F. Piccoli M. Printista
J.A. Gonzalez C. LeonJ.L.RodaC. Rodrguez F. Sande
UniversidadNacionaldeSanLuis. Cen troSuperiordeInformatica.
EjercitodelosAndes950,SanLuis,Argentina. UniversidaddeLaLaguna,Tenerife,Spain.
e-mail: [email protected]
Abstract
Sincetheearlystagesofparallelcomputing,oneofthemostcommonsolutionstoin
tro-duceparallelismhasbeentoextendasequentiallanguagewithsomesortofparallelversion
oftheforconstruct,commonlydenotedasforallconstruct. Althoughsimilarsyntax,these
forall loopsdierin theirsemantics andimplementations. TheHigh PerformanceFortran
(HPF) andOpenMPversionsare, likely,among themostpopular. This paperpresentsyet
anotherforallloopextensionfortheClanguage.
Inthiswork,weintroduceaparallelcomputationmodel: OneThreadMultipleProcessor
Model(OTMP).Thismodelproposesanabstractmachine,aprogrammingmodelandcost
model. Theprogrammingmodeldenesanotherforallloopconstruct,thetheoricalmachine
aims forbothhomogeneoussharedanddistributed memorycomputers,andthecostmodel
allowsthe prediction of the performance of a program. OTMP does not only integrates
and extends sequential programming, but also includes and expands the messagepassing
programmingmodel. Themodelallowsandexploits anynestedlevelsofparallelism,taking
advantageofsituationswhere thereareseveralsmallnestedloops.
Keywords: Computation Model,AbstractMachine,ProgrammingModel,CostModel.
1 Introduction
Whencompared parallelcomputingwith thatof sequential computing,the currentsituation is
dierent. No single model of parallel computation has yetcome to dominate developments in
parallelcomputingin the waythat vonNeumannmodel has dominatedsequential computing.
The aims of parallel computing model are: to describe classes of architecturesin simple and
realistic terms and, to propose the design methodology of parallel algorithm. It provides an
abstractview of boththetechnologiesand applications. An abstract modeldenes such asthe
algorithmsaredesignedand analyzed intheabstract modeland codedinprogrammingmodel.
The design of parallel programsrequires fancy solutions that are not present in sequential
programming. Thus,adesignerofparallelapplicationsisconcernedwiththeproblemofensuring
thecorrectbehaviorof all theprocesses thattheprogram comprises.
Generally, a programmingmodel describesa programmer's view of the parallel systems. It
has a dierent meaning in other areas of computer science, but in particular, it often stands
for complete semantics of a language. A good parallel programming model has to satisfy the
next properties: Programmability,Reectivity, Cost model, Architecture independence and
exibility[8].
In this paper, wepresent OTMP computation model,its abstract machine and, its
enceswith theircurrent versions.
Thenextsectionpresentsthetheoricalmachine,theprogrammingmodel: syntaxandsemantic,
and the associated complexity model. Section three deals load balancing issues and mapping
andschedulingpoliciesused. Finally,thesectionfourshows manyexamplesandcomputational
results.
2 OTMP Model
One of the most common solutions to introduceparallelism has been to extend a sequential
language with a short set of parallel constructors. Such constructor are a versionof the for
construct, commonly denoted as forall construct. This model proposes another forall loop
extension for the C language. These extensions are aimed both for homogeneous distributed
memoryand sharedmemory architectures.
Thismodelhasseveral dierences withother model[6 ][11 ]. Themost important are:
Theparallelprogrammingmodelintroducedhasassociatedacomplexitymodelthatallows
the analysisand predictionof theperformance.
Itallowsandexploitsanynestedlevelsofparallelism,takingadvantageofsituationswhere
there areseveral smallnestedloops: althougheachloopdoesnotproduceenoughworkto
parallelize,theirunionsuÆces. Therecursivedivideand conqueralgorithmsarethemost
paradigmatic example.
Itdoesnotonlyintegratesandextendsthesequentialprogrammingmodelbutalsoincludes
and expands themessage passingprogrammingmodel.
2.1 Abstract Machine
OTMP theorical computeris a machine composed ofa numberofinnite processors,each one
with its own private memory and a networkinterfaceconnecting them. The processors are
organized ingroups. At any time, the memorystate of all theprocessors inthe same group is
identical. An OTMP computation assumes that they also havethe same input data and the
same program in memory. The initial group is composed of all the processors in the machine.
Each processor is a RAM machine [1], the only dierence among them is an internalregister,
theNAME oftheprocessor. Thisregisterisnotavailabletotheprogrammer.Accordingtothis
denition,every real parallelmachineis aOTMP machine.
2.2 Syntax and Semantic
Theprogramming model being introduced, extends the classicsequential imperative paradigm
witha newconstruct: parallelloops. The modelaims forbothdistributedand sharedmemory
architectures.The implementationon thelastcan be consideredthe\easypart" ofthe task.
The programmer withtheparallelloops
forall(i=rst;i<=last;(r[i],s[i]))
compound_statement_i
states that the dierent iterations i of the loop can be performed independently in parallel.
(r[i],s[i])isthememoryareaoftheresultsofthei-thiteration,wherer[i]pointstorstpositions
ands[i] is thesizeinbytes.
Whenreachingtheformerforall loop,eachprocessordecidesintermsofits NAME the
anyprocessorNAME rulingthedivisionprocess are:
Numberofiterationstodo: M=l ast first+1 (1)
Iterationtodo: i=first+NAME%M (2)
for(j=1;j<M;j++)
neighbor[j]=+(NAME+j)%M (3)
whereisgivenby:=M(NAME=M)
Newvalueofregister: NAME=NAME=M (4)
These equations decide the mapping of processors to tasks, and howthe exchangeof results
willtake place. After theforallis nished,the processorsrecovertheirformervalueof NAME.
Each time a forall loop is executed, the memory of the group, up to that point contains
exactly the same values. At suchpoint the memory is divided in twoparts: the one that is
going to be modied and theone that isnot changedinside the loop. Variables inthe lastset
area vailableinside theloop forreading.The othersarepartitioned among thenew groups.
Thelastparameterintheforall hasthepurposeto informthenew\ownership"of thepart
of the memory that is going to be modied. It announces that the group performingthread i
\owns"(and presumablyisgoing to modify)the memoryareas delimitedby (r[i];s[i]). r[i]+j
isa pointerto thememoryarea containingthe j-th resultof thei-th thread.
Toguarantee thatafter returningto the previousgroup,the processors inthe father group
haveaconsistentviewofthememoryandthattheywillbehaveasthesamethread,itisnecessary
to providethe exchangeamong neighbors of the variablesthat w eremodied inside the forall
loop. Let us denote the execution of the body of the i-th thread (compound statementi) by
T
i
. The semanticimposes two restrictions:
1. Given two dierentindependentthreadsT
i and T
k
and two dierent result itemsr[i] and
r[k],it holds:
[r[i];s[i]] T
[r[k];s[k]]=;8i;k
2. Foranythread T
i
and any result j, all the memoryspace dened by[r[i]+j;s[i]] hasto
be allocated previously to the execution of the thread body. This makes impossiblethe
use ofnon-contiguous dynamicmemorystructures.
The programmer has to be speciallyconscious of the rst restriction: it is mandatory that
theaddress of an ymemory cellwritten during theexecution of T
i
has to belong to one of the
intervals in the list of results for the thread. As an example, consider the code in gure 1.
1 forall(i=1; i<=3; (ri[i], si[i]))
2 f ... 3 forall(j=0; j<=i; (rj[j], sj[j]))f 4 int a, b; 5 ... 6 if (i % 2 == 1) 7 if (j % 2 == 0) 8 send(j+1, a, sizeof(int));
9 else receive(j-1, b, sizeof(int));
10 ...
11 g
12 ...
13 g
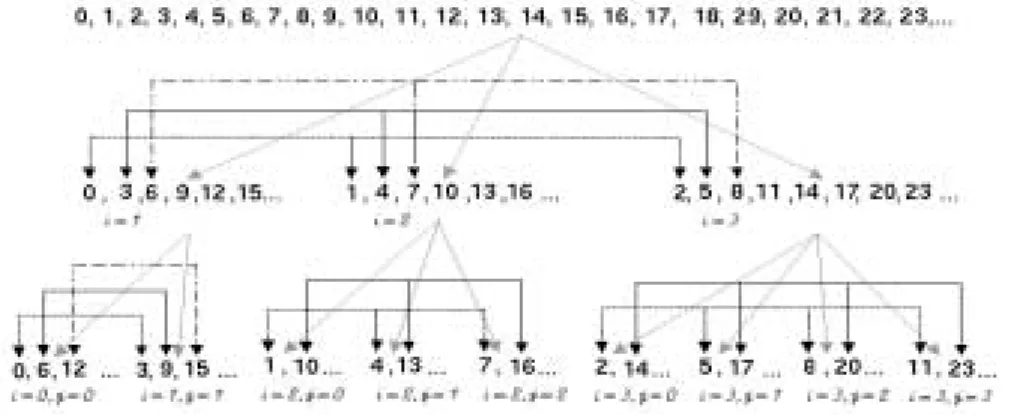
Figure 1: Two nestedforalls
theirlocalmemory. Applyingequations1,2,3and4,theparallelloopinline1ofgure1divides
thegroup inthree. After theexecution of the loop, and to keep thecoherence of the memory,
eachprocessorexchangeswithitstwoneighborsthecorrespondingresults. Thus,processor0in
thegroup executes iteration i=1 and sends its memory area, (ri[1],si[1]) to processors 1 and
2. Furthermore, itreceivesfromprocessor1 (ri[2],si[2]) andfromprocessor2(ri[3], si[3]). The
sameexchangeisrepeatedamongtheother correspondingtriplets( (3;4;5);(6;7;8);:::) . Every
new nested forall creates/structures the current subgroup according as a M-ary hypercube,
whereM isthenumberofiterationsintheparallelloopand theneighborhoodrelationis given
byformula3. Thus,thisrstforallproduces\theface"ofaternaryhypercubicdimension,where
everycornerhastwoneighbors. Thesecond nestedforall atline3requestsfordierent number
Figure 2: The mappingassociatedwiththetwo nestedforallingure 1
of threads inthe dierent groups. Forexamples, to thelast group (i=3) executes a forallof
size4,and consequentlythegroup ispartitioned in4 subgroups. In this4-arydimension, each
processor is connected with 3 neighbors in the other subgroups. Therefore, at the end of the
nestedcompoundstatement, processor 17 willsend its data, rj[1], to processors 14, 20 and 23
andwillreceive from them theirdatarj[0], rj[2] and rj[3].
2.3 Others Clauses
TheOTMP modeladmitsseveral coherentextensions,inthissectionwepresent tw o:reduction
clausesand globalcommunication.
The reduction clauses havesyntax and semantic similar to the aboveforall, its simplied
syntax is
forall R(i=rst;i<=last;(r[i],s[i]);fr[i];(rr[i],sr[i]))
f
compound_statement_i;
fr;
g
The forallR works of the same waythat forall, divides the processors, executes in parallel
compound statement i overowns data and exchangesthe results, r. When all is done, each
processorreducestheresultsthroughf r. The resultof f r isrr and ithassizesr. Thef r can
be any function,butit ismandatorythat ithasto be commutativeand associative.
OtherOTMPclauses aretheglobalcommunicationclauses: r esult and r esultP.Their
ery processors in theother groups, and r esultP communicates data to every processors inthe
other groups, but the data are dierent and depend of the receptor processor's group. The
corresponding syntax is
result(i,data[i],s[i])
result P(i,data to[i],sto[i],data from[i], s from[i])
whereiidenties thetask,T
i
. In therst clauses,data[i] pointsto thedataof T
i
ands[i] is its
size. In the second clauses, datato[i] is a pointer to the memory area containing the data to
sendto T
i
,ands to[i]containsitssize. datafrom[i]ands from[i]havethesamefunction,but
to received data of T
i
. These clauses are similarto functions gather and scatter in standards
librarysuchasMPI[10 ],butoneofdierencesistheneighborhoodrelation,ittakesplaceevery
thattheexchangingofdata isnecessary.
2.4 Cost Model
In this section, w eanalyze the cost of the forall loop. A similar analysis is required to other
clauses.
ThecomplexityT(P)ofanyOTMP programP canbecomputedinwhatrefertosequential
ordinaryconstructs(while, for, if,... ) asintheRAMmachine[1 ]. Thecost oftheforallloop
isgiven by therecursive formula:
T(forall)=A 0 +A 1 M+ e 2 max i=e 1 ( T(T i ))+ e2 X i=e 1 (gN i )+L (5) whereT i
isthecodeofcompound statement i,M isthesizeoftheloopandN
i
isthesizeofthe
messagetransferred initerationi,
M =(e 2 e 1 +1) N i = P m k=1 s ki A 0
istheconstant timeinvestedcomputingformulas1,2and4. A
1
isthetimespentndingthe
neighbors(formula3). Constantgistheinverseof thebandwidth,andListhestartuplatency.
Assuming the rather common case in which the volumeof communicationof eachiteration is
roughlythesame
N N i N j 8i6=j =e 1 ;e 2
Fromformula 5 and from the fact that in current machines the schedulingand mapping time
A
0 +A
1
M isdominatedbythecommunicationtime P e 2 i=e1 (gN i
+L),itfollows theresult
thatestablisheswhen an independentfor loop isworthto convert inaforall:
T(forall)T(for),M (gN)+L+ e2 max i=e1 T(T i ) e2 X i=e1 T(T i ) (6)
AremarkablefactisthattheOTMP machinenotonlygeneralizesthesequentialRAMbutalso
theMessage PassingProgramming Model. Lines 6-8 ingure 1 illustrate the idea. Each new
forall \creates"acommunicator(intheMPIsense). Theexecutionoflines7and8inthefourth
group(i=3)impliesthat thread j=0sendsato thread j=1. Thisoperation carriesthat, at the
same timethat processor2 sends its replicaof ato processor 5,processor14 sends its copyto
processor 17 and so on. To summarize: anysendor receive is executed bythe innite couples
involved.Still,thetwoaforementionedconstraintshavetobetrue.Anyvariablemodiedinside
Unfortunately, an innite machine, suchas that described in the previous section, is only an
idealization. Real machines ha vea restricted number of processors. Each processor has an
internal register NUMPROCESSORS where stores the number of availableprocessors in its
current group. Three dierent situations have to be considered in the execution of a forall
constructwith M =e 2 e 1 +1threads: NUMPROCESSORSisequalto1;
M islargerorequalthanNUMPROCESSORS;
NUMPROCESSORSislargerthanM;
The rst case is trivial. Thereis only one processor that executes all the threads sequentially,
andthere is notopportunityto exploitanyintrinsicparallelism.
The second case has been extensively studied as at parallelism. The main problem that
arises is the load balancing problem. Todeal with it, several scheduling policies havebeen
proposed[11 ]. Manyassignmentpoliciesarealsopossible: block,cyclic-block,guided ordynamic.
Thethirdcasewasstudiedintheprevioussection. Butthefactthatthenumberofavailable
processorsislargerthanthenumberofthreadsintroducesseveraladditionalproblems: therst
isload balancing. The secondis that, notanymore,the groupsare dividedinsubgroupsof the
samesize.
If a measure of the workw
i
per thread T
i
is available,the processors distribution policy
viewed in the previous section can be modied to guarantee an optimal mapping [3 ]. The
syntax of theforall isrevisitedto include thisfeature:
forall(i=rst; i<=last; w[i]; (r[i], s[i]))
compound_statement_i
If there are not weights specication, the same w orkload is assumed for every task. The
semanticis similarto thatproposedin[2 ]. Therefore,themapping iscomputed according to a
policysimilartothatsketchedin[3 ].Thegure3showstheappliedmappingalgorithm. There
is, however, the additional problem of establishing the neighborhood relation. This time the
simpleone to (M 1) hypercubicrelationoftheformersection doesnothold. Instead,the
hypercubic shapeis distorted to a polytope holding the property that each processor in every
grouphasone and onlyone incomingneighborinanyof theother groups.
1 for(i = 0; i< M; i++)
2 p_i = 1; 3 for( j = M+1 ; j< NUMPROCESSORS; j++) 4 f 5 Get p_k such as wk pk maxi= 2;:::; M wi pi ; 6 p_k= p_k + 1; 7 g
Figure3: Optimal Mapping Algorithm
Thisalgorithm satiseswith thepostulate of optimalmapping.
4 Examples
Many examples havebeen chosento illustrate the use of the OTMP model: Matrix
Multipli-cation,Fast FourierTransform, QuickSortand ParallelSort byRegular Sampling. The results
arepresented forseveral machinesand we usethecurrentsoftware systemthat consistsof a C
Theproblemtosolveistocomputetasksmatrixmultiplications(C i =A i B i i=0;:::tasks 1). Matrix A i and B i haverespectivelydimensionsmq i and q i
m. Therefore, the product
A i
B i
takesanumberofoperationsw[i] proportionaltom 2
q
i
. Figure4showsthealgorithm.
VariablesA,B and C arearrays of pointers to thematrices. The loop inline 1deals withthe
dierent matrices, the loops in lines 5 and 7 traversethe rows and columns and nally, the
innermost loop in line 8 produces the dot product of the current rowand column. Although
allthe for loopsarecandidates to beconvertedto forall loops, we willfocuson twocases: the
parallelizationofonlytheloopinline5(labeledFLATintheresults,gure5)andtheoneshown
ingure4 whereadditionally,theloopat line1is also converted to aforall (labelNESTEDin
gure5). Thisexample illustratesone of the common situationwhere you can take advantage
1 forall(i = 0; i < tasks; w[i]; (C[i], m * m))
2 f
3 q = ...;
4 Ci = C+i; Ai = A+i; Bi = B+i;
5 forall(h = 0; h < m; (Ci[h], m)) 6 f 7 for(j = 0; j < m; j++) 8 for(r = &Ci[h][j], *r=0.0, k=0; k<q; k++) 9 *r += Ai[h][k] * Bi[k][j] 10 g 11 g
Figure 4: Exploiting2levels of parallelism
of nested parallelism: when neither the inner loop (lines 5-10) nor the external loop (line 1)
haveenough w orkto havea satisfactory speedup, but the combination of both does. We will
denote bySP
R
(A) the speedup of an algorithm A with R processors and byT
P
(A) the time
spentexecutingalgorithmAonP processors. Letusalsosimplifytothecasewhenalltheinner
tasks takethe same time, i.e. q
i
=m. Under thisassumptions, the previousstatement can be
rewrittenmore precisely:
Lemma1 Letbe tasks<P, SP P (inner)<SP P=tasks
(inner) and tasks(gm 2 )+LT P=tasks (inner) then SP P (FLAT)<SP P (NESTED)
Thegure5showstheexpressedbeforeforthisexample. Bothmatrixhave dimensions4545.
Thenumberof taskis 8,and to when thenumberof processors is 2 and 4,there are processor
virtualization. In allcase and to dierentarchitectures, thenestedparallelismworkswell.
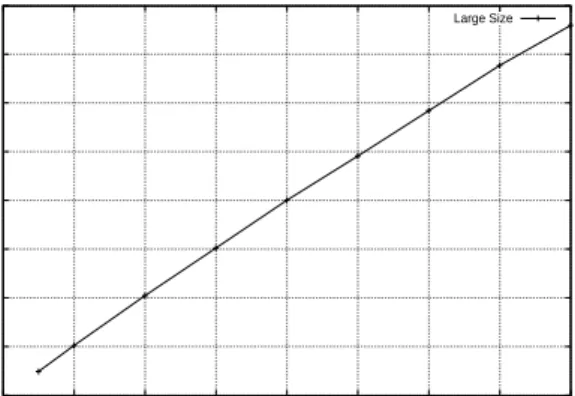
Moreover, when the size of the problems to solveis large, the speedup grows to be
quasi-lineal. We check that the speedup reached is linear asit showsgure 6. In thenext examples
wewillconcentrateinthemore interestingcasewherethenestedloopsaresmalland,according
to thecomplexityanalysis,there arefew opportunitiesforparallelization.
4.2 Fast FourierTransform
The Discrete Fouriertransform is widely used insolving problems in science and engineering.
Itis denedas A(j)= 1 N N 1 X k =0 a(k)e 2ik j=N (7)
0.003
0.004
0.005
0.006
0.007
0.008
0.009
0.01
0
2
4
6
8
10
12
14
16
Time (secs.)
No. of processors
Matrix N=46 Tasks=4 Cray T3E
FLAT
NESTED
(a)Cra yT3E
2
3
4
5
6
7
8
0.4
0.5
0.6
0.7
0.8
0.9
1.0
NP
Time
Flat
Nested
(b)Origin2000Figure5: Nested versusFlatparallelism
0
2
4
6
8
10
12
14
16
0
2
4
6
8
10
12
14
16
Speedup
No. of processors
Matrix N=500 Tasks=4 Cray T3E
Large Size
Figure6: Speedupreached forlargesizeproblems
TheOTMPcodeingure7implementstheFastFourierTransform(FFT)algorithmdeveloped
byTukeyandCooley[4]. ParameterW
k =e
2ik=N
containsthepowersoftheN-throot ofthe
unity.
Thegure8 showsthecomputationalresultsforsuchimplementationonaSGIOrigin2000
andCRAY T3E.Thespeedupcurve behavesaccordingtowhatacomplexityanalysisfollowing
formula 5 predicts. Moreover, when thesizeof problem issmall, thecommunications inuence
ontheperformance.
4.3 QuickSort
The well-known quicksort algorithm [5 ] is a divide-and-conquer sorting method. As such,it
is amenable to a nested parallel implementation. This example is specially interesting,since
the size of the generated sub-vectors are used as weights for the forall, see gure 9, line 14.
Rememberthat,dependingonthegoodnessofthepivotchosen,thenewsubproblemsmayhave
ratherdierentweights.
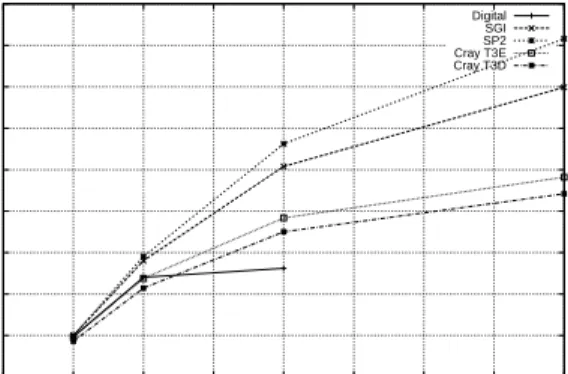
Figure 10presentsthespeed-upson adigitalAlpha Server, anOrigin2000, an IBM SP2,a
unsigned N,unsigned stride,Complex *D)f 2 Complex *B, *C, Aux, *pW; 3 unsigned i, n; 4 5 if(N == 1) f 6 A[0].re = a[0].re; 7 A[0].im = a[0].im; 8 g 9 else f 10 n = (N >> 1); 11 forall(i = 0; i <= 1;(D+i*n , n)) 12 f
13 llcFFT(D+i*n,a+i*stride,W ,n, stri de< <1,A +i* n);
14 g
15 B = D; /* Combination phase */
16 C = D + n;
17 for(i = 0,pW = W; i<n; i++,pW += stride) f
18 Aux.re = pW->re*C[i].re - pW->im*C[i].im;
19 Aux.im = pW->re*C[i].im + pW->im*C[i].re;
20 A[i].re = B[i].re + Aux.re;
21 A[i].im = B[i].im + Aux.im;
22 A[i+n].re = B[i].re - Aux.re;
23 A[i+n].im = B[i].im - Aux.im;
22 g
25 g
26 g
Figure 7: TheOTMP implementationof theFFT
1.5
2
2.5
3
3.5
4
4.5
5
5.5
6
6.5
0
5
10
15
20
25
30
35
Speed-up
Processors
64 Kb
256 Kb
1024 Kb
(a)Cra yT3E
2
3
4
5
6
7
8
1.5
2.0
2.5
3.0
3.5
4.0
NP
Speedup
64
512
1024
(b)Origin2000Figure 8: FFT.Dierent sizes.
4.4 Parallel Sorting byRegular Sampling
Parallel Sorting by RegularSampling(PSR S) isan parallelsortingalgorithmproposedbyLiet
all[9].It is an example of simpleand synchronousalgorithm, and hasbeen shown eective for
awidevarietyof MIMDarchitecture.
PSRS workswith p process and assumes that the input list has n unsorting elements. It
arisesinfour synchronous phases:
Phase 1
Eachofthepprocessorsusesthesequentialquicksortalgorithmtosortalocald n
p
eelements.
2 int w[2]; /* weight vector */
3 int posf[2],pos l[2]; /* first and last of each partition*/
4 int pivot, i, j;
5
6 select(v, first, last, *pivot);
7 i=first; j=last;
8 partition(v, &i, &j, pivot);
9 /* setting each subproblems and weight vector*/
10 w[0]=(j-first+1); w[1]=(last-i+1);
11 posf[0]=first; posf[1]=i;
12 posl[0]=j; posl[1]=last;
13
14 forall(i=0; i<=1; w[i]; (v+posf[i],w[i]*sizeof(int)))
15 qs(v, pos[i],posl[i]);
16 g
Figure 9: The OTMP implementationmainof QuickSort
1
1.5
2
2.5
3
3.5
4
4.5
5
5.5
0
2
4
6
8
10
12
14
16
Speed-up
No. of processors
Matrix N=46 Tasks=4 Cray T3E
Digital
SGI
SP2
Cray T3E
Cray T3D
Figure 10: QuickSort. Sizeof thevector: 1M
data, a sortedlist asregularsample.
Phase 2
One processorgathersand sorts every local samples. Finally,itselects p 1 piv otsvalue
from listof regularsamples. At thispoint,each processors knows thenalpivotslist and
partitionsitssorteddataintopdisjointpieces, thepivotvaluesaretheseparatorsbetween
the pieces.
Phase 3
Each processorikeeps itsith partitionandassignsthejth partitionto processorj. Each
processorkeeps one partitionand reassignsp 1other partitions to other processors.
Phase 4
Each processor merges its p partition into a single list. The concatenation of every
pro-cessor's listsobtainsthenal sortedlistwith nelements.
OTMP algorithm to PSR S is shown in gure 11. Tosolvethe problem, it uses the global
communication constructors, line 14 and 23. This algorithm is dierent to original propose,
everyprocesses haveeverysamples and don't need extra communications to know the nal
pivots.
Thequicksortinline17can bereplaced byamergeofNUMPR OCESSOR S sortedlistof
2 int j, k;
3 int *Samples, samplest; /*Samples vector and stride in v to obtain samples*/
4 int *Pivots, pivotst; /*Pivots vector and stride in Samples to obtain pivots*/
5 int *totask; /*First list to each process*/
6 int *resotask, *from size; /*List of received data from other process and its size*/
7
8 int vLocal; /*Data list of local process*/
9
10 /* ================== Phase 1 =================*/
11 quicksort(v, size);
12 for ((k=0,j=i*NTASK); k<NTASK; (k+=samplest,j++))
13 Samples[j]= v[k]; 14 result(i,Samples+(i*NTASK), NTASK*sizeof(int)); 15 16 /* ================== Phase 2 ================*/ 17 quicksort(Samples, NTASK*NTASK); 18 for(k=0,j=1;j<=(NTASK- 1);k ++, j++)
19 Pivots[k]=Samples[(j*N TAS K + pivotst)-1];
20 dividelist(v, Pivots, totask);
21
22 /* ================== Phase 3 ================*/
23 resultP(i,v,to_task,resotask,fromsize);
24
25 /* ================== Phase 4 ===============*/
26 V= mergelist(vLocal, resotask, fromsize, sizeV);
27 g
Figure 11: TheOTMP implementationof thePSRS
The gure 12 showsthe main function. The problem is solved byNUMPR OCESSOR S
tasks. Each task worksin parallel over
SIZE
NUMPROCESSORS
data. V is the output vector,it is
sorted. After the forall not is necessary anycommunications, everyprocesses havethe total
sortedvector.
1 void main(argc, argv)f
2 int i, size, new_size;
3 int *v, *V; 4 5 size= SIZE/NUMPROCESSORS; 6 v = calloc(size, sizeof(int)); 7 V = calloc(SIZE, sizeof(int)); 8 9 initialize(v, size);
10 forall(i=0; i<=NUMPROCESSORS-1; (V[i],newsize[i]))
11 PSRS(i,v,size[i],(V[i]), &(ne wsize[i]))
12 g
Figure 12: The OTMP mainfunctionofPSRS
The OTMP PSR S is an algorithm easy to understand and follow. The computational
resultsarenotreported because we aretakingand analyzingtheir.
5 Conclusions and Future Work
OTMPis acomputationmodeloers: simplicity,easinessofprogramming,improvement ofthe
performance (does not introduceanyoverheadforthe sequential case), portability,and a cost
modelassociated. Inadditionto thesecharacteristics,themodelextendnotonlythesequential
butthe MPIprogrammingmodel.
predictionof performance. The other isthat it allows exploits any nestedlevels of parallelism,
taking advantage of situations where there are several small nested loops: although eachloop
doesnotproduceenoughworktoparallelize,theirunionsuÆces. Perhapsthemostparadigmatic
exampleofsuchfamilyof algorithmsarerecursivedivideand conqueralgorithms.
We havea prototype for the model. Many issues can be optimized. Even incorporating
these improvements, the gains for distributed memory machines will never be equivalent to
whatcanbeobtainedusingrawMPI.Resultsobtainedprovethefeasibilityofexploitingnested
parallelismwiththe model. How ever,thecombination ofevery its propertiesmakes worth the
research and development oftools orientedto thismodel.
Acknowledgments
WewishtothanktheUniversidadNacionaldeSanLuisandtheANPCYTfromwhichwereceive
continuous support. Alsoto theeuropean centers: EPCC,CIEMAT, CEPBAand CESCA.
References
[1] Aho, A. V.Hopcroft J. E. and UllmanJ. D.: The Design and Analysis of Computer
Algo-rithms, Addison-Wesley,Reading,Massachusetts,(1974).
[2] Ayguade E., Martorell X., Labarta J, Gonzalez M. and Navarro N. Exploiting Multiple
Levelsof ParallelisminOpenMP:ACaseStudy Proc.of the1999 InternationalConference
on Parallel Processing,Aizu (Japan),September1999.
[3] BlikbergR., SrevikT..Nested parallelism: Allocationof processors to tasksand OpenMP
implementation. Proceedings of The Second European Workshop on OpenMP (EWOMP
2000). Edinburgh,Scotland, UK.(2000).
[4] Cooley,J.W.andTukey,J.W.: AnalgorithmforthemachinecalculationofcomplexFourier
series,Mathematics of Computation,19, 90, (1965)297{301.
[5] Hoare,C. A.R.: Quicksort,ComputerJournal,5(1), (1962) 10{15.
[6] HPF Forum: HPF Language Specication. Version 2.0
http://dacnet.rice.edu/Depts/CRPC/HPFF/versions/hpf2/hpf-v20/index.html(1997)
[7] Keller, J. Kesler, C. Larsson, J.. Practical PRAM programming. John Wiley & Sons inc.
(2001)
[8] Leopold, C. Paralleland Distributed Computing: A survey of models, paradigms, and
ap-proaches.John Wiley&Sonsinc.(2001)
[9] Li, X. Lu, P.Schaeer,J. Shillington, J. Wong, P.Shi, H.. On the Versatilityof Parallel
Sorting byRegular Sampling. Tech. Report TR 91-06. Universityof Alberta, Edmonton,
Alberta,Canada.(1992)
[10] MPI Forum: MPI-2: Extensions to the Message-Passing Interface, h
ttp://www.mpi-forum.org/docs/mpi-20.ps.Z(1997).
[11] OpenMP Architecture Review Board: OpenMP Specications: FORTRAN 2.0.
http://www.openmp.org/specs/