ABSTRACT
KHARBUTLI, MAZEN MAHMOUD
Improving the Security of the Heap through
Inter-Process Protection and
Intra-Process Temporal Protection.
(Under the direction of Dr. Yan Solihin)
In most current implementations, memory allocations and deallocations are performed by user-level library code which keeps heap meta-data (heap structure information) and the application’s heap data stored in an interleaved fashion in the same address space. Such implementations are inherently unsafe: they allow attackers to use application’s vulnerabilities (e.g. lack of heap-based buffer over-flow checking) to corrupt its heap meta-data in order to execute malicious code or cause denial-of-service. In this dissertation, we propose an approach where heap meta-data and heap data are protected separately.
Server’s address space, attacks on the application can no longer corrupt it. Heap Server is directly implementable in current systems because it does not require new hardware. To optimize Heap Server’s performance, we explore non-blocking communication, bulk deallocation, and pre-allocation optimizations. Evaluated on a real system, a fully-optimized Heap Server performs almost identical to a Base heap management library with no protection mechanisms.
As an alternative solution, we propose a new User-level Temporal Intra-Process Protection (UTIPP) mechanism in which a process protects itself from its own vul-nerabilities by write-protecting its own heap meta-data, and only removing the protection for legitimate stores in the heap management library. Unlike existing kernel-level page protection which can only be modified in the privileged mode, UTIPP allows a process to modify the new write-protection bit with a single in-struction without disrupting normal pipeline flow. Evaluated on a cycle-accurate simulator, UTIPP adds negligible overhead in most benchmarks.
Improving the Security of the Heap through Inter-Process
Protection and Intra-Process Temporal Protection
by
MAZEN MAHMOUD KHARBUTLI
A dissertation submitted to the Graduate Faculty of
North Carolina State University
in partial fulfillment of the
requirements for the Degree of
Doctor of Philosophy
COMPUTER ENGINEERING
Raleigh
2005
APPROVED BY:
Dr. Gregory Byrd Dr. Eric Rotenberg
Dr. Yan Solihin
Dr. William Boettcher Dr. Milos Prvulovic,
DEDICATION
to myself ...
BIOGRAPHY
MAZEN KHARBUTLI was born on March 8, 1977, in the Jordanian capital Amman, to Dr. Mahmoud Kharbutli and Mrs. Nariman Ghazawi. He grew up in Irbid, Jordan where he attended Yarmouk University’s Model School. Mazen received his Bachelor of Science degree in Electrical Engineering from the Jordan University of Science and Technology in 2000. Following the footsteps of his fa-ther, he came to the USA in pursue of higher education. He received his Master of Science degree in Electrical Engineering from the University of Maryland, Col-lege Park in 2002. This dissertation fulfills the requirements for his Ph.D. degree in Computer Engineering from North Carolina State University.
ACKNOWLEDGEMENTS
First and foremost, I would like to express my gratitude to my parents, Dr. Mahmoud Kharbutli and Mrs. Nariman Ghazawi, for devoting their lives for their children, and for their unconditional love and never-ending support. I am also deeply grateful to my brothers and sisters: Lamis, Bilal, Nadine, and Khader, for their love, encouragement, and for always being there for me.
I would like to thank Dr. Yan Solihin, not only for being my advisor and com-mittee chair, but for being a mentor and a friend. His continuous support and encouragement was what kept me going. I am also thankful to my co-advisor, Dr. Milos Prvulovic, whose knowledge and keen eye greatly influenced the direction of this work. In addition, I appreciate the thoughtful comments and suggestions of all my other committee members: Dr. Gregory Byrd, Dr. Edward Gehringer, Dr. Eric Rotenberg, and Dr. William Boettcher.
I am also thankful to Dhruba Chandra, Seongbeom Kim, Fei Guo, Brian Rogers, Rithin Shetty, Xiaowei Jiang, Christopher Hazard, and Muawya Al-Otoom; my (past and current) fellow graduate students in the ARPERS research group for their help and friendship. I am especially thankful to Muawya and Chris for their con-tributions to this work.
Contents
List of Figures ix
List of Tables xi
1 Introduction 1
2 Related Work 9
3 Heap Attacks and Scope of Protection 13
3.1 Heap Overview . . . 13
3.2 Heap Attacks . . . 18
Denial of Service Attack . . . 19
Forward Consolidation Attack . . . 20
Backward Consolidation Attack . . . 22
Function Pointer Overwrite Attack . . . 23
3.3 Scope of Protection . . . 24
4 Heap Server Design 26
4.1 Modes of Operation and Optimizations . . . 26
4.2 Communication . . . 32
4.3 Meta-Data Structures . . . 36
4.4 Heap Server’s Security . . . 40
5 User-Level Temporal Intra-Process Protection (UTIPP) 44 5.1 Implementation . . . 48
5.2 UTIPP Security . . . 49
6 Heap Layout Obfuscation 51 7 Evaluation Methodology 53 8 Heap Server Evaluation 60 8.1 Benchmark Characteristics . . . 60
8.2 Heap Server Performance . . . 74
9 UTIPP Evaluation 87
10 Attack Avoidance 93
Bibliography 97
Appendix A: malloc.Base.c 103
Appendix B: malloc.heapServer.c 114
List of Figures
1.1 Simplified heap chunk structure used in GNU C [12]. . . 2
3.1 Application’s address space. . . 14
3.2 An overview of the heap and chunk structures used in GNU C [12]. . 16
3.3 Denial of service attack. . . 19 3.4 Forward consolidation attack. . . 21
3.5 Backward consolidation attack. . . 22
4.1 Traditional heap management (a) and Heap Server using blocking communication (b), non-blocking communication (c), non-blocking communication with bulk deallocation (d), and non-blocking com-munication with bulk deallocation and pre-allocation (e). . . 27 4.2 Heap Server’s interface. . . 32
4.3 Bit-mapped meta-data information that is kept by the Heap Server. . 37
8.3 Average allocation size in Bytes (logarithmic scale) . . . 65
8.4 Breakdown of heap requests service time . . . 66
8.5 Distribution of allocation and deallocation requests over time and distri-bution of aligned requested allocation sizes . . . 72
8.6 Execution time overhead without Heap Server and no kernel-level page-level protection (a) and with kernel-level page-level protection (b) . . . 75
8.7 Execution time overhead of Heap Server with different optimization. 77 8.8 Execution time overhead of Heap Server with dual-copy protection.. 79
8.9 Execution time breakdown. . . 81
8.10 Percentage of eliminated requests. . . 82
8.11 Heap Server’s occupancy. . . 84
8.12 Heap Server’s sensitivity to the number of pointers in a bulk deal-location request. . . 85
8.13 Heap Server’s sensitivity to the number of pointers in a pre-allocation request. . . 86
9.1 Execution time overhead using UTIPP . . . 88
9.2 Data TLB hit rates using UTIPP. . . 91
9.3 L2 cache hit rates using UTIPP . . . 92
List of Tables
4.1 Types of request and reply messages. * indicates that it is only gen-erated for blocking communication. . . 33
7.1 The 24 applications used in our evaluation, their categories, sources, programming languages, inputs, and run times. . . 56
7.2 Parameters of the simulated architecture. RT stands for round-trip from the processor. . . 57
7.3 The applications used in our evaluation of UTIPP along with the number of simulated heap requests and the corresponding number of instructions when theBaseheap management library is used. . . . 58
8.1 Total number of allocation and deallocation requests for the 24 benchmarks. . . 62
Chapter 1
Introduction
Motivation. In most current implementations, memory allocations and dealloca-tions are performed by user-level library code which keeps heap meta-data (heap structure information) and the application’s heap data stored in an interleaved fashion and in the same address space. Such implementations are inherently un-safe: they allow attackers to use vulnerabilities of the application (e.g. lack of overflow checking for a heap-based buffer) to corrupt its heap meta-data in order to execute malicious code or cause denial of service.
meta-data used in the GNU standard C [12] library. We note, however, that other im-plementations, such as System V implementations in IRIX and Solaris operating systems, are vulnerable to similar attacks [1].
The GNU standard C library keeps track of heap memory in terms ofchunks. When a program requests heap memory (e.g. via a call to malloc), the library finds a free chunk of a suitable size, updates its meta-data to reflect the fact that the chunk is now allocated, and returns a pointer to the chunk to the application. If the free chunk is too large, a chunk of the needed size is created from it, while the remainder becomes a new free chunk. Similarly, when a chunk is freed, its meta-data is updated to reflect this and, if possible, consecutive free chunks are consolidated into a larger free chunk.
prev_size
PIU
Free
Space
bk
fd
size
Free Chunk
Allocated Chunk
size
prev_size
PIU
Application
Data
if PIU=0
Free List
Pointers
Figure 1.1 shows how each chunk stores its meta-data (shown in light color) and data (shown in dark color). 1 Memory locations of a chunk are shown top to bottom, starting with lower-address locations at the top of the figure. In an allo-cated chunk, the 4-bytesizefield indicates the number of bytes occupied by the chunk, whereas the 1-bit PIU (Previous-In-Use) field indicates whether the chunk that is located right before the current chunk is also allocated 2. If that previous chunk is not in use, its last memory word is used by the current chunk as a 4-byte
prev sizefield that contains the previous chunk’s size. Finally, a freed chunk is placed as a node in a doubly-linkedfree listof similar-size deallocated chunks. The successor (fd) and predecessor (bk) pointers for this list are also maintained in the chunk itself. A more detailed overview of the heap and the organization of chunks can be found in Section3.1.
In general, there are two types of heap attacks: heap meta-data corruption and heap data corruption. The former type of attack relies on corrupting the meta-data information (size,prev size,PIU,fd, and/orbk) in order to execute malicious code or cause denial of service, while the latter type of attack relies on corrupting the heap data information such as function pointers (Chapter3). Heap meta-data 1Throughout this dissertation, allocated chunks will be represented in blue, free chunks in red, meta-data in light color (light blue or red), and the application’s data in dark color (dark blue or red).
2Actually, the last three bits in thesizenumeric field are used to store thePIUfield and some additional information.
corruption is by far the most frequently employed heap attack type [19]. Exam-ple vulnerabilities on popular programs include ones in Microsoft Windows [26], Microsoft’s Internet Explorer [31], the Mozilla web browser [32], CVS [29], Null httpd [23], Check Point Firewall-1 [30], and Apache [19]. This popularity of meta-data attacks is a result of interleaving meta-meta-data of free and in-use chunks with data of in-use chunks (Figure 1.1), which makes meta-data corruption relatively as easy as data corruption. At the same time, heap meta-data structures are not application-specific, so their corruption requires less detailed knowledge of the application.
rectly implementablein current systems without any new hardware or modifications to the application’s code. One potential major bottleneck for applications with a high allocation and deallocation frequency is the high latency of inter-process com-munication between the application and the Heap Server. Thus, we explore ways to hide this latency through three optimizations: non-blocking communication, bulk deallocation, and pre-allocation mechanisms.
Our second solution is based on the observation that heap attacks (as well as many other attacks) are based on writing to a location at a time when the write is not supposed to occur, such as when a buffer overflows. To protect a process from its own vulnerabilities, its data should betemporally protected, i.e. it should be pro-tected all the time except when a legitimate store needs to modify it. For example, heap meta-data should not be writable except when it is updated by the heap man-agement library 3. Through intra-process temporal protection, illegitimate stores that try to modify meta-data outside the heap management library will be detected and the attacks avoided. Conceptually, existing kernel-level page protection bits can provide such a temporal protection. However, in practice changing such pro-tection bits requires executing privileged instructions, which incurs a high-latency system call and context switches to/from the kernel. These latencies, as measured 3Similarly, a function’s return address on the stack should not be writable except during function calls and returns, but such protection is outside the scope of this work.
on a real machine, are in the millions of cycles.
and can be applied for other purposes that need intra-process temporal protection (e.g. protection of return addresses and function pointers).
Finally, to make heap data corruption attacks more difficult, we propose aheap layout obfuscationtechnique, which randomizes the heap layout and makes it dif-ficult for the attacker to attempt attacks that depend on a particular ordering of chunks in the heap region. This obfuscation is integrated with both Heap Server and UTIPP. Together with the existing address obfuscation technique [6], our lay-out obfuscation makes heap data corruption attacks even more difficult.
To take advantage of the Heap Server or UTIPP protection, only the alloca-tion/deallocation routines need to be modified. In most applications, they are localized in the heap management library. Thus, Heap Server and UTIPP only require changes to the heap management dynamic library or relinking the appli-cation with a new static library for heap management. Some appliappli-cations manage their own heap through custom allocation/deallocation routines. However, we found that custom routines are typically localized in very few functions. They can be augmented to use Heap Server or UTIPP without a significant programming effort.
We evaluate Heap Server and UTIPP differently. Since Heap Server does not
quire new hardware support, we implement and evaluate it using 24 benchmarks on a real platform, which is a 2-way SMP with 2-GHz Xeon processors running RedHat Linux 8.0. We found that, on average, a fully-optimized Heap Server per-forms almost identical to a traditional Base implementation with no heap protec-tion. We implement and evaluate UTIPP with a cycle-accurate event-driven sim-ulator, and find that it adds a maximum execution time overhead of 10.5% (-0.3% on average) for the same benchmarks.
Chapter 2
Related Work
Several approaches have been proposed in the past for reducing vulnerability to heap-corrupting attacks. One proposed solution is to make the heap non-executable [17]. This protection does not prevent denial-of-service and other at-tacks that do not rely on code injection, and atat-tacks in which malicious code is injected into another portion of the address space (e.g. the stack). Transparent Runtime Randomization (TRR) is an approach that randomizes the starting ad-dress of various segments (heap, stack, BSS, etc.) and dynamic library codes when a program is loaded [34]. Although TRR increases the difficulty of attacks that involve more than one segment, it cannot protect against attacks that are solely
carried out within the heap segment. Address obfuscation is another technique that, in addition to randomizing the starting address of the heap segment, also introduces random padding between consecutive heap chunks to make the heap layout less predictable [6], but does not really prevent heap attacks. PointGuard is an approach to defend against pointer corruption, where pointers are encrypted when they are written, and decrypted when they are read. This makes it harder for attackers to overwrite a pointer with a value that, once decrypted, points to de-sired malicious code. PointGuard requires the compiler to statically and accurately identify all pointer reads and writes in the code, and apply encryption/decryption on them [10]. In addition, PointGuard does not protect against attacks which do not rely on corrupting pointers as in non-control-data attacks [8].
bitrary memory location beyond the array bounds. For example, a vulnerability to integer overflow attack has been found in the Unix mail transport utility
send-mail [34]. In contrast, in Heap Server the heap meta-data cannot be corrupted because it is in a separate address space; in UTIPP, heap meta-data pages are al-ways protected when executing code outside the heap management library.
Non-executable-memory-based protections such as those implemented in StackPatch [27] and Microsoft Windows XP Service Pack 2 [22] cannot prevent non-control-data attacks and control-data attacks that do not rely on injecting ma-licious code [8].
Finally, page-level protection is provided by most operating systems through kernel-level access control bits associated with each virtual page in the page ta-ble and TLB entries. Hardware support for word-level protection has also been proposed through Mondrian Memory Protection (MMP) [33]. Since inter-process protection depends solely on these access control bits, changes to them require the processor to be in the privileged (system) mode. To change the protection bits, an application must perform a system call, which typically flushes the processor’s pipeline and traps to the kernel. This in turn typically flushes the TLB and some-times caches, incurs a page table walk, pollutes the cache with kernel code and
Chapter 3
Heap Attacks and Scope of Protection
In this chapter, we give an overview of the organization of the heap (Section 3.1), describe in detail the different types of heap attacks (Section 3.2), and finally dis-cuss Heap Server and UTIPP’s scope of protection (Section 3.3).
3.1. Heap Overview
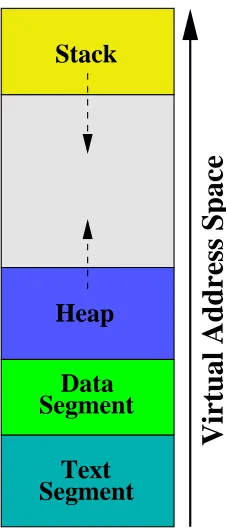
Figure3.1 shows a traditional virtual address space organization as seen from the user-space on Linux/Unix systems. It is made up of four main segments
Stack
Heap
Segment
Data
Text
Segment
Virtual Address Space
Figure 3.1: Application’s address space.
nized with lower virtual addresses at the bottom:
• Text Segment: Also referred to as the application’s code or binary. It contains
the application’s executable instructions and is usually read-only and fixed in size. Purposedly, the start address of this segment is not initialized to 0x00000000, in order to catch uninitialized pointers in the application.
Zero-• Heap: The heap is where dynamic data is allocated usingmalloc()and other
allocation functions. The heap can grow upward increasing the application’s address space by making calls to brk() and sbrk() with positive arguments. The size of the heap can also be decreased by making calls to sbrk() with negative arguments.
• Stack: The stack is where local variables are allocated. It is also where func-tion parameters and return addresses are placed. The stack grows down-ward.
Figure 3.2 shows a section of the application’s heap memory. The heap is di-vided into chunks. Chunks can be either allocated (shown in blue) or freed (shown in red). Chunks are allocated by calls to malloc() or similar functions. Allocated chunks are still in use by the application, whereas, freed chunks are chunks that were allocated by the application, used, and then freed (by a call tofree()or similar functions). As the figure shows, allocated chunks and freed chunks are interleaved.
In Doug Lea’s widely-used implementation [12], which is used in GNU C and other systems, chunk sizes are aligned to 8 bytes with a minimum size of 16 bytes1. Freed chunks are organized in bins of equal or similar sizes using a doubly-linked
1when used on a 32-bit x86 machine running Linux/Unix.
Freed
Allocated
Chunks
Chunks
4 Bytes
4 Bytes
Heap Segment
Address Base Chunk’s
Address Returned
size
PIU
Application
Data
PIU
Free
Space
bk
fd
size
size
Base Chunk’s
Address
Figure 3.2: An overview of the heap and chunk structures used in GNU C [12].
On a call to free(), or similar functions, the chunk is first consolidated with neighboring chunks if they are also free and of suitable sizes2and is then placed in a suitable bin based on its size using two pointers placed where the application’s data once was when the chunk was allocated.
The first four bytes of an allocated chunk are used to store the chunk’s size and additional information such as whether it is memory mapped (using the second least significant bit) and whether the previous chunk is used or not (the least sig-nificant PIU bit). The chunk size is needed to know the boundaries of the chunk when it is freed or re-allocated (by a call torealloc()). The PIU bit is used to identify whether the previous chunk is allocated or not for consolidation purposes.
For a freed chunk, there are three additional fields: The fdand bkpointers are used to place the chunk in a doubly linked-list bin. The last four bytes are also used to store the chunk’s size. This is used by the following chunk to read the size of this chunk if consolidation is to be performed.
Finally, when a freed chunk is removed from a bin (either to be allocated or consolidated), its predecessor and successor in the doubly-linked list bin are linked using theirfd and bkpointers, respectively. This can be done, for example, using 2Chunks smaller than a certain threshold are consideredfast chunks and are not consolidated normally.
code similar to the one below:
/* Assuming the chunk to be removed is P */
P->bk->fd = P->fd
P->fd->bk = P->bk
3.2. Heap Attacks
We will now describe heap attack mechanisms and illustrate them using a heap buffer overflow exploit, although other exploits such as format string and integer overflow are possible. The attack can be a control-data attack aimed at changing the control flow of the application in order to execute injected malicious code or out-of-context library code, or can be anon-control-data attackthat corrupts critical application data such as user identity information, configuration data, or decision-making data [8]. In the attacks illustrated below, we assume the attack is a control-data attackalthoughnon-control-data attackscan be performed almost similarly.
• denial of service
• forward consolidation
• backward consolidation
The fourth type,function pointer overwriteattack does not rely on corrupting heap meta-data. Instead, it corrupts heap data that contains, for example, a function pointer.
Each of the four types of attacks is illustrated below.
Denial of Service Attack
size B
size A
00000000000 00000000000 11111111111 11111111111 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000
11111111111 11111111111 11111111111 11111111111 11111111111 11111111111
Chunk A
Chunk B
size A
wrong size B
Initially
After A’s Buffer
is Overflown
(contains a buffer)
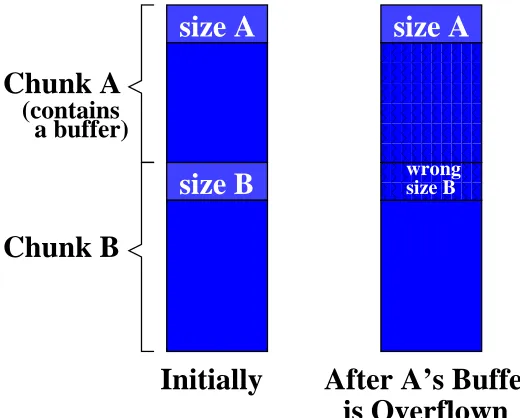
Figure 3.3: Denial of service attack.
Figure3.3shows two consecutive allocated chunks A and B, where A contains a buffer that is overflown in the attack.
The denial of service attack overflows the buffer in chunk A to overwrite chunk B’ssizewith a larger value. When chunk B is freed and its space allocated again, B’s data overlaps with that of subsequent chunks, which can cause the application to produce wrong output, crash, or hang. Similarly, overwriting B’s sizewith a smaller value causes a memory leak or crash when B is freed.
Forward Consolidation Attack
00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111
Chunk A
Chunk B
(contains a buffer)size B
size A
size B
fd
bk
Chunk C Chunk Dsize A
size B
funcptr funcptr br M br MInitially
size A
wrong size Bsize B
wrong bk wrong fdAfter A’s Buffer
is Overflown
After B is
Allocated
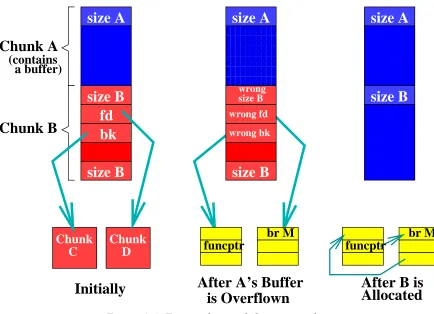
Figure 3.4: Forward consolidation attack.
The memory management library tries to avoid fragmentation of free heap space by merging consecutive free chunks into a larger one. As a result, deallocation of chunk A results in merging A with B. To do this, B is removed from its free list, merged with A, and the resulting chunk is inserted into another free list. Similarly, if chunk B is allocated, it is also removed from its free list. Removal of B from its free list is accomplished by copying B’sfdpointer into thefdof the chunk pointed to by B’sbkpointer as described earlier. This results in copying the malicious code address M into the target memory location which can be, for example, a return address on the stack or a function pointer. When this return address is used to
turn from a function or the function pointer is used to call a function, the attacker’s malicious code M is executed. The malicious code M could have been injected in chunk A’s buffer or anywhere else. Note also that the attacker may not insert ma-licious code at all, but use the attack to redirect the execution flow as desired. For example, the execution flow may be redirected to bypass a password check.
Backward Consolidation Attack
00000000000 00000000000 00000000000 00000000000 00000000000 00000000000
11111111111 11111111111 11111111111 11111111111 11111111111 11111111111
Chunk A
Chunk B
(contains a buffer)
size B
size A
funcptr funcptr
br M br M
size A
After A’s Buffer
is Overflown
After B is
fake fd
fake bk
size A
size B 0
new fd
new bk
size A + size B
size A + size B
Freed
Initially
Figure 3.5 shows a backward consolidation attack where the meta-data of an allocated chunk B is overwritten by overflowing a buffer in chunk A. The attack overwrites B’sPIUfield to falsely indicate that the previous chunk is free3. When chunk B is deallocated, the memory management library tries to consolidate B and A into a single larger chunk. The first step in this consolidation is to remove A from its free list. However, chunk A is actually allocated and the locations where itsfd and bkpointers would be is actually the beginning of the buffer. By placing fake
fdand bkvalues in chunk A’s buffer, one to point to malicious code and another to a target location minus displacement, the consolidation attempt actually over-writes the target location with the malicious code address and eventually results in execution of the malicious code or simply redirection of the application execution flow. Moreover, hybrid backward-forward consolidation attacks are possible, like the one used by the Slapper worm [19].
Function Pointer Overwrite Attack
Finally, in a function pointer overwrite attack a function pointer in a heap data chunk is overwritten to point to malicious code or to any section of the program 3Actually, by setting a fakeprev sizein the last four bytes of chunk A, the fake chunk can start from an arbitrary address that does not need to coincide with chunk A’s boundary.
allowing the attacker to control the application’s execution flow.
3.3. Scope of Protection
lay-out obfuscation discussed in Chapter6greatly improves the randomness of heap layout and makes heap data corruption even more difficult.
Although Heap Server and UTIPP only protect against heap attacks, it is impor-tant to also use them in conjunction with stack protection schemes such as Stack-Guard [9], because some heap-based attacks can bypass certain stack protections. For example, StackGuard places a canary value between a return address and local variables in the stack [9]. A buffer overflow that overwrites the return address also overwrites the canary value, which is checked before returning from the function to detect the attack. However, as illustrated earlier, some heap attacks can directly overwrite a single memory location with a desired value and can be used to by-pass StackGuard’s protection by overwriting the return address or the generated canary value itself [17].
Chapter 4
Heap Server Design
4.1. Modes of Operation and Optimizations
locate
chunk locate
chunk locatechunk locatechunk
Process (a) Heap Server Process (b) malloc()
. . .
free(). . .
malloc() book−keep free(). . .
. . .
book−keep book−keep book−keep (c) (d) msgsnd msgrcv msgsnd msgrcv. . .
. . .
book−keep free() malloc()Process Heap Server
msgsnd msgrcv (e) Process pre−allocate book−keep malloc() free() msgrcv Heap Server
. . .
. . .
. . .
. . .
book−keep book−keep free() malloc()Process Heap Server
msgsnd msgsnd msgrcv free() msgsnd book−keep
. . .
free() msgsndbook−keep
. . .
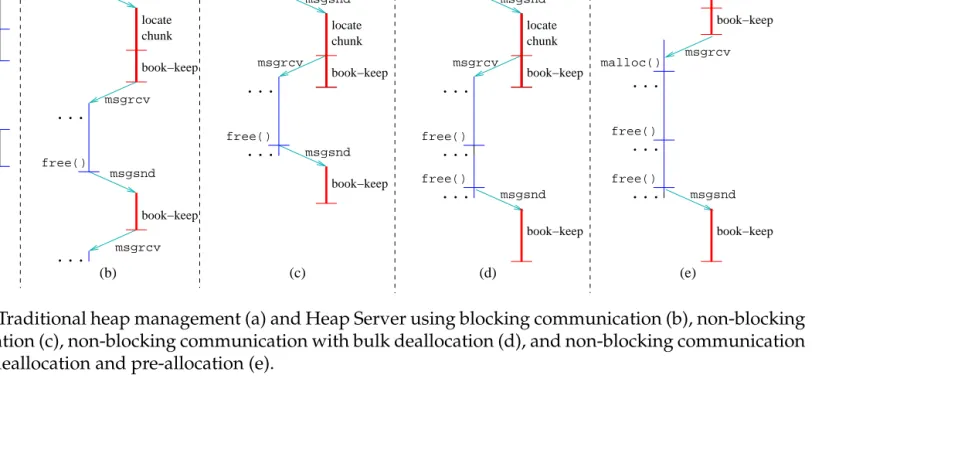
Figure 4.1: Traditional heap management (a) and Heap Server using blocking communication (b), non-blocking communication (c), non-blocking communication with bulk deallocation (d), and non-blocking communication with bulk deallocation and pre-allocation (e).
Heap Server is a separate process that is forked by the application when it starts. Although it is possible to run Heap Server as a daemon process which runs all the time and serves multiple different application processes, it has quite different implementation issues and is beyond the scope of this work. Figure4.1b shows the “base” unoptimized Heap Server, while the remaining parts (c, d, and e) show different Heap Server modes of operation, which represent different levels of optimizations. The base Heap Server implementation (Figure4.1b) operates simi-larly to a traditional heap management implementation, but uses standard System Vmsgsnd()andmsgrcv()primitives [16] to pass heap management operations to the Heap Server process. This fully blocking implementation of Heap Server introduces a significant overhead due to the high inter-process communication la-tency.
book-keeping in the background. In this way, part of the communication latency for deallocations and book-keeping latency for both allocations and deallocations are hidden from the application and are done in parallel with the application’s exe-cution. However, frequent deallocation requests can occupy the Heap Server and delay processing of allocation requests, for which the application is waiting.
Bulk Deallocation Optimization. To avoid delaying allocation requests due to high Heap Server occupancy, our bulk deallocation optimization groups mul-tiple deallocation requests into a single request (Figure 4.1d). The application temporarily stores each deallocation request locally, and when a limit is reached
(BU LK DEALLOC P T RS = 64 requests in our implementation), a new bulk
deallocation request is created and sent to the Heap Server. Upon receiving the bulk request, the Heap Server handles each deallocation sequentially. Although handling each deallocation in a bulk deallocation request takes just as much time as handling each deallocation request in the unoptimized case, the Heap Server overhead is reduced because it spends a lot less time fetching messages from the communication queue (a single message as opposed toBU LK DEALLOC P T RS
messages). Note that postponing the handling of a deallocation request does not affect correctness, although it may lead to a bounded increase of the memory
print. Finally, since bulk deallocation targets applications with a high deallocation frequency, its use is triggered only after a certain number of deallocations are per-formed (BU LK DEALLOC T HRESH= 1024 in our implementation).
Pre-allocation Optimization. Non-blocking and bulk deallocation optimiza-tions do not tackle the high inter-process communication latency suffered by cation requests, which is especially a problem in applications with frequent allo-cations. Fortunately, we observe that, in such applications, such frequent requests are typically caused by repeated allocations for only a few different types of small data structures. We exploit this observation by pre-allocating several chunks of those sizes in anticipation of future allocations (Figure4.1e). Pre-allocation is trig-gered when the total number of allocation requests exceeds a certain threshold
P RE ALLOC T HRESH = 1024, indicating that the application probably has a
the pre-allocation array without communicating with the Heap Server. When all the pre-allocated chunks for a certain size are consumed and there is a new request for that size, a new pre-allocation request is sent to the Heap Server. Moreover, Heap Server attempts to hide the allocation time, in addition to the communica-tion time, by pre-allocating newP RE ALLOC P T R chunks as soon as it replies to a pre-allocation request in anticipation of the next pre-allocation request. This way, at any given time, there are 2xP RE ALLOC P T R pre-allocated chunks of every common size in the system, half of them at the application’s side, and the other half at the Heap Server’s side.
Pre-allocation mispredictions are largely inconsequential. Unused pre-allocated chunks may result in memory fragmentation. Large fragmentation is avoided by only performing pre-allocation for small chunk sizes (less than 512 Bytes). The pre-allocation optimization hides the communication and allocation overhead for most frequent allocations and, together with non-blocking and bulk deallocation optimizations, allows the Heap Server and application execution to proceed almost fully in parallel.
4.2. Communication
Kharbutli - HeapServer
Ph.D. Preliminary Examination – May 20, 2005 22
HeapServer Interface
Memory
Hierarchy
Processor 2
Processor 1
Application SpaceApplication’s Heap
HeapServer Space
Malloc Library
Kernel
msgsnd/msgrcv Management Heap Structures Preallocated List
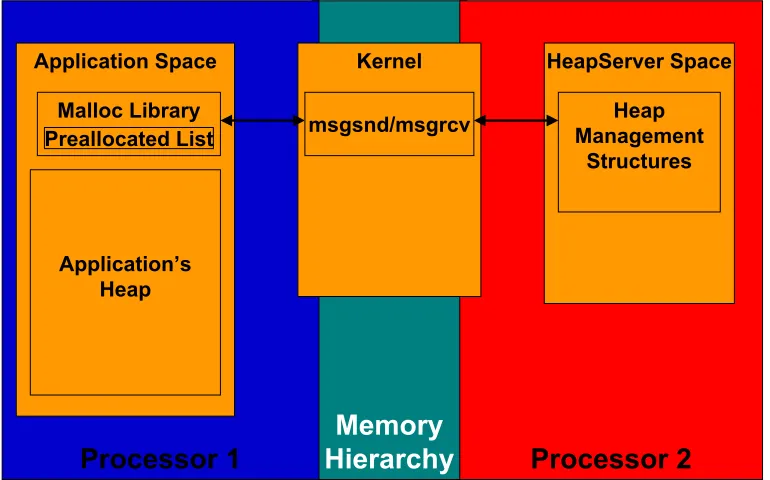
Figure 4.2: Heap Server’s interface.
Figure4.2 shows the communication interface between the application and its Heap Server. Communication between the application and its Heap Server process uses standard System V message-passing. The application sets up two message queues: aRequest Queuefor sending heap requests to the Heap Server, and aReply Queue for receiving Heap Server’s replies. A message M small has three fields:
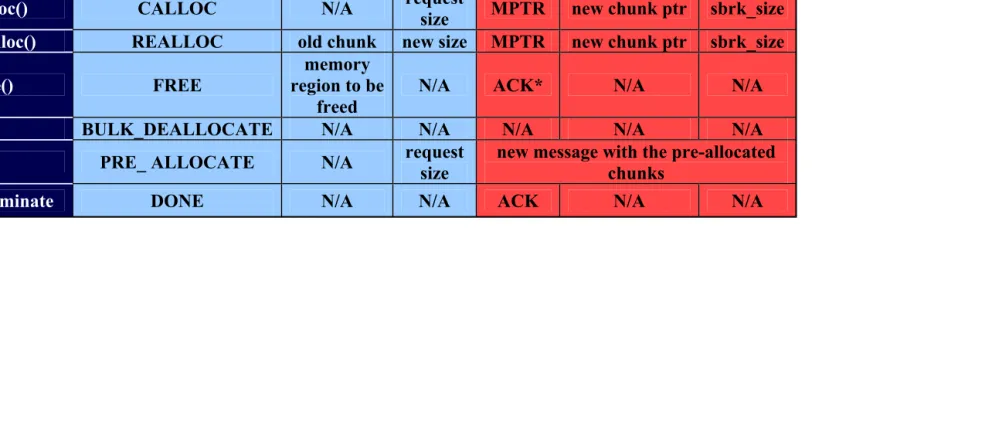
Table 4.1: Types of request and reply messages. * indicates that it is only generated for blocking communication.
Request Message Reply Message
Request
type mem_ptr value type mem_ptr value
malloc() MALLOC N/A request size MPTR new chunk ptr sbrk_size
calloc() CALLOC N/A request
size MPTR new chunk ptr sbrk_size
realloc() REALLOC old chunk new size MPTR new chunk ptr sbrk_size
free() FREE
memory region to be
freed
N/A ACK* N/A N/A
BULK_DEALLOCATE N/A N/A N/A N/A N/A
PRE_ ALLOCATE N/A request size new message with the pre-allocated chunks
Terminate DONE N/A N/A ACK N/A N/A
Table 4.1 lists the request and reply message types and their associated
mem ptrandvaluecontents. When the application process performs its first heap allocation, it uses an sbrksystem call with a zero argument to request the start-ing address of its heap memory space from the operatstart-ing system, which returns a pointer to the base address of the heap memory. Then the application creates the message queues and forks a Heap Server process. The Heap Server then initializes its meta-data structures using the application’s heap base address, and connects to the request and reply message queues.
coop-Server process is a direct consequence of the address space separation between the application and the Heap Server.
If Heap Server can not satisfy an allocation request because the application’s current heap region is too small, it requests additional heap memory by sending a positive value in the sbrk size field of the MPTR reply. The application then extends its heap region by the requested size through an sbrkcall. We note that Heap Server can not directly usesbrkon behalf of the application because it runs in a separate address space. The sbrk sizevalue may also be a negative value indicating that the application must trim its heap region through ansbrkcall. This ensures that the application’s memory footprint is kept to a minimum.
If bulk deallocation is used, aBULK DEALLOCATErequest is sent to Heap Server followed by an array of pointers to chunks to be deallocated. If pre-allocation is used, a PRE ALLOCATE request is sent to Heap Server, which in its turn replies with a group of pointers to pre-allocated chunks.
When bulk deallocation and pre-allocation are used, a larger messageM large is used. Similar to theM small message, the M largemessage has a typefield that identifies the type of the message (a bulk deallocation or a pre-allocation message) and an integer value field used in the pre-allocation message as a
sbrk sizefield. However, rather than a single mem ptr pointer field, there are several such fields that are used to pass the pointers of the chunks to be freed from the application to the Heap Server in a bulk deallocation, or the pre-allocated chunks from the Heap Server to the application in response to a pre-allocation
PRE ALLOCATErequest.
Finally, when the application process completes execution, it can send aDONE message to the Heap Server, which deallocates the process’ heap meta-data and terminates execution.
4.3. Meta-Data Structures
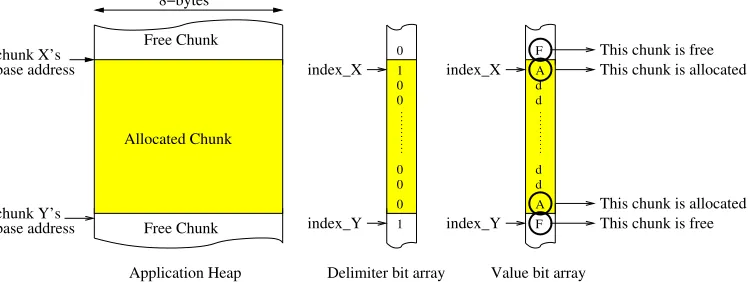
suitably-search by maintainingbins, each of which is a doubly-linked list of free chunks of the same or similar sizes. For Heap Server, we also need an implementation that allows fast lookup of a chunk’s and its neighbors’ sizes, as well as search for a suitably-sized chunk for allocation.
This chunk is allocated
This chunk is free This chunk is allocated This chunk is free
d d
F A F A d d index_X
index_Y index_Y
index_X 8−bytes
Free Chunk base address
chunk Y’s
Allocated Chunk Free Chunk base address
chunk X’s
Application Heap Delimiter bit array Value bit array 0
0
1 0 0 1 0 0
Figure 4.3: Bit-mapped meta-data information that is kept by the Heap Server.
One alternative is to keep lists of allocated chunks, similar to the free list struc-tures. These chunks can also be organized as a search tree or a hash table. To locate a chunk, the tree/table is searched for a matching address. However, at any given time there can be many (sometime millions of) small allocated chunks and there may also be many allocations/deallocations per unit time. In such programs, tree searches and re-balancing become time-consuming and the tree itself has a large memory footprint. Hash tables can maintain rapid lookup times, but become very large. As a result, we choose a bit-mapped implementation, which is efficient in
terms of space when chunks are small and which allows a chunk’s meta data to be located directly through simple indexing.
Given a chunk’s address, its meta-data is located by simple indexing to the de-limiter and value bit arrays, and the bits corresponding to the chunk are extracted through bit masking. To compute the sizes of a chunk and its neighbors, delimiter bits are fetched as a 32-bit word, and the locations of ’1’s are found using bit scan forward (bsfl) and bit scan reverse (bsrl) x86 instructions. For chunks whose value bits span over more than two 32-bit words, the chunk’s size is stored and read directly from the value bit array.
To facilitate fast re-allocation of deallocated chunks, we also maintain free-list structures similar to traditional C heap library implementations [12]. However, instead of keeping the prev size and size fields, we only keep the addresses of free chunks and use them to access the bit-arrays where the rest of the meta-data can be found. In addition, to reduce the storage overhead of the free lists, we implement them as singly-linked lists, in which each node only stores the chunk’s address and the list’s forward pointer.
Compared to traditional interleaved meta-data implementation, Heap Server incurs an extra 3.1% overhead to keep the delimiter and value bit arrays, plus a small bounded overhead to keep the free list structures. In some cases, sepa-rating heap data and meta-data storage improves performance because, without
meta-data, heap data is more compact and has better spatial locality. However, there are cases where spatial locality exists between data and meta-data, and in this case, separating them results in a slight loss of performance. We also tried tree or hash meta-data implementations, but such structures required at least 160 bits per chunk, so our bit-map scheme is more space-efficient when the average chunk size is less than 640 bytes, which is the case for many applications as we will demonstrate in Section8.1.
4.4. Heap Server’s Security
Because Heap Server interacts with other processes only through request and response message queues, it is imperative to keep each process’s queues private between that process and its Heap Server process. There are two types of attacks that can be attempted on the Heap Server. First, a rogue process may destroy the communication queues. It may also read messages from, and write messages to the communication queues. Unfortunately, System V message queues were designed for simple inter-process communication and lack protection against those attacks. Simple modifications to the communication queue implementations can greatly improve their security. Specifically, a queue should have anownerprocess, which is the only process besides of the OS that can destroy the queue. In addition, a queue should maintain aparticipants list which contains the IDs of processes that can read from or write to the queue. Only the owner process can add or remove a participant process into or from the list. Each time a process executes amsgsnd() andmsgrcv(), its ID is checked, and an error is returned if its ID is not found in the participants list and does not match the owner ID.
When an application creates communication queues, it becomes the owner of the queues, and adds the forked Heap Server process ID as a participant of the queues. This mechanism prevents other processes from destroying, reading from, or writing to the queues, since they are neither the owner nor participants of the
queues. It is possible that an application may crash while the Heap Server is run-ning. To avoid the Heap Server from becoming an orphan process that keeps wait-ing for requests to handle, periodically each message queue should be checked to determine if the queue’s owner or participant is no longer alive. If it is found that the application’s process is no longer present in the system, the Heap Server is terminated and the message queues are freed.
de-can be surrounded with write-protected pages. Hence, buffer overflows in the application cannot write to this new meta-data without incurring a segmentation fault. Fourth, because the amount of meta-data is small, we can duplicate it by writing identical dual-copies at different (possibly random) locations. To read the meta-data, all copies are fetched and an attack is detected if not all copies are iden-tical. Note that keeping separate identical copies of meta-data cannot be easily or cheaply done if the application maintainsall of its heap meta-data in its address space because of the sheer amount of meta-data involved. Finally, pre-allocation array and bulk deallocation information can themselves be protected temporally, e.g. through existing kernel-level page-level protection. Our current Heap Server implementation includes a dual-copy protection mechanism in which two copies of the bulk deallocation requests and pre-allocation arrays are maintained at the application’s side.
Finally, a full implementation of Heap Server can be found in Appendix B along with some instructions on compiling and running it.
Chapter 5
User-Level Temporal Intra-Process
Protection (UTIPP)
tect the application’s meta data from the application’s own vulnerabilities. Since the heap meta-data can only be legitimately modified by the heap management library, at all other times the meta-data should be write-protected to prevent ille-gitimate modifications. We note that heap meta-data can easily be separated from heap data by placing it in separate pages, so page-level protection is sufficient. Finer-grain word-level protection a la Mondrian Memory Protection [33] can also be used, although it would be an overkill.
Most current operating systems (OS) already provide page-level protection through access control (read/write/execute) bits for each virtual page in the page table as well as TLB entries. Since the bits serve as the foundation to inter-process protection mechanisms, they can be manipulated only in the privileged mode. When an application wants to change the protection bits for a page, it has to make a system call which traps to the kernel, such as through themprotect()system call in Linux. Measured on a real system, such a call costs up to millions of cy-cles because it raises an exception that flushes instructions in the pipeline, saves the current context and switches to the kernel, flushes the TLB and sometimes all caches1, walks through the page table to change the protection information of the corresponding page, pollutes caches with kernel code and data, and causes sub-1In some systems, caches are flushed to avoid traversing them to find entries corresponding to the affected pages.
sequent cache misses when the application resumes. Compounding the problem, a single allocation/deallocation request typically results in modifications of meta-data in several non-contiguous pages and needs multiple system calls. Word-level protection would incur even higher overheads because even more system calls must be made.
sors [14] already have multiple unused bits in the page table reserved for future use. In addition, some processors already have instructions to modify a TLB en-try [13]. However, those instructions can only be executed in the privileged mode and UTIPP will require similar instructions that can run in user mode and that can only modify the user-level write-protection bit. Alternatively, existing instruc-tions can be allowed to manipulate only the user-level write-protection bit if they execute in the user mode.
Each store is checked against the write-protection bit and raises an exception if it tries to write to a location in a write-protected page. In an out-of-order proces-sor, it is necessary to maintain the correct ordering between the instructions that set/clear the write-protection bits and store instructions. To achieve that, the exe-cution of a write-protection instruction is delayed if there are preceding stores or write-protection instructions with overlapping addresses that have not been exe-cuted, or if their addresses are not known yet. Likewise, store instructions are de-layed from accessing the TLB entries until preceding write-protection instructions with overlapped addresses have been executed, or if their addresses are not known yet. This mechanism does not add much performance overheads for several rea-sons. First, write-protection instructions only delay stores which are typically not in the processor’s critical path, and do not delay loads. In addition, write-protect
instructions occur very infrequently (only in the heap management library). Even for programs with very frequent allocations and deallocations, the frequency of write-protection instructions is much smaller than that of loads/stores.
5.1. Implementation
5.2. UTIPP Security
For a heap meta-data corruption attack to succeed in UTIPP, the attacker must (1) unprotect the meta-data page, (2) corrupt it, and (3) protect it again to avoid detection. This three-step attack requires exploiting several specific vulnerabilities in the function’s code. In particular, the attacker must cause the application to unprotect a given heap meta-data page at the beginning of the attack. To do that, the attacker needs the ability to redirect the application’s control flow to a desired memory location (where the unprotect instruction is). However, such ability to re-direct control flow is the goal of the entire attack and is not available before the attack begins – if it is available, the attacker already controls the application and needs no heap meta-data attack. In contrast, without temporal protection, the attacker only needs the ability to overwrite the meta-data.
Note that only user-level write-protection bits can be manipulated in user mode. The privileged-mode access control bits are still present and used by the OS for its regular protection mechanism. With UTIPP, a page is considered writable only if writes are permitted by both the user-mode and privileged-mode access control bits. This prevents use of our user-level write-protection mechanism to de-feat system-level protections. On the other hand, in the privileged mode the OS
Chapter 6
Heap Layout Obfuscation
Our heap layout obfuscation augments existing address obfuscation [6] to make the exact position of a particular heap-based data less predictable. With address obfuscation, each allocation request is padded with a randomly-sized padding. The padding size is between zero bytes (no padding) and the minimum of 64 bytes and 12.5% of the requested chunk size. The padding size is limited to avoid exces-sive fragmentation. The random padding makes the precise location of the target function pointer relative to the buffer to be unknown. However, to optimize for temporal locality, a deallocated chunk is often immediately reallocated when there is an allocation request to the same size. Such temporal locality optimization
Chapter 7
Evaluation Methodology
Heap Server Evaluation
Because Heap Server does not require new hardware support, we evaluate it on a real bus-based symmetric multiprocessor (SMP) with two 2GHz Intel Xeon pro-cessors. Each processor is simultaneously multi-threaded (SMT) with two thread contexts, has a small L1 data cache, a small L1 instruction trace cache, and a uni-fied 512KB L2 cache. Both processors share a common memory bus. The memory controller is part of the Intel 860 Chipset and the main memory is 512MB of Ram-bus RDRAM. The operating system on the machine is Red Hat Linux 8.0, kernel version 2.4.20, and supports SMP. The machine is run under a relatively light load,
where normal Linux OS processes run, but we do not run major applications ex-cept the application and the Heap Server. Machine cycles, read using therdtsc Read Time-Stamp Counter instruction, are used to compute runtimes. Each exper-iment is run ten times1 and the results averaged when reporting them to reduce noise in the data we present. Both the applications and the Heap Server are com-piled withgccversion 3.2 with a-O3optimization level. All benchmarks are run from start to completion. No skipping or sampling is used.
To evaluate the Heap Server, we use all 16 C/C++ benchmarks from the SPEC CPU 2000 benchmark suite [28], which is a popular suite for evaluating processor performance: ammp, art, bzip2, crafty, eon, equake, gap, gcc, gzip, mcf, mesa, parser, perlbmk, twolf, vortex, and vpr. Benchmarks written in Fortran are not used because they do not use dynamic memory allocation and perform identically with and without the Heap Server. All our benchmark runs use the SPEC CPU 2000 reference input sets.
several memory allocation studies [4,2,3,5,11,15,21,7].
Table7.1lists the 24 benchmarks used, their categories, sources, programming languages, inputs, and run times.
UTIPP Evaluation
We evaluate UTIPP using a cycle-accurate event-driven simulator based on SESC [20] that supports an aggressive out-of-order superscalar processor model. Table7.2shows the parameters used for each component of the architecture.
To evaluate UTIPP, we use the same 24 benchmarks and inputs used for evalu-ating Heap Server (Table7.1). However, we do not evaluate perlbmk and roboop because we were unable to run them on our simulator. The applications were com-piled with the-O3optimization flag. Because we are evaluating the performance of several different heap management libraries, we run each application for a fixed number of heap allocation/deallocation requests. The number of heap requests simulated varies among benchmarks and was chosen to correspond to about two billion instructions when the application uses theBaseallocation library described below. The benchmarks along with the number of simulated instructions and heap requests when using the Base heap management library are summarized in
Table 7.1: The 24 applications used in our evaluation, their categories, sources, programming languages, inputs, and run times.
Benchmark Category Source Language Input Used
Run Time
(sec)
ammp Computational Chemistry SpecFP2000 C ref 644
art Image Recognition / Neural Networks SpecFP2000 C ref 465
boxed Boxed Spheres Simulation Heap Layers C -n 50 -s 1 85
bzip2 File Compression SpecINT2000 C ref
(input.source) 90 cfrac Large Integer Factorization Heap Layers C a 40 digit number 34
crafty Game Playing: Chess SpecINT2000 C ref 158
deltaBlue Incremental Dataflow Constraint Solver Other C++ 100000 4
eon Computer Visualization SpecINT2000 C++ ref (cook) 101
equake Seismic Wave Propagation Simulation SpecFP2000 C ref 180
espresso PLA Optimizer Heap Layers C largest.espresso 251
gap Group Theory, Interpreter SpecINT2000 C ref 160
gcc C Programming Language Compiler SpecINT2000 C ref (200.s) 59
gzip File Compression SpecINT2000 C ref
(input.source) 45
lindsay Hypercube Simulator Heap Layers C++ script.mine 92
LRUsim Locality Analyzer Heap Layers C++ 20,000,000 accesses 48
mcf Combinatorial Optimization SpecINT2000 C ref 319
mesa 3-D Graphics Library SpecFP2000 C ref 274
parser Word Processing SpecINT2000 C ref 318
perlbmk PERL Programming Language SpecINT2000 C ref (splitmail) 62
richards OS Kernel Task Dispatcher Simulator Other C++ 100000 447
roboop Robotics Object-Oriented Package Heap Layers C++ bench 4
twolf Place and Route Simulator SpecINT2000 C ref 597
vortex Object-Oriented Database SpecINT2000 C lendian2 87
Table 7.2: Parameters of the simulated architecture. RT stands for round-trip from the processor.
Clock Rate 5 GHz
Issue Unit 6-issue dynamic
Integer, FP, LD/ST units 8, 8, 2/2
ROB Entries 156
Integer/FP Registers 128/128
Branch Predictor Hybrid, 16 KB
Processor
BTB 4 KB
DTLB 128 entries, FA, random replacement
ITLB 128 entries, FA, random replacement
Hit Time 1 Cycle
Miss Time 500/1000/2000 cycles
TLB
Write-back Time 500/1000/2000 cycles
L1 Instruction Cache 16 KB, 2-way, 64-B lines, WB, 2-cycles RT, 16-entry MSHR
L1 Data Cache 16 KB, 2-way, 64-B lines, WB,
2-cycles RT, 16-entry MSHR
L2 Unified Cache 512 KB, 8-way, 64-B lines, WB,
10-cycles RT, 32-entry MSHR
Memory Bandwidth 3.2 GB/sec
Memory
Hierarchy
Main Memory 75 ns latency
ble7.3.
The Base Heap Management Library
We evaluate Heap Server and UTIPP against aBaseheap management library that we developed. The library is based on Doug Lea’s heap management library v.2.7.2 [12], which is a very popular heap management library used in GNU C and in other systems. We evaluated the performance of ourBaseimplementation compared to the traditional one and found that their performance was on average
Table 7.3: The applications used in our evaluation of UTIPP along with the number of simulated heap requests and the corresponding number of instructions when theBaseheap management library is used.
Benchmark Instructions Retired Requests Heap
ammp 1,628,461,873 34,750
art 2,000,000,000 30,940
boxed 2,001,272,307 65,200
bzip2 2,000,000,000 10
cfrac 2,026,435,250 1,100
crafty 2,000,000,000 42
deltaBlue 2,003,057,132 1,437,000
eon 2,000,000,000 4,517
equake 2,001,271,392 538,000
espresso 2,001,057,272 470,300
gap 2,000,000,000 15
gcc 2,007,943,145 7,750
gzip 2,000,000,000 6
lindsay 2,001,605,126 1,307,650
LRUsim 2,810,248,202 2,040
mcf 2,000,000,000 7
mesa 2,000,000,000 66
parser 2,566,140,361 110
richards 1,999,520,209 7,880
twolf 5,612,570,884 33,800
vortex 2,000,111,001 104,535
vpr 2,000,000,000 68,281
To evaluate Heap Server and UTIPP’s ability to protect against heap attacks, we first devised three attack kernels representing three different types of attacks described in Chapter3: backconis a backward consolidation attack,forconis a for-ward consolidation attack, and funptris a function pointer overwrite attack. The three attack kernels aim to, directly or indirectly, overwrite a function pointer in order to re-direct the application’s execution to malicious code. We consider the attack a success if it succeeds in modifying any function pointer in the application.
In addition, we obtained two real-world exploits that perform heap attacks. They are:
• Wu-Ftpd File Globbing Heap Corruption Vulnerability [24] against
Washing-ton University’s FTP daemon (ftpd).
• Sudo Password Prompt Heap Overflow Vulnerability [25] against the Linux/Unix sudo utility.
Chapter 8
Heap Server Evaluation
This chapter presents a characterization of the heap requests in the 24 applications (Section8.1) and our evaluation of Heap Server’s performance (Section8.2).
8.1. Benchmark Characteristics
re-quests, request frequencies, request distribution over time, allocation request sizes, memory footprints, and in the fraction of the total execution time spent servicing requests. This diversity is beneficial because it tests our heap protection mecha-nisms under a wide range of different benchmark behavior. Moreover, this char-acterization will help explain some of the later observations.
Table 8.1 shows the total number of different heap requests for the 24 bench-marks. The table only shows the requests made to the standard heap management functions (malloc(), calloc(), realloc(), and free()), and does not include requests made to a custom memory allocator, if one exists. As the table shows, the benchmarks differ greatly in their heap allocation behavior. The num-ber of allocation (malloc and calloc) requests ranges from 5 in mcf to over 10 mil-lion in espresso. Nine benchmarks (boxed, deltaBlue, equake, espresso, lindsay, perlbmk, richards, roboop, and vortex) have over a million allocations each. On the other hand, five benchmarks (bzip2, crafty, gap, mcf, and mesa) have less than 100 allocations each. Applications with a large number of allocations are likely to benefit from Heap Server’s pre-allocation optimization.
The benchmarks differ in their deallocation behavior as well. Two benchmarks (equake and richards) have no deallocation requests. This is either because the
Table 8.1: Total number of allocation and deallocation requests for the 24 benchmarks.
Benchmark malloc() calloc() realloc() free()
ammp 38,141 0 0 3,371
art 30,488 0 0 2
boxed 1,056,735 0 41 1,046,877
bzip2 12 0 0 2
cfrac 16,866 0 0 16,403
crafty 39 0 0 2
deltaBlue 2,001,020 0 0 501,006
eon 1,932 0 0 1,303
equake 1,335,067 0 0 0
espresso 10,485,624 0 3,159 10,485,620
gap 68 1 0 66
gcc 55,485 0 4 50,534
gzip 33,084 0 0 33,080
lindsay 7,994,779 0 0 7,994,776
LRUsim 21,974 1 0 21,912
mcf 2 3 0 5
mesa 13 49 0 58
parser 150 0 0 147
perlbmk 5,215,911 0 211,639 5,065,621
richards 2,600,001 0 0 0
roboop 6,793,550 0 0 6,793,389
twolf 561,505 13,062 4 492,727
vortex 6 1,518,382 0 1,446,306
vpr 34,313 8 6 34,152
its allocated heap objects. Benchmarks with a large number of deallocations will likely benefit from Heap Server optimizations that target deallocations, such as non-blocking communication and bulk deallocation.
Maximum Heap Size (Bytes)
100,000 1,000,000 10,000,000 100,000,000 1,000,000,000
a
mmp ar
t
boxed bzi
p
2
cfrac crafty
del
taBl
ue eon
equake
espr
esso gap gcc gzi
p
lindsay LRUsim
mcf
me
sa
par
ser
per
lbm
k
richar
ds
roboop twolf vortex
vpr
Figure 8.1: Maximum heap memory footprint in Bytes (logarithmic scale)
Figure 8.1 shows the maximum heap memory’s footprint in bytes reached by each of the 24 benchmarks during execution. The figure is in logarithmic scale. Note that an application’s heap memory’s footprint may grow and shrink dur-ing execution. It grows when the heap management makes an sbrk call with a positive argument asking the operating system to extend the application’s heap by assigning new physical pages. Similarly, the heap memory’s footprint shrinks when the heap management library makes ansbrkcall with a negative argument. This happens when the size of the free region at the top of the heap exceeds a
tain threshold after deallocation. The benchmarks have a wide range of maximum memory footprints ranging from 256 KB1for roboop to 192 MB for gap.
Average Heap Requests per Second
0 0 1 10 100 1,000 10,000 100,000 1,000,000 10,000,000
ammp
art
boxed bzip2 cfrac crafty
deltaBlue
eon
equake
espresso
gap gcc gzip lindsay LRUsim
mcf
mesa parser
perlbmk richards roboop
twolf
vortex
vpr
0.1 0.01
Figure 8.2: Average heap requests per second (logarithmic scale)
Figure8.2shows the heap requests frequency, measured as the number of allo-cation and dealloallo-cation requests per second, for each appliallo-cation. The figure shows that the benchmarks have a wide range of heap requests frequency: high/very high – more than 2,000 up to 3,367,281 (boxed, deltaBlue, equake, espresso, lindsay, perlbmk, richards, roboop, and vortex), medium – between 10 to 2,000 (ammp, art, cfrac, eon, gcc, gzip, LRUsim, twolf, and vpr), and low – below 10 (bzip2, crafty, gap, mcf, mesa, and parser). We pay a particular attention to benchmarks with high/very high heap request frequencies because they stress our heap protection
![Figure 1.1: Simplified heap chunk structure used in GNU C [12].](https://thumb-us.123doks.com/thumbv2/123dok_us/1508079.1184674/15.612.166.485.462.652/figure-simplied-heap-chunk-structure-used-in-gnu.webp)
![Figure 3.2: An overview of the heap and chunk structures used in GNUC [12].](https://thumb-us.123doks.com/thumbv2/123dok_us/1508079.1184674/29.612.138.513.87.423/figure-overview-heap-chunk-structures-used-gnuc.webp)