Proceedings of NAACL-HLT 2018, pages 1760–1769
Relational Summarization for Corpus Analysis
Abram HandlerandBrendan O’Connor College of Information and Computer Sciences
University of Massachusetts Amherst
[email protected], [email protected]
Abstract
This work introduces a new problem, rela-tional summarization, in which the goal is to generate a natural language summary of the re-lationship between two lexical items in a cor-pus, without reference to a knowledge base. Motivated by the needs of novel user inter-faces, we define the task and give examples of its application. We also present a new query-focused method for finding natural language sentences which express relationships. Our method allows for summarization of more than two times more query pairs than baseline re-lation extractors, while returning measurably more readable output. Finally, to help guide future work, we analyze the challenges of re-lational summarization using both a news and a social media corpus.
1 Introduction
Research on automatic summarization (Nenkova
et al.,2011;Das and Martins,2007) aims to help users understand large document sets. However, the details of how textual summaries might actu-ally be presented to users are often ignored. We propose that user interfaces which display
note-worthy terms or concepts present the need for
re-lational summaries: descriptions of the relation-ship between two entities or noun phrases from a corpus.
Examples of such interfaces include: comman-dline software for examining noteworthy terms or
phrases (Squirrell, 2017; Robinson, 2016;
Mon-roe et al.,2008), point-and-click browsers which display named entities and their
interconnec-tions on a network diagram (Wright et al.,2009;
G¨org et al., 2014; Tannier, 2016), concept map
browsers (Falke and Gurevych, 2017b) and
doc-ument search engines which suggest terms rele-vant to a query, such as the related searches dis-played on Wikipedia info boxes from Google. In
Aristide
Aristide
Gen. Cedras UN
Liberation Theology
rival of
influenced by relied on
Aristide the Haitian leader … governing philosophy informed by liberation theology
Aristide, as a young Catholic priest … was influenced by the liberation theology
Aristide was earlier expelled from Salesian Order for promoting liberation theology
Clinton criticized
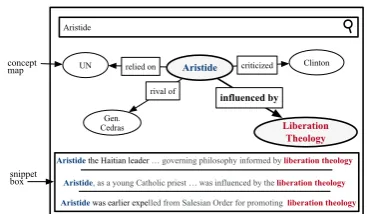
concept map
[image:1.595.324.508.220.327.2]snippet box
Figure 1: An example interface which requires rela-tional summarization. The user has queried for the en-tityAristide. The interface shows aconcept map(top), displaying short summaries of Aristide’s important re-lationships. The user has drilled down to see a more detailed summary of Aristide’s relationship with liber-ation theology, displayed in asnippet box(bottom).
all such settings a natural question arises: what is the nature of the relationship between the entities or concepts shown in the interface? One particular interface which presents the need for a relational
summary is shown in figure1.
Relational questions are ubiquitous and varied. Examples include the following. What is the rela-tionship between the “City of London” and “goal-delivery of Newgate” in 18th century court records (Hitchcock et al., 2012)? What is the relation-ship between “Advanced Integrated Systems” and
“United Arab Emirates” in the Paradise Papers?1
What does “dad” have to do with “mom” on the
subreddit discussion forumRelationship Advice?
This study seeks to answer such questions by
examining the problem ofrelational
summariza-tion, which lies at the intersection of prior work
on summarization and relation extraction. Un-like previous efforts at summarizing relationships (Falke and Gurevych, 2017a), our approach fo-cuses on answering user queries about the connec-tions between two particular terms, without
ref-1https://www.icij.org/investigations/paradise-papers/
United States ousted former President Jean-Bertrand Aristide
… Jean-Bertrand Aristide restored to power … under watch of United States… Jean-Bertrand Aristide restored to power under watch of United States
Jean-Bertrand Aristide, left Haiti for the United States
United States ousted former President Jean-Bertrand Aristide
… the United States ousted former President Jean-Bertrand Aristide to … … claimed the United States said that Rev.Jean-Bertrand Aristidewanted to … … by the United States since the Rev. Jean-Bertrand Aristide argued …
… Jean-Bertrand Aristide, left Haiti for the United States in March … Candidate set
Summary Mention set
Jean-Bertrand Aristide restored to power under watch of United States
summary construction
task candidate set generation task
[image:2.595.81.522.64.156.2]…
Figure 2: A relational summary is a synopsis of all sentences which mention two terms, denoted (t1)and (t2).
We refer to such sentences as amention set. In the figure above (t1)isJean-Bertrand Aristideand (t2)is
United States. To create a summary first requires identifying all statements in the mention set which coherently describe some relationship between (t1)and (t2). Thiscandidate set generation taskis a prerequisite for the
subsequentsummary construction task: selecting the topKcandidates to create a summary. In this work, we
offer a method for the first task and show how the second task will likely require a diversity of summarization techniques (§6).
erencing a knowledge graph (Voskarides et al.,
2015).2 In order to answer such queries we:
• Formally define the problem (§2), which we
divide into two subtasks: candidate set
gen-erationandsummary construction.
• Provide a new method for the candidate set
generation task (§4), which we show
outper-forms baseline relation extraction techniques (§5) in terms of readability and yield.
• Analyze the summary construction task for
future work (§6), demonstrating that
differ-ent summarization techniques are likely most appropriate for different mention sets.
2 Formal definition and method
We refer to all sentences within a collection of
documents which contain two terms, (t1)and
(t2)as the mention set. (t1)and (t2)are noun
phrases, a syntactic category which encompasses both traditional named entities like people and places, as well as less concrete, but important, entities and concepts like “liberation theology” (Handler et al.,2016).
A relational summary is a synopsis of the
men-tion set. A summary consists ofK relation
state-ments, each displayed on its own line. Relation statements are natural language expressions which
begin with (t1)and end with (t2). We refer
to the span of tokens in between (t1) and (t2)
as a relation phrase. We use the notation (t1) r
(t2) to denote a relation statement, indicating two
2Relational summaries are intended for general-purpose corpus analysis. Existing knowledge bases do not cover top-ics discussed in many corpora, such as historical court records (Hitchcock et al.,2012). Therefore, our approach does not employ a knowledge base.
terms and a relation phrase. In the relation
state-ment, “AristidefledHaiti”, ris the token “fled”,
(t1)is the tokenAristide, and (t2)is the token Haiti.
Relation statements, which are strings intended
for human readers, are similar to the 3-tuples, “
re-lations”, from prior work on information
extrac-tion (Banko et al.,2007). However, in this work,
we show that the assumptions underlying the ex-traction of 3-tuples for machines (§3) leads to poor performance in summarizing mention sets for peo-ple (§5).
In this study, we present a strictly extractive method for generating relation statements: each relation statement must be constructed by
delet-ing tokens from some sentence in the mention set.3
Some relation statements constructed by deleting tokens from a sentence make sense; others do not.
We refer to any(t1) r (t2) which makes makes
sense to a human reader as acceptable.4 Table
1shows examples of acceptable and unacceptable
relation statements, constructed by deletion.
s1 Aristide
(t1) fled
r Haiti
(t2) in 2004.
s2 For instance Bush
(t1) told
r
Aristide (t2)
to leave.
Table 1: Two relation statements constructed by delet-ing tokens from source sentences,s1ands2. The
re-lation statement extracted from s1 is acceptable; the
statement extracted froms2is not.
3In subsequent studies of relation extractors (
§5), we al-low extractors to lightly introduce new tokens, such as adding the word “is” in relations expressed as noun phrases.
Only acceptable relation statements are permit-ted in a summary. The set of all possible
accept-able relation statements is called the candidate
set, denoted C. We refer to the task of
identify-ing all acceptable relation statements as the
candi-date set generation task. Identifying a candidate set presents a subsequent problem of choosing the
best collection ofKrelation statements fromCto
create a summary. We refer to this second step as thesummary construction task.
As in traditional summarization (Das and
Mar-tins,2007;Nenkova et al.,2011), a good relational summary should (i) be readable, (ii) include the most important aspects of the relationship between
(t1)and (t2), (iii) avoid redundancy, and (iv)
cover the full diversity of topics in the mention set. Relational summaries might be presented with different kinds of user interfaces. In cases where a user seeks to browse many relationships, a
sum-mary might be displayed as aconcept map(Falke
and Gurevych, 2017a), where the two terms are vertexes in a directed graph and their relationship is printed along the edge label between them. In cases where user wants to investigate a specific relationship, a relational summary might be
dis-played as a snippet box: a short list of sentences
which begin and end with the two terms. Figure1
shows a snippet box and concept map. In a snippet box, both the number of lines in the summary and the length of the lines in the summary is longer than in a concept map.
3 Related work
Relational summarization intersects with a diver-sity of prior work from natural language
process-ing, including work onrelation extraction,
sum-marizationandsentence compression.
Traditionally, the goal ofrelation extractionis
to cull structured facts for knowledge databases from unstructured text. Often, such facts take the form of a 3-tuple which defines a relationship between two arguments, such as (arg1=Angela Merkel, rel=met with, arg2=Theresa May). If ex-tractors do not make use of a predefined schema, the task of finding relations is called Open
Infor-mation Extraction (OpenIE). OpenIE systems5
of-fer an off-the-shelf method for generating a candi-date set for a relational summary. Their output can easily be linearized to(t1) r (t2) statements by
5There are many available OpenIE systems. See
Stanovsky and Dagan(2016) for an inventory of major work.
simply concatenating the three arguments of the triple to form a string.
However, we find that the recall of relation ex-tractors is often too low to summarize many men-tion sets. We measure this disadvantage
exten-sively in section§5.1. One reason for their poor
performance might be that extractors have goals and assumptions which are poorly suited to the re-lation summarization task. In rere-lation extraction, the aim is to find relation strings that recur for many different entity pairs, which allows such sys-tems to build knowledge databases. For instance, relation extraction might be used to build tables of world leaders who rel=“met with” other world leaders in order to analyze international politics. From this perspective, long, sparse, heterogenous and detailed relation strings which might apply only to a pair of specific arguments are unde-sirable, as they make it difficult to find general patterns across many different entity pairs. For example, the influential ReVerb OpenIE system (Fader et al., 2011) excludes “overly-specific re-lation phrases” which apply only to two entities. One way to help ensure that relations generalize across entity pairs is to strive for arguments which are as short as possible, a common goal in OpenIE (Stanovsky and Dagan,2016).6
Our method for generating a candidate set is
closer to approaches fromsentence compression
(Knight and Marcu, 2002; Clarke and Lapata,
2008;Filippova and Altun,2013;Filippova et al.,
2015), an NLP task which seeks to make a source
sentence shorter while preserving the most impor-tant information and producing readable output. We show that our sentence compression approach allows us to achieve higher readability than off-the-shelf relation extractors (§5).
Sentence compression is often used in
tradi-tional extractivesummarizationto make more
ef-ficient use of a budgeted summary length. We
dis-cuss summarization further in §6, where we
con-sider how existing work might be applied to the
problem of selectingK statements from the
can-didate set.
Sampled unacceptable compression Auburn policeare investigating the death of aTuskegeewoman who died ... Known acceptable compression Drug firmGlenmarkhas opened its new facility inArgentinawhich would ... Table 2: Examples of known acceptable and presumed unacceptable training examples, with entities shown in bold. We refer to crossed out spans asoutside of the compression. Our model uses grammatical information from inside and outside of the compression to predict the acceptability of a compression.
4 Query-focused candidate set generation
Traditionally, relation extraction begins with a fixed notion of what constitutes a desirable “rela-tion” between two arguments, defined by a
prede-fined schema, a syntactic template (Fader et al.,
2011), or a collection of seed examples (Angeli
et al., 2015). The relation extraction task is then to correctly identify spans in which arguments are joined by a relation.
The relational summarization problem is some-what different: we begin with a pair of query
terms, (t1) and (t2), and we wish to learn the
nature of their relationship. Therefore, any state-ment which coherently describes any relationship between the two query terms is potentially of in-terest, even if it does not match prior expectations of what constitutes a relation.
We thus approach the candidate set generation task as a specialized form of sentence compres-sion: we attempt to predict if a sentence from the text can be coherently compressed to the form
(t1)r(t2). Table2shows examples of sentences
which can and cannot be shortened to this form. We use gold standard sentence–compression
pairs from theFilippova and Altun(2013) dataset
to supervise this prediction. In sentence compres-sion corpora, gold standard comprescompres-sions must be acceptable sentences. Therefore, compressions from the dataset which happen to begin and end
with a named entity,7 once extracted from source
sentences, can serve as positive examples of ac-ceptable relation statements. On the other hand,
randomly chosen spans of the form (t1) r (t2),
which happen to arise in source sentences, are very often not acceptable as standalone sentences. These randomly sampled spans can serve as exam-ples of unacceptable relation statements. We then predict acceptability with supervision from known gold acceptable and sampled, presumed
incoher-ent examples.8
7https://github.com/google-research-datasets/
sentence-compression
8We manually inspect 100 negative examples, selected at random, and find that roughly 80% are in fact incoherent.
Filtering the original dataset in this manner9
yields 17,529 positive and 30,266 negative sen-tences. We then downsample negative training examples to create two balanced classes of equal size, and use 81% of data for training, 9% for val-idation and the remaining 10% for testing.
Let p(c = 1 | s, (t1) r (t2)) indicate the
probability that a span of form (t1) r (t2)
ex-tracted from sentence s is coherent. We model
p(c = 1|s, (t1) r (t2)) using logistic
regres-sion, with features based on the position of
part-of-speech tags and dependency edges ins.
Specif-ically, each sentence in the filtered dataset contains a span of the form(t1)r(t2). We refer to the
to-kens in this span as in the compression because
a user would see these tokens in a relation
state-ment compressed froms. Each sentence also
con-tains spans of tokens which areoutside of the
com-pressionbecause they are deleted from the original
source sentence to create a relation statement.
Ta-ble2displays examples.
Our feature vector records the counts of how many times each part-of-speech tag in the tagset occurs in the compression and also independently records the counts of how many times each part-of-speech tag occurs out of the compression. We refer to the count of each part-of-speech tag in the compression and the count of each part-of-speech
tag out of the compression asΦ. We also count the
occurrence of each possible dependency edge la-bel in the compression, and the count of each pos-sible dependency edge label out of the sion. If a label’s dependent lies in the
compres-9We also exclude randomly chosen spans which happen to encompass the entire source sentence and exclude randomly chosen spans where (t1)and(t2)are joined by only edges of type compound in the dependency graph of the compres-sion (e.g. “Coup leader Cedras ...”). We use CoreNLP vercompres-sion 3.8 to extractenhanced++Universal Dependencies ( Man-ning et al.,2014;Schuster and Manning,2016;Nivre et al.,
2016). We also filter positive and negative examples where the span between (t1)and (t2)is longer thanJ=75
charac-ters, to simulate a space constraint in a user interface. Finally, we remove all punctuation from the end of the sentence for both positive and negative examples because all gold positive compressions end in punctuation marks. For positive exam-ples, if the compressed version of a sentence deletes tokens betweent1andt2, we replace the span betweent1andt2in
p(c= 1|s,(t1)r(t2)) (t1)r(t2)
.005 Jean-Bertrand Aristidethat theUnited States
.010 United Statessince the Rev.Jean-Bertrand Aristide
... ...
.894 United Statesousted former PresidentJean-Bertrand Aristide
[image:5.595.130.468.60.124.2].976 Jean-Bertrand Aristide, left Haiti for theUnited States
Table 3: Highest and lowest coherence predictions from the setUnited States–Jean-Bertrand Aristide
sion, we consider the label in the compression.10
We refer to these dependency edge counts as Ψ.
Our final feature vector,Ω, is defined as the
con-catenation ofΨandΦ.
Features Test accuracy Φ(pos) .858 Ψ(deps) .892 Ω(deps & pos) .896
Table 4: Test accuracies.
We implement our model withscikit-learn(
Pe-dregosa et al.,2011) and manually tune the inverse
regularization constant to the setting,c= 1, which
achieves the highest accuracy on the validation set. For evaluation, a sentence is presumed coherent if
p(c = 1|s, (t1) r (t2)) > .5. Using the
fea-ture vector Ωwe achieve an accuracy of .896 on
the test set. We also present results using only the
Ψ and Φ features (table 4) because reliable
de-pendency parses are not available in some settings (Blodgett et al.,2016;Bamman,2017).
Two limitations of this approach suggest areas for future work. First, in some cases, the
rela-tionship between (t1) and (t2)might not be
ex-pressed in the form,(t1)r(t2), as in “Russiaand Francesigned an agreement”. In order to gener-ate candidgener-ate relation stgener-atements it would be
help-ful to lightly rewrite the sentence, as in “Russia
signed an agreement withFrance”. Additionally,
a sentence might express a relationship between two terms but be too long to display on a concept map or a snippet box. In these cases, it would be helpful to compress the sentence to create a more concise relation statement.
5 Experiments
Any relational summarization system should de-liver a high-quality summary when a user queries for two terms. Therefore, ideally, a system should generate the largest possible candidate set, without returning incoherent relation statements. We thus
10Enhanced dependencies allow for a token to have more than one incoming edge (i.e., multiple parents). If there is more than one incoming edge, we pick an edge at random.
evaluate our query-focused generation method in terms of both readability and yield (total relation statements recalled). Our method generates three times more relation statements than OpenIE sys-tems, allowing for summarization of two times more query pairs. We also achieve higher scores
in a test of human coherence judgements (table5).
More concretely, we evaluate our compression-based method for generating candidate sets against two relation extractor baselines on two very differ-ent corpora: (1) all commdiffer-ents from the large
“rela-tionships”11subreddit from June, 2015 –
Septem-ber, 201712 and (2) a collection of New York
Times articles from 1987 to 2007 which
men-tion the country “Haiti” (Sandhaus, 2008). For
each corpus, we first find a collection of
multi-word phrases using thephrasemachine
pack-age (Handler et al.,2016) which extracts all multi-word, noun phrase terms from the corpus.
After extracting all terms, we determine the top 100 terms, by count. We then examine all non-empty mention sets for all possible combinations of two top terms. A mention set is a set of
sen-tences which mention two terms (§2). We
exam-ine all mention sets because an investigator should be able to investigate any entity she chooses while analyzing a corpus.
In subsequent experiments, we require all
rela-tion statements be less than or equal to J = 75
characters, which excludes overly verbose relation statements which are unsuitable for many user in-terfaces.
5.1 Yield experiments
Off-the-shelf relation extractors generate 3-tuples from each mention set. Some of those 3-tuples
might have one argument which is equal to (t1)
and another argument which is equal to (t2).
Each such 3-tuple can be linearized into a string
of the form (t1) r (t2) to generate a candidate
set. However, we find that using extractors in this
11“relationships” refers to interpersonal relationships 12https://medium.com/@jason 82699/
manner achieves a low yield (total number of ex-tracted relations). A low yield is undesirable both because it limits the number of mention sets which may be summarized and generates fewer relation statements from which to select an optimal rela-tional summary.
More precisely, we identify the 3-tuples which an OpenIE system extracts from a mention set such that exactly one argument from the triple is equal13to(t
1) and exactly one argument from the
triple is equal to(t2). We refer to these 3-tuples as
“matching”. We then count (1) the total number of mention sets which contain at least one matching 3-tuple and (2) the total number matching 3-tuples across all mention sets. We refer to such counts as
theyieldof a candidate generation system.
We measure the yield of Stanford OpenIE (
An-geli et al., 2015) and ClausIE (Del Corro and Gemulla, 2013) on the New York Timesand
Red-dit corpora, and compare each system to our
compression-based approach (§4).14 We
mea-sure these two relation extractors because Stanford OpenIE is included with the popular CoreNLP software and ClausIE achieves the highest recall in two systematic studies of relation extractors (Stanovsky and Dagan,2016;Zhang et al.,2017). We find that, for the great majority of sentences, relation extractors do not extract any relations
be-tween (t1)and (t2). Moreover, for many
men-tion sets, the number of relamen-tions extracted with off-the-shelf systems is often zero. We show these results in table5.
This suggests that although relation summariza-tion is superficially similar to relasummariza-tion extracsummariza-tion, off-the-shelf extractors are poor tools for creating textual units to summarize mention sets. Very of-ten, two terms are related to each other in ways which are simply not captured by relation extrac-tors.
13Note that OpenIE systems might not extract the literal string (t1)or (t2)as arguments. For instance, if (t1) is “Merkel” the OpenIE system might extract the argument “Angela Merkel”. If some term and some argument from a relational triple share the same head token in the dependency parse of the sentence we say that they are equal. Falke and Gurevych(2017c) employ a similar equality criterion. We tokenize with CoreNLP. In extremely rare cases, tokenization mismatches between CoreNLP and ClausIE make it impossi-ble to apply this criterion.
14For our compression-based approach, we count all cases wherep(c= 1|s,(t1)r(t2))> .5as extracting a relation statement.
5.2 Human acceptability judgments
Our compression-based method achieves higher yield than off-the-shelf relation extractors. How-ever, because all sentences in a mention set include
(t1)and (t2), it is always possible to generate a
very large candidate set by simply extracting all
spans between (t1) and (t2) from the mention
set, regardless if such relation statements are co-herent. We examine if gains in yield come at the expense of acceptability by presenting randomly selected relation statements to workers on the
plat-form Figure Eight15 (formerly Crowdflower) and
asking workers to rate the extent to which they agree or disagree as to whether a relation state-ment is a “coherent English sentence” on a scale from 1 to 5. Each relation statement is shown to
three workers in total.16 Our approach is broadly
similar to the readability experiments reported in
Filippova and Altun(2013).
We solicit 481 total judgements from work-ers and calculate the mean acceptability score, by
method and corpus (table5). Our method achieves
the highest mean acceptability score for both cor-pora.
Additionally, aggregating judgments across
cor-pora, we observe a statistically significant (p=8x
10−4) difference between our method(µ= 3.89,σ= 1.38) and Stanford OpenIE (µ= 3.33, σ= 1.46) in a two-tailed t-test. Our method also achieves a higher mean score than ClausIE(µ= 3.69,σ= 1.44),
although the difference is not significant.
6 Future work: summary construction task
After a relational summarization system generates a candidate set, the next task is selecting the top
K candidate statements for inclusion in a
sum-mary (figure 2). In this work, we do not
at-tempt this summary construction task. However, in this section, we analyze the nature of the rela-tional summarization challenge by describing ferences among mention sets, and how these dif-ferences might affect future efforts at summariza-tion.
We observe that mention sets are inherently het-erogenous. Some describe a single,
temporally-15https://www.figure-eight.com/
Yield Coherence Total non-empty pairs Total rel. stmts. Mean judgment
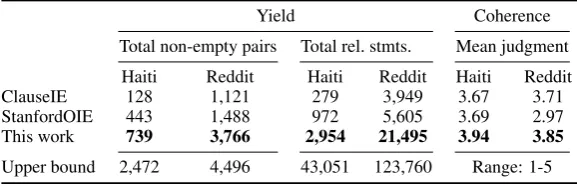
Haiti Reddit Haiti Reddit Haiti Reddit
ClauseIE 128 1,121 279 3,949 3.67 3.71
StanfordOIE 443 1,488 972 5,605 3.69 2.97
This work 739 3,766 2,954 21,495 3.94 3.85
[image:7.595.153.442.63.156.2]Upper bound 2,472 4,496 43,051 123,760 Range: 1-5
Table 5: We compare Stanford OpenIE, ClausIE and our headline-based compression method for the candidate set generation task on two different corpora (Haiti articles fromNew York Times, and theRedditrelationships forum) in terms of (1) how many entity pairs have a non-empty candidate set, (2) how many total relation statements are generated, and (3) the average human judgment of acceptability (§5.2). For yield measures, the upper bound on the left shows the total number of non-empty entity pairs (i.e. how many pairs actually cooccur in at least one sentence, out of all 100
2
= 4950theoretically possible pairs) and the upper bound on the right shows the total number of sentences in the corpus which mention at least two of the terms. Our method summarizes more entity pairs across both corpora, and achieves the highest acceptability scores among all techniques (§5.2).
focused event. Others describe a consistent, un-changing relationship. Still others describe intri-cate sagas unfolding across time. For instance, within the Haiti corpus, one mention set describes
events in 1994 whenGeneral Cedrasfled to the
Dominican Republic. This mention set is quite different from a set of sentences in the Reddit
cor-pus in which users assert thatvideo games are a
deal breaker in interpersonal relationships.
Fig-ure3displays hand-crafted summarizes for these
mention sets.
In general, the properties which guide how a
mention set should be summarized are its size,
topical diversity,temporal focusand the degree
to which the set expressesstates or events. In this
section, we use the notation (t1)– (t2)to refer
to a mention set. For instance,New York–London
would refer to all sentences from a corpus which contain the names of both of these cities.
Size. In general, because many word types in a
corpus occur infrequently (Zipf,1949), the
num-ber of sentences which mention (t1)and (t2)
is often small. For instance, of the 320,670 total sentences in the Haiti corpus, only 160 mention “Jean-Bertrand Aristide” and the “United States,” which is nonetheless among the larger mention sets in the corpus. In general, larger sets often describe complex and noteworthy relationships,
which are more difficult to summarize (figure3c).
Note that although individual mention sets are of-ten small enough to simply read (unlike in some multi-document summarization settings), summa-rization of mention sets is still quite useful, as practitioners will often seek to understand many different relationships as they investigate a new
topic (e.g. figure1).
Topical diversity. In general, some mention sets are focused on a single topic, others are more diffuse. For instance, after losing power in a sec-ond, 2004 coup Haiti’s Jean Bertrand Aristide was forced into exile in South Africa. The mention
set forJean Bertrand Aristide–South Africa
con-tains twelve sentences which (mostly, but not ex-clusively) describe Aristide’s removal from power and life in exile in South Africa from 2004 on-wards. Detecting and including diverse or com-plex topics is a classic aim of traditional multi
doc-ument summarization (e.g.Lin and Hovy(2000)),
which might be applied in this new setting.
Temporal focus. In timestamped corpora such as news archives or social media posts, some men-tion sets are focused within certain time periods; others are spread across the span of the corpus.
For instance, in the Haiti corpus,General Cedras–
Dominican Republicare only mentioned together
during a few months of 1994 (figure3b). A good
summary for this mention set should describe a central event from this time period: when General Cedras fled to the Dominican Republic. On the
other hand,Jean-Bertrand Aristide–United States
are mentioned together in 67 months in the cor-pus, covering a number of important events spread
across decades (figure3c). For this mention set, a
narrow summary focusing on a single event would be inappropriate.
video gamesand I don’t want that to be adeal breaker
video gameswas adeal breaker
video gamesis adeal breaker
(a) A hand-crafted summary for the mention setvideo games–deal breaker. The mention set contains many stative descriptions of the relationships between the two terms, indicating that a summary might focus on presenting fixed relationships rather than evolving events.
General Cedras... last week fled to theDominican Republic
Dominican Republic... has indicated it will not permit permanent residence byGeneral Cedras
(b) A hand-crafted summary for the mention setGeneral Cedras–Dominican Republic. The set has a high number of mentions which all fall within a several month span, hinting at a relationship focused on a particular event at a particular point in time.
Aug. 1994 United Statessupports the restoration of the democratically elected president of Haiti,Jean-Bertrand Aristide Oct. 1995 Jean-Bertrand Aristidewas restored to power a year ago under the watch ofUnited States
Sep. 2002 United Statesand other donors withheld contributions, hoping to spur PresidentJean-Bertrand Aristide Mar. 2004 Jean-Bertrand Aristideasserted that he had been driven from power by theUnited States
(c) A hand-crafted summary for the mention setJean-Bertrand Aristide–United States, one of the largest in the Haiti corpus. The mention set describes a complex, shifting relationship; at different times over several decades, Aristide was a beneficiary, opponent and critic of the United States.
Figure 3: Mention sets are heterogenous, requiring a diversity of summarization techniques. In this work, we analyze the diversity of mention sets towards future attempts that the relational summarization problem.
Alfonseca et al.(2013)) and on social media (e.g.
Nichols et al.(2012)). In some cases, the event de-scribed in a mention set will even match the loose
form of a common narrative template (Chambers
and Jurafsky,2008), such as when the two terms are codefendants at a trial.
Mention sets which are more temporally diffuse are also more challenging. Update summarization refers to summarizing changes introduced by new documents, possibly from a high volume stream (Kedzie et al.,2015). This form of summarization is important in cases when a relationship shifts or
changes through time, as in figure3c.
States or events. Mention sets may be coarsely divided into cases where the set expresses a stable state or property of the world in the eyes of the author (e.g. “England is a close ally of the US” or “video games are a deal breaker”) and cases where the relation statement expresses a change or event (e.g. “Gen. Cedras fled to the Dominican Repub-lic” or “dad left mom”). In many interesting cases, the mention set contains a mix of stative and even-tive relation statements which express a narraeven-tive,
such as “Americais an ally ofSouth Korea” and
“Americasent a destroyer toSouth Korea”.
Defining (Pustejovsky, 1991), extracting
(Aguilar et al., 2014) and determining
relation-ships between events (Hovy et al., 2013) is a
challenging research area. But a better under-standing of states and events would improve future work. For instance, if a summary includes the event “Jolie divorced Pitt”, it does not need
to include the stative relation phrase “Jolie was married to Pitt”. To our knowledge, there is no prior work which considers how fine-grained relations between states and events might be
employed for summarization. MacCartney and
Manning (2009) offer a framework which might serve as a useful starting catalog.
Conclusion
This work defines a problem which lies at the intersection of typically unrelated fields in natu-ral language processing, summarization and rela-tion extracrela-tion. We present a new method which finds large numbers of natural language expres-sions which coherently describe relationships. We also analyze the challenges of the relational sum-marization task, by investigating and describing the inherent heterogeneity of mention sets. Be-cause of this heterogeneity, we argue that future attempts to summarize relationships will likely re-quire a diversity of models and techniques.
Acknowledgments
References
Jacqueline Aguilar, Charley Beller, Paul McNamee, Benjamin Van Durme, Stephanie Strassel, Zhiyi Song, and Joe Ellis. 2014. A comparison of the events and relations across ACE, ERE, TAC-KBP, and FrameNet annotation standards. InProceedings of the Second Workshop on EVENTS: Definition,
Detection, Coreference, and Representation.
Asso-ciation for Computational Linguistics.
Enrique Alfonseca, Daniele Pighin, and Guillermo Garrido. 2013. Heady: News headline abstraction through event pattern clustering. InACL.
James Allan, Jaime Carbonell, George Doddington, Jonathan Yamron, and Yiming Yang. 1998. Topic detection and tracking pilot study: Final report.
Gabor Angeli, Melvin Jose Johnson Premkumar, and Christopher D. Manning. 2015. Leveraging linguis-tic structure for open domain information extraction. InACL.
David Bamman. 2017. Natural language processing for the long tail. Digital Humanities.
Michele Banko, Michael J. Cafarella, Stephen Soder-land, Matthew Broadhead, and Oren Etzioni. 2007. Open information extraction from the web. In IJ-CAI.
Su Lin Blodgett, Lisa Green, and Brendan T. O’Connor. 2016. Demographic dialectal variation in social media: A case study of african-american english. InEMNLP.
Nathanael Chambers and Dan Jurafsky. 2008. Unsu-pervised learning of narrative event chains. In
Pro-ceedings of ACL-08: HLT.
Allison Chaney, Hanna Wallach, Matthew Connelly, and David Blei. 2016. Detecting and characteriz-ing events. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Pro-cessing. Association for Computational Linguistics, Austin, Texas.
James Clarke and Mirella Lapata. 2008. Global in-ference for sentence compression: An integer linear programming approach. Journal of Artificial
Intelli-gence Research31:399–429.
Dipanjan Das and Andr´e F. T. Martins. 2007. A survey on automatic text summarization. Technical report, Literature Survey for the Language and Statistics II course at Carnegie Mellon University.
Luciano Del Corro and Rainer Gemulla. 2013. Clausie: clause-based open information extraction. In Pro-ceedings of the 22nd international conference on
World Wide Web. ACM.
Anthony Fader, Stephen Soderland, and Oren Etzioni. 2011. Identifying relations for open information ex-traction. InEMNLP. Edinburgh, Scotland, UK.
Tobias Falke and Iryna Gurevych. 2017a. Bringing structure into summaries: Crowdsourcing a bench-mark corpus of concept maps. InEMNLP.
Tobias Falke and Iryna Gurevych. 2017b. Graphdo-cexplore: A framework for the experimental com-parison of graph-based document exploration tech-niques. InEMNLP: System Demonstrations.
Tobias Falke and Iryna Gurevych. 2017c. Utilizing automatic predicate-argument analysis for concept map mining. In Proceedings of the 12th Inter-national Conference on Computational Semantics (IWCS).
Katja Filippova, Enrique Alfonseca, Carlos A Col-menares, Lukasz Kaiser, and Oriol Vinyals. 2015. Sentence compression by deletion with LSTMs. In
EMNLP.
Katja Filippova and Yasemin Altun. 2013. Overcom-ing the lack of parallel data in sentence compression.
InEMNLP.
Carsten G¨org, Zhicheng Liu, and John Stasko. 2014. Reflections on the evolution of the jigsaw visual ana-lytics system. Information Visualization13(4):336– 345.
Abram Handler, Matthew J Denny, Hanna Wallach, and Brendan OConnor. 2016. Bag of what? Simple noun phrase extraction for text analysis. Workshop
on NLP + CSS, EMNLP.
Tim Hitchcock, Robert Shoemaker, Clive Emsley, Sharon Howard, and Jamie McLaughlin. 2012. The old bailey proceedings online, 1674-1913. www. oldbaileyonline.org.
Eduard Hovy, Teruko Mitamura, Felisa Verdejo, Jun Araki, and Andrew Philpot. 2013. Events are not simple: Identity, non-identity, and quasi-identity. In
NAACL.
Chris Kedzie, Kathleen McKeown, and Fernando Diaz. 2015. Predicting salient updates for disaster summa-rization. InACL.
Kevin Knight and Daniel Marcu. 2002. Summariza-tion beyond sentence extracSummariza-tion: A probabilistic ap-proach to sentence compression. Artificial
Intelli-gence139(1):91–107.
Chin-Yew Lin and Eduard Hovy. 2000. The auto-mated acquisition of topic signatures for text sum-marization. InProceedings of the 18th conference
on Computational linguistics-Volume 1. Association
for Computational Linguistics.
Christopher Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven Bethard, and David McClosky. 2014. The stanford corenlp natural language pro-cessing toolkit. In Proceedings of 52nd Annual Meeting of the Association for Computational
Lin-guistics: System Demonstrations. Association for
Computational Linguistics, Baltimore, Maryland, pages 55–60. http://www.aclweb.org/anthology/ P14-5010.
Burt L Monroe, Michael P Colaresi, and Kevin M Quinn. 2008. Fightin’ words: Lexical feature se-lection and evaluation for identifying the content of political conflict. Political Analysis16(4):372–403. Ani Nenkova, Kathleen McKeown, et al. 2011.
Au-tomatic summarization. Foundations and Trends in
Information Retrieval5(2–3):103–233.
Jeffrey Nichols, Jalal Mahmud, and Clemens Drews. 2012. Summarizing sporting events using twitter. InIUI.
Joakim Nivre, Marie-Catherine de Marneffe, Filip Gin-ter, Yoav Goldberg, Jan Hajic, Christopher D. Man-ning, Ryan McDonald, Slav Petrov, Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, and Daniel Zeman. 2016. Universal dependencies v1: A multilingual treebank collection. In Nicoletta Calzolari (Con-ference Chair), Khalid Choukri, Thierry Declerck, Sara Goggi, Marko Grobelnik, Bente Maegaard, Joseph Mariani, Helene Mazo, Asuncion Moreno, Jan Odijk, and Stelios Piperidis, editors, Proceed-ings of the Tenth International Conference on
Lan-guage Resources and Evaluation (LREC 2016).
Eu-ropean Language Resources Association (ELRA), Paris, France.
Fabian Pedregosa, Ga¨el Varoquaux, Alexandre Gram-fort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexan-dre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and ´Edouard Duchesnay. 2011. Scikit-learn: Machine learning in python. J. Mach.
Learn. Res.12:2825–2830.
James Pustejovsky. 1991. The syntax of event struc-ture. Cognition41(1):47–81.
Sebastian Riedel, Limin Yao, Benjamin M. Marlin, and Andrew McCallum. 2013. Relation extraction with matrix factorization and universal schemas. In
NAACL.
David Robinson. 2016.Text analysis of trump’s tweets confirms he writes only the (angrier) android half.
http://varianceexplained.org/r/trump-tweets/. Evan Sandhaus. 2008. The New York Times
An-notated Corpus. Linguistic Data Consortium
LDC2008T19.
Sebastian Schuster and Christopher D. Manning. 2016. Enhanced english universal dependencies: An im-proved representation for natural language under-standing tasks. InLREC.
John Sprouse and Carson Sch¨utze. 2014. Research Methods in Linguistics, Cambridge University Press, Cambridge, UK, chapter Judgment Data.
Tim Squirrell. 2017. Linguistic data analysis of 3 billion Reddit comments shows the alt-right is getting stronger. https://qz.com/1056319/ what-is-the-alt-right.
Gabriel Stanovsky and Ido Dagan. 2016. Creating a large benchmark for open information extraction. In
EMNLP. Austin, Texas.
Xavier Tannier. 2016. NLP-driven data journalism: Time-aware mining and visualization of interna-tional alliances. InProceedings of the 2016 IJCAI Workshop on Natural Language Processing meets Journalism.
Nikos Voskarides, Edgar Meij, Manos Tsagkias, Maarten De Rijke, and Wouter Weerkamp. 2015. Learning to explain entity relationships in knowl-edge graphs. InACL.
Brandon Wright, Jason Payne, Matthew Steckman, and Scott Stevson. 2009. Palantir: A visualization plat-form for real-world analysis. In Visual Analytics Science and Technology, 2009. VAST 2009. IEEE
Symposium on. IEEE, pages 249–250.
Sheng Zhang, Rachel Rudinger, and Benjamin Van Durme. 2017. An Evaluation of PredPatt and Open IE via Stage 1 Semantic Role Labeling. InThe Pro-ceedings of the 12th International Conference on
Computational Semantics (IWCS).