A genetic algorithm for generalized
tardiness flowshop problems
Sareh Meshkinfam, Department of Industrial Engineering,
Sharif University of Technology Azadi ave., P.O. Box 11155-9414, Tehran, Iran.
Farhad Ghassemi Tari
Associate Professor,
Department of Industrial Engineering, Sharif University of Technology Azadi ave., P.O. Box 11155-9414, Tehran, Iran.
Tel: +98-21-66165714, Fax: +98-21-66022702 [email protected]
Abstract - In this paper a generalized version of the tardiness flowshop permutation scheduling problems is considered. A mathematical programming formulation, in the form of a combinatorial optimization model, is also developed. Then a genetic algorithm is developed for solving the proposed problem. The efficiency of the developed algorithm is evaluated through a computational experiment, in which several classes’ of test problems is randomly generated. Through this experiment, the solutions obtained by the proposed algorithm are compared to the optimal solutions and the results are reported. The computational results revealed that the solutions of the proposed algorithm are very close the optimal solutions. An ANOVA statistical test is also conducted for evaluating the effect of the parameters of the test problems on the solutions obtained by the proposed algorithm and the results are reported.
Keywords:Generalized Tardiness Flowshop, Permutation Schedule, Genetic Algorithm, Analysis of Variance, I. Introduction
a genetic algorithm that included a neighborhood of the batches of jobs belonging to the same set-up family. They also conducted a computational experiment which its result revealed a significant reduction in total earliness and tardiness of the test problems.Mainieri and Ronconi [13] analyzed the total tardiness minimization in a flowshop with multiple processors at each stage. They proposed a set of heuristic methods and have conducted extensive computational experiments which were showed the competitiveness of their developed heuristics with respect to the classical counterparts. There are other studies dealing with the special cases of the flowshop tardiness problems. One is the work of Moslehi et al. [14] who presented an optimal scheduling in a two-machine flowshop problem with the objective of minimizing the sum of maximum earliness and the total tardiness of scheduling the jobs. They developed a branch- and-bound procedurefor solving their proposed problem. A number of effective lemmas were introduced which led to increase the efficiency of the searching procedure. Thirty eight problems were randomly generated and solved, in which %82 of the problems were shown to obtain optimal solutions. In another special flowshop study a bi-criteria flowshop scheduling problems with sequence dependent set up time were considered [15]. In this work, a modified genetic algorithm was proposed. The objective was the minimization of the weighted sum of total weighted squared tardiness the minimization of the makespan. A computational analysis was also carried out and the results were reported.Use of the genetic algorithm for solving two machine flowshop problems was also addressed by Cemil et al. [16]. They studied the minimization of the total earliness/tardiness penalties under learning effects in a two-machine flow-shop scheduling problem. They limited their work to a flowshop tardiness with a common due date for the jobs. They proposed a genetic and a Tabu search algorithm for solving their problem. Through a computational experiment they concluded that their proposed approaches were performing quite well for the large size problems. In this paper we proposed a genetic algorithm for solving the generalized version of tardiness flowshop problem. We first thoroughly express the problem in section two. Section three is devoted to the mathematical formulation of the problem. Section fourdescribes the development of the genetic algorithm. The computational experiment is illustrated in Section five. Then we concluded this research effort and presented in Section six.
II. Problem Statement
The n jobs m machines traditional flowshop model is based on the designs in which m machines are arranged in series. Each job is broken down into distinct m tasks or more precisely m operations, and each operation is performed at each of m machines in a unidirectional precedence. In other words, each operation after the first has exactly one direct predecessor and each operation before the last has exactly one direct successor. Thus, each job requires a specific sequence of operations to be carried out for the job to be completed. The machines in a flowshop can thus be numbered1,2,,m and the operations of job j numbered(1,j),(2,j),,(m,j) so that
they correspond to the machine required. In the general case, jobs may require fewer than m operations, and their operations may not always require adjacent machines, so the initial and final operations may not always occur at machines 1 and m. Nevertheless, the flow of work is still unidirectional, and the general case can be presented as a pure flowshop in which some of the missing operation times can be considered zero. In traditional tardiness flowshop model there is a due date for the last operation of the jobs. However in most of the real world problems such as product design and research/consulting projects, the outcomes are delivered through predefined phases and there is an associated due date for each phase of the deliverable tasks. Considering the deliverable phases as the project operation and assuming phases in different projects are carried out in a unidirectional precedence structure, when there are n projects to be scheduled and each having m phases, the problem can be modeled as n jobs-m machines tardiness flowshop scheduling problem with the intermediate jobs due dates. This model is called the generalized version of the tardiness flowshop model due to the fact that if one assign a large number to each of the intermediate due date, the traditional tardiness flowshop model can be constituted. The proposed problem is governed under the following assumptions:
A set of nunrelated jobs is available for processing at time zero.
Setup times for the operations are sequence independent and are included in their processing times.
Job processing time is determined and given.
Machines are non interruptible.
Jobs processing preemption is not allowed.
Considering the proposed problem, we proposed a genetic algorithm for finding the best permutation schedule. Then the efficiency of the proposed algorithm is evaluated with respect to the optimal solution.
III. Mathematical Model
To present a mathematical programming formulation for the proposed problem, the following notations will be used:
:
ik:
ikd
Due date for kthoperation of job i.:
ik
x
Starting time for kthoperation of job i.:
ik
T
Tardiness for kthoperation of job i.:
TT
Total tardiness of a schedule.The mathematical programming model for finding the optimal solution of the problem is presented as follow:
n i m k ik ik ikt
d
x
Max
MinTT
1 1)}
(
,
0
{
m
k
n
i
x
n
j
i
or
y
m
k
n
j
i
x
t
x
y
M
m
k
n
j
i
x
t
x
y
M
m
k
n
j
i
x
t
x
My
m
k
n
j
i
x
t
x
My
n
j
i
x
t
x
y
M
n
j
i
x
t
x
My
ik ji ik jk jk ji ik jk jk ji jk ik ik ji jk ik ik ji i j j ik j i i ik
1
,
1
for
0
,
1
for
1
0
2
,
,
1
for
)
1
(
2
,
,
1
for
)
1
(
2
,
,
1
for
2
,
,
1
for
,
1
for
)
1
(
,
1
for
1 1 1 1 1 1 1 1 1 1
Where M is considered as a large number.Clearly this mathematical programming model is in the form of nonlinear combinatorial optimization model. However by a simple manipulation the above model can be converted to a linear combinatorial optimization model as following:
1 1
n i m k ikT
MinTT
m
k
n
i
x
n
j
i
or
y
m
k
n
i
T
m
k
n
i
d
t
x
T
m
k
n
j
i
x
t
x
y
M
m
k
n
j
i
x
t
x
y
M
m
k
n
j
i
x
t
x
My
m
k
n
j
i
x
t
x
My
n
j
i
x
t
x
y
M
n
j
i
x
t
x
My
ik ji ik ik ik ik ik ik jk jk ji ik jk jk ji jk ik ik ji jk ik ik ji i j j ik j i i ik
1
,
1
for
0
,
1
for
1
0
1
,
1
for
0
1
,
1
for
2
,
,
1
for
)
1
(
2
,
,
1
for
)
1
(
2
,
,
1
for
2
,
,
1
for
,
1
for
)
1
(
,
1
for
1 1 1 1 1 1 1 1 1 1
Even in the linear combinatorial optimization, the computational time for obtaining the optimal solution increases exponentially as the number of the decision variables is increased. Since the real-world flowshop problems are formulated as a large scale combinatorialoptimization model, the only applicable approach for obtaining a solution is a heuristic approach. In this research, the development of such heuristic approach is considered.
IV. The proposed solution algorithms
solution. Due to this obstacle, we proposed a genetic algorithm for solving the proposed problem. In order to evaluate the efficiency of the developed algorithm, a computational experiment is conducted through which the closeness of the solution to the optimal solutions is determined.For developing the proposed algorithm, considering the permutation schedules for the flowshop model, each job is represented as a genome of a chromosome, which by referring to the flowshop model is actually a representative of each machine. Due to the general steps of the genetic algorithms, the next step is the generation of the initial populations. Then by the use of crossover and mutation operators the next populations are generated. Using the same general phenomena, the proposed algorithm can be described by the following steps.
4.1. Initial solution
A chromosome for each population is considered as a permutation schedule of the flowshop model. Therefore in a model with n jobs and m machines there are m chromosomes, each having n genies which represent the job’s sequences. By the use of the pseudo random generation, first a random number is generated form a uniform density function with range of
[
1
,
m
].
By eliminating the repeated numbers, m distinct machines are generated. Then another uniform density function is employed with the range of[
1
,
n
],
and again by eliminating the repeated numbers, n jobs are assigned to each of the m machines. Now for generating a permutation schedules,the same sequence is used for all other flowshop machines. By repeating this procedure for every m generated machines m permutation schedules will be constructed for representing one of the parents of the initial population. The other parent is generated by employing the same routine with a different seed of the random number. The following algorithmic procedure summarizes the steps for generating each parent of the initial populations.Step1. Let xj 0,j1,2,m, and j1 .
Step2. Generatea random variablexjfrom theU~[1,n],for allxj x0,x1,x2,xm ,andselect the machine .
, 2 , 1 0 and , 1 Let .
number MN xj k yk k n
Step3. Generatea random variablefrom the for all andassignjob to theU ~[1,n],for all the valuesof
sequence. of
position the
to job assign and , , ,
, 1 2
0 n k th
k y y y y y k
y
Step4. If
k
n
,
Assign the same sequence of the machine MN to all the machines of the flowshop and calculate the total tardiness of this permutation schedule, then go to step 5, otherwise letk
k
1
,
and go to step 3.Step5. Ifj=m,designate the initial population containing m permutation schedules, each as one of the chromosome, then stop, otherwise let j = j+1,and go to step 2.
4.2. Genetic Algorithm Operators
Genetic algorithms consist of three major operators, namely; selection/reproduction, crossover, and mutation operators. In the following sub sections, we describe the proposed genetic algorithm operators.
4.2.1. Selection/Reproduction Operator
The objective function of the proposed problem is the minimization of the total tardiness. Therefore the best solution is the one which has the least objective function value. The elitist and roulette wheel selection operators are employed for the proposed genetic algorithm. In this type of selection method, a probability is assigned according to its fittingness values and it will become a basis for the selection of a member for the further reproduction. In proposed algorithm the m permutation schedules are first sorted, by the values of their tardiness, in a non-decreasing order. By assigning the rank k, from 0 to the top and m-1 to the last schedule, we then defined function
w
(
k
)
2
(
m
k
)
/
m
(
m
1
)
for assigning a weight to each of the m schedules.Now by assigning a corresponding probability according to the defined weights, to each population member, we can obtain the cumulative density function. By generating a random variable xfrom a uniform density function with the range of [0, m-1], the selection of each schedule is accomplished according to the inverse of the cumulative density function with the following functional relation:.
2
/
)
))]
1
)(
1
(
1
(
4
)
2
1
[(
1
2
(
)
(
1/2 1/21
x
m
m
m
m
m
x
F
chromosomes by crossover and mutation operator are replaced with those having worst objective function values in the current population.
4.2.2. Crossover Operator
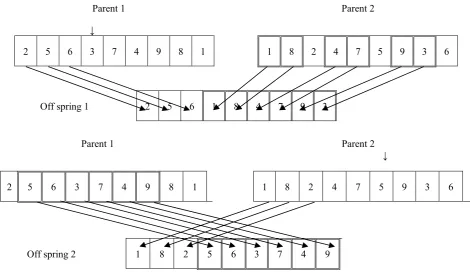
In proposed genetic algorithm, the number of chromosomes generated by the crossover operator, isachieved with the crossover rate of%pc. In the proposed algorithm we assigned different values from %70 to %90 to the crossover rateto evaluate their effects through the computational experiment. The Modified Order Crossover (MOX) is employed as the crossover operator. In MOX operator by a random number generation mechanism a cut point is determined.Then the genes in the left segment of the cut from first (second) parent are copied to the genes in the left segment of the cut in the first (second) offspring. The genes from second (first) parent, after omitting the selected genes are designated and mapped to right of the cut of the first (second) offspring in the same order. Through this procedure two offspring are generated and kept in a file to be considered after the mutation process.Figure (1) presents an illustrative example of the crossover for developing the offspring’s from a parent.
4.2.3. Mutation operator
Mutation in a way is the process of randomly disturbing genetic information and is commonly applied to avoid getting trapped at local optimum. It is an operator which provides diversity in the population whenever the population tends to become homogeneous due to repeated use of reproduction and crossover operators. They operate at genes level by which one or more genes of the current string alter to obtain a new string. In the proposed algorithm the mutation is applied after pm100*(1pc)percent, in whichpcis the percentage of crossover iterations.
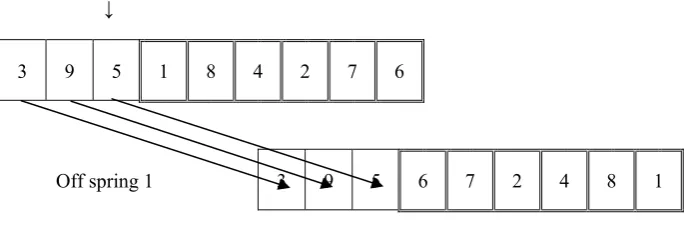
The mutation is performed by the one point inversionmethod. To perform the mutation we first generated a random variable from a uniform density function with the range of [0, n]. This random variable specifies the cut point. Then the genes in the left segment of the cut of the parent are copied to the left segment of the cut of the genes of the offspring in the same order. The remaining genes of the parent are then reversed and mapped to right of the cut of the offspring. Figure (2) presents an illustrative example of the mutation for developing the offspring’s from a parent.
Parent 1 Parent 2
↓
2 5 6 3 7 4 9 8 1 1 8 2 4 7 5 9 3 6
Off spring 1 2 5 6 1 8 4 7 9 3
Parent 1 Parent 2
↓
2 5 6 3 7 4 9 8 1 1 8 2 4 7 5 9 3 6
Off spring 2 1 8 2 5 6 3 7 4 9
↓
3 9 5 1 8 4 2 7 6
Off spring 1 3 9 5 6 7 2 4 8 1
Figure (2) An example of the mutation operator
4.3. Steps of the Genetic Algorithm
Using the above mentioned operators, we now can outline the steps of the proposed genetic algorithm by the following algorithmic procedures.
Step1. Generate the initial populationand calculate the tardiness of the parents. Step2. Let
p
c
0
.
70
,
and
It
1
.
Step3. Perform crossover iteration.
Step4. Calculate the tardiness of the offspring’s and save it on File OFC. Step5. Perform Mutation iteration.
Step6. Calculate the tardiness of the offspring and save it on File OFM.
Step7. Select offspring with the rate of
100
p
cfrom OFC and offspring with the rate of)
1
(
100
p
c percent from OFM, then chose a population with the size of m with smallest tardiness values among the new and older generation as the new population.Step8. If
It
20
,
go to Step 9, otherwise letIt
It
1
,
and go to Step3.Step9. Designate the sequence with the smallest tardiness as the final solution for this
p
c.
If,
90
.
0
cp
stop. Otherwise letp
c
p
c
0
.
05
,
and go to Step 3. V. Computational ExperimentsWe implement extensive numerical experiments to evaluate the effectiveness of the proposed algorithm. To show the effectiveness of the algorithm in obtaining the optimal solution a computational experimentis conducted with a variety of randomly generated test problems and the deviation of the average of solutions from the optimal solution is determined. Then an ANOVAstatistical test is also conducted to evaluate the effects of the problem’s controllable variables on the solutions obtained by the proposed genetic algorithm. In the following subsections the computational experiments will be presented.
a. Generation of the Test Problems
The concept of pseudo random generation is employed for generating an unbiased set of the test problems. For each test problem with the size of n jobs and m operations, several classes of the proposed problem are contemplated. For evaluating proximity of the problems solution obtained by our algorithm with the optimal solution we assigned m5and n5. For the same number of machines, m5,we increased the number of
jobs from 5 to 10 to generate five different classes of the test problems. We then let the number of machines to take the values of 7, 9, and 10 and generate 15 more classes of the test problems. It is to be noted that using total enumeration for obtaining the optimal solution for the number of jobs more than 10 the optimal solution could not be reached. For each class five problems are generated. We used a normal distribution function with the mean4and the standard deviation of 5for generating the job’s processing times and mean 9and the standard deviation of 4for generating their due dates.
To conduct an ANOVA statistical test the proposed algorithm coded by C++. We then generated the total of 750
b. Computational results
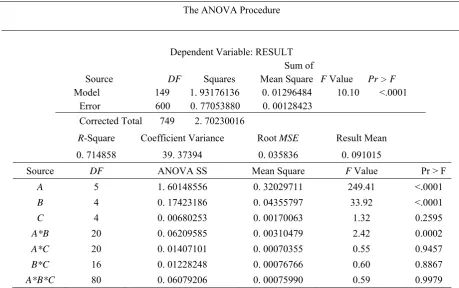
The computation results are two folds. First the ANOVA statistical experiment is conducted. For statistical analysis the software of SAS is employed and 750 experiments are run using the 3 factorial experimental design. Table (1) illustrates the results of this experiment. In this table factors A, B, and C presents the number of jobs, the number of machines and different values of the crossover rates respectively. It was intended to test the hypothesis equality of means according to the variation of such factors.
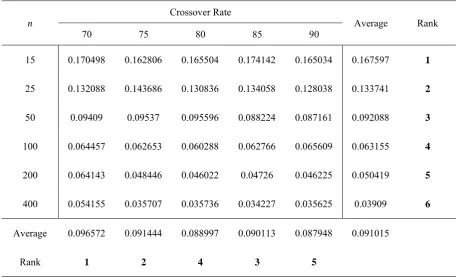
The results of ANOVA test reveal that the equality of means for factors A and B, the number jobs and the number of machines, and their interaction is rejected with considerably high probability. But for the case of equality of means for different crossover factors the hypothesis is accepted with good probabilities. To better reveal these facts Table (2) to Table (4) are prepared. In Table (2) improvement on the objective function for different number of machines while keeping the number of jobs unchanged are depicted. In Table (3) improvement on the objective function for different number of Jobs while keeping the number of machines unchanged are depicted. In both of these tables we assigned a ranking mechanism to the improvement values. The best improvement takes a rank with the value of 1 and worse takes rank of 5. From Table (2) we can deduct that as the number machines increases, the improvement also increases, while the improvement decreases as the crossover rate increases. From Table (3) we can see the same results according to the changes in the number of jobs while ranking are from 1 to 6.From Table (3) we can deduct that as the number jobs increases, the improvement decreases, while the improvement decreases as the crossover rate increases.
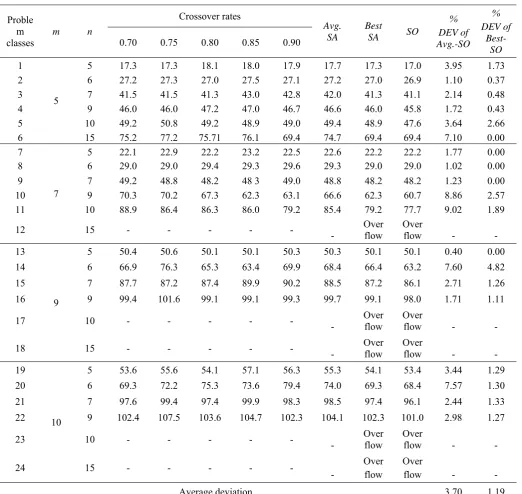
Next the deviation of the solutions obtained by the proposed algorithm from the optimal solutions is determined. For small classes of the test problems, five problems are generated and solved via the genetic algorithm and by total enumeration procedure. Letting SA to represent the average tardiness obtained by the proposed algorithm and SO representing the optimal tardiness obtained by the total enumeration procedure, the deviation is determined and designated as DEV (SASO)/SO.
Table (4) Illustrate the results of the first computational experiments. In this table, the solution of the genetic algorithm for different crossover rates of 70, 75, 80, 85, and 90 are presented.
Table (1) The ANOVA results for all the crossover rates
The ANOVA Procedure
Dependent Variable: RESULT Sum of
Source DF Squares Mean Square F Value Pr > F Model 149 1. 93176136 0. 01296484 10.10 <.0001 Error 600 0. 77053880 0. 00128423
Corrected Total 749 2. 70230016
R-Square Coefficient Variance Result Root MSE Mean
0. 714858 39. 37394 0. 035836 0. 091015
Source DF ANOVA SS Mean Square F Value Pr > F
A 5 1. 60148556 0. 32029711 249.41 <.0001
B 4 0. 17423186 0. 04355797 33.92 <.0001
C 4 0. 00680253 0. 00170063 1.32 0.2595
A*B 20 0. 06209585 0. 00310479 2.42 0.0002
A*C 20 0. 01407101 0. 00070355 0.55 0.9457
B*C 16 0. 01228248 0. 00076766 0.60 0.8867
Table (2) Improvement on the total tardiness according to changes on the machines number
Rank Average
Crossover Rate m
90 85
80 75
70
5 0.063725
0.061395 0.064279
0.062351 0.062893
0.067708 3
4 0.085025
0.079291 0.08515
0.085003 0.08564
0.09004 5
3 0.09978
0.09341 0.096279
0.099729 0.096298
0.113182 7
1 0.104614
0.107132 0.102535
0.099413 0.114448
0.099544 9
2 0.101931
0.098514 0.102322
0.098491 0.097943
0.112385 10
0.091015 0.087948
0.090113 0.088997
0.091444 0.096572
Average
5 3
4 2
1 Rank
Table (3) Improvement on the total tardiness according to changes on the jobs number
Rank Average
Crossover Rate n
90 85
80 75
70
1 0.167597
0.165034 0.174142
0.165504 0.162806
0.170498 15
2 0.133741
0.128038 0.134058
0.130836 0.143686
0.132088 25
3 0.092088
0.087161 0.088224
0.095596 0.09537
0.09409 50
4 0.063155
0.065609 0.062766
0.060288 0.062653
0.064457 100
5 0.050419
0.046225 0.04726
0.046022 0.048446
0.064143 200
6 0.03909
0.035625 0.034227
0.035736 0.035707
0.054155 400
0.091015 0.087948
0.090113 0.088997
0.091444 0.096572
Average
5 3
4 2
VI. Conclusion
In this paper a generalized version of the tardiness flowshop permutation scheduling problems is proposed. In generalized version of the tardiness flowshop problems there is an associated due date for every operation of the jobs. We called this model “the generalized version of the tardiness flowshop model” due to the fact that if one assign a large number to each of the intermediate due date, the traditional tardiness flowshop model can be constituted.A mathematical programming formulation, in the form of a combinatorial optimization model, is also developed. Due to the combinatorial nature of the mathematical model, the conventionalsolution approaches for solving this problem is limited only to the small size problems. Hence a genetic algorithm is developed for solving the proposed problem. In order to evaluate the efficiency of the developed algorithm, a computational experiment consisting of different class of randomly generated test problems is conducted. For each class of the test problems five different problems are randomly generated and solved by the proposed algorithm. Through this experiment, the solutions obtained by the proposed algorithm are compared to the optimal solutions and the results are reported. The computational results revealed that the solutions of the proposed algorithm in averagedeviatefrom the optimal solutions only by 0.03,while in some instances the
Table 4. Deviation of the average solutions from the optimal solution
Proble m
classes m n
Crossover rates
Avg.
SA Best SA SO
% DEV of Avg.-SO
% DEV of
Best-SO 0.70 0.75 0.80 0.85 0.90
1
5
5 17.3 17.3 18.1 18.0 17.9 17.7 17.3 17.0 3.95 1.73
2 6 27.2 27.3 27.0 27.5 27.1 27.2 27.0 26.9 1.10 0.37
3 7 41.5 41.5 41.3 43.0 42.8 42.0 41.3 41.1 2.14 0.48
4 9 46.0 46.0 47.2 47.0 46.7 46.6 46.0 45.8 1.72 0.43
5 10 49.2 50.8 49.2 48.9 49.0 49.4 48.9 47.6 3.64 2.66
6 15 75.2 77.2 75.71 76.1 69.4 74.7 69.4 69.4 7.10 0.00
7
7
5 22.1 22.9 22.2 23.2 22.5 22.6 22.2 22.2 1.77 0.00
8 6 29.0 29.0 29.4 29.3 29.6 29.3 29.0 29.0 1.02 0.00
9 7 49.2 48.8 48.2 48 3 49.0 48.8 48.2 48.2 1.23 0.00
10 9 70.3 70.2 67.3 62.3 63.1 66.6 62.3 60.7 8.86 2.57
11 10 88.9 86.4 86.3 86.0 79.2 85.4 79.2 77.7 9.02 1.89
12 15 - - - - Over flow Over flow - -
13
9
5 50.4 50.6 50.1 50.1 50.3 50.3 50.1 50.1 0.40 0.00
14 6 66.9 76.3 65.3 63.4 69.9 68.4 66.4 63.2 7.60 4.82
15 7 87.7 87.2 87.4 89.9 90.2 88.5 87.2 86.1 2.71 1.26
16 9 99.4 101.6 99.1 99.1 99.3 99.7 99.1 98.0 1.71 1.11
17 10 - - - - Over flow Over flow - -
18 15 - - - - Over flow Over flow - -
19
10
5 53.6 55.6 54.1 57.1 56.3 55.3 54.1 53.4 3.44 1.29
20 6 69.3 72.2 75.3 73.6 79.4 74.0 69.3 68.4 7.57 1.30
21 7 97.6 99.4 97.4 99.9 98.3 98.5 97.4 96.1 2.44 1.33
22 9 102.4 107.5 103.6 104.7 102.3 104.1 102.3 101.0 2.98 1.27
23 10 - - - - Over flow Over flow - -
24 15 - - -
-
Over flow
Over
flow - -
conduct an ANOVA statistical test the total of 750 test problems are randomly generated and used as the data for the ANOVA test. The test problems are classified according to different values of the number of the jobs and the number of machines and solved by the proposed algorithm with different crossover rates. The effects of the controllable variables on the genetic algorithm solutions are then analyzed and reported.
References
[1] Baker K.R., Trietsh D. Principle of Sequencing and Scheduling. John Wiley& Son Inc., United State of America, 2009.
[2] Ghassemi-Tari F., Olfat L. (2004).Two COVERT based algorithms for solving the generalized flowshop problems.Proceedings of the 34th International Conference on Computers and Industrial Engineering 34; 29-37.
[3] Ghassemi-Tari F., Olfat L. (2008). COVERT based algorithms for solving the generalized tardiness flow-shop problems.Journal of Industrial and Systems Engineering 2(3); 197-213.
[4] Ghassemi-Tari F., Olfat L. (2007). Development of a set of algorithms for the multi-projects scheduling problems.Journal of Industrial and Systems Engineering 1(1):11-17.
[5] Ghassemi-Tari F., Olfat L. (2010). A Set of algorithms for solving the generalized tardiness flowshop problems.Journal of Industrial and Systems Engineering 4 (3): 156-166.
[6] Ghassemi-Tari F., Olfat L. (2014). Heuristic rules for tardiness problem in flowshop with intermediate due dates.International Journal of Advanced Manufacturing 71(1-4): 381-393.
[7] Lyer S.T., Saxena B. (2004). Improved genetic algorithm for the permutation flowshop scheduling problem.Computers & Operations Research 31 (4): 593-606.
[8] Alaei R., Ghassemi-Tari F. (2013). Scheduling TV commercials using genetic algorithms.International Journal of Production Research 51(51): 4921-4929.
[9] Murata T., Ishibuchi H., Tanaka H. (1996). Genetic algorithms for flowshop scheduling problems.Computers & Industrial Engineering 30(4):1061-1071.
[10] Mirabi M., Dehghani Ashkezari M. (2011). Application of hybrid meta-heuristic approach to solve flow-shop scheduling problem.Australian Journal of Basic and Applied Sciences 5(10): 93-98.
[11] Reeves C.R., Yamada T. (1998). Genetic algorithms, path relinking, and the flowshop sequencing problem.Evolutionary Computation 6(1): 45-60.
[12] Schaller J., Valente J.M.S. (2013). An evaluation of heuristics for scheduling a non-delay permutation flowshop with family setups to minimize total earliness and tardiness. Journal of the Operational Research Society 64; 805-816.
[13] Mainieri G.B., Ronconi D.P. (2013). New heuristics for total tardiness minimization in a flexible flowshop, Optimization Letters 7(4): 665-684.
[14] Moslehi G., mirzaee M., Vasei M., Modarres M., Azaron A. (2009). Two-machine flowshop scheduling to minimize the sum of maximum earliness and tardiness.International Journal of Production Economics 122(2): 763-777.
[15] Dhingra A., Chandna, P. (2010). A bi-criteria m-machine SDST flowshop scheduling using modified heuristic genetic algorithm. International Journal of Engineering Science and Technology 2(5); 216-225.