ENCRYPTION QUALITY ANALYSIS
IN MPEG VIDEO FORMAT
Priyanka Sharma Dinesh Goyal M.Tech (Purs.) Associate Professor SGVU, Jaipur SGVU, Jaipur Abstract-: In this work, an attempt is made to analyze
four fast MPEG video encryption algorithms. These algorithms use a secret key randomly changing the sign bits of DCT coefficients and/or the sign bits of motion vectors. The encryption effects are achieved by the IDCT during MPEG video decompression processing. These algorithms add very small overhead to MPEG codec. Software implementations are fast enough to meet the real time requirement of MPEG video applications and thus the analysis shows that satisfactory results can be obtained using these video encryption algorithms. The experiments conducted helped us analyze two points. First, to test the encryption results with overheads added to MPEG codec and second, encoding time with varying key lengths. We believe that these experiments will produce satisfactory results and thus help to know the efficiency and application of such algorithms in the real world. And will also give us a chance to analyze the drawbacks in the existing algorithms so that certain modification may be suggested for getting fast and better security. Keywords: MPEG video encryption, MPEG codec, VEA algorithms
1. INTRODUCTION
Multimedia data security is a very important requirement in both traditional and electronic commerce. As we see in real world that video on demand and video conferencing applications require that those who have paid for the services can only access the data. No doubt authentication controlled mechanisms are available to control the access of distributed multimedia data. However, multimedia data transmitted on wireless, satellite or IP networks cannot only be made secure by such authentication mechanisms. One of the most popular method to provide security to multimedia data is to treat the whole data as a binary file and encrypt the whole data using secret key encryption algorithms such as DES(Data Encryption Standard), AES, IDEA, etc. Secret key encryptions are very complicated and require heavy computations. Software implementations of these algorithms is not fast enough to process the vast amount of data generated by multimedia applications and hardware implementations add extra costs to both the data generators and receivers.
There are two major factors causing challenge to multimedia data encryption. First, typical multimedia data have large size (for example, the size of a two-hour MPEG-1 video is about 1GB). Second,
multimedia data needs to be processed in real time (for example, the data rates of MPEG-2 can go up to 40 Mbps or more).Processing huge amount of data in a very short time span puts heavy burden on video codec, storage space requirements and network communications. Applying heavy-weight encryption and decryption algorithms either during or after encoding phase aggravates the problem and increases the latency.
In this paper, four efficient MPEG video encryption algorithms are presented. All these algorithms although have varied attack protection strengths, add very small overhead to the MPEG codec. Software implementations of these algorithms are fast enough to meet the real time requirement of MPEG video applications. The DVD protection is becoming vital. Developing video encryption technique for hardware environment is also becoming important because hardware may be used for decoding MPEG bit stream on DVD. Usage of MPEG encryption techniques protects the DVD contents from two possible types of pirate devices: DVD video decoders and recordable storage devices. Our technique can possibly be used in encrypting the DVD video decoders.
The rest part of this paper is organized as follows. Part 2 is a brief introduction to MPEG-1 compression model. Part 3 discusses the related work. Part 4, 5, 6 and 7 describe the four video encryption algorithms. Part 8 shows experimental results. Finally, conclusion and future work are discussed in Part 9.
2. BACKGROUND MPEG-1
The MPEG (Moving Pictures Expert Group) had started in 1988 as Working Group 11, Subcommittee 29, of ISO/IEC JTC11 with the aim of defining the standards for digital compression of video and audio signals. The basis taken by it was the ITU-T2 standard for video-conferencing and video-telephony, together with that of the Joint Photographic Experts Group (JPEG) which had initially been developed for compressing still images such as electronic photography.
The primary goal of MPEG was to define a video coding algorithm for digital storage media, in particular CD-ROM. The resulting standard comprises of three main parts, covering the systems aspects (multiplexing and synchronization), video coding and audio coding. This standard has been
IJCTA | Nov-Dec 2013
Available [email protected]
applied in the CD-i system to provide full motion video playback from CD, and is widely used in PC applications for which a range of hardware and software coders and decoders are available.
It is important to note that MPEG-1 is restricted to non-interlaced video formats and is primarily intended to support video coding at bit-rates up to about 1.5 Mbit/s. Also, the MPEG standards specify only the syntax and semantics of the bit streams and the decoding process too. They do not specify the coding process at all: this is left primarily to the discretion of the coder designers, thus providing scope for improvement as the coding techniques are refined and new techniques are developed. A video bit-rate reduction (compression) system operates by removing the redundant and less important or unimportant information from the signal prior to transmission, and by reconstructing an approximation of the image from the remaining information at the decoder. In video signals, three distinct kinds of redundancy can be identified:
1) Spatial and temporal redundancy
Here, the fact that is made use of is that the pixel values are not independent but are correlated with their neighbours, both within the same frame and across frames. So, to some extent, the value of a pixel is predictable, given the values of the neighbouring pixels.
2) Entropy redundancy
For any non-random digitized signal, some code values occur more frequently than others. This can be exploited by coding the more frequently occurring values with shorter codes than the values occurring rarely.
3) Psycho-visual redundancy
This type of redundancy results from the way the brain and the eye work. In audio, we know that the ear has limited frequency response: in video, we need to consider two limits:
– the limit of spatial resolution (i.e. the fine detail which the eye can resolve);
– the limit of temporal resolution (i.e. the ability of the eye to track fast-moving images).
Temporal resolution means, for example, that a change of picture (a shot-change) masks the fine detail on either side of the change.
Picture types
The picture type defines which prediction modes may be used to code each macro-block:
1) Intra pictures (I-pictures)
These are coded without reference to other pictures. Moderate compression is achieved by reducing spatial redundancy but not temporal redundancy. They are important as they provide access points in the bit-stream where decoding can begin without reference to previous pictures.
2) Predictive pictures (P-pictures)
These are coded using motion-compensated prediction from a past I- or P-picture and may be used as a reference for further prediction. By reducing spatial and temporal redundancy, P-pictures offer increased compression compared to I-pictures. 3) Bi-directionally-predictive pictures (B-pictures) These use both past and future I- or P-pictures for motion compensation, and offer the highest degree of compression. As noted above, to enable backward prediction from a future frame, the coder re-orders the pictures from the natural display order to a “transmission” (or “bitstream”) order so that the B-picture is transmitted after the past and future pictures which it references. This introduces a delay which depends upon the number of consecutive B-pictures.
Group of pictures
The different picture types typically occur in a repeating sequence termed a Group of Pictures or GOP. A regular GOP structure can be described with two parameters:
– N (the number of pictures in the GOP); – M (the spacing of the P-pictures).
For a given decoded picture quality, coding – using each picture type – produces a different number of bits. In a typical sequence, a coded I-picture needs three times more bits than a coded P-picture, which itself occupied 50% more bits than a coded B picture. Method of encoding
In MPEG-1 video coding model, a video is composed of a sequence of group of pictures called (GOPs). Each GOP is a series of I, P and B pictures. I pictures are intra frame coded without any reference to other pictures. P pictures are predictively coded using a previous I or P picture. B pictures are bi-directionally interpolated from both, the previous and following I and/or P pictures. The relative frequency of occurrence of I, P and B pictures can be controlled by the applications. Each picture is divided into macro blocks. A macro block is a 16×16 pixel array. Macro blocks belonging to I-pictures are spatially encoded.
Macro blocks belonging to B and P pictures are temporally interpolated from the corresponding
Figure2 motion-compensated prediction
reference picture(s), and consequently the error between the actual and reference values is computed. The interpolation process also produces up to two motion vectors (a forward prediction vector and a backward prediction vector) for each macro block in the reference pictures, as shown in Figure 2
Regardless of the type of pictures it is belonging to, each of the macro blocks is further sub sampled into four 8 × 8 luminance blocks (Y blocks) and two 8 × 8 chrominance blocks (a Cr block and a Cb block) as shown in figure1. Each of the 8 × 8 Y, Cb and Cr blocks is fed to a pipeline of DCT (Discrete Cosine Transformation), quantization and Huffman entropy coding. DCT concentrates most of the energy in the lower spatial frequencies, i.e., the upper-left corner of the 8 × 8 block. After quantization, many DCT coefficients will become zeros.
The quantization output is then linearized according to the zigzag order to a vector < DC,AC1,AC2, · · · ,AC63 >. DC coefficient denotes the average brightness in the spatial block, and AC coefficients contain detail image information.
The DC coefficients of I blocks are differentially coded. The motion vectors of B blocks and P blocks are also differentially coded.
The run length encoding (RLE) turns vector < AC1, AC2, · · ·, AC63 > into a sequence of (skip, value) pairs. Then the Huffman entropy coding is used to change the (skip, value) pair sequence into a compressed bit stream. MPEG standard provides a Huffman codeword table, where more frequently occurring values are assigned fewer bits in order to achieve high compression rate. Every Huffman code word reserves a sign bit, 0 mean positive, 1 mean negative. These sign bits are the positions we encrypt the video in the RVEA algorithm.
3. RELATED WORKS WITH VIDEO ENCRYPTION
In many multimedia data scrambling systems, data are treated as bit streams and encrypted with DES. However, the real-time requirements of MPEG video playback are not easily met because software implementations of DES are too slow to meet such requirements. One way to solve this problem is to selectively encrypt only some portions of MPEG video.
One selection scheme proposed in the literature is to encrypt only MPEG video headers (including GOP headers, slice headers, macro-block headers). However, this strategy is not effective against attack due to the following reasons. First the header contains mostly standard information. It is easier for the attacker to guess the information. Second, in many MPEG applications, a video stream is indexed by frame in order to perform synchronization. Hence, the beginning of each frame is known. Third, when block encrypted video headers are sent over a noisy
Figure3 motion-compensated interpolation
IJCTA | Nov-Dec 2013
Available [email protected]
channel, bit errors which occurred in an encrypted block will propagate to the whole block when decrypting the video. Consequently, it can make a decoder lose synchronization during a video playback.
Another scheme to selectively encrypt the video is to encrypt I frames only. One might think that P and B frames are of no use without knowing the corresponding reference I frames. But a large portion of the video could be visible without I frames because some of the P and B frames may contain intra-coded I blocks. Therefore, encrypting only I frames does not provide a satisfactory security level. Other selective MPEG video encryption strategies include (1) encrypting all headers plus DCs and lower AC terms; (2) encrypting one half of a frame with DES/IDEA, and the other half of the frame with “one-time-pad” generated from that frame.
In those systems, MPEG compression operations are performed before the encryption operations are processed; MPEG decompression operations are processed after the decryption operations are processed. Those systems add overhead to video decoding and latency to real-time video delivering. Tang introduced some methods to incorporate together MPEG compression and encryption in one single step. Tang’s methods make use of a random permutation list to replace the zigzag order to map the DCT coefficients to a 1 x 64 vector. Since mapping according to a random permutation list (the secret key) and mapping according to the zigzag order have the same computational complexity, the encryption and decryption add very little overhead to the video compression and decompression processes. However, the problem with this method was that Tang’s methods decrease the video compression rate. The obvious reason is that the random permutations distort the probability distribution of DCT coefficients and render the Huffman table used less than optimal.
A new video encryption algorithm called VEA was suggested by Qiao and Nahrstedt. Video encryption algorithm works upon the statistical properties of MPEG video standard and symmetric key algorithm standard to reduce the amount of data that is encrypted. A VEA is actually dividing the input video stream into chunks (a1, a2, a3, a4, …, a2n-1 ,a2n ). The chunk is divided into two data segments odd list (a1, a3, a5, …. , a2n-1 ) and Even list (a2, a4,a6, … , a2n ) , afterward the encryption key would be applied to the list even list E(a2, a4,a6, … , a2n ), where E denotes an encryption function. Then the final cipher text is a concatenation of output of encryption algorithm XOR with the odd list streams. Thus VEA algorithm is immune from
known-plaintext attack, because the key will be changed for each frame(s).
4. ALGORITHM-I
Bharagava, Shi, and Wang have introduced four different video encryption algorithms named Algorithm I, Algorithm II (VEA), Algorithm III (MVEA), and Algorithm IV (RVEA).
Algorithm I uses the permutation of Huffman codewords in I-frames. This method incorporates encryption and compression in one step. The secret part of the algorithm is a permutation p which is used to permute standard MPEG Huffman codeword list. In order to save compression ratio, the permutation p must be such that it only permutes the codewords with same number of bits. Daniel Socek, showed that the Algorithm I is highly vulnerable to both known plaintext attack, and ciphertext-only attack. If some of video frames known in advance the adversary could easily figure out and reconstruct the secret permutation p by comparing the known frames with the encrypted frames. However, algorithm I is also subject to cipher text-only attack, but there is low frequency error attack on algorithm I cipher text. Basically, since permutation p is of the special form; i.e., it only shuffles code words with the same length, the most security comes from shuffling 16bit code words in the AC coefficient entropy table. However, since there are very limited numbers of code words with length of less than 16bits, it is very easy to reconstruct all of the DC coefficients and most frequent AC coefficients (since these will be encoded with less than 16bit code words). In other words, the only hard part would be to figure out how the permutation p shuffles the 16bit code words. But these are appearing extremely rare, and the reconstructed video may be of almost the same quality as the original.
5. ALGORITHM II (VEA)
Since the I-blocks carry the most important information so the scheme sufficient to encrypt only the sign bits of the DC coefficients in the I-frame blocks by simply XORs sign bits of DC coefficients with a secret m-bit binary key, k=k1k2...km in this algorithm. The effect of this scheme is that the encryption function randomly changes the sign bits of the DCT coefficients in an MPEG stream that belong to the same GOP(Grop Of Pictures) by s1s2....sn. Then, a bit si will not be changed if the value of the key bit ki(mod m) is 0, and it will be flipped if the value of the key bit ki(mod m) is 1. The next GOP
would simply reuse the secret key, which serves for the resynchronization purposes. The ability to resynchronize the video stream is required in the case of transmission errors, unreliable network, and VCR-like functionality such as rewinding or fast forwarding. The security level of this scheme depends on the length of the key. The authors encourage the use of a long binary key. However, too long key size may be infeasible and impractical. On the other hand with a short key size, the system could be easily broken. If the key is as long as the video stream and it is unique and used only once that would correspond to Vernam cipher( also referred to the one-time pad), which is known to be absolutely secure. However, this is not possible practically for mass applications such as VOD (Video on Demand) and similar. On the other hand, if the key is too short, the whole method simply becomes the Vigenere-like cipher, a well-studied classical cipher for which there are many attacks developed. In addition, Vigenere is highly sustainable to the known plain-text attack(one can literally read off the secret key). Authors suggest the use of the pseudo-random generator that generates a stream of pseudo-random bits to be the key k of arbitrary length. The trouble with this approach is the security, randomness, and speed of this P-RNG(Pseudo-Random Number Generator). The additional issues includ the synchronization of the P-RNG and the secure transmission of the seed(the secret key) for the P-RNG.
6. ALGORITHM III (MVEA)
Bharagava and Shi have made an improvement to the Algorithm II (VEA). Instead of encrypting only the sign bits of DC coefficient in the I-frame block, the sign bits of the differential values of DC coefficient and motion vectors in P-frames and B-frames can be encrypted by XORs them with the secret key. This type of improvement makes the video playback more random and more non-viewable. When the sign bits of differential values of motion vectors are changed, the directions of motion vectors change as well. In addition, the magnitudes of motion vectors change, making the whole video very chaotic. The authors found that the encrypting of sign bits of motion vectors makes the encryption of sign bits of DCT coefficients in B- and P- frames unnecessary.
Further, the original Algorithm III (MVEA) was designed to encrypt only the sign bits of DC coefficients in the I-frames of MPEG video sequence, while leaving the AC coefficients unencrypted. This significantly reduces the computational overhead, but it opens up new security risks. Namely, because the DC coefficient and the sum of all AC coefficients
within the block are related, an adversary may use the unencrypted AC coefficients to derive the unknown (encrypted) DC coefficients. For this treason, the authors recommend encrypting all DCT coefficients in the I-frames for applications that need higher level of security. However this type of improvement makes the video playback more random and more unviewable. Just like the Algorithm II (VEA), the Algorithm III (MVEA) is relies on the secret key size.
The Algorithm II (MVEA) is an improvement to the Algorithm II (VEA) described above.
Just like the Algorithm II (VEA), the Algorithm III (MVEA) relies on the sec ret m-bit key k. Also, the resynchronization is done at the beginning of a GOP. Unfortunately, the fundamental security issues and problems that are applicable to VEA are also applicable to MVEA.
7. ALGORITHM IV (RVEA)
Algorithm IV (RVEA) was proposed by Bhargava, and el. The difference between Algorithm IV (RVEA) and Algorithm III (MVEA) is that Algorithm IV (RVEA) uses a traditional symmetric key cryptography to encrypt the sign bits of DCT coefficient and the sign bits of motion vectors. The algorithm speeds up the process of encryption by only encrypting certain sign bits in MPEG stream. Therefore, it is much better than the previous three algorithms Algorithm I, Algorithm II (VEA), and Algorithm III (MVEA) in terms of security. In the Algorithm IV (RVEA), the sign bits of DCT coefficients and motion vectors are simply extracted from the MPEG video sequence, encrypted using a fast conventional cryptosystem such as AES, and then restored back to their original position in the encrypted form. The effect of this is similar to VEA/MVEA where the sign bits are either flipped or left unchanged. The authors limited the number of bits for encryption to at most 64 for each MPEG stream macro block, for the purposes of reducing and bounding the computation time. Next, we describe exactly how these sign bits are selected for encryption.
Each MPEG video slice consists of one or more macro blocks. the macro block corresponds
to a 16x16 pixel square, which is composed of four 8x8 pixel luminance blocks denoted by Y1,Y2,Y3,Y4, and two 8x8 chrominance blocks Cb and Cr. Each of these six 8x8 blocks can be expressed as a sequence ba1a2...an, where n is at most 64 since b is the code for DC coefficient and ai is the code for a non-zero AC coefficient. Then, for
IJCTA | Nov-Dec 2013
Available [email protected]
each such 8x8 block, we can define the sequence βα1α2...αn, that corresponds to the sign bits of the matching DCT coefficients b, a1,a2,..,andan. Figure4 shows the order of selection of the sign bits for each macroblock.
The obvious reason for this selection order is that the DC and higher order AC coefficients are carrying much more information that the low-order AC coefficients.
RVEA achieve the goal of reducing and bounding its computation time by limiting the maximum number of bits selected. RVEA’s decryption operations are the same as its encryption operations.
Fig4 Bits Selection Order
Changing the sign bits of DC coefficients of I frames can lead to a very dramatic change in the decoded frame. Since DC coefficients of I frames are differentially encoded, changing the sign bit of a differential value will affect all of its following DC coefficients during MPEG decoding. As an example, Figure 5(a) is a plot of the sequence of DC values of a I frame. Figure 5(b) shows the differential values of those DC values. RVEA encryption randomly changes the signs of these encoded values, as shown in Figure 5(c). Without a correct secret key, a decoder will get wrong DC values, as shown in Figure 5(d).
Figure 5. Encryption of differential values of DCs of I frames. (a) Signal values; (b)
Differential values; (c) Encrypted differential values; (d) Result of decoding without
decryption.
The differential encoding of DC coefficients and motion vectors in MPEG compression increases the difficulty of breaking RVEA encrypted videos. If the initial guess of a DC coefficient is wrong, it is very difficult to guess the following DC values correctly. Theoretically, the difficulty of breaking an RVEA encrypted MPEG video is the same as the difficulty of breaking the underlining secret key cryptography algorithms. Even if plaintext and ciphertext are known, currently there is no practical method to determine the secret key in DES or IDEA. Please note that the cost of plaintext attack to RVEA is increased by the MPEG decoding process, which includes expensive IDCT computations.
Ciphertext attacks on RVEA encrypted MPEG videos are not practical either. Ciphertext attacks on RVEA can be done by trying all possible combinations of the sign bits of a frame and check if any one of the combination of the sign bits can produce a comprehensible video frame. The decorrelative property of AC coefficients of DCT makes a correlation attack not very easy. Even with a
powerful computer, an automatic ciphertext attack (revealing secret key or generating quality pictures without human involvement) is hard, because the computer does not know if a guessed picture is comprehensible to human beings. A ciphertext attack with human involvement by playing picture puzzles of flipping the sign bits may get some blurred pictures or figure out some objects in certain frames. It will take many hours for an attacker to get a blurred picture. Anyone who found the picture interesting would rather buy the video than attack the ciphered video because the cost of buying the program is actually cheaper. RVEA only selectively encrypts a fraction of the whole video. It is faster than encrypting the whole video with DES/IDEA. We found that in typical MPEG videos sign bits occupy less than 10% of a whole video bit stream. Therefore RVEA can save 90% of encryption time comparing to algorithms which encrypt the whole video. RVEA encrypts at most 64 bits (8 bytes) for each macroblock.
Thus, it considerably reduces encryption computations. For example, for 320 × 240 video frames, there are 20 × 15 macroblocks in each frame.
Figure 6. Example of video frame sizes.
To process 30 frames per second, RVEA needs to encrypt data at 20 × 15 × 30 × 8 bytes per second, which is about 72 Kb/sec. Using IDEA, even a 66Mhz 486 PC can encrypt data at 300kb/sec (Schneier, 1996).
We do realize that applying RVEA encryption to the unit of video slice implies that the decryption can start only after the full slice is available; and the decryption followed by sign correction may impose certain amount of delay. But because the time spent in encryption computations is much longer than the communication delay, so RVEA is still much faster than the approaches which encrypt the whole video frames.
To guarantee QoS (Quality of Service) in real-time
video applications, it is desirable that the encryption/decryption time be bounded by a constant. Encryption and decryption should not take too much time, otherwise the video session will suffer from jitters. This is especially true for MPEG video applications because MPEG video frame sizes vary in time, as shown in Figure 6.
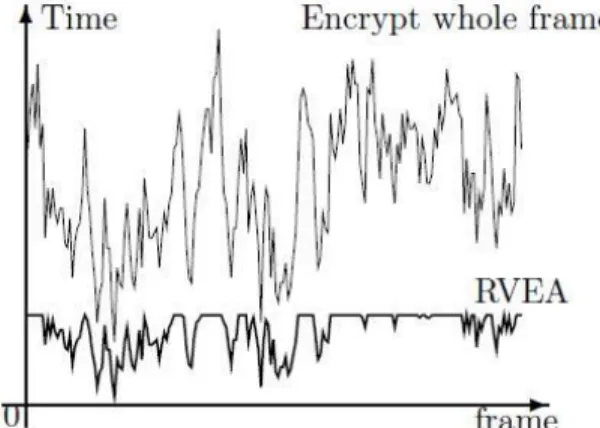
The encryption time spent by the algorithms which encrypt whole frames may vary with frame sizes. Larger frame size requires longer encryption time, which means longer delay. It may either degrade the video playback or add extra burden to the video frame synchronization. Burstiness of data does not affect RVEA’s encryption speed. RVEA encrypts at most 64 bits (8 bytes) of data for each macroblock, no matter how large the frame size is and what type (I, P, or B) the frame is (see Figure 7). This is a very desirable property to video decoding.
Figure 7. RVEA encryption time for each frame is bounded.
In conclusion, RVEA only encrypts the fraction (typically about 10%) of the whole MPEG video by using the conventional secure cryptographic schemes such as DES, IDEA, AES, etc. Therefore, the Algorithm IV (RVEA) is a much better method than the previous three algorithms in terms of security. Furthermore, it saves up to 90% of the computation time comparing to the naive approach.
8. EXPERIMENTS
Experiment 1: Analysis to calculate the encoding time with changing key length.
IJCTA | Nov-Dec 2013
Available [email protected]
Figure8:Regular MPEG video (AKIYO Frame#101)
Figure 9:Encrypted sign bits of motion vectors
Figure 10:Algorithm II (VEA) – Encrypted sign bits of DCT coefficients with fixed 64-bit key
Figure 11: Algorithm III (MVEA) - Encrypted sign bits of DCT coefficients and Motion Vectors with fixed 64-bit key
Figure 12:Algorithm II (VEA) - Encrypted sign bits of DCT coefficients with fixed 127-bit key
Figure 13:Algorithm III (MVEA) - Encrypted sign bits of DCT coefficients and Motion Vectors with fixed 127-bit key
Figure 14:Algorithm IV (RVEA) - Encrypted sign bits of DCT coefficients and Motion Vectors with fixed 256-bit AES
Table I Encoding time with varied key length Result: The encoding time increases with increase in key length as shown in Table I. Hence, selection of key must be made carefully in order to ensure secure transmission of video.
Experiment-2: Analysis of VEA algorithms proposed by Shi, Wang and Bhargava on MPEG video format
There are two purposes in this experiment: 1. to test the encryption results;
2. to find the overheads added to MPEG codec. We selected key lengths of 128-bits. To test RVEA encryption results, we used IDEA in the RVEA implementation because IDEA is faster than DES. IDEA uses a key of 128 bits to encrypt a plaintext block of 64 bits. IDEA is generally considered to be very secure. No practical attack on it has been published.
Results
- The input data is the "table tennis" MPEG-1 video clips. One frame of the original clip is shown in Figure 15.
- Encrypting all AC coefficients of DCT with VEA. One frame of the results is shown in Figure 16.The video image is blurred, but still comprehensible. - Encrypting all AC coefficients and DC coefficients of Cr and Cb blocks with VEA. One frame of the results is shown in Figure 17. The image is obscured, but still comprehensible.
- Encrypting all DC and AC coefficients, including DCs of Y blocks with VEA. One frame of the results is shown in Figure 18. The image is incomprehensible.
-Figure 19 shows the effect of encrypting only motion vectors of a B frame with MVEA.
-Figure 20 shows one of the RVEA encrypted frames. All pictures in our RVEA tests are incomprehensible. From the experiment, it was found that motion vectors are more significant than other DCT coefficients, and DC coefficients are more significant than the AC coefficients in an encryption. When we encrypt all DC coefficients of Y blocks, we always got satisfactory encryption results.
The time spent on compression only and compression with encryption is shown in Table II (where fps=frames per second)
From Table II it was seen that relative time spent on the encryption is very small, only 1.81% of computation time. Hence, our software implementation of VEA is fast enough to secure MPEG video applications.
Table-II Overheads test results
IJCTA | Nov-Dec 2013
Available [email protected]
Fig 15: Original image frame
Fig16: Encrypted AC coefficient with VEA
Fig17: Encrypted ACs, DCs of Cr and Cb blocks with VEA
Fig18: Encrypted all ACs and DCs with VEA
Fig19: Encrypted motion vectors only with MVEA
Fig20: An RVEA encrypted frame.
9. CONCLUSION
We have analysed four MPEG video encryption algorithms. These algorithms can achieve satisfactory results with less computation. Also software implementations are fast enough to meet the real-time requirement of MPEG decoding. It is believed that these algorithms can be used to secure video-on-demand applications and pay-per-view programs. It is possible to extend the ideas of these four algorithms to non-MPEG compression scheme such as H.263 for video-conferencing applications.
It is important to carefully select what level of security needs to be in place and then choose an algorithm. The choice of algorithm will affect the codec speed. Experiment presented some comparative analysis of few selected encryption algorithms highlighting the four video encryption algorithms proposed by Shi, Wang and Bhargava that can serve as good criteria for choosing the right video encryption algorithm.
REFERENCES
L. Qiao and K. Nahrstedt, \A new algorithm for MPEG video encryption," in Proceedings of The First International Conference on Imaging Science, Systems, and Technology (CISST'97), (Las Vegas, Nevada), pp. 21{29, July 1997.
C. Shi and B. Bhargava, “A Fast MPEG Video Encryption Algorithm,” Proceedings of the 6th International Multimedia Conference, Bristol, UK, September 12-16, 1998.
C. Shi, S.-Y. Wang and B. Bhargava, “MPEG Video Encryption in Real-Time Using Secret key Cryptography,” 1999 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA'99), Las Vegas, NV, June 28 - July 1, 1999.
T. Seidel, D. Socek, and M. Sramka, “Cryptanalysis of Video Encryption Algorithms ,” to appear in Proceedings of The 3rd Central European Conference on Cryptology TATRACRYPT 2003, Bratislava, Slovak Republic, 2003.
T. Seidel, D. Socek, and M. Sramka, “Cryptanalysis of Video Encryption Algorithms ,” to appear in Proceedings of The 3rd Central European Conference on Cryptology TATRACRYPT 2003, Bratislava, Slovak Republic, 2003.
B. Bhargava and C. Shi, "An Efficient MPEG Video Encryption Algorithm", IEEE Proceedings of the 17th Symposium on Reliable Distributed Systems, 1998, Pages 381 – 386.
IJCTA | Nov-Dec 2013
Available [email protected]