Some Novel Applications of Explanation Based Learning to Parsing Lexicalized Tree Adjoining Grammars
8
0
0
Full text
Figure
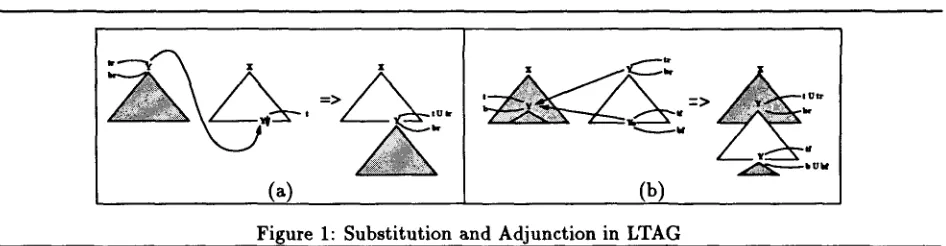
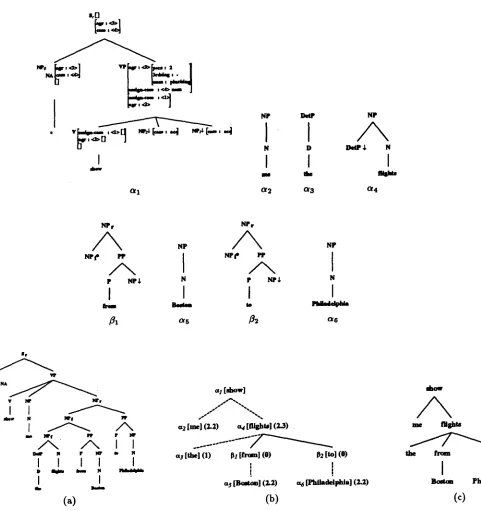


+3


Related documents