1031
Integrating Semantic Knowledge to Tackle Zero-shot Text Classification
Jingqing Zhang∗ Data Science Institute Imperial College London
London, UK
Piyawat Lertvittayakumjorn∗ Department of Computing
Imperial College London London, UK
{jingqing.zhang15,pl1515,y.guo}@imperial.ac.uk
Yike Guo Data Science Institute Imperial College London
London, UK
Abstract
Insufficient or even unavailable training data of emerging classes is a big challenge of many classification tasks, including text classifica-tion. Recognising text documents of classes that have never been seen in the learning stage, so-calledzero-shot text classification, is there-fore difficult and only limited previous works tackled this problem. In this paper, we pro-pose a two-phase framework together with data augmentation and feature augmentation to solve this problem. Four kinds of semantic knowledge (word embeddings, class descrip-tions, class hierarchy, and a general knowl-edge graph) are incorporated into the pro-posed framework to deal with instances of un-seen classes effectively. Experimental results show that each and the combination of the two phases achieve the best overall accuracy com-pared with baselines and recent approaches in classifying real-world texts under the zero-shot scenario.
1 Introduction
As one of the most fundamental problems in ma-chine learning, automatic classification has been widely studied in several domains. However, many approaches, proven to be effective in tradi-tional classification tasks, cannot catch up with a dynamic and open environment where new classes can emerge after the learning stage (Romera-Paredes and Torr,2015). For example, the number of topics on social media is growing rapidly, and the classification models are required to recognise the text of the new topics using only general in-formation (e.g., descriptions of the topics) since labelled training instances are unfeasible to ob-tain for each new topic (Lee et al., 2011). This scenario holds in many real-world domains such
∗
Piyawat Lertvittayakumjorn and Jingqing Zhang con-tributed equally to this project.
as object recognition and medical diagnosis (Xian et al.,2017;World Health Organization,1996).
Zero-shot learning (ZSL) for text classification aims to classify documents of classes which are absent from the learning stage. Although it is challenging for a machine to achieve, humans are able to learn new concepts by transferring knowl-edge from known to unknown domains based on high-level descriptions and semantic representa-tions (Thrun and Pratt,1998). Therefore, without labelled data of unseen classes, a zero-shot learn-ing framework is expected to exploit supportive semantic knowledge (e.g., class descriptions, rela-tions among classes, and external domain knowl-edge) to generally infer the features of unseen classes using patterns learned from seen classes.
A collection of classifiers
Phase 1: Coarse-grained Classification
Data augmentation
A traditional classifier
Phase 2: Fine-grained Classification
A zero-shot classifier Feature
augmentation 𝑦"#∈ 𝒞𝒮
𝑦"#∉ 𝒞𝒮 if
𝑥# 𝑦"#
Refinement
𝑣*#
𝑣*#; 𝑣,; 𝑣*,,#
A classifier for𝑐/∈ 𝒞𝒮
A classifier for𝑐|𝒞𝒮|∈ 𝒞𝒮
[image:2.595.75.529.60.212.2]𝑣*#
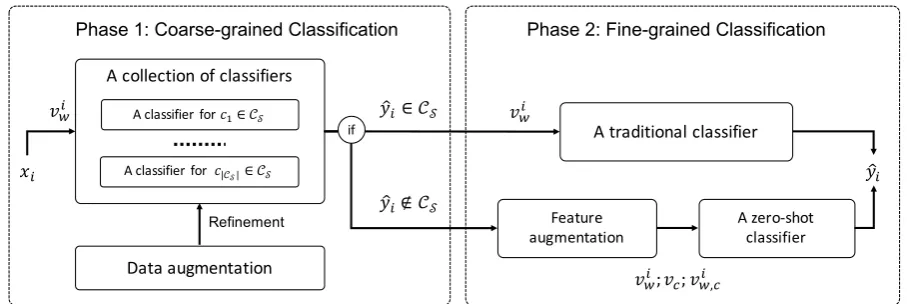
Figure 1: The overview of the proposed framework with two phases. The coarse-grained phase judges if an input documentxicomes from seen or unseen classes. The fine-grained phase finally decides the classyˆi. All notations are defined in section2.1-2.2.
the testing set. Hence, these methods are not work-ing under a strict zero-shot scenario.
To tackle the zero-shot text classification prob-lem, this paper proposes a novel two-phase frame-work together with data augmentation and fea-ture augmentation (Figure 1). In addition, four kinds of semantic knowledge including word em-beddings, class descriptions, class hierarchy, and a general knowledge graph (ConceptNet) are ex-ploited in the framework to effectively learn the unseen classes. Both of the two phases are based on convolutional neural networks (Kim, 2014). The first phase called coarse-grained classifica-tion judges if a document is from seen or un-seen classes. Then, the second phase, named
fine-grained classification, finally decides its class.
Note that all the classifiers in this framework are trained using labelled data of seen classes (and augmented text data) only. None of the steps learns from the labelled data of unseen classes.
The contributions of our work can be sum-marised as follows.
• We propose a novel deep learning based two-phase framework, including coarse-grained and fine-grained classification, to tackle the zero-shot text classification problem. Un-like some previous works, our framework does not require semantic correspondence be-tween classes in a training stage and classes in an inference stage. In other words, the seen and unseen classes can be clearly different.
• We propose a novel data augmentation tech-nique called topic translation to strengthen the capability of our framework to detect doc-uments from unseen classes effectively.
• We propose a method to perform feature augmentation by using integrated semantic knowledge to transfer the knowledge learned from seen to unseen classes in the zero-shot scenario.
In the remainder of this paper, we firstly explain our proposed zero-shot text classification frame-work in section2. Experiments and results, which demonstrate the performance of our framework, are presented in section3. Related works are dis-cussed in section4. Finally, section 5 concludes our work and mentions possible future work.
2 Methodology
2.1 Problem Formulation
Let CS and CU be disjoint sets of seen and
unseen classes of the classification respec-tively. In the learning stage, a training set
{(x1, y1), . . . ,(xn, yn)} is given where xi is the
i-th document containing a sequence of words
[w1i, w2i, . . . , wti] andyi ∈ CS is the class of xi.
In the inference stage, the goal is to predict the class of each document,yˆi, in a testing set which
has the same data format as the training set ex-cept that yi comes from CS ∪ CU. Note that (i)
every class comes with a class label and a class de-scription (Figure2a); (ii)a class hierarchy show-ing superclass-subclass relationships is also pro-vided (Figure2b);(iii)the documents from unseen classes cannot be observed to train the framework.
2.2 Overview and Notations
education
research university
Related To
At Location At Location
Related To
Used For
science Related To
Used For
Related To
book reading Used For
Related To
Has Prerequisite
Causes
Used For Used For
Class labels Class descriptions
Company an organization that provides services, or that makes or sells goods for money
Educational Institution
a place where people of different ages gain an education.
Artist someone who makes paintings, sculptures etc
(a)
(b)
(c)
Used For Thing
Agent Work Place
Village Building Natural Person Organisation Written work Film Album
Office
holder Athlete Artist Company Educational
[image:3.595.74.292.61.312.2]institution
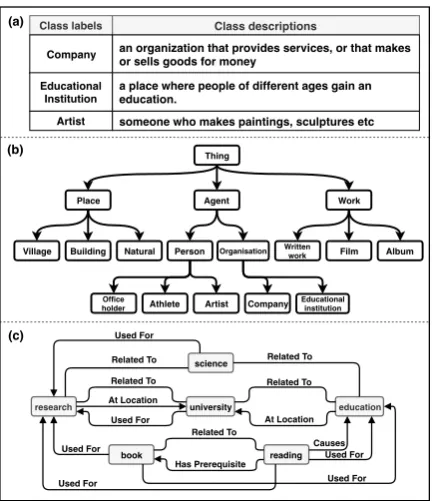
Figure 2: Illustrations of semantic knowledge inte-grated into our framework: (a) class labels and class descriptions (b) class hierarchy and (c) a subgraph of the general knowledge graph (ConceptNet).
(Figure1). The first phase, coarse-grained classifi-cation, predicts whether an input document comes from seen or unseen classes. We also apply a data augmentation technique in this phase to help the classifiers be aware of the existence of unseen classes without accessing their real data. Then the second phase, fine-grained classification, fi-nally specifies the class of the input document. It uses either a traditional classifier or a zero-shot classifier depending on the coarse-grained predic-tion given by Phase 1. Also, feature augmentapredic-tion based on semantic knowledge is used to provide additional information which relates the document and the unseen classes to generalise the zero-shot reasoning.
We use the following notations in Figure1and throughout this paper.
• The list of embeddings of each word in the document xi is denoted by viw = [vwi1, vwi2, . . . , viwt].
• The embedding of each class label c is de-noted byvc,∀c∈ CS∪ CU. It is assumed that
each class has a one-word class label. If the class label has more than one word, a similar one-word class label is provided to findvc.
• As augmented features, the relationship
vec-torvwij,c shows the degree of relatedness be-tween the wordwj and the classcaccording
to semantic knowledge. Hence, the list of re-lationship vectors between each word in xi
and each classc∈ CS∪ CUis denoted byvw,ci = [vwi1,c, viw2,c, . . . , vwit,c]. We will explain the construction method in section2.4.1.
2.3 Phase 1: Coarse-grained Classification
Given a documentxi, Phase 1 performs a binary
classification to decide whetheryˆi ∈ CS oryˆi ∈/ CS. In this phase, each seen classcs ∈ CS has its
own CNN classifier (with a subsequent dense layer and a sigmoid output) to predict the confidence thatxicomes from the classcs, i.e.,p(ˆyi =cs|xi).
The classifier usesvwi as an input and it is trained using a binary cross entropy loss with all docu-ments of its class in the training set as positive ex-amples and the rest as negative exex-amples.
For a test document xi, this phase computes
p(ˆyi=cs|xi)for every seen classcsinCS. If there
exists a class cs such that p(ˆyi = cs|xi) > τs,
it predictsyˆi ∈ CS; otherwise, yˆi ∈ C/ S. τs is a
classification threshold for the classcs, calculated
based on the threshold adaptation method from (Shu et al.,2017).
2.3.1 Data Augmentation
During the learning stage, the classifiers in Phase 1 use negative examples solely from seen classes, so they may not be able to differentiate the positive class from unseen classes. Hence, when the names of unseen classes are known in the inference stage, we try to introduce them to the classifiers in Phase 1 via augmented data so they can learn to reject the instances likely from unseen classes. We do data augmentation by translating a document from its original seen class to a new unseen class using analogy. We call this processtopic translation.
In the word level, we translate a word w in a document of classc to a corresponding word w0
candidates ofw0:
w0 = argmax x∈V
cos(x, c0) cos(x, w) cos(x, c) +
whereV is a vocabulary set andcos(a, b)is a co-sine similarity score between the vectors of worda
and wordb. Also,is a small number (i.e., 0.001) added to prevent division by zero.
In the document level, we follow Algorithm 1 to translate a document of class c into the topic of another class c0. To explain, we translate all nouns, verbs, adjectives, and adverbs in the given document to the target class, word-by-word, using the word-level analogy. The word to replace must have the same part of speech as the original word and all the replacements in one document are 1-to-1 relations, enforced by replace dict in Algorithm 1. With this idea, we can create augmented doc-uments for the unseen classes by topic-translation from the documents of seen classes in the training dataset. After that, we can use the augmented doc-uments as additional negative examples for all the CNNs in Phase 1 to make them aware of the tone of unseen classes.
Algorithm 1:Document-level topic translation
Input :a documentxi= [wi1, w2i, . . . , wti],
an original class labelc, a target class labelc0
Output:a translated documentx0i 1 replace dict =dict();x0i= []; 2 foreachw∈xido
3 ifis valid pos(w)then 4 ifw /∈replace dictthen
5 cands = solve analogy(w,c,c0,
top k=20);
6 forj= 0tolen(cands)-1do
7 ifcands[j]∈/replace dict.values()∧ pos of(w)∈pos list(cands[j])
then
8 replace dict[w] = cands[j];
9 break;
10 ifj== len(cands)then 11 x0i.append(w);
12 continue;
13 x0i.append(replace dict[w]);
14 else
15 x0i.append(w); 16 returnx0i
2.4 Phase 2: Fine-grained Classification
Phase 2 decides the most appropriate classyˆi for
xi using two CNN classifiers: a traditional
classi-fier and a zero-shot classiclassi-fier as shown in Figure 1. Ifyˆi ∈ CSpredicted by Phase 1, the traditional
classifier will finally select a classcs ∈ CS asyˆi.
Otherwise, ifyˆi ∈ C/ S, the zero-shot classifier will
be used to select a classcu ∈ CU asyˆi.
The traditional classifier and the zero-shot clas-sifier have an identical CNN-based structure fol-lowed by two dense layers but their inputs and outputs are different. The traditional classifier is a multi-class classifier (|CS|classes) with a softmax
output, so it requires only the word embeddings
viw as an input. This classifier is trained using a cross entropy loss with a training dataset whose examples are from seen classes only.
In contrast, the zero-shot classifier is a binary classifier with a sigmoid output. Specifically, it takes a text documentxi and a class c as inputs
and predicts the confidence p(ˆyi = c|xi).
How-ever, in practice, we utiliseviw to representxi,vc
to represent the classc, and also augmented fea-tures vi
w,c to provide more information on how
intimate the connections between words and the classcare. Altogether, for each wordwj, the
clas-sifier receives the concatenation of three vectors (i.e., [viwj;vc;vwij,c]) as an input. This classifier is trained using a binary cross entropy loss with a training data from seen classes only, but we ex-pect this classifier to work well on unseen classes thanks to the distinctive patterns ofvw,ci in positive examples of every class. This is how we transfer knowledge from seen to unseen classes in ZSL.
2.4.1 Feature Augmentation
The relationship vectorvwj,c contains augmented
features we input to the zero-shot classifier. vwj,c
shows how the wordwjand the classcare related
considering the relations in a general knowledge graph. In this work, we use ConceptNet providing general knowledge of natural language words and phrases (Speer and Havasi,2013). A subgraph of ConceptNet is shown in Figure 2c as an illustra-tion. Nodes in ConceptNet are words or phrases, while edges connecting two nodes show how they are related either syntactically or semantically.
We firstly represent a class c as three sets of nodes in ConceptNet by processing the class hi-erarchy, class label, and class description ofc. (1)
the class nodesis a set of nodes of the class
Con-ceptNet nodes for this class are:
(1) educational institution, educational, institution (2) organization, agent
(3) place, people, ages, education.
To construct vwj,c, we consider whether the
wordwjis connected to the members of the three
sets above within K hops by particular types of relations or not1. For each of the three sets, we construct a vector with3K+ 1dimensions.
• v[0] = 1ifwjis a node in that set; otherwise,
v[0] = 0.
• fork= 0, . . . , K−1:
– v[3k+ 1] = 1if there is a node in the set whose shortest path to wj isk+ 1.
Otherwise,v[3k+ 1] = 0.
– v[3k+ 2]is the number of nodes in the set whose shortest path towj isk+ 1.
– v[3k+3]isv[3k+2]divided by the total number of nodes in the set.
Thus, the vector associated to each set shows how
wj is semantically close to that set. Finally, we
concatenate the constructed vectors from the three sets to becomevwj,cwith3×(3K+1)dimensions.
3 Experiments
3.1 Datasets
We used two textual datasets for the experiments. The vocabulary size of each dataset was limited by 20,000 most frequent words and all numbers were excluded. (1) DBpedia ontology dataset (Zhang et al., 2015) includes 14 non-overlapping classes and textual data collected from Wikipedia. Each class has 40,000 training and 5,000 testing sam-ples. (2) The20newsgroupsdataset2has 20
top-ics each of which has approximately 1,000 docu-ments. 70% of the documents of each class were randomly selected for training, and the remaining 30% were used as a testing set.
3.2 Implementation Details3
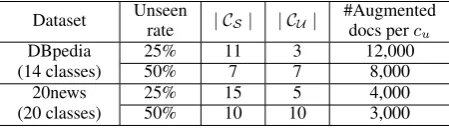
In our experiments, two different rates of unseen classes, 50% and 25%, were chosen and the corre-sponding sizes ofCSandCU are shown in Table1.
For each dataset and each unseen rate, the random
1
In this paper, we only consider the most common types of positive relations which areRelatedTo, IsA,PartOf, and AtLocation. They cover∼60% of all edges in ConceptNet.
2
http://qwone.com/∼jason/20Newsgroups/
3Code: https://github.com/JingqingZ/KG4ZeroShotText.
selection of (CS,CU) were repeated ten times and
these ten groups were used by all the experiments with this setting for a fair comparison. All doc-uments fromCU were removed from the training
set accordingly. Finally, the results from all the ten groups were averaged.
In Phase 1, the structure of each classifier was identical. The CNN layer had three filter sizes [3, 4, 5] with 400 filters for each filter size and the subsequent dense layer had 300 units. For data augmentation, we used gensim with an implemen-tation of 3COSMUL(Reh˚uˇrek and Sojka,ˇ 2010) to solve the word-level analogy (line 5 in Algorithm 1). Also, the numbers of augmented text docu-ments per unseen class for every setting (if used) are indicated in Table1. These numbers were set empirically considering the number of available training documents to be translated.
In Phase 2, the traditional classifier and the zero-shot classifier had the same structure, in which the CNN layer had three filter sizes [2, 4, 8] with 600 filters for each filter size and the two intermediate dense layers had 400 and 100 units respectively. For feature augmentation, the max-imum path length K in ConceptNet was set to 3 to create the relationship vectors4. The DBpe-dia ontology5 was used to construct a class hier-archy of the DBpedia dataset. The class hierar-chy of the 20newsgroups dataset was constructed based on the namespaces initially provided by the dataset. Meanwhile, the classes descriptions of both datasets were picked from Macmillan Dictio-nary6as appropriate.
For both phases, we used 200-dim GloVe vec-tors7 for word embeddings vw and vc
(Penning-ton et al., 2014). All the deep neural networks were implemented with TensorLayer (Dong et al., 2017a) and TensorFlow (Abadi et al.,2016).
Dataset Unseen
rate | CS| | CU|
#Augmented docs percu
DBpedia 25% 11 3 12,000 (14 classes) 50% 7 7 8,000
20news 25% 15 5 4,000
[image:5.595.308.533.592.656.2](20 classes) 50% 10 10 3,000
Table 1: The rates of unseen classes and the numbers of augmented documents (per unseen class) in the ex-periments
4
Based on our observation, most of the related words stay within 3 hops from the class nodes in ConceptNet.
5
http://mappings.dbpedia.org/server/ontology/classes/
6
https://www.macmillandictionary.com/
3.3 Baselines and Evaluation Metrics
We compared each phase and the overall frame-work with the following approaches and settings.
Phase 1: Proposed by (Shu et al.,2017),DOC
is a state-of-the-art open-world text classification approach which classifies a new sample into a seen class or “reject” if the sample does not belong to any seen classes. The DOC uses a single CNN and a 1-vs-rest sigmoid output layer with thresh-old adjustment. Unlike DOC, the classifiers in the proposed Phase 1 work individually. However, for a fair comparison, we used DOC only as a binary classifier in this phase (yˆi∈ CS oryˆi ∈ C/ S).
Phase 2: To see how well the augmented
fea-turevw,c work in ZSL, we ran the zero-shot
clas-sifier withdifferent combinations of inputs. Par-ticularly, five combinations of vw, vc, and vw,c
were tested with documents from unseen classes only (traditional ZSL).
The whole framework: (1) Count-based
modelselected the class whose label appears most
frequently in the document asyˆi. (2)Label
simi-larity (Sappadla et al., 2016) is an unsupervised
approach which calculates the cosine similarity between the sum of word embeddings of each class label and the sum of word embeddings of every n-gram (n = 1,2,3) in the document. We adopted this approach to do single-label classifi-cation by predicting the class that got the highest similarity score among all classes. (3)RNN
Au-toEncoder was built based on a Seq2Seq model
with LSTM (512 hidden units), and it was trained to encode documents and class labels onto the same latent space. The cosine similarity was ap-plied to select a class label closest to the document on the latent space. (4) RNN+FC refers to the architecture 2 proposed in (Pushp and Srivastava, 2017). It used an RNN layer with LSTM (512 hid-den units) followed by two hid-dense layers with 400 and 100 units respectively. (5)CNN+FCreplaced the RNN in the previous model with a CNN, which has the identical structure as the zero-shot classi-fier in Phase 2. Both RNN+FC and CNN+FC pre-dicted the confidencep(ˆyi = c|xi) givenvw and
vc. The class with the highest confidence was
se-lected asyˆi.
For Phase 1, we used the accuracy for binary classification (y,yˆi ∈ CS or y,yˆi ∈ C/ S) as an
evaluation metric. In contrast, for Phase 2 and the whole framework, we used the multi-class classi-fication accuracy (yˆi=yi) as a metric.
Artist Building Office holder Written work 0.975
[image:6.595.315.518.60.195.2]0.980 0.985 0.990 0.995 1.000
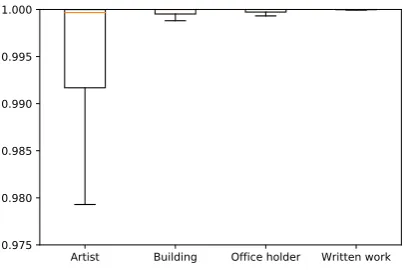
Figure 3: The distributions of confidence scores of pos-itive examples from four seen classes of DBpedia in Phase 1.
3.4 Results and Discussion
The evaluation of Phase 1(coarse-grained
classi-fication) checks if eachxiwas correctly delivered
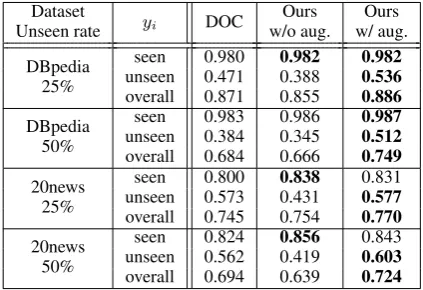
to the right classifier in Phase 2. Table 3 shows the performance of Phase 1 with and without aug-mented data compared with DOC. Considering test documents from seen classes only, our frame-work outperformed DOC on both datasets. In addition, the augmented data improved the accu-racy of detecting documents from unseen classes clearly and led to higher overall accuracy in every setting. Despite no real labelled data from unseen classes, the augmented data generated by topic translation helped Phase 1 better detect documents from unseen classes. Table4 shows some exam-ples of augmented data from the DBpedia dataset. Even if they are not completely understandable, they contain the tone of the target classes.
Although Phase 1 provided confidence scores for all seen classes, we could not use them to pre-dictyˆi directly since the distribution of scores of
positive examples from different CNNs are dif-ferent. Figure 3 shows that the distribution of confidence scores of the class “Artist” had a no-ticeably larger variance and was clearly different from the class “Building”. Hence, even ifp(ˆyi =
“Building”|xi) > p(ˆyi = “Artist”|xi), we cannot
conclude thatxi is more likely to come from the
class “Building”. This is whya traditional
clas-sifier in Phase 2 is necessary.
Regarding Phase 2, fine-grained classification is in charge of predicting yˆi and it employs two
classifiers which were tested separately. Assum-ing Phase 1 is perfect, the classifiers in Phase 2 should be able to find the right class. The purpose of Table 5 is to show that the traditional CNN
Dataset Unseen
rate yi Count-based
Label Similarity (Sappadla et al.,2016)
RNN Autoencoder
RNN + FC (Pushp and Srivastava,
2017)
CNN +
FC Ours
DBpedia
25%
seen 0.322 0.377 0.250 0.895 0.985 0.975 unseen 0.372 0.426 0.267 0.046 0.204 0.402 overall 0.334 0.386 0.254 0.713 0.818 0.852
50%
seen 0.358 0.401 0.202 0.960 0.991 0.982 unseen 0.304 0.369 0.259 0.044 0.069 0.197 overall 0.333 0.386 0.230 0.502 0.530 0.590
20news
25%
seen 0.205 0.279 0.263 0.614 0.792 0.745 unseen 0.201 0.287 0.149 0.065 0.134 0.280 overall 0.204 0.280 0.236 0.482 0.633 0.633
50%
seen 0.219 0.293 0.275 0.709 0.684 0.767
unseen 0.196 0.266 0.126 0.052 0.126 0.168 overall 0.207 0.280 0.200 0.381 0.405 0.469
Table 2: The accuracy of the whole framework compared with the baselines.
Dataset
Unseen rate yi DOC
Ours w/o aug.
Ours w/ aug.
DBpedia 25%
seen 0.980 0.982 0.982
unseen 0.471 0.388 0.536
overall 0.871 0.855 0.886
DBpedia 50%
seen 0.983 0.986 0.987
unseen 0.384 0.345 0.512
overall 0.684 0.666 0.749
20news 25%
seen 0.800 0.838 0.831 unseen 0.573 0.431 0.577
overall 0.745 0.754 0.770
20news 50%
seen 0.824 0.856 0.843 unseen 0.562 0.419 0.603
[image:7.595.79.521.61.230.2]overall 0.694 0.639 0.724
Table 3: The accuracy of Phase 1 with and without aug-mented data compared with DOC .
Animal (Original)
Mitra perdulca is a species of sea snail a marine gastropod mollusk in the family Mitridae the miters or miter snails.
Animal → Plant
Arecaceae perdulca is a flowering of port aster a naval mollusk gastropod in the fabaceae Clusiaceae the tiliaceae or rock-ery amaryllis.
Animal → Athlete
Mira perdulca is a swimmer of sailing sprinter an Olympian limpets gastropod in the basketball Middy the miters or miter skater.
Table 4: Examples of augmented data translated from a document of the original class “Animal” into two target classes “Plant” and “Athlete”.
Besides, given test documents from unseen classes only, the performance of the zero-shot
classifier in Phase 2is shown in Table 6. Based
on the construction method, vw,c quantified the
relatedness between words and the class but, un-likevw andvc, it did not include detailed
seman-tic meaning. Thus, the classifier using vw,c only
could not find out the correct unseen class and nei-ther[vw;vw,c]and[vc;vw,c]could do. On the other
Dataset DBpedia 20news Input\Unseen rate 50% 25% 50% 25%
[image:7.595.75.287.270.415.2]vw 0.993 0.992 0.878 0.861
Table 5: The accuracy of the traditional classifier in Phase 2 given documents from seen classes only.
Dataset DBpedia 20news Inputs\Unseen rate 50% 25% 50% 25%
Random guess 0.143 0.333 0.100 0.200
vw,c 0.154 0.443 0.104 0.210 [vc;vw,c] 0.163 0.400 0.099 0.215 [vw;vw,c] 0.266 0.460 0.122 0.307 [vw;vc] 0.381 0.711 0.274 0.431 [vw;vc;vw,c] 0.418 0.754 0.302 0.500
Table 6: The accuracy of the zero-shot classifier in Phase 2 given documents from unseen classes only.
hand, the combination of[vw;vc], which included semantic embeddings of both words and the class label, increased the accuracy of predicting unseen classes clearly. However, the zero-shot classifier fed by the combination of all three types of inputs
[vw;vc;vw,c]achieved the highest accuracy in all
settings. It asserts that the integration of semantic knowledge we proposed is an effective means for knowledge transfer from seen to unseen classes in the zero-shot scenario.
Last but most importantly, we compared the
whole framework with four baselines as shown
in Table2. First, the count-based model is a rule-based model so it failed to predict documents from seen classes accurately and resulted in unpleasant overall results. This was similar to the label simi-larity approach even though it had higher degree of flexibility. Next, the RNN Autoencoder was trained without any supervision sinceyˆi was
[image:7.595.307.528.351.441.2]the implicit semantic relatedness between classes caused the failure of the RNN Autoencoder. Be-sides, the CNN+FC and RNN+FC had same in-puts and outin-puts and it was clear that CNN+FC performed better than RNN+FC in the experi-ment. However, neither CNN+FC nor RNN+FC was able to transfer the knowledge learned from seen to unseen classes. Finally, our two-phase framework has competitive prediction accuracy on unseen classes while maintaining the accuracy on seen classes. This made it achieve the highest overall accuracy on both datasets and both unseen rates. In conclusion, by using integrated seman-tic knowledge, the proposed two-phase framework with data and feature augmentation is a promising step to tackle this challenging zero-shot problem.
Furthermore, another benefit of the framework is high flexibility. As the modules in Figure1has less coupling to one another, it is flexible to im-prove or customise each of them. For example, we can deploy an advanced language understanding model, e.g., BERT (Devlin et al.,2018), as a tradi-tional classifier. Moreover, we may replace Con-ceptNet with a domain-specific knowledge graph to deal with medical texts.
4 Related Work
4.1 Zero-shot Text Classification
There are a few more related works to discuss be-sides recent approaches we compared with in the experiments (explained in section 3.3). Dauphin et al. (2013) predicted semantic utterance of texts by mapping class labels and text samples into the same semantic space and classifying each sam-ple to the closest class label. Nam et al. (2016) learned the embeddings of classes, documents, and words jointly in the learning stage. Hence, it can perform well in domain-specific classification, but this is possible only with a large amount of training data. Overall, most of the previous works exploited semantic relationships between classes and documents via embeddings. In contrast, our proposed framework leverages not only the word embeddings but also other semantic knowledge. While word embeddings are used to solve analogy for data augmentation in Phase 1, the other seman-tic knowledge sources (in Figure2) are integrated into relationship vectors and used as augmented features in Phase 2. Furthermore, our framework does not require any semantic correspondences be-tween seen and unseen classes.
4.2 Data Augmentation in NLP
In the face of insufficient data, data augmentation has been widely used to improve generalisation of deep neural networks especially in computer vi-sion (Krizhevsky et al., 2012) and multimodality (Dong et al.,2017b), but it is still not a common practice in natural language processing. Recent works have explored data augmentation in NLP tasks such as machine translation and text clas-sification (Saito et al., 2017;Fadaee et al., 2017; Kobayashi, 2018), and the algorithms were de-signed to preserve semantic meaning of an orig-inal document by using synonyms (Zhang and Le-Cun,2015) or adding noises (Xie et al.,2017), for example. In contrast, our proposed data augmen-tation technique translates a document from one meaning (its original class) to another meaning (an unseen class) by analogy in order to substitute un-available labelled data of the unseen class.
4.3 Feature Augmentation in NLP
Apart from improving classification accuracy, fea-ture augmentation is also used in domain adapta-tion to transfer knowledge between a source and a target domain (Pan et al.,2010b;Fang and Chi-ang,2018;Chen et al.,2018). An early research paper applying feature augmentation in NLP is Daume III(2007) which targeted domain adapta-tion on sequence labelling tasks. After that, fea-ture augmentation was used in several NLP tasks such as cross-domain sentiment classification (Pan et al., 2010a), multi-domain machine translation (Clark et al., 2012), semantic argument classifi-cation (Batubara et al., 2018), etc. Our work is different from previous works not only that we ap-plied this technique to zero-shot text classification but also that we integrated many types of semantic knowledge to create the augmented features.
5 Conclusion and Future Work
baselines and recent approaches in all settings. In the future, we plan to extend our framework to do multi-label classification with a larger amount of data, and also study how semantic units defined by linguists can be used in the zero-shot scenario.
Acknowledgments
We would like to thank Douglas McIlwraith, Nontawat Charoenphakdee, and three anonymous reviewers for helpful suggestions. Jingqing and Piyawat would also like to thank the support from the LexisNexisR
Risk Solutions HPCC SystemsR
academic program and Anandamahidol Founda-tion, respectively.
References
Martin Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. Ten-sorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), pages 265– 283.
Dina Khaira Batubara, Moch Arif Bijaksana, and Adi-wijaya. 2018.On feature augmentation for semantic argument classification of the quran english trans-lation using support vector machine. Journal of Physics: Conference Series, 971(1):012043.
Zitian Chen, Yanwei Fu, Yinda Zhang, Yu-Gang Jiang, Xiangyang Xue, and Leonid Sigal. 2018. Semantic feature augmentation in few-shot learning. CoRR, abs/1804.05298.
Jonathan H Clark, Alon Lavie, and Chris Dyer. 2012. One system, many domains: Open-domain statisti-cal machine translation via feature augmentation. In
Proceedings of the Conference of the Association for Machine Translation in the Americas.
Hal Daume III. 2007. Frustratingly easy domain adap-tation. In Proceedings of the 45th Annual Meet-ing of the Association of Computational LMeet-inguistics, pages 256–263. Association for Computational Lin-guistics.
Yann N Dauphin, Gokhan Tur, Dilek Hakkani-Tur, and Larry Heck. 2013. Zero-shot learning for semantic utterance classification. arXiv preprint arXiv:1401.0509.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understand-ing. arXiv preprint arXiv:1810.04805.
Hao Dong, Akara Supratak, Luo Mai, Fangde Liu, Axel Oehmichen, Simiao Yu, and Yike Guo. 2017a. Tensorlayer: a versatile library for efficient deep learning development. InProceedings of the 2017 ACM on Multimedia Conference, pages 1201–1204. ACM.
Hao Dong, Jingqing Zhang, Douglas McIlwraith, and Yike Guo. 2017b. I2t2i: Learning text to image syn-thesis with textual data augmentation. InImage Pro-cessing (ICIP), 2017 IEEE International Conference on, pages 2015–2019. IEEE.
Marzieh Fadaee, Arianna Bisazza, and Christof Monz. 2017. Data augmentation for low-resource neural machine translation. arXiv preprint arXiv:1705.00440.
Wen-Chieh Fang and Yi-Ting Chiang. 2018. A dis-criminative feature mapping approach to heteroge-neous domain adaptation. Pattern Recognition Let-ters, 106:13–19.
Rob Fergus, Hector Bernal, Yair Weiss, and Antonio Torralba. 2010. Semantic label sharing for learning with many categories. InComputer Vision – ECCV 2010, pages 762–775, Berlin, Heidelberg. Springer Berlin Heidelberg.
Y. Fu, T. Xiang, Y. Jiang, X. Xue, L. Sigal, and S. Gong. 2018. Recent advances in zero-shot recog-nition: Toward data-efficient understanding of vi-sual content. IEEE Signal Processing Magazine, 35(1):112–125.
Yoon Kim. 2014. Convolutional neural net-works for sentence classification. arXiv preprint arXiv:1408.5882.
Sosuke Kobayashi. 2018. Contextual augmentation: Data augmentation by words with paradigmatic re-lations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech-nologies, Volume 2 (Short Papers), pages 452–457. Association for Computational Linguistics.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hin-ton. 2012. Imagenet classification with deep con-volutional neural networks. In Advances in neural information processing systems, pages 1097–1105.
Christoph H Lampert, Hannes Nickisch, and Stefan Harmeling. 2009. Learning to detect unseen object classes by between-class attribute transfer. InIEEE Conference on Computer Vision and Pattern Recog-nition, pages 951–958. IEEE.
Omer Levy and Yoav Goldberg. 2014. Linguistic reg-ularities in sparse and explicit word representations. InProceedings of the eighteenth conference on com-putational natural language learning, pages 171– 180.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jef-frey Dean. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Jinseok Nam, Eneldo Loza Menc´ıa, and Johannes F¨urnkranz. 2016. All-in text: Learning document, label, and word representations jointly. InThirtieth AAAI Conference on Artificial Intelligence.
Mohammad Norouzi, Tomas Mikolov, Samy Bengio, Yoram Singer, Jonathon Shlens, Andrea Frome, Greg S Corrado, and Jeffrey Dean. 2013. Zero-shot learning by convex combination of semantic embed-dings. arXiv preprint arXiv:1312.5650.
Sinno Jialin Pan, Xiaochuan Ni, Jian-Tao Sun, Qiang Yang, and Zheng Chen. 2010a. Cross-domain sen-timent classification via spectral feature alignment. InProceedings of the 19th international conference on World wide web, pages 751–760. ACM.
Sinno Jialin Pan, Qiang Yang, et al. 2010b. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359.
Jeffrey Pennington, Richard Socher, and Christo-pher D. Manning. 2014. Glove: Global vectors for word representation. InEmpirical Methods in Nat-ural Language Processing (EMNLP), pages 1532– 1543.
Pushpankar Kumar Pushp and Muktabh Mayank Sri-vastava. 2017. Train once, test anywhere: Zero-shot learning for text classification. arXiv preprint arXiv:1712.05972.
Radim ˇReh˚uˇrek and Petr Sojka. 2010. Software Frame-work for Topic Modelling with Large Corpora. In
Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45–50, Val-letta, Malta. ELRA.
Bernardino Romera-Paredes and Philip Torr. 2015. An embarrassingly simple approach to zero-shot learn-ing. InInternational Conference on Machine Learn-ing, pages 2152–2161.
Itsumi Saito, Jun Suzuki, Kyosuke Nishida, Kugatsu Sadamitsu, Satoshi Kobashikawa, Ryo Masumura, Yuji Matsumoto, and Junji Tomita. 2017. Improv-ing neural text normalization with data augmenta-tion at character-and morphological levels. In Pro-ceedings of the Eighth International Joint Confer-ence on Natural Language Processing (Volume 2: Short Papers), volume 2, pages 257–262.
Prateek Veeranna Sappadla, Jinseok Nam, Eneldo Loza Menc´ıa, and Johannes F¨urnkranz. 2016. Using se-mantic similarity for multi-label zero-shot classifica-tion of text documents. InProc. European Sympo-sium on Artificial Neural Networks, Computational Intelligence and Machine Learning.
Lei Shu, Hu Xu, and Bing Liu. 2017. Doc: Deep open classification of text documents. InProceedings of the 2017 Conference on Empirical Methods in Nat-ural Language Processing, pages 2911–2916. Asso-ciation for Computational Linguistics.
Richard Socher, Milind Ganjoo, Christopher D. Man-ning, and Andrew Y. Ng. 2013. Zero-shot learning through cross-modal transfer. InProceedings of the 26th International Conference on Neural Informa-tion Processing Systems - Volume 1, NIPS’13, pages 935–943, USA. Curran Associates Inc.
Robert Speer and Catherine Havasi. 2013. Conceptnet 5: A large semantic network for relational knowl-edge. InThe Peoples Web Meets NLP, pages 161– 176. Springer.
Sebastian Thrun and Lorien Pratt. 1998. Learning to learn: Introduction and overview. In Learning to learn, pages 3–17. Springer.
Xiaolong Wang, Yufei Ye, and Abhinav Gupta. 2018. Zero-shot recognition via semantic embeddings and knowledge graphs. InProceedings of the IEEE Con-ference on Computer Vision and Pattern Recogni-tion, pages 6857–6866.
World Health Organization. 1996. Infectious diseases kill over 17 million people a year. Malaria Weekly, 3:11–16.
Yongqin Xian, Christoph H Lampert, Bernt Schiele, and Zeynep Akata. 2017. Zero-shot learning-a com-prehensive evaluation of the good, the bad and the ugly. arXiv preprint arXiv:1707.00600.
Ziang Xie, Sida I Wang, Jiwei Li, Daniel L´evy, Aiming Nie, Dan Jurafsky, and Andrew Y Ng. 2017. Data noising as smoothing in neural network language models. arXiv preprint arXiv:1703.02573.
Xiang Zhang and Yann LeCun. 2015. Text understand-ing from scratch.arXiv preprint arXiv:1502.01710.
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text clas-sification. In Advances in neural information pro-cessing systems, pages 649–657.