International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
A Protocol for Secure Mining of Association principle in HDDs
based on QDM
R.Raju
1& J.Raja Shekar
21
M-Tech Dept. of CSE St.Peter’s Engineering College, Hyderabad, TS, INDIA 2Assistant Professor Dept. of CSE St.Peter’s Engineering College, Hyderabad, TS, INDIA
Abstract:
We propose a protocol for secure mining of association principles in horizontally distributed databases. This leading protocol is that of Kantarcioglu and Clifton. Our protocol, like theirs, relies on the quick Distributed Mining (QDM) formula of Cheung et al. that is associate unsecured distributed version of the Apriori principle. The most ingredients in our protocol are two novel secure multi-party algorithms one that computes the union of personal subsets that every of the interacting group of actors hold, and second one that tests the coupling of a component control by one actor in an exceedingly set control by another. Our protocol offers increased privacy with relevance the protocol. Additionally, it is less complicated and is considerably a lot of economical in terms of
communication rounds, communication value and machine value.
Key-Terms: Privacy protectiveData processing; DistributeCalculation; Regular Item Sets; AssociationPrinciples.
1.
Introduction
We study here the matter of secure mining of association principles in horizontally partitioned off databases. In this setting, there square measure many sites (or actor) that hold same databases, i.e., databases that share an equivalent schema however hold data on totally different entities. The goal is to search out all association principles with support a minimum of s and confidence a minimum of c, for a few given minimal support size s and confidence level c, that hold within the unified Information, whereas minimizing the knowledge disclosed regarding the personal databases command by those actor. the knowledge that we'd wish to defend during this context isn't solely individual
transactions within the totally different
databases, however additionally a lot of world data like what association principles square measure supported domestically in every of these databases. That goal defines a retardant of secure multi-party Calculation. In such issues, there square measure M actor that hold personal
inputs, x1, . . . , xM, and that they would like to firmly work out y = f(x1, . . ., xM) for a few public perform f. If there existed a trustworthy third party, the actor might surrender to him their inputs and he would perform the perform analysis and send to them the ensuing output. Within the absence of such a trustworthy third party, it's required to plan a protocol that the actor will run on their own so as to make the desired output y. Such a protocol is taken into account dead secure if no actor will learn from his read of the protocol quite what he would have learnt within the perfect setting wherever the Calculation is administered by a trustworthy third party. Yao was the primary to propose a generic answer for this downside within the case of two actors. Alternative generic solutions, for the multi-party case.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
support and confidence no smaller than the given thresholds s and c, severally. Because the on top of mentioned generic solutions rely on an outline of the perform f as a Boolean circuit, they'll be applied solely to tiny inputs and functions that square measure realizable by easy circuits. in additional complicated settings, like ours, alternative strategies square measure needed for winding up this Calculation. In this cases, some reductions of theidea of good security could be inevitable once longing for sensible protocols, as long as the surplus data is deemed benign (see samples of such protocols studied that downside devised a protocol for its answer). the most a part of the protocol could be a sub-protocol for the secure Calculation of the union of personal subsets that square measure command by the various actors. (The personal set of a given actor, as we have a tendency to justify below, includes the item sets that square measure s-frequent in his partial Information.) That’s the foremost expensive a part of the protocol and its implementation depends upon science primitives like independent encoding, oblivious transfer, and hash functions. This can be additionally the sole half within the protocol during which the actors could extract from their read of the protocol data on alternative databases, on the far side what's inexplicit by the ultimate output and their own input. Whereas such outpouring of knowledge renders the protocol not dead secure, the perimeter of the extra data is expressly delimited and it's argued there that such data outpouring is innocuous, wherefrom acceptable from a sensible purpose of read.
Here in we have a tendency to propose an alternate protocol for the secure Calculation of the union of personal subsets. The projected protocol improves upon that in terms of simplicity and potency yet as privacy. Above all, our protocol doesn't rely on independent encoding and oblivious transfer (what simplifies
it considerably and contributes towards abundant reduced communication and process costs). Whereas our answer continues to be not dead secure, it leaks excess data solely to a tiny low variety (three) of potential coalitions, in contrast to the protocol of that discloses data additionally to some single actors. Additionally, we have a tendency to claim that the surplus data that our protocol could leak is a smaller amount sensitive than the surplus data leaked by the protocol. The protocol that we have a tendency to propose here computes a parameterized family of functions, that we have a tendency to decision threshold functions, during which the two extreme cases correspond to the issues of computing the union and intersection of personal subsets. Those square measure really all-purpose protocols which will be employed in alternative contexts yet. Another downside of secure multiparty Calculation that we have a tendency to solve here as a part of our discussion is that the set inclusion problem; specifically, the matter wherever Alice holds a non-public set of some ground set, and Bob holds a component within the ground set, and that they would like to see whether or not Bob’s component is among Alice’s set, while not revealing to either of them data regarding the opposite party’s input on the far side the on top of delineate inclusion. In Section II we have a tendency to describe connected Work. In Sections III Objectives and Motivations and IV we have a tendency to discuss the implementation of the two remaining
steps of the distributed protocol: The
identification of these candidate item sets that square measure globally s frequent, then the derivation of all (s,c)-association principles. I have a tendency to conclude the paper in Section v.
2.
Related work
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
employed in several reality applications. it's accustomed reveal surprising relationships within the Information. During this paper, we'll discuss the matter of computing association principles among a horizontally partitioned off Information. we tend to assume same databases. All sites have identical schema, however every website has Information on totally different entities. The goal is to provide associate particle principles that hold globally, whereas limiting the data shared regarding every website to preserve the privacy of Information in every site.
A. Association Principle Mining
Association principle mining finds fascinating associations and/or correlation relationships among massive sets of Information things. Association principles show attributes worth conditions that occur of times along in a very given dataset.
Association Principles
The association principle mining drawback was developed by Agrawal in 1993 and is commonly named as market-basket drawback. During this drawback, set of things is given and enormous assortment of dealings is occurred, that are subsets of those things. The task is to seek out relationship between the presences of varied
things among these baskets. Association
principle mining is to seek out association principles that satisfy the predefined minimum support and confidence from given Information. The matter is typically rotten into two sub issues. One is to seek out those itemsets whose occurrences exceed a predefined threshold within the database; those item sets are known as frequent or massive itemsets with the constraint of bottom confidence. Let I= be a group of things. Let D is that the task relevant Information and a group of Information dealings wherever every dealings T could be a set of things such T ⊆ I. every dealings is related to
associate degree symbol, called TID. Let A be the set of things. A dealings T is contained A if and provided that A ⊆ T. associate degree
association principle is associate degree
Implication of the shape A⟹B, wherever A ⊂ I, B ⊂ I and A ⋂ B = ∅ . The principle A⟹B holds the dealings set D with the assistance of support s, wherever s is termed because the share of dealings in D that contains A ⋃ B. this can be taken to be the chance, P(A ⋃ B). The principle A⟹B has confidence c within the dealings set D, wherever c is termed because the share of dealings in D containing A that additionally contain B. this can be the probability, p(B|A). That is, Support (A⟹B) = P(A⋃B) Confidence
(A⟹B)= p=(B|A) normally, association
principle mining are often viewed as a two step process:
i. Realize All Frequent Itemsets:
Here, every of this item sets can occur a minimum of as of times as a planned minimum support count, min_sup.
Generate little association principles from the frequent itemsets:
During this step, these principles mast satisfy minimum support and minimum confidence.
Apriori formula
The Apriori formula planned to finds frequent
things in very given Information set
mistreatment the hymenopter on monotone
constraint. Apriori is associate degree
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
(k+1) itemsets.Apriori formula is associate degree in fluential formula for mining frequent item sets for Boolean association principles. This formula contains variety of passes over the Information. Throughout pass k, the formula finds the set of frequent item sets Lk of length k that satisfies the minimum support demand.
Apriori is intended to control on
databasescontaining transactions. The aim of the Apriori formula is to seek out associations between totally different sets of Information. It’s generally named as "Market Basket Analysis". Every set of Information features a variety of things and is termed dealings. The output of Apriori is sets of principles that tell North American nation however usually things are contained in sets of Information. Verification if the auditor is convinced with the Information integrity; the auditor erases the native data.
Privacy protective data processing
Privacy protective data processing is outlined as protective the individual privacy and retentive the data in dataset to be free for mining. The paper [1] analyzed the privacy offered by protocol UNIFI-KC. That protocol doesn't respect good privacy since it leaks actor’s data. This paper used anonymous ID assignment (AIDA) for protective privacy to the actor's Information. Currently, there is a unit such a lot of applications that need dynamic distinctive IDs. Such IDs will be used for knowledge storage, sharing knowledge and alternative resources anonymously and while not conflict. In AIDA, Random integers between one and S area unit chosen by every node [11].
Principle:Given nodes, n1, n2....nN uses distributed computation to search out associate degree anonymous categorization permutation.
S: →
1) Set the amount of appointed nodes A=0.
2) Each unassigned node rangeni chooses a random number Ocean State within the vary one to S. A node appointed in an exceedingly previous spherical chooses ri=0.
3) The random numbers area unit shared anonymously. Denote the shared values by q1, q2,...qN .
4) Let q1....qk denote a revised list of shared values with duplicated and nil values entirely removed wherever k is that the variety of distinctive random values. The nodes range nithat historian distinctive random numbers then confirm their index si from the position of their random number within the revised list because it would seem once being sorted: si=A+ Card
5)Update the amount of nodes assigned: A=A+k.
6)If Acome to step (2).
The quick Distributed Mining algorithmic principle
This paper is predicated on the Privacy protective quick Distributed Mining principle (PPQDM) that may be a combination of protective privacy associate degreed quick Distributed mining principleprinciple that is an
unsecured distributed version of the
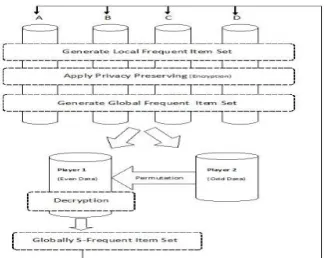
Aprioriprinciple. Its main plan is that any s-frequent item set should be additionally regionally s-frequent in a minimum of one in every of the sites. Hence, so as to search out all globally s-frequent item sets, every actor reveals his regionally s-frequent item sets and so the actors check every of them to visualize if they're s-frequent additionally globally. The QDM principle income as follows:
[1] Candidate Sets Generation:
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
behind the candidate set generation is that if associate degree itemset X has minimum support, therefore do all subsets of X. thence the
actor then applies set the
Aprioriprincipleicprinciple on LK-1 so as to come up with the set of candidate k-item sets.
[2] Native Pruning:
The pruning step eliminates the extension of (K-1) itemsets that aren't found to be frequent. Here, actor pm computes suppm(X). He retains solely those item sets that area unit regionally s-frequent. we tend to denote this assortment of item set by Csk,m .
[3] Computing Native Supports:
All actors calculate the native supports of all item sets in Csk,m .
Broadcast mining results: every actor broadcasts the native supports that he computed. From that, everybody will calculate the worldwide support of each item set in Csk,m . Finally, Fsk is that the set of Csk,m that consists of all globally s-frequent k-item sets.
Fig 1: Design of PPQDM (Privacy Protective Quick DistributedData Mining)
3. Objectives and Motivations
Objectives usually, data mining (sometimes referred to as knowledge or Information discovery Information (KDD)) is that the
process of analyzing knowledge from
completely different views and summarizing it into helpful data. Data which will be wont to increase revenue, cuts costs, or each data processing software package is one in every off variety of analytical tools for analyzing knowledge. It permits users to investigate knowledge from many various proportions or angles, cause it, and summarize the associations known. Technically, data is that the process of
finding correlations or patterns among
completely different fields in massive relative databases. Building an appropriate knowledge set for data processing functions may be a time- intense task. This task usually needs writing long SQL statements or customizing SQL Code if it's mechanically generated by some tool. There are two main ingredients in such SQL code: joins and aggregations; we tend to specialize in the second. The foremost widely-known aggregation is that the total of a column over teams of rows. Other aggregationscome the typical, highest, and lowest or row count over teams of rows. There
exist several aggregations functions and
operators in SQL. Sadly, of these aggregations have limitations to make knowledge sets for data processing functions.
The main reason is that, in general, knowledge sets that area unit keep in exceedingly relational Information (or a knowledge warehouse) come back from On-Line dealings process (OLDP) systems wherever database schemas area unit extremely normalized. However data processing, applied math or machineLearning Principles
usually need aggregate knowledge in
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
optimized and tested. There are additional sensible reasons to come aggregation ends up in a horizontal (cross-tabular) layout. Customary aggregations area unit laborious to interpret once there are a unit several result rows, particularly once grouping attributes have high cardinalities. To do analysis of exported tables into spreadsheets it's going to be additional convenient to possess aggregations on constant cluster in one row (e.g. to supply graphs or to
check knowledge sets with repetitive
Information). OLAP tools produce SQL code to transpose results (sometimes referred to as PIVOT). Transposition will be additional economical if there area unit mechanisms combining aggregation and transposition along. With such limitations in mind, we tend to propose a brand new category of combination functions that combination numeric expressions and transpose results to supply a knowledge set with a horizontal layout. Functions happiness to the present category area unit referred to as horizontal aggregations. Horizontal aggregations represent associate degree extended kind of ancient SQL aggregations, that come a collection of values in an exceedingly horizontal layout (somewhat just like a dimensional vector), rather than one price per row. This text explains the way to estimate and optimize horizontal aggregations generating customary SQL code.
A. Data Processing Techniques
The most unremarkably used techniques in data processing are:
a. Clustering:
Knowledge things area unit sorted in keeping with logicalRelationships or client preferences. As an example, knowledge will be Strip-mined to mark market segments or client affinities.
b. Associations Principle:
Knowledge will be strip-mined to spot associations. The beer-diaper example is associate degree example of associative mining.
c. Ordered Patterns:
Knowledge is strip-mined to anticipate behavior patterns and trends. as an example, an out of doors instrumentality distributor might predict the chance of a backpack being purchased supported a consumer's purchase of sleeping luggage and hiking shoes.
d. Artificial neural networks:
Non-linear prognosticative models that learn through coaching and gibe biological neural networks in structure.
e. Genetic principles:
Improvement techniques that use method like genetic combination, mutation, and action in an exceedingly style supported the ideas of natural evolution.
f. Decision Trees:
Arborous structures that represent sets of selections. These choices generate principlesfor the classification of a dataset. Specific call tree strategies embrace Classification and Regression
Trees (CART) and Chi sq. Automatic
Interaction.Detection (CHAID) CART and CHAID area unit call tree techniques used for classification of a dataset. they supply a collection of principles that you simply will apply to a brand new (unclassified) dataset to predict that records can have a given outcome.
g. Nearest Neighbor Method:
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
generally referred to as the k-nearest neighbor technique
h. PrincipleInduction:
The extraction of helpful if-then principles from knowledge supported applied math significance.
i. Knowledge Visualization:
The visual interpretation of complicated
relationships in dimensional knowledge.
Graphics tools area unit won’t to illustrate knowledge relationships.
4. Experimental Evaluations
In Section IV.A we tend to describe the artificial Information that we tend to used for our experimentation. In SectionIV.2 we tend to make a case for however the Information was split horizontally into partial databases. In SectionIV.3 we tend to describe the experiments that we tend to conducted. The results square measure given in SectionIV.4.
a) Artificial Information Generation
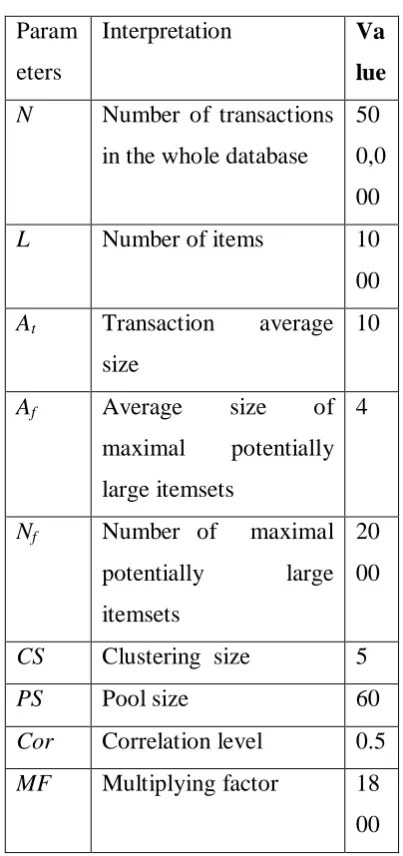
The databases that we tend to employed in our experimental analysis square measure artificial databases that were generated victimisation an equivalent techniques that were introduced in [2] so used conjointly in resultant studies like [9]. Table one provides the parameter values that were employed in generating the artificial Information. The reader is observed [9] for an outline of the artificial generation technique and also that means of every of these parameters. The parameter values that we tend to used here square measure just like those employed in [9].
Table 1: Parameters for Generating the
artificial Information.
b) Distributing the Information:
Given a generated artificial Information D of N
transactions and variety of actors M, we tend to
produce a man-made split of D into M partial
databases, Dm, 1 ≤ m ≤ M, within the following manner: for every one ≤ m ≤ M we tend to draw
a random variety wm from a traditional
distribution with mean one and variance zero.1, Param
eters
Interpretation Va
lue
N Number of transactions
in the whole database 50
0,0
00
L Number of items 10
00
At Transaction average
size
10
Af Average size of
maximal potentially
large itemsets
4
Nf Number of maximal
potentially large
itemsets
20
00
CS Clustering size 5
PS Pool size 60
Cor Correlation level 0.5
MF Multiplying factor 18
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
wherever numbers outside the interval [0.1, 1.9]
square measure unnoticed. Then, we tend to
normalize those numbers in order that ΣMm=1
wm = one. Finally, we tend to haphazardly split
D into m partial databases of expected sizes of
wm N, 1 ≤ m ≤ M, as follows: every group
action t ∈ D is appointed every which way to at
least one of the partial databases, in order that Pr
(t ∈Dm) = wm, 1 ≤ m ≤ M.
5. Experimental Results
Fig.1 shows the values of the 3 measures that
were listed in Section four.3 as a perform of N.
all told of these experiments, the worth of M and
s remained unchanged M = ten and s = zero.1.
Fig.2 shows the values of the 3 measures as a
perform of M; here, N = 500, zero and s = 0.1.
Fig.3 shows the values of the 3 measures as a
perform of s; here, N = 500, 000 and M = ten.
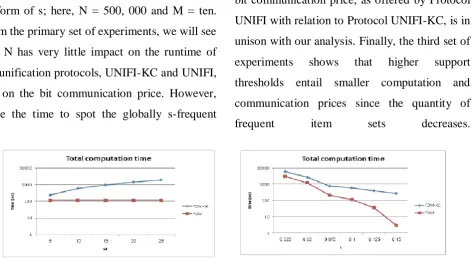
From the primary set of experiments, we will see
that N has very little impact on the runtime of
the unification protocols, UNIFI-KC and UNIFI,
nor on the bit communication price. However,
since the time to spot the globally s-frequent
item sets will grow linearly with N, which
Procedure is administrated within the same
manner in FDM-KC and FDM, the advantage of
Protocol FDM over FDM-KC in terms of
runtime decreases with N. whereas for N = one
hundred, 000, Protocol FDM is twenty two times
quicker than Protocol FDM-KC, for N = five
hundred, 000 it's 5 times quicker.
The total computation times for larger values of
N retain an equivalent pattern that emerges from
Fig.1; for instance, with N = 106 the entire
computation times for FDM-KC and FDM were
744.1 and 238.5 seconds, severally, which
supplies AN improvement issue of three.1. The
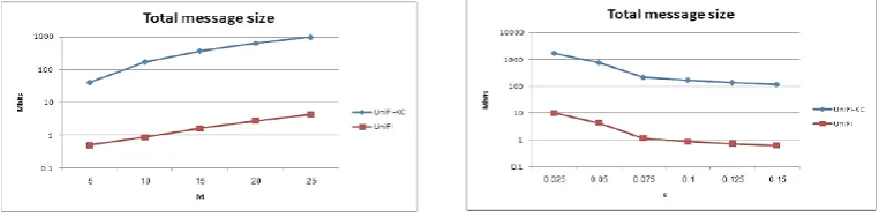
second set of experiments shows however the
computation and communication prices increase
with M. above all, the advance think about the
bit communication price, as offered by Protocol
UNIFI with relation to Protocol UNIFI-KC, is in
unison with our analysis. Finally, the third set of
experiments shows that higher support
thresholds entail smaller computation and
communication prices since the quantity of
frequent item sets decreases.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
Fig 3: Computation and communication prices versus the quantity ofActors M.
Fig 4: Computation and communication prices versus the supportThresholds.
6.
Conclusion
We planned a protocol for secure mining of association principles in horizontally distributed databases that improves considerably upon this leading protocol in terms of privacy and potency. One in every of the most ingredients in our planned protocol could be a novel secure multi-party protocol for computing the union (or intersection) of personal subsets that every of the interacting actors holds. Another ingredient could be a protocol that tests the inclusion of part command by one player during a set command by another. Those protocols exploit the actual fact that the underlying downside is of interest only if the quantity of actors is larger than 2. One analysis downside that this study suggests was described; specifically, to plot AN economical protocol for difference verifications that uses the existence of a semi honest third party. Such a protocol would possibly change to any improve upon the communication and machine prices of the second and third stages of
the protocol of, as delineated. different analysis issues that this study suggests is that the implementation of the techniques conferred here to the matter of distributed association principle mining within the vertical setting, the matter of mining generalized association principles, and also the downside of subgroup discovery in horizontally divided Information.
7.
References
[1] TamirTassa, ―Secure Mining of
Association Rules in Horizontally
Distributed Databases‖, IEEE Transactions on Knowledge and Data Engineering.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 10, October 2015Available at http://internationaljournalofresearch.org
[3] R. Agrawal and R.
Srikant.Privacy-preservingdata mining. In SIGMOD
Conference, pages 439–450, 2000.
[4] D. Beaver, S. Micali, and P. Rogaway. The round complexity of secure protocols. In STOC, pages 503–513, 1990.
[5] M. Bellare, R. Canetti, and H. Krawczyk.
Keying hash functions for message
authentication. In Crypto, pages 1–15, 1996.
[6] A. Ben-David, N. Nisan, and B. Pinkas. FairplayMP -A System for secure multi-party computation. In CCS,Pages257–266,2008.
[7] J.C. Benaloh. Secret sharing
homomorphism’s: Keeping shares of a secret secret. In Crypto, pages 251–260, 1986.
[8].Ms. Manali Rajeev Rautand Ms.
HemlataDakhore, Association Rule Mining in Horizontally DistributedDatabases. Pages 7540-7544, 2014.
[9].Mr. Jay Deepa, A Protocol for Secure Mining ofAssociation Rules in Horizontally
Distributed Databases, Pages 1198-1203,
2014257–266, 2008.
K.suresh received B.Tech Degree from
Annamacharya Institute of Technology
And Science, Tirupati. He is currently in
Pursuing M. Tech Degree in Computer Science
specialization in Shree Rama
Educational Society Group of
InstitutionsTirupati, Andhra Pradesh, India.
1. CK. Hemantha Rama received M.Tech
Degree in Computer Science & Engineering
from Madanapalle Institute of Technology
and Science, Madanapalle. She is currently
working as Assistant Professor in the Dept of
CSE, Shree Rama Educational Society Group of
Institutions, Tirupati, and Andhra Pradesh,
India.