An implementation
Séverin Lemaignan
a,
b,∗
,
Mathieu Warnier
a,
E.
Akin Sisbot
a,
Aurélie Clodic
a,
Rachid Alami
aaLAAS-CNRS, Univ. de Toulouse, CNRS, 7 avenue du Colonel Roche, F-31400 Toulouse, France bCentre for Robotics and Neural Systems, Plymouth University, Plymouth, United Kingdom
a
r
t
i
c
l
e
i
n
f
o
a
b
s
t
r
a
c
t
Article history:
Received in revised form 4 July 2016 Accepted 9 July 2016
Available online 26 July 2016
Keywords:
Human–robot interaction Cognitive robotics Perspective taking Cognitive architecture
Knowledge representation and reasoning
Human–Robot Interaction challenges Artificial Intelligence in many regards: dynamic, partially unknown environments that were not originally designed for robots; a broad varietyofsituationswithrichsemanticstounderstandandinterpret;physicalinteractions with humans that requires fine, low-latency yet socially acceptable control strategies; naturalandmulti-modalcommunicationwhichmandatescommon-senseknowledgeand the representation of possibly divergent mental models. This article is an attempt to characterise thesechallengesand to exhibita set ofkey decisionalissues that need to beaddressedforacognitiverobottosuccessfullysharespaceandtaskswithahuman. We identify first the needed individual and collaborative cognitive skills: geometric reasoning andsituationassessmentbasedonperspective-takingand affordanceanalysis; acquisition and representation of knowledge models for multiple agents (humans and robots, with their specificities); situated, natural and multi-modal dialogue; human-awaretask planning;human–robotjointtask achievement.The articlediscusses eachof these abilities, presents working implementations, and shows how they combine in a coherent and original deliberative architecture for human–robot interaction. Supported byexperimental results,weeventuallyshow howexplicitknowledge management,both symbolicand geometric, provesto beinstrumental to richer and morenaturalhuman– robot interactions by pushing for pervasive, human-level semantics within the robot’s deliberativesystem.
©2017TheAuthors.PublishedbyElsevierB.V.Thisisanopenaccessarticleunderthe CCBYlicense(http://creativecommons.org/licenses/by/4.0/).
1. Thechallengeofhuman–robotinteraction
1.1. Thehuman–robotinteractioncontext
Human–RobotInteraction(HRI)representsachallengeforArtificialIntelligence(AI).Itlaysatthecrossroadofmany sub-domainsofAIand, ineffect,itcallsfortheirintegration:modellinghumansandhumancognition;acquiring,representing, manipulatingina tractable wayabstractknowledgeatthehuman level;reasoningon thisknowledgetomake decisions; eventually instantiating those decisions into physical actions both legible to andin coordination with humans. Many AI techniquesaremandated,fromvisualprocessingtosymbolicreasoning,fromtaskplanningtotheoryofmindbuilding,from reactivecontroltoactionrecognitionandlearning.
*
Corresponding author at: Plymouth University, Portland Square A216, PL48AA Plymouth, United Kingdom.E-mail addresses:[email protected], [email protected](S. Lemaignan), [email protected](M. Warnier), [email protected](E.A. Sisbot), [email protected](A. Clodic), [email protected](R. Alami).
http://dx.doi.org/10.1016/j.artint.2016.07.002
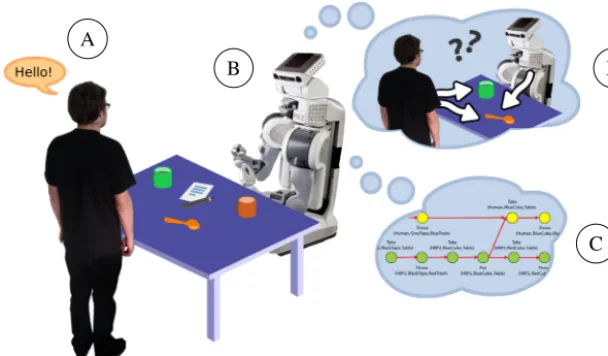
Fig. 1.The robot reasons and acts in domestic interaction scenarios. The sources of information are multi-modal dialogue (A)and perspective-aware mon-itoring of the environment and human activity (B). The robot must adapt on-line its behaviours by merging computed plans (C)with reactive control. The robot explicitly reasons on the fact that it is (or is not) observed by the human. Reasoning and planning take place at symbolic as well as geometric level and take into account agents beliefs, perspectives and capabilities (D)as estimated by the robot.
We donot claim to address here the issueas a whole. This articleattempts however to organise it intoa coherent challengeforArtificialIntelligence,andtoexplainandillustratesomeofthepathsthatwehaveinvestigatedonourrobots, thatresultinasetofdeliberative,knowledge-oriented,softwarecomponentsdesignedforhuman–robotinteraction.
Wefocusonaspecificclassofinteractions:human–robotcollaborativetaskachievement [1]supportedbymulti-modal andsituatedcommunication.
Fig. 1
illustratesthiscontext:thehumanandtherobotshareacommonspaceandexchange informationthrough multiplemodalities(wespecificallyconsiderverbal communication,deictic gesturesandsocialgaze), and the robot is expectedto achieve interactive object manipulation, fetch andcarry tasks andother similar chores by taking into account, at every stage, the intentions, beliefs, perspectives, skills of its human partner. Namely, the robot mustbeabletorecognise,understandandparticipateincommunicationsituations,bothexplicit(e.g.thehumanaddresses verbally therobot)andimplicit(e.g.thehumanpointstoan object);therobot mustbeabletotake partinjointactions, bothpro-actively(byplanningandproposingresultingplanstothehuman)andreactively;therobotmustbeabletomove andactinasafe,efficientandlegibleway,takingintoaccountsocialruleslikeproxemics.Thesethreechallenges,communication,jointaction,human-awareexecution,structuretheresearchinhuman–robot inter-action.Theycanbeunderstoodintermsofcognitiveskillsthattheymandate.Jointaction,forinstance,buildsfrom:
•
ajointgoal,whichhasbeenpreviouslyestablishedandagreedupon(typicallythroughdialogue);•
aphysicalenvironment,estimatedthroughtherobot’sexteroceptivesensing capabilities,andaugmentedbyinferences drawnfrompreviousobservations;•
a beliefstate thatincludes apriori common-senseknowledgeandmentalmodels ofeachofthe agentsinvolved(the robotanditshumanpartners).Therobotcontroller(withthehelpofataskplanner)decideswhatactiontoexecutenext[2],andwhoshouldperformit, fromtherobotorthehuman(orbothincaseofacollaborativeactionsuchasahandover[3,4]),howitshouldachievedand whatsignalsshouldbesensedand/orproducedbytherobottofacilitatehuman–robotjointaction[5–8].Itfinallycontrols andmonitorsitsexecution.Theoperationcontinuesuntilthegoalisachieved,isdeclaredunachievableorisabandonedby thehuman[9].
Thistranslatesintoseveraldecisional,planning,representationskillsthatneedtobeavailabletotherobot[10].Itmust be able:1 torepresentandmanipulatesymbolicbeliefstates,2 toacquireandkeepthem up-to-datewithrespecttothe state oftheworldandthetaskathand,3 tobuildanditerativelyrefineshared(human–robot)plans,4 to instantiateand executetheactionsithastoperform,andconversely,tomonitorthoseachievedbyitshumanpartner.
Besides,suchabilitiesshouldbedesignedandimplementedinatask-independentmanner,andshouldprovidesufficient levels ofparametrisation,so thattheyadapttovarious environments,differenttasksandvariablelevelsofengagementof therobot,rangingfromteammatebehaviourtoassistantorpro-activehelper.
Thesearethechallengesthatwewilldiscussinthisarticle.
1.2. Contributionandarticleoverview
aswellasformulti-disciplinarystudies[15–20].
Theremainingofthearticledetailsthisroboticarchitecture.Weorganisethisdiscussioninfivesections.Thenextsection introduces thearchitectureasawhole,aswell astheknowledgemodelthatwe havedevelopedforourrobots.Section3 discusseseachofthecognitivecomponentsofthearchitecture.Section4presentstwostudiesthatillustrateinapractical waywhatcanbe currentlyachievedwithourrobots.The Sections5and6finallysummariseourmaincontributions and restatethekeychallengesthathuman–robotinteractionbringstoArtificialIntelligence.
2. Deliberativearchitectureandknowledgemodel
2.1. Buildingahuman-awaredeliberativelayer
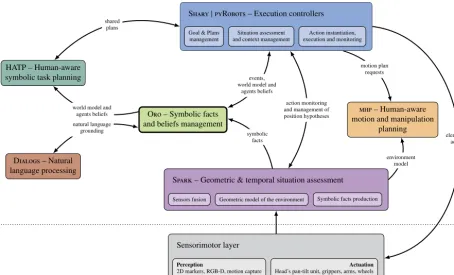
Articulatingmultipleindependentsoftwaremodulesinonecoherentroboticarchitectureisnotonlyatechnicalchallenge, butalsoadesignandarchitecturalchallenge.Inparticular,properlymanagingtherichsemanticsofnaturalinteractionswith humans raises a rangeof issues.Our basicassumption andguidingprinciple is that human-levelinteraction is easierto achieveiftherobotitselfreliesinternallyonhuman-levelsemantics.Weimplementthisprinciplebyextensivelyrelyingon explicitknowledgerepresentationandmanipulation: softwarecomponentscommunicatewitheachotherusingfirst-order logicstatementsorganisedintoontologiesandwhosesemanticsareclosetotheonesmanipulatedbyhumans.
Fig. 2 gives an overview of our architecture. An active knowledge base (Oro), conveniently thought as a semantic blackboard, connectsmostofthemodules:thegeometricreasoningmodule (Spark) producesatrelatively highfrequency symbolicassertionsdescribingthestateoftherobotenvironmentanditsevolutionovertime.Theselogicalstatementsare storedintheknowledgebase, andqueried back,whennecessary,by thelanguageprocessingmodule(Dialogs),the sym-bolictaskplanner(HATP)andtheexecutioncontroller(SharyorpyRobots).Theoutputofthelanguageprocessingmodule andtheactivitiesmanagedbytherobotcontrollerarestoredbackassymbolicstatementsaswell.
Forinstance,a booklaying on a furnituremightbe pickedup by Spark andrepresented insymbolictermsasBOOK1 type Book, BOOK1 isOn TABLE.ThesesymbolicstatementsarestoredintheknowledgebaseOroandmadeavailabletothe othercognitivemodules.Later,therobotmightprocessasentencelike“givemeanotherbook”.TheDialogsmodulewould thenquerytheknowledgebase:find(?obj type Book, ?obj differentFrom BOOK1),andwritebackassertionslikeHUMAN desires GIVE_ACTION45, GIVE_ACTION45 actsOn BOOK2toOro.ThiswouldinturntriggertheexecutioncontrollerSharyto preparetoact.ItwouldfirstcalltheHATPplanner.Theplannerusestheknowledgebasetoinitialisetheplanningdomain (e.g.find(BOOK2 isAt ?location)),andreturnsafullsymbolicplantotheexecutioncontroller.Finally,thecontrollerwould
executetheplanandmonitoritsachievement,bothforitselfandforthehuman.Wepresentcompleteexamplesofsimilar interactionsinSection4.
Ourarchitecturehasnotbeendesignedtoreplicateorprovideaplausiblemodelofhumancognition,andinthissense, wedistinguishourselvesfromresearchoncognitivearchitectures.Instead,ourmaindesignprincipleistonurturethe deci-sionalcomponentsoftherobotwithmodelsofhumanbehaviourandhumanpreferencesinordertodevelop aneffective artificial cognitionforarobotthatisabletoserveandinteractseamlesslywithhumans.Inthissense,itsharesitsobjectives with[21,22].
Athighlevel,thisarchitecturereliesonthesameprinciplesasanumberofknownroboticlayeredarchitectures[23–26]. However, themainpointforuswasto refineandstudyindetailtheinternalsofthedeliberative layer.Inourmodel,we suggest that the interactions betweencomponents within thisdeliberative level have to be essentially bidirectional. We alsosuggestnot tointroduceanysub-layersofabstractionamongst thesedeliberative components.1 Thenaturallanguage processingcomponentillustratesthisstructure: insteadofbeingan independentinputmodality whoseoutputs wouldbe unidirectionallyfedto“higher”decisionalcomponents,itlivesinthedeliberativespaceatthesamelevelasother delibera-tivecomponents,andmakeuseoftheknowledgebaseinabidirectionalmanner,tointerpret,disambiguatenaturallanguage, andeventuallystorenewly producedinterpretations(naturallanguageprocessingisdiscussedinSection3.3).Another
Fig. 2.Overview of the architecture. A deliberative layer, composed of six main modules, interacts with a low-level sensori-motor layer. Knowledge is centrally managed in an active semantic blackboard, pictured above with a thick border. The links between components depicted on the figure underline the central role of the knowledge base: many of the data streams are actually symbolic statements exchanged through this semantic blackboard.
ample istheintricate relationbetweenhigh-levelsymbolicplanningandgeometricplanningtodealwithaffordancesand humanpreferences.
Ourarchitecture relatesto Beliefs,Desires,Intentions(BDI) architectures.Asputby Woolridge[27],BDI architecturesare primarily focusedonpracticalreasoning,i.e.theprocessofdeciding,stepby step,whichactiontoperformtoreachagoal. The managementoftheinteraction betweenknowledge(the beliefs) andtaskandplan representationandexecution(the desiresandtheintentions)iscentral,andaimsatselectingateachstepthebestsub-goal.Itbecomesthenanintentionthat therobotcommitsto.Asforanycognitivesystem,thisfundamentalinteractionbetweenknowledgeandactionsiscentralto ourapproachaswell,andtypicallyinvolvesthedialoguemoduletoacquire desiresfromtheotheragents,andtheplanner andtheexecutioncontrollertofirstdecidetotakeintoaccount(ornot)anincomingdesireasagoal,andthentogenerate andmanageintentionsfromthesegoalsthroughthesymbolictaskplanner.
We extendupon BDIarchitecturesby runningother backgrounddeliberative tasks,withoutthembeingexplicitly trig-gered by desires in the BDI sense. The main ones include situation assessment, action monitoring and processing of non-imperative speech(including performativedialogue thatcanpossibly changetheinternalstate oftherobot,butdoes notleaddirectlytothecreationofdesires,likeassertionofnewfactsorquestionanswering).
2.2. Knowledgemodel
In our architecture, knowledge manipulation relies on a central server (the Oroserver [28], Fig. 5 top)which stores knowledge asitisproduced byeachoftheother deliberativecomponents(the clients).Itexposesa
json
-basedRPCAPI toquerytheknowledgebase[29].WerepresentknowledgeasRDFtriplesintheOWLsub-language.2Everytimetriplesare addedorremoved fromtheknowledgebase, aDescriptionLogicsreasoner(Pellet[30]) classifiesthewholeontologyand insertsallpossibleinferredtriples.TheclientsoftheOroserverareinchargeofmanagingthemselvestheknowledge(when toadd,whentoupdate,whentoretractknowledge)asnometa-semanticsarecarriedoverthatlettheservermanageitself thesedynamics.3This architecture design(acentral knowledge basethat essentially appearsasa passive componenttothe restofthe system–eventhough itactually activelyprocessestheknowledgepool inthebackgroundtoperforminferences)departs
2 http://www.w3.org/TR/owl2-overview/.
bolicfacts when needed, we havean explicit approachwhere we greedilycompute andassertsymbolicstatements (like spatial relations betweenobjects,see Section 3.2). Forinstance,whenever aclient queries KnowRobtoknow ifOBJECT1 isOn OBJECT2,KnowRobcalls ageometricreasonerto evaluateifthisspecific spatialrelationholds atthat pointintime.
Withourapproach, spatial relationsare insteadcomputedandasserted apriori bya dedicatedprocess that continuously runsinthebackground.Thisdesignchoicetradesscalabilityforexplicitreasoning:atanytime,thefullbeliefstateismade explicit,andthereforeprovidesthereasonerwiththelargestpossibleinferencedomain.Thisisofspecialimportanceforan
event-basedarchitecturelikeours(seeSection3.5),whereanexplicitandcomprehensivebeliefstateisrequiredtonotmiss events.
2.2.1. RDFasaformalismforsemantics
TheOroserverreliesonDescriptionLogics(OWL) torepresentandmanipulateknowledge.RelyingonRDFtriples and DescriptionLogicshasadvantagessuchasgoodunderstandingofitstrades-off,thankstobeingwidespreadinthesemantic Webcommunity;theavailabilityofmaturelibrariestomanipulatetheontology;interoperabilitywithseveralmajoron-line knowledgebases(OpenCyc,WordNet,DBPediaorRoboEarth[34] forexamples);open-worldreasoning(whichenablesus torepresentthatsomefactsmightbeunknowntotherobot);andtheformalguaranteeofdecidability(itisalwayspossible toclassifyaDescriptionLogicsontology).
Italsohasrestrictions,bothbasic(thesuitability ofDescription Logicswhenreasoningon–typicallynon-monotonic – commonsense knowledge has been questioned) and practical:RDF triples imply binary predicates, which constrains the expressiveness ofthe systemor leads to inconvenient reifications. Alternatives havebeen proposed (like KnowRob [33]) that interleave RDF withmore expressive logic languages like Prologwith howeverother limitations,like closed-world reasoning.
Classificationperformanceisanotherissue: inourexperience,anontology sizedfora typicalstudy(about100classes and200instances),classificationtakesaround100ms,whichmayintroduceperceptibledelaysduringinteractions.Besides, the performances are difficult to predict: the insertion of seemingly simple statements may change abruptlythe logical complexityoftheknowledgemodelandleadtoanoticeabledegradationofclassificationtime.
Thisknowledgemodelalsolargelyexcludesrepresentationofcontinuous phenomena(liketime)oruncertain phenom-ena. When required (for instance for action recognition), these are managed within dedicated components (like Spark, discussedinSection3.2),andarenotrepresentedintheknowledgebase.
Alternativeformalismshavebeensuccessfullyinvestigatedinroboticstoaddresssomeoftheserestrictions.Besidesthe Prolog/OWLcombinationrelieduponby KnowRob,AnswerSetProgramminghasbeenusedinrobotics[35,36] forinstance tobettersupportsnon-monotonicreasoning.Wehavealsopointedin[37]howmodallogicsliketheepistemiclogicscould be relevant to the particular field of social human–robot interaction as they allow for the representation of alternative mentalmodels.First-orderlogicandOWLontologieshavehoweverprovedsofarasimple,effectiveandsufficientsymbolic frameworkforourexperimentalapplications.
Incidentally,andbecauseontologiesandRDFstatementsremainconceptuallysimple(comparedtofulllogicallanguages like Prolog or modal logics), their adoption has also effectively helped to grow awareness amongst colleagues on the significanceofthe“semanticlevel”whendevelopingnewcomponentsfortherobot.
2.2.2. TheOpenRobotsontology
Aspreviously mentioned,the logicalstatementsexchangedbetweenthedeliberative componentsare organisedwithin the Oroknowledgebaseinto an ontology.The conceptualisation (i.e.the systemofconcepts orTBox) ofthis ontologyis staticallyasserted,4whiletheinstantiation(theABox)oftheontologyisgenerallydynamicallyassertedatrun-time,bythe othercognitivecomponents.
TheOpenRobotscommon-senseontologyrepresentsthestaticallyassertedpartoftheontology.Ithasbeendesignedfrom two requirements:being practical(i.e. coveringour experimental needs)andconformingasmuch aspossibleto existing standards(specifically,theOpenCycupperontology[38]).
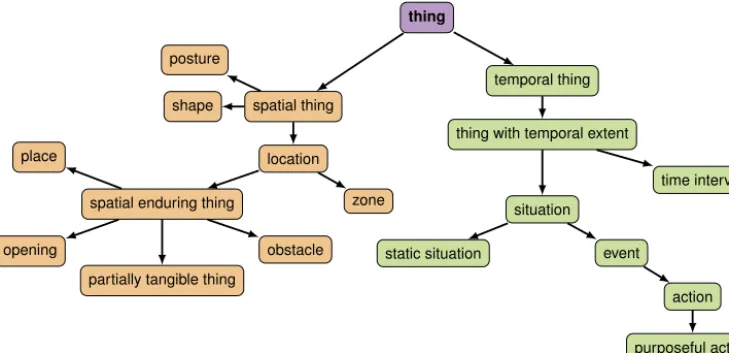
Fig. 3.The upper part of theOrocommon-sense conceptualisation (TBox). These concepts are shared with theOpenCycupper-ontology. They relate to each
other through ‘is-a’ subsumption relations.
This leads toa bidirectionaldesignprocess:frombottom-up regardingthe choicesofconcepts tomodel,top-down re-gardingtheupperpartoftheconceptualisation.ThisupperpartoftheontologyispicturedinFig. 3.Alltheclassesvisible inthisfigurebelongtotheOpenCycnamespace.
Aligning the upper part of the ontology on OpenCyc (as done by other knowledge representation systems, like KnowRob[33]orPEISK&R[39])hasmultipleadvantages.Firstthedesignofthispartoftheontologyisgenerallydifficult: it pertainsto abstractconcepts whosemutualrelations comesto philosophicaldebates. Theupper taxonomyofOpenCyc representsarelativeconsensus,atleastwithinthesemanticWebcommunity.Then,becauseitisawellestablishedproject withnumerouslinksto otheron-linedatabases (likeWikipediaorWordNet), thereuseofkey OpenCycconceptsensures that theknowledgestoredbytherobotcanbesharedorextendedwithwell-definedsemantics.TheconceptofObject isa goodexampleasitrepresentsatypicalcaseofambiguousmeaning:ineverydayconversation,anobjectisarelativelysmall physicalthing,thatcanbeusuallymanipulated.Ahumanisnotusuallyconsideredasanobject.OpenCychoweverprecisely definesanobjectasanythingatleastpartiallytangible.Thisincludesobviouslythehumans,andactuallymanyotherentities thatwouldnotbecommonlysaidtobeobjects(theEarthforinstance).Byrelyingonwell-definedandstandardsemantics toexchangeinformationbetweenartificialsystems,weavoidsemanticambiguities.Astherobotinteractswithhumans,we musthoweveraddressthediscrepancybetweenOpenCycconcepts andhumanterminology.Inthesesituations,we manu-allylabeltheOpenCycconceptswithappropriatehumannames:forinstance,theOpenRobotsOntologyassociatesthelabel “object”totheconceptcyc:Artifactinsteadoftheconceptcyc:PartiallyTangible.Theselabelsareusedinpriority duringthegroundingofverbalinteractions.
Fig. 3 also illustrates the fundamental disjunction in the Oro modelbetween temporal and spatial entities (formally,
(TemporalThing
SpatialThing)
I= ∅
,withI
theinterpretationofourmodel).Onthissamefigure,theclassPurposefulActionrepresentsthesupersetofalltheactions thatare purposefully per-formedbytherobot(oranotheragent).Actualactions(i.e.subclassesofPurposefulActionlikeGiveorLookAt)arenot initially asserted inthe common-senseontology.They areinstead addedat run-timeby theexecutioncontroller (in link withthe symbolictaskplanner)andthe naturallanguage processor basedon whatthe robotis actuallyable toperform and/ortointerpretinthecurrentcontext(i.e.thecurrentrobotconfigurationandtheactionsrequiredbythescenario).The setofactionsthattherobotcaninterpretusuallycloselyresembletheplanningdomaininuse(i.e.thesetoftasksknown tothesymbolictaskplanner,withtheircorrespondingpre- andpost-conditions).
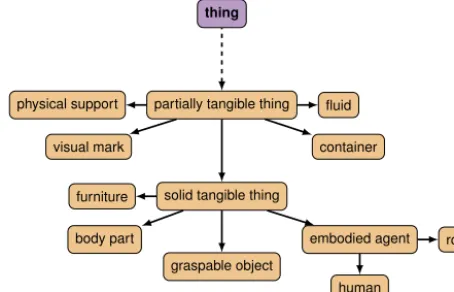
The tree5 in Fig. 3 is not equally developed in every directions. For example, the subclasses of Partially-TangibleThing(i.e.whatwecommonlycallobjects) areshownin
Fig. 4
.Our‘bottom-up”designprocessoftheontology is apparent on thisfigure: only the subclasses relevantto the context ofservice roboticsin an human-like environment areasserted:Forperformancereasonsaswellasclarity,wehavedecidedagainstanextendedconceptualcoverageofwhat “partially tangiblethings”mightbe.We insteadopportunisticallyextendthecommon-senseknowledgewhenrequiredby studies.Lastly,the Orocommon-senseontology containsseveralrulesandclassexpressionsthat encodenon-trivialinferences. ThedefinitionofBottleasfoundintheOroontologyisatypicalexample:
Bottle
≡
Container
∧
GraspableObject
∧
hasShape
∈
CylinderShape
I∧
hasMainDimension
∈ [
0.
1,
0.
3]
Fig. 4.Subclasses ofPartiallyTangibleThingexplicitly stated in the OpenRobots Ontology.
Ifahumaninformstherobotthatagivenobjectisindeedabottle,therobotcanconsequentlyderivemoreinformation ontheobject.Conversely,ifthehumanaffirmsthat“acarisabottle”, thereasonermaydetectlogicalcontradictions(like inconsistentsizes)andrejecttheassertion.TheDialogsmodulereliesonsuchlogicalconsistencycheckswhenprocessing naturallanguageinputs,bothtoensurethattheverbalinputhasbeencorrectlyacquiredandparsed,andalsotoverifythat whatthehumansaysislogicallyconsistent.
WefurtherdiscussthestrengthsandweaknessesofthisknowledgeframeworkinSection5.4.
2.3. Symbolgrounding
Grounding (also calledanchoring whenspecifically referring to thebuilding oflinksbetweenpercepts andphysical ob-jects [40]) is the taskconsisting in buildingand maintaining a bi-directional link betweensub-symbolic representations (sensors data,low-level actuation) and symbolicrepresentations that can be manipulated and reasoned about[11]. This representsanimportantcognitiveskill,inparticularinthehuman–robotinteractioncontext:inthissituation,thelinkthat the robothas toestablishbetweenpercepts andsymbolsmustmap aswell aspossibleto thehuman representationsin ordertoeffectivelysupportcommunication.
Symbolgrounding connectshencethe knowledge model tothe perception andactuation capabilitiesofthe robot. The different components that we have mentioned so far exhibit grounding mechanisms: geometric reasoning and dialogue processingmodules constantlybuild andpushnewsymboliccontents abouttheworld tothe knowledgebase.We detail thisprocessinthenextsections.
3. Cognitiveskills
The previous section has introduced the integration model of our architecture, as well asthe associated knowledge model.Wediscussinthissectioneachofitsbuildingblocks.Theyarepicturedin
Fig. 2
,alongwiththeirconnectionstothe otherscomponents.We call cognitiveskills the deliberative behaviours that are 1 stateful, i.e.keeping trackof previous statesis typically neededforthecomponenttoperformappropriately;2amodalinthattheskillisnotinherentlyboundtoaspecific percep-tionoractuationmodality; 3 manipulateexplicitsemantics,typicallyby themeanofsymbolicreasoning;4 operate atthe
human-level,i.e.arelegibletothehumans,typicallybyactingatsimilarlevelsofabstraction.
Wepresentfirstthemain internalcognitivecapabilities, implementedintheOroknowledgebaseitself,andthen dis-cusssuccessivelythesituationassessmentmoduleSpark,thedialogueprocessorDialogs,thesymbolictaskplannerHATP, andfinallythemain featuresofourexecutioncontrollers SharyandpyRobots.Notethatgreater detailsoneach ofthese modulescanbefoundintheirrespectivepublications(thecorrespondingreferencesareprovidedhereafter).
3.1. Internalcognitiveskills
We call internalthose cognitive capabilitiesthat are tightly bound to theknowledge model,and henceimplemented directlywithintheOroserver.Wepresentherethreeofthem:reasoning,theoryofmindmodellingandour(naive)approach tomemorymanagement.
3.1.1. Symbolicreasoning
Besides, Oroserverimplements severalalgorithms(presented in[17]) toidentifysimilarities anddifferencesbetween concepts(classesorinstances):theCommonAncestorsalgorithm,usefultodeterminethemostspecificclass(es)thatinclude a given set of individuals; the FirstDifferentAncestors algorithm that returns what can be intuitively understood as the most generic typesthat differentiate two concepts;andclarification anddiscriminationalgorithms that play a key role in the processofinteractivegroundingofthesemantics ofconcepts(wediscussthisprocessinsection 3.3).Clarificationand discrimination algorithms are basedon whatwe call descriptors,i.e.propertiesof individuals, eitherstatically assertedin the common-sense ontology,acquired by the robot through perception or pro-active questioning ofthe human partner, orderived fromotherreasoningalgorithms liketheCommonAncestorsandDifferentAncestors.Thediscriminationalgorithm consiststheninlookingfordiscriminants,i.e.descriptorsthatallowamaximumdiscriminationamongasetofindividuals.
3.1.2. Theoryofmind
TheoryofMind(originallydefinedin[41])isthecognitiveabilitythatallowsasubjecttorepresentthementalstateof another agent,possiblyincludingknowledge thatcontradicts thesubject’sownmodel:forexample,abook canbe atthe sametimevisibleforagentA,andnotvisibleforagentB.Childrendevelopthisskill,whichisessentialtounderstandothers’ perspectivesduringinteractions,aroundtheageofthree[42].
From thepointofview ofinteractiverobotics,itsupposestherobot abilitytobuild,store andretrieveseparatemodels of thebeliefs ofthe humansit interactswith. Ourknowledge baseimplements such amechanism [28]: when therobot detects that anewhumanhasappeared,it initialisesanewindependentknowledgemodel (anontology)forthishuman agent.Alltheontologiesthatarecreatedsharethesamecommon-senseknowledge,butrelyontheestimationoftherobot ofeach agent’sperspectivefortheir actualinstantiation.Forexample,therobot can(geometrically)compute that agiven book is inits own field of view, but not in the human one (the detail ofthis computation, called perspectivetaking, is discussed inthe next section).The robot updatesaccordinglythetwo knowledge models itmaintains: the robotmodel is updated withthe fact BOOK isVisible true, whilethe human modelis updated withBOOK isVisible false. These
two logicalstatementsare simultaneouslyasserted,yetcontradict whentakentogether.Sincethetwo knowledgemodels are howeverimplementedastwoindependentontologies,thecontradictiondoesnotactually appearandboththemodels remainlogicallyconsistent.
Oneclassicalapplicationofthiscognitiveskillistheso-calledFalse-Belief experiment(alsoknownastheSallyandAnne
experiment,introducedby[43]fromanoriginalexperimentalsettingby[44]):achildisaskedtowatchascenewheretwo people,AandB,manipulateobjects.Atsomepoint,AleavesandBhidesawayoneobject.WhenAcomesback,weaskthe child“wheredoyouthinkAwilllookfortheobject?”.Beforeacquiringatheoryofmind,childrenarenotabletoseparate their own(true)modeloftheworld(wherethey knowthattheobjectwashidden) fromthemodelofA,whichcontains
falsebeliefsontheworld(AstillthinkstheobjectisatitsoriginalpositionsincehedidnotseeBhidingitinanewplace). Relyingon theseseparateknowledge modelsintheknowledge base,we havebeenableto replicatethisexperiencewith ourrobots[45],inamannersimilartoBreazealetal.
[46]
.3.1.3. Workingmemory
Memoryhasbeenstudiedatlengthinthecognitive psychologyandneuro-psychologycommunities:the ideaof short-termandlong-termmemoryisduetoAtkinsonandShiffrin[47];Anderson[48] proposestosplit memoryintodeclarative
(explicit)andprocedural(implicit)memories;Tulving[49]organisestheconceptsofprocedural,semanticandepisodic mem-ories intoahierarchy.Short-term memoryiseventually refinedwiththeconcept ofworkingmemoryby Baddeley[50].In the field of cognitive architectures,the Soararchitecture [51] isone of those that tryto reproduce a human-like mem-ory organisation. TheGLAIR cognitive architecture [52]also hasaconcept oflongterm/shorttermandepisodic/semantic memories.
Itisworthemphasisingthatwhilememoryiscommonlyassociatedwiththeprocessofforgettingfactsafteravariable amount of time, it actually covers more mechanisms that are relevant to robotics, like priming (concept pre-activation triggeredbyaspecificcontext[53])orreinforcementlearning.
TheOroserverfeatures amechanismtomimiconlyminimalisticformsofmemoryfamilies.Whennewstatementsare insertedintheknowledgebase,amemoryprofileisattachedtothem.Threesuchprofilesarepredefined:shortterm,episodic
andlongterm.Theyarecurrentlyattachedtodifferentlifetimeforthestatements(respectively10seconds,5minutesand notimelimit).Afterthisduration,thestatementsareautomaticallyremoved.
Thisapproachislimited. Inparticular,episodicmemoryshouldprimarilyrefertothesemantics ofthestatements(that isexpectedtoberelatedtoanevent)andnottoaspecificlifespan.
We relyhoweveronthismechanismin certaincases:some moduleslike thenaturallanguage processorusetheshort term memoryprofile to markconcepts that are currentlymanipulated by the robot as activeconcepts: if a human asks the robot “Giveme all red objects”, the human, the Give action, and every red objects that are found are marked as active concepts by inserting statements such as HUMAN type ActiveConcept in the short-term memory (which can be
considered, in this case, to be a workingmemory). Likewise, recentlyseen or updated geometric entities are flagged as
Fig. 5.Functional overview of the geometric situation assessment moduleSpark.Sparkcomputes symbolic relationships between objects and agents, and
exports them to the knowledge base. (For interpretation of the references to colour in this figure legend, the reader is referred to the web version of this article.)
Fig. 6.Test setup involving videotapes boxes that are manipulated, with other objects acting as supports or containers. After identification and localisation of the set of objects (using fiducial markers) and acquisition of the position and posture of the human partner (using skeleton tracking), the robot is able to compute that two tapes only are reachable by itself: the black and grey (in the 3D model) tapes. The third tape and the container box are only reachable by the human. This physical situation is transformed bySparkinto the set of facts presented in Table 1.
3.2. Acquiringandanchoringknowledgeinthephysicalworld
Anchoringperceptionsinasymbolicmodelrequiresperceptionabilitiesandtheirsymbolicinterpretation.Wecall phys-icalsituationassessmentthecognitiveskillthatarobotexhibitswhenitassessesthenatureandcontentofitssurroundings andmonitorsitsevolution.
Numerousapproachesexist,likeamodal(inthesenseofmodality-independent)proxies[54],groundedamodal represen-tations[55],semanticmaps[56–58]oraffordance-basedplanningandobjectclassification[59,60].
WerelyonadedicatedgeometricandtemporalreasoningmodulecalledSpark(SPAtialReasoning&Knowledge,presented in[61]).Itactsasasituationassessmentreasonerthat generatessymbolicknowledgefromthegeometryofthe environ-mentwithrespectto relationsbetweenobjects,robotsandhumans (Figs. 5 and 6),alsotakingintoaccountthe different perspectivethateachagenthasontheenvironment.Sparkembedsanamodal(asdefinedbyMavridisandRoyin[55]:the differentperceptualmodalitiesareabstractedawayintoablendedspatialmodel)geometricmodeloftheenvironmentthat servesbothasbasisforthefusionoftheperceptionmodalitiesandasbridgewiththesymboliclayer.Thisgeometricmodel isbuiltfrom3DCADmodelsoftheobjects,furnituresandrobots,andfullbody,riggedmodelsofhumans(Fig. 6(b)).Itis updatedatrun-timebytherobot’ssensors(usually,acombinationofvision-basedtrackingof2Dfiducialmarkersto iden-tifyandlocaliseobjects,andKinect-basedskeletontrackingofhumans,optionallyassistedbymotioncapturetoaccurately tracktheheadmotion,whichisrequiredtocomputewhatthehumanislookingat).
[image:9.561.40.502.230.433.2]Table 1
Symbolic facts computed from the situation depicted in Fig. 6. Note how reachability differs for the two agents. Robot’s beliefs about itself (robot’s model)
PINK_BOX isReachable false WHITE_TAPE isReachable false BLACK_TAPE isReachable true GREY_TAPE isReachable true WHITE_TAPE isVisible true BLACK_TAPE isVisible true GREY_TAPE isVisible true WHITE_TAPE isOn TABLE BLACK_TAPE isOn TABLE GREY_TAPE isOn TABLE
Robot’s beliefs about the human (human’s model) PINK_BOX isReachable true
WHITE_TAPE isReachable true BLACK_TAPE isReachable false GREY_TAPE isReachable false WHITE_TAPE isVisible true BLACK_TAPE isVisible true GREY_TAPE isVisible true WHITE_TAPE isOn TABLE BLACK_TAPE isOn TABLE GREY_TAPE isOn TABLE
knowledge base.This approach may raise scalabilityconcerns (we did not however observed performance issues in our constrained scenarios,involvingtypically about10objects andtwoagents) aswell asprevent reasoningonthe situation history,butsimplifiesthemanagementofthedynamicsoftheknowledge(WhendoIdiscardoutdatedknowledge?WhendoI updateit?).Sinceitisequivalenttoaresetofthereasonerdomain,italsoessentiallynullifiesissueslinkedtonon-monotonic reasoningintheknowledgebase(see[62]foradiscussiononthatquestion).
3.2.1. Buildinganagent-awaresymbolicmodeloftheenvironment
Perspectivetaking.Visualperspectivetakingreferstotheabilityforvisuallyperceivingtheenvironmentfromanotherperson’s pointofview.Thisabilityallowsustoproperlyhandleandrepresentsituationswherethevisualperceptionofoneperson differsfromtheotherone.Atypicalexamplefoundindevelopmentalpsychologyconsistsoftwosimilarobjectsinaroom (e.g.two balls)thatare bothvisibleforachild,butonlyoneisvisibletotheadult. Whentheadult requeststhechild to handover“theball”,thechildisabletocorrectlyidentifywhichballtheadultisreferringto(i.e.theonevisiblefromthe adultpointofview),withoutasking[63].Ourarchitectureendowstherobotwithsuchacognitiveskill.
Spatial perspective taking refers to the qualitative spatial location ofobjects (or agents) withrespect to a frame (e.g.
thekeysonmyleft). Based on thisframe of reference, the descriptionof an object varies[64].Humans mix perspectives frequentlyduring interaction.Thisismoreeffectivethanmaintainingaconsistent one,eitherbecausethe(cognitive)cost of switching is lower than remaining with the same perspective, or if the cost is about the same, because the spatial situationmaybemoreeasilydescribedfromoneperspectiveratherthananother[65].Ambiguitiesarisewhenonespeaker referstoanobjectwithinareferencesystem(orchangesthereferencesystem,i.e.switchesperspective)withoutinforming her partner about it [66,67]. For example, the speaker could ask for the “keys on the left”. Since no reference system has been given, the listener would not know where exactly to look. However, asking for “the keys on your left” gives enough informationtothelistenertounderstandwherethespeakerisreferringto.Onthecontrary,whenusingan exact, unambiguous termof reference to describe a location (e.g.. “go north”) no ambiguity arises. In Spark, agent-dependent spatialrelationsarecomputedfromtheframeofreferenceofeachagent.
Symboliclocations.Humanscommonlyrefertothepositionsofobjectswithsymbolicdescriptors(likeon,nextto...)instead of precise, absolute positions (qualitative spatial reasoning). These type of descriptors have been extensively studied in thecontextoflanguagegrounding
[68–72]
.Spark distinguishesbetweenagent-independentsymboliclocations(allocentric spatialrelations)andagent-dependent,relativelocations(egocentricspatialrelations).Spark computesthreemainagent-independentrelations basedontheboundingboxandcentreofmassofthe objects (Fig. 5(a), [61]): isOn holds when an object O1 is on another object O2, and is computedby evaluating the centre of mass of O1 accordingto the boundingboxof O2.isIn evaluates ifan object O1 is inside anotherobject O2 based on their boundingboxes B BO1 and B BO2.isNextTo indicateswhetheranobject O1 isnext toanotherobject O2.Notethat we donot useasimpledistancethresholdtodetermine iftwo objectsarenext toeach other sincetherelationishighly dependent onthedimensionsoftheobjects.Forinstance,themaximumdistancebetweenlargeobjects (e.g.two houses) toconsiderthemasbeingnexttoeachotherismuchlargerthanthemaximumdistancewewouldconsiderfortwosmall objects(e.g.twobottles).Thus,thedistancethresholdisscaledwiththeobjects’size.Finally,Sparkalsocomputessymbolic facts relatedto agent independentworld dynamics.ThepredicateisMoving states,foreach trackedentity,whetherit is currentlymovingornot.
Many other topological relations are dependent from the observation point (egocentric perspective). The predicate
hasRelativePosition represents the superset of such spatial relations between agents and objects that are agent-dependent.Wecomputethesespatialrelationsbydividingthespacearoundthereferent(anagent)intonregionsbasedon arbitraryanglevaluesrelativetothereferentorientation(Fig. 5(b)).Forexample,forn
=
4 wewouldhavethespacedivided into front,left,rightandback.Additionally, twoproximity values,near andfar,arealsoconsidered.The numberofregions andproximityvaluescanbechosendependingonthecontextwheretheinteractiontakesplace.Throughperspectivetaking, Sparkcomputesforeachagentasymbolicdescriptionoftherelativepositioningofobjectsintheenvironment.→behind≡cyc:behind-Generally inverse ofinFrontOf →inFrontOf≡cyc:inFrontOf-Generally inverse ofbehind
→leftOf inverse ofrightOf
→rightOf inverse ofleftOf
Object cyc:farFrom Agent
Object cyc:near Agent
Agent looksAt SpatialThing
Agent sees SpatialThing
SpatialThing isInFieldOfView xsd:boolean myself sees *⇔* isInFieldOfView true Agent pointsAt≡cyc:pointingToward SpatialThing
Agent focusesOn SpatialThing looksAt∧pointsAt⇔focusesOn
Agent seesWithHeadMovement SpatialThing
Agent canReach Object
Object isReachable xsd:boolean myself canReach *⇔* isReachable true
3.2.2. Buildingamodelofagents
Buildingagroundedsymbolicmodelofthephysicalenvironmentdoesnotsufficeingeneraltofullygroundthehuman– robotinteraction,andamodelofthecurrentcapabilitiesoftheagentsinteractingwiththerobotisalsorequired.
Sparkcomputesthefollowingcapabilitiesfromtheperspectivesofeachagent:
•
Sees:thisrelationdescribeswhattheagentcansee,i.e.whatiswithinitsfieldofview(FOV).Inourcurrent implemen-tation,thisaffordanceiscomputedby dynamicallyplacinganOpenGLcameraatthelocationoftheeyesandrunning occlusionchecksfromit.InFig. 5
(c)thefieldofviewofapersonisillustratedwithagreycone(thewiderone).While sheis ableto see thetwo smallboxes on thetable in frontof her,the bigbox onher right isout ofher FOV, and therefore,sheisnotabletoseeit.Besides,SparkalsocomputestheseesWithHeadMovementrelationbysimulatingasmallleft-rightrotationofthehead. Itrepresentswhatanagentcouldseewithaminimaleffort.
•
LooksAt: thisrelationcorresponds to what theagent is focused on,i.e.where itsfocus ofattentionis directed.This model is based on a narrower field of view,the field of attention(FOA). Fig. 5(c)shows the field of attentionof a personwithagreencone(thenarrowerone).InthisexampleonlythegreyboxsatisfiesthelooksAtrelation.•
PointsAt holdswhenanobjectispointedatbyanagent. Thisrelationiscomputedbyplacingavirtual cameraonthehand,alignedwiththe forearm.pointsAtistypically usedduring dialoguegrounding,forinstancewhen oneofthe agentsisreferringtoanobjectsaying“this”or“that”whilepointingatit.
Weapplyanhysteresisfilteratthegeometricleveltoensureasufficientlystablerecognitionofthesethreecapabilities.
[image:11.561.39.498.93.306.2]•
Reachableenables therobot to estimate theagent’s abilityto reachforan object, whichisinstrumental for effective socialtaskplanning.Forexample,ifthehumanaskstherobottogiveheranobject,therobotmustcomputeatransfer pointwheresheisabletogettheobjectafterwards.Reachabilityiscomputedforeachagent(humanorrobot)basedon GeneralisedInverseKinematicsandcollisiondetection.Besides,therobot isableto computeanestimate oftheeffort neededbyanagenttoreachanobject[73].Table 2alsoliststheseabilities,alongwiththeadmissibleclassesforthesubjectsandobjectsofthestatements.
3.2.3. Primitiveactionrecognition
Initial human model Input Generated query to ontology Statements added to robot model BOOK1 type Book HUMAN1says: find(?obj type Book) HUMAN1 desires SITUATION1 HUMAN1 type Human “Give me the book” ⇒?obj = BOOK1 SITUATION1 type Give
SITUATION1 performedBy myself SITUATION1 actsOnObject BOOK1
Fig. 7.Processing of a simple, non-ambiguous command, taken from[74]. Thematic roles (performedBy,actsOnObject,receivedBy) are automat-ically extracted byDialogsfrom the imperative sentence “Give me the book.” The resulting statements (right column) are added to the knowledge base,
and may eventually trigger an event in the execution controller (see Section3.5.1).
forapick),or“ahandholdinganobjectisoveracontainer”(precursorforaput).Sparkrecognisesasetofsuchprimitives. When combinedwiththeothergeometric computationsandapredictiveplanofthehumanactions(seeSection 3.4),the execution controller can track the fulfilmentof the pre- and post-conditions of the predictedhuman actions. The robot reliesonthesetomonitortheengagementofthehumanandtheoverallprogressofthehuman–robotsharedplan.
3.2.4. Limitations
Initscurrentform,oursituationassessmentmodulemakestwoassumptions:theobjectsareknowninadvance(hence, we canrely onproper3D CADmodelforspatial reasoning)andtherobot benefitsofan nearly perfectperception,made possiblebytheuseoffiducialmarkers.Eachobjectreceivesauniquetagwhichenablesan accuratelocalisationin3Dand preventsrecognitionambiguitiesthatwouldbeotherwisereflectedintheknowledgebase.WhileSpark algorithmsdonot concernthemselveswiththenatureoftheinputsources,andwouldworkequallywellwithafullobjectrecognitionstack, wedidnotinvestigatethisresearchareasofar.
Additionally,temporalreasoning(essentialforaccurateactionrecognitionforinstance)isnotgenerallyaddressedinthe currentstate ofoursystem. Temporalreasoningisusedonlylocally,anddoesnotallowfortrackingoflongsequences or globalevents.
3.3. Multi-modalcommunicationandsituateddialogue
3.3.1. Naturallanguagegrounding
Naturallanguage isabasicinteractionmodality thatwe useinoursystemboth asan input(processing ofthe human speech) and asan output (verbalisation ofthe robot intentions, aswell ashuman–robot sharedplans). Naturallanguage processingisfacilitatedasourarchitecturemanipulatessemanticsthat areclosetothehumanlevel.Thissection presents the main features of our speech processor, Dialogs, that include semantic and multi-modal grounding, and interactive disambiguation.Algorithmsandimplementationdetailsareprovidedin[74].
We acquirenaturalspeechinput fromthehumanparticipantsthroughacustom Android-basedinterface.Theinterface reliesontheGooglespeechrecognitionAPIforspeech-to-text(ASR)andrelaysthetextualtranscripttotherobot.Thetext isparsedintoagrammaticalstructure(PartofSpeechtagging)byacustomheuristics-basedparser.Theresultingatomsare thenresolvedwiththehelpoftheknowledgebasetogroundconceptslikeobjects(i.e.whenausersays“pickupthecan”, it resolves to whichinstance ofCan the useris referring to) andactions.
Fig. 7
gives an exampleof theprocessingof a simple,non-ambiguouscommand.Thefirststudy(Section4.1)walksthroughmorecomplexexamples.Heuristics,likethe presence ofa question markorthe useofimperative mood,are usedto classifythe sentencesinto questions,desiresor statements.Dialogsprocessestheseaccordinglybyansweringquestionsorupdatingtheknowledgebase.Thesystemsupportsquantification(“giveme {a|the|some|all |any|n}can”), thematicroles(action-specific predi-catesthat qualifytheactions), interactive disambiguation(the robotasksquestionswhenitneedsmoreinformation),and anaphoraresolution(“giveittome”)basedonthedialoguehistoryandtheworkingmemory.Italsosupportsknowledge ex-tensionbylearningnewsemanticstructures.Forinstance,asentencelike“learnthatcatsareanimals”isconvertedintoCat subClassOf Animalandaddedtotheknowledgebaseaftercheckingforpossiblecontradictionswithexisting knowledge. Dialogsfinallyinterpretscommontemporalandspatialadverbs(likeaboveortomorrow)andtranslatessimpleexpressions of internalstate intoexperiences(forinstance,“I’mtired” isprocessedinto HUMAN1 experiences STATE1, STATE1 hasFea-ture tired,see alsoSection 3.5.2). A fullaccount ofthe Dialogs features andthecorresponding algorithms isavailable in[74].
3.3.2. Dialogueandmulti-modality
Because all of the components of our architecture rely on the same RDF formalism to represent their outputs, the differentcommunicationmodalitiesare presentedinahomogeneousway,assymbolicstatementsinthe knowledgebase. This applies both to explicit modalities (verbal communication, deictic gestures, gazefocus), andimplicit modalities(like the body position of the human). The dialogue grounding process makes use of them at two distinct levels to provide multi-modalconceptgrounding.
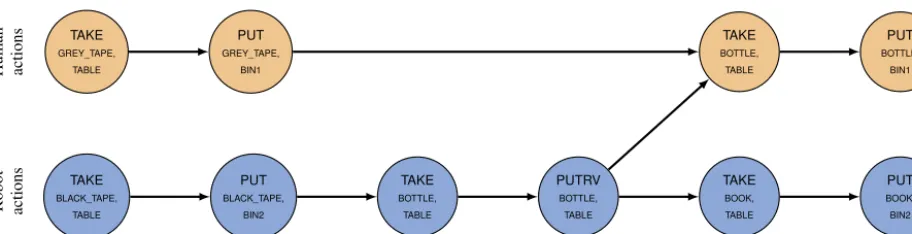
Fig. 8.An example of plan produced by HATP for a task consisting in cooperatively moving objects into their associated bins. Two action streams are generated (human actions at the top, robot actions at the bottom,PUTRVstands here for Put it so it is both Reachable and Visible). The arrow between the two streams represents a synchronisation point between the robot and the human based on a causal link.
Asanotherexample,when thehumansays“this”,therobot checksifthehumaniscurrentlypointingatan object.In thatcase,thisisreplacedbytheobjectfocusedon.Otherwise,therobotperformsanaphoraresolutionbylookingupinthe dialoguehistorytofindapreviousconceptthattheusercouldreferto.
Notethatwhilethesystembenefitsfromcomplementarymodalities,theyarenotallrequired.Thesystemcanrunwith the verbal modality alone,at the costof a simplerinteraction. For example,ifthe human says“this” without therobot tracking what the human points at, no HUMAN1 pointsAt ... fact is possibly available inthe knowledge base, andthe
robotfallsbackontheanaphoraresolutionstepalone.
The secondlevel ofintegrationofmulti-modalityis implicit.By continuouslycomputingsymbolicpropertiesfromthe geometricmodel,richersymbolicdescriptionsareavailabletothesystemtoverbaliseordiscriminateentities.Forinstance, therobotmaycomputethatonebottleisnexttoaglass,whileanotheronestandsalone.Thesesymbolicdescriptionsare transparentlyre-usedinadialoguecontexttogenerateunambiguousreferencestodiscriminatebetweensimilarobjects:“do youmeanthebottlethatisnexttotheglass?”.Thephysicalcontextoftheinteractionisusedasanimplicitcommunication modality by Dialogs.Ros et al.[17] provides a detailedaccount of our approachto interactive concept clarification and discrimination,alongwiththerelatedalgorithms.
3.4. Human-awaretaskplanning
Whenevernecessary,theexecutioncontrollers relyonsymbolictaskplanningtoconvertlong-termdesiresintoasetof partiallyorderedelementaryactions.ThisistheroleoftheHATPplanner(HumanAwareTaskPlanner)[75–77].
TheHATPplanningframeworkextendsthetraditionalHierarchicalTaskNetwork(HTN)planningdomainrepresentation andsemanticsby makingthem moresuitable toproduceplans whichinvolvehumans androbotsactingtogethertoward a jointgoal.HATP isused by therobot to produce human–robotsharedplans [78–80] which arethen used to anticipate humanaction,tosuggestacourseofactiontohumans,orpossiblytoaskhelpfromthehumanifneeded.
TheHATPplanningdomaindefinesasetofmethodsdescribinghowtoincrementallydecomposeataskandtoallocate subtasks andactions totherobot and/orthehumandepending onthecontext.Thisrepresentstheproceduralknowledge oftherobotaswellasitsknowledgeabouttheactionsthatthehumanpartnerisabletoachieve.Itisstoredoutsideofthe centralknowledgebase,usingaspecificformalism(seetherelateddiscussionattheendofthissection).
We discussnext howHATP incrementally buildsandsynchronises streams ofactions foreach orthe agents(humans androbot)involvedinatask,andhowitpromotesplansthatsatisfyhumansneedsandpreferencesaswellascomfortand legibility.
3.4.1. Agentsandactionstreams
TheoriginalityofHATPresidesinitsabilitytoproducesharedplanswhichmightinvolvetherobotaswell astheother participants.
HATPtreats agentsas“first-class entities”inthedomainrepresentationlanguage. Itcanthereforedistinguishbetween thedifferentagentsinthedomainaswellasbetweenagentsandtheotherentitiessuchastablesandchairs.Thisenables a post-processingstep that splits thefinal solution(sequence of actions)intotwo (or moreifthere areseveralhumans) synchronisedsolutionstreams,one forthe robotandoneforthehuman,sothatthestreams maybe executedinparallel andsynchronisedwhennecessary(Fig. 8).
This effectively enriches the interaction capabilities of the robot by providing the system with what is in essence a predictionofthehumanbehaviour.Thispredictionisusedbytherobotexecutioncontrollertomonitortheengagementof thehumanpartnerduringplanachievement.
The planner also generates causal links andsynchronisation points betweenthe robot and his human partners. For instance,inthe plandepictedin Fig. 8,thehuman needsto wait forthesuccessofthe robot’saction
PUTRV
.The robot monitorsthesuccessofitsownaction(bycheckingforthefulfilmentoftheactionpost-conditions;inthisparticularcaseFig. 9.An alternative plan for the task presented inFig. 8where theno wasted timesocial rule is used to optimise the total duration of the task.
action(here,TAKE(BOTTLE, TABLE)).This,inturn,allowstherobot tomonitorthehumanengagementandtheprogress
inthesharedplanexecution.AcompleteexampleispresentedinSection4.1
The hierarchical structureof theshared plans obtainedthrough theHTN refinement process provide agood basis for planverbalisation.Uponrequest,itallowstherobottoexplaintoitshumanpartnerhowataskcanbeshared[12,14].
3.4.2. Actioncostsandsocialrules
Adurationandacostfunctionareassociatedtoeachaction.Thedurationfunctionprovidesa durationintervalforthe action achievement.It serves bothto schedulethedifferentstreamsandasan additionalcostfunction. Besidestime and energyconsumption,thecostfunctionintegratesfactorsthatmeasurethesatisfactionofthehumanintermsofacceptability andlegibilityoftheresultingrobotbehaviour.
HATPincludesmechanismscalledsocialrulestopromoteplansthatareconsideredassuitableforhuman–robot interac-tion.Thefollowingconstraintscanbeset:
Wastedtime:avoidsplanswherethehumanspendsalotofhertimebeingidle;
Effortbalancingwithrespectofhumandesires:avoidsplanswhereeffortsarenotdistributedamongtheagentstakingpart to theplan,respectiveofthehumanpreferences.It isindeedsometimes beneficialtobalanceeffortsbetweenthehuman andtherobot.Sometimesthehumanwantstodomore,oronthecontrary,preferstoleavetherobotdomostofthework;
Simplicity:promotesplansthatlimitasmuchaspossibletheinterdependenciesbetweentheactionsofagentsinvolved in the plan, as an issue during the execution of one of those actions would put the entire plan at risk. Also intricate human–robotactivitymaycausediscomfortsincethehumanwillfindherselfrepeatedlyinasituationwheresheiswaiting fortherobottoact;
Undesirablesequences: avoids plans that violate specific user-defined sequences (for instance sequences which can be misinterpretedbythehuman).
Combiningtheabove criteria,weyieldsharedplans withdesirableinteractionfeatureslikehavingthehumanengaged inanumberoftaskswhileher overalllevelofeffortsremainslow,oravoidinghavingthehumantowaitfortherobotby preventingtheactionstreamsfromhavingtoomanycausallinksbetweenthem.
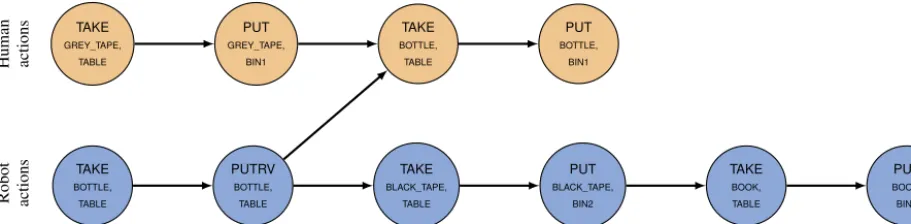
Fig. 9 illustrates such a socially-optimisedplan wherethe nowastedtime socialrule isapplied: compared tothe plan depictedin
Fig. 8
,therobotfirstmovesthebottlesothatthehumancanimmediatelytake itandputitintothebin,thus reducingthehumanidletime.In thecurrentimplementation,the socialrules areeffectivelyimplemented asfiltersapplied totheset ofall possible plans computedbytheplanner.Inthefuture,weintendtoextendtheplan-searchalgorithmandintegratethesocialrules intheprocessitself.
As HATPis a generic symbolic taskplanner anddoes not enforce anyabstraction levelfor the planningdomain, we havedesignedaplanningdomainmadeoftop-leveltaskswhosesemanticsareclosetotheone usedinthehuman–robot dialogue: theplannerdomain effectivelycontains concepts like
Give
,table
,isOn
.This leads toan effectivemapping betweentheknowledgeextractedfromthesituationassessmentorthedialogue,andtheplanner.Due to expressiveness issues, we do not represent the planning domain (i.e., the set of tasks with their pre- and post-conditions) in the knowledge base directly (see appendix B of [81] for the full rationale). This effectively leads to independentdeclarative(theOroknowledgebase)andprocedural(theplanner)knowledgestores.
3.5. Robotexecutioncontrol
aswellasthehumantocommunicatetheirbeliefsaboutthetasktobeachieved,inordertosharemutualknowledgeand tosynchronisetheiractivities.Thisisdonethroughreal-timetask-basedsituationassessmentachievedbythecombination ofSharymonitoringprocessesandOroinferencemechanisms.InShary,eachactiondescriptioncontainsnotonlyhowto executeitandmonitorit,butalsohowtoinitiateit(e.g.inthecaseofasharedaction,howbothagentsneedtocommit tothetask) andhowto suspend(or cancel)it.Ineach ofthesecases,theactiondescriptionalsomakes explicithowthe transitionhastobecommunicated tothehumanpartnerifnecessary.Thisissupportedby adescriptionofthebeliefsof eachoftheagentsregardingtheactionachievement process,aswell asasetofso-calledmonitoringprocessesthatupdate them.
Tworecentdevelopmentshavefurtherimprovedtherobot’sabilityto adapttohumanaction,both attheactionlevel andat the plan level. In [89], an extension is proposed forthe system to estimate the intentions of the human during collaborativetasks usingPOMDPmodels. The controlleradjusts thenappropriately the chosen setofactions. In [13],the controlleriscomplementedwithaframeworkthatallowstherobottoestimatethementalstateofthehumanpartner,not onlyrelatedtotheenvironmentbutalsorelatedtothestateofgoals,plansandactions.Theyarethenaccountedforbythe executioncontroller.
3.5.1. Event-drivencontrol
TheOroserversupportstwoparadigmstoaccessitscontent:RPC-stylequeries(basedonthestandardSPARQLlanguage) orevents.Amodulecansubscribetoaneventbyregisteringaneventpattern(initssimplestform,apartialstatementlike
? type Book)andacallback.Eachtimeanewinstanceofabookappearsintheknowledgebase,thecallbackistriggered.
Thisallowsustowritereactive robotcontrollerswithahighlevelofexpressiveness:forinstance,bysubscribingtothe event HUMAN1 desires ?action, ?action type Give, ?action actsOnObject ?obj, ?obj type Book, we effectively
trig-gerabehaviourwhenthehumanexpresses(throughdialogue,gestures...)thathewantstherobottogiveherabook. The robot controller designer does not need to directly care about how thisdesire is produced (this is delegated to perceptionmodules),hecaninsteadfocusonthesemanticsofthedesire.
Notethatwetransparentlytakeadvantageofthereasoningcapabilitiesofthesystemtotriggereventtotriggerevents: forexample,thetypeoftheobject(?obj type Book)maynotbeexplicitlyasserted,butinferredbythereasonerbasedon
otherassertions.
3.5.2. Complyingwithhumandesiresandexperiences
Wedividethe interactionsituationsperceived fromthesituationassessmentandthecommunicationcomponentsinto twocategories:desires(relatedtoperformativeactsinAustin’sclassificationofspeechacts[90])andexperiences.
Desiresaretypicallyhumancommands(“Givemethatbook”).Thenatureofthedesiredaction(topick,togive,tolook, tobring, toshow...), alongwiththeactionparametrisation (thematicroles) arefetchedby theexecutioncontrollerinthe knowledgebase,andareeithersentasgoalstothetaskplanner,orexecutediftheelementaryactionisdirectlyavailable.
Experiences,on theother hand,comprise ofemotions, statesandquestions (when asking a question, we considerthe humanto beinan interrogativestate).When theknowledgebasestatesthat an agentexperiences aparticularemotion or state,theexecutioncontrollermaydecidetohandleit,typicallybytryingtoanswerthequestionorusingtheemotionalor physicalstate asaparameterforsubsequentactions. Asan example,whenthespeakersays“I feeltired”,we changethe motionplannerparametrisation tolowertheeffortthehumanneedstoprovideforthefollowingjointmanipulationtasks.6
3.5.3. Human-awareactionrefinement
Before being executed, elementary actions are further refined by the execution controller with the help of a set of dedicated human-aware geometric motion planning functionsprovided by a componentcalled Mhp (see architecture in Fig. 2).
Thesefunctionsaredesignedtoplannavigation[91]andmanipulation[92,93]pathsnotonlysafebutalsocomfortable andsociallyacceptable byreasoningexplicitlyonhuman’s kinematics,visionfield,postureandpreferences[94–96].They
Table 3
Main studies conducted with our cognitive architecture.
Study Focus Reference
Point & Learn(2010) Interactive knowledge acquisition [28]
Spy Game(2010) Interactive object discrimination [17]
Interactive Grounding I(2011) Multi-modal interaction, perspective taking [98]
Roboscopie(2011) Human–Robot theatre performance [99]
Cleaning the table(2011) Complete architecture integration [100]
I’m in your shoes(2012) False beliefs [45]
Give me this(2012) Natural joint object manipulation [101]
Interactive Grounding II(2012) Multi-modal interaction, perspective taking [102]
Fig. 10.A scenario involving multi-modal, interactive grounding: the humans can refer to invisible or ambiguous objects that the robots anchor to physical objects through multi-modal interactions with the user.
alsoprovideroutinestocomputespatial placementsforrobotandobjectsthatobey constraintsrelatedtotheinteraction, likeoptimalmutualreachabilityoroptimalvisibility[97].
Finally,whenanactionrequiresthemotionofboththehumanandtherobot, Mhpcanplanforbothoftheminorder fortherobottotaketheleadbyautomaticallycomputingwheretheinteractionmightpreferablytakeplace[3,4].Thiscan effectively smoothentheinteraction by off-loadingapartofthe cognitiveloadof theinteraction fromthe humanto the robot.Assuch,thisisthegeometriccounterpartoftheHATPsymbolictaskplanner:itisabletomakeuseofasetofsocial rulestoadaptgeometricplanstosocialinteractions.
4. Supportstudies
Ourarchitecturehasbeendeployedandtestedinanumberofstudiesonseveralroboticplatforms.
Table 3
liststhemost significantones,withtheirmainfocusesandreferencepublications.Wepresenthereelementsoftwooftheminordertoillustrateinapracticalwaythedifferentaspectsofthearchitecture. The firstone isfocused on knowledge representationand verbal interaction: the human asksfor help to findand pack objects (InteractiveGroundingIinTable 3). Thesecond one(Cleaningthetable)involvestheSharyexecutioncontrollerand the HATPsymbolictaskplanner.In thisscenario,the humanandthe robot needto cooperativelyremove objectsfroma table.Robotbehavioursandmotionsarefullyplannedandthenexecuted.
4.1. Interactivegrounding
Thisfirststudyisbasedona“homemove” backstory:twousers aremovingtheir belongingstoadifferenthome,and needthehelpofarobottopack.Jido,asingle-armmobilemanipulator,isobservingwhiletheycarry overboxes(Fig. 10), andanswersquestionsconcerningthelocationofspecificobjects.Thisstudyfocusesonmulti-modal,interactivegrounding only:therobotobserves,buildsandmaintainsknowledgeaboutitshumanpartnersperspectivesandaffordancesbutdoes notactuallyperformanyphysicalactionbesidesverbalinteractionandsimpleheadmovements.
Objectsare perceivedthrough 2Dfiducialmarkersattachedtothem,andhumansare trackedthroughmotioncapture. The robot knowledgebaseisinitialisedwiththeOrocommonsense ontology.Wenext describetwo situationswherewe canfollowtheinternalrobot’sreasoningandtheinteractionwiththeuser.
Implicit disambiguationthroughvisualperspectivetaking. User A enters the room while carrying a large box (Fig. 10(a)). He approaches the table and asks Jido to hand him over a video tape: “Jido, can you give me the video tape”. The Dialogs module processes this sentence, and queries the ontology to identify the object the human is referring to:
Fig. 11.The face-to-face setup of the Clean the Tablestudy. The physical situation, theSparkmodel, and the current step of the plan are visible on the
picture.
Twovideotapes are visibletotherobot: one onthetable, andanotherone insidethecardboardbox.The knowledge basereturnsboth:?obj = [BLACK_TAPE, WHITE_TAPE].
However,onlyoneisvisibletoUserA(theoneonthetable).Althoughthereisanambiguityfromtherobot’sperspective, thehumanreferredtothevideotapeusingthedefinitequantifierthe:thisisinterpretedbythenaturallanguageprocessor asthehumanreferringtoaknownobject,i.e.theonevisibleinthehuman’sknowledgemodel.7
Explicitdisambiguationthroughverbalinteractionandgestures.Inthesecondsituation,UserBenterstheroomwithout know-ing whereUser Ahadmoved the videotapes (Fig. 10(b)).He first asksJido: “What’sinthe box?”. Therobot first needs to ground the word “box”. Similar to the previous situation, two boxes are visible: find(?obj type Box)
⇒
?obj = [CARDBOARD_BOX, TOOLBOX]Howeverbotharevisibletothehumanandthepreviousambiguityresolutionprocedurecannotbeapplied.Therobot generates a question (using the Discrimination algorithm, Section 3.1.1) andasks User B which box heis referring to by verbalising thefollowingquestion:“Whichbox,thetoolboxorthecardboardbox?”UserB couldanswerthequestion, but heinsteaddecidestopointatit:“Thisbox”(Fig. 10(b)).Sparkidentifiesthe
CARDBOARD_BOX
asbeingpointedat,aswell aslookedat, bythehumanandupdatestheontologywiththisnewinformation.The reasonerappliesarule availablein thecommon-senseontologypointsAt(?ag, ?obj) ∧ looksAt(?ag, ?obj) → focusesOn(?ag, ?obj).TheDialogsmodule mergesboth sources ofinformation,verbal(“this”)anddeictic, byissuinga querytotheknowledge basethat eventually liftstheambiguity:find(?obj type Box; USER_B focusesOn ?obj)
⇒
?obj = [CARDBOARD_BOX]
Finally,Dialogsqueriestheontologyaboutthecontentoftheboxandthequestioncanbeanswered:“Wall-E”(thelabel oftheobjecthadbeenstaticallyassertedintheontologyatstart-up).
AtthispointUserBwantstoknowwhereistheothertape:“Andwhereistheothertape?”.Dialogsisabletoconvert “theothertape”intoanewqueryusingthedifferentFromOWLpredicate:
?obj type VideoTape
?obj differentFrom WHITE_TAPE
⇒
?obj = [BLACK_TAPE]Sincethereisonlyonepossible“other”videotape,nospecificdisambiguationisrequired.Thereferentisuniquely iden-tifiedandDialogscanthenqueryforits location:find(BLACK_TAPE isAt ?loc).Therobot finallyverbalisestheresult
BLACK_TAPE isOn table, BLACK_TAPE isNextTo TOOLBOXinto“Theothertapeisonthetableandnexttothetoolbox.”
4.2. Collaborativetaskplanning
Thissecondstudydemonstratesaricherdecision-makingprocesswheretheOroserverisusedinconjunctionwiththe HATPsymbolictaskplannerandtheSharyexecutioncontrollertoproduceandexecuteasharedplan.Thetaskconsistsin cooperativelycleaningatablebymovingobjectsintotheirtargetbins(Fig. 11).
Fig. 12walksthrougha simplifiedversion ofthewholetask.Itdepictsa runwithasingle video tapeonatable. The video tape isreachable by the robot only, whilethe bin (wherethe objects are supposed to be eventually moved to) is reachablebythehumanonly:therobotneedstocomeupwithasharedplanthatinvolvesajointaction.
Fig. 12.Timeline of the Cleaning the tablestudy, presented here in a simplified version: a single object,TAPE, must be removed from the table and dropped in the binBIN. The light arrows sketch the global execution flow.
The goalisfirst receivedby theexecutioncontroller(after processingoftheuserrequest bythe Dialogsmodule,not shownonthefigure).Att1inFig. 12,thevideotapeiscomputedbytherobotasbeingreachablebytherobotonly(columns
5. Discussion:whenartificialintelligenceenableshuman–robotinteraction
The previoussectionsprovide aperspective ona completedeliberative architecture forsocialrobots,includingits im-plementation,supported by experimentaldeployments. Thissection synthesiseswhatwe seeasthemain challengesthat human–robotinteractionbringstoArtificialIntelligence.Wefirstdiscusshowembodiedcognitionisanessentialchallenge inhuman–robotinteraction;werephrasethentherequirementsofjointactionsintermsoffivequestions;wediscussthe importance of buildingand maintaining a multi-levelmodel of the human; andwe finally reflecton the importance of explicitknowledgemanagementinroboticarchitecturesthatdealwithhuman-levelsemanticsandstateinthatrespectthe currentlimitsofourlogicframework.
5.1. Embodiedcognition
Roboticsis traditionallyregarded astheprototypical instanceofembodied artificial intelligence,andthis dimensionis especiallyprevalentinhuman–robotinteraction,wheretherobot hastoshareandcollaborateinajointphysical environ-ment.This leads toa tight couplingbetweenthe symbolicandthe geometricrealms: while AIatits origins was mostly concerned withsymbolic models, it has been since recognised that not only the mind is not a purely abstract system, disconnectedfromthephysicalworld,butevenmore,cognitionfundamentallyreliesonits relationtothephysicalworld (so-calledembodiedcognition).Varela[103] isoneofthemaindiscovererofthesemechanisms,andcoinedtheconceptof
enactivismasthetheoreticalframeworkthat studiesthelinksbetweencognition,embodimentandactions.Thishassince beenthoroughlystudiedinroboticsandartificialintelligence(PfeiferandBongard[104]isoneofthereference).
Thechallengeofsymbolgroundingisalsotightlylinkedtothisissue.Itcorrespondstotheidentificationorcreation,and then,maintenanceofalinkbetweenthesymbol(thesyntacticformofknowledgethatthecomputermanipulates)andits semantics(itsmeaning,anchoredintheworld).Therelationbetweenthesymbol,thereferentofthesymbol,andmediating mindsisclassicallyreferredasthesemantictriangleandhasbeenextensivelystudiedinlinguistics.Theissueofgrounding iswellknownincognitivescienceandissummarisedbyHarnad[11]bythisquestion:“howthesemanticinterpretationof aformalsymbolsystemcanbemadeintrinsictothesystem?”.Thisissuehasamajorpracticalimportanceinrobotics:for arobottobebothendowedwithasymbolicrepresentational andreasoningsystem,andabletoactinthephysicalworld, itmustgrounditsknowledge.
Aswehaveseen,groundingisimplementedatdifferentlevelsinourarchitecture.Themainsourceofgroundedsymbolic knowledge is thesituation assessmentmodule, Spark.It buildssymbolic facts fromspatial reasoning, andalso relieson (limited) temporalreasoningto tracktheworld state andbuild explanations tointerpret unexpectedperceptions(like an objectthatsuddenlydisappears). BecauseSparkalsotrackshumans,whichenablesperspective-awarespatial reasoning,it canproduceaswellgroundedsymbolicknowledgefortheagentsitinteractswith.Thisisatypicalembodiedcognitiveskill. Groundingalsooccursduringverbalandnon-verbalcommunication.The Dialogsmodulegroundsnewconcepts intro-ducedbythespeakerbyaskingquestionsuntilitcanattachthenewconcepttoconceptsalreadypresentintheknowledge pool (if one asksthe robot “bring me a margarita”,the robot may initially asks“what is amargarita?”. The user would answer“acocktail”andtherobotwouldcontinue thegrounding–“whatisacocktail?”–untilitanchorsthenewconcept to onesit alreadyknowslike Drink).Embodied interactions (like gestures) are alsotakeninto account atthislevel: we havepresentedhowpointing,forinstance,isusedbytherobottoground“this”or“that”tothepointedartifact.
Notethat,becauseonlyobjectsmarkedwith2Dfiducialmarkersarecurrentlyrecognised(typically,abouttenofthem aresimultaneouslyusedinagivenexperiment),ourgroundingmechanismshaveonlybeenexercisedinsmall-sizedclosed world.Thissimplifiesthetask,andwecannotclaimthatourapproachprovidesagenericgroundingcapability.Context, cul-turalbackground,“naivephysics”knowledge,emotionalstateofthehumanaresomeofthenumerousdeterminantsbeyond theperceptionofgeometricentities.Theywouldneedtobeaccountedforwhengroundinghuman–robotinteraction.
5.2. TheW-questionsofjointaction
Whattodonext,atdifferentlevelsofabstractionsandwhiletakingintoaccountnot onlythecurrentstatebutalsothe long termgoals, isthe basicquestion foran intelligent robot. It ismademore complexhereby havingto deal withthe partiallyobservablephysicalandmentalstateofthehumanpartner,andbytheextendedsetofpossibleactions.
Whoshouldactnowisofkeyimportanceandalsoneedstobedecideduponbytherobot.Itissometimesexpectedasan intelligent behaviourfortherobottowaitandletitshumanpartneractinstead.Correctmanagementofturn-takingleads tovariousdecisionalchallenges.
Whentoperformagivenactionismademorecomplexbythepresenceofhumans.Therobothastotakeintoaccounther needs,herrhythmsandpace,andhermentalstate.Whileperformingitsshareofthetask,therobothastoproducesignals directedtowardsthehumanandtorespondtosignalsproducedbackattheproperpacetoensurecollaboration.
Wheretoperformanactionplaysan importantroleaswell:thechoiceisnottrivialandmightneedelaborateddecision. The robot isexpectedto takeinto accounteffort sharing,visibilityof itsaction bythe human,disturbanceordiscomfort inducedbyitsaction.
Howtoperformanaction,finally, needs to be reflected upon by the robot: several options to performan actionor to achieveagoalareoftenavailable,andselectingoneisanon-trivialdecisionproblem.Cost-basedplannersaugmentedwith social rules are one possibleapproach: they search forplans that satisfy an acceptable cost in terms of acceptability or
legibilityaswell.
These five questions should not be considered independently from each other andoften require, on the contrary, to be dealtwithina singledecisionstep.Thehuman-awaretaskandmotionplannerswhichwehavebuiltareinstances of systemswhichhavebeendesignedtodealwithsuchintricatedecisionissues.
Theyareinfactconsideredineach ofthecomponents,atdifferentlevelsofabstraction(fromtheabstractsharedplan level to the