PRESIDENTIAL ADDRESS, 1999
The perception of speech sounds by the human
brain as reflected by the mismatch negativity
~
MMN
!
and its magnetic equivalent
~
MMNm!
RISTO NÄÄTÄNEN
Cognitive Brain Research Unit~CBRU!, Department of Psychology, University of Helsinki, Finland BioMag Laboratory, Helsinki University Central Hospital, Helsinki, Finland
Abstract
The present article outlines the contribution of the mismatch negativity~MMN!, and its magnetic equivalent MMNm, to our understanding of the perception of speech sounds in the human brain. MMN data indicate that each sound, both speech and nonspeech, develops its neural representation corresponding to the percept of this sound in the neurophys-iological substrate of auditory sensory memory. The accuracy of this representation, determining the accuracy of the discrimination between different sounds, can be probed with MMN separately for any auditory feature~e.g., frequency or duration!or stimulus type such as phonemes. Furthermore, MMN data show that the perception of phonemes, and probably also of larger linguistic units~syllables and words!, is based on language-specific phonetic traces developed in the posterior part of the left-hemisphere auditory cortex. These traces serve as recognition models for the corre-sponding speech sounds in listening to speech. MMN studies further suggest that these language-specific traces for the mother tongue develop during the first few months of life. Moreover, MMN can also index the development of such traces for a foreign language learned later in life. MMN data have also revealed the existence of such neuronal populations in the human brain that can encode acoustic invariances specific to each speech sound, which could explain correct speech perception irrespective of the acoustic variation between the different speakers and word context. Descriptors: Mismatch negativity~MMN!, Magnetic MMN~MMNm!, Event-related potentials~ERP!, Speech sounds, Speech perception, Phonemes, Categorical processing, Central auditory processing, Central sound representation
MMN as an Index of the Central Sound Representation (CSR)
The mismatch negativity~MMN! ~Figure 1! is a frontocentrally negative component of the auditory event-related potential~ERP!, usually peaking at 100–250 ms from stimulus onset, that is elicited by any discriminable change in some repetitive aspect of the on-going auditory stimulation irrespective of the direction of the sub-ject’s attention or task~Näätänen, Gaillard, & Mäntysalo, 1978; for reviews, see Kraus & Cheour, 2000; Kraus, McGee, Carrell, & Sharma, 1995a; Näätänen, 1990, 1995; Näätänen & Alho, 1995, 1997; Picton, Alain, Otten, Ritter, & Achim, 2000!. The fact that MMN~and its magnetic equivalent MMNm!can be elicited even in the absence of attention makes it a unique measure of auditory discrimination accuracy, with no comparable measure being pro-vided by any of the more recent, and “more modern,”
brain-imaging technologies, such as positron emission tomography~PET! or functional magnetic resonance imaging~f MRI!. Although some studies ~Näätänen, Paavilainen, Tiitinen, Jiang, & Alho, 1993a; Woldorff, Hackley, & Hillyard, 1991; Woldorff, Hillyard, Gallen, Hampson, & Bloom, 1993!showed that the MMN amplitude can be modulated by strongly focused attention in dichotic selective-listening conditions, no data suggest that the withdrawal of atten-tion can totally eliminate the MMN that would otherwise be elicited ~for a review, see Näätänen, 1991!. As an account of this data pattern, Ritter, Deacon, Gomes, Javitt, and Vaughan ~1995! pro-posed that the MMN generator per se is fully automatic, with the MMN-amplitude attenuation associated with the withdrawal of attention being caused by the reduced afferent input to the MMN generator mechanism.
Perhaps the most convincing evidence for the automaticity of the MMN generator is provided by MMN recorded in coma pa-tients~then strongly predicting the return of consciousness within a week; Kane, Butler, & Simpson, 2000; Kane, Curry, Butler, & Gummins, 1993; Kane et al., 1996; see also Fischer et al., 1999, Fischer, Morlet, & Giard, 2000; Morlet, Bouchet, & Fischer, 2000!, in sleeping subjects at the stage-2 and REM sleep~Campbell, Bell, & Bastien, 1991; Sallinen, Kaartinen, & Lyytinen, 1994, 1996!, I thank Kimmo Alho, Judy Ford, Teija Kujala, Walter Ritter, Mari
Tervaniemi, and Istvan Winkler for their very helpful comments on the previous version of this manuscript.
Address reprint requests to: Risto Näätänen, P.O. Box 13 ~Meri-tullinkatu 1!, 00014 University of Helsinki, Finland. E-mail: risto. [email protected].
Copyright © 2001 Society for Psychophysiological Research
and in anesthetized cats~Csépe, Karmos, & Molnár, 1989!, guinea pigs~Kraus et al., 1994a; Kraus, McGee, Littman, Nicol, & King, 1994b!, and rats~Ruusuvirta, Penttonen, & Korhonen, 1998!. In these conditions, the MMN amplitude is lower than normal, how-ever, which is consistent with data~Lang et al., 1995; May, Ti-itinen, Sinkkonen, & Näätänen, 1994!suggesting reduction of MMN amplitude with decreased vigilance and increased drowsiness.
As already mentioned, any discriminable auditory change elicits an MMN. MMN is thus elicited, for example, by a change in a sim-ple sound such as a sinusoidal tone~Näätänen et al., 1978; Sams, Paavilainen, Alho, & Näätänen, 1985; see Figure 1!or in a complex sound such as a phoneme~Aaltonen, Niemi, Nyrke, & Tuhkanen, 1987!or a complex spectrotemporal pattern~Näätänen et al., 1993b; Schröger et al., 1994!. Importantly, the repetitive~“standard”! stim-ulus element does not have to be acoustically constant for MMN to be elicited, as long as some pattern or rule is shared by the stan-dards. MMN is then elicited by stimuli violating this pattern or rule ~Paavilainen, Jaramillo, Näätänen, & Winkler, 1999; Paavilainen, Saarinen, Tervaniemi, & Näätänen, 1995; Paavilainen, Simola, Jaramillo, Näätänen, & Winkler, in press; Saarinen, Paavilainen, Schröger, Tervaniemi, & Näätänen, 1992; Tervaniemi, Rytkönen, Schröger, Ilmoniemi, & Näätänen, in preparation!. Furthermore, MMN elicitation tolerates some range of standard-stimulus varia-tion~Gomes, Ritter, & Vaughan, 1995; Huotilainen et al., 1993; Win-kler et al., 1990!.
MMN elicitation is based on the presence of short-term mem-ory~sensory-memory!trace, formed in the auditory cortex, repre-senting the repetitive aspect or element of stimulation that usually has to be repeated at least once ~with a short enough interval! before a deviant event can elicit the MMN~Cowan, Winkler, Teder, & Näätänen, 1993; Näätänen, 1984; Winkler, Cowan, Csépe, Czi-gler, & Näätänen, 1996!. The trace underlying MMN elicitation usually fades within 5–10 s~Näätänen, Paavilainen, Alho,
Reini-kainen, & Sams, 1987; Sams, Hari, Rif, & Knuutila, 1993!; there-after no MMN can be elicited irrespective of how wide the stimulus deviation is.~For long-term auditory traces probed with MMN, see below.!The results of several studies~e.g., Winkler & Näätänen, 1992; Winkler, Reinikainen, & Näätänen, 1993!using MMN in the backward-masking paradigm also suggested that MMN reflects echoic memory~the traces underlying this memory being probed by presenting deviant stimuli!.
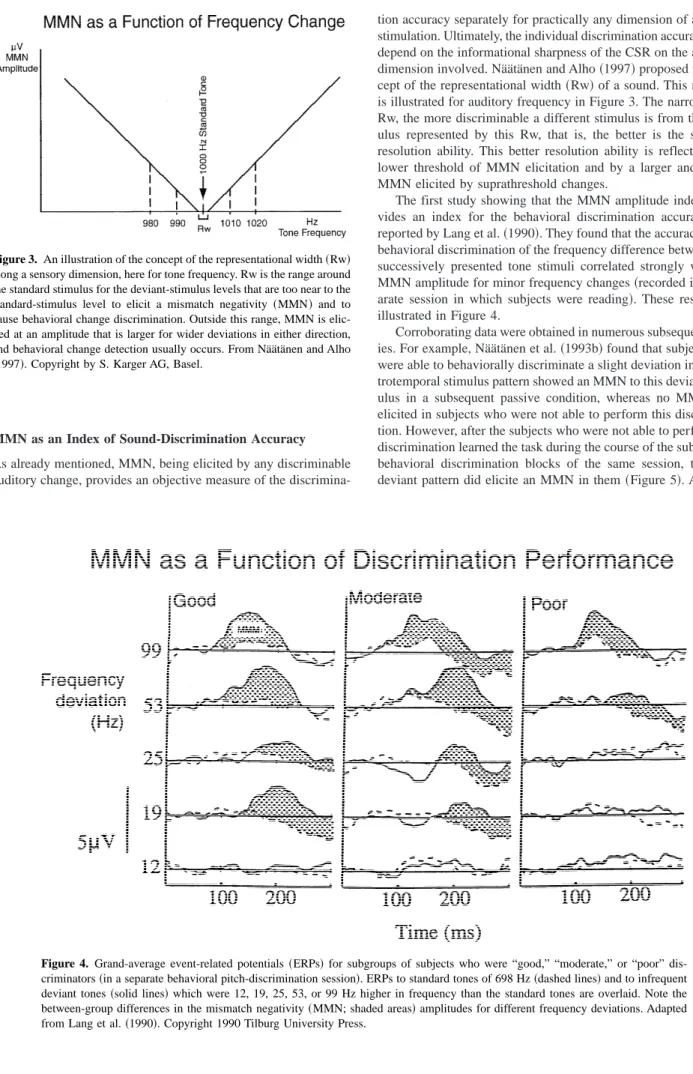
Reviewing a large number of converging MMN studies, Näätänen and Winkler~1999!, however, extended this notion to involve the central sound representation~CSR!of the brain, thus linking the sound perception and sensory memory tightly together ~see also Kraus & Cheour, 2000; Kraus et al., 1995a; Näätänen, 1995!. They suggested that sound perception occurs at the phase of the fast emergence of CSR, at its rising slope until completion, which is then followed by a latent, slowly decaying phase underlying sen-sory ~echoic! memory~Figure 2!. MMN ~Winkler & Näätänen, 1992; Winkler et al., 1993; Yabe, Tervaniemi, Reinikainen, & Näätänen, 1997; Yabe et al., 1998!and behavioral~Foyle & Wat-son, 1984; Hawkins & PresWat-son, 1986; Massaro, Cohen, & IdWat-son, 1976; Scharf & Houtsma, 1986; Winkler et al., 1993!data suggest that CSR, encoded as a memory trace~or as a set of interlinked memory traces!, is “ready” by 200 ms from stimulus onset. The 200 ms is needed for the afferent processes and for the subsequent temporal and feature integration of their outcomes. The duration of the temporal window of integration can be estimated, on the basis of MMN data, to be 150–200 ms ~Winkler & Näätänen, 1992; Winkler et al., 1993; Yabe et al., 1997, 1998!.
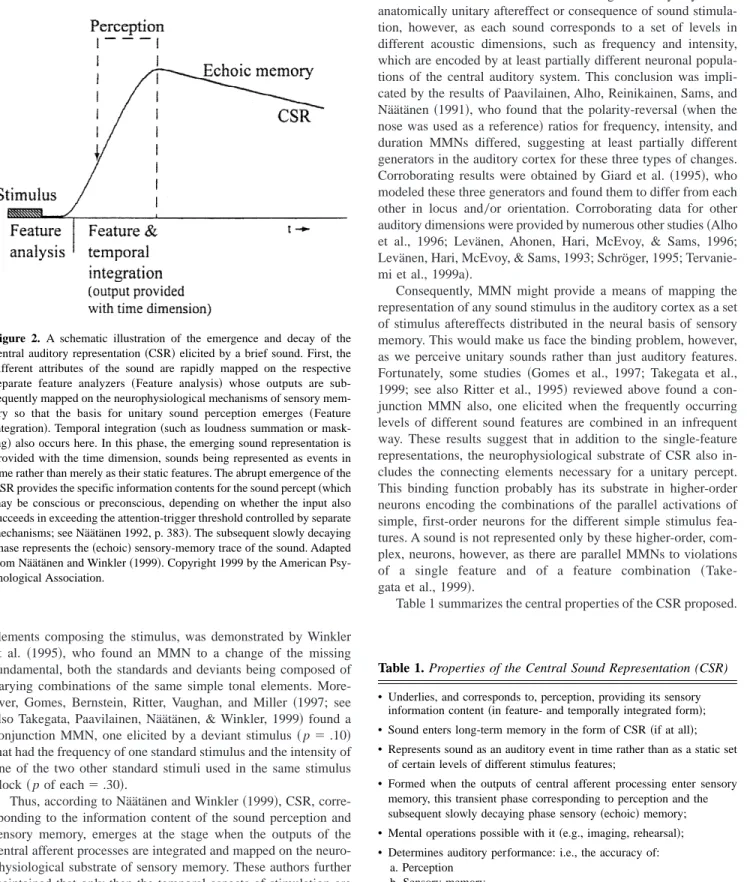
According to Näätänen and Winkler~1999!, these integration processes are essential in the formation of a unitary sound percept. That the sensory information carried by sensory-memory traces underlying MMN generation indeed corresponds to sound percep-tion ~and thus provides CSR!, rather than just to the acoustic Figure 1. Left: Frontal~Fz!event-related poten-tials~ERPs; averaged across subjects!to 1000-Hz standard~thin line! and to deviant~thick line! stimuli of different frequencies, as indicated on the left side. Right: The difference waves ob-tained by subtracting the standard-stimulus ERP from that to the deviant stimulus separately for the different deviant stimuli. MMN5mismatch negativity. Adapted from Sams et al. ~1985!. Copyright 1985 Elsevier Science Publishers BV ~Biomedical Division!.
elements composing the stimulus, was demonstrated by Winkler et al. ~1995!, who found an MMN to a change of the missing fundamental, both the standards and deviants being composed of varying combinations of the same simple tonal elements. More-over, Gomes, Bernstein, Ritter, Vaughan, and Miller ~1997; see also Takegata, Paavilainen, Näätänen, & Winkler, 1999! found a conjunction MMN, one elicited by a deviant stimulus~p5.10! that had the frequency of one standard stimulus and the intensity of one of the two other standard stimuli used in the same stimulus block~p of each5.30!.
Thus, according to Näätänen and Winkler~1999!, CSR, corre-sponding to the information content of the sound perception and sensory memory, emerges at the stage when the outputs of the central afferent processes are integrated and mapped on the neuro-physiological substrate of sensory memory. These authors further maintained that only then the temporal aspects of stimulation are fully represented; that is, from this point on in the sound-processing stream, sound is represented as an auditory event in time rather than as a set of fragmentary stimulus features without temporal
coordinates. Furthermore, this temporal organization of the stim-ulus representation is maintained, as time passes; for example, it is possible to estimate the duration, and to reconstruct the order, of unattended sounds that occurred a moment ago.
CSR should not be understood as being carried by any neuro-anatomically unitary aftereffect or consequence of sound stimula-tion, however, as each sound corresponds to a set of levels in different acoustic dimensions, such as frequency and intensity, which are encoded by at least partially different neuronal popula-tions of the central auditory system. This conclusion was impli-cated by the results of Paavilainen, Alho, Reinikainen, Sams, and Näätänen~1991!, who found that the polarity-reversal~when the nose was used as a reference!ratios for frequency, intensity, and duration MMNs differed, suggesting at least partially different generators in the auditory cortex for these three types of changes. Corroborating results were obtained by Giard et al.~1995!, who modeled these three generators and found them to differ from each other in locus and0or orientation. Corroborating data for other auditory dimensions were provided by numerous other studies~Alho et al., 1996; Levänen, Ahonen, Hari, McEvoy, & Sams, 1996; Levänen, Hari, McEvoy, & Sams, 1993; Schröger, 1995; Tervanie-mi et al., 1999a!.
Consequently, MMN might provide a means of mapping the representation of any sound stimulus in the auditory cortex as a set of stimulus aftereffects distributed in the neural basis of sensory memory. This would make us face the binding problem, however, as we perceive unitary sounds rather than just auditory features. Fortunately, some studies ~Gomes et al., 1997; Takegata et al., 1999; see also Ritter et al., 1995! reviewed above found a con-junction MMN also, one elicited when the frequently occurring levels of different sound features are combined in an infrequent way. These results suggest that in addition to the single-feature representations, the neurophysiological substrate of CSR also in-cludes the connecting elements necessary for a unitary percept. This binding function probably has its substrate in higher-order neurons encoding the combinations of the parallel activations of simple, first-order neurons for the different simple stimulus fea-tures. A sound is not represented only by these higher-order, com-plex, neurons, however, as there are parallel MMNs to violations
of a single feature and of a feature combination ~
Take-gata et al., 1999!.
Table 1 summarizes the central properties of the CSR proposed. Figure 2. A schematic illustration of the emergence and decay of the
central auditory representation~CSR!elicited by a brief sound. First, the different attributes of the sound are rapidly mapped on the respective separate feature analyzers ~Feature analysis! whose outputs are sub-sequently mapped on the neurophysiological mechanisms of sensory mem-ory so that the basis for unitary sound perception emerges ~Feature integration!. Temporal integration~such as loudness summation or mask-ing!also occurs here. In this phase, the emerging sound representation is provided with the time dimension, sounds being represented as events in time rather than merely as their static features. The abrupt emergence of the CSR provides the specific information contents for the sound percept~which may be conscious or preconscious, depending on whether the input also succeeds in exceeding the attention-trigger threshold controlled by separate mechanisms; see Näätänen 1992, p. 383!. The subsequent slowly decaying phase represents the~echoic!sensory-memory trace of the sound. Adapted from Näätänen and Winkler~1999!. Copyright 1999 by the American Psy-chological Association.
Table 1. Properties of the Central Sound Representation (CSR)
• Underlies, and corresponds to, perception, providing its sensory information content~in feature- and temporally integrated form!; • Sound enters long-term memory in the form of CSR~if at all!; • Represents sound as an auditory event in time rather than as a static set
of certain levels of different stimulus features;
• Formed when the outputs of central afferent processing enter sensory memory, this transient phase corresponding to perception and the subsequent slowly decaying phase sensory~echoic!memory; • Mental operations possible with it~e.g., imaging, rehearsal!; • Determines auditory performance: i.e., the accuracy of:
a. Perception b. Sensory memory c. Recognition d. Discrimination
MMN as an Index of Sound-Discrimination Accuracy As already mentioned, MMN, being elicited by any discriminable auditory change, provides an objective measure of the
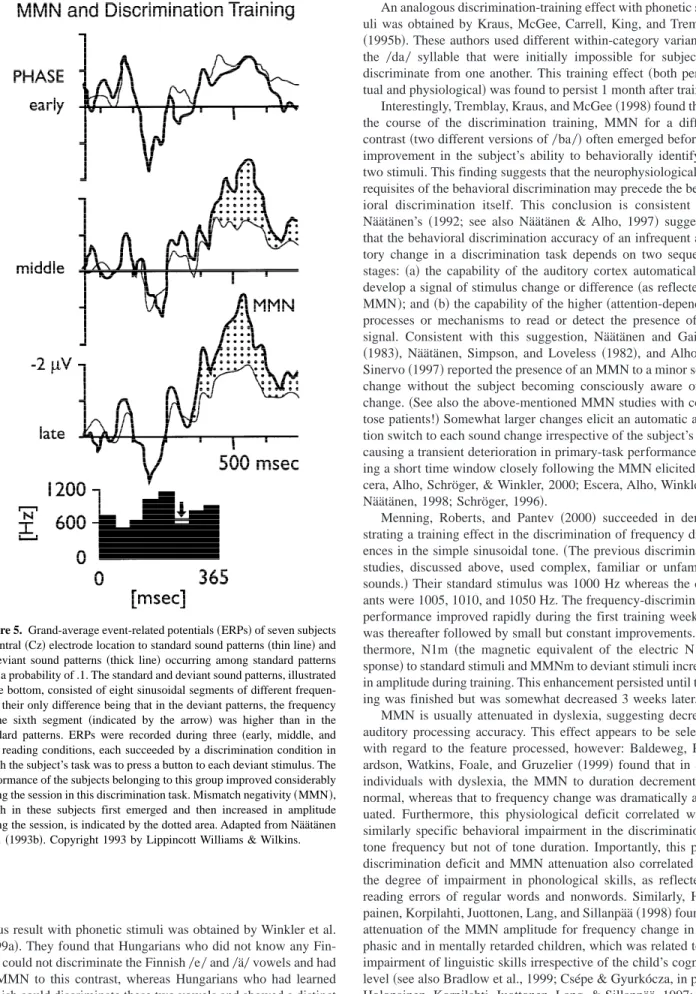
discrimina-tion accuracy separately for practically any dimension of auditory stimulation. Ultimately, the individual discrimination accuracy must depend on the informational sharpness of the CSR on the auditory dimension involved. Näätänen and Alho~1997!proposed the con-cept of the representational width~Rw!of a sound. This measure is illustrated for auditory frequency in Figure 3. The narrower the Rw, the more discriminable a different stimulus is from the stim-ulus represented by this Rw, that is, the better is the system’s resolution ability. This better resolution ability is reflected by a lower threshold of MMN elicitation and by a larger and earlier MMN elicited by suprathreshold changes.
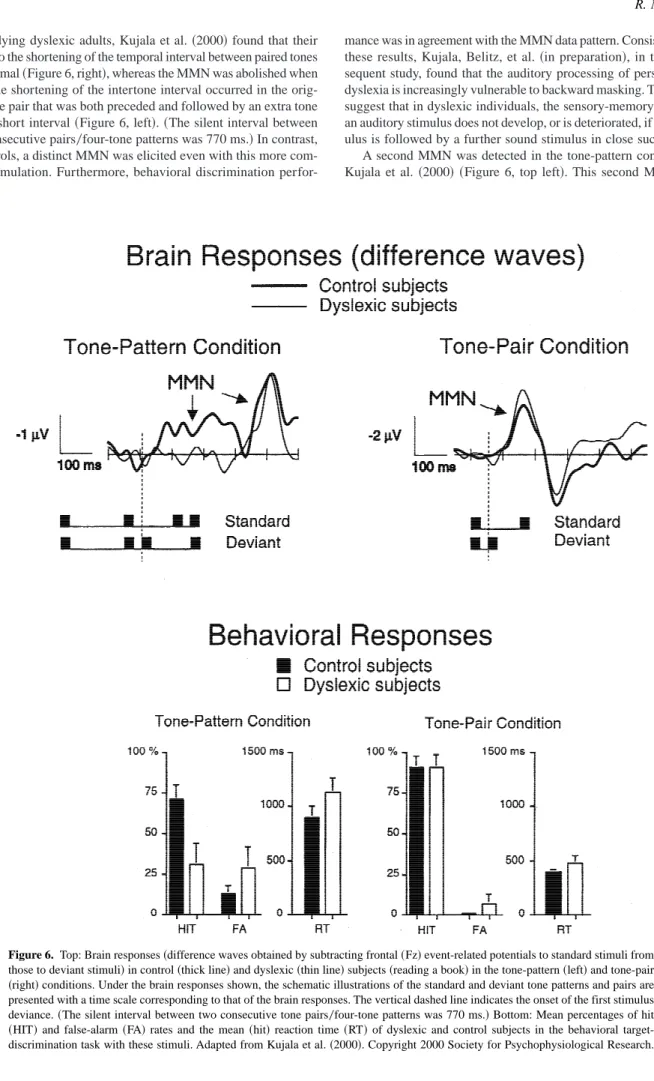
The first study showing that the MMN amplitude indeed pro-vides an index for the behavioral discrimination accuracy was reported by Lang et al.~1990!. They found that the accuracy of the behavioral discrimination of the frequency difference between two successively presented tone stimuli correlated strongly with the MMN amplitude for minor frequency changes~recorded in a sep-arate session in which subjects were reading!. These results are illustrated in Figure 4.
Corroborating data were obtained in numerous subsequent stud-ies. For example, Näätänen et al.~1993b!found that subjects who were able to behaviorally discriminate a slight deviation in a spec-trotemporal stimulus pattern showed an MMN to this deviant stim-ulus in a subsequent passive condition, whereas no MMN was elicited in subjects who were not able to perform this discrimina-tion. However, after the subjects who were not able to perform the discrimination learned the task during the course of the subsequent behavioral discrimination blocks of the same session, then the deviant pattern did elicite an MMN in them~Figure 5!. An anal-Figure 3. An illustration of the concept of the representational width~Rw!
along a sensory dimension, here for tone frequency. Rw is the range around the standard stimulus for the deviant-stimulus levels that are too near to the standard-stimulus level to elicit a mismatch negativity~MMN! and to cause behavioral change discrimination. Outside this range, MMN is elic-ited at an amplitude that is larger for wider deviations in either direction, and behavioral change detection usually occurs. From Näätänen and Alho ~1997!. Copyright by S. Karger AG, Basel.
Figure 4. Grand-average event-related potentials~ERPs!for subgroups of subjects who were “good,” “moderate,” or “poor” dis-criminators~in a separate behavioral pitch-discrimination session!. ERPs to standard tones of 698 Hz~dashed lines!and to infrequent deviant tones~solid lines!which were 12, 19, 25, 53, or 99 Hz higher in frequency than the standard tones are overlaid. Note the between-group differences in the mismatch negativity~MMN; shaded areas!amplitudes for different frequency deviations. Adapted from Lang et al.~1990!. Copyright 1990 Tilburg University Press.
ogous result with phonetic stimuli was obtained by Winkler et al. ~1999a!. They found that Hungarians who did not know any Fin-nish could not discriminate the FinFin-nish0e0and0ä0vowels and had no MMN to this contrast, whereas Hungarians who had learned Finnish could discriminate these two vowels and showed a distinct MMN to this contrast.
An analogous discrimination-training effect with phonetic stim-uli was obtained by Kraus, McGee, Carrell, King, and Tremblay ~1995b!. These authors used different within-category variants of the 0da0 syllable that were initially impossible for subjects to discriminate from one another. This training effect~both percep-tual and physiological!was found to persist 1 month after training. Interestingly, Tremblay, Kraus, and McGee~1998!found that in the course of the discrimination training, MMN for a difficult contrast~two different versions of0ba0!often emerged before the improvement in the subject’s ability to behaviorally identify the two stimuli. This finding suggests that the neurophysiological pre-requisites of the behavioral discrimination may precede the behav-ioral discrimination itself. This conclusion is consistent with Näätänen’s~1992; see also Näätänen & Alho, 1997! suggestion that the behavioral discrimination accuracy of an infrequent audi-tory change in a discrimination task depends on two sequential stages:~a! the capability of the auditory cortex automatically to develop a signal of stimulus change or difference~as reflected by MMN!; and~b!the capability of the higher~attention-dependent! processes or mechanisms to read or detect the presence of this signal. Consistent with this suggestion, Näätänen and Gaillard ~1983!, Näätänen, Simpson, and Loveless ~1982!, and Alho and Sinervo~1997!reported the presence of an MMN to a minor sound change without the subject becoming consciously aware of the change.~See also the above-mentioned MMN studies with coma-tose patients!!Somewhat larger changes elicit an automatic atten-tion switch to each sound change irrespective of the subject’s task, causing a transient deterioration in primary-task performance dur-ing a short time window closely followdur-ing the MMN elicited~ Es-cera, Alho, Schröger, & Winkler, 2000; EsEs-cera, Alho, Winkler, & Näätänen, 1998; Schröger, 1996!.
Menning, Roberts, and Pantev ~2000! succeeded in demon-strating a training effect in the discrimination of frequency differ-ences in the simple sinusoidal tone.~The previous discrimination studies, discussed above, used complex, familiar or unfamiliar, sounds.!Their standard stimulus was 1000 Hz whereas the devi-ants were 1005, 1010, and 1050 Hz. The frequency-discrimination performance improved rapidly during the first training week and was thereafter followed by small but constant improvements. Fur-thermore, N1m ~the magnetic equivalent of the electric N1 re-sponse!to standard stimuli and MMNm to deviant stimuli increased in amplitude during training. This enhancement persisted until train-ing was finished but was somewhat decreased 3 weeks later.
MMN is usually attenuated in dyslexia, suggesting decreased auditory processing accuracy. This effect appears to be selective with regard to the feature processed, however: Baldeweg, Rich-ardson, Watkins, Foale, and Gruzelier~1999!found that in adult individuals with dyslexia, the MMN to duration decrement was normal, whereas that to frequency change was dramatically atten-uated. Furthermore, this physiological deficit correlated with a similarly specific behavioral impairment in the discrimination of tone frequency but not of tone duration. Importantly, this pitch-discrimination deficit and MMN attenuation also correlated with the degree of impairment in phonological skills, as reflected in reading errors of regular words and nonwords. Similarly, Holo-painen, Korpilahti, Juottonen, Lang, and Sillanpää~1998!found an attenuation of the MMN amplitude for frequency change in dys-phasic and in mentally retarded children, which was related to the impairment of linguistic skills irrespective of the child’s cognitive level~see also Bradlow et al., 1999; Csépe & Gyurkócza, in press; Holopainen, Korpilahti, Juottonen, Lang, & Sillanpää, 1997; Kor-pilahti, 1995!.
Figure 5. Grand-average event-related potentials~ERPs!of seven subjects at central~Cz!electrode location to standard sound patterns~thin line!and to deviant sound patterns~thick line!occurring among standard patterns with a probability of .1. The standard and deviant sound patterns, illustrated at the bottom, consisted of eight sinusoidal segments of different frequen-cies, their only difference being that in the deviant patterns, the frequency of the sixth segment~indicated by the arrow!was higher than in the standard patterns. ERPs were recorded during three~early, middle, and late!reading conditions, each succeeded by a discrimination condition in which the subject’s task was to press a button to each deviant stimulus. The performance of the subjects belonging to this group improved considerably during the session in this discrimination task. Mismatch negativity~MMN!, which in these subjects first emerged and then increased in amplitude during the session, is indicated by the dotted area. Adapted from Näätänen et al.~1993b!. Copyright 1993 by Lippincott Williams & Wilkins.
Studying dyslexic adults, Kujala et al.~2000!found that their MMN to the shortening of the temporal interval between paired tones was normal~Figure 6, right!, whereas the MMN was abolished when the same shortening of the intertone interval occurred in the orig-inal tone pair that was both preceded and followed by an extra tone with a short interval~Figure 6, left!.~The silent interval between two consecutive pairs0four-tone patterns was 770 ms.!In contrast, in controls, a distinct MMN was elicited even with this more com-plex stimulation. Furthermore, behavioral discrimination
perfor-mance was in agreement with the MMN data pattern. Consistent with these results, Kujala, Belitz, et al.~in preparation!, in their sub-sequent study, found that the auditory processing of persons with dyslexia is increasingly vulnerable to backward masking. These data suggest that in dyslexic individuals, the sensory-memory trace for an auditory stimulus does not develop, or is deteriorated, if this stim-ulus is followed by a further sound stimstim-ulus in close succession.
A second MMN was detected in the tone-pattern condition of Kujala et al.~2000! ~Figure 6, top left!. This second MMN was
Figure 6. Top: Brain responses~difference waves obtained by subtracting frontal~Fz!event-related potentials to standard stimuli from those to deviant stimuli!in control~thick line!and dyslexic~thin line!subjects~reading a book!in the tone-pattern~left!and tone-pair ~right!conditions. Under the brain responses shown, the schematic illustrations of the standard and deviant tone patterns and pairs are presented with a time scale corresponding to that of the brain responses. The vertical dashed line indicates the onset of the first stimulus deviance.~The silent interval between two consecutive tone pairs0four-tone patterns was 770 ms.!Bottom: Mean percentages of hit ~HIT!and false-alarm~FA!rates and the mean~hit!reaction time~RT!of dyslexic and control subjects in the behavioral target-discrimination task with these stimuli. Adapted from Kujala et al.~2000!. Copyright 2000 Society for Psychophysiological Research.
obviously elicited by the second change inevitably occurring in this type of paradigm, that is, the omission of one of the two paired tones in the end of the standard-stimulus pattern. Interestingly, this MMN was normal in dyslexic persons, indicating that MMN data can pinpoint the specific deficient aspect of auditory processing ~which the behavioral response, apparently based on the first change, could not do!.
A correlation between the behavioral discrimination accuracy and the MMN amplitude was also reported by several other studies ~e.g., Amanedo & Escera, 2000; Groenen, Snik, & van den Broek, 1996; Kileny, Boerst, & Zwolan, 1997; Kraus et al., 1996; Martin, Kurtzberg, & Stapells, 1999; Winkler et al., 1999a; for a review, see Kraus et al., 1995a!.
MMN as an Index of Tech-Sound Discrimination
MMN can also be used as an index of the discrimination of lin-guistic stimuli, such as phonemes and consonant-vowel~CV! syl-lables, with no MMN being elicited if two phonemes or syllables are indiscriminable to the subject or patient. Furthermore, the MMN amplitude is larger with easier discriminations and with improved discrimination ability. The first study reporting an MMN to a phoneme change was conducted by Aaltonen et al.~1987!. They found an MMN when the Finnish0y0was occasionally replaced by the Finnish0i0, and a smaller MMN when it was replaced by the border stimulus0yi0.
More recently, Kraus et al. ~1996!, in their extensive study, found an MMN for the0da0-0ga0contrast only in those children who were able to behaviorally discriminate the two syllables.~Both groups were easily able to discriminate the0ba0and0wa0 sylla-bles and had a robust MMN for this contrast.!Many of the children who could not discriminate the0da0and0ga0syllables belonged to different problem-learner categories. One might, however, as-sume that many of these children became problem learners just because of the inability of their auditory cortex to discriminate all phonemes or syllables~see also Kemner, Verbaten, Koelega, Buite-laar, & van der Gaag, 1996; Kraus & McGee, 1994; Kraus et al., 1995a!. This assumption would in fact signify a good message to their teachers and parents for, as already reviewed, intensive dis-crimination training of relatively short duration may improve the discrimination accuracy considerably~e.g., Karma & Turkkila, in preparation; Kraus et al., 1995b; Kujala, Karma, et al., in prepa-ration; Merzenich et al., 1996; Tallal et al., 1996!.
MMN can also be used to study the discrimination of speech sounds by newborns. Cheour-Luhtanen et al.~1995!found in new-borns an MMN to Finnish0i0deviants whereas the Finnish 0y0 was the standard. Furthermore, in their subsequent study with the same stimuli, Cheour-Luhtanen et al.~1996!found an MMN even in preterm infants~the conceptional age 25–30 weeks at the time of the recording!. In view of the small acoustic difference~only in the F2 formant!between the standard and deviant used, one may conclude that the capacity of discriminating such fine-grained acous-tic differences that is a prerequisite for later phoneacous-tic distinctions emerges unexpectedly early.
A relationship between speech understanding and the MMN amplitude was found in cochlear-implant patients by Groenen et al.~1996!. These authors obtained an MMN for the0ba0-0da0 contrast in cochlear-implant users who were clearly able to dis-criminate the two syllables behaviorally. In contrast, no signifi-cant MMN was obtained with any of the cochlear-implant users with “moderate” discrimination performance ~see also Kileny et al., 1997; Kraus et al., 1993!. For reviews on MMN in
cochlear-implant users, see Ponton and Don ~1995! and Ponton et al. ~2000!.
The role of genetic factors in developmental dyslexia was dem-onstrated by Leppänen and Lyytinen~1997!. These authors found an attenuated MMN to the Finnish nonsense word0atta0, while the standard was another Finnish nonsense word0ata0~shorter in du-ration than 0atta0!, over the left, but not right, hemisphere of 6-month-old infants with at least one dyslexic parent and one more remote dyslexic relative compared with control infants with no such familial background~Figure 7!. This MMN attenuation might signal an elevated risk of developmental dyslexia in these infants. Aphasic patients also show an attenuated MMN. Aaltonen, Tuomainen, Laine, and Niemi ~1993! found that MMN, or its lack, could provide specific information with regard to the per-ceptual deterioration caused by a brain lesion. Two of their pa-tients, those with a posterior left-hemispheric lesion, had a normal MMN to the frequency change of a simple tone, whereas a vowel change~from the Finnish0y0to0i0!elicited no MMN.
The above-mentioned studies demonstrate that MMN can be used to determine the accuracy of central auditory processing of speech and nonspeech sounds. In clinical cases, MMN could pro-vide the profile of deterioration for the different aspects of sound processing. Furthermore, such studies can also be extended to newborns and infants whose central auditory processing cannot be studied reliably with purely behavioral means.
Language-Specific Speech-Sound Traces as Revealed by the MMN
In addition to providing an objective measure of speech-sound discrimination, MMN has also revealed some central brain ele-ments of speech perception. Recent MMN data suggest that the correct speech perception, a prerequisite of speech understanding, is based on a set of phoneme traces of the language involved~and their combinations representing syllables and words; see Kor-pilahti, Krause, Holopainen, & Lang, in press; Pulvermüller et al., submitted!. This system of the speech-sound traces for the mother tongue develops, as will be discussed later, as a function of lan-guage exposure at a very early age, thereafter providing the rec-ognition models or templates used by the central auditory system in the perception of these speech sounds. Hence, when a famil-iar speech sound is presented, it activates the corresponding phonetic trace or recognition model, in addition to the different sound-analysis mechanisms common to speech sounds and equally complex nonspeech sounds. A speech sound would thus cause speech-specific and -nonspecific activations.
The first electric sign of the speech-sound specific recogni-tion activarecogni-tion was reported by Hoppe, Moser, Rosanowski, and Eysholdt~1996!. This sign was a negativity peaking at about 170 ms~“N170”!from the onset of a phoneme stimulus, which did not occur in response to the noise analog of the stimulus. This bilateral~Rosanowski, Hoppe, Hies, & Eysholdt, 1999!N170 might be generated when the sound-elicited process encounters the cor-responding recognition model or trace in the sensory-memory sys-tem. Hence this activation~if it cannot be accounted for by the remaining acoustic differences between the two stimulus types! might manifest a read-out of the corresponding phonetic code to perception, which then would be of a phonetic-acoustic rather than of merely an acoustic nature.
The speech-sound recognition models discussed above could also explain the categorical perception of the phonemes so that, for example, for each phoneme, there is a constant~or nearly constant!
phoneme code, carried by the trace, which is activated by the different prototype and nonprototype variants of the phoneme~by the latter probably to a lesser extent, however!. Thus, the neural mechanisms of categorical perception possess, obviously, only a limited set of response alternatives, there hence being no contin-uous mapping of stimuli into this system.
Thus, regarding what is special about speech perception, one could argue, consistently with Liberman, Harris, Hoffman, and Griffith ~1957! and Kuhl ~1991, 1993!, that both speech and complex nonspeech sounds activate acoustic sound-analysis mech-anisms, but only speech sounds activate the speech-sound traces or recognition models. The MMN data to be reviewed below suggest that this speech-specific activation predominantly is a left-hemisphere function, whereas both hemispheres participate in the analysis of the acoustic sound features.
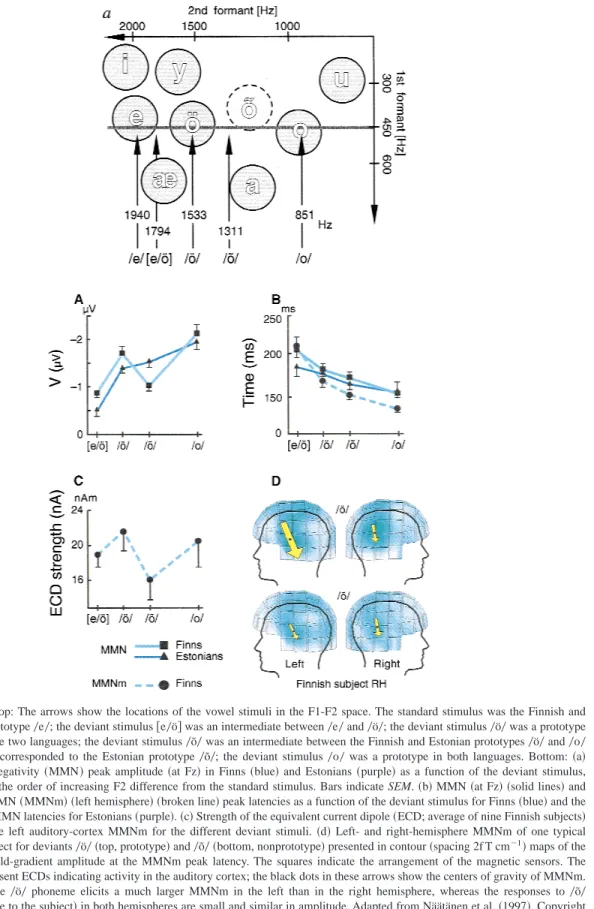
Evidence for the existence of phoneme traces was obtained by Näätänen et al. ~1997!. Finnish subjects ~reading a book! were presented with the Finnish0e0vowel as the standard stim-ulus and two other Finnish vowels0ö0and0o0and the Estonian vowel 0õ0 as deviant stimuli. ~The stimuli differed from each other only in F2, with F0 and the other formants being con-stant.! It was found that the MMN elicited by the Estonian0õ0
was smaller in amplitude than that elicited by the Finnish 0ö0, even though the acoustical deviation of 0õ0 from the standard 0e0 was larger than that of0ö0. This MMN difference was not found in Estonian subjects in whose language all these sounds are phonemes ~Figure 8!. Whole-head magnetoencephalographic
~MEG! measurements of MMNm showed that the
phoneme-related MMN enhancement in the Finnish subjects originated from the left auditory cortex, which was therefore concluded to be the locus of the phoneme traces.
These results suggest that two parallel processes contributed to the MMN~MMNm!measured:~1!the acoustic change-detection process occurring bilaterally to a deviant stimulus and involving the short-duration acoustic memory traces developed by the stan-dards;~2! the phoneme-specific process occurring in the left au-ditory cortex when the deviant stimulus was a phoneme of the subject’s mother tongue, implicating the presence of permanent phoneme traces in the left auditory cortex.
Thus, the left-hemispheric MMNm enhancement for the devi-ant phoneme stimuli might be explained by the occurrence of two parallel change-detection processes in the left auditory cortex: the acoustic~F2 change!and the phonetic~0e0replaced by0ö0!, whereas only the acoustic change-detection process occurred when the de-Figure 7. Grand average across-subject difference waves~event-related potentials to the standard0ata0subtracted from those to the deviant0atta0!in the dyslexia-risk group~dashed line!and in the control group~solid line!of 6-month-old infants. Stimulus onset is indicated by the short vertical line. Adapted from Leppänen and Lyytinen~1997!. Copyright 1997 S. Karger AG, Basel.
Figure 8. Top: The arrows show the locations of the vowel stimuli in the F1-F2 space. The standard stimulus was the Finnish and Estonian prototype0e0; the deviant stimulus@e0ö#was an intermediate between0e0and0ö0; the deviant stimulus0ö0was a prototype
shared by the two languages; the deviant stimulus0õ0was an intermediate between the Finnish and Estonian prototypes0ö0and0o0
and closely corresponded to the Estonian prototype0õ0; the deviant stimulus0o0was a prototype in both languages. Bottom:~a!
Mismatch negativity~MMN!peak amplitude~at Fz!in Finns~blue!and Estonians~purple!as a function of the deviant stimulus, arranged in the order of increasing F2 difference from the standard stimulus. Bars indicate SEM.~b!MMN~at Fz! ~solid lines!and magnetic MMN~MMNm! ~left hemisphere! ~broken line!peak latencies as a function of the deviant stimulus for Finns~blue!and the respective MMN latencies for Estonians~purple!.~c!Strength of the equivalent current dipole~ECD; average of nine Finnish subjects! modeling the left auditory-cortex MMNm for the different deviant stimuli.~d!Left- and right-hemisphere MMNm of one typical Finnish subject for deviants0ö0~top, prototype!and0õ0~bottom, nonprototype!presented in contour~spacing 2f T cm21!maps of the
magnetic field-gradient amplitude at the MMNm peak latency. The squares indicate the arrangement of the magnetic sensors. The arrows represent ECDs indicating activity in the auditory cortex; the black dots in these arrows show the centers of gravity of MMNm. Note that the0ö0phoneme elicits a much larger MMNm in the left than in the right hemisphere, whereas the responses to 0õ0
~nonphoneme to the subject!in both hemispheres are small and similar in amplitude. Adapted from Näätänen et al.~1997!. Copyright 1997 by Macmillan Magazines, Ltd.
viant stimulus was a foreign phoneme ~0õ0!. In contrast, in the right auditory cortex, only the acoustic change-detection process occurred irrespective of whether the deviant stimulus was a pho-neme or not.~The phoneme-recognition negativity N170 cannot explain these results as it was generated bilaterally; Rosanowski et al., 1999.!
Dehaene-Lambertz ~1997! also found evidence for the exis-tence of language-specific memory traces. Recording ERPs to synthetic syllables varying along a voiced place of articulation continuum, Dehaene-Lambertz observed that for an equal acous-tical distance between the deviant and standard syllables, MMN was enhanced by the linguistic relevance of the syllable change in the subject’s native language. For example, no MMN was found for a Hindi phonetic contrast in French adults, whereas MMN was elicited by an acoustical change of equal magnitude that crossed a French phonetic boundary. ~See also Tremblay, Kraus, Carrell, & McGee, 1997, to be discussed below.!In their study with Finnish and Hungarian subjects, Winkler et al.~1999b! reached an essentially similar conclusion~see below!.
Sharma and Dorman’s~1999!recent results also are consistent with the existence of phonetic traces. These authors addressed the neural encoding of voice-onset time~VOT!distinctions that sep-arate the phonetic categories0da0and0ta0. Behaviorally, a sharp category boundary was revealed between these two categories around the same location for all subjects. Furthermore, their dis-crimination of a VOT change of equal magnitude was more accu-rate across the0da0-0ta0categories than within the0ta0category. Consistent with this finding, MMN elicited by the across-category change was larger in amplitude than that elicited by the within-category change ~see also Aaltonen, Eerola, Hellström, Uusi-paikka, & Lang, 1997!. This enhanced MMN, as well as the discontinuity in N1 morphology observed in the region of the 0da0-0ta0 phonetic boundary, were suggested by the authors as providing neurophysiological correlates of categorical perception for VOT. On the grounds of the Näätänen et al.~1997!results, one could propose that this MMN enhancement originated from a pho-netic MMN process.
Rinne et al.~1999!wished to clarify more exactly the stimulus determinants of the left-hemispheric preponderance of MMN. By gradually reducing stimulus complexity, they created two eight-step stimulus dimensions, one starting from the Finnish0a0~like in “but”! and the other from the Finnish 0i0 ~like in “hit”!, both ending with the corresponding simple tone ~F1!. It was found, when the stimuli were gradually degraded, that as long as the subject heard the stimuli phonetically, MMN to an0i0-dimension stimulus~deviant! was left-hemispheric preponderant~when the corresponding0a0-dimension stimulus was used as the standard!. This left-hemispheric predominance was no longer present when stimuli were not perceived phonetically. Further, the MMN source in the left hemisphere was located for the phonetically perceived stimuli posteriorly to that for the nonphonetically perceived stim-uli, apparently in Wernicke’s area. Consistent with this finding, as already mentioned, Aaltonen et al.’s~1993!posterior left-hemispheric patients with aphasia had no phoneme MMN, whereas MMN to frequency change was preserved. ~In contrast, MMN was pre-served for both changes in their anterior left-hemispheric patients.! For consistent results, see Csépe~1995!and Sharma, Kraus, Car-rell, and Thompson~1994!.
Data suggesting the left-hemisphere locus of phonetic traces were also obtained by Sharma and Kraus~1995!. They found that the MMN elicited by the syllable0da0was larger over the left than right hemisphere when0da0signaled a phonetic change~standards
0ga0! but was symmetric when the same 0da0 signaled a pitch change ~0da0 high vs. 0da0 low!. Moreover, Tremblay et al.’s ~1997!learning and transfer effects of training on a foreign pho-netic contrast ~to be discussed later! were larger for the MMN recorded over the left than right hemisphere.
In their MEG study with binaurally presented CV syllables, Alho et al. ~1998! also obtained data consistent with the left-hemispheric locus of speech-sound memory traces. Their standard was the syllable 0da0 and deviants were the syllables0di0 and 0ba0. The MMNm amplitude was clearly larger over the left than right hemisphere ~and did not depend significantly on whether syllables were attended or not!.~See also Tervaniemi et al., 1999a.! PET data supporting the mainly left-hemispherically predom-inant MMN with phonetic stimuli were obtained by Tervaniemi et al. ~2000!. By subtracting the standards-alone PET map from that with deviants and standards, they found a distinct left-hemispheric activation ~but no significant right-hemispheric ac-tivation, apparently because of the high threshold used for determining statistical significance!with phoneme stimuli, whereas with chord stimuli, a clear right-hemispheric activation was ob-tained ~Figure 9!. For related f MRI studies, see Opitz, Meck-linger, von Cramon, and Kruggel~1999!and Celsis et al.~1999!.
Figure 9. The functional lateralization of the mismatch negativity~MMN! shown with positron emission tomography~PET!. The upper panel~on the left, seen from above; on the right, seen from back!shows the activation resulting from subtracting the activity in a condition in which only0e0 phonemes were presented from the activity in a condition in which0e0 phonemes were presented as standards and0o0phonemes as deviants. The differential neural activity reflecting the MMN response is seen in the left superior and medial temporal gyri of the auditory cortex, indicating that change detection for speech sounds is left lateralized. The lower panel~on the left, seen from above; on the right, seen from back!shows the activa-tion resulting from subtracting the activity in a condiactiva-tion in which only A-major chords were presented from that in a condition in which A-major chords were presented as standards and A-minor chords as deviants. Neural activity reflecting the MMN response is now seen in the right superior temporal gyrus of the auditory cortex, indicating that change detection for musical information is right lateralized. Adapted from Tervaniemi et al. ~2000!.
The above-reviewed results suggest strongly that phonetic traces are located in the left hemisphere. The clear left-hemispheric pre-ponderance of the MMN with phoneme stimuli cannot be observed in all conditions, however. For example, Shtyrov et al. ~1998! found that under noisy conditions, the MMNm recorded over the left hemisphere decreased and that over the right hemisphere in-creased, so that in most subjects, larger MMNm dipoles were found in the right hemisphere.
Consistent with the left-hemispheric phoneme traces providing an account for the left-hemispheric predominance of speech pro-cessing~Näätänen et al., 1997!, Shtyrov, Kujala, Palva, Ilmoniemi, and Näätänen~in press!found that a stimulus pattern imitating the rapid-transition acoustic structure of CV syllables but perceived in a nonphonetic way did not elicit a left-preponderant MMNm but rather one that had no clear hemispheric lateralization. Further-more, when this stimulus pattern was temporally stretched, that is, made slower~cf. Merzenich et al., 1996; Tallal et al., 1996!, MMNm became right-hemisphere preponderant~Shtyrov et al., in press!.
Cheour et al.~1998!wished to determine the age at which the language-specific memory traces of the mother tongue emerge. Using the Näätänen et al.~1997!paradigm with0e0as the standard stimulus but only0ö0and 0õ0as the deviant stimuli, they found that the MMN amplitude in 6-month-old Finnish infants was larger for the Estonian0õ0than for the Finnish0ö0, the acoustically less deviant stimulus. Thus, MMN at this age was merely acoustic. At the age of 12 months, however, the same infants had a much larger MMN for0ö0than0õ0, suggesting that the language-specific mem-ory traces developed between 6 and 12 months. Consistent with this finding, Estonian 12-month-old infants had a larger MMN for 0õ0than for0ö0, both being phonemes in their language but0õ0 deviating acoustically more than0ö0from0e0~Figure 10!.
Dehaene-Lambertz and Baillet ~1998! found a larger MMN kind of response but of positive polarity to across-category than ~acoustically equal! within-category phoneme changes in infants as young as 3 months, which suggests that the memory traces of the mother tongue may be present already at this early age ~see also Dehaene-Lambertz & Dehaene, 1994!. Both change-detection responses seemed to be generated bilaterally in the temporal lobes ~though there was a tendency for both responses being larger in the left than right hemisphere!, with the across-category response hav-ing a source posterior and dorsal to that of the within-category response. ~The results of Cheour et al., 1998, suggesting a later emergence of the language-specific memory traces, might be due to the fact that0ö0is an infrequent phoneme in Finnish, therefore needing, presumably, a longer time to develop its phoneme trace in the infant’s brain!.
Winkler et al.~1999a!demonstrated that with MMN, one can also follow how adults learn to perceive and discriminate correctly foreign-language phonemes. Their standard stimulus was a vowel that is perceived as0e0both by Finns and Hungarians, whereas the deviant stimulus was the Finnish 0ä0, which in the Hungarian language belongs to the same category as the 0e0 used as the standard. It was found that Hungarians who did not know any Finnish had no MMN to the deviant0ä0in the ignore condition and were very poor in discriminating it behaviorally from0e0in the discrimination condition. In contrast, Hungarians who had lived in Finland for years and learned to speak fluent Finnish had a distinct MMN to0ä0, similar to that of native Finns, and were also able behaviorally to discriminate it from0e0~Figure 11!.
Tremblay et al.~1997!trained normal-hearing English-speaking adults to discriminate and identify a VOT contrast that does not
occur in English but is phonetically salient in Hindi and Eastern Armenian. Subjects were trained to perceive this VOT contrast in a bilabial context, but their ability to discriminate and identify this contrast both in the bilabial context~training condition!and in an alveolar context~transfer condition!was evaluated before and after training. After training, the subjects could identify and discrimi-nate both the training and transfer contrasts behaviorally. These training and transfer effects were manifested by increases in the MMN duration and area, which were more pronounced for the training than transfer stimuli and over the left than right frontal cortex. This lends further credibility to the left-hemisphere locus of the language-specific phonetic traces. Based on these results, Kraus and Cheour~2000!proposed that, from a rehabilitative per-spective, discrimination training for well-chosen acoustic elements of speech might generalize to other acoustic contexts.
Combining phonemes into syllables and in particular into words is of course to a large extent language-specific. One might there-fore think of the cerebral representation of the speech sounds of a language as a hierarchically organized structure where the lowest level is formed by phoneme traces, which are then at the next level combined to form syllables and at a still higher level words, so that the temporal order is strictly preserved.~This structure, of course, depends on the language involved.!Thus, one could also assume the existence of word traces, representations for whole words. Further, these traces could be expected to be stronger for more frequent than for less frequent words.
The possible existence of language-specific word traces was tested recently by Pulvermüller et al.~submitted!. These authors recorded brain responses of native Finnish-speaking subjects to the same spoken syllables when they completed a Finnish word or when they completed a pseudoword. Subjects were instructed to ignore the sound stimuli and watch a silent movie. MMN to each syllable was found to be larger in amplitude when the syllable completed a word than when it completed a pseudoword. This enhancement did not occur in foreign subjects who did not know any Finnish. These results appear to demonstrate the presence of memory traces for spoken words in the human brain ~see also Korpilahti et al., in press!. With MEG, the intracranial origin of this word-specific MMN enhancement was located in the left su-perior temporal lobe~Pulvermüller et al., submitted!.
Properties of the Language-Specific Speech-Sound Memory Traces Reflected by the MMN
Table 2 lists the properties of the language-specific speech-sound memory traces as suggested here. First, it is obvious that these traces are permanent or based on long-term memory, probably remaining throughout the lifetime of an individual, at least those for the mother tongue. As already reviewed, these traces are prob-ably located in the posterior part of the left auditory cortex in Wernicke’s area or in its vicinity.
The key question in understanding how the brain perceives speech involves the nature of the code carried by the phonetic trace, one recognizing the corresponding speech sound irrespective of the large acoustic variation between the voices of the different speakers and between the different word contexts. This means that all acoustic signals heard, say, as an0e0, irrespective of the speaker and word context, must have something in common, that is, there must exist some complex acoustic invariance or constancy shared by all these sounds. For vowels, this invariance probably to a large extent involves the F1 and F2 formants, as all vowels, at least in Finnish, can be recognizably produced by manipulating just those
two formants ~Figure 8!. An essential aspect of this invariance might thus be the F20F1 ratio ~with F2, and thus F1, remaining within a certain frequency range!. This assumption would mean that there must exist in the central auditory system such neuronal populations that do not respond to any single frequencies, or their combinations, as such but rather to certain F20F1 ratios. MMN evidence for the existence of neuronal populations that encode invariant sound patterns, such as these ratios, contained by acous-tically varying sound stimulation will be reviewed in the next section.
The central function of the phonetic traces is, presumably, to act as recognition patterns or templates in speech perception, enabling one to correctly perceive the speech sounds uttered. Without these phonetic traces, one would perceive the spoken language only acous-tically, similarly to any other complex sound, with the main differ-ence from speech perception being that there is no category effect.
Thus, it appears that both speech and nonspeech sounds are mapped continuously into auditory perception but, in addition to this, speech sounds are pre-perceptually classified into different phonetic categories corresponding to the different phonemes and their combinations~cf. Broadbent’s@1970#response set!. Hence, in this categorical process, each phoneme input probably activates the “closest” phoneme trace, the one best corresponding to it, there thus being as many different response alternatives by this system as there are different phoneme traces in it.~This applies, presum-ably, to larger linguistic units, too.!
Consequently, the results reviewed above suggest that in learn-ing to correctly perceive the mother tongue, the exposure to this language environment causes in the brain plastic changes in the form of the emergence of the language-specific memory traces ~but the early exposure to a specific language environment might also permanently modify the afferent mechanisms, so that they Figure 10. Top: The mismatch negativity~MMN!amplitude at the Cz electrode~grand-average deviant-standard difference wave-forms!for0ö0~solid line!and0õ0~dashed line!deviants while0e0was the standard. At 6 months of age, the MMN amplitude of Finnish infants reflects only the acoustical difference between the deviant and standard stimuli~left!. At 1 year of age, however, the MMN amplitude in the same children was considerably enhanced for the Finnish vowel0ö0but not for the Estonian0õ0, suggesting the emergence of language-specific vowel traces~middle!. In Estonian 1-year-old infants, the MMN amplitude was larger for0õ0than for 0ö0because of the larger acoustic difference from0õ0than from0ö0to the0e0standard stimulus, both deviant stimuli being vowels in Estonian~right!. Bottom: The MMN peak amplitude~at Cz!as a function of the deviant stimulus for 6-month-old Finnish infants, for the same infants at the age of 1 year, and for 1-year-old Estonian infants. Adapted from Cheour et al.~1998!. Copyright 1998 by Macmillan Magazines, Ltd.
become increasingly more sensitive to, or accurate for, the type of acoustic variation that is frequently present in stimulation!.
The same learning~memory-trace development!process has to occur before a foreign language with a speech-sound structure different from that of the mother tongue can be perceived correctly. Everyday experience suggests that this process succeeds perfectly only in the early childhood. When adults try to learn a foreign language, it appears that they often have to cope with their mother-tongue speech-sound recognition system, making encoding of the foreign-language speech sounds less accurate and their perception
thus more vulnerable to demanding external~like noise!or internal ~alcohol, tiredness!conditions.
As to the role of attention, this trace development might occur automatically in the case of the “tabula rasa” of a very young infant but become increasingly attention dependent with increasing age. In their study on the learning of a complex spectrotemporal pattern by adult subjects, Näätänen et al.~1993b!found that no learning, as indexed by the lacking MMN to a slight change in this pattern, occurred with hours-long continuous passive exposure to this stimulation with no discrimination task. In contrast, only a few Figure 11. Top and middle: Mismatch negativity~MMN! to vowel contrasts. Group-average frontal~Fz!MMN re-sponses in Finns, fluent~Finnish-speaking!Hungarians, and naïve~not Finnish-speaking!Hungarians to rare0ä0 ~top panel!and0y0~middle panel!vowels presented in a repet-itive series of the0e0vowel. The0e0versus0ä0contrast, which is relevant in Finnish but not in Hungarian, did not elicit an MMN in naïve Hungarians, but elicited in fluent Hungarians an MMN that was similar to that of the native Finnish speakers~top panel!. The0e0versus0y0contrast, which is relevant in both languages, elicited almost identical MMN responses in all three groups of subjects ~middle panel!. Bottom: Vowel identification. The group-averaged correct identification rate~left: SEM values marked above each bar!of Finns approached 90% and that of fluent Hun-garians 80%, whereas naïve HunHun-garians performed at the chance level. Finns and fluent Hungarians were also faster in the identification task than were naïve Hungarians~right: group-averaged reaction times, SEM values above the bars!. From Winkler et al.~1999a!. Copyright 1999 Society for Psychophysiological Research.
blocks of discrimination trials were needed to produce an MMN in the subsequent passive condition.
These phonetic traces might also provide the sensory informa-tion needed in the producinforma-tion and control of the pronunciainforma-tion. Try-ing to learn the correct pronunciation for a foreign speech sound may be described as an iterative process in which the goal is to produce a pronunciation that would match with the sensory information en-coded in the trace of this target speech sound. Actually, in this ex-ercise, one presumably tries to get his or her own phoneme, syllable, and word traces activated by his or her own voice. Therefore, the accuracy of sensory information in these traces for foreign speech sounds probably sets the upper limit for the individual accuracy of pronouncing these sounds. Hence, in an attempt to improve pro-nunciation, individuals should try to improve the informational ac-curacy of their own speech-sound traces.
The phoneme traces, and their higher-order combinations, are of course not the only sensory traces present when we are exposed to speech. Speech sounds also continuously produce short-term, purely acoustic traces representing their acoustic features and fea-ture combinations, an MMN being elicited when a change occurs in any of these features or their combinations~see Winkler et al., 1999b!. Thus, for a given speaker, a set of traces develops which represents the different sensory qualities of his0her voice. There is, of course, continuous variation around some median level in each feature, such as sound intensity at the listener’s ear but, as Winkler et al.~1990; see also Gomes et al., 1995; Huotilainen et al., 1993! have shown, the trace development tolerates this variation, judging from MMN elicitation by frequency deviations even in the pres-ence of standard-stimulus intensity variation. This MMN was more attenuated relative to the constant-standard amplitude with larger-range standard-stimulus variation, however.
These acoustic traces might also be essential in the preattentive stream formation and maintenance and in stream segregation~ Breg-man, 1990; SussBreg-man, Ritter, & Vaughan, 1999!. Each new stimulus from the same source corresponds to the source represented by the trace~s!developed by the preceding stimuli from the same source. Thus, for example, if there are two concurrent speakers in different locations, then there also are two parallel spatial memory traces, serving stream segregation~see Bregman, 1990!, that is, keeping
the two input channels separate. ~For MMN evidence for the existence of two parallel traces, see Näätänen et al., 1978; Sams, Alho, & Näätänen, 1983; Winkler et al., 1996.!Stream segregation considerably improves, however, if there are also other differences between the concurrent sound streams such as in frequency~Alho, Töttölä, Reinikainen, Sams, & Näätänen, 1987; Hansen & Hill-yard, 1983; HillHill-yard, Hink, Schwent, & Picton, 1973!, but even a frequency difference alone, when exceeding a certain limit, is suf-ficient to cause stream segregation when the stimulus rate is fast ~Bregman, 1990; Sussman et al., 1999!, providing continuous re-inforcement and updating for the two separate traces, one under-lying the lower-pitch stream and the other the higher-pitch stream. Timbre differences, too, between the voices of different speakers serve speaker segregation in natural listening conditions. Consis-tent with this, timbre changes tend to elicit distinct MMNs~ Ter-vaniemi, Winkler, & Näätänen, 1997!.
Thus, it might be that the sensory-memory traces involved in MMN generation determine whether stream segregation occurs or not. Hence, for example, two separate sound streams are per-ceived, if the traces of two sufficiently different sounds both re-ceive frequent reinforcement and updating~and then it probably would be possible to obtain two separate, within-stream MMNs, as with dichotic stimulation; Näätänen et al., 1978; see also Ritter, Sussman, & Molholm, 2000; Sussman et al., 1999; Winkler et al., submitted!.
In addition to these short-term memory traces for acoustic stim-ulus aspects, there are also, presumably, long-term sensory traces for purely acoustic sound features. These traces explain, for in-stance, speaker recognition based on the mere voice. The brain must contain numerous sets of permanent sensory voice traces, with each trace set characterizing the voice qualities of some per-son to whom we have often listened, making the recognition of the speaker on the basis of the mere voice possible.
Furthermore, there also are sound-pattern or -sequence traces such as those of well-known melodies that are, of course, of long-term or permanent nature ~Verleger, 1990!. The melody traces represent no fixed acoustic attributes but rather are sound-sequence-pattern traces, judging from the fact that a melody can be recog-nized irrespective of the instrument or key with which it is played. Table 2. Assumed Properties of Phoneme Traces
• Long-term memory~permanent or semipermanent!traces.
• Located in the left-hemisphere posterior auditory cortex in or near Wernicke’s area.
• Serve as recognition patterns or templates in speech perception~their activation immediately causing the corresponding phoneme perception!. • Represent some complex invariance~roughly approximated for vowels by the F20F1 ratio, with F2 within a certain range!, specific to each phoneme,
shared by each combination of the levels of acoustic features causing the perception of this phoneme.
• Activated~partially!also by sounds nearly matching with the phoneme-specific invariant codes~the category effect; this effect may also contribute to the correct phoneme perception in the presence of the speaker and context variation!.
• The number limited to the number of the different phonemes the individual can recognize perceptually.
• Their combinations form larger linguistic units such as syllables and words that also serve as recognition patterns~and might in part explain word-context-independent perception!.
• Develop for the mother tongue during the first few months, at least before 12 months of age. • For a foreign language, develop with high informational precision only at an early age. • Development depends on attention at least after infancy.
• Provide reference information for the control of pronunciation.
• May be paralleled by long-duration acoustic traces in auditory cortices of both hemispheres for familiar sounds~serving speaker recognition and discrimination!and by short-duration acoustic traces representing the preceding stimuli~serving stream formation and segregation, and thus speaker recognition as the same as, or different from, the previous speaker@s#in that situation!.
MMN Evidence for the Existence of Neurons Coding Auditory Invariances
As already mentioned, the occurrence of speech-sound recognition and discrimination processes in the auditory cortex implicates the presence of neurons capable of extracting and encoding some com-plex invariance from a large set of acoustically widely varying sounds. Otherwise traces representing this invariance, for example, the phonetic traces, could not be developed.
In this section, I review MMN studies implicating the presence of such higher-order auditory neuronal populations that encode, recognize, and discriminate auditory stimulus patterns contained by acoustically widely varying sound stimulation. In the first of these studies, Saarinen et al.~1992!used tone pairs with an ap-proximately 12% frequency difference between the two members of each pair, and the pair could randomly occur at any of five different frequency levels. The only common property of the stan-dard pairs was the direction of the intrapair change. Thus, when standards were ascending pairs, then deviants were descending pairs, and vice versa. A distinct MMN of low amplitude but long duration was elicited by these direction deviants in subjects read-ing a book. The authors concluded that the memory trace formed by the two members of the standard pairs represented no fixed frequency levels but rather just the direction of the within-pair change, suggesting that the “ascending-pair” and “descending-pair” concepts were formed pre-perceptually at the level of the auditory cortex.
These results were confirmed by Paavilainen et al.~1995!, using 10 different frequency levels instead of the five of Saarinen et al. ~1992!, and by Paavilainen, Jaramillo, and Näätänen~1998!. An analogous MEG result with rising and falling frequency-glide stim-uli was obtained by Pardo and Sams~1993!.
More complex cognitive performance of the central auditory system was also observed by Saarinen et al.~1992!. For instance, the common property of the standard pairs~again randomly oc-curring at the five different frequency levels!was just the occur-rence of an intrapair change as the standard pairs equiprobably were either ascending or descending pairs, whereas the deviant pairs were no-change pairs, the second member sharing the fre-quency level of the first. Although late, small, and prolonged, an MMN was elicited.
Paavilainen et al. ~1995! wished to ensure that the Saarinen et al.~1992!findings indeed indicated cognitive achievements of pre-perceptual auditory processing rather than products of post-perceptual cognitive operations possibly not excluded by the easy reading task. Therefore, they presented the types of stimulus blocks used by Saarinen et al. dichotically to their subjects instructed to press a response key to each deviant tone pair in the designated ear. A significant MMN was nevertheless elicited by the direction-deviant pairs even in the ignored ear, if it was the right ear. The authors concluded that it was the left hemisphere that was the origin of the aspects of the MMN data that could be interpreted in terms of pre-perceptual, sensory-level intelligence.
A new type of abstract-pattern MMN was found by Tervaniemi, Maury, and Näätänen ~1994!. Their standard was a continuous sequence of steadily descending, in reality or seemingly~Shepard tones; Shepard, 1964!, tones by small, semitone steps, whereas the deviant events were either a tone repetition or the ascension of a tone to the preceding frequency level. An MMN was elicited in reading subjects in both conditions, albeit a smaller MMN to rep-etition than to direction change. The authors proposed that on the basis of the trend automatically detected, an extrapolatory trace
was developed, that is, a trace corresponding to the next stimulus as it should occur if the detected trend continued.
Although these results could also be explained without assum-ing an anticipatory sensory-memory function, they nevertheless suggest that the trace system had automatically encoded the stim-ulus trend expressed by the sequence of the consecutive stimuli. Furthermore, the automaticity of the trend-change detection was supported by the fact that for changes in the Shepard-tone se-quences, no parietal positivity, not even a frontocentral P3a, was elicited~whereas P3a was elicited by changes in the sinusoidal-tone sequences!.
Tervaniemi et al.’s~in preparation!recent data, too, indicate the abstract-pattern encoding ability of the neuronal traces underlying MMN generation. Their standard stimulus was a tone pattern formed by five consecutive tones but randomly starting at any of the 12 different frequency levels used, whereas the deviant stimulus was a similar tone pattern with the exception that the fourth tone of the pattern was displaced relative to its position in the standard pattern. The session began with a reading condition in which no MMN was elicited by the pattern deviants. This passive condition was fol-lowed by a discrimination condition in which some subjects learned to discriminate deviant patterns. Most of these subjects were mu-sicians who played their instruments without written music. In the subsequent reading condition, the pattern deviants elicited a dis-tinct MMN only in these subjects. This MMN was further en-hanced in amplitude after a subsequent discrimination condition. In contrast, the remaining subjects~consisting of nonmusicians and of musicians who needed written music to play their instru-ments!did not learn behaviorally to discriminate the deviant tone patterns from the standard tone patterns during the session. Con-sistent with this finding, no MMN was elicited in these subjects by the deviant patterns at any phase of the session.
Consequently, in this study, MMN enabled one to monitor how the learning of a complex abstract sound pattern shared by a num-ber of acoustically varying short stimulus sequences occurred in the brain of a group of subjects in the course of discrimination trials~ensuring that attention was paid to the stimulation!. In these subjects, the neural representation was able to encode the five-tone pattern per se; otherwise, no MMN could have been elicited by deviant patterns in the presence of the wide frequency variation between all five-tone sequences presented. Notice also that al-though attention was needed in learning, or encoding, the ~ ab-stract!pattern, this pattern thereafter served in stimulus processing as a template in the automatic classification of the subsequent stimulus sequences as forming the same pattern~no MMN elicited! or a different pattern~MMN elicited!!~See also Näätänen et al., 1993b!.
These studies on abstract-pattern MMNs, elicited without vio-lating any constant acoustic stimulus aspect, suggest the involve-ment of two types of automatic sensory-memory mechanisms involved in representing abstract sound patterns: The first is non-plastic, short-term, sound-pattern encoding mechanisms, which do not need attention to develop the representation of the abstract sound pattern, enabling MMN to be elicited early in a stimulus block even with no previous~or current!attention to these stimuli but probably showing no~at least major!learning effects~ Paavilai-nen et al., 1995; SaariPaavilai-nen et al., 1992; Tervaniemi et al., 1994!. The second is plastic, long-term, sound-pattern-encoding mechanisms, which need attention to develop the representation of the abstract sound pattern~before which no MMN is elicited! but thereafter automatically serve auditory processing, by providing a long-term template or recognition pattern, at least in some subjects ~