT (χ2(1) = 4.981, p =
0.026), prolonging the naming latency by 10.796 ± 4.836 ms when the target and the distractor belong to the same semantic category. Possible interaction of the two main factors has also been examined, but no significant effect was found on RT (χ2(1) = 1.042, p
= 0.307).
considered. Results of analysis using the lme4 package in R reveal that both classifier congruency and semantic relatedness had a significant influence on naming latencies.
t Resp t Resp t Resp
Predictors Estim ates
CI p Estima
tes
CI p Estima
tes
CI p
(Intercept) 0.87 0.82 –
0.93
<0.00 1
0.87 0.81 –
0.92
<0.00 1
0.87 0.82 – 0.93 <0.00
1
Incongruent 0.01 0.00 –
0.02
0.040 0.01 0.00 – 0.02 0.041
Unrelated -0.01 0.02 –
-0.00
0.026
Random Effects
σ2 0.03 0.03 0.03
τ00 0.00 Item 0.00 Item 0.00 Item
0.01 Subject 0.01 Subject 0.01 Subject
ICC 0.37 0.37 0.37
N 21 Subject 21 Subject 21 Subject
30 Item 30 Item 30 Item
Observatio ns
4701 4701 4701
Marginal R2 /
Conditional
R2
0.000 / 0.374 0.001 / 0.375 0.001 / 0.376
26.44% of all experimental trials were dropped from analysis due to incorrect responses (6.16%) and artifact rejection (20.28%). For each condition, an average of 49 epochs were available for analysis. The data were categorized into 4 regions of interest (ROIs): left fronto-central (F3, C3, FC1, FC5), right fronto-central (F4, C4, FC2, FC6), left centro-parietal (CP1, CP5, P3, PO3) and right centro-centro-parietal (CP2, CP6, P4, PO4), given that the distribution of N400 component is maximal over the centro-parietal electrode sites (see Kutas & Federmeier, 2009 for a review). The categorization is also kept the same as Wang et al.’s (2018) previous research for the purpose of comparison. Epochs in each trial were divided into 3 consecutive windows (0-235 ms, 235-405 ms and 405-580 ms) based on visual inspection of ERP peaks and previous studies (Costa et al., 2009; Dell’Acqua et al., 2010, Zhu et al., 2015) in order to avoid biasing ERP component measurement procedures toward significant but bogus effects (Luck & Gaspelin, 2017). Repeated analysis of variance (ANOVA) was conducted separately for every time window on mean amplitudes of segmentations for all selected channels with the R software (R core team, 2012) using the
ez package (Lawrence, 2016). The two independent variables of classifier congruency (2 levels) and semantic relatedness (2 levels) that were used in the behavioral data analysis were also used as predictors in the ERPs analysis, together with ROIs (4 levels).
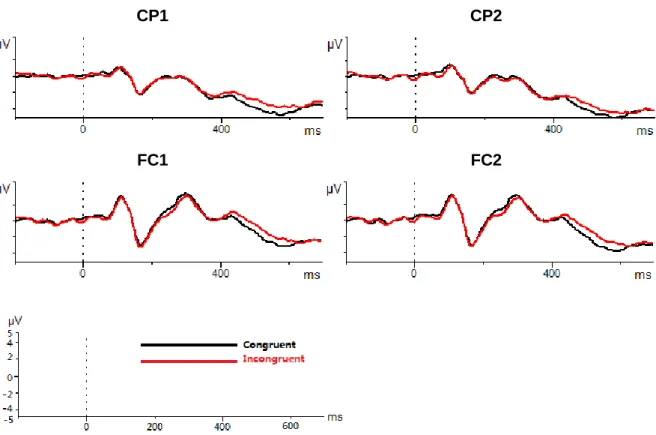
Repeated ANOVA were run in time window 0-235 ms, 235-405 ms and 405-580 ms, respectively. Since the mean amplitudes obtained were averaged across items, only the by-subject analysis was performed. In the first two time windows, no significant effect was found from any of the three factors (except ROI in the second window), nor from the two-way or three-two-way interactions of the factors. In the time window 405-580 ms, we observed a negative wave that peaked approximately between 420 and 460 ms, and a main effect was found from classifier congruency, F(1, 9) = 5.34, p = 0.046, semantic relatedness, F(1,9) = 5.17, p = 0.049, as well as ROI, F(3, 27) = 3.48, p = 0.030. This denotes an N400-like effect that was stronger when target and distractor classifiers were incongruent than when the classifiers were congruent. Similarly, the result also shows that there was a larger negative wave within the classical N400 window when target and distractor stimuli were semantically unrelated than when they were from the same semantic category. No two-way or three-way interactions among any of the three factors were found in this time window after sphericity corrections were applied.
Tables 3a, b & c. Results for repeated ANOVA of mean amplitudes of epochs in time window 0-235 ms, 235-405 ms and 405-580 ms, with classifier congruency, semantic relatedness and ROIs and their interactions as predictors.
(3a) By-subject ANOVA in time window 0-235 ms
Source F
DFn DFd F
Classifier Congruency 1 9 0.67
ROI 3 27 2.66
Congruency X Relatedness 1 9 0.05
Congruency X ROI 3 27 0.47
Relatedness X ROI 3 27 0.03
Congruency X Relatedness X ROI 3 27 1.01
* p<.05
**p<0.01
***p<0.001
(3b) By-subject ANOVA in time window 235-405 ms
Source F
DFn DFd F
Classifier Congruency 1 9 0.50
Semantic Relatedness 1 9 1.29
ROI 3 27 6.80*
Congruency X Relatedness 1 9 1.93
Congruency X ROI 3 27 0.56
Relatedness X ROI 3 27 0.68
Congruency X Relatedness X ROI 3 27 0.65
* p<.05
***p<0.001
(3c) By-subject ANOVA in time window 405-580 ms
Source F
DFn DFd F
Classifier Congruency 1 9 5.34*
Semantic Relatedness 1 9 5.17*
ROI 3 27 3.48*
Congruency X Relatedness 1 9 1.55
Congruency X ROI 3 27 0.46
Relatedness X ROI 3 27 0.27
Congruency X Relatedness X ROI 3 27 0.80
* p<.05
**p<0.01
***p<0.001
C3 C4
CP1 CP2
FC1 FC2
Figure 3. Examples of grand averages of epochs from representative electrodes for the comparison between classifier-congruent (C+) and incongruent (C-) conditions.
C3 C4
F3 F4
CP1 CP2
Figure 4. Examples of grand averages of epochs from representative electrodes for the comparison between semantically related (S+) and unrelated (S-) conditions.
5. Discussion
In this study, the potential impact of classifier congruency and semantic relatedness on speech production in Mandarin was examined with the employment of the PWI paradigm. As participants saw both the target pictures and corresponding distractor words simultaneously on the screen, we recorded their naming latencies and real-time EEG activities. In the following paragraphs, we will base our discussion of the activation and selection question on the behavioral and ERP data in the order of semantic effect and classifier effect.
As is summarized in the Literature Review section of this paper, the impact of semantic category on the processing speed of nouns and phrases, namely the semantic interference effect, has already been studied and proved by a number of studies. Our behavioral results are in accordance with the established findings that distractor words from the same or a related semantic group would cause longer naming latencies through imposing a semantic interference effect (e.g. Glaser, 1992; La Heij, 1988). The semantic facilitation effect found by some studies involving priming from semantically less distant distractor word (e.g., Caramazza & Costa, 2001; Costa, Alario, & Caramazza, 2005; Finkbeiner & Caramazza, 2006) is not applicable here since our word pairs were selected from equal level of semantic categories. Similar results were also achieved in the previous study by Wang et al. (2018) in both by-item and by-subject analyses using the repeated ANOVA measures. These all point to the conclusion that semantic relatedness results in more competition during the lexical selection process, as more than one candidates are activated at the same time, resonating with the lexical selection by competition view shared by numerous studies that found semantic interference in their results (e.g., Belke et al., 2005; Bloem & La Heij, 2003; La Heij, 1988; Levelt, et al., 1999; Roelofs, 2003).
previous study which also observed a significantly more negative ERP wave as N400 effect in the semantically unrelated condition, as well as with other PWI-based ERPs studies focusing on semantic inhibitory effect in Mandarin and other languages (e.g., Dell’Acqua et al., 2010; Wicha, Moreno & Kutas, 2003; Zhu et al., 2015).
between the two studies too. Given all these differences between the two studies, we should be more careful when comparing and interpreting the results of these studies, bearing in mind the above-mentioned factors and variables that can potentially weaken our reasoning and conclusions.
Besides the significant effect of classifier congruency on naming latency discovered in the behavioral data, we also noticed in examination of fronto-central and centro-parietal regions an N400-like effect in time window 405-580 ms that was significantly larger in the classifier-incongruent than in the classifier-congruent condition. This result is consistent with the previous study which, albeit seeing no difference in naming latency between classifier-congruent and inclassifier-congruent conditions, still found an ERP wave that was significantly more negative in the latter condition. The observation of a stronger or weaker N400 effect by the manipulation of classifiers is a result also found in existing studies on classifier-noun inconsistency (e.g., Tsai et al., 2008; Zhou et al., 2010; Zhang et al., 2012; Hsu et al., 2014), as well as in research studying the determiner and gender disagreement effects in Indo-European languages (e.g., Barber & Carreiras, 2005).
of our time windows differed from that in the previous study, which we would not explore extensively due to the scope of this paper.
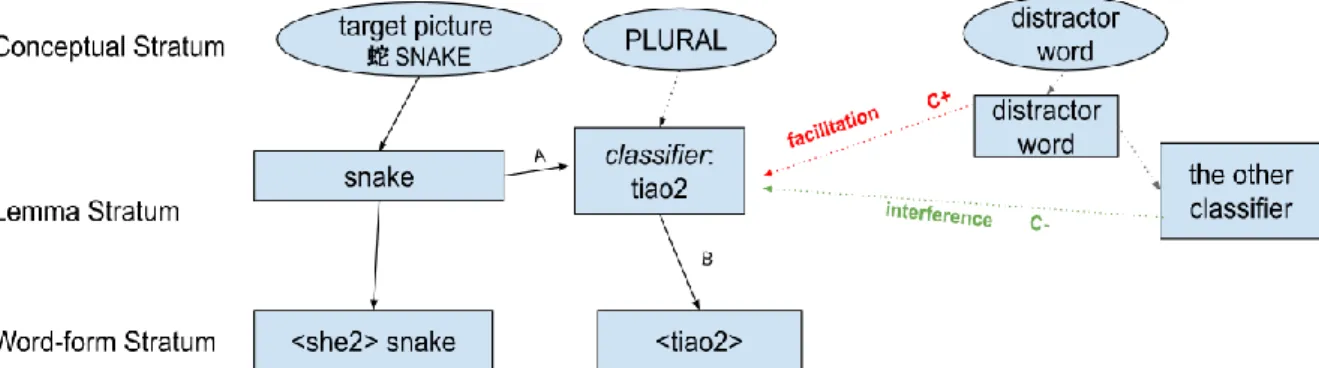
Figure 5. The competitive selection process of classifier in NP production in Mandarin, adapted from Levelt et al. (1999). A target picture activates its corresponding classifier. Depending on classifier congruency condition, the target classifier receives either facilitation from the distractor word or interference from the other candidate classifier activated by the presence of the distractor. The competitive selection of classifier takes place after lemma retrieval and completes before the start of word-form encoding. Unlike the dash line in the automatic activation model for bare noun naming in the previous study, Link B is active and functional in our model because the chosen classifier is relevant for production. The naming of quantifier is not included here since it is not involved in the competitive selection process.
6. Conclusion
To sum up, the current paper explored the activation/selection of Mandarin classifier in noun phrase production through an overt picture naming experiment using the picture-word interference paradigm. The behavioral analysis of naming latency shows that participants take significantly less time to respond in semantically unrelated and classifier-congruent conditions than in semantically related and classifier-incongruent conditions. Analysis of ERP data also showed that N400 is more negative in the semantically unrelated than in the related condition, and in the classifier-incongruent than in the congruent condition. Interaction of the two factors was found in neither behavioral nor ERP data analysis. Given these evidence, we propose that classifier as a lexico-syntactic feature goes through competitive selection instead of automatic activation in NP production. This finding complement the observations from the previous study by Wang et al. (2018), which reported automatic activation of classifier in bare noun naming based on finding no naming latency difference by classifier congruency status but indeed a stronger N400 effect in the incongruent condition. Together, the two studies suggest that Mandarin with its simple morphological structure is an early selection language like German and Dutch under the independent feature hypothesis (Alario & Caramazza, 2002), as the manipulation of lexico-syntactic features affects the production speed in only NP but not bare noun naming tasks. In terms of accounting for the specific process of classifier activation in both scenarios, Levelt et al.’s model (1999) outperforms other hypotheses by attributing lexical access to a post-lemma retrieval position in the serial procedure of speech production.
options. While it is impossible to keep track of individuals’ level of acceptance of stimuli, we should be aware that Chinese classifier-noun pairs do not have one single combination like grammatical gender and determiner for most nouns in Indo-European languages, which might have resulted in extra variability in performance. Secondly, our ERP data suffered from considerable data loss largely due to the inexperience of experimenter. More importantly, the current study does not include a section of permutation test with Monte Carlo approximation on the ERP data as the previous study has done, mainly because of the use of different statistical software in the two studies. The findings from the ERP data analysis would have been more robust and comparable with the ones from the previous study had the permutation test been run.
Nonetheless, findings of this study are meaningful in that they provide the missing piece in existing studies on classifier accessing with not only behavioral but also electrophysiological data analysis. In particular, they complement and extend the previous results achieved in bare noun naming tasks to cover a broader scope of Mandarin speech, which in turn examines the generalizability of earlier hypotheses made on determiner and grammatical gender effect and enables further cross-language comparison by including a Sino-Tibetan language in the established discussion of Indo-European languages. Future research may want to consider examining other languages with classifier as a lexico-syntactic feature to see whether the conclusions for Chinese hold within a wider scope.
References
Alario, F. X., & Caramazza, A. (2002). The production of determiners: Evidence from French. Cognition, 82(3), 179-223.
Barber, H., & Carreiras, M. (2005). Grammatical gender and number agreement in Spanish: An ERP comparison. Journal of cognitive neuroscience, 17(1), 137-153.
Bates, D., Maechler, M., & Bolker, B. (2012). lme4: Linear mixed-effects models using S4 classes. R package version 0.999999-0.
Belke, E., Meyer, A. S., & Damian, M. F. (2005). Refractory effects in picture naming as assessed in a semantic blocking paradigm. The Quarterly Journal of Experimental
Psychology, 58(4), 667-692.
Bi, Y., Yu, X., Geng, J., & Alario, F. X. (2010). The role of visual form in lexical access: Evidence from Chinese classifier production. Cognition, 116(1), 101-109.
Bloem, I., & La Heij, W. (2003). Semantic facilitation and semantic interference in word translation: Implications for models of lexical access in language production. Journal of
Memory and language, 48(3), 468-488.
Boutonnet, B., Athanasopoulos, P., & Thierry, G. (2012). Unconscious effects of grammatical gender during object categorisation. Brain Research, 1479, 72-79.
Caramazza, A., & Costa, A. (2001). Set size and repetition in the picture–word interference paradigm: Implications for models of naming. Cognition, 80(3), 291-298.
Chen, J.-Y., & Wang, T.-Y. (2003). The nature of the classifier–noun agreement in Chinese
word production. Paper presented at the 44th annual meeting of the psychonomic
society, Vancouver, Canada.
Chen, Q., Xu, X., Tan, D., Zhang, J., & Zhong, Y. (2013). Syntactic priming in Chinese sentence comprehension: evidence from Event-Related Potentials. Brain and cognition,
83(1), 142-152.
Costa, A., Alario, F. X., & Caramazza, A. (2005). On the categorical nature of the semantic interference effect in the picture-word interference paradigm. Psychonomic Bulletin & Review, 12(1), 125-131.
Costa, A., & Caramazza, A. (1999). Is lexical selection in bilingual speech production language-specific? Further evidence from Spanish–English and English–Spanish bilinguals. Bilingualism: Language and Cognition, 2(3), 231-244.
Costa, A., Sebastián-Gallés, N., Miozzo, M., & Caramazza, A. (1999). The gender congruity effect: Evidence from Spanish and Catalan. Language and Cognitive
Processes, 14(4), 381-391.
Croft, W. (1994). Semantic universals in classifier systems. Word, 45(2), 145-171.
Cubelli, R., Lotto, L., Paolieri, D., Girelli, M., & Job, R. (2005). Grammatical gender is selected in bare noun production: Evidence from the picture–word interference paradigm. Journal of Memory and Language, 53(1), 42-59.
Dell'Acqua, R., Sessa, P., Peressotti, F., Mulatti, C., Navarrete, E., & Grainger, J. (2010). ERP evidence for ultra-fast semantic processing in the picture–word interference paradigm. Frontiers in Psychology, 1, 177.
Dell, G. S. (1986). A spreading-activation theory of retrieval in sentence production.
Psychological Review, 93(3), 283.
Dell, G. S. (1988). The retrieval of phonological forms in production: Tests of predictions from a connectionist model. Journal of Memory and Language, 27(2), 124-142.
Dell, G. S. (1990). Effects of frequency and vocabulary type on phonological speech errors.
Language and Cognitive Processes, 5(4), 313-349.
Dell, G. S., & O'Seaghdha, P. G. (1991). Mediated and convergent lexical priming in language production: A comment on Levelt et al (1991). Psychological Review, 98(4),
604-614.
Dell, G. S., & O'Seaghdha, P. G. (1992). Stages of lexical access in language production.
Cognition, 42(1-3), 287-314.
Dhooge, E., De Baene, W., & Hartsuiker, R. J. (2016). The mechanisms of determiner selection and its relation to lexical selection: An ERP study. Journal of Memory and
Language, 88, 28-38.
Dhooge, E., & Hartsuiker, R. J. (2010). The distractor frequency effect in picture–word interference: Evidence for response exclusion. Journal of Experimental Psychology:
Learning, Memory, and Cognition, 36(4), 878.
Dhooge, E., & Hartsuiker, R. J. (2012). Lexical selection and verbal self-monitoring: Effects of lexicality, context, and time pressure in picture-word interference. Journal of Memory
and Language, 66(1), 163-176.
Duncan-Johnson, C. C., & Kopell, B. S. (1981). The Stroop effect: Brain potentials localize the source of interference. Science, 938-940.
Erbaugh, M. S. (1986). Taking stock: The development of Chinese noun classifiers historically and in young children. In Craig, C. (Ed.), Noun classes and categorization
(pp. 399-436). Eugene, Oregon: John Benjamins Publishing.
Erbaugh, M. S. (1990). Mandarin Oral Narratives Compared with English: The Pear/Guava Stories. Journal of the Chinese Language Teachers Association, 25(2), 21-42.
Eulitz, C., Hauk, O., & Cohen, R. (2000). Electroencephalographic activity over temporal brain areas during phonological encoding in picture naming. Clinical Neurophysiology,
111(11), 2088-2097.
Fang, F. (1985). An experiment on the use of classifiers by 4-to 6-year-olds. Acta
Psychologica Sinica.
Finkbeiner, M., & Caramazza, A. (2006). Lexical selection is not a competitive process: A reply to La Heij et al.(2006).Cortex: A Journal Devoted to the Study of the Nervous
System and Behavior, 42(7), 1032-1035.
Friederici, A. D., Hahne, A., & Mecklinger, A. (1996). Temporal structure of syntactic parsing: early and late event-related brain potential effects. Journal of Experimental