Question Classification Based on an Extended Class Sequential Rule
Model
Zijing Hui, Juan Liu*, Lumei Ouyang
Computer School, Wuhan University, Wuhan 40072, P. R. China
{zijinghui, liujuan, ouyanglumei}@whu.edu.cn
Abstract
Question classification is a crucial preprocessing for question answering system; it can help to make sure the user’s intention. Most of previous researches fo-cus on the feature driven methods that represent a question with a bag of features, which ignore the im-portant information contained in the words order and distance. To take such information into account, this paper proposes to describe the questions via the ExCSR (Extended Class Sequential Rule) model. To mine ExCSR rules, a method based on PrefixSpan, called DS-SRM (Distance Sensitive Sequential Rule Miner), is presented as well. Due to the existence of redundancy in the mined rules, a rule selection algo-rithm MCRSelection (Most Cover Rule Selection) is also proposed to find the most interesting rules. Ex-periments results on UIUC question set1 show that the proposed method can achieve the accuracy of 90.6%, which outperforms the previously reported results.
1
Introduction
Question classification, i.e., classifying ques-tions into predetermined types, is quite an im-portant problem in question answering (QA) sys-tem, it helps to make clear the intention of users so that the system can choose the appropriate strategies of answers searching and ranking. Similar to other classification problems, question classification usually needs to build the classifier from the training data which contains a set of labeled questions; the classifier is then used to classify the unlabeled questions.
Although questions are special kinds of texts, question classification is more challenging than text classification. Compared to normal texts, a question is usually a very short sentence (some even with few of words), and mostly one word just occurs once in one question, which results that the widely used vector space model (mainly based on TF/IDF) fails to work. To address this problem, researchers usually develop a lot of
* the corresponding author
1 http://cogcomp.cs.illinois.edu/Data/QA/QC/
tures, such as location, organization, name, etc., to annotate the words/phrases in the questions, and then use the bag of features to represent the questions. However, such methods still suffer some problems. (1) To get the satisfactory classi-fication performances, they usually need an ex-tremely large amount of features. For example, Li et al. used more than 200,000 features (Li et al., 2006) to represent questions in UIUC ques-tion set, while Huang et al. used 13,697 binary features in their best feature space (Huang et al., 2008). (2) The bag of features representation ig-nores the relationship and the order information among words within the questions, which will cause the misclassification. For example, “Which city is famous for rose?” and “Which rose is fa-mous for city?” belong to two different classes (the former one asks about the <location>, while the later one is about the <entity> or <plant>), due to that “rose” and “city” have different or-ders. (3) The information of word distance is valuable in question classification yet is not con-sidered by the present methods. For example, “How many people did Randy Craft kill?” asks about the <number>, while “How Randy Craft killed many people?” is about the <description>. The difference of the distances between “how” and “many” plays a role on the types of the ques-tions. CSRs (Class Sequential Rules) originally proposed for opinion extraction (Hu and Liu, 2006) take the word sequences into account. However, it still ignores the distance information between words.
In this paper, we extend the representation of CSRs by integrating the distance information into it, and propose the ExCSR (Extended Class Sequential Rule) model. To mine the ExCSRs, we further propose an algorithm, called DS-SRM (Distance Sensitive Sequential Pattern Miner), based on PrefixScan (Pei et al., 2004). To re-move the redundancy of the mined rules, we pre-sent an efficient rule selection method, MCRSe-lection (Most Cover Rule SeMCRSe-lection). The re-mainder of this paper is organized as follows: section 2 introduces the related works; section 3
describes the CSR and its extension ExCSR; the rule mining and selection algorithms are present-ed in section 4; section 5 is the evaluation exper-iments and results; the paper ends with the con-cluding remarks in the last section.
2
Related Works
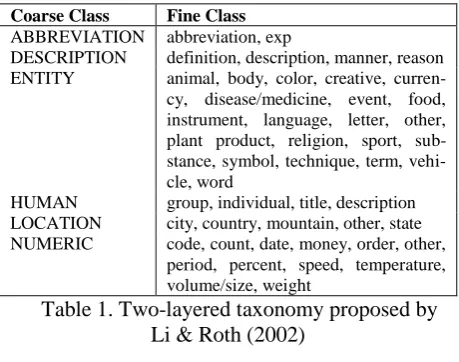
Question classification is a process that assigns a question to a single category or a set of catego-ries. The categories can be organized as either flat or hierarchical taxonomies. Li & Roth (2002) defined a two-layered taxonomy shown in Table 1. The taxonomy consists of six coarse categories and a total of 50 finer categories. Since this tax-onomy has been regarded as somewhat informal standard and has been used in much other work on question classification, it is also used in our paper. Given the taxonomy, the classification machinery is then needed to put the questions into specific category or categories. There are two main machineries for the classification, i.e., manual and automatic. The manual methods (Hermjakob, 2001) use hand-written rules and heuristics to do the classification, thus it is time consuming and hard to extend to new question categories; while the automatic methods classify the questions based on machine learning tech-nologies or statistical methods, thus are much more efficient and easy to extend to new ques-tion types. Therefore, most of the work follows the automatic methods, which will be also adopt-ed in our work. There are many machine learning methods have been proposed for automatic ques-tion classificaques-tion. Radev et al. (2002) proposed to learn rules by using decision tree method, after trained on TREC-8 and TREC-9, it reached an accuracy of around 70% on TREC-10. Li and Roth (2002) reported a hierarchical approach based on the SNoW learning architecture. By trained on 5500 questions and tested on 500 questions from TREC-10, which are collected in UIUC dataset, it reached an accuracy of 84.2%. Zhang and Lee (2003) used linear SVMs with all possible question word grams, and obtained ac-curacy of 79.2%. Krishnanet al. (2005) used a short sequence called informer span as important features that are identified by the Conditional Random Field (CRF), and built a meta-classifier using a linear SVM on the features. Their model got the accuracy of 86.2% on UIUC question set. Li and Roth (2006) used more semantic infor-mation in WordNet, plus their originally pro-posed syntactic ones (Li & Roth, 2002), after being trained on 21500 questions, their model
achieved an accuracy of 89.3% on a test set of 1000 questions. Li et al. (2008) propose to classi-fy what-type questions by head noun tagging and achieve 85.60% accuracy. Huang et al. (2008; 2009) used much more compact feature set than Li and Roth’s work, by taking the head words and their hypernyms as features, with other standard features such as unigrams, they ob-tained accuracy of 89.2% using linear support vector machine (SVMs), and 89.0% using Max-imum Entropy (ME) model. Ray et al. (2010) used the semantic features of the WordNet and the vast knowledge repository in Wikipedia to build the classification model. They trained their model over 5500 questions in UIUC, and tested it over 2393 questions from five TREC collec-tions, and got the average precision of 89.55%. However, to our best knowledge, all of the pre-sent works seldom consider the word sequence and word distance for question classification problem. In this paper, we exploit the infor-mation of word sequence and word distance in the questions and develop an efficient classifica-tion method. The details of the proposed methods will be provided in the next sections.
Coarse Class Fine Class
ABBREVIATION abbreviation, exp
DESCRIPTION definition, description, manner, reason ENTITY animal, body, color, creative, curren-cy, disease/medicine, event, food, instrument, language, letter, other, plant product, religion, sport, sub-stance, symbol, technique, term, vehi-cle, word
HUMAN group, individual, title, description LOCATION city, country, mountain, other, state NUMERIC code, count, date, money, order, other,
period, percent, speed, temperature, volume/size, weight
Table 1. Two-layered taxonomy proposed by Li & Roth (2002)
3
Class Sequential Rule Model and Its
Extension
Class sequential rule (CSR) model was originally proposed to represent the labeled sequences in the research of opinion feature extraction (Hu & Liu, 2006). For the completeness of this paper, we first introduce CSR model, then state its ex-tension model ExCSR in this section.
3.1 Class Sequential Rule Model
Let I = {i1, i2, ..., in} be a set of items, and an
el-ement or itemset be a non-empty set of items. A
2007). An item can occur only once in an ele-ment of a sequence, but can occur multiple times in different elements. each English word is an item and the class label is in the right side.
Id Sequence Class
1 <What difference between> Desc:desc
2 <Who> Human:ind
3 <How much weight> Count:weight 4 <How much> Count:money 5 <What be NN> Desc:def
Table 2. Examples of CSRs
A data instance (si, yi) in D is said to cover the portion of instances in D that covers the rule also satisfies the rule.
3.2 Extended Class Sequential Rule Model
Although the CSR takes the word sequence into account, it still ignores the distance information between words/phrases which should be also important to question classification. Therefore, we extend the representation of CSRs by consid-ering the distance information. The extended class sequential rule model is called ExCSR hereinafter.
First, we define three simple kinds of distance constraints, shown in Table 3.
Index Distance tance, [ANY] can be omitted. Table 3. Definition of distance labels
Suppose <x1x2 … xr>→y be a CSR rule, then we define an ExCSR as <d1x1d2x2… drxrdr+1>→y, where di takes one of the distance constraints in Table 3, which limits the occurring distance be-tween elements xi-1 and xi when the rule is select-ed to match an instance for classification. For d1, we can image that there is a special element “x0”
representing the beginning of a sentence, there-fore, d1 is used to constrain the occurring dis-tance of x1 apart from the beginning of a sentence. Similarly, dr+1 constrains the occurring distance of xr to the end of a sentence.
Then, taking the CSR rules in Table 2 as ex-amples, their extended ExCSR rules might be in the forms listed in Table 4. The support and con-fidence of an ExCSR is just the same as its origi-nal CSR.
Table 4. Possible ExCSR examples originated from CSRs in Table 2.
It is noticeable that if only [ANY] is used, then the ExCSR model is actually the same as CSR model. Furthermore, by using ExCSR model, more compact rules that are usually ignored in CSRs mining but play important roles in ques-tion classificaques-tion will be considered. For exam-ple, the CSR “<in what year> → date” is too short that it may cover many questions belonging to different classes which causes its confidence may be lower than the threshold; while its corre-sponding ExCSR “< [NEIGH] in [NEIGH] what [NEIGH] year [ANY] > → date” cannot cover so many questions with conflicted classes as the CSR due to the distance constraint, thus it should have higher confidence and be included in the final classification model.
4
DS-SRM: ExCSRs Mining Method
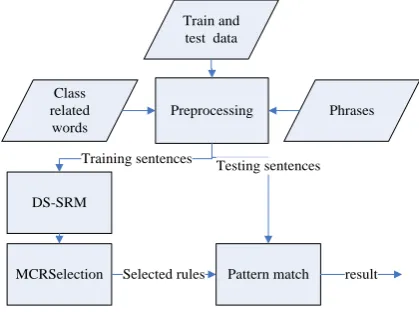
DS-SRM consists of three parts: preprocessing, mining and rules filtering, shown in Figure 1.
support (min_sup) and minimum confidence (min_conf) requirements from the sequences. Since the distance label [ANY] covers [NEIGH] and [NEAR], the mined ExCSR set should con-tains a lot of redundant rules with the same ele-ment sequences but different distance labels. Therefore, the filtering step is required to remove the redundancy of the rule set. The filtered ExCSRs are to be used to classify the unseen question sentences.
Figure 1. The workflow of DS-SRM
4.1 Preprocessing the Question Texts
Now that the question sentences are in the form of raw texts and cannot be directly used for the rules mining purpose, it’s necessary to do the preprocessing by scanning each sentence to do annotation, chunking, and so on. By doing this, each sentence is re-organized by a set of ele-ments with semantic information, especially with the words related to class information. This paper performs the following main preprocessing: (1) Phrases recognition
There are some phrases consisting of several noun words, which can represent entity classes as a whole, yet each word of it may has different meanings. For example, “state flower” denotes a kind of “plant” where “state” is just as a modifier of “flower”. While “state” could be regarded as a “location” and “flower” is a kind of “plant” if “state” and “flower” are separately considered. Therefore, we need to recognize such kinds of phrases to avoid ambiguity. We first collect a lot of frequent phrases by grouping the adjacently occurring words from the web pages according to the mutual information statistics. And then locate the ambiguous phrases within the question sentences and manually annotate them with the related class labels (It should be noticed that this
processing just recognizes out the phrases of am-biguity, not all phrases or the name entities). (2) Named entities recognition
A named entity recognizer (NER) of Stanford (Finkel et al., 2005) which defines four types of entities is used to assign a semantic type to noun phrases in a sentence.
For example, a question “What was W.C. Fields ' real name?” will be changed into “What was [person_name] ' real name?” after the using
NER, which will be helpful to assign this ques-tion to correct class. However, if we do not tag “W.C. Fields” as a person’s name, it will be dif-ficult to correctly identify the question’s class. (3) Part-Of-Speech (POS) tagging
POS is important syntactic information in text preprocessing, and it allows us to generate gen-eral rules. In our wok, we have used the Stanford Log-linear Part-Of-Speech (Toutanova et al., 2003) to do POS tagging.
(4) Chunking
Besides POS tagging, we also use a chunker, also called as shallow parser, to find out some special structures and phrases and then to elimi-nate the adjunct words which may have bad im-pacts on the classification.
For example, in the following question: What is a group of turkeys called? (Huang, et al. 2008)
The word “turkeys” acts as the central word and contributes to classifying question as “ani-mal”, however, the phrase “a group of” would introduce ambiguity to misclassify this question to “human group”. Therefore, we need to deal with such kinds of phrases. In this work, we adopt the Illinois chunker package (Mavronico-las et al., 1991).
(5) Class related words tagging
For each type of question, there are usually some words related to the question class. Li et al., (2002) have built a list of related words for each question class in their research. For example, for class “food”, the related words set would be { al-coholic, apple, beer, berry, breakfast, brew, but-ter, candy, cereal, champagne, cook, eat, sweat...}. Using the class label to tag such related words would be very useful for the question clas-sification. However, the class related words may be nouns, verbs and adjectives, and we have found that the verbs and adjectives would cause the ambiguity in our test. Therefore, we only use the nouns in the class related word sets collected by Li et al. (2002). Nevertheless, there still may-be exist the word ambiguity problem. At present, we just ignore it for it has less impact on the per-formance of our ExCSR rules.
Class related words
Preprocessing
DS-SRM
MCRSelection
Train and test data
Pattern match Phrases
Training sentences
Testing sentences
After the preprocessing, the each question sen-tence will be transformed into a sequence of tri-plets <[pos], word, [cid]>, where “pos” and “cid” are the POS and class tags of the word respec-tively. For those wh words (“what”, “when”, “who”, “how”…), the “pos” in the triplet is left blank; for any words except those class related nouns, the “cid” is left blank. From the sequenc-es, we can mine out the ExCSRs.
4.2 Mining the ExCSR Rules
The mining procedure is extended from Pre-fixSpan (Pei et al., 2004), an efficient sequence rule mining method. We will not introduce the PrefixSpan method itself, which is beyond the topic of this paper. Instead, we present our
modi-fied version based on the framework of Pre-fixSpan. The mining algorithm, called DS-SRM (Distance Sensitive Sequential Rule Miner), is shown in Algorithm 1, which is composed of a recursive procedure DS-SPM (Distance Sensitive Sequen-tial Pattern Mining).
It is noticeable that the imported distance in-formation [NEIGH], [NEAR] and [ANY] are not exclusive: [ANY] covers [NEIGH] and [NEAR]; and [NEAR] covers [NEIGH]. Therefore, when counting the occurrence for each item in Step 1 of Procedure DS-SPM, if the current item is (NEIGH, b), then the counters for (NEIGH, b), (NEAR, b), (ANY, b) increase one; if the current item is (NEAR, b), then the counters for (NEAR, b), (ANY, b) increase one.
Algorithm 1: (DS-SRM)Distance Sensitive Sequential Rule Miner
Input: The training set D = {(s1, y1), (s2, y2), ..., (sn, yn)}, where each si is the preprocessed sequence;
The minimum support threshold: min_sup; The minimum confidence threshold: min_conf.
//Rules with the confidence below min_conf or support below min_sup will be disregarded.
Output: A set of ExCSRs satisfying the support and confidence requirements
Parameters: - a sequential pattern set;
- a sequential pattern in ;. Step 1: S = {s1, s2, …, sn}; Y = {y1, y2, …, yn}
Step 2: = DS-SPM(<>, 0, S); Step 3: for each in
(a) count the frequencies of all covered classes (the classes that the covered sequences belong to), and find the most frequent class label yY;
(b) if support(y) min_sup and confidence(y) min_conf then output y.
Procedure DS-SPM (, len, S|) Input: A sequence set S;
The minimum support threshold: min_sup; Output: The complete set of sequential patterns
Parameters: - a sequential pattern, where each element is a triplet originated from section 4.1 and have attached the distance information in the form of [(d, pos), (d, word), (d, cid)] (d is the distance information and initially is blank), each pair in a triplet is regarded as an item;
len - the length of ;
S| - the -projected sequence set, the collection of labeled suffixes of sequences in S with re-gards to prefix . If is empty, then S|= S.
Tnear - the threshold to indicate whether two triplets are NEAR. Step 1: Scan S| once to find each frequent item, (db,b), such that
a) (db,b) can be assembled to the last element of to form a sequential pattern; or
b) <(db,b)> can be appended to the last item of to form a sequential pattern (<(db,b)> denotes the triplet
containing (db,b)).
Step 2: for each frequent item (db,b), append it to to form a sequential pattern ’, and output ’.
Step 3: for each ’, construct ’-projected set S|’ by the following ways: (a) S|’ = set of suffixes of sequences in S with regards to prefix ’;
(b) For each item (dc,c) in S|’, revising its distance information by one of the following ways: (i) if (dc,c) is in the same triplet with (db,b), then modify (dc,c) to (b,c);
(ii) if (dc,c)’s triplet is neighbor to (db,b)’s triplet, then modify (dc,c) to (NEIGH, c);
(iii) if (dc,c)’s triplet is near to (db,b)’s triplet with regards of Tnear, then modify (dc,c) to (NEAR, c);
(iv) OTHERWISE, modify (dc,c) to (ANY, c);
Step 4: call DS-SPM(’,len+1, S|’).
4.3 Filtering out Redundant ExCSR Rules
Since [NEIGH], [NEAR], and [ANY] are not exclusive, Algorithm 1 may generate quite a lot of redundant rules. In order to remove the redun-dancy, we first define the interestingness of a rule r as Equation (1):
Interestingness(r)=support(r)*confidence(r) (1)
Then we can rank the rules according to their interestingness. Rules with high interestingness score tend to have high support as well as high confidence, thus should be remained.
Due to the use of overlapping constraints, there are usually some rules with the same sup-port and confidence, exemplified in Table 5.
Rule Id Class Conf. Sup. Rule
1 DESC
Table 5. Example rules with same support and confidence
Rule 1 and 2 are with the same confidence 100% and support 32 thus have the same inter-estingness. However, rule 1 is more general than rule 2 for it uses less distance constraints, so we prefer to remain rule 1 and discard rule 2. For
Where label_value(i) denotes the value of the
i-th distance label (the value of [NEIGH], [NEAR], [ANY] is set to 2, 1, 0.5 separately), and k is the total number of distance labels used in rule r.
Obviously, shorter rules with simpler distance constraint are more general and preferred.
Therefore, we propose a rule selection algo-rithm MCRSelection illustrated in Algoalgo-rithm 2, which will be used iteratively for all classes, one run for one class, to remove the redundant rules.
5
Experiments and Discussions
combination. Finally, we compare our method with the optimal distance combination to other representative methods. In the experiments, we set the threshold values of parameters min_sup,min_conf and Tnear as 3, 0.75 and 2 respective-ly by experience.
Algorithm 2: MCRSelection
Input: rule set R = {r1, r2...rn} for specific class; The training question set D.
Output: rule set R’ without redundancy
Step 1: R’ = ;
Step 2: Calculate interestingness for each rule in R; Step 3: Rank rules according to the interestingness
and find the rule r with the highest interesting-ness. If there are one more than such rules, then choose the one with the least Distance-Constraint value;
Step 4: R’ = R’ {r}; R = R – {r}; Step 5: D = D- {instances satisfied by r}; Step 6: if D is empty, then return R’;
Step 7: For each rR, update support(r) with regards to the updated D;
Step 8: go to step 2.
Algorithm 2. The flow of MCRSelection algo-rithm
5.1 Data Set
Class Question Num. Class Question Num. ABBR 9 desc 7
In order to facilitate the comparison, similar to previously reported results, we also use the same benchmark UIUC question training and test sets in our experiments, where the questions are la-beled as six coarse categories and a total of 50 finer categories. Concretely, we train our model with training set containing 5500 labeled ques-tions and test it on the TREC 10 question set with 500 questions. The composition of the test set is listed in Table 6.
5.2 Investigation on the Distance Combina-tions
In section 3.2, we have introduced three kinds of distance: [NEIGH], [NEAR] and [ANY]. In or-der to know whether all of them are necessary in our method, we have tested our method with dif-ferent distance combination on the same data sets. Table 7 shows the overall performances on 6 coarse classes and 50 fine classes with different combinations separately; and Table 8 presents more details on the six coarse categories.
ANY NEAR+ Table 7. Performances of our method with
dif-ferent distance constration combinations Table 8. More detailed investigation on the
dis-tance combinations
The more detailed results in Table 8 also show that including all of the distance information can get the highest prediction accuracies on all of the six categories. Especially for the DESC class, the previously feature bag based methods usually
perform not very good due to the fact that ques-tion classes are distance sensitive, while our method with all distance information included can get 95% overall accuracy. For example, “What foods contain vitamin B12?” is labeled as “ENTY: food”, while “What is fiber in food?” belongs to “DESC: define” in UIUC data sets. The main difference between above question texts is the distance between two words “what” and “food” that are critical to the classification. Due to ignoring the distance information, the feature-bag based method usually cannot correct-ly classify the second question and may label it as “ENTY: food”. While our method can proper-ly distinguish these two questions for they corre-spond to different ExCSRs. The similar cases occur in questions of class “DESC: desc”.
All in all, our proposed ExCSR including all of the three distance constraints is an effective model to the question classification. Thus in the comparison experiment, we consider all of the distance constraints.
5.3 Comparing with other Methods
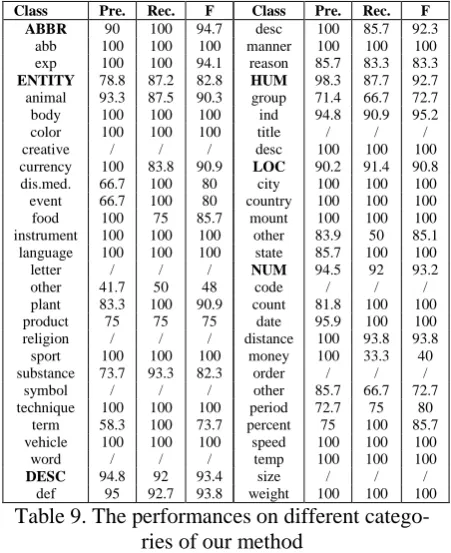
By considering all of the distance constraints, the performances on different categories of our method are listed Table 9.
Class Pre. Rec. F Class Pre. Rec. F
Table 9. The performances on different catego-ries of our method
Huang et al. (2008) have compared their method with Li et al. (2006) and show that their method is superior, we don’t consider Li et al., (2006) method in this work.
The comparison results are shown in Table 10, showing that our method achieves the best accu-racy. Although the results of Huang’s method are competitive to our method, however, they use some manual regular expression patterns. More-over, Huang et al. used a large amount of fea-tures 13697 to construct their model, while our ExCSRs model are more compact and final clas-sifier only has 412 rules with length less than 4.
Table 10. Overall comparison results with oth-er three methods
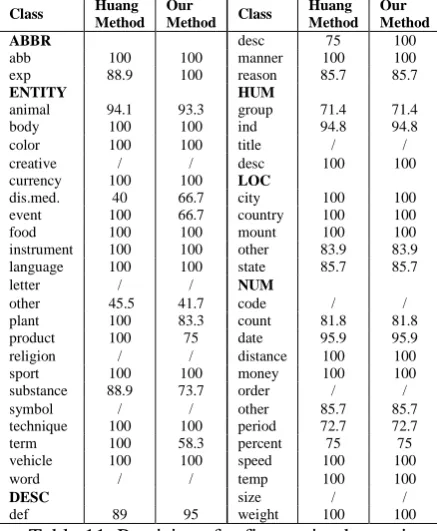
Now that the results of Huang’s method are competitive to ours, we further compare it with ours on each fine grained class, and the accura-cies are shown in Table 11.
Class Huang
Table 11. Precisions for fine grained question categories with Huang’s method and our method
Table 11 shows that our method can achieve better results on most classes, especially for
DESC coarse class that is considered to be diffi-cult to identify (Li et al., 2006). By investigating the questions in that class we found that the question classes are sensitive to the word order and distance. Huang represents a sentence as a bag of features and ignore the relative order and of words their distances, thus performed not very well.
Of course, both our method and Huang’s method show bad performance on Entity: other class, which is also shown to be difficult to iden-tify, for the question texts in “other” class is quite fuzzy, we will put emphasis on this kind of class.
We also analyzed the incorrectly identified questions, and found that there are inherently ambiguity in training and testing questions (see examples in Table 12), which also conforms to Huang et al (2008)’s analysis.
Class Rule
ENTITY:animal What is a group of frogs called ?
ENTITY:termeq What are the spots on dominoes called ?
ENTITY:termeq What 's the term for a young fox ?
ENTITY:animal What is the scientific name for ele-phant ?
Table 12. Ambiguous questions in testing set
6
Conclusion
In this paper, we first present ExCSR model for question classification, which is extended from the CSR model by integrating the distance in-formation. Compared to CSR model, ExCSR is more compact intuitive, yet effective; then we describe the ExCSR mining algorithm, DS-SRM, and the rule filtering algorithm MCRSelection. By MCRSelection algorithm, we can keep the most interesting rules with less redundancy. Ex-periment results on the UIUC question set show that our method outperforms previously reported results.
In the future, we will consider more sophisti-cated method to address the questions with fuzzy information such as those of “other” class in UI-UC data set.
Acknowledgements
(20090141110026), and the Fundamental Re-search Funds for the Central Universities (6081007).
References
Xin Li and D. Roth. 2006. Learning Question Classifiers: the Role of Semantic Information. Natural Language Engineering, 12(3):229–249.
Zhiheng Huang, M. Thint, and Z. Qin. 2008. Question classification using head words and their hypernyms. In Proc. of the EMNLP. pp.927-936
Minqing Hu and Bing Liu. 2006. Opinion Feature Extraction Using Class Sequential Rules. In Proc. of AAAI-06.
Pei, J. Han, J., Mortazavi-Asl, B., Wang, J., Pinto, H., Chen, Q., Dayal, U., and Hsu, M.-C. 2004. Mining Sequential Patterns by Pattern-Growth: The PrefixSpan Approach. IEEE Transactions on Knowledge and Data Engineering, 16(10):1-17.
Li, X. and D. Roth. 2002. Learning Question Classifiers. In Proc. of the 19th international conference on Computational linguistics (COLING '02 ), vol. 1: 556–562.
Hermjakob, U. 2001. Parsing and question classification for question answering. In Proc. of ACL-2001 Workshop on Open-Domain Question Answering.
Radev, D., Fan, W., Qi, H.,Wu, H. & Grewal, A. 2002. Probabilistic question answering on the web. In Proc. of the 11th international conference on World Wide Web (WWW2002), Hawaii.
Zhang D. and W. S. Lee. 2003. Question Classification using Support Vector Machines. In Proc. of the ACM SIGIR conference on information retrieva l(SIGIR’03): 26–32.
V. Krishnan, S. Das, and S. Chakrabarti. 2005. Enhanced answer type inference from questions using sequential models. In Proc. of the HLT/EMNLP’2005.
Fangtao Li, Xian Zhang, Jinhui Yuan and Xiaoyan Zhu. 2008. Classifying What-Type Questions by Head Noun Tagging. In Proc. of the 22nd International Conference on Computational Lin-guistics (COLING 2008), pp. 481-488
Zhiheng Huang, Marcus Thint, Asli Celikyilmaz. 2009. Investigation of Question Classifier in Question Answering. In Proc. of the 2009 Conference on Empirical Methods in Natural Language Processing. pp. 543–550.
Santosh Kumar Ray, Shailendra Singh, B.P. Joshi. 2010. A semantic approach for question classification using WordNet and Wikipedia. Pattern Recognition Letters: 1935-1943.
Bing Liu. 2007. Web data mining: Exploring hyper-links, contents, and usage data. Springer-Verlag, Berlin, Heiderlberg.
Jenny Rose Finkel, Trond Grenager, and Christopher Manning. 2005. Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. In Proc. of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005). pp.363-370.
Kristina Toutanova, Dan Klein. 2003. Christopher Manning, and Yoram Singer. Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network. In Proc. of HLT-NAACL. pp.252-259.
![Table 4. Possible ExCSR examples originated [NEAR] NN [NEIGH]> from CSRs in Table 2.](https://thumb-us.123doks.com/thumbv2/123dok_us/803110.1094642/3.595.307.526.297.429/table-possible-excsr-examples-originated-near-neigh-table.webp)
![Table 5. Example rules with same support and en]> confidence](https://thumb-us.123doks.com/thumbv2/123dok_us/803110.1094642/6.595.311.511.450.753/table-example-rules-support-en-confidence.webp)