Ample Data Exploration and Map Reduce Indoctrination
Decisive Factor
1
Nagaraj Peddarapu ,
2Erukala Mahender
,
3Kakkerla Shivakumar
1
Assistant Professor, Dept. of CSE, Geethanjali College of Engineering & Tech., Hyderabad, India, 501301
E-mail:
1[email protected],
2[email protected] ,
3[email protected]
Abstract- This immense volume of information of knowledge of information is thought as huge data. The info flow therefore quick that the overall accumulation of the past 2 years is currently a zettabyte. Huge information refers to technologies and initiatives that involve information that's too various, fast-changing or huge for typical technologies, skills and infrastructure to deal with efficiency. Information currently stream from way of life from phones and credit cards and televisions and computers; from the infrastructure of cities from sensor-equipped buildings, trains, buses, planes, bridges, and factories. Aforesaid otherwise, the volume, rate or kind of information is just too nice. The amount {of information of knowledge of information with the speed it's generated makes it tough for this computing infrastructure to handle huge data. to beat this downside, huge processing are often performed through a programming paradigm called MapReduce. Typical, implementation of the MapReduce paradigm needs networked connected storage and multiprocessing. Hadoop and HDFS by apache are wide used for storing and managing huge information. During this analysis paper the authors recommend numerous ways for line of work to the issues in hand through MapReduce framework over HDFS. MapReduce technique has been studied at during this paper that is required for implementing huge information analysis victimization HDFS. In this paper, we have a tendency to gift a outline of our activities related to the storage and query process of Google 1T 5-gram information set. Tendency to 1st provides a transient introduction to a number of the implementation techniques for the relative pure mathematics followed by a Map scale back implementation of equivalent operators. We have a tendency to then implement a info schema in Hive for the Google 1T 5-gram data set. This paper can more look at the question process with Hive and Pig within the Hadoop setting. More specifically, we have a tendency to report statistics for our queries during this setting.
Keywords:MapReduce, HDFS, Big Data, Web 1T-5, Hadoop, Nutch, Lucene, NDFS, Map Phase, Map Reduce
I. INTRODUCTION
Big information may be a standard term wont to describe the exponential growth and availableness of knowledge, each structured and unstructured. Huge information could also be vital to business and society because the net has become. Huge information is thus large that it's tough to method exploitation traditional information and software package techniques. More data may result in a lot of correct analyses. Lot of correct analyses might result in a lot of assured deciding. Better selections will mean bigger operational efficiencies [9], cost reductions and reduced risk. Analyzing huge information is one in every of the challenges for researchers system and academicians that desires special analyzing techniques. Huge information analytics is that the method of examining huge information to uncover hidden patterns, unknown correlations and different helpful info that may be used to make higher selections. This thesis is an experiment within the storage and
question process of the Google Web1T-5gram information set. From currently on, we'll use Web1T-5gram rather than Google Web1T-5gram. Web1T-5gram addresses the frequency of words in an exceedingly corpus: "A corpus may be a giant, principle assortment of naturally occurring samples of language hold on electronically [1]". In 2006, Google free the Web1T-5gram information supported one trillion words. This information keeps the frequency of Unigram, Bigram, trigram, four-grams and ve-grams. In applied math language processing, this technique is named AN N-gram model [9].
The N-grams square measure won‟t to train Language models supported the hidden Andrei Markov paradigm. N-gram model is intended to stay track of the frequency of word sequences in an exceedingly text. Google additionally created AN open supply software package answer called Web1T5-easy supported a computer database system to control the info. In this thesis, we tend to show AN efficient technique for assortment and storing the Web1T-5gram in Hive. The system Hive takes advantage of Hadoop's distributed agglomeration surroundings. The Hive and Hadoop will decrease the quantity of storage prices and scale back process whereas additionally increasing responsibility and speed on huge information searches.
II. CHALLENGES AND GOALS OF ANALYZING
BIG DATA
2.1.GOALS:
Two main goals of high-dimensional knowledge analysis area unit to develop effective ways, that may accurately predict the longer term observations and at constant time to realize insight into the link between the options [5] and response for scientific functions [15]. Moreover, as a result of giant sample size, massive knowledge make to extra goals: to grasp heterogeneousness and commonality across completely different subpopulations. In alternative words, massive knowledge offer guarantees for:
exploring the hidden structures of every population of
the information, that is historically not possible and may even be treated as „outliers‟ once the sample size is small
Extracting vital common options across several
subpopulations even once there are unit giant individual variations.
2.2.CHALLENGES:
In today‟s hypercompetitive business surroundings, corporations not solely need to realize and analyze the relevant knowledge they have, they have to realize it quickly. Visualization helps organizations perform analyses and create selections rather more apace; however the challenge goes through the sheer volumes of knowledge and accessing the extent of detail required, all at a high speed [9]. The challenge solely grows because the degree of roughness will increase. One doable answer is hardware. Some vendor‟s area unit mistreatment magnified memory and powerful data processing to crunch giant volumes of knowledge extraordinarily quickly. Another technique is golf shot knowledge in memory however employing a grid computing approach, wherever several machines area unit accustomed solve a retardant. Each approach permits organizations to explore large knowledge volumes and gain business insights in near-real time.
2.2.2. Understanding the data
the info the information it takes plenty of understanding to induce knowledge within the right form in order that you'll use image as a part of data analysis. The information comes from social media content, you would like to understand World Health Organization the user is during a general sense [13]. One answer to the current challenge is to own the right domain experience in situ. Check that the folks analyzing the information have a deep understanding of wherever the information comes from, what audience is going to be overwhelming the information and the way that audience can interpret the data.
2.2.3. Addressing data quality
Though you'll realize and analyze knowledge quickly and place it within the correct context for the audience which will be overwhelming the data, the worth of knowledge for decision making functions are going to be jeopardized if the information isn't correct or timely. This can be a challenge with any knowledge analysis, however once considering the volumes [19] {of information of knowledge of knowledge} concerned in massive data comes, it becomes even a lot of pronounced. Again, knowledge image can solely influence be a valuable tool if the information quality is assured. It‟s continually best to own a pro-active technique to handle knowledge quality problems therefore issues won‟t arise later.
2.2.4. Displaying meaningful results
Plotting points on a graph for analysis becomes tough once addressing extraordinarily giant amounts of data or a spread of classes of data. As an example, imagine you've got ten billion rows of retail SKU knowledge that you‟re making an attempt to check. The user making an attempt to look at ten billion plots on the screen can have a tough time seeing such a lot of knowledge points [12]. Way to resolve this can be to cluster knowledge into a higher level read wherever smaller teams of knowledge come into view. By grouping the information along, or “binning,” you'll a lot of effectively visualize the information [7].
2.2.5. Dealing with outliers
The graphical representations of knowledge created doable by image will communicate trends and outliers a lot of quicker
than tables containing numbers and text. Users will simply spot problems that require attention just by glancing at a chart. Outliers usually represent regarding one to five % of knowledge, however once you‟re operating with large amounts of knowledge, viewing one to five % of the information is quite tough [18]. However does one represent those points while not moving into plotting issues? doable solutions area unit to get rid of the outliers from the information (and so from the chart) or to form a separate chart for the outliers.
III. MAPREDUCE
In 2004, Google introduced MapReduce, which provides its user with helpful thanks to work with each parallel paradigm process and run time programming [7]. In 2005, Nutch developers created Nutch file system(NDFS) supported MapReduce. Early in 2006, Lucene created Hadoop supported NDFS and MapReuce. In 2008, Yahoo! proclaimed a research index supported MapReduce with over ten,000 core Hadoop clusters [12] . MapReduce that uses the runtime programming and might work across an oversized cluster of computers. Every of the foremost often used parallel computing platforms for process huge knowledge. MapReduce is reliable, easy-to-use, and easy-to-program for distributed paradigm and occur in 3 stages [2]: map stage, shuffle stage, scale back stage. The MapReduce programs cash in of the cluster of artefact servers. 1st it divides employment among a bunch of servers called Mappers. It then uses a shuffle to distribute the output of Mappers to the cluster of servers called Reducers. The clerk assumption is that the information may be parallel processed by clerk and Reducer. Google runs or so 1,000 MapReduce jobs daily [8]. The subsequent describes the 3 stages of MapReduce on a word count example. During this example, we have a tendency to describe a MapReduce application that computes the words with the best frequency in an exceedingly given set of text.
3.1.MAP PHASE
The following word count example, the input is files of text. We want to grasp what number times every word has occurred at intervals this specific corpus. Whitespace separates the words [11, 20].
The subsequent example wherever every line represents a file of text:
Today is Monday
Today is sunny
Today is a sunny Monday
Table 3.1: Map Function Output
In the diagram of this example on figure 3.1
Figure 3.1: Map Function
3.2.SHUFFLE PHASE
Shuffle stage is implemented by the system that sort and send all the values to the Reducer [9, 14]. Those pairs that have the same key go to the same Reducer.
Table 3.2: Shuffle Function Output
Figure 3.2: Shuffle Stage
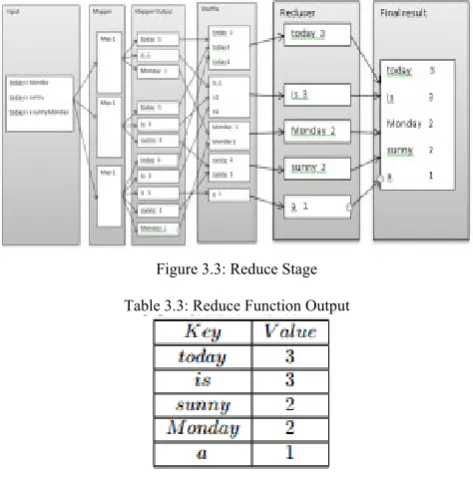
3.3.REDUCE PHASE
Reducer joins and unites all intermediate values with the same intermediate key. Reducer is a program written by the programmer to sums the values for each key [16]. Usually, Reducer produces Zero or one output value. The result of reducer in below.
Figure 3.3: Reduce Stage
Table 3.3: Reduce Function Output
IV. HDFS & BIG DATA ANALYTICS
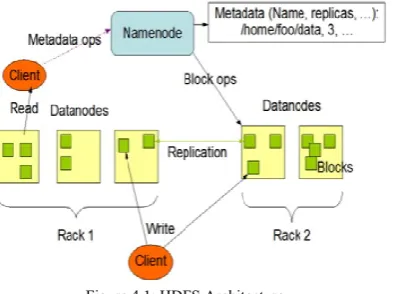
Square measure variety of Data Nodes, typically one per node within the cluster, that manage storage hooked up to the nodes that they run on. HDFS exposes a filing system namespace and permits user information to be kept in files. Internally, a file is split into one or a lot of blocks and these blocks square measure keep in a very set of Data Nodes [8, 9].
Figure 4.1: HDFS Architecture
The NameNode executes filing system namespace operations like gap, closing, and renaming files and directories. It additionally determines the mapping of blocks to Data Nodes.
Big information analytics [5] refers to the method of aggregation, organizing and analyzing giant sets of data of knowledge of data ("big data") to get patterns and different helpful information. Not solely can massive information analytics assist you to know the knowledge contained among the information, however it'll additionally facilitate establish the information that's most significant to the business and future business selections. massive information analysts primarily need the data that comes from analyzing the information.
V. CONCLUSION
As we've got entered associate degree era of massive information, process massive volumes of knowledge has ne'er been larger. Through higher huge Data analysis tools like Map cut back over Hadoop and HDFS, guarantees quicker advances in several scientific disciplines and up the gain and success of many enterprises. MapReduce has received lots of attentions in several fields, as well as data processing, data retrieval, image retrieval, machine learning, and pattern recognition. However, because the quantity of knowledge that requires being processed Grows, several processing strategies became not suitable or restricted. This paper exploits the MapReduce framework for efficient analysis of massive information and for resolution difficult data processing issues on massive scale datasets in different domains. MapReduce provides straightforward thanks to scale your application. It effortlessly scales from one machine to thousands, providing Fault tolerant & High performance.
REFERENCES
[1]. Ziad Benslimane. Optimizing hadoop parameters based on the application resource consumption. 2013.
[2]. Wei Dai and Mostafa Bassiouni. An improved task assignment scheme for hadoop running in the clouds. Journal of Cloud Computing, 2(1):1{16, 2013.
[3]. Je_rey Dean and Sanjay Ghemawat. Mapreduce: simpli_ed data processing on large clusters. Communications of the ACM, 51(1):107{113, 2008.
[4]. Francis X Diebold. big datadynamic factor models for macroeconomic measurement and forecasting. In Advances in Economics and Econometrics: Theory and Applications, Eighth World Congress of the Econometric Society,(edited by M. Dewatripont, LP Hansen and S. Turnovsky), pages 115{122, 2000.
[5]. Stefan Evert. Google web 1t 5-grams made easy (but not for the computer). In Proceedings of the NAACL HLT 2010 Sixth Web as Corpus Workshop, pages 32{40. Association for Computational Linguistics, 2010.
[6]. Wei Fan and Albert Bifet. Mining big data: current status, and forecast to the future. ACM SIGKDD Explorations Newsletter, 14(2):1{5, 2013.
[7]. Jared Gray and Thomas C Bressoud. Towards a mapreduce application performance model. In Midstates Conference, 2012.
[8]. D Laney. 3-d data management: Controlling data volume, velocity and variety, meta group,research note, february 2001.
[9]. Efficient Analysis of Big Data Using Map Reduce Framework: Dr. Siddaraju,Sowmya C L, Rashmi K, Rahul M, IJRDET, June 2014. [10]. Attila Marton, Michel Avital, and Tina Blegind Jensen. Reframing
open big data. 2013.
[11]. Christopher Olston, Greg Chiou, Laukik Chitnis, Francis Liu, Yiping Han, Mattias Larsson, Andreas Neumann, Vellanki BN Rao, Vijayanand Sankarasubramanian, Siddharth Seth, et al. Nova: continuous pig/hadoop workows. In Proceedings of the 2011 ACM SIGMOD
[12]. International Conference on Management of data, pages 1081{1090. ACM, 2011.
[13]. Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, Zheng Shao, Prasad Chakka, Ning Zhang, Suresh Antony, Hao Liu, and Raghotham Murthy. Hive-a petabyte scale data warehouse using hadoop. In Data Engineering (ICDE), 2010 IEEE 26th International Conference on, pages 996{1005. IEEE, 2010.
[14]. Tom White. Hadoop: The de_nitive guide. " O'Reilly Media, Inc.", 2012.
[15]. Xiaoyang Yu. Estimating language models using hadoop and hbase. University of Edinburgh, 2008.
[16]. Apache Giraph Project, http://giraph.apache.org/
[17]. Guoping Wang and CheeYong Chan, MultiQuery Optimization in MapReduce Framework
[18]. VinayakBorkar, Michael J. Carey, Chen Li, Inside “Big Data Management”:Ogres, Onions, or Parfaits?, EDBT/ICDT 2012 Joint Conference Berlin, Germany,2012 ACM 2012, pp 3-14.
[19]. OnurSavas, YalinSagduyu, Julia Deng, and Jason Li,Tactical Big Data Analytics: Challenges, Use Cases and Solutions, Big Data Analytics Workshop in conjunction with ACM Sigmetrics 2013,June 21, 2013. [20]. GrzegorzMalewicz, Matthew H. Austern, Aart J. C. Bik, James
C.Dehnert, Ilan Horn, NatyLeiser, and GrzegorzCzajkowski,Pregel: A System for Large-Scale Graph Processing, SIGMOD‟10, June 6– 11, 2010, pp 135-145.
About the authors:
Nagaraj Peddarapu (Ph.D), currently
working as an Assistant Professor in
Dept. of CSE atGeethanjali College of
Engineering & Tech affiliated to JNTU Hyderabad. He was pursuing Ph.D from Osmania University, Hyderabad. He gained 10 years in teaching. He
Presented papers National &
His research interests includes: Big Data, Data Mining and Cloud Computing.
Erukala Mahender. He holds B.Tech.
degree in Computer Science and
Engineering, and M.Tech. degree in
Software Engineering from JNTU,
Hyderabad. At present, he is working as Assistant Professor, Dept of Computer Science and Engineering in Geethanjali College of Engineering & Technology, Hyderabad, Telangana, India.
His areas of interests are Big Data, Data mining, Image Processing, Network security.
Kakkerla Shiva Kumar He completed