Available Online atwww.ijcsmc.com
International Journal of Computer Science and Mobile Computing
A Monthly Journal of Computer Science and Information Technology
ISSN 2320–088X
IMPACT FACTOR: 6.017
IJCSMC, Vol. 5, Issue. 12, December 2016, pg.07 – 12
Program Restructuring and Components
Reuse with Clustering of Software
Components Based on Fuzzy Logic
Huma Khan
1, Yukti Kesharwani
2, Rida Anwar
3¹Software Engineering, Dr. C.V Raman, INDIA
²Computer Science, Dr. C.V Raman, INDIA
³Computer Science & Engineering, CSVTU, INDIA
1
[email protected]; [email protected]; [email protected]
Abstract—Software Engineering (SE) is worried with creating and keeping up programming frameworks
that carry on dependably and effectively, are moderate to create and keep up, and fulfill every one of the necessities that clients have characterized for them. It is essential in light of the effect of extensive, costly programming frameworks and the part of programming in security basic applications. It incorporates huge arithmetic, software engineering and practices whose sources are in designing. Programming reuse has many measurements or features. The principles measurements along which ways to deal with programming reuse can be recognized are recorded in Table SR-1. Each of these measurements will be dissected by highlighting fundamental attributes of outrageous positions along the tomahawks. Most reuse frameworks, be that as it may, show a blend of these attributes. For instance, an ordinary reuse framework may utilize a blend of a compositional and a generative approach. The k-implies bunching calculation the segment which are like each other are gathered in one group and disparate protest are assembled in another group. The need drawbacks are understood by changing item lattice to relative grid and group unevenness drawback are frequently illuminated by k-mean cluster. Contrasted and Fuzzy bundle, relative K-mean cluster is a considerable measure of adaptable and sensible for world.
Keywords— Clustering, Software Engineering, Components Reuse, Fuzzy Logic, K-mean Clustering.
I. INTRODUCTION
from higher rate of alteration in client necessities and setting on that the product framework is working.
1. monster programming framework – it's difficult to make a house or working than to a divider, in like manner, in light of the fact that the span of programming framework get to be distinctly enormous; building must stride to offer it a logical technique.
2. Scalability-If the product framework strategy wasn't upheld logical and building ideas; it may be less demanding to re-make new programming framework than to scale a blessing one.
3. Cost-As equipment exchange has demonstrated its capacity and huge creating has let down the value of tablet and electronic equipment. On the off chance that right strategy isn't custom fitted then the cost of programming framework stays high.
4. Dynamic Nature-The constantly developing and adjusting nature of programming framework amazingly relies on the setting amid which client works. New improvements must be constrained to be depleted the common one, if the character of programming framework is frequently rapid. Through this product framework building assumes a legit part.
5. Quality Management-Provides savvy quality programming bundle for the higher technique for programming framework advancement.
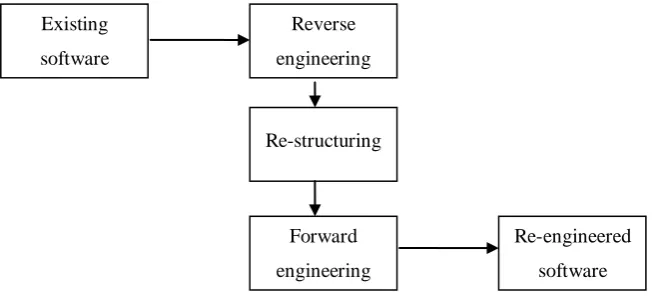
Fig. 1 Software Re-Engineering Process
At the point when must be constrained to overhaul the PC code to stay it to the present market, while not touching its common sense, it's alluded to as PC code re-designing. It's a technique wherever programs square measure re-composed furthermore the style of PC code is altered. endowment PC code can't keep institutionalization with the preeminent late innovation available inside the market. Change of PC code turns into a cerebral pain once equipment gets to be distinctly old. PC code common sense doesn't despite the fact that it becomes past with time.
In Re-Engineering method all else choose what to re-design. To get details of current PC code, Perform Reverse Engineering. Rebuild a Program if it's required. For instance, evolving capacity situated projects into protest arranged programs. Re-structure information PRN with a specific end goal to instigate re-designed PC code applies Forward building thoughts.
II. RELATED WORK
Segment use might be a strategy of part based for the most part programming bundle building. A few examinations demonstrate that reusability truly works, improves profitability, diminishes advancement time and lessens the esteem.
Reusability isn't a terribly late subject to discuss, began in 1969. [Basem Y. Alkazemi et al., 2014] Doug McIlroy, leading presented the considerations of methodical use of programming bundle components in 1968. right now a few programming bundle enterprises like IBM, HP, Dell, Hitachi and heaps of others, concurring undefeated use programs comprehensively. Use is Associate in Nursing umbrella develop, incorporating a scope of methodologies and things.
Existing
software
Reverse
engineering
Re-structuring
Forward
engineering
Re-engineered
The reusable resources or components are in many structures like part storehouse, various modules in an exceedingly area particular system.
[Chung-Horng respiratory organ et al., 2006] presented A way to deal with program rebuilding inside a work upheld cluster systems with attachment on the grounds that the real concern. bunch has been wide wont to group associated elements along. This approach concentrates on programmed bolster for trademark badly organized or low-durable capacities and giving heuristic suggestion in each the occasion and advancement stages.
[Muhammad Husnain Zafar et al.,2015] arranged a route through that they'll characterize the reusable components in right on account of get the entire edges of reusability. We tend to characterize the reusable components per their group. Groups square measure made on the possibility of parameters provided with components. They build up AN administer for dispersion bunches to the reusable components.
[Duo Liu et al., 2015] anticipated Associate in Nursing accommodating fluffy group strategy bolstered possibilistic bunch calculations to manage the trouble of single metric. The anticipated procedure cooperatively considers separation, thickness, and in this way the pattern of thickness change of component occasions inside the enrollment degree estimation. The post group partition of bunched components upheld the predefined limits and regrouping of the isolated component focuses end in higher durable group.
III. PROBLEM IDENTIFICATION
The way to the response to the present drawback is Reusability. After you use program or style parts, you must take after the look decisions made by the underlying designer of the component. use a component needs a component library for finding, understanding and adjusting reusable parts.
Finding the part which might be utilized as a part of the framework - A component could likewise be any reusable and independent unit of common sense, similar to a classification or a library. These parts square measure set in use libraries or component vault. to choose a component which may coordinate basically into the code frameworks that square measure to be created exploitation reusable parts. Component should be essentially comprehended by the engineers.
Sparsity-A dispersed network might be a framework inside which the vast majority of the climate square measure zero. The division of nonzero parts over the whole assortment of segments in an extremely framework is named the sparseness or thickness. Operations exploitation typical thick grid structures and calculations square measure moderate and wasteful once connected to monster conveyed networks as process and memory square measure squandered on the zeroes
Group Imbalance-class or bunch irregularity disadvantage get to be distinctly most prominent issue in information preparing. Lopsidedness downside happen wherever one in everything about 2 classifications has a considerable measure of test than various classifications. information handling calculations square measure works best once the quantities of cases of each class square measure generally equivalent. once the amount of examples of 1 classification so much surpasses the inverse, issues emerge..
IV. PROPOSED METHODOLOGY
Exploitation this grid bunch strategy is connected to seek out the comparable arrangement of reports.
A. Data Acquisition
Information obtaining is illustrated in light of the fact that the strategy for combination and arranging data. part or data securing is that the strategy of exertion components for utilize or advancement into a reusable part. it will include getting to privately created components or administrations or finding the components from partner degree outside supply.
B. Pre-processing
It comprises of steps that taken as info a content report and yield a gathering of tokens or single terms got the chance to be side in vector. This system takes after these means:
a. Filtering: it's a method for take out full-stop, exceptional character and distinctive accentuations from reports as a consequence of they don't supportive for data extraction. Segregation control underneath the vector demonstrate. inside the instance of organized reports this is frequently extra fundamental, similar to web content, wherever design labels will either be disposed of or known and their constituent terms ascribed very surprising weights.
b. Stemming: it's a method for dropping words to their bolster structure, or stem in support of example the words "encompassed", "encompassing", "environment" region unit all diminished to the stem "encompass".
c. Stop word disposal: A stop word is particular term, that isn't thought to exact any consistent data as a measurement inside the vector territory. A typical strategy to take out stop words is toward assessing every word with a gathering of perceived stop words. Another philosophy is to first apply a grammatical feature tagger then reject all tokens that don't appear to be things, verbs, or modifiers.
C. Term Frequency
Term Frequency will be with achievement utilized for stop words separating as a part of fluctuated subject fields still as content record and arrangement. On the off chance that a word appears to be customarily in an exceedingly report, it's essential. give the word a high score. be that as it may if a word appears in many archives, it is not a novel image. give the word a periodic score.
D. Fuzzy Clustering
In difficult or non fluffy bunch, data is part into fresh groups, wherever every datum has a place with accurately one group however in fluffy bunch furthermore alluded to as delicate cluster, the data focuses can have a place with very one bunch, and identified with everything about data focuses square measure participation reviews that demonstrate the degree to that the data guides have a place toward the fluctuated groups. The part has a place with the group that has higher enrolment cost.
E. K-means Clustering
K-mean is one in everything about just unsupervised learning calculations that comprehend the reported group drawback. The methodology takes after a straightforward and simple because of order a given learning set through an express scope of bunches consider as k groups.
This algorithm aims to minimizing an objective function is:
Where J is an objective function, k is a number of cluster, n is a number of cases, is a case i, is a
centroid for cluster j and is a chosen distance measure between a data point and the
The calculation is made out of the accompanying strides: 1. Randomly select k centroid.
2. Calculate the separation between every information point and centroid.
3. Appoint every information indicate the gathering which has the nearest centroid. 4. At the point when all information is appointed to the nearest centroid then recalculate the places of k centroid.
5. Recalculate the separation between every information point and acquired k new centroid.
6. Rehash from Steps 3 until the group focus do not move anymore.
The k-implies calculation can be run various circumstances to lessen this impact. As contrast and Fuzzy bunching K-mean grouping calculation is quick, vigorous and less demanding to get it.
K implies bunch and Fuzzy C Mean group is framed then look at that which bunching calculation is better to group the part into a bunch.
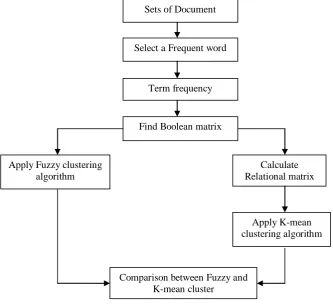
Fig. 2 Flow Diagram of Proposed Method
V. RESULT & CONCLUSIONS
Reusability assumes an essential part in picking a component for code frameworks. Reusability is that the real normal for the component. The components that in light of the fact that the higher key of reusability, which will be reused horribly speedier with higher quality and less estimation of improvement. The upper the measure of reflection greater is that the level of reusability. It spares the time. Upkeep of the code is a considerable measure of flexible and conceivable that the one made new. amid this proposal, blessing an examination between 2 pack method that's, fluffy group and k-mean bunch is finished for the reusability of code component. The outcomes gave by relative K-mean pack are important and target data. Fluffy bundle sort group that contain conflictingly circulated record. The destitution drawbacks are fathomed by changing item grid to relative network and group unevenness
Sets of Document
Select a Frequent word
Term frequency
Apply K-mean clustering algorithm Find Boolean matrix
Apply Fuzzy clustering algorithm
Comparison between Fuzzy and K-mean cluster
drawback are frequently illuminated by k-mean cluster. Contrasted and Fuzzy group, relative K-mean bundle is a ton of flexible and sensible for world.
R
EFERENCES[1] Chintakindi Srinivas, Vangipuram Radhakrishna and C.V. Guru Rao, “Clustering software components for program restructuring and component reuse using hybrid XNOR similarity function,” The 7th International Conference Interdisciplinarity in Engineering, Procedia Technology 12 , pp. 246–254, 2014.
[2] Chung-Horng Lung, Xia Xu, Marzia Zaman and Anand Srinivasan, “Program restructuring through clustering technique,” Journal of Systems and Software, vol. 79, pp. 1261-1279, 2006.
[3] Muhammad Husnain Zafar, Rabia Aslam and Muhammad Ilyas, “Classification of reusable components based on clustering,” I.J. Intelligent Systems and Applications, vol. 10, pp. 55-62, 2015.
[4] Charu Singh, Amrendra Pratap and Abhishek Singhal, “Estimation of software reusability for component based system using soft computing techniques,” 5th International Conference-Confluence the Next Generation Information Technology Summit (Confluence), pp. 788–794, 2014.
[5] Duo Liu, Chung-Horng Lung and Samuel A. Ajila, “Adaptive clustering techniques for software components and architecture,” IEEE 39th Annual International Computers, Software & Applications Conference, pp. 460–465, 2015.
[6] Mehajabi Sayeeda and Rachana Kamble, “An Enhancement of Clustering Technique using Support Vector Machine Classifier,” International Journal of Computer Applications, vol.117, pp. 17-22, 2015.
[7] Prakriti Trivedi and Rajeev Kumar, “Software metrics to estimate software quality using software component reusability,” International Journal of Computer Science Issues, vol. 9, issue 2, no 2, pp. 144-149, March 2012.
[8] Chintakindi Srinivas, Vangipuram Radhakrishna and Dr.C.V.Guru Rao, “Clustering and classification of software component for efficient component retrieval and building component reuse libraries,” 2nd International Conference on Information Technology and Quantitative Management, ITQM, Procedia Computer Science 31, pp. 1044–1050, 2014.
[9] Amarjeet Kaur and Iqbaldeep Kaur, “Design and development of algorithm for software components retrieval using clustering and support vector machine,” International Journal of Innovation in Engineering and Technology (IJIET), issue 2, vol. 5, pp. 28–39, April 2015.
[10] Shivani Budhkar and Dr. Arpita Gopal,“Component identification from existing object oriented system using Hierarchical clustering,” IOSR Journal of Engineering, vol. 2(5), pp. 1064-1068, 2012.
[11] Arvinder Kaur and Kulvinder Singh, “Component selection for component based software engineering,” International Journal of Computer Applications(0975-8887), vol. 2, pp. 109-114, May 2010.
[12] B.Jalender, Dr A.Govardhan and Dr P.Premchand, “Designing code level reusable software components,” International Journal of Software Engineering & Applications (IJSEA), vol.3, pp. 219-229, 2012.
[13] Mr.Rushi Longadge, Ms. Snehlata S. Dongre, Dr. Latesh Malik, “Class Imbalance Problem in Data Mining: Review,” International Journal of Computer Science and Network (IJCSN), vol. 2, issue 1, 2013. [14] Anshul Kalia and Sumesh Sood, “Component based software reusability and framing standards for
components to be reused,” International Journal of Computer Science and Information Technologies, vol. 5 (2), pp.1459-1462, 2014
[15] Amit Kumar, Balkar Singh and Sandeep, “Improve reusability of software using clustering techniques,” IJCSMS International Journal of Computer Science & Management Studies, vol. 14, issue 02, pp. 17-21 February 2014.
[16] Ms.K.Sruthi and Mr.B.Venkateshwar Reddy, ―Document Clustering on Various Similarity Measures,” International Journal of Advanced Research in Computer Science and Software Engineering, vol. 3, pp. 1269-1273, 2013.
[17] Chintakindi Srinivas, Vangipuram Radhakrishna and Dr.C.V.Guru Rao, “Clustering software components for programming restructuring and component reuse using hybrid XOR similarity function,” AASRI Conference on Intelligent Systems and Control, pp. 319-328, 2013.
[18] G.N.K.Suresh Babu and Dr.S.K.Srivatsa, “Analysis and measures of software reusability,” International Journal of Reviews in Computing, pp. 41-16, 2009.
[19] Swati Thakral, Shraddha Sagar and Vinay, “Reusability in component based software development – a review,” World Applied Sciences Journal 31 (12), pp. 2068-2072, 2014.