A DOMAIN-DRIVEN METHOD FOR CREATING
SELF-ADAPTIVE APPLICATION ARCHITECTURE
Jin Huang
A Thesis Submitted for the Degree of MPhil
at the
University of St Andrews
2017
Full metadata for this item is available in
St Andrews Research Repository
at:
http://research-repository.st-andrews.ac.uk/
Please use this identifier to cite or link to this item:
http://hdl.handle.net/10023/15644
A Domain-Driven Method for Creating Self-Adaptive
Application Architecture
Jin Huang
This thesis is submitted in fulfilment for the degree of MPhil
at the
University of St Andrews
1. Candidate’s declarations:
I, Jin Huang, hereby certify that this thesis, which is approximately 22000 words in length, has been written by me, and that it is the record of work carried out by me, or principally by myself in collaboration with others as acknowledged, and that it has not been submitted in any previous application for a higher degree.
I was admitted as a research student in [09, 2011] and as a candidate for the degree of MPhil in [03, 2017]; the higher study for which this is a record was carried out in the University of St Andrews between [2011] and [2017].
(If you received assistance in writing from anyone other than your supervisor/s):
I, Jin Huang, received assistance in the writing of this thesis in respect of [language, grammar, spelling or syntax], which was provided by Janie Brooks
Date …… signature of candidate ………
2. Supervisor’s declaration:
I hereby certify that the candidate has fulfilled the conditions of the Resolution and Regulations appropriate for the degree of ……… in the University of St Andrews and that the candidate is qualified to submit this thesis in application for that degree.
Date …… signature of supervisor ………
3. Permission for publication: (to be signed by both candidate and supervisor)
In submitting this thesis to the University of St Andrews I understand that I am giving permission for it to be made available for use in accordance with the regulations of the University Library for the time being in force, subject to any copyright vested in the work not being affected thereby. I also understand that the title and the abstract will be published, and that a copy of the work may be made and supplied to any bona fide library or research worker, that my thesis will be electronically accessible for personal or research use unless exempt by award of an embargo as requested below, and that the library has the right to migrate my thesis into new electronic forms as required to ensure continued access to the thesis. I have obtained any third-party copyright permissions that may be required in order to allow such access and migration, or have requested the appropriate embargo below.
The following is an agreed request by candidate and supervisor regarding the publication of this thesis:
PRINTED COPY
a) No embargo on print copy
b) Embargo on all or part of print copy for a period of … years (maximum five) on the following ground(s): • Publication would be commercially damaging to the researcher, or to the supervisor, or the University • Publication would preclude future publication
• Publication would be in breach of laws or ethics
c) Permanent or longer term embargo on all or part of print copy for a period of … years (the request will be referred to the Pro-Provost and permission will be granted only in exceptional circumstances).
Supporting statement for printed embargo request if greater than 2 years:
ELECTRONIC COPY
a) No embargo on electronic copy
b) Embargo on all or part of electronic copy for a period of … years (maximum five) on the following ground(s): • Publication would be commercially damaging to the researcher, or to the supervisor, or the University • Publication would preclude future publication
• Publication would be in breach of law or ethics
ABSTRACT AND TITLE EMBARGOES
An embargo on the full text copy of your thesis in the electronic and printed formats will be granted automatically in the first instance. This embargo includes the abstract and title except that the title will be used in the graduation booklet.
If you have selected an embargo option indicate below if you wish to allow the thesis abstract and/or title to be published. If you do not complete the section below the title and abstract will remain embargoed along with the text of the thesis. a) I agree to the title and abstract being published YES/NO
b) I require an embargo on abstract YES/NO c) I require an embargo on title YES/NO
Date …… signature of candidate …… signature of supervisor ………
Please note initial embargos can be requested for a maximum of five years. An embargo on a thesis submitted to the Faculty of Science or Medicine is rarely granted for more than two years in the first instance, without good justification. The Library will not lift an embargo before confirming with the student and supervisor that they do not intend to request a continuation. In the absence of an agreed response from both student and supervisor, the Head of School will be consulted. Please note that the total period of an embargo, including any continuation, is not expected to exceed ten years.
Acknowledgement
I would like to offer great thanks to my supervisor Dr. Dharini Balasubramaniam who gave me a chance to do research under her valuable guidance. I really appreciate that she is always being patient with me, even when I was suffering healthy and mental problems. I would like to show my special thanks to Ms. Janie Brooks for her great help in my English study.
Abstract
Table of Contents
Abstract...1
1 Introduction...3
1.1 Issues of uncertainty...3
1.2 Importance of software architecture...3
1.3 Principled software architecture design...4
1.4 Self-adaptation...4
1.5 Motivations...5
1.6 Dissertation organisation...5
1.7 Summary...6
2 Related work...8
2.1 Software architecture and patterns...8
2.2 Software architecture design methods...11
2.3 Software architecture description methods...11
2.4 Uncertainty...12
2.5 Self-adaptive software system design methods...13
3 Proposed approach...14
4 A framework for understanding software architecture in an uncertain context...16
4.1 A self-consistent terminology...16
4.2 Properties of interest...18
4.3 Architectural patterns for self-adaptive applications...19
4.4 Summary...21
5 The role-behaviour-based modelling language...22
5.1 Design principles...23
5.2 Conceptual model...24
5.3 Grammar...26
5.4 A simple event calculus...28
5.5 Consistency checking...30
5.5.1 Using process calculus...30
5.5.2 Using transitions...30
5.5.3 Generating architectural outline with business constraints...31
5.6 Completeness checking...32
5.7 Summary...32
6 Grasp+:an enhanced version of Grasp...32
6.1 Grasp...33
6.2 Problems...34
6.3 The role-action-based conceptual model...34
6.4 Grammar...35
6.5 Case-Study: An intelligent data-providing system...37
6.6 Summary...39
7 Case study – an intelligent multiple strategies trading system...41
7.1 Domain requirements...42
7.1.1 stakeholders...42
7.1.2 Functional requirements...43
7.1.3 Non-functional requirements...43
7.2 Domain model...44
7.3 Architecture descirption...46
7.4 Proposed implementation...50
7.5 Evaluation...51
7.6 Summary...53
1
Introduction
Both the growing complexity of current software systems and context requirements necessitates the research in the field of self-adaptive software systems [1]. However, to construct a self-adaptive application is still not easy, especially in a complex environment, e.g. a mobile environment. Further, architects now are facing the issues arising from uncertainties that are sourced from requirements [2], e.g. handling human errors, behaving intelligently, collaborating among multiple platforms in a dynamic environment, self-adapting. In this situation, one big problem is about constructing self-adaptive applications which have a desired behaviour that is consistent with their domain requirements. As a consequence, our research focus on the work on how best to make architectural decisions from domain requirements for providing desired properties to self-adaptive applications.
1.1 Issues of uncertainty
Nowadays, domain requirements are becoming increasingly complex, and thereby the design of a modern software application system is becoming dramatically more complicated and software engineering research is facing new challenges. One of the challenges is uncertainty. The sources of uncertainty are various, e.g. “unknownness” [3] and changing requirements. Traditionally, software engineering research concerns how best to resolve issues of a domain by modelling the certainty aspects of this domain. To successfully construct a software system, ideally, software engineers should first have a complete understanding of the design context and foresee any issues. But, in practice, software engineers may not be able to understand and foresee everything. That is one of the reasons why software application systems fail: people believe that it is possible to have a complete and clear understanding of their projects, but in reality, it is not true [2]. The world is changing and uncertain, so software engineers need new methods to ensure their design survive in this world. In this situation, to help construct applications that can deal with uncertainty, software architecture research faces new challenges: What uncertainty issues exist at architectural level? how best model the uncertainty at architectural level? How are context uncertainty and architectural decisions related? how best to make architectural decisions to handle uncertainty.
1.2 Importance of software architecture
architecture in terms of their experience and work, and to emphasise the significance of our work, we have the main (not all) advantages of having a software architecture listed below [4] [5] [6] [7]:
• A well-documented architecture improves communication among stakeholders;
• An architecture works as an abstract guidance of how a software system can address context
concerns;
• An architecture can be used as a basis for estimating costs;
• An architecture helps partition a software system into parts and thereby different groups of people
can work cooperatively and productively together to solve a more complex problem;
• An architecture can be used as a basis for performing dependency and consistency analysis;
• An architecture can be used as a basis for reasoning about this system’s properties and behaviour at
design stage; and
• An architecture can be used as a basis for managing and reasoning about changes.
1.3 Principled software architecture design
The design of software architecture is principled. In other words, a software architecture is created following a set of constraints from its context. The context of a software system has multiple aspects due to the existence of the stakeholders of this system, e.g. technical and business aspects. For example, before making architectural decisions, architects should have a clear understanding of what the business purposes of this project are, what technologies can be used to complete this project, how long the project’s lifetime is, and what properties desired of this system are, etc.. A well-designed architecture can be reused and applied in order to obtain the same properties in the future. A software architectural pattern (or styles) is a package of architectural decisions that have been proven in practice. It is more abstract than an architecture, and a software architecture is an instance of a software architectural pattern [5]. As Fielding illustrated in his work [8], architects can successfully create their own architectures by making their architecture as an instance of one or more architectural patterns.
1.4 Self-adaptation
dependable, energy-efficient, recoverable, customisable, configurable, and self-optimising [1]. However, self-adaptation is not a silver bullet for solving all complexity issues, and by introducing a self-adaptation process, a system may have more uncertainty introduced as well, e.g. uncertain plans [11]. In addition to this, architects may need to consider the impact of using self-adaptation on a software system, e.g. resource limitation, performance impact. A software system may contain more than one self-adaptation processes, and the need to guide carefully the design necessitates considering the coordination mechanism of coordinating these processes at architectural level.
1.5 Motivations
This dissertation explores a junction on the frontiers of three research disciplines in software engineering: software architecture, self-adaptation and system uncertainty processing. Software architecture research has long been concerned with the architectural decisions concerning certain aspects of software systems, but has rarely been able to evaluate objectively the impact of various design choices on uncertain system behaviour. In addition to this, researchers in this field do not concern much on the relationship between business constraints and architectural decisions. Self-adaptation research mainly focuses on how best to model a self-adaptation process, how an uncertainty can be solved by introducing a self-self-adaptation process, and how best to construct a adaptive software system in a given context, often ignoring the fact that introducing adaptation can bring new uncertainties and there is still a lack of the guidance on how best to build a self-adaptive software system when considering both the business constraints and architectural uncertainty. On the other hand, the community of architectural uncertainty research often pay attention to the methods of modelling and describing uncertainty and the methodologies of reasoning about possible system behaviour at architectural level, rather than the methods concerning how best to resolve architectural uncertainties by making appropriate architectural decisions which are consistent with business constraints.
As a consequence, my work is motivated by the desire to understand and evaluate the architectural design of a self-adaptive application system through principled use of business and architectural constraints, thereby obtaining the desired properties of an architecture in an uncertain context. In short, the output of this work is mainly about a method by which software engineers can design their applications to behave following domain constraints even in complex environments. Furthermore, if we understand architectural style as a set of reusable architectural constraints with a given name, which are used to solve a collection of general issues in a specific context, we can expect that for self-adaptive application systems, an architectural style may have certain aspects supporting the systems’ runtime dynamic behaviour.
1.6 Research methodology
self-adaptive application system, and by doing research in this way, we can also limit our research scope. Considering the required properties of a self-adaptive application, the context of making architectural decisions for a self-adaptive application is uncertain. Further, integrating a self-adaptation process with an application inherently brings uncertainties. In addition to this, a software system is developed to satisfy business purposes, and it has been shown by Peled [40] that two different process patterns can be identified as being consistent or not when considering them in different business contexts. Moreover, according to Evans [27], the design of a software system should satisfy the constraints extracted from the domain model that represents the specific context in which this system is designed.
As a consequence, to carry out our research, several issues need to be solved:
• how best to understand the design of software architecture in an uncertain context;
• how a set of business constraints, especially the ones from the uncertain aspects of a business
context, can help create a software architecture in a principled way;
• how best to describe a self-adaptive application architecture, including description of the dynamic
aspects of an architecture;
• how to create an architecture in a principled way for guiding the construction of an application,
especially a self-adaptive one; and • how to evaluate our research output.
To solve the above issues, we investigate the existing definition of software architecture, and then propose a framework for understanding self-adaptive application architecture via suitable architectural patterns, including a self-consistent terminology for software architecture in uncertain contexts. Further, we propose a novel language for representing business constraints, and by using a method based on CCS (Calculus of Communicating Systems), we can outline a software architecture constrained by a model in our language by arranging the architectural elements of this architecture in a certain structure that is consistent with this model. By providing an ADL based on Grasp, we obtain a suitable way to describe self-adaptive application architecture. Further, we provide an architectural pattern with desired properties, which is constructed in a principled way by applying proven architectural patterns, to help create architecture to satisfy the same context constraints. Finally, we evaluate our methods by applying them to an ongoing business project. In practice, by checking the system log, if an implementation created following our methods can behave as same as the design, then we can define that our research achieve our goal.
1.7 Dissertation organisation
Chapter 3 defines a framework for understanding the software architecture in an uncertain context via architectural patterns that support self-adaptive behaviour, and reveal what uncertainties existing in it. A set of architectural patterns used for supporting self-adaptive behaviour are surveyed and classified based on the architectural properties of these patterns when applying them to a self-adaptive application architecture, especially in an uncertain context, e.g. decentralised environments. This classification is used to identify a set of architectural constraints that could be used to improve the architecture of self-adaptive and decentralised collaboration applications.
Chapter 4 presents and elaborates the design of a novel language used for modelling business constraints. These core concepts of this language are role, event, behaviour and processes. Through using this language, a business constraint can be described as an event causality chain created by the temporally ordered behaviour of a specific group of independent roles. With a business constraint in this model, we can perform completeness checking by having an event-reaction graph. To provide a potential capability of perform automatic checking, we also provide a simple formal framework for this language by introducing CCS [12] (Calculus of Communicating Systems).
Chapter 5 presents and elaborates the design of an ADL (Architecture Description Language) on the basis of Grasp [13]. To describe a self-adaptive application architecture, an ADL should be capable of being used to describe dynamic structures. The core concept of this enhanced Grasp is role. A role is an abstract element that provides one service or a set of cohesive services. Through using this language, a structure is re-defined as sequential fragments happening in various given scenarios following a temporal order.
Chapter 6 presents and elaborates the design of the Independent Reaction Chain (IRC) architectural style for self-adaptive and decentralised collaboration applications. IRC provides a set of architectural constraints that, when applied as a whole, emphasises scalability of node interactions, capability of collaboration without a central controller, generality of communication, capability of coping with unexceptional behaviour and independent working capability of nodes to maintain consistency in a work flow and reduce the uncertainty brought by its context.
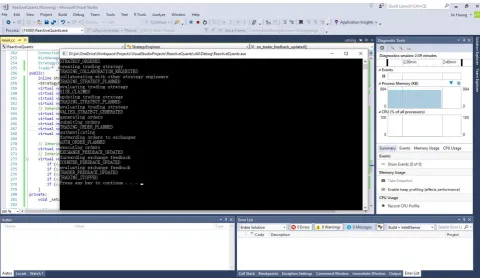
A case-study is illustrated in chapter 7. I have evaluated the result of the above methods by applying it to the design of the architecture of a futures-trading system. This system aims to trade the futures of the commodities, e.g. iron ore, coke and steel, in Shanghai Futures Exchange online. To make a profit, multiple strategies are running in different nodes at the same time. Each strategy runs independently, but multiple strategies can collaborate with each other by exchanging trading signals. Further, in this domain, to place an order, several roles have to work together in a given work flow according to the domain context, e.g. internal and external regulations.
1.8 Summary
• A framework for understanding software architecture from a new perspective, in which an
architecture is treated as a guide of dealing with uncertainty, and includes a self-consistent set of terminology for describing software architecture with uncertainty;
• A novel language used for modelling business constraints for deriving the domain-specific outline of
an architecture;
• A novel architectural style for guiding the construction of software systems in an uncertain context;
and
• Application and evaluation of the above architectural style in the design and deployment of the
2
Related work
This chapter examines the background for this dissertation by investigating and discussing the relevant concepts of software architecture, including architectural patterns; the way in which an architectural pattern is used to guide the design at architectural level; the existing architecture description methods; the way in which a software architecture is derived from its context constraints; the uncertainty issues that need to be considered to design a software application; the challenges brought by these uncertainty issues at architectural level; the definition of self-adaptation; the way in which self-adaptation processes are used to solve uncertainty, especially for the applications in decentralised environments; and the existing architectural patterns or styles supporting self-adaptation with specific properties.
2.1 Software architecture and patterns
The design of software architecture is an important stage of software development process. But, regarding the definition of software architecture, there is still no common agreement. An early definition from Perry and Wolf [6] represented software architecture as a model that has 3 members {elements, form, rationales} by an analogy with building’s architecture. According this model, an architecture is composed by a collection of elements that are constrained by a form. The so-called rationales are reasons for making architectural decisions, e.g. adopting a certain element or form. The most of existing definitions of software architecture is built on this model. Though there is still no a commonly accepted definition, there are some widely recognised characteristics of software architecture:
A software architecture is an abstraction that can be used to reason about the behaviour of a software system. An architecture is an abstraction of a software system, and therefore it only contains the selected set of information that is necessary for reasoning about the system properties [4]. An architecture not only constrains the structure of a system, but also the behaviour of this system[4]. The behaviour specified in an architecture is achieved by the collaboration of the architectural elements described in this architecture [14]. Design decisions made at architectural level are the most essential ones and are expensive to change [15]. An architecture does not only concern high-level design decision issues [8];it spans across multiple levels of granularity [16]. That is, at a lower-level, each element of an architecture may have its own architecture that specifies and constrains the structure and behaviour of this element. However, not all design at every level, e.g. colour of a button, is architectural design, since this kind of design is not sufficient for reasoning about a software system’s behaviour.
considered at architectural level, such as functional, behavioural, and social requirements. An architect has to evaluate the priority of constraints of a project at the very beginning of this project in order to make appropriate architectural decisions [4].
A software architecture has a set of elements constrained by specified structures. An architecture comprises of a set of structures, and an architectural element is the basic unit of an architecture that is viewed from a certain structure [4]. A structure is a certain arrangement of architectural elements [6], and architectural structures are important to reasoning about the properties of an architecture [4]. Each architectural element specifies a system element’s behaviour. In general, Perry and Wolf [6] categorised architectural elements into 3 types, which are processing, data and connecting elements, from a component-connector viewpoint. In detail, the processing elements are the components performing computation and transforming data; the data elements are the components providing data used in a software system; the connecting elements are connectors that are used to glue the other elements together and characterise the properties of the interactions among the other elements.
A module is an architectural element in a module-based structure. Bass et al. [4] defined a module as a static partition of a software system from a module-based viewpoint, and in this kind of structure, a module has been assigned a set of functional responsibilities. A module-based structure makes a software system flexible by allowing architects to reassembled and replaced a module independently [18]. Clements et al. [7] treated a module as an important unit of a software system, and as a set of codes or data that hides the changing information and provides an interface to access this module’s functionalities and data.
A component is an architectural element in a component-connector-based structure. An architectural component is a conceptual unit [8] with a clear boundary [4]. Particularly, a component is an architectural element of a software architecture if we partition this architecture into elements from the component-and-connector perspective. Perry and Wolf [6] defined architectural components as the elements which are responsible for transforming data elements. Bass et al. [4] defined architectural components as a set of architectural elements which can behave at runtime. Solms [16] claimed that architectural components are responsible for resolving technical issues. Gorton [19] defined components as a set of related architectural elements, and each of which elements has been assigned responsibilities, and at architectural level, a component is described as a black box that only has externally visible properties. In addition to this, Gorton [19] also pointed out that each component has a specific role in an application, and it is important to specify this and the collaboration among these roles at architectural level.
communication, coordination, or cooperation. Clements et al. [7] also describe connectors as a depiction of component interactions. In short, a connector can be characterised as an abstract mechanism for mediating interactions among components.
Data is a specific kind of architectural elements. In practice, a datum is generated or consumed, sent from, or received by a processing element via connecting elements [8]. A datum can be in any form, including files, byte streams, string-based messages, objects, etc. Fielding [8] argued that it is important to consider data elements in some cases since the selection of data elements may affect the properties of a software system, especially for network-based software systems. Buschmann et al. [21] introduced their work by modelling components through encapsulating core data and functionalities together;
A software architecture can provide a set of properties. Properties are emergence of software systems [22]. All the properties of an architecture are induced by the context constraints of this architecture [8]. There are two types of properties: functional properties and non-functional properties. Functional properties are the functionalities required to fulfil context functional requirements, and non-functional properties are the desired context qualities of the software system being designed. Non-functional properties are mainly derived from the constraints from technical, business, and application domains [19]. Examples of quality properties are: reliability, scalability, performance and availability. Fielding [8] claimed that the goal of architectural design is to create an architecture with a set of properties that can lead to a superset of the system requirements. This claim is not precise. The main reason is that a superset of the system requirements may lead to undesired system behaviour.
An architectural structure is presented in a view. An architectural view is a representation of a structure [4]. It is used as a presentation of a certain architectural structure for system stakeholders. Like a structure, an architectural view is written from various perspectives to illustrate different aspects of an architecture. It is important to document an architecture in different views from various perspectives since it is not easy to describe an architecture in a one-dimensional fashion [7]. An example is the 4+1 architectural view model designed by Kruchten [23]. The model presents an architecture by using 4+1 views: the development view describes system components; the logical view describes relationships; the physical view describes how components are deployed physically; the process view describes the runtime behaviour of a system; and the scenarios describe use-cases for testing the design presented in the other 4 views.
achieve a particular set of properties [21]. An architectural style is more abstract and general than an architecture [6]. Some examples of existing architectural styles or patterns are layered architecture style, event-driven architecture style and micro-kernel architecture style.
2.2 Software architecture design methods
Software architecture design research focuses on how best to decompose a software system into parts and how best to arrange these parts in order to satisfy context requirements [25]. Software architecture design is a part of the whole process of software engineering. Albin [25] summarised the traditional design process of software architecture as 4 activities: modelling problems; identifying architectural elements and relationships; evaluating the design; and refactoring the architecture of being designed. Fielding [8] proposed that the best way to design a software architecture is to identify the design context, including stakeholders; confirm the properties required in the design context; make design choices by applying appropriate architectural patterns; and finally implement the adopted architectural decisions. By applying architectural patterns, architects finally find a way to share the architecture knowledge with developers for building a good software system [26]. Microsoft [5] listed the key design principles of software architecture: separating functionality at appropriate boundaries; and making each element responsible for only a specific group of functionalities; and making each element has minimum knowledge of the others; and not allowing two elements have the same functionality; and minimising the upfront design.
A challenge to software architecture design is to do architecting for an application required in a very complex domain. Since a domain may be very complex, even uncertain, architects may not possible to predict all potential properties of the application of the software system being designed. Failure of many software applications is caused by domain complexity rather than technical complexity [27]. For managing the domain complexity during software design, Evans [27] presented a set of principles and a pattern language for guiding mapping business models to the design of software systems. In addition to this, both Evans [27] and Vernon [28] positively encouraged domain experts to take part in software architecture design. As a consequence, both domain experts and architects need new methods and tools to share their knowledge with each other.
2.3 Software architecture description methods
Software architectural description activity can be treated as a process of recording or modelling a software architecture in various forms, e.g. text, diagrams, formalisms. As W.Ellis et al. [29] pointed out, “an architectural description is a model — document, product or other artifact — to communicate and record a system’s architecture.”. Broadly speaking, when talking about software architectural description methods, we mean the methods used for documenting, representing and specifying an architecture [6]. A well documented software architecture works as a communication among stakeholders, and is essential to produce a software system with desired properties that can be predicated [7]. In detail, with an architectural description, we can: record architectural decisions at desired granularity and abstract level; ignore useless details; represent architectural structures from various stakeholders’ viewpoints; and perform certain kinds of analysis [6].
In a narrow sense, software architectural description methods mainly refer to architecture description languages, abbreviated as ADL. An ADL is a language used for describing and representing a software architecture in an informal or formal way. An ADL typically describes and specifies a software architecture’s structures (may also include the rationales behind a structure, e.g. Grasp [13]) from a given perspective. For example, the foundation of Acme [30] is an ontology comprising seven types of architectural concepts: components, connectors, systems, ports, representations, and rep-maps. An ADL may also be built on a formal framework in order to provide certain features, e.g. Wright [31] is built on Communicating Sequential Processes, and so the architectural models in Wright can be used to perform both port compatibility and system consistency checking. ADLs can also be used to describe large-scale systems. For example, Luckham [32]proposed Rapide for supporting component-based development of large-scale distributed systems, which is built on an event-based execution model introduced by Kenney [33].
Considering the fact that traditional ADLs provide limited features for describing dynamic structures, e.g. self-adaptive software systems in a decentralised environment, researchers in this field have begun to focus on the methods for specifying the dynamic behaviour of a software system. An example is π-ADL [34], which is built on π-calculus [35]. π-ADL provides a capability for describing dynamic, especially mobile, structure by using conditional statements and a certain set of keywords. However, the actual description ability of π-ADL is limited. Since it is still designed for describing certainty rather than uncertainty. That is, architects still need to have a clear understanding of their projects to elaborate every possible change of structures, otherwise, it would cause potential problems. Further, even architects know everything about their systems, it would require huge effort to elaborate all aspects of a large-scale software systems by a lot of conditional statements.
2.4 Uncertainty
wheel, throttle, brake, and sensors, since the context of driving a car is changing. The main reason for the uncertainties is that software engineers cannot predict everything since their limited knowledge [3]. In detail, Garlan [2] listed the possible sources of system uncertainty: human error; intelligent system behaviour; mobility; rapid runtime evolution; complex automatic controlling behaviour. This situation is against the foundation of traditional requirement and software engineering methods, which assumes that designers are capable of having a clear understanding of their projects [36].
To solve these uncertainties, a software system may need to be more dependable, flexible, recoverable, or configurable [1], and hereby architects should carefully compose architectural elements following the context constraints to achieve overall goals. Self-adaptation is one of the solutions to uncertainty. A self-adaptive software system has one or more self-adaptation processes and the system can manage uncertainty at runtime by adapting its behaviour in terms of the analysis of its observation.
2.5 Self-adaptive software system design methods
For managing complexity and uncertainty at runtime, self-adaptation mechanisms have been introduced to software engineering in recent years [37]. Normally, a self-adaptation process is modelled as a close-loop named as MAPE (Monitoring, Analysing, Planning and Executing plans) loop in general [10]. A self-adaptive software system is a kind of software system developed with one or more self-adaptation techniques. Self-adaptive software systems can behave to achieve their goals by adapting themselves to changes at runtime. The properties of a self-adaptive software system are named as self-* properties [37]. Due to the increasing complexity of software system design, more and more researchers have joined the research in the field of self-adaptation. But, it is still not easy to design and develop self-adaptive software systems, especially in a complex environment, as Lemos et al. [1] pointed out, the issues relating to the design and development of self-adaptive software systems are:
• how best to capture, describe and represent domain uncertainty, including the domain-specific methods for managing the uncertainty, for making appropriate design decisions;
• how best to design a self-adaptation mechanism;
• how best to make architectural decisions on achieving the desired properties by making trade-offs among every potential choice;
• how best to fill the gap between the design and the implementation of self-adaptive software systems;
• how best to coordinate the collaboration self-adaptation mechanisms and processes.
In practice, to engineer a self-adaptive software system, there are three problems need to be considered [38]:
• performing adaptation in an off-line or on-line way. That is, whether a system is adapted externally
or internally;
• processing the uncertainty caused by the introduction of self-adaptation processes.
For example, Garlan et al. [39] presented a framework named as Rainbow. This framework supports self-adaptation in an off-line way. In detail, Rainbow has 3 layers: from top to bottom, there are architectural layer, translation layer, and system layer. The system layer maintains an abstract system model at runtime, which is an ADL-based model of a target system, and this layer also has modules can monitor and adapt the target system. On the other hand, the architecture layer maintains a self-adaptation mechanism on the basis of a MAPE loop, so that it can make architectural decisions at runtime by analysing the information it receives. Thus, by communicating through the translation layer, the architecture layer can make decisions by comparing the system model with the target system and adapting the target system by sending execution orders to the system layer. But, a problem not being mentioned in this work is how Rainbow makes architectural trade-offs. Garlan et al. also did not discuss the actual performance of their framework: Considering it may need significant resources to maintain a complex abstract model at runtime and make architectural decisions at runtime based on the checking on this model, how can they ensure the target system will behave properly within the desired time? And how is the situation if the resource of the target system is limited?
3
A framework for understanding software architecture in
an uncertain context
“The thirty spokes unite in the one nave; but it is on the empty space (for the axle), that the use of the wheel depends. Clay is fashioned into vessels; but it is on their empty hollowness, that their use depends. The door and windows are cut out (from the walls) to form an apartment; but it is on the empty space (within), that its use depends. Therefore, what has a (positive) existence serves for profitable adaptation, and what has not that for (actual) usefulness.” by Lao Tzu, Tao Te Ching
The understanding of software architecture improves as time goes on. The traditional definitions of software architecture are based on an assumption that it is possible to have a clear understanding of a project. But, in reality, this is not true, and a software architecture may be created within uncertain contexts. For example, a self-adaptive software system is designed to solve uncertainty at runtime by adapting its behaviour when facing changes from its contexts. Considering this, the architecture of a self-adaptive application may have dynamic aspects. To study how best to design architecture for self-adaptive application systems, we would first like to have a solid understanding of software architecture with respect to self-adaptation. In detail, we would like to solve the following problems through an examination of existing definitions related to software architecture:
• how to define software architecture, especially application software architecture;
• what the factors are that should be considered during architecture design;
• how best to design an architecture for self-adaptive application.
To solve the above issues, in this chapter, we provide a self-consistent terminology for software architecture with respect to dynamic behaviour. We also investigate the difference between software architecture and application software architecture. Finally, we discuss desired properties of self-adaptive applications and investigate existing architectural patterns which could be applied to provide these properties.
3.1 A self-consistent terminology
Based on the existing definition of software architecture and self-adaptation introduced in the previous chapter, we can thus present an understanding of self-adaptive application architecture from our viewpoint. To achieve this, we first need to clarify several issues regarding our research scope first:
• The issues of designing architecture for self-adaptive application is our main concern in this
focuses on the issues of developing self-adaptive applications. An application is a software system, but not all software systems are applications. Therefore, a self-adaptive application is normally domain-specific;
• Business context is the only design context that we focus on in this dissertation. According to the
above discussion, a context actually is a set of constraints from a certain stakeholder. According to Bass et al. [4], the design of a software architecture occurs within multiple contexts. However, in this dissertation, we only focus on the impact of business context on the architectural design.
We can then provide our understanding of self-adaptive application architecture based on the existing definition introduced in the previous chapter as below:
• A self-adaptive application architecture is an abstract design that supports both business and software
processes and deals with uncertainty with suitable self-adaptation properties. Application architecture bridges domain requirements and software implementations [5]. A domain-specific software system’s architecture is restricted by the domain specific constraints [27]. According to Lemos et al. [1], it is important to comprehend fully the business and software processes and identify the related uncertainty issues before engineering a self-adaptive software system in order to take appropriate actions; further, for self-adaptive software systems, the self-adaptation (also known as self-*) properties are the emergence required for achieving certain quality requirements at runtime [37].
• An architectural element of a self-adaptive application architecture has a certain life-time at the
operational stage of this application, and an architectural element of a self-adaptive application architecture may be structured in a dynamic way following one or more self-adaptation processes. The main design concern of a self-adaptive software system is how to structure an architectural element in terms of self-adaptation processes [40]. To design self-adaptation processes at architectural level, it is necessary to specify the architectural adaptation processes by elaborating what architectural element needs to be changed in what way, at what time and for what reasons [37];
• The business context of a self-adaptive application architecture may change over time. The business
constraints which need to be considered at architectural level may change over time, and more importantly, the business purposes of a self-adaptive application may change over time too [4]. Further, due to the complexity of a domain, the understanding of this domain may improve over time. In addition to this, due to the development of technology, user requirements may change over time as well;
• The desired degree of the quality properties, also known as non-functional properties, provided by a
important for architects to evaluate the situation, so that they can balance all quality properties and achieve a better trade-off in different contexts [38];
• The architectural patterns adopted by a self-adaptive application architecture may change over time.
An architectural pattern is a reusable solution to a certain group of issues in a given context. When the context changes, a self-adaptive application architecture needs to adopt different architectural patterns;
• An architectural view of a self-adaptive application architecture may need to specify the dynamism
of this architecture. An architectural view is a representation of a given architectural structure [8]. The structures of a self-adaptive application architecture may have dynamic aspects. Therefore, to describe a self-adaptive application architecture, it is important for architects to specify at architectural level the dynamism of the application which is being designed by using a certain type of view.
3.2 Properties of interest
This section introduces the key properties of a self-adaptive application, including both functional and non-functional properties. This section does not aim to provide a comprehensive list of the properties, but only the essential properties that are important for constructing a self-adaptive application. Further, we do not intended to talk about self-* properties here, since our concern is the issue of how best to make architectural decisions to develop self-adaptive applications, rather than the issue of what properties a self-adaptive application provides.
According to the MAPE model [10], the basic functional properties of a self-adaptive application should be:
• the capability of performing business tasks;
• the capability of monitoring and capturing the changes which happened in the environment of this
application at runtime. In detail, a self-adaptive application should be able to identify the changes, collect the changes, transfer the existence of the collected changes to the other architectural elements that are waiting for this information. To provide these functionalities, this system should also have its own way to represent a change;
• the capability of analysing and making architectural decisions based on the collected information at
runtime. The application should provide functionalities to understand the collected changes at runtime;
• the capability of performing adaptation on the application. The application should be able to manage
its own elements, e.g. components and connectors, at runtime;
According to the understanding of self-adaptation, self-adaptive applications need to make architectural decisions in their operational phase. As a consequence, self-adaptive applications may need to have a flexible and extensible structure which can be evolved at runtime. Further, the adaptation processes within a adaptive application should be available and reliable, or event fault-tolerant; otherwise, the failure of a adaptation process may lead to system failure or unexpected behaviour. Additionally, the execution of a self-adaptation process should not cause unexpected performance issues. In detail, the possible non-functional properties of a self-adaptive application should be:
• flexibility. A self-adaptive application should be flexible so that it can respond to uncertainty by
changing its behaviour and structures;
• scalability. A self-adaptive application should be scalable so that its behaviour or structures can be
changed efficiently at runtime;
• changeability. It is easy to change or replace an architectural element at runtime;
• reliability. The self-adaptation processes within a self-adaptive application should be sufficiently
reliable;
• availability. The self-adaptation processes within a self-adaptive application should be sufficiently
available;
• performance. The execution of a self-adaptation process of a self-adaptive application should not
negatively impact on the performance of the execution of domain-specific business processes;
• maintainability. It is easy to maintain the self-adaptive application since it has an understandable
structure and the architectural elements of this application are loosely coupled.
3.3 Architectural patterns for self-adaptive applications
The key issue which needs to be solved at architecture design stage is: how best to make architectural decisions which support both business and self-adaptation processes. To answer this problem, existing architectural patterns that can be used to support the activities of the MAPE loop should be evaluated and discussed. However, we are not going to list and discuss all patterns that could be used for supporting the development of self-adaptive applications here, since the number of existing patterns is huge, and our word count is limited. Therefore, in this section, we select and discuss several classical patterns that are well-known. We believe that it would be easier for software architects to understand the design process if we use common patterns rather than specialised patterns here. We introduce the following patterns by referring to the existing studies [21] [4] [8] [19] [25].
domain-specific properties and self-adaptation properties can be separated into two layers, e.g. domain layer and self-adaptation layer, and the domain layer works on top of the self-adaptation layer. The non-functional properties provided by layer pattern are: maintainability and changeability. However, the failure of one layer can cause serious problems since one layer depends on the functionalities provided by the other layer; and it is very important for architects to decide the appropriate number of layers, since the performance may also be decreased if there are too many layers.
Microkernel pattern. By using this pattern, the architecture of an application contains 5 kinds of architectural elements: a micro-kernel; internal servers; external servers; adapters; clients. In practice, the micro-kernel encapsulates the lower-level system functionalities, e.g. interprocess communicating and file processing, as the foundation infrastructure of an application; internal servers provide various extended and complex services; external servers are used to request that appropriate services are executed according to the interpretation of the requests it has received from the clients. By being structured with this pattern, an application can behave adaptively and provides required services according to the various types of requests that have been received by this application. The non-functional properties provided by the Microkernel pattern are: flexibility, scalability, availability, reliability, maintainability, and changeability. However, it is complex to implement and may have performance issues. Further, since the Microkernel pattern is normally implemented with the Layers pattern, it may have the same disadvantages of the Layers pattern.
Reflection pattern. This pattern is used to provide large scale changeability. By using this pattern, the architecture of an application will be separated to two different layers. One layer includes the data elements that represent the states, properties, and configuration of this application; another layer includes the logic that can access and modify the data elements reflecting this application. These two layers normally communicate with each other through a specifically designed protocol. The applications created with this pattern inherently support runtime modification of these applications. However, it is not generally easy to implement this pattern, and in some situations, it may be impossible to do so. Further, a dependable mechanism is required to protect the applications from incorrectly modification.
Shared Repository pattern. This pattern can be treated as a variation of the Blackboard pattern. The core element of this pattern is a central repository that can be shared with other elements. The repository can work as only a data warehouse, or a data warehouse with a synchronous mechanism, or a data warehouse with a notification mechanism. Self-adaptation processes can be implemented on the basis of this pattern, so that each module that is designed to perform a certain MAPE activity can collaborate through reading information from or writing information to this shared repository. The implementation complexity of this pattern is controllable. Further, this pattern also provides flexibility, scalability, changeability and maintainability. However, the performance of self-adaptive applications created with this pattern may be negatively affected if the access to the shared repository is synchronous.
Publisher-Subscriber pattern. The main elements of this pattern are a publisher and a set of subscribers. In detail, a subscriber can subscribe to certain information maintained by a publisher, and if there is any change to the information, the publisher will notify the subscribers who have subscribed to this information. In practice, this pattern can be used to implement the monitoring activity of a self-adaptation process. This pattern can be implemented in an asynchronous manner; therefore, the performance of self-adaptive applications created with this pattern is controllable. Further, this pattern provides flexibility, scalability, changeability, and maintainability. However, the reliability and availability of a self-adaptive application created with this pattern depend on the reliability and availability of the shared repository.
Even Channel pattern. This pattern is a variation of the Publisher-Subscriber pattern, but it allows multiple publishers rather than single publisher. It inserts an architectural element known as an event channel between a publisher and its subscribers. As a consequence, the event channel is the subscriber of the publisher, and it also the publisher of these subscribers. This pattern provides better maintainability, flexibility and scalability than the Publisher-Subscriber pattern.
Producer-Cache-Consumer pattern. This pattern is another variation of the Publisher-Subscriber pattern. The information provided by the producer is stored in the cache, and the consumer only needs to access the cache and consume the information stored in the cache.
3.4 Summary
4
The role-behaviour-based modelling language
As discussed above, business context constrains the design of a self-adaptive application architecture. The first step towards a successful architecture is to confirm the required domain-specific functionalities, which are the functional constraints in the business context, and hereby shape the functional outline of the architecture [22]. To develop a self-adaptive application in a complex domain, it is essential for architects to have a clear understanding of the uncertainty of the business context of this application, so that architects can make appropriate architectural decisions on the selection of the appropriate self-adaptation processes and the suitable architectural patterns for supporting these processes at the operational phase of this application.
A domain-specific model is an abstract representation of the business context of a software application. Therefore, to a certain extend, a software application architecture is constrained by a domain-specific model. Considering a software application architecture actually bridges domain-specific knowledge and implementation [5], it is also important for architects to ensure that a software application architecture, including architectural structures and properties, conforms the domain-specific model constraining it. In addition to this, considering a domain can be uncertain, and there may be some unknown aspects of this domain, it is also important for architects to ensure that the certainty is complete. That is, the designed behaviour of a software application in a changing context will not lead to an unexpected state, e.g. failure.
Further, for a software application, which is designed for performing certain business tasks, in a certain domain, the domain-specific knowledge is vital to the success of this application. But, for a very complex domain, it is hard for architects to have a clear understanding of this domain. Therefore, it can be very helpful if domain experts can join the architectural design [27]. To allow the participation of domain experts in the architectural design, an understandable method for describing domain knowledge that will affect architectural decisions should be available.
Given the above factors, it would not be suitable for domain experts to model domain-specific certainty with existing methods, such as UML(Unified Modelling Language) and formal methods. Since these methods may be too complex for domain experts. For example, the UML, which is widely used to model software systems, has more than 10 kinds of diagrams and various ambiguous graphical concepts and this tool is still evolving. Considering this, it may be difficult for domain experts to learn: there is an intuitive evidence, a brief guide [41] for using UML has more than 200 pages. Formal methods are much more difficult to learn, even for software architects. Further, these methods are all designed for describing certainty rather than uncertainty, and it would be very complicated for users to describe uncertainty information by using these tools. On the other hand, some more flexible tools, e.g. informal graphical tools, are lacking of support to the analysis of the models created by these tools.
domain experts can describe the domain-specific concepts and workflow in a concise way, and check the completeness of the models created in this language, and then architects can generate the functional outline of the architectures of their systems by adopting suitable architectural patterns on the basis of consistency checking.
4.1 Design principles
This chapter introduces the design of a modelling language for describing domain-specific business processes. As mentioned above, the design principles of this language are:
• simplicity. This language should have a concise grammar so that it is easy for domain experts who
have limited software knowledge to understand and use. Further, this language should have limited concepts that are easy to be mapped to business concepts;
• expressiveness. This language should be capable of describing domain-specific certainty
information, e.g. business constraints, business processes. Further, this language should be used to describe domain-specific uncertainty information and the corresponding reslolutions, e.g. domain specific changes and the domain-specific reactions to these changes;
• capability of managing complexity. This language should allow users to describe their models at
various abstract levels, and provide concepts for users to reduce the complexity of their models efficiently;
• correctness. This language should have a formal foundation for users to understand the models in
this language in a correct way. Further, a formal foundation is essential for users to perform formal checking, e.g. consistency checking, completeness checking, so that a domain-specific model in this language can provide a solid foundation for making architectural decisions at architecture design stage.
In practice, we introduce a role-behaviour-based method in which users can describe business constraints through specifying the behaviour of domain-specific roles. Further, we also introduce a high-order method for specifying various kinds of domain uncertainty with complex event patterns. In summary, by proposing this language, we have made the following contributions to the field of software engineering:
• providing a concise language that have limited concepts and easy for both domain experts and
software architects to use;
• providing a method for users to describe not only the knowledge about domain-specific certainty, but
also the knowledge about domain-specific uncertainty;
• provide a method for users to manage the complexity of their models by specifying certainty and
• providing a method for users to perform formal checking, e.g. consistency checking, completeness
checking. As a consequence, domain experts can take part in the architecture design by constraining the functional topology with their domain-specific models.
4.2 Conceptual model
The following figure illustrates the proposed conceptual model of this language. We define a business domain as a set of business constraints. The core concept is role. A role has its own behaviour that is constrained by the roles context. A role can extends other roles and therefore behave like the others. A role extends the other roles is termed as the “child role”, and the role being extended is termed as the “parent role”. Two different roles do not have the same behaviour. A context comprises a set of events. From the outside of a role, the visible behaviour of a role is defined by a pair of events <e1, e2>, where e1 indicates the
This conceptual model refers to concepts of a well-designed ontology model [42] [43] [44]: The world is made of things. A thing can be simple or composite. A composite thing is a combination of simple things. A thing possesses a set of properties, and the properties of two things are always not the same. A class of things possesses a same group of properties which is a subset of the properties of each thing in this class. A property can be observable or unobservable. A thing is characterised only by its observable properties. At a given time, a property has a given value. The state of a thing is the values of all properties of a thing at a given time. The state space of a thing is all possible states of this thing. A constraint on the possible value of a property is called a state law. A state conforms to a state law is a lawful state. An event represents a change on the states of a group of things. The behaviour of a thing in a given period is denoted by an ordered set of states in this period. A thing X acts on another thing Y if Y’s state has been affected by the present of thing X. If X acts on Y, and Y acts on X, then X interacts with Y. A system is a composite thing that cannot be decomposed into non-interacting simple things. An event happening on a thing is external only if this event is caused by a stimulus from the environment of this thing. Otherwise, an event is internal. Further, a thing will not behave arbitrarily. That is, without external stimuli, a thing will change its state only if there is a lawful transition from this state to another state. If there is such a lawful transition from state A to state B, then state A is unstable. A thing in an unstable state will change to a stable state. A thing can be changed by external stimuli since the value of at least one property of this thing can be changed by external events.
Based on the above ontology, we can clarify our conceptual model in this way: a role specifies the lawful behaviour of a class of things in its lifetime; invisible behaviour represents the internal behaviour of a thing, which is unobservable from the outside; visible behaviour represents the observable behaviour of a thing from outside; A thing acting as a role will behave following the behaviour restrictions imposed by this role; a simple event represents a change only and a complex event also represents a change between states, which can be split into an ordered series of simple events. An action in this model represents the changes, which are imposed by a role, on the environment of the things acting as this role, or the changes on the things acting as other roles; A business process represents an ordered set of lawful transitions. With the above conceptual model and ontological explanation, we can therefore provide a formal foundation for this language. Based on this, the rest of this section will introduces how we solve the other issues mentioned above.
of a certain set of behaviour of roles is actually defined by the temporal order of the events related to the set of behaviour.
Further, by introducing the event concept, including simple and complex events, we can therefore describe the domain-specific uncertainty in a simple way at a desired level. Since an event inherently represents changes, and thus it is ideally to describe uncertainty with events. To deal with uncertainty, users can describe the role behaviour to uncertainty events. Additionally, by using various event patterns, users can describe uncertainty in a concise and sophisticated way. That is, users can manage the complexity of their models by deciding the abstract level of the description of the events.
By establishing the extending relationship among roles, and by deciding the abstract level of events, users can describe the knowledge of a domain at various granularity in a collaborative way. In this way, domain experts can cooperate together for describing complex domain-specific knowledge through decomposing the knowledge into various layers. For example, a manager can be responsible for describing overall information in management layer, and an employee can then elaborate the detailed information in technical layer. In detail, the syntax of this language is defined in the following section.
4.3 Grammar
The grammar of this language is defined in the EBNF (Extended Backus-Naur Form) [45] notation. A domain defines the scope of a model, the syntax is:
domain-definition: ‘domain’ domain-name=identifier '{'event-definition* role-definition* process-definition* '}'
In this way, a domain has:
• zero or more business events;
• zero or more business roles;
• zero or more business processes;
The syntax of event definition is:
event-definition: 'external'? ‘event’ event-name=identifier ('(' arg-list ')' ':' event-expression)? arg-list: args+=identifier (',' args+=identifier)*;
An event can be explicitly defined as an external event by beginning with a keyword “external”. For example, a key has been pressed by a user. Optionally, an event can be defined as a complex event by specifying it as a high-order predicate explained by an event expression. Otherwise, we can define an event as a simple one by simply giving it a name. The syntax of event expression is defined as:
event-expression: simple-event
| 'not' simple-event
| simple-event 'while' event-expression | simple-event 'then' event-expression | simple-event 'after' event-expression | simple-event 'before' event-expression | simple-event 'during' event-expression | '(' event-expression ')'
simple-event: event-name = identifier
This syntax shows an event calculus that will be discussed later. In this definition, a simple event is denoted by an identifier-based name. A complex event is an event defined by an expression specified with a set of operators and other events.
The syntax of a role is shown as below:
role-definition: ‘role’ role-name-list +=identifier '{' behaviour = reaction* '}' reaction: internal-transitions+= event-logical-expression*
| 'on' ('context''::')? stimuli = expression '{' invisible-behaviour+ = event-logical-expression* (':' result = event-logical-expression )? '}'
event-logical-expression: simple-event
|
| identifier logic-operator event-logical-expression | '(' event-logical-expression ')'
logic-operator: '&' | '|'
A role is characterised by its behaviour in different contexts. According to the conceptual model, the behaviour of a role specifies a transition between states of the things acting as this role, and thus we can describe behaviour with events. In the syntax, we describe a behaviour as a set of reactions to certain external stimuli, and each reaction is denoted by a tuple <c, a, r>, where c is a set of external events, a is a simple or complex event and it indicates the invisible behaviour of this reaction, and r indicates the result of this reaction, which is also a set of events. For example, the following statements define a role and its behaviour, and these statements mean: analyser is the name of a role; this role should behave when external event AnalysisRequest happens and cause event TradingSignalFound; In detail, the behaviour of role analyser is achieved by a set of events, which represents internal lawful transitions.
role analyser{
on AnalysisRequest{
prepare_strategy then calculate_strategy: TradingSignalFound }
}
The grammar of a business process is specified as below:
process-definition: ‘process’ process-name=ID '{' participant-name-list = participant* interactions = transition-ordered-set * '}'
participant: ‘role’ name = identifier
![Figure 3: the conceptual model of original Grasp, cited from [13]](https://thumb-us.123doks.com/thumbv2/123dok_us/8688351.379413/39.595.61.540.565.728/figure-conceptual-model-original-grasp-cited.webp)