ContentslistsavailableatScienceDirect
Artificial
Intelligence
in
Medicine
jou rn al h om e p a g e :w w w . e l s e v i e r . c o m / l o c a t e / a i i m
Boosting
drug
named
entity
recognition
using
an
aggregate
classifier
Ioannis
Korkontzelos
a,∗,
Dimitrios
Piliouras
a,
Andrew
W.
Dowsey
b,c,
Sophia
Ananiadou
aaNationalCentreforTextMining(NaCTeM),SchoolofComputerScience,TheUniversityofManchester,ManchesterInstituteofBiotechnology,
131PrincessStreet,ManchesterM17DN,UnitedKingdom
bCentreforEndocrinologyandDiabetes,InstituteofHumanDevelopment,FacultyofMedicalandHumanSciences,TheUniversityofManchester,
Manchester,UnitedKingdom
cCentreforAdvancedDiscoveryandExperimentalTherapeutics(CADET),TheUniversityofManchesterandCentralManchesterUniversityHospitalsNHS
FoundationTrust,ManchesterAcademicHealthSciencesCentre,OxfordRoad,ManchesterM139WL,UnitedKingdom
a
r
t
i
c
l
e
i
n
f
o
Keywords:
Namedentityannotationsparsity Gold-standardvs.silver-standard annotations
Namedentityrecogniseraggregation Genetic-programming-evolved string-similaritypatterns Drugnamedentityrecognition
a
b
s
t
r
a
c
t
Objective:Drugnamed entityrecognition(NER)isacriticalstepforcomplexbiomedicalNLPtasks suchastheextractionofpharmacogenomic,pharmacodynamicandpharmacokineticparameters.Large quantitiesofhighqualitytrainingdata arealmostalwaysaprerequisiteforemploying supervised machine-learningtechniquestoachievehighclassificationperformance.However,thehumanlabour neededtoproduceandmaintainsuchresourcesisasignificantlimitation.Inthisstudy,weimprovethe performanceofdrugNERwithoutrelyingexclusivelyonmanualannotations.
Methods:WeperformdrugNERusingeitherasmallgold-standardcorpus(120abstracts)ornocorpus atall.Inourapproach,wedevelopavotingsystemtocombineanumberofheterogeneousmodels, basedondictionaryknowledge,gold-standardcorporaandsilverannotations,toenhanceperformance. Toimproverecall,weemployedgeneticprogrammingtoevolve11regular-expressionpatternsthat capturecommondrugsuffixesandusedthemasanextrameansforrecognition.
Materials:Ourapproachusesadictionaryofdrugnames,i.e.DrugBank,asmallmanuallyannotated corpus,i.e.thepharmacokineticcorpus,andapartoftheUKPMCdatabase,asrawbiomedicaltext. Gold-standardandsilverannotateddataareusedtotrainmaximumentropyandmultinomiallogistic regressionclassifiers.
Results:AggregatingdrugNERmethods,basedongold-standardannotations,dictionaryknowledgeand patterns,improvedtheperformanceonmodelstrainedongold-standardannotations,only,achieving amaximumF-scoreof95%.Inaddition,combiningmodelstrainedonsilverannotations,dictionary knowledgeandpatternsareshowntoachievecomparableperformancetomodelstrainedexclusively ongold-standarddata.Themainreasonappearstobethemorphologicalsimilaritiessharedamongdrug names.
Conclusion:Weconcludethatgold-standarddataarenotahardrequirementfordrugNER.Combining heterogeneousmodelsbuildondictionaryknowledgecanachievesimilarorcomparableclassification performancewiththatofthebestperformingmodeltrainedongold-standardannotations.
©2015TheAuthors.PublishedbyElsevierB.V.ThisisanopenaccessarticleundertheCCBYlicense (http://creativecommons.org/licenses/by/4.0/).
1. Introduction
Namedentityrecognition(NER)isthetaskofidentifying mem-bersofvarioussemanticclasses,suchaspersons,mountainsand
vehiclesinrawtext.Inbiomedicine,NERisconcernedwithclasses suchasproteins,genes,diseases,drugs,organs,DNAsequences,RNA
∗Correspondingauthor.Tel.:+4401613063094.
E-mailaddresses:[email protected](I.Korkontzelos),
[email protected](D.Piliouras),[email protected] (A.W.Dowsey),[email protected](S.Ananiadou).
sequencesandpossiblyothers[1].Drugs(aspharmaceutical prod-ucts)arespecialtypesofchemicalsubstanceshighlyrelevantfor biomedical research.Asimplisticand naiveapproach toNERis todirectlymatchtextualexpressionsfoundinarelevantlexical repositoryagainstrawtext.Eventhoughthistechniquecan some-timesworkwell,oftenitsuffersfromcertainlimitations.Firstly, itsaccuracyheavilydepends onthecompletenessofthe dictio-nary.However,asterminologyisconstantlyevolving,especiallyin bio-related disciplines,producing a complete lexical repository is notfeasible. Secondly,direct string matchingoverlooks term ambiguityandvariability[2].Ononehand,ambiguousdictionary entries refer to multiplesemantic types (term ambiguity), and http://dx.doi.org/10.1016/j.artmed.2015.05.007
thereforecontextualinformationneedstobeconsideredfor dis-ambiguation.Ontheotherhand,severalslightlydifferenttokens mayrefertothesamesemantictype(termvariability).Typically, toaddresstheseissues,statisticallearning modelsaredeployed forNER.
Insuchapproaches,NERisformalisedasaclassificationtaskin whichaninputexpressioniseitherclassifiedasanentityornot. Supervisedlearningmethodsarereportedtoachievesuperior per-formancethanunsupervisedones,butpreviouslyannotateddata areessentialfortrainingsupervisedmodels[2].Dataannotatedby humancuratorsareofhighqualityandguaranteebestresultsin exchangeforthecostofmanualeffort.Forthesereasons,theyare alsoknownasgold-standarddata.Duetothecostofmanual anno-tations,corporaforNERareoftenoflimitedsizeandforparticular domains.
Drugsarereferredtobytheirchemicalname,genericnameor brandname.Sincethechemicalnameistypicallycomplexanda brandnamemaynotexclusivelyidentifyadrugoncetherelevant patentsexpire,auniquenon-proprietarynamefortheactive ingre-dientisdevisedforstandardisedscientificreportingandlabelling. Thisgenericnameisnegotiated whenthedrugisapproved for use,asthenomenclatureistightlyregulatedbytheWorldHealth Organization(WHO)andlocalagenciessuchastheU.S.Foodand DrugAdministration(FDA)andtheEuropeanMedicinesAgency. Severalcriteria are assessed, such as ensuring the drug action fitsthe namingscheme, easeof pronunciation and translation, anddifferentiationfromotherdrugnamestoavoidtranscription andreproductionerrorsduringprescription[3].Since the nam-ingscheme,assessmentcriteriaandcross-bordersynchronyhave developedorganicallyovertheyears,thereisneitheradefinitive dictionarynorsyntaxofdrugnames.
Inthisstudy,weinvestigatemethodsforachievinghigh perfor-manceindrugnamerecognitionincaseswhereeitherverylimited ornogold-standardtrainingdataisavailable.Ourproposedmethod employsavotingsystemabletocombinepredictionsfroma num-berofdiverserecognisers.Moreover,geneticprogrammingisused toevolvestring-similaritypatternsbasedoncommonsuffixesof single-tokendrugnamesoccurringintheDrugBankdatabase[4]. Subsequently,thesepatternsareusedtocompileregular expres-sionsinordertogeneralisedictionaryentriesinanefforttoincrease coverageandtaggingaccuracy.
Wecomparetheperformanceofourmethodwithseveral state-of-the-art NER approaches in recognising manually annotated drugnamesin thePKcorpus[5].Wherenogold-standarddata isavailable,theproposedmethodisshowntoachieve competi-tiveperformance.Inparticular,theperformanceachievedwithout gold-standarddata is comparable withthe performance of the modelawareofgold-standardannotations.
Therestofthispaperisorganisedasfollows:Section2 sum-marisespreviousworkondrugNERandmethodsfordealingwith datasparsityingeneralNER.Section3describesthedictionaries and data used in our experiments, as well as the experimen-talmethodologyfollowed.Sections4and 5 presentand discuss theexperimentsandtheirresults.Finally,section6concludesthe paper.
2. Relatedwork
NERisalarge,well-studiedfieldofnaturallanguageprocessing (NLP)[6].Mostpublicationsaddressitasasupervisedtask,i.e.the procedureoftrainingamodelonannotateddataandthenapplying ittonewtext.Inthepast,severalevaluationchallengeshavetaken placeonrecognisingentitiesofthegeneraldomain[7–10]aswell asscientificdomains[2,11,12].Incontrast,researchrelatedwith DrugNERislimited[13–15].Veryrecently,anevaluationchallenge
thatfocussedexclusivelyondrugnamerecognitionanddrug-drug interactionshastakenplace[16].
Asaresultofthecollaborativeannotationofalargebiomedical corpusproject[17],alarge-scalebiomedicalsilverstandard cor-pushasbeenproduced.Itcontainsannotationsresultingfromthe harmonisationofnamed entities(NEs)automaticallyrecognised byfivedifferenttools,namely,Whatizit[18],Peregrine[19],GeNO [20],MetaMap[21]andI2E[22].Apartfromnamesofchemicals anddrugs,proteins,genes,diseasesandspeciesnameswerealso taggedbythesetoolsinthe174,999MEDLINEabstractscomprising thecorpus.ApproximatelyhalfamillionNEannotationsforeach semanticcategoryarecontainedintheresultingharmonised cor-puswhichispubliclyavailable.Ithasbeenusedforthe2annotation challenges[23].
Dictionariesandontologieshavebeenusedextensivelyasthe basistogeneratepatternsandrulesforNER.Tsuruokaetal.[24] usedlogisticregressiontolearnastringsimilaritymeasurefrom a dictionary, useful for soft-string matching. Kolarik et al. [25] usedlexico-syntacticpatternstoextractterms.Patternsare sim-ilartotheonesintroducedin[26] andcontaindrugnamesand directlyrelateddrugannotationtermsfoundinDrugBank.Then, thesepatternswereappliedtoMEDLINEabstracts,toadd anno-tationsofpharmacologicaleffectsofdrugs.Similarmethodshave alsobeenappliedforrecognisingdrug-diseaseinteractions[27]and interactionsbetweencompoundsanddrug-metabolisingenzymes [28].Hettneetal.[29]developedarule-basedmethodintended for term filtering and disambiguation. They identify names of drugsandsmallmoleculesbyincorporatingseveraldictionaries suchastheUMLS(nlm.nih.gov/research/umls,accessed:15April 2015),MeSH(nlm.nih.gov/mesh,accessed:15April2015),ChEBI (www.ebi.ac.uk/chebi,accessed:15April2015),DrugBank (drug-bank.ca,accessed: 15 April2015), KEGG(www.genome.jp/kegg, accessed:15April2015),HMDB(hmdb.ca,accessed:15April2015) andChemIDplus(chem.sis.nlm.nih.gov/chemidplus,accessed:15 April2015).Anearliersystem,EDGAR[30],extractsgenes,drugs and relationshipsbetween them using existing ontologies and standardNLPtoolssuchaspart-of-speechtaggersandsyntactic parsers.
A popularmeansof dealing withdata sparsity in NER isto generatedatasemi-automaticallyorfullyautomatically.Although, theresultingdataisoflowerqualitythangold-standard annota-tions,supervisedlearnerscanbenefitlargelyfromlargevolumes ofdata,sincetheyarebasedonannotationstatistics.Towardsthe sameultimategoal,ourapproachaimstoovercomethe restric-tionsofdatasparsityorunavailabilityinthebiomedicaldomain. Usamietal.[31]describeanapproachforautomatically acquir-inglargeamountsoftrainingdatafromalexicaldatabaseandraw textthatreliesonreferenceinformationandcoordinationanalysis. Similarly,noisytrainingdatawasobtainedbyusingafew man-uallyannotatedabstractsfromFlyBase(flybase.org,accessed:15 April2015)[32,33].Theapproachusesabootstrappingmethodand context-basedclassifierstoincreasethenumberofNEmentions intheoriginalnoisytrainingdata.Eventhoughtheyreporthigh performance,theirmethodrequiressomeminimumcuratedseed data.Similarly,Thomasetal.[34]demonstratedthepotentialof distantlearninginconstructingafullyautomatedrelation extrac-tion process. They produced two distantly labelled corpora for protein–proteinanddrug–druginteractionextraction,with knowl-edgefoundindatabasessuchasIntAct[35]forgenesandDrugBank [4]fordrugs.
Activelearning isa frameworkthatcanbeusedfor reducing the amountof human effortrequired to create a training cor-pus[36,37].Themostinformativesamplesarechosenfromabig poolofhumanannotationsbyamaximumlikelihoodmodelinan iterativeand interactivemanner.It hasbeenshown thatactive learningcanoftendrasticallyreducetheamountoftrainingdata
Table1
Binarytokentypefeatures. Tokentypefeatures
initialcapitalletter containshyphen all lowercaseletters containsslash
allletters containsperiod
alldigits containsuppercase
containsdigit containsletters
necessarytoachievethesamelevelofperformancecomparedto purerandomsampling[38].Asimilarapproach,accelerated anno-tation[39],allowstoproduceNEannotationsforagivencorpusat reducedcost.Incontrasttoactivelearning,itaimstoannotateall occurrencesofthetargetNEs,thusminimisingthesamplingbias. Despitethesimilaritiesbetweenthetwoframeworks,theirgoals aredifferent.Whileactivelearningaimstooptimisethe perfor-manceofthecorrespondingtagger,acceleratedannotationaimsto constructanunbiasedNEannotatedcorpus.
3. Methodsanddata
Inthissectionwepresentouraggregateclassifierforrecognising drugnamesandthenecessaryresources.
3.1. Methodology
Toclassifylabelsoftokens,weusedtwoclassifiers,amaximum entropy(MaxEnt)model,alsoknownasmultinomiallogistic regres-sion[40],andaperceptronclassifier[41].MaxEntclassifiersassume thatthebestmodelparametersaretheonesforwhicheach fea-ture’spredictedexpectationmatchesitsempiricalexpectationand classifyinstancessothattheconditionallikelihoodismaximised. Inotherwords,MaxEntmaximisesentropywhileconformingto theprobabilitydistributiondrawnbythetrainingset.Perceptron isalinearclassifierthattunestheweightsinanetworkduringthe trainingphase,soastoproducethedesiredoutput.Theperceptron methodisguaranteedtolocatethecombinationofweightsthat solvetheproblem,ifsuchacombinationexists.Weusedstandard implementationsofMaxEntandPerceptron,partsoftheApache openNLPproject(opennlp.apache.org,accessed:15April2015).
Forboth classifiers,we usedthesamefeatureset,described below.Foreachtoken,weconsiderasfeatures:
-tokens:thecurrentand±2tokens -charactern-grams:±2tokens
-sentence:abinaryfeatureindicatingwhetherthetokenappears atstartorendofasentence
-binarytokentypefeaturesofthecurrentand±2tokens,shownin Table1
-previousmap:a binaryfeatureindicatingwhetherthecurrent tokenwaspreviouslyseenasaNE
-prefixandsuffixofthecurrenttoken
-dictionary:abinaryfeatureindicatingwhetherthecurrenttoken existsinthedictionary
WeattempttoaggregatepredictionsfromdictionariesandNER systems,underthefundamentalhypothesisthatthecombined out-putmightimproveovertheresultsofsingleclassifiersdeployed asstandalone.Ouraggregateclassifieriscompatiblewithany dic-tionariesandrecognitionsystems,andcouldbeappliedinother domainsandsequencerecognitiontasks.
Wedevelopedasimplevoting-systemassumingthatthe predic-tionsofdictionariesaremorereliablethanpredictionsofmachine learners.Asaresult,thealgorithmacceptsdictionarypredictions asvalidiftheyexist.Thisassumptionisnottrue,ifadictionary
contains non-drug entities but, since dictionaries are produced manually,weconsiderthemideal.AmbiguousNEsmightalsoaffect thevalidityofthisassumption.Weobservedverylittlesuch ambi-guitiesinourdictionary,DrugBank,thus,weacceptthehypothesis toholdinthedomainofdrugNEs.
Algorithm1summarisesthevotingsystem.Inshort,itstarts withanemptylistLanditerates overallsentences andtokens oftheinputtext.For each token,itqueries available dictionar-iesorregular expressionpatternsand acceptspositive answers asvalid.Otherwise,itconsiderssequentiallyeachmodel’sopinion regardingwhetherthecurrenttokenisadrugentityornot. When-everamodelpositivelyrecognisesadrug-name,westorethename alongwiththeconfidenceofthepredictioninamap.After consid-eringthepredictionsofallmodels,westorethepositiveprediction withthehighestconfidence,ifsuchapredictionexists,andproceed tothenexttoken.Predictionsofdictionariesorregularexpression patternsareassigned100%confidence.
Algorithm1. Aggregationofpredictions
1: ListL→[]
2: forallSentences∈Textdo
3: MapM→{:prediction:confidence}
4: forallTokenst∈sdo
5: if∃dictionarythen
6: ifdictionary.predict(t)→POSITIVEthen
7: PUTM{prediction1.0}
8: else
9: forallModelm→Modelsdo
10: ifm.predict(t)→POSITIVEthen
11: STORE{predictionconfidence}
12: endif
13: endfor
14: PUTM{predictionmax-confidence}
15: endif
16: endif
17: endfor
18: DROPoverlapping/intersectingspans*
19: ADDLM
20: endfor
21: returnL
*Rulesfordroppingspans:
-Identical/Intersecting:firstspaniskept
-Contained:Containedspansaredropped
Afterprocessingalltokensofa sentence,anyintersectingor overlappingspansareremovedaccordingtothefollowingrules. Forpredictionsthatcrossintoeach-other,wediscardallbutthe firstone.Fornestedpredictions,onlythemaximaloneiskept.Upon algorithmcompletion,Lshouldcontainasequenceofmaps,each representingthepredictionsonasinglesentence.
Atasecondexperimentalstage,wede-constructedthe dictio-nary into2 distinct models:(a) a model trained ontextsolely annotated by the dictionary, and (b) an evolved set of string-patterns that attempts to accurately cover commonsuffixes of single-tokendrugnames.
For evaluation, we used the standard information retrieval metrics:precision,recallandF-score(F1)[42].
3.2. Data
Theproposedmethodrequirestwotypesofresources:(a)one ormorecomprehensivelexicalrepositories,suchasdictionariesor lexicons.(b)largeamountsofrawtextinthedomainofinterest, whichisdrugsforthecurrentstudy.Supplementally,asmall gold-standardcorpusmayenhanceNERperformanceifavailable.
Ourmethodcouldpotentiallybeappliedtorecogniseanytype ofbiomedicalNEs,suchasgenesandproteins.Wechoosetofocus onidentifyingdrugnames,asthisdomainhasbeenstudiedtoa muchsmallerextent.Inthissection,wepresenttheresourcesthat
wemadeavailable tothealgorithm proposedin Section3.1 for experimentation.
3.2.1. DrugBank
Asourdictionary,wechosetouseDrugBank[4]becauseitis rel-ativelyup-to-dateandprovidesamappingbetweendrug-names andcommonsynonyms.DrugBankcurrentlycontainsmorethan 6700entriesincluding1447FDA-approvedsmallmoleculedrugs, 131FDA-approvedbiotech(protein/peptide)drugs,85 nutraceuti-calsand5080experimentaldrugs.Wepre-processedthedictionary bynormalisingall officialdrugterms and linkedthem totheir synonymsinakey-valuedata-structure.Eachkey(drugname)is uniqueandmapstoasinglevalue(alistofsynonyms).
3.2.2. Thepharmacokineticcorpus
The pharmacokineticcorpus (PK) [5] is manually annotated andconsistsof240MEDLINEabstractsannotatedandlabelledon thebasis of MESH terms relevant to pharmacokinetics suchas drugnames,enzymenamesandpharmacokineticparameters,e.g. clearance.Halfof thecorpusisintendedfor training(invivo/in vitro-train)andhalffortesting(invivo/invitro-test).Itisfreely availableat: rweb.compbio.iupui.edu/corpus (accessed:15 April 2015).Asapre-processingstep,allannotationsconcerning enti-tiesotherthandrugswereremoved,sincethisstudyisconcerned withdetectingdrugnamesonly.
3.2.3. Rawtext
Nowadays,acquiringlargeamountsofrawtextisnotadifficult task,evenforveryspecialiseddomains.Publicelectronic reposi-toriesofopen-accessarticlesexistformostscientificdomainsand usuallycanbequeriedviaRESTfulwebservices.Inbiomedicine,for example,UKPubMedCentral(UKPMC,europepmc.org,accessed: 15April2015)isanarticledatabasewhichextendsthe functional-ityoftheoriginalPubMedCentral(ncbi.nlm.nih.gov/pmc,accessed: 15April2015)repository.Forthepurposesofthisstudy,weuseda smallsubsetoftheentireUKPMCdatabasewhichincludesmore than two million papers. The sample we used wascreated by Mih˘ail˘a and Navarro [43], totaling 360pharmacology and cell-biologyrelatedarticles.Asapre-processingstep,thecorpuswas sentence-splitandtokenised.Part-of-speechtaggingwasomitted fromtheprocesssincewedidnotplantousethepart-of-speech tagsasfeaturesduringtraining.
4. Experimentalresults
Thefirstsetofexperiments,inSection4.1,consideredtheentire setofgold-standardannotations.Inthesecondset,weassessthe importanceofsilverdata,i.e.dataannotatedbyrecognising dic-tionaryentriesonrawtext.Weevaluatetheperformanceofour classifiertrained onsilver dataonly,andwe alsocombinegold andsilver datatomeasure whetherthecombinationcanboost performance.Insuccession,weinvestigatehowwecanproduce stringsimilaritypatternsbasedondictionaryknowledgetofurther increaserecall.Finally,weinvestigatehowtheproposedaggregate classifierperformsinabsenceofgold-standardannotations.
4.1. Baselines
Firstly,wetestedhowthedictionaryperformsasasingle recog-niser,includingorexcludingsynonyms.Secondly,wetrainedtwo NErecognisers,namelyaMaxEntandaperceptronclassifier,on halfthePKcorpus(invivo/invitro-train)andtestedthemonthe otherhalf(invivo/invitro-test). Finally,weusedourprediction aggregationalgorithmtocombinepredictionsoriginatingfromthe dictionary,withpredictionsoriginatingfromtheclassifiers.
Table2
Resultsofbaselineclassifierstrainedongold-standarddata(P:precision,R:recall,
F1:F-score). Classifier P R F1 Dictionary 99.7% 78.5% 87.8% Dictionary+synonyms 93.4% 78.9% 85.6% MaxEnt(gold) 98.3% 84.5% 91.0% Perceptron(gold) 97.5% 72.0% 82.8%
MaxEnt(gold)+dictionary 99.1% 88.4% 93.4% Perceptron(gold)+dictionary 97.6% 84.3% 90.4%
Table2presentstheresultsfromourbaselineexperiments.It is worthnoting thatthepuredictionary-basedapproach is not 100%preciseasourvotingsystemassumes.Carefulerroranalysis revealedthatthereareatleasttwoentities,i.e.“nitricoxide”and “tranylcypromine”thathavenotbeentaggedinthegold-standard corpus.Consequently,theevaluatormarksthemasfalse-positives while,infact,theyareperfectlycorrectpredictions.Another inter-estingobservationisthatincludingsynonymscausesprecisionto degrade.SynonymsinDrugBankoftenincludeacronyms,which havenotbeentaggedappropriatelyinthetestcorpus.Asbefore, theevaluatorclassifiesthemasfalse-positives.
Ingeneral,wecanseethatboththedictionaryandtheclassifiers exhibitveryhighprecisionandgoodrecall, whereascombining the two has a minimal positive effect on overall performance. The perceptron classifier, despite training significantly faster, consistently showed inferior performance in comparison with MaxEnt.
Unfortunately,nootherexperimentalresultsontheexactdata thatweexperimentedwithhavebeenpublished.However,toput ourresultsintoperspective,wecanconsidertheresultsofarecent evaluation challenge,SemEval-2013 Task9:DDIExtraction[16]. Itsfirstsubtaskwasconcernedwithrecognisingandclassifying drugnames.Severalparticipatingsystemsaimedatrecognising genericandbrandeddrugnames,amongotherentities.Table3 showtheexact-matchingprecision,recall and F-scoreachieved bythe bestperformingsystems in terms ofF-score in the cat-egories of genericand brandeddrug names.The DDIExtraction 2013task wasevaluated onthe DDIcorpus, which consistsof 784DrugBanktextsand233MEDLINEabstractsandwas manu-allyannotated[44].Althoughthedatausedinthisworkarenot identicaltothe DDIcorpus, theresultsin Table 3can beused as indirect baselines. It can beobserved that the our baseline resultsinTable2arecomparableifnotslightlybetterthanthebest performingsystemstheDDIExtraction2013task,despitethefact thatwetrainedonsignificantlysmallerandpossiblylower-quality data.
Ourbaselineexperimentsshowthat,despiteacquiring state-of-the-artprecision,thereisstillspaceforimprovementwithregards torecall.Highprecisionindicatesthat themodel extractssome veryinformativefeatureswhiletraining,whereasnotsohighrecall essentiallyreflectslackofenoughtrainingdata.Ideally,wewould needmoregold-standardannotations,however,asdiscussed pre-viously,thisisnotalwaysfeasible.
Table3
Resultsofthebestperformingsystems(intermsofexact-matchingF-score)in generalandbrandeddrugnamerecognitionintheDDIExtraction2013task[16].
Category Generaldrugnames Brandeddrugnames
System NLMLHC[16] UTurku[15]
Team NationalLibraryofMedicine UniversityofTurku
Approach Dictionary-based SVMclassifier(TEES)
Precision 72.5% 94.5%
Recall 91.7% 88.1%
Table4
Resultsofclassifierstrainedongold-standardandsilverannotationdata(P: preci-sion,R:recall,F1:F-score).
Classifier P R F1
MaxEnt(silver) 98.7% 47.1% 63.7%
MaxEnt(silver)+dictionary 99.2% 78.5% 87.6% Perceptron(silver) 98.3% 76.9% 86.3% Perceptron(silver)+dictionary 99.3% 78.5% 87.7% MaxEnt(gold+silver) 97.8% 84.8% 91.0% MaxEnt(gold+silver)+dictionary 98.6% 89.7% 93.9% Perceptron(gold+silver) 97.2% 79.1% 87.2% Perceptron(gold+silver)+dictionary 98.0% 85.1% 91.1%
4.2. Combiningheterogeneousmodels
Attempting to improve recall, we trained separate models purelyonsilverdata,i.e.dataannotatedbydirectstring-matching dictionaryentries.Annotationcoverageultimatelydependsonthe qualityof thedictionary, itscoverageand howup-to-dateit is. DrugBankisagoodcandidateforthistask,asitisacomprehensive dictionaryofdrugsandalsofreelyavailable.The360fullpapers mentionedinSection3.2.3wereannotatedandpartitionedinto30 collections,eachonecontaining12items.Thiswasdoneinaneffort toincrementallycheckwhethertheadditionofsilverannotations hasanypositiveornegativeeffectsonclassifier’sperformance.We foundthatwehadtoincludeall30partitionsinordertowitness someimprovement.
Table6summarisestheresultsofourexperiments.The Max-Entclassifiertrainedonsilverannotationdataachievesmarginally higherprecisionandsignificantlylowerrecallthanthesame classi-fiertrainedongold-standarddata.Thisisexpected,sincethesilver annotationsreflectthecontentsofthedictionary,only.Trainedona mixtureofgoldandsilverdata,theMaxEntclassifierachieves0.5% lowerprecisionand0.3%higherrecallthanitsequivalenttrained ongold-standarddata.
IncludingthedictionarybooststherecalloftheMaxEntclassifier trainedonamixtureofgold-standardandsilverannotationdataby 1.3%incomparisonwithitsbaselineequivalent.Thelast2rowsof Table4showthatallstatisticswereslightlyboostedjustbyutilising theseextra,easytoproducesilverannotations.
Inallourexperimentssofar,thebestachievedrecallis89.7%, farless than precision,thus, we focus onimprovingit. Careful examinationoffalse-negativesrevealsthatmostofthemareeither acronyms(e.g.HMR1766),longchemicaldescriptions(e.g. 5beta-cholestane-3alpha,7alpha,12alpha-triol)ortermswhoselexical morphologyisparticularlydifferentthantheusualmorphologyof drugs(e.g.grapefruit juice).We attemptedtocaptureacronyms byemployingastate-of-the-artacronymdisambiguator,AcroMine [45],howeveritdidnotdisambiguateanyoftheacronymsin ques-tion,listedbelow:
•ANF •E3174 •PO4 •RPR106541 •HMR1766 •MDZ4-OH •MDZ1-OH
Under datasparsity, it iscrucial toextract maximumutility from ourtraining set, which necessitates incorporation of fea-tureswithlowoccurrencefrequency.TheMaxEntandperceptron modelsweemploydonotconsidertheuncertaintyintroducedby lowfrequency training data,henceafrequency thresholdvalue isintroducedtocontrolthecompromisebetweenprecisionand recall.For ourexperimentswesetthisthreshold at5,aslower
valuesdetrimentallyaffectedprecision.Asdiscussed,anumberof false-negativesweremissedduetotheirmorphologywhichis dif-ferentthantheusualmorphologyofdrugs.Thesetwofacts,suggest thatprobablysomeinformativefeaturesdidnotqualifyduetothe frequencythresholdvalue.Itshouldbenotedthat,incontrasttothe MaxEntclassifier,whichisprobabilistic,theperceptronclassifieris notaffectedbythefrequencythreshold.Theperceptronis essen-tiallyaneuralnetwork,thusitdoesnotgatherprobabilitiesand thereforeperformsbestwhennofrequencythresholdisapplied.
Beyondthescopeofthispaper,therearemoresophisticated methodstoselectimportantfeaturesortunefeatureweightsto addressdatasparsity.Ingeneral,twosmoothingapproaches[46] areapplied:linearinterpolation[47]andback-offmodels[48–51]. Datasparsitycanalsobeaddressedbyfeaturerelaxation,basedon hierarchicalfeatures[52].Amoresophisticatedapproachtofeature weightingwouldbetoemployDirichletregression[53–55]rather thanMaxEnt.Dirichletregressionconsidersfrequenciesdirectlyas thedependentvariable,ratherthanprobabilitiesasinmultinomial logisticregression.Thesumoffrequenciesforaparticularfeature representsits“precision”.Itshouldbenotedthatforhighfrequency dataDirichletandmultinomiallogisticregressionmodelsbehave similarly.
4.3. Evolvingstring-similaritypatterns
Inthissectionweaimtoimproverecallbylearningstring sim-ilaritypatternsbasedondictionaryknowledge.Exploringwaysto restorethepredictivepowerthemodelcouldhaveifmore train-ingdata wereavailable,we develop a mechanismtodeal with theseeasy,yetelusivefalse-negativecasesdiscussedinthe previ-oussection.Weattempttogeneticallyevolvestringpatternsthat canthenbeusedasregularexpressions tocapturedrugnames thatarenotpresentinthedictionary.Wefollowedathree-step processdescribedbelow:geneticprogramming,filteringandpattern augmentation.
FollowingtheworkofTsuruokaetal.[24],wealsouseaformof regressioninordertolearncommonstringpatternsofdrugnames. Morespecifically,we usedgeneticprogramming,alsoknownas symbolicregression,atechniquewhichallowstheevolutionof pro-gramsatthesymboliclevel[56].Geneticprogrammingisusedin thistaskasaglobaloptimisationalgorithm.
The pseudo-random sampling inherent in genetic program-ming means that no hard guarantees about the final outcome canbemade.However,therandomness alsoenablesgood cov-erage of thefitness landscapeand therefore avoids fallinginto localoptima,whichisessentialtosolveourproblem.Furthermore, theself-drivennatureofevolutionisrobustasitmakeslittleto noassumptionsaboutthefitnesslandscape,thusmitigatingbias duringthelearningstage,whichenablesittoproduce meaning-fulsolutionswhereotherglobaloptimisationalgorithmscanfalter [56].Learningbymeansofevolutionisagoodfitforouruse-caseas itallowsfindingdecentsolutionswithminimalpriorknowledge.
Geneticprogramsassemblevariablelengthprogramstructures fromthebasicunits,i.e. functionsand terminals.Theassembly occursatthebeginningofarun,whenthepopulationisinitialised. Insuccession,programsaretransformedusinggeneticoperators, suchascrossover,mutationandreproduction.Thealgorithmevolves a population of programsby determining which individuals to improvebasedontheirfitness,whichisinturnassessedbythe fitness-function.
Inourimplementation,geneticprogramswererepresentedas treesthatweretraversedinadepth-firstmanner.Afitnessfunction, afunctionsetandaterminalsetarerequiredfordevelopingagenetic algorithm.Terminalsprovidethevaluesthatcanbeassignedtothe treeleaves,whilefunctionsperformoperationsoneitherterminals orontheoutputofotherfunctions.Typically,thefunctionsetofa
str interpose a wrap str z [] t s p rest str e n i . ?
Fig.1.Thebest-evolved“organism”.
Fig.2. Exampleofone-pointcrossoverbetweenparentsofdifferentsizesand shapes.
Imagesource:[62].
geneticalgorithmthatdealswithnumericalcalculationscontains thefourbasicarithmeticoperations(+−*/),whiletheterminalset containsone-digitnon-negativeintegers,[0-9].Inthecurrentcase, thefunctionandterminalsetshavetodealwithstrings.The termi-nalsetcontainsallLatinlowercaseletters,[a–z],plusseveralother charactersneededforbuildingmeaningfulregularexpressions,i.e. |\*+?()[].Thefunctionsetcontainsseveralstring-manipulating functions,e.g.split,joinandconcatenate.
Weemployedtwogeneticoperators,crossoverandmutation.As illustratedinFig.2,tree-basedcrossovergeneratesnewindividuals byswappingsubtreesofexistingindividuals.Thepopulation per-centageapplicabletocrossoverwassetto35%.Mutationtypically operatesononeindividual.AsshowninFig.3,apointinthetree
Fig.3.Exampleofsubtreemutation. Imagesource:[62].
undermutationischosenandthecorrespondingsubtreeisreplaced withanewrandomlygeneratedsubtree.Thisnewsubtreeis cre-atedinthesameway,andissubjecttothesamelimitationsasthe originaltreesintheinitialpopulation.Asamatteroffuturework, moregeneticoperatorscanbeemployed.Althoughweattemptto employthesimplestgeneticoperatorspossible,evolving similar-itypatternsbygeneticprogrammingisthemostdemandingpart ofthiswork,intermsofcomputationalcomplexity.
Each“organism”inthegeneticpopulationisasmallprogram. Whenexecuted,theprogram producesa stringthatis assigned a score according to the fitness function. For this purpose, all thesingle-wordtermswereextractedfromDrugBankandwere usedas“test-data”withinthefitnessfunction,whichreturnsthe proportionofmatchesasameasureoffitness.Incasethestring producedisnotavalidregularexpression,thecandidatereceives negative scoreand willmost likely bedisregarded in the next generation.Forinstance,acandidatethatmatches50/6700terms inDrugBankisobviouslyfitterthanonethatmatchesonly10/6700 terms, which in turn,is fitter than one whose string doesnot compileasaregularexpression.However,geneticprogramming didnotachieve anythinglessthan100% errorwhenattempting tomatchentiretokens,andsowelimitedthetestingscopetothe last4, 5or6 charactersofeach token.Thisdecisionwasmade afterobservingthatword-endings tendtobemoresimilarthan word-beginnings in drug names, mainly for conformance with the WHO’s international non-proprietary name stem grouping (who.int/medicines/services/inn/stembook/en,accessed:15April 2015).Thishadamajorpositiveeffectonthepopulationinmost executions.
After200experimentswith80generationsperexperimentand 10,000individualspergeneration,the30best-evolvedindividuals wereselected.Eachindividualisafunctionthatbuildsastringthat representsapotentiallycommonsuffix,intheformofaregular expressionpattern.Thepatternproducedbythebestindividual matched7.3%ofthetermsinthetest-set(130terms).Itshouldbe notedthattheevolutionaryprocessevaluatescandidatesusinga listofsingletonsandnotactualsentences.Asaconsequence,these patternswillmostlikelyintroducefalse-positivesifapplieddirectly onrealtext,thus,decreasingprecision.
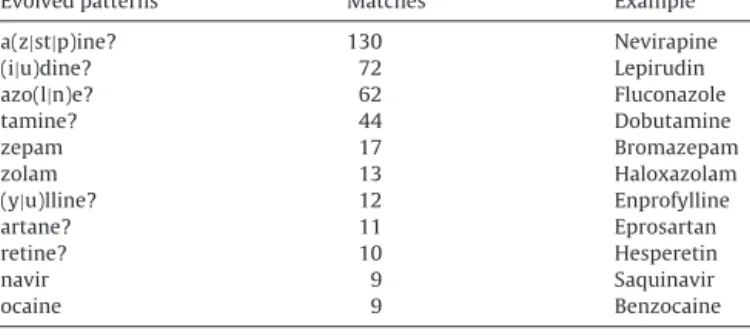
Insuccession,weaimtokeepthetopperformingpatternsonly, i.e.theleastlikelytointroducefalse-positives.Thisfilteringcanbe doneeithermanuallyoralgorithmically.Sincethenumberof pat-ternsissmall,thecostofmanualcheckingbyadomainexpertis limited.Non-expertscouldalsoaccomplishthistask.Instead,we chosetoincreasetheapplicabilityofourapproach,weselected thebestpatternsautomatically.We calculatedallpossible com-binationsofsetsof5stringpatternsandperformedanextensive evaluationprocesswhereeachcombinationwasevaluatedonlyfor false-positiveson10randomlyselectedparagraphsfromthe orig-inaltraining set(PKcorpus).Weselected5setsofpatterns(25 patterns)whichintroducedtheleastfalse-positives.These25 pat-ternswerereducedto11afterremovingduplicatesandthosethat wouldclearlyintroducefalse-positives.Forexample,thepattern
“m?ine”wasremovedbecauseit wouldrecognise“fluvoxamine”
correctly,butitwouldalsoincorrectlyrecogniseasdrugswords suchas“examine”,“define”,“jasmine”and“cosine”.Table5shows the11bestperformingpatterns,accompaniedwiththenumberof matchesandanexampleforeachone,whileFig.1showsthetree thatcorrespondstothebestperformingpattern.
Finally,inthepatternaugmentationstep,weaugmentedthese 11patternsbywrappingthemasfollows:
\b(\d?\,?\d?\−?)?\w+<pattern>+\b
Thestring “\b”at thestart and endof thepattern,make it applicabletowholewordsonly.Thestring“(\d?\,?\d’?\-?)?\w+”
Table5 Evolvedpatterns.
Evolvedpatterns Matches Example
a(z|st|p)ine? 130 Nevirapine
(i|u)dine? 72 Lepirudin
azo(l|n)e? 62 Fluconazole
tamine? 44 Dobutamine zepam 17 Bromazepam zolam 13 Haloxazolam (y|u)lline? 12 Enprofylline artane? 11 Eprosartan retine? 10 Hesperetin navir 9 Saquinavir ocaine 9 Benzocaine
specifiesoptionaltriggers,i.e.digits,commasanddashes,mainly formatchinghydroxylatedcompounds.Forexampleifapattern appliesto“midazolam”,it alsomatches “4-hydroxymidazolam”, “4,5-hydroxymidazolam”and“4,5’-hydroxymidazolam”.Itis com-monknowledgein biochemistrythat allorganiccompoundsgo through oxidative degradationwhen they come in contact with air.Hydroxylation is thefirststep inthat processand converts lipophiliccompounds into water-soluble(hydrophilic) products thataremorereadilyexcreted.Weobservemanymentionsofsuch
compoundsin pharmacologypapers, and therefore weattempt
tocapturethemwiththissimpleregularexpression.Thepattern augmentationrule,waschosenmanually,introducingaminimal humaninteractioninthislaststep.
Thegeneticprogrammingparadigmparallelsnatureinthatit isa never-endingprocess.In practisehowever,and particularly whenevolvingcode,arbitrarycomplexityisrarelydesiredbecause itisveryeasyforthemodeltoover-fitorstartdeviating substan-tiallyfromagoodsolutionapproximation.Weadopttwosimple andwidelyusedterminationcriteriatoaddressthis.Westopped theevolutionprocess(a)afteranumberofiterations(generations) and(b)bysettingamaximumallowedtreedepth(10).Thepatterns wereevolvedassumingthateachwillspanasinglewordterm.
4.4. Evaluationofevolvedpatterns
Weevaluatedthebestaugmentedpatterns(Table5)asa sep-arate classificationmodel. During aggregations,similarly tothe dictionarypredictions,positivepredictionsofthepatternmodel areassignedaprobabilityof100%.Table6showsevaluationresults. Asafirstobservation,classifierensemblestrainedbothon gold-standardand silverannotationdatadonotperformbetterthan classifierensemblestrainedongold-standarddata,only. Combin-ingthedictionaryandthepatternmodelcompensatesforthelack ofalower-qualitymodelbothfortheMaxEntandtheperceptron classifier.ComparingTables2,4and6demonstrateshowwe grad-uallymovedfromtherecallrange84–88%to89–93%,whilekeeping precisionabove 96–97%.In fact,there aresome verified anno-tationinconsistenciesinthetestcorpusresponsibleforaminor decreaseinprecision.More specifically,someterms,suchas 3-hydroxyquinidine,cycloguaniland 4-hydroxyomeprazole,havenot beenappropriatelytaggedasdrugs.
Table6
Evaluationresultsofensemblesthatcontainthepatternclassifier(P:precision,R: recall,F1:F-score).
Classifier P R F1
MaxEnt(gold)+dictionary+patterns 97.3% 93.0% 95.1% MaxEnt(gold+silver)+dictionary+patterns 97.3% 93.0% 95.1% Perceptron(gold)+dictionary+patterns 95.8% 88.9% 92.3% Perceptron(gold+silver)+dictionary+patterns 96.0% 88.8% 92.3%
Table7
Resultsofclassifiersthatdidnotusegold-standarddata(P:precision,R:recall,F1:
F-score).
Classifier P R F1
MaxEnt(silver)+dictionary+patterns 97.4% 85.4% 91.0% Perceptron(silver)+dictionary+patterns 97.3% 85.1% 90.8%
4.5. Ignoringgold-standarddata
Inourexperimentssofar,weassumedthatatleastsome gold-standard data is availablefor training. Howeverthis might not alwaysbe thecase. In this section,we areconcerned withthe question:“Howmuchworsewouldresultsbe,intheabsenceof a gold-standardtrainingset?”Thisisanimportantquestionbecause, asdiscussedearlier,gold-standardannotationsaretime consum-ing and costly. Ignoring expensiveannotations, we experiment withclassifierstrainedontheeasy-to-produceautomatically gen-eratedannotations,thedictionaryandthepatternmodel.Thesame gold-standardcorpuswasusedfortestingandeachincremental improvementwasalsotestedforstatisticalsignificanceagainstthe previousoneusingchi-squaretest,withandwithoutYate’s cor-rection.Inallcases,improvementswerefoundtobestatistically significantwithp-valuesrangingfrom10−4to4×10−4.Theresults obtainedareshowninTable7.
Comparingtheseresultswiththeonesfromourbaseline exper-iments, presented in Table2, shows that theMaxEnt classifier trainedsolelyonsilverannotationdata,combinedwiththe dic-tionaryand thepatternmodel,achievessimilarperformance to theMaxEntclassifiertrainedongold-standarddata.Thisresultis encouraging,sinceitsuggeststhataccesstogold-standarddatais notnecessarilyaprerequisiteforhighperformancedrug-NER. 5. Discussion
UsingalexicaldatabasetoannotateNEsinrawtextisnotanew concept.Infact,sincelexicaldatabasesaremanuallyannotated, annotatingsentencesforNEsfromscratchcertainlycontainssome levelofeffortduplication.Weattemptedtoautomatethe annota-tionprocessbyutilisingsuchresources.Unfortunately,ourresults showthatusingadictionaryasadirectannotatorofdrugnames achievestopprecisionbutlimitedrecall.Classifierstrainedon gold-standard annotations achieved comparable precision but much higherrecall.
Forthesereasons,weattemptedtoexperimentwithmethodsto pre-processDrugBankbeforeusingitasanannotator.Toincrease recall we generaliseddictionary entriesinto regularexpression patterns.Wewereexpectingthatthepatternswouldbeableto capturedrugnamesthatwerenotlistedinthedictionarybutshare commonmorphologicalcharacteristics,suchassuffixesorprefixes, withsomedictionaryentries.
Obtainingsuchpatternsautomaticallyandaccuratelyishard and, thus, our listof patterns is neither perfect nor complete. Perhapsapharmacologistcooperatingwitharegular-expression expertwouldfindhigherqualitypatterns,i.e.patternsthat gen-eralisebetter.However,weprefertoexploretheextenttowhich automaticmethodscanaddressthistaskadequately.Inthefutureit wouldbeveryinterestingtocompareourautomatedmethodwith expert-drivenregularexpressions,togetherwithincorporationof rulesderivedfromexistingWHOandFDAdrugnomenclature pro-cesses.
Throughoutour experiments, we relied heavily onthe pro-posed algorithm for aggregating predictions,which is also not perfect. It is based on assumptions that may not hold in a different context. Moreover,the algorithm always favours pre-dictionsoftheknowledge-basedmodels(dictionariesandregular
expressions)againstlearningmodels,acceptingtheinconsistencies ofknowledge-basedmodelsasvalid.Themanuallyconstructed dic-tionarywasofmajorimportanceforthisstudy,asitwasusedin anumberofways.Itwasthebasistoextractsynonyms,common word-endingpatterns,andwasalsoseenasadirectannotatorfor anentirecorpus.Votingsystemssimilartotheproposedprediction aggregationalgorithmarebecomingincreasinglypopularmainlyto boostperformancebutalsofortheoverallstabilityoftheresulting classifier[57–61].
Itisalsonoteworthythatbothsetsofgold-standarddata,for trainingandtesting,areofroughlythesamesize.Contrastingthis withothersimilarNERexperiments,wefindthatthetesting-setis usuallyalotsmallerthanthetraining-setregardlessofthe evalu-ationscheme(holdoutorcross-validation).Thisisduetothefact thattheproblemofdata-sparsityispervasiveacrosstheentiretext miningandNLPdiscipline(withregardstoprobabilistictraining). Inpractice,thismeansthatthereisrarelyenoughtrainingdata, thussplittingitintwoequallysizedpieceswillmostlikelynotlead tosatisfyingstatistics.Wedecidedtoleavethedataasis,inorder fortheexperimentstobeaseasilyreproducibleaspossible.
Ourresultsdemonstratethat,eventhoughavailabilityof gold-standard dataiscertainly helpful, it is nota strictrequirement withregardstodrugNER.Drugsoftenshareseveral morpholog-icalcharacteristics,whichreducesthecontextualinformationthat isneededinordertomakeinformedpredictions.Nonetheless,it remainstobeinvestigatedwhetherourcombinationof heteroge-neousmodelswillachievehighperformancewhentestedagainst largercorpora.
6. Conclusionsandfuturework
Thisstudymainlyfocusedonachievinghighperformancedrug NERwithverylimitedornomanualannotations.Weachievedthis bymergingpredictionsfromseveralheterogeneousmodels includ-ingmodelstrainedongold-standarddata,modelstrainedonsilver annotationdata,DrugBankand,finally,evolvedregularexpression patterns.Wehaveshownthatstate-of-the-artperformanceindrug NERiswithinreach,eveninthepresenceofdatasparsity.
Our experiments also show that combining heterogeneous models can achieve similar or comparable classification per-formance with that of our best performing model trained on gold-standardannotations.Wehaveshownthatinthe pharma-cologydomain, staticknowledge resourcessuchas dictionaries actuallycontainmoreinformationthanisimmediatelyapparent, and therefore can be utilisedin other,non-static contexts (i.e. todevise high-precision regular expressionpatterns). Including synonymsinthedictionaryordisambiguatingacronymsdidnot improveresultsinthisstudymainlyduetocertaindesign deci-sionsthatsurroundthePKcorpus.Morespecifically,noneofthe taggedacronymswereidentifiedbyAcroMine,whereasmostof theidentifiedsynonymshave simplynotbeentagged appropri-atelyinthetest-set.Generallyspeakinghowever,wewouldexpect asignificantperformanceboostfromapplyingthesemethods.
Weplantoextendthisworkinthefuture.Firstofall,weplan totakeadvantageofalltheannotationsinthePKcorpus.Being abletorecognisebothdrugsanddrug-targetsisessentialforthe taskofidentifyingrelationshipsandinteractionsbetweenthem. Wearealsoveryinterestedtoseeifwecanimproveon,orfindmore accurateregularexpressionpatternsinordertoenrichour“safety net”model.Moreover,choosinga drugnameisaverylongand costlyprocess,andthereforegeneratinggoodqualitycandidates automaticallywouldbeveryuseful.Finally,wewouldliketoextend ourprediction–aggregationalgorithmsoastoassignprobabilities topredictionsoftheknowledge-basedmodels(dictionariesand regularexpressions).
Acknowledgements
ThisresearchwasfundedbytheU.K.EPSRC–Centrefor Doc-toral Training and by the AHRC-funded “History of Medicine” project(grantnumber:AH/L00982X/1).Itwasalsofacilitatedby theManchesterBiomedicalResearchCentreandtheNIHRGreater ManchesterComprehensive Local ResearchNetwork.We would liketothankProf.GarthCooperforhisvaluableadviceand dis-cussion.
References
[1]CohenAM,HershWR.Asurveyofcurrentworkinbiomedicaltextmining.Brief Bioinform2005;6(1):57–71.
[2]AnaniadouS,McNaughtJ.TextMiningforBiologyandBiomedicine.Norwood, MA,USA:ArtechHouse,Inc.;2005.
[3]U.S.FoodandDrugAdministration.HowFDAReviewsProposedDrugNames. www.fda.gov/downloads/Drugs/DrugSafety/MedicationErrors/ucm080867. pdf[online,accessed15.04.15].
[4]WishartDS,KnoxC,GuoAC,ChengD,ShrivastavaS,TzurD,etal.DrugBank: aknowledgebasefordrugs,drugactionsanddrugtargets.NuclAcidsRes 2008;36(Suppl.1):D901–6.
[5]SubhadarshiniA,KarnikS,WangZ,PhilipsS,DukeJ,QuinneyS,etal.An inte-gratedpharmacokineticsontologyandsemanticallyannotatedcorpusfortext mining.In:ProceedingsofSummitonTranslationalBioinformatics.Bethesda, MD,USA:AmericanMedicalInformaticsAssociation(AMIA);2012. [6]LinguisticDataConsortium.ACE(AutomaticContentExtraction)English
Anno-tation Guidelines forEntities; 2008, June www.ldc.upenn.edu/sites/www. ldc.upenn.edu/files/english-entities-guidelines-v6.6.pdf [online, accessed 15.04.15].
[7]Sundheim BM. Overviewof results of the MUC-6 evaluation. In:MUC6 1995:Proceedingsofthe6thConferenceonMessageUnderstanding,MUC6 1995.Stroudsburg,PA,USA:AssociationforComputationalLinguistics;1995, November.p.13–31.
[8]ChinchorNA.MUC-7namedentitytaskdefinition.In:SundheimB,editor. ProceedingsoftheSeventhMessageUnderstandingConference(MUC-7).VA: Fairfax;1998,April[version3.5].
[9]TjongKimSangEF.IntroductiontotheCoNLL-2002sharedtask: language-independentnamedentityrecognition.In:Proceedingsofthe6thConference onNaturalLanguageLearning,vol.20,COLING-02.Stroudsburg,PA,USA: Asso-ciationforComputationalLinguistics;2002.p.1–4.
[10]TjongKimSangEF,DeMeulderF.IntroductiontotheCoNLL-2003sharedtask: language-independentnamedentityrecognition.In:Proceedingsofthe Sev-enthConferenceonNaturalLanguageLearningatHLT-NAACL2003,vol.4, CONLL2003.Stroudsburg,PA,USA:AssociationforComputationalLinguistics; 2003.p.142–7.
[11]LiuF,ChenY,ManderickB.Namedentityrecognitioninbiomedicalliterature: acomparisonofsupportvectormachinesandconditionalrandomfields.In: FilipeJ,CordeiroJ,CardosoJ,editors.ICEIS(SelectedPapers),vol.12of Lec-tureNotesinBusinessInformationProcessing.Berlin&Heidelberg,Germany: Springer;2007.p.137–47.
[12]GoulartRRV,deLimaVLS,XavierCC.Asystematicreviewofnamedentity recognitioninbiomedicaltexts.JBrazComputSoc2011;17(2):103–16. [13]DoanS,XuH.Recognizingmedicationrelatedentitiesinhospitaldischarge
summariesusingsupportvectormachine.In:HuangC-R,JurafskyD,editors. Proceedingsofthe23rdInternationalConferenceonComputational Linguis-tics:PostersCOLING’10.Stroudsburg,PA,USA:AssociationforComputational Linguistics;2010.p.259–66.
[14]Sanchez-CisnerosD,AparicioGaliF.UEM-UC3M:anontology-basednamed entityrecognitionsystemforbiomedicaltexts.In:ManandharS,YuretD, edit-ors.SecondJointConferenceonLexicalandComputationalSemantics(*SEM), vol.2:ProceedingsoftheSeventhInternationalWorkshoponSemantic Eval-uation(SemEval2013).Atlanta,Georgia,USA:AssociationforComputational Linguistics;2013,June.p.622–7.
[15]BjörneJ,KaewphanS,SalakoskiT.UTurku:drugnamedentityrecognition anddrug-druginteractionextractionusingSVMclassificationanddomain knowledge.In:ManandharS,YuretD,editors.SecondJointConferenceon Lexical and Computational Semantics(*SEM), vol. 2: Proceedings of the Seventh InternationalWorkshoponSemantic Evaluation(SemEval2013). Atlanta,Georgia,USA:AssociationforComputationalLinguistics;2013,June. p.651–9.
[16]Segura-BedmarI,MartínezP,HerreroZazoM.Semeval-2013task9: extrac-tionofdrug–druginteractionsfrombiomedicaltexts(DDIExtraction2013). In:ManandharS,YuretD,editors.SecondJointConferenceonLexicaland ComputationalSemantics(*SEM),vol.2:ProceedingsoftheSeventh Inter-nationalWorkshoponSemanticEvaluation(SemEval2013).Atlanta,Georgia, USA:AssociationforComputationalLinguistics;2013June.p.341–50. [17]Rebholz-SchuhmannD,YepesAJJ,vanMulligenEM,KangN,KorsJ,Milward
D,etal.TheCALBCsilverstandardcorpus–harmonizingmultiplesemantic annotationsinalargebiomedicalcorpus.In:ProceedingsoftheThird Inter-nationalSymposiumonLanguagesinBiologyandMedicine,LBM2009.2009, November.p.64–72.
[18]Rebholz-Schuhmann D, Arregui M, Gaudan S, Kirsch H, Jimeno A. Text processing through web services: calling Whatizit. Bioinformatics 2008;24(2):296–8.
[19]SchuemieMJ,JelierR,KorsJA.Peregrine:Lightweightgenename normaliza-tionbydictionarylookup.In:ProceedingsoftheSecondBioCreativeChallenge EvaluationWorkshop,BioCreativeII.Madrid,Spain:CNIOCentroNacionalde InvestigacionesOncológicas,CarlosIII;2007.p.131–3.
[20]WermterJ,TomanekK,HahnU.High-performancegenenamenormalization withGeNo.Bioinformatics2009;25(6):815–21.
[21]AronsonAR,LangF-M.AnoverviewofMetaMap:historicalperspectiveand recentadvances.JAmMedInformAssoc2010;17(3):229–36.
[22]MilwardD,MilliganP.Textdataminingusinginteractiveinformation extrac-tion.In:ProceedingsoftheBioLinkSpecialInterestGrouponTextMining: LinkingLiterature,InformationandKnowledgeforBiology,BioLinkSIG2007. 2007.
[23]Rebholz-SchuhmannD,Jimeno-YepesA,LiC,KafkasS,LewinI,KangN,etal. AssessmentofNERsolutionsagainstthefirstandsecondCALBCsilverstandard corpus.In:CollierN,HahnU,Rebholz-SchuhmannD,RinaldiF,PyysaloS, edit-ors.SemanticMininginBiomedicinevol.714ofCEURWorkshopProceedings. CEUR-WS.org;2010.
[24]Tsuruoka Y, McNaughtJ, TsujiiJ, AnaniadouS.Learningstringsimilarity measuresforgene/proteinnamedictionarylook-upusinglogisticregression. Bioinformatics2007;23(20):2768–74.
[25]Kol˘arikC,Hofmann-ApitiusM,ZimmermannM,FluckJ.Identificationofnew drugclassificationtermsintextualresources.Bioinformatics2007;23(13): i264–72.
[26]HearstMA.Automaticacquisitionofhyponymsfromlargetextcorpora.In: Proceedingsofthe15thInternationalConferenceonComputational Linguis-tics,vol.2,COLING1992.Stroudsburg,PA,USA:AssociationforComputational Linguistics;1992.p.539–45.
[27]ChenES,HripcsakG,XuH,MarkatouM,FriedmanC.Automatedacquisition ofdiseasedrugknowledgefrombiomedicalandclinicaldocuments:aninitial study.JAmMedInformAssoc2008;15(February):87–98.
[28]Feng C, Yamashita F, Hashida M. Automated extraction of information fromtheliteratureonchemical-CYP3A4interactions.JChemInformModel 2007;47(6):2449–55.
[29]HettneKM,StierumRH,SchuemieMJ,HendriksenPJM,SchijvenaarsBJA, Mul-ligenEMv,etal.Adictionarytoidentifysmallmoleculesanddrugsinfreetext. Bioinformatics2009;25(November):2983–91.
[30]RindfleschT,TanabeL,WeinsteinJN,HunterL.EDGAR:extractionofdrugs, genesandrelationsfromthebiomedicalliterature.In:PacificSymposium of Biocomputing. 2000. p. 514–25. Available from: psb.stanford.edu/psb-online/proceedings/psb00/[accessed15.04.15].
[31]UsamiY,ChoH-C,OkazakiN,TsujiiJ.Automaticacquisitionofhugetraining dataforbio-medicalnamedentityrecognition.In:CohenKB,Demner-Fushman D,AnaniadouS,PestianJ,TsujiiJ,WebberB,editors.ProceedingsofBioNLP2011 WorkshopBioNLP2011.Stroudsburg,PA,USA:AssociationforComputational Linguistics;2011.
[32]VlachosA,GasperinC.Bootstrappingandevaluatingnamedentityrecognition inthebiomedicaldomain.In:VerspoorK,CohenKB,GoertzelB,ManiI,editors. ProceedingsoftheHLT-NAACLBioNLPWorkshoponLinkingNaturalLanguage andBiologyLNLBioNLP2006.NewYork,NY:AssociationforComputational Linguistics;2006.p.138–45.
[33]Korkontzelos I,VlachosA,LewinI.Fromgenenamestoactualgenes.In: ProceedingsoftheBioLinkSpecialInterestGrouponTextMining:Linking Literature,InformationandKnowledgeforBiology,BioLinkSIG2007.2007. [34]ThomasP,BobicT,LeserU,Hofmann-ApitiusM,KlingerR.Weaklylabeled
corporaassilverstandardfordrug-drugandprotein–proteininteraction.In: AnaniadouS,CohenK,Demner-FushmanD,ThompsonP,editors.Proceedings oftheWorkshoponBuildingandEvaluatingResourcesforBiomedicalText Mining(BioTxtM)onLanguageResourcesandEvaluationConference(LREC). Instanbul,Turkey:EuropeanLanguageResourcesAssociation(ELRA);2012, May. p. 63–70. Available from: www.lrec-conf.org/proceedings/lrec2012/ workshops/14.BioTxtM-Proceedings.pdf#page=70[accessed15.04.15]. [35]KerrienS,ArandaB,BreuzaL,BridgeA,Broackes-CarterF,ChenC,etal.The
IntActmolecularinteractiondatabasein2012.NuclAcidsRes2012;40(D1): D841–6.
[36]DaganI,EngelsonSP.Committee-basedsamplingfortrainingprobabilistic classifiers.In:PrieditisA,RussellSJ,editors.ProceedingsoftheTwelfth Inter-nationalConferenceonMachineLearningtheMorganKaufmannSeriesin MachineLearning.SanFrancisco,CA,USA:MorganKaufmannPublishersInc.; 1995.p.150–7.
[37]ThompsonCA,CaliffME,MooneyRJ.Activelearningfornaturallanguage pars-ingandinformationextraction.In:BratkoI,DˇzeroskiS,editors.Proceedingsof theSixteenthInternationalConferenceonMachineLearningtheMorgan Kauf-mannSeriesinMachineLearning.SanFrancisco,CA,USA:MorganKaufmann PublishersInc.;1999.p.406–14.
[38]TomanekK,WermterJ,HahnU.Anapproachtotextcorpusconstructionwhich cutsannotationcostsandmaintainsreusabilityofannotateddata.In:Eisner J,editor.Proceedingsofthe2007JointConferenceonEmpiricalMethodsin NaturalLanguageProcessingandComputationalNaturalLanguageLearning (EMNLP-CoNLL).Prague,CzechRepublic:AssociationforComputational Lin-guistics;2007,June.p.486–95.
[39]TsuruokaY,TsujiiJ,AnaniadouS.Acceleratingtheannotationofsparsenamed entitiesbydynamicsentenceselection.In:Demner-FushmanD,AnaniadouS, CohenKB,PestianJ,TsujiiJ,WebberB,editors.ProceedingsoftheWorkshop onCurrentTrendsinBiomedicalNaturalLanguageProcessingBioNLP2008. Columbus,OH,USA:AssociationforComputationalLinguistics;2008,June.p. 30–7.
[40]BergerAL,PietraVJD,PietraSAD.Amaximumentropyapproachtonatural languageprocessing.ComputLinguist1996Mar;22:39–71.
[41]RosenblattF.Theperceptron:aperceivingandrecognizingautomaton,Report 85-460-1,ProjectPARA.Ithaca,NY:CornellAeronauticalLaboratory;1957, January.
[42]RadevD,TeufelS,SaggionH,LamW,BlitzerJ,QiH,etal.Evaluationchallenges inlarge-scaledocumentsummarization.In:Proceedingsofthe41stAnnual MeetingonAssociationforComputationalLinguistics,vol.1.Sapporo,Japan: AssociationforComputationalLinguistics;2003,July.p.375–82.
[43]Mih˘ail˘aC,Batista-Navarro RTB.What’sin aname? Entity typevariation acrosstwobiomedicalsubdomains.In:LisonP,NilssonM,RecasensM, edit-ors.ProceedingsoftheStudentResearchWorkshopatthe13thConference of the European Chapter of the Association for Computational Linguis-tics.Avignon,France:AssociationforComputationalLinguistics;2012,April. p.38–45.
[44]Segura-BedmarI, Martínez P, De Pablo-Sánchez C. Using a shallow lin-guistickernelfordrug–druginteractionextraction.JBiomedInform2011, October;44:789–804.
[45]Okazaki N, Ananiadou S, Tsujii J. Building a high quality sense inven-toryforimprovedabbreviationdisambiguation.Bioinformatics2010;26(9): 1246–53.
[46]ChenSF,GoodmanJ.Anempiricalstudyofsmoothingtechniquesfor lan-guagemodeling.In:Proceedingsofthe34thAnnualMeetingonAssociation forComputationalLinguistics,ACL1996.Stroudsburg,PA,USA:Associationfor ComputationalLinguistics;1996.p.310–8.
[47]JelinekF,MerialdoB,RoukosS,StraussMJ.Self-organizedlanguage model-ingforspeechrecognition.In:WaibelA,LeeK-F,editors.ReadingsinSpeech Recognition.SanFrancisco,CA,USA:MorganKaufmann;1990.p.450–506. [48]KatzSM.Estimationofprobabilitiesfromsparsedataforthelanguagemodel
componentofaspeechrecognizer.IEEETransAcoustSpeechSignalProcess 1987;ASSP-35(March):400–1.
[49]CollinsM,BrooksJ.Prepositionalphraseattachmentthroughabacked-off model.In:YarowskyD,ChurchK,editors.ProceedingsoftheThirdWorkshop onVeryLargeCorpora.Cambridge,MA,USA:AssociationforComputational Linguistics;1995.p.27–38.
[50]RothD,ZelenkoD.Partofspeechtaggingusinganetworkoflinear sepa-rators.In:Proceedingsofthe36thAnnualMeetingoftheAssociationfor ComputationalLinguisticsand17thInternationalConferenceon Computa-tionalLinguistics,vol.2,ACL1998.Montreal,Quebec,Canada:Associationfor ComputationalLinguistics;1998.p.1136–42.
[51]BikelDM,SchwartzR,WeischedelRM.Analgorithmthatlearnswhat’sina name.MachLearn1999;34(February):211–31.
[52]ZhouG,SuJ,YangL.Resolutionofdatasparsenessinnamedentity recogni-tionusinghierarchicalfeaturesandfeaturerelaxationprinciple.In:Gelbukh A,editor.Proceedingsofthe6thInternationalConferenceonComputational LinguisticsandIntelligentTextProcessing,CICLing2005.Berlin&Heidelberg, Germany:Springer-Verlag;2005.p.750–61.
[53]CampbellG,MosimannJE.Multivariatemethodsforproportionalshape.In: ProceedingsoftheSectiononStatisticalGraphics,AnnualMeetingofthe AmericanStatisticalAssociation.Alexandria,VA,USA:AmericanStatistical Association;1987.p.10–7.
[54]HijaziRH(Ph.D.thesis)AnalysisofCompositionalDataUsingDirichlet Covari-ateModels.Washington,DC,USA:TheAmericanUniversity;2003.
[55]HijaziRA,JerniganRW.Modellingcompositionaldatausingdirichletregression models.JApplProbabStat2009;4(1):77–91.
[56]KozaJR,BennettFH,AndreD,KeaneMA.GeneticProgrammingIII:Darwinian InventionandProblemSolving.1sted.SanFrancisco,CA,USA:Morgan Kauf-mannPublishersInc.;1999,May.
[57]BennettPN,DumaisST,HorvitzE.Thecombinationoftextclassifiersusing reliabilityindicators.InformRetr2005;8(January):67–100.
[58]Al-KofahiK,TyrrellA,VachherA,TraversT,JacksonP.Combiningmultiple classifiersfortextcategorization.In:ProceedingsoftheTenthInternational ConferenceonInformationandKnowledgeManagement,CIKM2001.New York,NY,USA:ACM;2001.p.97–104.
[59]YangY,AultT,PierceT.Combiningmultiplelearningstrategiesforeffective cross-validation.In:FurnkranzJ,JoachimsT,editors.InternationalConference onMachineLearning.Madison,WI,USA:TheInternationalMachineLearning Society;2000.p.1167–74.
[60]Bi Y, Mcclean S, Anderson T. Combining rough decisions for intelligent text mining using Dempster’srule. Artif Intell Rev 2006;26(November): 191–209.
[61]SiL.Boostingperformanceofbio-entityrecognitionbycombiningresultsfrom multiplesystems.In:Proceedingsofthe5thInternationalWorkshopon Bioin-formatics,BIOKDD2505.NewYork,NY,USA:ACMPress;2005.p.76–83. [62]PoliR,LangdonWB,McPheeNF.AFieldGuidetoGeneticProgramming;2008.
Publishedvialulu.comandfreelyavailableat:www.gp-field-guide.org.uk, WithcontributionsbyJ.R.Koza[accessed15.04.15].