Target Deduplication Metrics and Risk Analysis Using
Post Processing Methods
Gayathri.R1,1Dr. Malathi.A2 1Assistant Professor,2Assistant Professor
1School of IT and Science,2PG and Research Department of Computer Science
,1Dr. G.R.D. College of Science,2Government Arts College
1Coimbatore - 641 014,2Coimbatore, India
1[email protected],2[email protected]
Abstract
In modern intelligent storage technologies deduplication of data is a data compression technique used for discarding duplicate copies of repeating data. It is used to improve storage utilization and applied to huge network data transfers to reduce the number of bytes which is to be transferred. In this process, similar data chunks, patterned bytes, are classified and stored at this stage. As a parallel process to the analysis process the rest of the data chunks are analyzed to the already available stored data and whenever a similarity in data is identified, the surplus chunk is replaced with minor changes that denote the already available stored data chunk. This process is repeated for n number of times .which discards the duplicate entry. Target deduplication is the process of removing duplicates of data in the secondary store. Generally this will be a backup store such as a data repository or a Virtual Space. In this paper post processing in Target Data is implemented and compared with the multiple
data collected from different data centers with duration of 50 Days and analyzed for its efficiency & throughput of the global & local data using post processing in Target Data.Keywords:[post processing in Target Data, Target Deduplication, Post Processing Deduplication Methods]
1. INTRODUCTION
The implementation approaches of Target deduplication system divide into several modes including post-process approach, In-line approach and source-based approach. In today’s world most commercial systems are implemented and operated in an ILA and PPA approach, and a very few researchers focus on other approaches As data deduplication systems are widely used, to choose an appropriate mode considering operation environment becomes more and more important than ever. Because the overhead of each mode and resource usage wasn’t fully studied, in some operating environments, the deduplication mode can lead to inefficiency and poor performance. In this study, we propose a data deduplication system supporting multi-mode.
Due to the relatively low bandwidth of WAN (Wide Area Network) that supports cloud backup services, both the backup time and restore time in the cloud backup environment are in desperate need for reduction to make cloud backup a practical and affordable service for small businesses and telecommuters alike. Existing solutions that employ the deduplication technology for cloud backup services only focus on removing redundant data from transmission during backup operations to reduce the backup time, while paying little attention to the restore time that we argue is an important aspect and affects the overall quality of service of the cloud backup services.
As the volume of data increases, so does the demand for online storage services, from simple backup services to cloud storage infrastructures. Although deduplication is most effective when applied across multiple users, cross-user deduplication has serious privacy implications. Some simple mechanisms can enable cross-user deduplication while greatly reducing the risk of data leakage. Cloud storage refers to scalable and elastic storage capabilities delivered as a service using Internet technologies with elastic provisioning and use based pricing that doesn't penalize users for changing their storage consumption without notice.
Figure 1: Post processing in Deduplication
In this paper post processing in Target Data is implemented and compared with the multiple data collected from different data centers with duration of 50 Days and analyzed for its efficiency & throughput of the global &
local data using post processing in Target Data. These techniques enable a modern two-socket dual-core system to run at full CPU utilization with needed disks and achieve 100 MB/sec for single-stream throughput and 210 MB/sec for multi-stream throughput. to make the experiment of Target based post processing into an effective Task.
2. ANALYSIS IN DATA CENTERS
Large storage requirements for data protection have existing a serious problem for data centric companies. Most data centers perform a weekly full backup of all the data on their primary storage systems to secondary storage devices where they keep these backups for weeks to months. In addition, they may perform daily incremental backups that copy only the data which has changed since the last backup. The frequency, type and retention of backups vary for different kinds of data, but it is common for the secondary storage to hold 10 to 20 times more data than the primary storage. For disaster recovery, additional offsite copies may double the secondary storage capacity needed. If the data is transferred offsite over a wide area network, the network bandwidth requirement can be enormous. Given the data protection use case, there are two main requirements for a secondary storage system storing backup data.The first is low cost so that storing backups and moving copies offsite does not end up costing significantly more than storing the primary data. The second is high performance so that backups can complete in a timely fashion. In many cases, backups must complete overnight so the load of performing backups does not interfere with normal daytime usage. The traditional solution has been to use tape libraries as secondary storage devices and to transfer physical tapes for disaster recovery. Tape cartridges cost a small fraction of disk storage systems and they have
good sequential transfer rates in the neighborhood of 100 MB/sec. But, managing cartridges is a manual process that is expensive and error prone. It is quite common for restores to fail because a tape cartridge cannot be located or has been damaged during handling. Further, random access performance, needed for data restores, is extremely poor. Disk-based storage systems and network replication would be much preferred if they were affordable.
2.1 Challenges and Observations
An Identical Segment for post processing in Target Data Deduplication system could choose to use either fixed length segments or variable length segments created in a content dependent manner. Fixed length segments are the same as the fixed-size blocks of many non-deduplication file systems. For the purposes of this discussion, extents that are multiples of some underlying fixed size unit such as a disk sector are the same as fixed-size blocks.Variable-length segments can be any number of bytes in length within some range. They are the result of partitioning a file or data stream in a content dependent manner [Man93, BDH94].
The main advantage of a post processing in Target Data fixed segment size is simplicity. A conventional file system can create fixed-size blocks in the usual way and a deduplication process can then be applied to deduplicate those fixed-size blocks or segments. The approach is effective at deduplicating whole files that are identical because every block of identical files will of course be identical.
In backup applications, single files are backup images that are made up of large numbers of component files. These files are rarely entirely
identical even when they are successive backups of the same file system. A single addition, deletion, or change of any component file can easily shift the remaining image content. Even if no other file has changed, the shift would cause each fixed sized segment to be different than it was last time, containing some bytes from one neighbor and giving up some bytes to its other neighbor. The approach of partitioning the data into variable length segments based on content allows a segment to grow or shrink as needed so the remaining segments can be identical to previously stored segments.
Even for storing individual files, variable length segments have an advantage. Many files are very similar to, but not identical to other versions of the same file. Variable length segments can accommodate these differences and maximize the number of identical segments.
Because variable length segments are essential for deduplication of the shifted content of backup images, we have chosen them over fixed-length segments.
2.2 Segment Analysis:
Whether fixed or variable sized, the choice of average segment size is difficult because of its impact on compression and performance. The smaller the segments, the more duplicate segments there will be. Put another way, if there is a small modification to a file, the smaller the segment, the smaller the new data that must be stored and the more of the file’s bytes will be in duplicate segments. Within limits, smaller segments will result in a better compression ratio.
On the other hand, with smaller segments, there are more segments to process which reduces performance. At a minimum, more segments mean more times through the
deduplication loop, but it is also likely to mean more on-disk index lookups.
With smaller segments, there are more segments to manage. Since each segment requires the same metadata size, smaller segments will require more storage footprint for their metadata, and the segment fingerprints for fewer total user bytes can be cached in a given amount of memory. The segment index is larger. There are more updates to the index. To the extent that any data structures scale with the number of segments, they will limit the overall capacity of the system. Since commodity servers typically have a hard limit on the amount of physical memory in a system, the decision on the segment size can greatly affect the cost of the system.
A well-designed duplication storage system should have the smallest segment size possible given the throughput and capacity requirements for the product. After several iterative design processes, we have chosen to use 8 KB as the average segment size for the variable sized data segments in our deduplication storage system.
2.3 Segmentation Process Steps:
Segment filtering determines if a segmentis a duplicate. This is the key operation to deduplication segments and may trigger disk I/Os, thus its overhead can significantly impact throughput performance.
Container packing adds segments to be stored to a container which is the unit of storage in the system. The packing operation also compresses segment data using a variation algorithm. A container, when fully packed, is appended to the Container Manager.
Segment Indexing updates the segment index that maps segment descriptors to the container holding the segment, after the container has been appended to the Container Manager.
Segment lookup finds the container storing the requested segment. This operation may trigger disk I/Os to look in the on-disk index, thus it is throughput sensitive. Container retrieval reads the relevant
portion of the indicated container by invoking the Container Manager.
Container unpacking decompresses the retrieved portion of the container and returns the requested data segment.
3. PERFORMANCE & CAPACITY
ANALYSIS
A secondary storage system used for data protection must support a reasonable balance between capacity and performance. Since backups must complete within a fixed backup window time, a system with a given performance can only backup so much data within the backup window. Further, given a fixed retention period for the data being backed up, the storage system needs only so much capacity to retain the backups that can complete within the backup window. Conversely, given a particular storage capacity, backup policy, and deduplication efficiency, it is possible to compute the throughput that the system must sustain to justify the capacity. This balance between performance and capacity motivates the need to achieve good system performance with only a small number of disk drives.
Assuming a backup policy of weekly fulls and daily incremental with a retention period of 15 weeks and a system that achieves a 20x compression ratio storing backups for such a
policy, as a rough rule of thumb, it requires approximately as much capacity as the primary data to store all the backup images. That is, for 1 TB of primary data, the deduplication secondary storage would consume approximately 1 TB of physical capacity to store the 15 weeks of backups.
3.1 Experimental Setup:
The experimental setup was made very clear in defining how better deduplication storage system work with real world datasets using post processing in Target Data, also about the effectiveness of the techniques in terms of reducing disk I/O operations and in the throughput can a deduplication storage system using these techniques achieve. These three are taken as a primary metrics (Betterment, Efficiency & Throughput)
For the first metrics of post processing in Target Data , we will report our results with real world data from two customer data centers. For the next two questions, we conducted experiments with several internal datasets. Our experiments use a Data Domain deduplication storage system server. This deduplication system features two-socket duel-core CPU’s running at 2.4 Ghz, a total of 6 GB system memory, 2 gigabit NIC cards, and a 15-drive disk subsystem running software. We use 1 and 4 backup client computers running in servers
3.2 Real World Data Analysis
The system described in this paper has been used at over 100 data centres. The following paragraphs report the deduplication results from two data centres, generated from the auto-support mechanism of the system.
Data center A backs up structured database data over the course of 50 days during the initial deployment of a deduplication system. The backup policy is to do daily full backups, where each full backup produces over 200 GB at steady state. There are two exceptions:
Capacity in
GB Days VOLUMEDATA
0 0 0 1000 10 0 2000 20 2000 3000 30 2000 4000 40 5000 5000 50 5000 Average capacity :3000 Total No of Days :50 Total Data Volume=14000
Table:1-Days Capacity & Data Volume Data
During the First phase different post processing in Target Data data or different types of data are rolled into the backup set, as backup administrators figure out how they want to use the deduplication system. A low rate of duplicate segment identification and elimination is typically associated with the seeding phase.
There are few days where no backup is generated.
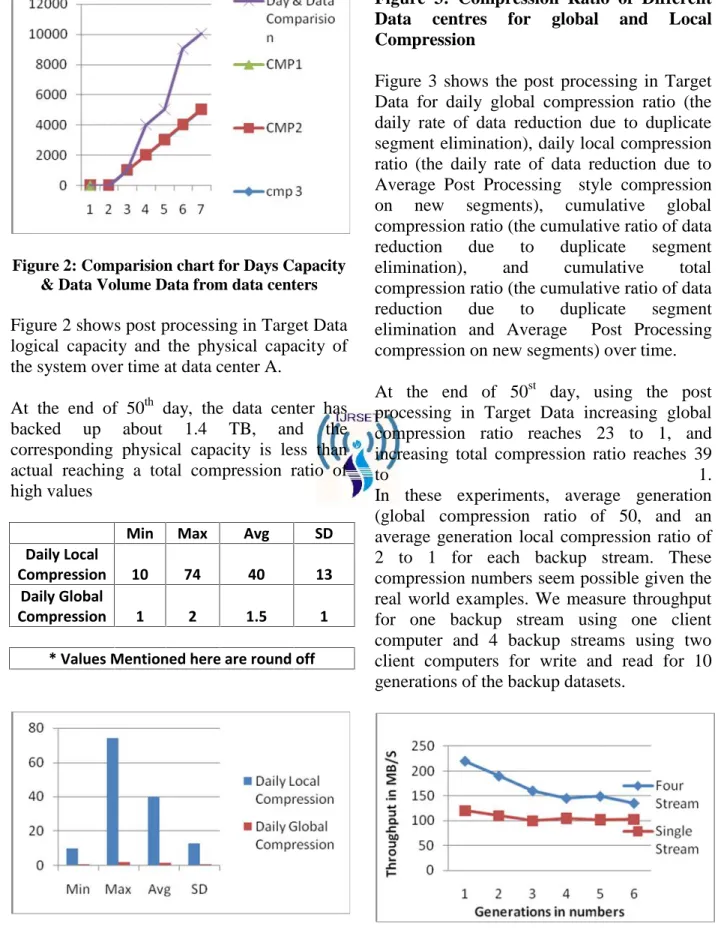
Figure 2: Comparision chart for Days Capacity & Data Volume Data from data centers
Figure 2 shows post processing in Target Data logical capacity and the physical capacity of the system over time at data center A.
At the end of 50th day, the data center has backed up about 1.4 TB, and the corresponding physical capacity is less than actual reaching a total compression ratio of high values
Min Max Avg SD
Daily Local
Compression 10 74 40 13
Daily Global
Compression 1 2 1.5 1
* Values Mentioned here are round off
Figure 3: Compression Ratio of Different
Data centres for global and Local
Compression
Figure 3 shows the post processing in Target Data for daily global compression ratio (the daily rate of data reduction due to duplicate segment elimination), daily local compression ratio (the daily rate of data reduction due to Average Post Processing style compression on new segments), cumulative global compression ratio (the cumulative ratio of data reduction due to duplicate segment elimination), and cumulative total compression ratio (the cumulative ratio of data reduction due to duplicate segment elimination and Average Post Processing compression on new segments) over time. At the end of 50st day, using the post processing in Target Data increasing global compression ratio reaches 23 to 1, and increasing total compression ratio reaches 39
to 1.
In these experiments, average generation (global compression ratio of 50, and an average generation local compression ratio of 2 to 1 for each backup stream. These compression numbers seem possible given the real world examples. We measure throughput for one backup stream using one client computer and 4 backup streams using two client computers for write and read for 10 generations of the backup datasets.
Figure 4 : Throughput Comparison Chart
4. CONCLUSION
This paper presents a set of techniques to post processing in Target Data and substantially reduce disk I/Os in high-throughput deduplication storage systems.
The experiments show that the combination of these techniques can achieve over high read and write data streams on storage server with two dual-core processors and one shelf of few drives. These techniques are general methods to improve throughput performance of deduplication storage systems. Our techniques for minimizing disk I/Os to achieve good deduplication performance match well against the industry trend of building many-core processors. When compared to the other deduplication methods here we have shown reduce disk index lookups by about 15% thus avoiding the duplicated item into the target system.
REFERENCES
1]G. R. Goodson, J. J. Wylie, G. R. Ganger, and M. K. Reiter.Efficient Byzantine-tolerant erasure-coded storage. InProceedings of the
2004 Int’l Conference on DependableSystems
and Networking (DSN 2004), June 2004. [2] Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI 2004.
[3] Carloz Alvarez. NetApp Technical Report: NetApp Deduplication for FAS and V-Series Deployment and Implementation Guide. [4] William D. Norcott and Don Capps. Iozone Filesystem Benchmark. http://www.iozone.org.
[5] Sean Quinlan and Sean Dorward, “Venti: A new
approach to archival storage,” in FAST ’02: Proceedings of the Conference on File and
Storage Technologies, Berkeley, CA, USA, 2002, pp. 89–101, USENIX Association. [6] OpenDedup, “A userspace deduplication file system (SDFS),” March 2010, http://code.google.com/p/opendedup/.
[7] ZHU, B., LI, K., AND PATTERSON, H. Avoiding the disk bottleneck in the Data Domain deduplication file system. In File and Storage Technology Conference (2008). [8] Shai Halevi, Danny Harnik, Benny Pinkas, and Alexandra Shulman-Peleg. Proofs of Ownership in Remote Storage Systems. CCS 2011
[9] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler. The Hadoop Distributed File System.MSST2010 [10] J. R. Douceur, A. Adya, W. J. Bolosky, D. Simon, and
M. Theimer. Reclaiming space from duplicate files in a
serverless distributed file system. In Proceedings of the 22nd
International Conference on Distributed Computing Systems
(ICDCS ’02), pages 617–624, Vienna, Austria, July 2002.
[11] F. Douglis and A. Iyengar. Application-specific
delta-encoding via resemblance detection. In Proceedings of
the 2003 USENIX Annual Technical Conference, pages
113–126. USENIX, June 2003.
[12] D. Goldschlag, M. Reed, and P. Syverson. Onion routing.
Communications of the ACM, 1999.
[13] Petros Efstathopoulos and Fanglu Guo. Rethinking Deduplication Scalability. HotStorage 2010.
[14] H. S. Gunawi, N. Agrawal, A. C. Arpaci-Dusseau, R. H.
Arpaci-Dusseau, and J. Schindler. Deconstructing
commodity storage clusters. In Proceedings of
Symposium on Computer Architecture, pages 60–71, June
2005.
[15] S. Hand and T. Roscoe. Mnemosyne: Peer-to-peer
steganographic storage. Lecture Notes in Computer Science,
2429:130–140, Mar. 2002.
[16] Health Information Portability and Accountability Act, Oct.
1996.
[17] D. Hitz, J. Lau, and M. Malcom. File system design for an
NFS file server appliance. In Proceedings of the Winter 1994
USENIX Technical Conference, pages 235– 246, San
Francisco, CA, Jan. 1994.
[18] R. J. Honicky and E. L. Miller. Replication under scalable
hashing: A family of algorithms for scalable decentralized
data distribution. In Proceedings of the 18th International
Parallel & Distributed Processing Symposium (IPDPS
2004), Santa Fe, NM, Apr. 2004. IEEE.
[19] A. Iyengar, R. Cahn, J. A. Garay, and C. Jutla. Design and
implementation of a secure distributed data repository. In
Proceedings of the 14th IFIP International Information
Security Conference (SEC ’98), pages 123– 135, Sept. 1998.