L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Processes
Prepared by
Dr. S. ATHITHAN
Assistant Professor
Department of of Mathematics
Faculty of Engineering and Technology
SRM INSTITUTE OF SCIENCE AND TECHNOLOGY
Kattankulathur-603203, Kancheepuram District.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Contents
1 Markov’s, Chebychev’s Inequalities and Law of Large Numbers 2
2 Central limit theorem 15
3 Chernoff Bound 21
4 Jensen’s and Cauchy-Schwarz Inequality 30
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
DEAR ALL, HERE IT HAS BEEN SOLVED FEW PROBLEMS ONLY AND SOME TOP -ICS MAY NOT BE COVERED. SO, YOU CAN FOLLOW THE REGULAR CLASSWORKNOTES TO HAVE ALL THE TOPICS FOR YOUR PREPARATION. TAKE EXERCISE
PROBLEMS GIVEN AT THE END FOR YOUR PRACTICE. APART FROM EXERCISE, YOU CAN FOLLOW ANY REFERENCE BOOK IN RELATED TOPICS FOR YOUR PRAC
-TICE.
SOME OF THE SECTIONS/TOPICS IN THIS NOTES ARE PRELIMINARIES WHICH ARE THE BASIC IDEAS NEEDED TO DO OUR REGULAR COURSE EXAMPLES AND EXERCISES.
1
Markov’s, Chebychev’s Inequalities and Law of Large
Num-bers
Here we prove a lot of different inequalities which may be useful for certain calculations. In particular, Chebyshev’s inequality will allow us to prove the weak law of large numbers. Consider a fair (p = 1/2 = q) coin tossing game carried out for 1000 tosses and a fair (p = 1/6, q = 5/6) dice throwing/tossing game carried out for 500 times to get any one the number on the dice, let it be 5. Explain in a sentence what the “law of averages” says about the outcomes of this game.
To explain these kind of instances, we call the key concept Law of Large Numbers (LLN)
which may classified into Weak Law of Large Numbers (WLLN) and Strong Law of Large Numbers (SLLN).
1. TheWeak Law of Large Numbersis a precise mathematical statement of what is usually loosely referred to as the “law of averages”. Precisely, letX1, . . . , Xnbe independent,
identically distributed random variables each with meanµand varianceσ2. LetSn =
X1+· · ·+Xnand consider thesample meanor more loosely, the “average”
Sn
n . Then
the Weak Law of Large Numbers says that the sample mean Sn
n converges in probability
to the population meanµ. That is:
lim
n→∞Pn
|Sn
n −µ|>
= 0.
In words, the proportion of those samples whose sample mean differs significantly from the population mean diminishes to zero as the sample size increases.
2. The Strong Law of Large Numbers says that Sn
n converges to µ with probability 1.
That is:
Pn→∞lim
Sn
n =µ = 1.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Before we see these concepts we need some of the preliminary concepts on probability which are as follows.
Lemma 1.1(Markov’s Inequality). LetX : S →Rbe a non-negative random variable. Then, for anya > 0,
Pr(X > a) ≤ E(X)
a .
Discrete Case Proof. LetAdenote the event{X > a}.Then:
E(X) =
X
ω∈S
Pr(ω)X(ω) = X
ω∈A
Pr(ω)X(ω) + X
ω∈A¯
Pr(ω)X(ω).
AsX is non-negative, we have X
ω∈A¯
Pr(ω)X(ω) ≥ 0.Hence:
E(X) ≥
X
ω∈A
Pr(ω)X(ω)≥ a X
ω∈A
Pr(ω) = a·Pr(A).
Continuous Case Proof. Here is a proof for the case whereX is a continuous random variable with probability densityf:
E(X) =
Z ∞
0
xf(x)dx
=
Z a
0
xf(x)dx+
Z ∞
a
xf(x)dx
≥
Z ∞
a
xf(x)dx
≥
Z ∞
a
af(x)dx
=a
Z ∞
a
f(x)dx
=aPrX ≥a.
(The proof for the case whereXis a purely discrete random variable is similar with summations replacing integrals. The proof for the general case is exactly as given with dF(x) replacing
f(x)dxand interpreting the integrals as Riemann-Stieltjes integrals.)
Lemma 1.2(Chebyshev’s/Chebychev’s/Tchebycheff’s Inequality). IfX is a random variable with finite meanµand varianceσ2, then for any valuek > 0:
P|X −µ| ≥ k ≤σ2/k2.
Proof. Since(X −µ)2 is a nonnegative random variable, we can apply Markov’s inequality (witha = k2) to obtain
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
But since(X −µ)2 ≥ k2 if and only if|X −µ| ≥ k, the inequality above is equivalent to:
P|X −µ| ≥ k ≤σ2/k2
and the proof is complete.
We now state the following lemma and corollary without proof.
Lemma 1.3 (One Sided Chebyshev’s/Chebychev’s/Tchebycheff’s Inequality). (To obtain an upper bound for a probability of the formP[X−µ≥ a]where ‘a’ is some positive value and when only the meanµ =EX and varianceσ2 = VarX of the distribution ofX are known) If X is a random variable with mean 0 and finite varianceσ2 then for anya > 0,
P(X ≥ a) ≤
σ2
σ2 +a2
Corollary 1.0.1. If the meanµ= EX and varianceσ2 = VarX, then fora > 0,
P(X ≥ µ+a) ≤
σ2
σ2+a2 i.e. P(X −µ≥ a) ≤
σ2
σ2 +a2 P(X ≤µ−a)≤
σ2
σ2+a2 i.e. P(X −µ≤ −a) ≤
σ2
σ2+a2
Proposition 1.0.1. IfVarX = σ2 = 0, thenP{X = EX} = 1. (i.e., the only RV’s having variances equal to 0 are those that are constant with probability 1). In other words we say, the probability about the constant mean of a RV is 1 if its variance is 0.
Proof. By Chebychev’s inequality,
P(|X −µ| ≥c)≤
σ2
c2 =⇒ P(|X −µ| ≤ c)≥ 1−
σ2
c2
Now, sinceVarX =σ2 = 0, we have
P(|X −µ| ≥ c)≤ 0 and P(|X −µ| ≤c) ≥ 1− − −(1)
(1) holds even for small values ofcalso, therefore takingc → 0we get
P(|X −µ|= 0) = 1 i.e. P(X =µ) = 1 P{X = EX} = 1
The Week Law of Large Numbers
Theorem 1.4 (Weak Law of Large Numbers). Let X1, X2, X3, . . . , be independent,
identi-cally distributed random variables each with meanµand varianceσ2. LetSn = X1+· · ·+
Xn. Then
Sn
n converges in probability toµ. That is:
lim
n→∞Pn
Sn
n −µ
>
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Proof. Since the mean of a sum of random variables is the sum of the means, and scalars factor out of expectations:
E
Sn
n = (1/n)
n
X
i=1
EXi = (1/n)(nµ) = µ.
Since the variance of a sum ofindependentrandom variables is the sum of the variances, and scalars factor out of variances as squares:
VarSn
n = (1/n
2) n
X
i=1
VarXi = (1/n2)(nσ2) = σ2/n.
Fix a value > 0. Then using elementary definitions for probability measure and Chebyshev’s Inequality:
0≤ Pn
Sn
n −µ
>
≤ Pn
Sn
n −µ
≥
≤ σ2/(n2).
Then by the squeeze theorem for limits
lim
n→∞Pn
Sn
n −µ
>
= 0.
The Strong Law of Large Numbers
Theorem 1.5(Strong Law of Large Numbers). Let X1, X2, X3, . . . , be independent,
iden-tically distributed random variables each with meanµand variance EXj2 < ∞. LetSn =
X1 +· · ·+Xn. Then
Sn
n converges with probability1toµ,
Pn→∞lim
Sn
n =µ = 1.
The proof of this theorem is beautiful and deep, but would take us too far afield to prove it. The Russian mathematician Andrey Kolmogorov proved the Strong Law in the generality stated here, culminating a long series of investigations through the first half of the 20th century.
1.1
Worked out Example Problems
Example : 1
Suppose that the average grade on the Mathematics exam is 75%. Find an upper bound on the proportion of students who score at least 85%.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Since we need only upper bound alone, we may use both Markov and one sided Chebychev’s inequality and then we compare the result.
Pr(X > a) ≤ E(X)
a (1.1)
Herea = 85andE(X) = 75, we havePr(X > 85) ≤ 75
85 = 0.88. To achieve this 88%
students has to score more than 85.
P(X ≥ a) ≤
σ2
σ2 +a2 (1.2)
Now, by equation (1.2) we also need the variance. So we assume the variance as 144, then we haveP(X ≥ 85) ≤ 144
144 + 7225 = 0.019To achieve this 1.9% students has to score more
than 85.
Example : 2
A random variable X takes the values -1,0,1 with probabilities 1
8, 3 4,
1
8 respectively.
Evaluate P{|X − µ| ≥ 2σ} and compare it with the upper bound given by Tcheby-cheff’s(Chebychev’s (or) Chebyshev’s) inequality.
Hints/Solution:
E(X) = 0
E(X2) = 1 4
V ar(X) = 1 4
∴ P{|X −µ| ≥2σ} = P{|X| ≥ 1}
= P{X =−1orX = 1} = 1 4
By Chebychev’s (or) Chebyshev’s inequality
P{|X −µ| ≥ c} ≤ σ
2
c2
Choosingc = 2σ
P{|X −µ| ≥2σ} ≤ 1
4
In this problem both the values coincide.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
wherek > 0, then it takes the form
P
|X −µ|
k ≥ σ
≤ 1
k2
P
|X −µ|
k ≤ σ
≥ 1− 1
k2
Example : 3
A fair dice is tossed 720 times. Use Tchebycheff’s(Chebychev’s (or) Chebyshev’s) in-equality to find a lower bound for the probability of getting 100 to 140 sixes.
Hints/Solution:
p = P{getting ‘6’ in a single toss} = 1 6
q = 1− 1
6 = 5 6 and
n = 720
X follows binomial distribution with meannp = 120and variancenpq = 100. i.e.µ = 120andσ = 100.
By Alternate form of Chebychev’s (or) Chebyshev’s inequality
P{|X −µ| ≤kσ} ≥ 1− 1
k2
P{|X −120| ≤10k} ≥ 1− 1
k2
P{120−10k≤ X ≤ 120 + 10k} ≥ 1− 1
k2
Choosingk = 2, we get,
P{100 ≤X ≤ 140} ≥ 3
4
∴Required lower bound is 3
4.
Example : 4
Let X1, X2, . . . be i.i.d. positive random variables with mean 5 and Y1, Y2, . . . be
i.i.d. positive random variables with mean 6. Show that X1 +X2 +· · ·+Xn
Y1 +Y2 +· · ·+Yn
→ 5
6
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Hints/Solution:By the law of large numbers,X1 +X2 +· · ·+Xnn →5with probability 1
and Y1+Y2+· · ·+Yn
n →6with probability 1, asn→ ∞. Note that if two events A and
B both have probability 1, then the eventA∩Balso has probability 1. So with probability 1, both the convergence involving theXi and the convergence involving theYj occur. Therefore,
X1+X2+· · ·+Xn
Y1 +Y2 +· · ·+Yn
→ 5
6 as
(X1 +X2 +· · ·+Xn)/n
(Y1+Y2+· · ·+Yn)/n
→ 5
6 with probability 1 as
n → ∞. There is no necessity to assume that the Xi are independent of the Yj because of
the pointwise with probability 1 convergence.
Example : 5
Let X1, X2, . . . , X60 be i.i.d. Unif(0,1) and X = X1 + X2 + · · · + X60. (a)
Which important distribution is the distribution of X very close to? Specify what the parameters are, and state which theorem justifies your choice. (b) Give a simple but accurate approximation forP(X > 17).
Hints/Solution:
(a)By the central limit theorem, the distribution ofXis approximatelyN(30,5). This has been found fromE(Xi) =
b+a
2 = 1
2,VarXi =
(b−a)2 12 =
1
12 thatE(X) =
60
X
i=1
E(Xi) =
30,Var(X) =
60
X
i=1
Var(Xi) = 60/12 = 5.
(b) We have P(X > 17) = 1 − P(X ≤ 17) = 1 − P
X −30
√
5 ≤
−13
√
5
' 1 −
φ
−13
√
5
= φ
13
√
5
This value is almost close to 1.
1.2
The normal distribution
Definition 1.2.1(Normal distribution). Thenormal distributionwith parametersµ, σ2, written
N(µ, σ2)has pdf
f(x) = √1
2πσ exp
−(x−µ)
2
2σ2
,
for−∞ < x < ∞.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
µ
Thestandard normalis whenµ= 0, σ2 = 1, i.e.X ∼ N(0,1).
We usually writeφ(x)for the pdf andΦ(x)for the cdf of the standard normal.
This is a rather important probability distribution. This is partly due to the central limit theorem, which says that if we have a large number of iid random variables, then the distribution of their averages are approximately normal. Many distributions in physics and other sciences are also approximately or exactly normal.
We first have to show that this makes sense, i.e.
Proposition 1.2.1.
Z ∞
−∞
1
√
2πσ2e − 1
2σ2(x−µ)
2
dx= 1.
Proof. Substitutez = (x−µ)
σ . Then
I =
Z ∞
−∞
1
√
2πe
−1 2z
2
dz.
Then
I2 =
Z ∞
−∞
1
√
2πe
−x2/2
dx
Z ∞
∞
1
√
2πe
−y2/2
dy
=
Z ∞
0
Z 2π
0
1 2πe
−r2/2
r dr dθ
= 1.
We also have
Proposition 1.2.2. E[X] =µ. Proof.
E[X] =
1
√
2πσ
Z ∞
−∞
xe−(x−µ)2/2σ2 dx
= √1
2πσ
Z ∞
−∞
(x−µ)e−(x−µ)2/2σ2 dx+ √1
2πσ
Z ∞
−∞
µe−(x−µ)2/2σ2 dx.
The first term is antisymmetric aboutµand gives0. The second is justµtimes the integral we did above. So we getµ.
Also, by symmetry, the mode and median of a normal distribution are also bothµ.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Proof. We haveVar(X) = E[X2]−(E[X])2. SubstituteZ = X −µ
σ . ThenE[Z] = 0,
E[Z2] =
1
σ2E[X 2
]. Then
Var(Z) = √1
2π
Z ∞
−∞
z2e−z2/2 dz
=
−√1
2πze
−z2/2
∞
−∞
+ √1
2π
Z ∞
−∞
e−z2/2 dz
= 0 + 1 = 1
SoVarX =σ2.
Example: 1. UK adult male heights are normally distributed with mean 70” and standard deviation 3”. In the Netherlands, these figures are 71” and 3”.
What isP(Y > X), whereX andY are the heights of randomly chosen UK and Netherlands males, respectively?
We have X ∼ N(70,32) and Y ∼ N(71,32). Then (as we will show in later lectures)
Y −X ∼N(1,18).
P(Y > X) = P(Y −X > 0) = P
Y −X −1
√
18 >
−1
√
18
= 1−Φ(−1/√18),
since (Y −√X)−1
18 ∼ N(0,1), and the answer is approximately 0.5931.
Now suppose that in both countries, the Olympic male basketball teams are selected from that portion of male whose hight is at least above 4” above the mean (which corresponds to the
9.1%tallest males of the country). What is the probability that a randomly chosen Netherlands player is taller than a randomly chosen UK player?
For the second part, we have
P(Y > X |X ≥ 74, Y ≥75) =
R75
x=74φX(x) dx+
R∞
x=75
R∞
y=xφY(y)φX(x) dy dx
R∞
x=74φX(x) dx
R∞
y=75φY(y) dy
,
which is approximately 0.7558. So even though the Netherlands people are only slightly taller, if we consider the tallest bunch, the Netherlands people will be much taller on average.
1.3
Moment generating functions
IfX is a continuous random variable, then the analogue of the probability generating function is the moment generating function:
Definition 1.3.1(Moment generating function). Themoment generating functionof a random variableX is
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
For thoseθin whichm(θ)is finite, we have
m(θ) =
Z ∞
−∞
eθxf(x) dx.
We can prove results similar to that we had for probability generating functions. We will assume the following without proof:
Theorem 1.6. The mgf determines the distribution of X provided m(θ)is finite for all θ in some interval containing the origin.
Definition 1.3.2(Moment). TherthmomentofX isE[Xr].
Theorem 1.7. The rth moment X is the coefficient of θ
r
r! in the power series expansion of
m(θ), and is
E[Xr] =
dn
dθnm(θ)
θ=0
= m(n)(0).
Proof. We have
eθX = 1 +θX+ θ
2
2!X
2 +· · · .
So
m(θ) = E[eθX] = 1 +θE[X] + θ
2
2!E[X
2
] +· · ·
Example: 2. LetX ∼ E(λ). Then its mgf is
E[eθX] =
Z ∞
0
eθxλe−λx dx =λ
Z ∞
0
e−(λ−θ)x dx= λ
λ−θ,
where0 < θ < λ. So
E[X] = m0(0) =
λ
(λ−θ)2
θ=0
= 1
λ.
Also,
E[X2] =m00(0) =
2λ
(λ−θ)3
θ=0
= 2
λ2.
So
Var(X) = E[X2]−E[X]2 = 2
λ2 −
1
λ2 =
1
λ2.
Theorem 1.8. IfXandY are independent random variables with moment generating functions
mX(θ), mY(θ), thenX +Y has mgfmX+Y(θ) = mX(θ)mY(θ).
Proof.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
1.4
More on the normal distribution
Proposition 1.4.1. The moment generating function ofN(µ, σ2)is
E[eθX] = exp
θµ+ 1 2θ
2σ2
.
Proof.
E[eθX] =
Z ∞
−∞
eθx√1
2πσe
−1 2σ
2(x−µ)2
dx.
Substitutez = x−µ
σ . Then
E[eθX] =
Z ∞
−∞
1
√
2πe
θ(µ+σz)e−1 2z
2
dz
=eθµ+12θ
2σ2 Z ∞ −∞
1
√
2πe
−1 2(z−θσ)
2
| {z }
pdf ofN(σθ,1)
dz
=eθµ+12θ 2σ2
.
Theorem 1.9. SupposeX, Y are independent random variables withX ∼ N(µ1, σ12), and
Y ∼ (µ2, σ22). Then
1. X +Y ∼N(µ1 +µ2, σ12+σ22).
2. aX ∼ N(aµ1, a2σ12).
Proof.
1.
E[eθ(X+Y)] = E[eθX]·E[eθY]
=eµ1θ+12σ 2
1θ2 ·eµ2θ+12σ 2 2θ
=e(µ1+µ2)θ+12(σ 2 1+σ22)θ2
which is the mgf ofN(µ1 +µ2, σ21 +σ 2 2).
2.
E[eθ(aX)] = E[e(θa)X]
=eµ(aθ)+12σ 2(aθ)2
=e(aµ)θ+12(a2σ2)θ2
Finally, suppose X ∼ N(0,1). Write φ(x) = √1
2πe
−x2/2
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
bound for it:
P(X ≥x) =
Z ∞
x
φ(t) dt
≤
Z ∞
x
1 + 1
t2
φ(t) dt
= 1
xφ(x)
To see the last step works, simply differentiate the result and see that you get
1 + 1
x2
φ(x). So
P(X ≥ x)≤
1
x
1
√
2πe
−1 2x
2
.
Then
logP(X ≥ x)∼ −1
2x
2.
1.5
Multivariate normal
LetX1,· · · , Xnbe iidN(0,1). Then their joint density is
g(x1,· · · , xn) = n
Y
i=1
φ(xi)
=
n
Y
1
1
√
2πe
−1 2x
2
i
= 1 (2π)n/2e
−1 2
Pn
1x2i
= 1 (2π)n/2e
−1 2xTx,
wherex = (x1,· · · , xn)T.
This result works ifX1,· · · , Xnare iidN(0,1). Suppose we are interested in
Z = µ+AX,
where Ais an invertible n ×n matrix. We can think of this as nmeasurements Z that are affected by underlying standard-normal factorsX. Then
X = A−1(Z−µ)
and
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
So
f(z1,· · · , zn) =
1 (2π)n/2
1
detAexp
−1
2 (A
−1
(z−µ))T(A−1(z−µ))
= 1
(2π)n/2detAexp
−1
2(z−µ)
TΣ−1
(z−µ)
= 1
(2π)n/2√det Σ exp
−1
2(z−µ)
TΣ−1
(z−µ)
.
whereΣ = AAT andΣ−1 = (A−1)TA−1. We say
Z =
Z1
.. .
Zn
∼ M V N(µ,Σ)orN(µ,Σ).
This is the multivariate normal.
What is this matrixΣ? Recall thatcov(Zi, Zj) =E[(Zi−µi)(Zj −µj)]. It turns out this
covariance is thei, jth entry ofΣ, since
E[(Z−µ)(Z−µ)T] = E[AX(AX)T]
=E(AXXTAT) = AE[XXT]AT
=AIAT
=AAT
= Σ
So we also callΣthe covariance matrix.
In the special case wheren= 1, this is a normal distribution andΣ =σ2.
Now supposeZ1,· · · , Zn have covariances0. ThenΣ = diag(σ12,· · · , σn2). Then
f(z1,· · · , zn) = n
Y
1
1
√
2πσi
e−
1 2σ2
i
(zi−µi)2 .
SoZ1,· · · , Zn are independent, withZi ∼N(µi, σi2).
Here we proved that ifcov = 0, then the variables are independent. However, this is only true whenZi are multivariate normal. It is generally not true for arbitrary distributions.
For these random variables that involve vectors, we will need to modify our definition of mo-ment generating functions. We define it to be
m(θ) = E[eθTX] = E[eθ1X1+···+θnXn].
Bivariate normal
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Thebivariate normalhas
Σ =
σ12 ρσ1σ2
ρσ1σ2 σ22
.
Then
corr(X1, X2) =
cov(X1, X2)
p
Var(X1) Var(X2)
= ρσ1σ2
σ1σ2
=ρ.
And
Σ−1 = 1 1−ρ2
σ1−2 −ρσ1−1σ−12
−ρσ1−1σ−12 σ2−2
The joint pdf of the bivariate normal with zero mean is
f(x1, x2) =
1 2πσ1σ2
p
1−ρ2 exp
− 1
2(1−ρ2)
x2 1
σ2 1
− 2ρx1x2
σ1σ2
+ x 2 2 σ2 2
If the mean is non-zero, replacexi withxi−µi.
The joint mgf of the bivariate normal is
m(θ1, θ2) = eθ1µ1+θ2µ2+ 1 2(θ
2
1σ21+2θ1θ2ρσ1σ2+θ22σ22).
Nice and elegant.
2
Central limit theorem
Suppose X1,· · · , Xn are iid random variables with mean µ and variance σ2. Let Sn =
X1 +· · ·+Xn. Then we have previously shown that
Var(Sn/
√
n) = Var
S
n −nµ
√
n
= σ2.
Theorem 2.1(Central limit theorem: Lindberg-Levy’s Form). LetX1, X2,· · · be iid random
variables withE[Xi] = µ,Var(Xi) = σ2 <∞. Define
Sn =X1 +· · ·+Xn.
Then for all finite intervals(a, b),
lim
n→∞P
a ≤ Sn −nµ
σ√n ≤ b
= Z b a 1 √
2πe
−1 2t
2
dt.
Note that the final term is the pdf of a standard normal. We say
Sn−nµ
σ√n →D N(0,1).
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Theorem 2.2(Continuity theorem). If the random variablesX1, X2,· · · have mgf ’sm1(θ), m2(θ),· · ·
and mn(θ) → m(θ) as n → ∞ for all θ, thenXn →D the random variable with mgf
m(θ).
We now provide a sketch-proof of the central limit theorem:
Proof. We assumeµ = 0, σ2 = 1(otherwise replaceXiwith
Xi −µ
σ ).
Then
mXi(θ) = E[e
θXi] = 1 +θ
E[Xi] +
θ2
2!E[X
2
i] +· · ·
= 1 + 1 2θ
2 + 1
3!θ
3
E[Xi3] +· · ·
Now considerSn/
√
n. Then
E[eθSn/ √
n] =
E[eθ(X1+...+Xn)/ √
n]
=E[eθX1/
√ n]· · ·
E[eθXn/ √
n]
=E[eθX1/
√ n]n
=
1 + 1 2θ 21 n + 1 3!θ 3
E[X3]
1
n3/2 +· · ·
n
→e12θ 2
asn→ ∞since(1 +a/n)n → ea. And this is the mgf of the standard normal. So the result follows from the continuity theorem.
Note that this is not a very formal proof, since we have to require E[X3] to be finite. Also, sometimes the moment generating function is not defined. But this will work for many “nice” distributions we will ever meet.
The proper proof uses the characteristic function
χX(θ) = E[eiθX].
An important application is to use the normal distribution to approximate a large binomial. LetXi ∼ B(1, p). ThenSn ∼ B(n, p). SoE[Sn] = npandVar(Sn) = p(1−p). So
Sn−np
p
np(1−p) →D N(0,1).
Theorem 2.3(Central limit theorem: Liapounoff’s (Liapunov’s) Form). Let X1, X2,· · · be
iid random variables withE[Xi] = µi,Var(Xi) = σi2 < ∞, i = 1,2,3, . . . . Define
Sn =X1 +· · ·+Xn.
Then for all finite intervals(a, b),
lim
n→∞P
a ≤ Sn−µ
σ ≤ b
= Z b a 1 √
2πe
−1 2t
2
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
whereµ=
n
X
i=1
µiandσ2 = n
X
i=1
σi2.
Note that the final term is the pdf of a standard normal. We say
Sn −µ
σ →D N(0,1).
Corollary 2.0.1. LetX1, X2,· · · be iid random variables with
¯
X = 1
n(X1 +X2 +· · ·+Xn).
ThenEX¯ = µandVar ¯X = 1
n2(nσ
2) = σ 2
n ∴
¯
X ∼ N
µ, √σ
n
asn→ ∞.
Example: 1. Suppose two planes fly a route. Each ofnpassengers chooses a plane at random. The number of people choosing plane 1 isS ∼ B(n,1
2). Suppose each hassseats. What is
F(s) = P(S > s),
i.e. the probability that plane 1 is over-booked? We have
F(s) = P(S > s) = P
S −n/2
q
n· 12 · 12
> s√−n/2
n/2
.
Since
S −np
√
n/2 ∼N(0,1),
we have
F(s) ≈1−Φ
s−n/2
√
n/2
.
For example, if n = 1000 and s = 537, then Sn√−n/2
n/2 ≈ 2.34, Φ(2.34) ≈ 0.99,
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Example: 2. An unknown proportionpof the electorate will vote Labour. It is desired to find
pwithout an error not exceeding0.005. How large should the sample be? We estimate by
p0 = Sn
n ,
whereXi ∼ B(1, p). Then
P(|p0 −p| ≤ 0.005) = P(|Sn−np| ≤0.005n)
= P
|Sn−np|
p
np(1−p)
| {z }
≈N(0,1)
≤ p0.005n
np(1−p)
We want|p0 −p| ≤ 0.005with probability≥ 0.95. Then we want
0.005n p
np(1−p) ≥ Φ
−1
(0.975) = 1.96.
(we use 0.975 instead of 0.95 since we are doing a two-tailed test) Since the maximum possible value ofp(1−p)is1/4, we have
n ≥ 38416.
In practice, we don’t have that many samples. Instead, we go by
P(|p0 < p| ≤ 0.03) ≥0.95.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Example: 3(Estimatingπ with Buffon’s needle). Recall that if we randomly toss a needle of length`to a floor marked with parallel lines a distanceLapart, the probability that the needle
hits the line isp = 2`
πL.
` X
θ L
Suppose we toss the pinntimes, and it hits the lineN times. Then
N ≈ N(np, np(1−p))
by the Central limit theorem. Writep0 for the actual proportion observed. Then
ˆ
π = 2`
(N/n)L
= π2`/(πL)
p0
= πp
p+ (p0 −p)
= π
1− p
0 −
p p +· · ·
Hence
ˆ
π−π ≈ p−p
0
p .
We know
p0 ∼N
p,p(1−p) n
.
So we can find
ˆ
π−π ∼N
0,π
2p(1−p)
np2
= N
0,π
2(1−p)
np
We want a small variance, and that occurs whenpis the largest. Since p = 2`/πL, this is maximized with` = L. In this case,
p= 2
π,
and
ˆ
π−π ≈ N
0,(π−2)π
2
2n
.
If we want to estimateπ to 3 decimal places, then we need
P(|πˆ −π| ≤ 0.001) ≥ 0.95.
This is true if and only if
0.001
s
2n
(π −2)(π2) ≥ Φ −1
(0.975) = 1.96
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
2.1
Problems based on Central Limit Theorem (CLT)
Example : 6
A random sample of size 100 is taken from a population whose mean is 60 and variance 400. Estimate using central limit theorem, with what probability can we assert that mean of the sample will not differ fromµ = 60by more than 4.
Hints/Solution:
Given: n= 100, µ= 60andσ = 20.
Required probability isP(|X¯ −60| ≤ 4) = P(56 ≤ X¯ ≤ 64). By CLT, we have standard normal variateZ =
¯
X −µ
σ/√n. ∴ P(56 ≤
¯
X ≤ 64) =P(−2 ≤
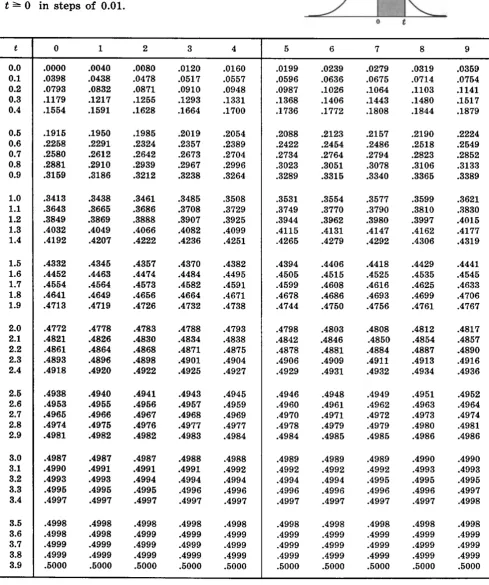
Z ≤ 2) = P(−2 ≤ Z ≤ 0) +P(0 ≤ Z ≤ 2) = 2×0.4772 = 0.9544.
0 2
-2 z
? 0.4772
Example : 7
The resistorsR1, R2, R3andR4 are independent random variables with mean 500 and
variance 100
2
12 . Using Central limit theorem findP(1900 ≤R1+R2+R3+R4 ≤ 2100).
Hints/Solution:
Given: n= 4, µ= 500andσ2 = 100
2
12 .
Required probability isP(1900 ≤Sn ≤ 2100).
By CLT, we have standard normal variateZ = S√n−nµ
nσ2 . ∴ P(1900 ≤ Sn ≤ 2100) =
P(−1.73≤ Z ≤ 1.73) = 2×0.4582 = 0.914.
0 1.73
-1.73 z
? 0.4582
Since we called the earlier the weak law, we also have the strong law, which is a stronger statement.
Theorem 2.4(Strong law of large numbers).
P
S
n
n →µasn→ ∞
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
We say
Sn
n →as µ,
where “as” means “almost surely”.
It can be shown that the weak law follows from the strong law, but not the other way round. The proof is left for Part II because it is too hard.
3
Chernoff Bound
3.1
Preliminaries for Chernoff Bound
Before we venture into Chernoff bound, let us recall two simple bounds on the probability that a random variable deviates from the mean by a certain amount: Markov’s inequality and Chebyshev’s inequality.
Markov’s inequality only applies to non-negative random variables and gives us a bound de-pending on the expectation of the random variable.
Deviation of a sum on independent random variables
As we are not able to improve Markov’s Inequality and Chebyshev’s Inequality in general, it is worth to consider whether we can say something stronger for a more restricted, yet interesting, class of random variables. This idea brings us to consider the case of a random variable that is the sum of a number of independent random variables.
This scenario is particularly important and ubiquitous in statistical applications. Examples of such random variables are the number of heads in a sequence of coin tosses, or the average support obtained by a political candidate in a poll. Can Markov’s and Chebyshev’s Inequality be improved for this particular kind of random variable? Before confronting this question, let us check what Chebyshev’s Inequality (the stronger of the two) gives us for a sum of independent random variables.
Theorem 3.1. LetX1, X2, . . . , Xnbe independent random variables withE(Xi) = µiand
Var(Xi) = σ2i.Then, for anya > 0:
P(|
n
X
i=1
Xi − n
X
i=1
µi| > a) ≤
Pn
i=1σ 2 i
a2
Proof. This follows from Chebyshev’s Inequality applied to
n
X
i=1
Xiand the fact thatVar( n
X
i=1
Xi) = n
X
i=1
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
In particular, for identically distributed random variables with expectationµand variance σ2, we obtain
P
Pn
i=1Xi
n −µ
> b
≤ σ
2
nb2
for anyb > 0. We already had the derivation of Markov’s, Chebychev’s inequality while we studied about Weak Law of Large Numbers (WLLN), that is why we just mentioned those here as it is needed.
Can this result be improved or is it tight? At a first glance, you may suspect that this is tight, as we have made use of all our assumptions. In particular, we exploited the independence of the variables{Xi}to getVar(
n
X
i=1
Xi) = n
X
i=1
Var(Xi).Notice, however, that this last step
actuallyonly uses the pairwise independence of the variables{Xi}, i.e. the fact that, for all
couplesi 6= j ∈[n]and allx, y ∈R:
P(Xi = x∧Xj = y) = P(Xi = x)·P(Xj = y). (3.1)
Indeed, it is possible to show that Theorem 3.1 is tight when all the variables {Xi} are just
guaranteed to be pairwise independent.
Hard Exercise Let X1, . . . , Xd be independent random variables that take value 1 or −1,
each with probability 1/2.For each S ⊆ [d], define the random variable YS =
Y
i∈S
Xi. i)
Show that the variables {YS} are pairwise independent. ii) Let Z =
X
S⊆D
YS. Show that
Chebyshev’s Inequality is asymptotically tight forZ.
We are now ready to tackle the case of a sum of independent random variables. Recall that we are now using the following strong version of independence (also known as joint or mutual independence), which guarantees the same property of Equation3.1for any subsetS ⊆ [n]of random variables:
∀S ⊆[n], P(^
i∈S
Xi = xi) =
Y
i∈S
P(Xi = xi).
In this case, the proof of Theorem3.1is too weak as it does not rely on the joint independence. In the next section, we will see that we can indeed obtainstronger boundsunder this stronger assumpiton. These bounds are known as Chernoff bounds, after Herman Chernoff, Emeritus Professor of Applied Mathematics at MIT!
3.2
Chernoff Bound: Theorem Statement
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Theorem 3.2 (Chernoff Bounds). LetX =n
X
i=1
Xi, where Xi = 1with probabilitypi and
Xi = 0with probability1−pi, and allXiare independent. Letµ =E(X) = n
X
i=1
pi.Then
(i). Upper Tail:P(X > (1 +δ)µ)≤ e− δ
2
2+δµfor allδ > 0;
(ii). Lower Tail: P(X < (1−δ)µ) ≤e−µδ2/2 for all0 < δ < 1;
3.3
The General outline of proof using Moment generating function
LetX be any random variable, anda ∈R. We will make use of the same idea which we used to prove Chebyshev’s inequality from Markov’s inequality. For anys > 0,
P(X > a) = P(esX > esa)
≤ E(e
sX)
esa by Markov’s inequality. (3.2)
(Recall that to obtain Chebyshev, we squared both sides in the first step, here we exponentiate.) So we have some upper bound onP(X > a)in terms ofE(esX).Similarly, for anys > 0,
we have
P(X < a) = P(e−sX > e−sa)
≤ E(e
−sX)
e−sa
The key player in this reasoning is themoment generating functionMX of the random variable
X, which is a function fromRtoRdefined by
MX(s) = E esX
.
The reason for the name is related to the Taylor expansion ofesX; assuming it converges, we have
MX(s) = E 1 +sX + 12s2X2+ 3!1s3X3 +· · ·
=
∞
X
i=0
1
i!s
i
E(Xi).
The termsE(Xi)are called “moments” and encode important information about the distribu-tion; notice that the first moment (i = 1) is just the expectation, and the second moment is closely related to the variance. So the moment generating function encodes information of all of these moments in some way.
Moment generating functions behave wonderfully with respect to addition of independent ran-dom variables:
Lemma 3.3. IfX =
n
X
i=1
XiwhereX1, X2, . . . , Xnare independent random variables, then
MX(s) = n
Y
i=1
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Proof.
MX(s) = E(esX) = E
esPni=1Xi
= E
n
Y
i=1
esXi !
=
n
Y
i=1
E(esXi) by independence
=
n
Y
i=1
MXi(s).
This lemma allows us to prove a Chernoff bound by bounding the moment generating function of eachXiindividually.
3.4
Proof of Theorem
3.2
Lemma 3.4. LetY be a random variable that takes value1with probabilitypand value0with probability1−p.Then, for alls ∈R:
MY(s) = E(esY)≤ ep(e
s−1) .
Proof. We have:
MY(s) = E(esY)
= p·es + (1−p)·1 by definition of expectation
= 1 +p(es−1)
≤ ep(es−1) using1 +y ≤ eywithy =p(es−1).
Proof of Theorem3.2. Applying Lemma3.3and Lemma3.4, we obtain
MX(s)≤ n
Y
i=1
epi(es−1) = e(es−1)Pni=1pi ≤ e(es−1)µ, (3.3)
using that
n
X
i=1
pi = E(X) = µ.
For the proof of the upper tail, we can now apply the strategy described in Equation3.2, with
a = (1 +δ)µand choosings= ln(1 +δ)(whereδis given in the statement of the theorem):
P(X > (1 +δ)µ) ≤e−s(1+δ)µe(es−1)µ)
=
eδ
(1 +δ)1+δ
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Taking the natural logarithm of the right-hand side yields
µ(δ −(1 +δ) ln(1 +δ)).
Using the following inequality forx >0(left as an exercise):
ln(1 +x) ≥ x
1 +x/2,
we obtain
µ(δ−(1 +δ) ln(1 +δ))≤ − δ
2
2 +δµ.
Hence, we have the desired bound for the upper tail:
P(X > (1 +δ)µ)≤
eδ
(1 +δ)1+δ
µ
≤e− δ
2 2+δµ.
The proof of the lower tail is entirely analogous. It proceeds by taking s = ln(1− δ)and applies the following inequality for the logarithm of(1−δ)in the range0< δ < 1 :
ln(1−δ) ≥ −δ+ δ
2
2 .
Details are left as an exercise.
3.5
Other versions of Chernoff Bound
Forδ ∈(0,1), we can combine the lower and upper tails in Theorem3.2to obtain the follow-ing simple and useful bound:
Corollary 3.5.1. WithX andX1, . . . , Xn as before, andµ =E(X),
P(|X −µ|> δµ)≤ 2e−µδ2/3 for all0 < δ < 1.
Chernoff bound can be applied to more general settings than that of Bernoulli variables. In particular, the following version of the bound applies to bounded random variables, regardless of their distribution!
Theorem 3.5. Let X1, X2, . . . , Xn be random variables such that a ≤ Xi ≤ b for all i.
LetX =
n
X
i=1
Xi and setµ =E(X).Then, for allδ > 0 :
(i). Upper Tail:P(X > (1 +δ)µ)< e−
2δ2µ2 n(b−a)2;
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Example application: coin tossing problem
Suppose we have a fair coin. Repeatedly toss the coin, and letSn be the number of heads from
the firstntosses. Then the weak law of large numbers tells us thatP(|Sn
n −1/2| > ) →0
asn → ∞. But what can we say about this probability for some fixedn? If we go back to the proof of the weak law that we gave in terms of Chebyshev’s inequality, we find that it tells us that
P(|Sn/n−1/2| > ) <
1 4n2.
So for example,P(|Sn
n −1/2| > 1/4) ≤
4
n.
But we can apply Chernoff instead of Chebyshev; what do we get then? From Corollary3.5.1, usingE(Sn) = n/2,
P(|Sn −n/2|> δ(n/2))≤ 2e−nδ 2/6
.
Taking δ = 1/2 we obtain P(|Sn
n − 1/2| > 1/4) ≤ 2e
−n/24
. This is amassive im-provement over the Chebyshev bound! Let’s try this now with a much smaller δ: let δ =
p
6 lnn/n. Then we obtain
P(|Sn
n −1/2| >
1 2
p
6 lnn/n) ≤2e−lnn = 21
n.
If instead we takeδ just twice as large,δ = 2p6 lnn/n,
P(|Sn
n −1/2|> p
6 lnn/n)≤ 2e−4 lnn = 2 1
n4.
3.6
Chernoff Bound for Normal Distribution
I’ve come across a question that firstly asks to derive the moment-generating function of a random variable X ∼ Normal(µ, σ2)as MX(t) = exp
µt+ σ
2t2
2
, which is fairly straightforward. Then, it asks to derive the following bound on the probability that X exceeds a certain value:
∀δ > 0.P(X ≥(1 +δ)µ)≤ exp
−d
2µ2
2
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Now, I make the following attempt:
P(X ≥(1 +δ)µ)≤ mint∈ R
expµt+ σ22t2 exp((1 +δ)µt)
= min
t∈R
exp
σ2t2
2 −δtµ
def
≡ min
t∈R
(f(t))
Now, optimising overtgives:
∂f
∂t =f(t)·(σ
2t−δµ)
∴ ∂f
∂t = 0 =⇒ t = δµσ
−2
Thus, the tightest bound that can be derived using Markov’s inequality with the mgf is
∀δ >0.P(X ≥ (1 +δ)µ) ≤exp
δ2µ2
2σ2 −
δ2µ2
σ2
= exp
−δ
2µ2
2σ2
This, however, is only a tighter bound than the desired one ifσ2 ≤ 1, which is not specified in
the question.
Is this because the question is flawed in not specifying this constraint, or is there an alternative strategy than the Markov bound which may be used to obtain the bound?
EDIT: As a commenter pointed out, the bound the question gives cannot hold in general because we can make the given probability arbitrarily high for fixedδ by settingσ2 arbitrarily close to
12. The question is therefore flawed.
3.7
Chernoff Bound in terms of MGF
If we use theChernoff bound in terms of MGFas given below
P(X ≥ a) ≤ e−atMX(t),∀t > 0 (3.4)
P(X ≤ a) ≤ e−atMX(t),∀t < 0 (3.5)
The above equations are calledChernoff bound in terms of MGF.
P(X ≥a) ≤ min
t>0 e −at
MX(t)
P(X ≤a) ≤ min
t<0 e −at
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
3.8
Chernoff Bound for Standard Normal Distribution
Now, we find the bound for Standard Normal Distribution VariateZ = X −µ
σ . For this Z,
we have
MZ(t) = e
t2
2
and
P(X ≥ a) ≤ e−atet
2
2,∀t ≥ 0
To minimize the RHSe−atet
2
2 , we have to minimize the term in the poweri.e.
t2
2 −at. For
that we have to differentiate the term and make it equal to zero. This leads tot−a = 0 =⇒
t = ai.e. we get the minimum value of the RHS att =a.
P(X ≥ a)≤ e−a
2
2 ,∀a > 0andP(X ≤ a)≤ e
−a2
2 ,∀a <0
3.9
Worked out Example Problems
Example : 8
LetX ∼ Exponential(λ). Using Chernoff bound find an upper bound forPr(X ≥
a), wherea > E(X). Compare the upper bound with (i) Markov’s inequality
(ii) Chebychev’s inequality and (iii) the actual value ofP(X ≥ a).
Hints/Solution:
IfX ∼Exponential(λ)
MX(t) =
λ
λ−t, for t < λ. (3.6)
Chernoff bound is given by
P (X ≥ a) ≤ min
t>0
e−taMX(t)
= min
t>0
e−ta λ λ−t
.
Iff(t) = e−ta λ
λ−t, to find themint>0 f(t)we have evaluate
d
dtf(t) = 0.From this we get, t∗ = λ− 1
a.
Now, sincea >EX = 1
λ =⇒ λ−
1
a > 0.
∴Pr (X ≥a)≤ e−t∗a λ
λ−t∗ =aλe 1−λa.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
(i)We haveEX = 1λ, Using Markov’s inequality we have
P (X ≥ a) ≤ EX
a =
1
λa.
(ii)We haveEX =
1
λ andVarX =
1
λ2. The Chebychev’s inequality now becomes
P (|X −EX| ≥ a) ≤ Var(X)
a2 =
1
λ2a2
(iii)The actual/real value ofPr (X ≥a)ise−aλand we havee−λa ≤ aλe1−λa or equiva-lentlyaλe ≥ 1which is correct sincea > 1
λ.
Finally we can easily see that the estimate by Chernoff bound is far better than both Markov’s and Chebychev’s inequality.
Example : 9
LetX ∼ Binomial(n, p). Using Chernoff bounds, find an upper bound onP(X ≥
γn), wherep < γ <1. Evaluate the bound forp= 1/2andγ = 3/4.
Hints/Solution:ForX ∼ Binomial(n, p), we have
MX(t) = (pet +q)n, whereq = 1−p. (3.8)
Thus, the Chernoff bound forP(X ≥a)can be written as P(X ≥ γn) ≤ min
t>0 e −ta
MX(t) (3.9)
= min
t>0 e −ta
(pet +q)n. (3.10) To find the minimization oft, we have to use
d
dte
−ta
(pet +q)n = 0, (3.11) which gives us
et = aq
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
By using this value oftin Equation (3.9) and some algebra, we obtain
P(X ≥ γn) ≤
1−p
1−γ
(1−γ)np
γ γn
. (3.13)
Forp = 1 2, γ =
3
4 we get
P
X ≥ 3
4n
≤
16
27
n4
. (3.14)
Now we compare the estimation between Markov, Chebychev, and Chernoff bounds: Above, we found upper bounds on P(X ≥ γn) for X ∼ Binomial(n, p). It is interesting to compare them. Here are the results that we obtain forp = 1/2andγ = 3/4:
P
X ≥ 3n
4
≤ 2
3 Markov, (3.15)
P
X ≥ 3n
4
≤ 4
n Chebychev, (3.16)
P
X ≥ 3n
4
≤
16
27
n4
Chernoff. (3.17) The bound given by Markov is the weakest one among these. It is constant and does not change as n increases. The bound given by Chebychev’s inequality is stronger than the one given by Markov’s inequality. In particular, note that 4/n goes to zero as ntends to infinity. The strongest bound is the Chernoff bound. It goes to zero exponentially fast compared to other bounds.
4
Jensen’s and Cauchy-Schwarz Inequality
Definition 4.0.1(Convex function). A functionf : (a, b) → Risconvexif for allx1, x2 ∈
(a, b)andλ1, λ2 ≥0such thatλ1 +λ2 = 1,
λ1f(x1) +λ2f(x2)≥ f(λ1x1 +λ2x2).
It isstrictly convexif the inequality above is strict (except whenx1 =x2 orλ1 orλ2 = 0).
x1 λ1x1+λ2x2 x2
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
A function isconcaveif−f is convex.
A useful criterion for convexity is
Proposition 4.0.1. Iff is differentiable andf00(x) ≥ 0for allx ∈ (a, b), then it is convex. It is strictly convex iff00(x) >0.
Theorem 4.1(Jensen’s inequality). Iff : (a, b) →Ris convex, then
n
X
i=1
pif(xi) ≥ f n
X
i=1
pixi
!
for allp1, p2,· · · , pnsuch thatpi ≥ 0and
X
pi = 1, andxi ∈(a, b).
This says thatE[f(X)] ≥ f(E[X])(whereP(X = xi) = pi).
Iff is strictly convex, then equalities hold only if allxiare equal, i.e.Xtakes only one possible
value.
Proof by induction : Induct onn. It is true forn = 2by the definition of convexity. Then
f(p1x1+· · ·+pnxn) = f
p1x1 + (p2 +· · ·+pn)
p2x2 +· · ·+lnxn
(p2+· · ·+pn)
≤p1f(x1) + (p2 +· · ·pn)f
p
2x2+· · ·+pnxn
p2+· · ·+pn
.
≤p1f(x1) + (p2 +· · ·+pn)
p
2
( )f(x2) +· · ·+
pn
( )f(xn)
=p1f(x1) +· · ·+pn(xn).
where the( )is(p2+· · ·+pn).
Strictly convex case is proved with≤replaced by<by definition of strict convexity.
Proof by Taylor’s series : Expanding f(x) in a Taylor’s series expansion about µ = EX
yields
f(x) = f(µ) +f0(µ) (x−µ) + f
00(ξ)(x−µ)2
2!
where theξ is some value betweenxandµ. For any convex function we know thatf00(ξ) ≥
0,∀ξwhich implies that
f(x) ≥f (µ) +f0(µ) (x−µ)
Taking Expectation on both sides, we getEf(x) ≥ f[µ] = f[EX]which proves the theorem.
Corollary 4.0.1(AM-GM inequality). Givenx1,· · · , xn positive reals, then
Y xi
1/n
≤ 1
n X
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Proof. Takef(x) = −logx. This is concave since its second derivative isx−2 > 0. TakeP(x=xi) = 1/n. Then
E[f(x)] =
1
n X
−logxi = −logGM
and
f(E[x]) = −log 1
n X
xi = −logAM
Sincef(E[x]) ≤ E[f(x)], AM≥GM. Since−logxis strictly convex, AM=GM only if allxi are equal.
Theorem 4.2(Cauchy-Schwarz inequality). For any two random variablesX, Y,
(E[XY])2 ≤E[X2]E[Y2].
Proof-1. IfY = 0, then both sides are0. Otherwise,E[Y2]> 0. Let
w =X −Y · E[XY]
E[Y2]
.
Then
E[w2] = E
X2 −2XY E[XY]
E[Y2]
+Y2(E[XY])
2
(E[Y2])2
=E[X2]−2(E[XY])
2
E[Y2]
+ (E[XY])
2
E[Y2]
=E[X2]− (E[XY])
2
E[Y2]
SinceE[w2] ≥0, the Cauchy-Schwarz inequality follows.
Proof-2. IfY = 0, then both sides are0. Otherwise,E[Y2]> 0. Let
w =X −sY, for any real values.
Then
E[w2] ≥0 E[X2]−2sE[XY] +s2E[Y2] ≥0
s2E[Y2]−2sE[XY] +E[X2] ≥0
LHS of above equation is quadratic in swith non-negative values, the discriminant becomes negative, we get
4(E[XY])2 ≤4E[X2]E[Y2].
which leads to
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
4.1
Worked out Example Problems
Example : 10
Let X and Y be two random variables with EX = 1,Var(X) = 4, and EY = 2,Var(Y) = 1. Find the maximum possible value forE[XY].
Hints/Solution:Usingρ(X, Y) ≤ 1andρ(X, Y) = Cov(X, Y)
σXσY
we have
EXY −EXEY
σXσY
≤1.
EXY ≤ σXσY +EXEY = 2 ×1 + 2×1 = 4
This result we can also be arrived by assumingY = aX +bwhich will producea = 1/2
andb = 3/2.
If we use the Cauchy-Schwarz inequality directly, we get
|EXY|2 ≤
EX2 ·EY2 = 5×5
i.e. EXY ≤ 5. In this case equality cannot be achieved and it achieved only ifY = aX. It is not possible here.
Example : 11
Show that iff : R 7→Ris convex and non-decreasing, andg : R 7→Ris convex, then
g(f(x))is a convex function.
Hints/Solution:Sincef is convex, we have
f(αx+ (1−α)y)≤ αf(x) + (1−α)f(y), for allα∈ [0,1].
Now, we have
g(f(αx+ (1−α)y)) ≤ g(αf(x) + (1−α)f(y)) (gis non-decreasing)
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Example : 12LetX be a positive random variable withEX = 10. Evaluate/Estimate the following quantities.
(i) EheX1+1
i
(ii) E
1
X + 1
and (iii) Ehln√Xi.
Hints/Solution:
(i) Let g(x) = ex, f(x) = 1
1 +x, then g is convex and non-decreasing and f is convex
function. This implies thatE
h eX1+1
i
≥ e1+1EX =e111 (by Jensen’s inequality) (ii) Let f(x) = 1
1 +x =⇒ f
00
(x) = 2
(1 +x)3 > 0, x > 0. Thus f is convex in
(0,∞).
E
1
X + 1
≥ 1
1 +EX =
1
11 (Jensen’s inequality)
(iii)Letf(x) = ln√x = 1
2lnx, thenf
0
(x) = 1
2x forx > 0andf 00
(x) = − 1
2x2. Thus
f is concave in(0,∞). By Jensen’s inequality we achieve the following:
E
h
ln√Xi = E
1
2 lnX
≤ 1
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
5
Exercise/Practice/Assignment Problems
1. If X1, X2, . . . , Xn be independent Poisson variables with parameter λ = 2. Use
Central Limit Theorem (CLT) to estimateP(120 < Sn < 160), whereSn = X1 +
X2 +· · ·+Xnandn= 75.
2. A random sample of size 100 is taken from a population whose mean is 60 and variance 400. Using CLT to find, with what probability can we assert that the mean of the sample will not differ fromµ= 60by more than 4?
3. A distribution with unknown mean µ has variance 1.5. Use CLT to find how large a sample should be taken from the distribution in order that the probability will be at least 0.95 that the sample mean will be within 0.5 of the population mean.
4. The life time of a certain brand of tube light may be considered as a random variable with mean 1200 hours and S.D. 250 hours. Find the probability using CLT that the average life time of 60 lights exceeds 1250 hours.
5. Use Tchebycheff’s(Chebychev’s (or) Chebyshev’s) inequality to find how many times a fair coin must be tossed in order to the probability that the ratio of the number of heads to the number of tosses will lie between 0.45 and 0.55.
6. IfX denotes the sum of the numbers obtained when 2 dice are thrown, obtain an upper bound forP{|X −7| ≥ 4}(Use Chebychev’s (or) Chebyshev’s inequality). Compare with the exact probability.
7. If a dice is thrown 2400 times, show that the probability that the number of sixes lies between 325 and 475 is atleast 0.94.Ans. 127/135
8. The number of transistors produced in a manufacturing unit during a week is a random variable with mean 100 and variance 25. a)What is the probability that the week’s pro-duction will exceed 125? b)What is the probability that the production will be 50 and 150 over one week? c) If the variance of a week’s production is equal to 40, then what can be said about the probability that this weeks production will be between 80 and 120?
Ans. 0.8,0.99,0.9
9. In a class, the average mark of a student is 65, with a variance of 15. a)Find the prob-ability that the mark will be greater than 73? b)What is the probability that the student mark will be 55 and 75?Ans. 127/135
10. A random variable X has mean 10 and variance 16. Find a lower bound forP(5< X <
15). Ans. 9/25
11. A random variable X has mean 10 and variance 16. Find an upper bound forP{|X −
10| ≥ 15}. Ans. 16/25
12. If Chebychev’s inequality for a random variable X with mean 12 is P{6 ≤ X ≤
18} ≥ 3/4,find the variance ofX Ans. 9
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
14. A random variable has the pdffX(x) = 3e−3x. Obtain an upper bound forP(X ≥1)
using Markov’s inequalityAns. 1/3
15. In a manufacturing company, a particular product of weight 1000 kg is to be manufac-tured. The average weight of the product was observed to be 1000 kg but a large variation was also observed. If all products above 1100 kg are discarded what percentage of prod-ucts are to be discarded? Ans. 90%
16. Estimate the Chernoff bounds for Binomial and Poisson distributions. 17. Estimate the Chernoff bound for Exponential distribution.
18. A coin is weighted so that its probability of landing on heads is 20%. Suppose the coin is flipped 20 times. Find a bound for the probability it lands on heads at least 16 times. 19. Suppose a fair coin is flipped 100 times. Find a bound on the probability that the number
of times the coin lands on heads is at least 60 or at most 40.
20. A biased coin lands heads with probability 1/10 . This coin is flipped 200 times. Use Markov’s inequality to give an upper bound on the probability that the coin lands heads at least 120 times. Improve this bound using Chebyshev’s inequality.
21. The average height of a raccoon is 10 inches.a. Given an upper bound on the probability that a certain raccoon is at least 15 inches tall. b. The standard deviation this height distribution is 2 inches. Find a lower bound on the probability that a certain raccoon is between 5 and 15 inches tall. c. Now assume this distribution is normal. Use a normal CDF table to repeat the calculation from part (b). How close was your bound to the true probability?
22. The number of customers visiting a store during a day is a random variable with mean
EX = 100 and variance Var(X) = 225. a.Using Chebychev’s inequality, find an
upper bound for having more than 120 or less than 80 customers in a day.b.Using the one-sided Chebychev’s inequality, find an upper bound for having more than 120 customers in a day.
23. LetX be a positive random variable withEX = 10. Evaluate/Estimate the following quantities.
(i) EX −X3
(ii) EhXln√Xiand (iii) E[|2−X|].
24. For i.i.d. r.v’sX1, X2, . . . , Xn with meanµand variance σ2, suggest a valuen(as a
specific number) that will ensure that there is at least a 99% chance that the sample mean will be within twice the standard deviations of the true meanµ.
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S
Acknowledgement:Some of the portions of this material are taken from the sources available from various sources. I thank the authors for those who prepared the calculus books and related materials.
Figure 5.1: Values ofe−λ.
Contact: (+91) 979 111 666 3 (or)[email protected]
L
E
C
T
U
R
E
N
O
T
E
S
O
F
A
T
H
IT
H
A
N
S