WEB CACHING AND RESPONSE TIME
OPTIMIZATION BASED ON EVICTION
METHOD
MS.S.LATHA SHANMUGAVADIVU, ASSISTANT PROFESSOR, ECE DEPT, TAMILNADU COLLEGE OF ENGINEERING, COIMBATORE
DR.M.RAJARAM, PROFESSOR AND HEAD, EEE DEPARTMENT, GOVERNMENT COLLEGE OF ENGINEERING, TIRUNELVELLI.
ABSTRACT
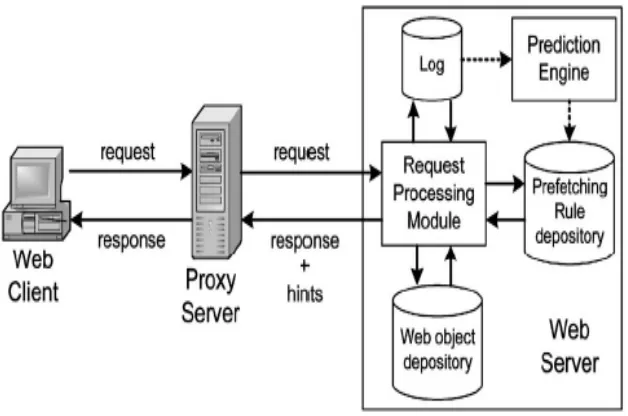
Caching is a technique first used by memory management to reduce bus traffic and latency of data access. Web traffic has increased tremendously since the beginning of the 1990s.With the significant increase of Web traffic, caching techniques are applied to Web caching to reduce network traffic, user-perceived latency, and server load by caching the documents in local proxies[5]. In this paper, analization of both advantages and disadvantages of some current Web cache replacement algorithms including lowest relative value algorithm, least weighted usage algorithm and least unified-value (LUV) algorithm is done. Based on our analysis, we proposed a new algorithm, called least grade replacement (LGR), which takes recency, frequency, perfect-history, and document size into account for Web cache optimization. The optimal recency coefficients were determined by using 2- and 4-way set associative caches. The cache size was varied from 32 k to 256 k in the simulation. The simulation results showed that the new algorithm (LGR) is better than LRU and LFU in terms of hit ratio (BR) and byte hit ratio (BHR).
1. INTRODUCTION
ADJACENCY CACHE DESIGN
of the cache index by one link’s worth, to enable a client system to determine ahead of time whether linked content is available at a remote proxy. As a consequence, communication between a client and remote cache system can be reduced because of these cache hints. This allows a client system to maintain a persistent connection with a remote cache, so that file requests for linked web content can be pipelined across the same socket. To create this combined index, the link structure of a cached file has to be extracted using regular expressions. This process creates an ordered set of links that can be used to create a bitmap vector of the linked files available at a remote site. As such, the length of a bitmap vector corresponds to the number of out links in a given web page. To encode the availability of linked content at a remote site, the corresponding bit locations of these out links are set in the bitmap. Therefore, the ith link is represented by the ith bit in the bitmap vector. To illustrate this idea, consider a web page that has five links to other files. If each of these linked files were available at a remote cache, then each bit location in the bitmap vector of this cached item would be set to one. However, if only the second and third links were available at a remote cache, then only bit locations one and two would be set in the bitmap. The intuition here is that users will browse to a new page through an existing hyperlink directly, instead of jumping to a new page at random [6]. Therefore, if we know which links are available ahead of time, the number of cache lookup messages routed across the network can be reduced. Once a browser has downloaded a list of IP addresses and adjacency cache bitmaps from the DHT, these are added to a fixed size in memory cache which has a least recently used eviction strategy.
1.1.2 DISTRIBUTED HASH TABLE
Distributed hash tables (DHTs) are a class of decentralized distributed systems that provide a lookup service similar to a hash table: (key, value) pairs are stored in the DHT, and any participating node can efficiently retrieve the value associated with a given key. Responsibility for maintaining the mapping from keys to values is distributed among the nodes, in such a way that a change in the set of participants causes a minimal amount of disruption. This allows DHTs to scale to extremely large numbers of nodes and to handle continual node arrivals, departures, and failures.DHTs characteristically emphasizes the following properties [7]: Decentralization: the
nodes collectively form the system without any central coordination. Scalability: the system should function
efficiently even with thousands or millions of nodes.
Fault tolerance: the system should be reliable (in some sense) even with nodes continuously joining, leaving, and
failing.
2.0 EXISTING SYSTEM
Lowest Relative Value Algorithm
Luigi and Vicisano proposed a replace algorithm for proxy cache called Lowest Relative Value (LRV). It is based on maximizing an objective function for the whole cache. The objective function uses a cost/benefit model to calculate the relative value of each document in the cache. Two performance parameters of cache are used: the HR and BHR [6].
Disadvantage of LRV
The LRV is particularly useful for small caches. With the cache capacity becoming larger, the overhead of maintaining the list of relative values of all cached documents increases, the performance of LRV drops.
1. Least Weighted Usage Algorithm
Ying, Edward, and Ye-sho argued that model-driven simulation was more objective than trace-driven. A web cache algorithm called Least Weighted Usage (LWU) was proposed using model-driven simulation [2].
Disadvantage of LWU
The drawback of LWU is that it ignores the size of web documents.
2. LUV Algorithm
Bahn et al. proposed a web cache replacement algorithm called LUV that uses complete reference history of documents, in terms of reference frequency and recency [1].
Disadvantage of LUV
PROBLEMS WITH EXISTING REPLACEMEN POLICIES
Requires data structure to be implemented.
Data structure requires a priority queue to be implemented.
Data structure needs to be constantly updated even when there is no deletion
Disadvantage of Existing System
A replacement policy is required for replacing a page from web cache to make room for new page. A replacement policy is a decision rule for evicting pages.
3.0 PROPOSED SYSTEM
This work web cache (proxy server) is to develop a utility to share internet from single connection to a
large network around 200 machines with different operating systems. The software is developed using the Java Language. Java applet applications are mostly used in the web pages, but we use JFC (swing) for developing the software.
This work provides an intelligent environment containing a number of ready-made options like cache, log file, error checking, connection pooling, etc. These ready-made tools may be any of the GUI components that are available in the Java AWT package. By using this utility, Administrator can control and maintain the whole network.
This thesis aim is to use the Least Recently Used document in web caches which replaces Randomized web cache replacement algorithm. A web cache sits between web server and a client and watches request for web pages. It caches web documents for serving previously retrieved pages when it receives a request for them.
Advantage of Proposed System
Saves memory
Saves processing power Reduces network traffic Reduces Latency time To reduce load on web servers Avoid the need for data structures.
The utility function assigns to each page a value based on -recentness of use -frequency of use -size of page -cost of fetching.
Least grade page replacement algorithm is proposed to support the deletion decision. N-M Method.
A proxy server is developed which runs with mentioned features, which inherently helps speeder browsing of web pages with use of least grade page replacement algorithms. This server is successfully implemented with a few numbers of clients but it could be implemented for more of them. As mentioned before it is more reliable, more advantageous than the existing one which uses the old Data structures concept. It can work in a larger network and also maintains load balancing so I conclude that this system application is executable under any platform and with any number of clients [5].
Fetch units and result pre-fetching
In many search engine architectures, the computations required during query execution are not greatly affected by the number of results that are to be prepared, as long as that number is relatively small. In particular, it may be that for typical queries, the work required to fetch several dozen results is just marginally larger than the work required for fetching 10 results. Since fetching more results than requested may be relatively cheap, the dilemma is whether storing the extra results in the cache (at the expense of evicting previously stored results) is worthwhile. Roughly speaking, result prefetching is profitable if, with high enough probability, those results will be requested shortly - while they are still cached and before the evicted results are requested again. One aspect of result prefetching was analyzed in, where the computations required for query executions (and not cache hit ratios) were optimized.
Table 1.Upper bounds on hit ratios for different values of the fetch unit
Fetch Unit Number of Fetches Hit Ratio
1 4496503 0.372
2 3473175 0.515
3 3099268 0.567
4 2964553 0.586
5 2861390 0.600
10 2723683 0.620
20 2658159 0.629
32 2657410 0.629
Web cache replacement algorithm
The keys of web caching have three aspects: 1. Algorithm of routing requests
2. Algorithm of replacing documents 3. Algorithm of updating documents
This paper focused on the second aspect, algorithm of replacing documents .With the study of web coaching’s characteristics going further, algorithms of replacing documents based on the statistics of collected web data were proposed. Each of them considers one or more of the following factors into its scheme:
Figure 2: Data Flow Diagram
The Dataflow Diagram in figure2 is also called as bubble chart. It is a simple graphical formalism that can be used to represent a system in terms of the input data to the system, various processing carried out on these data, and the output data is generated by the system.
Algorithm Sample
If (eviction) {
If (first iteration) {
Sample (N); evict_least_useful; keep_least_useful (M);
} else { Sample (N-M); evict_least_useful; keep_least_useful (M); }
}
Http Content and parsing analysis
Parsing is the process of analyzing an input sequence in order to determine its grammatical structure with respect to
Process Steps Lexical analysis:
– The input character stream is split into meaningful symbols (tokens) defined by a grammar of regular expressions – Example: the lexical analyzer takes "12*(3+4) ^2" and splits it into the tokens 12, *, (, 3, +, 4, ), ^ and 2.
● Syntax analysis,
– checking if the tokens form an legal expression, w.r.t. a CF grammar
– Limitations - cannot check (in a programming language): types or proper declaration of identifiers ● Semantic parsing
Works out the implications of the expression validated and takes the appropriate actions. Examples: an interpreter will evaluate the expression, a compiler, will generate code.
4. EXPERIMENTAL RESULTS:
Fig 3: Web cache main GUI
The figure 3 shows the web cache main GUI. Here java swing is used to build the user interface. It has four menus. First one is admin menu as shown in figure 4. It has four submenus. They are (i) start server to start HTTP server (ii) stop server to stop the HTTP server. (iii) Clear cache clears manually all the cache files in your cache directory. (iv) Clear image manually clears all the images in your image directory.
Figure 5: View menu
Fig6: Server Response & Client Request in server
Fig 7: Picture & Cache Viewer in server side
The figure 7 shows the picture and cache viewer in server side. The picture viewer is used to view all the pictures in your cached picture directory. The window is used to see each single image size and dimension and also to delete the unwanted single image from the cached image directory. (iv) Cache view is used to view the cache file from the cached directory and then view file and save the cached file in different formats, for example html, jsp and asp.
Fig 8: Error log for Admin & Client for server side
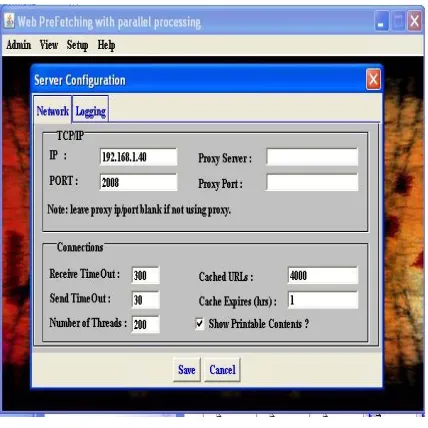
Fig 9: Web server Configuration
The figure 9 shows the web server configuration. The setup menu gives information about the server configuration which has two
Submenus. (i) The network input configuration window were we can set the proxy input and port number and the connection properties can be set like receive timeout, send time out number log of threads, cached url’s and cache expires (hrs) time. It is used for refreshing the server every one hour using N-M algorithm in LRU method. (ii) The logging window gives the access log and error log information. The access log caches the
Errors based on pages got from URL. The error log shows connection error between client and server. The logging level is based on minimal, normal and detail information about the error. The help menu shows the information about the server.
FIGURE 10: COMPARISON OF WEB CACHE ALGORITHMS
5. CONCLUSION
Based on perfect-history LFU and LRU, we proposed a new algorithm (LGR) by considering recency, frequency, perfect-history and size in replacing policy. The 2- and 4-way set associative caches were used to determine the optimal recency coefficients. The Real time with cache size varying from 32k to 256k showed that the new algorithm (LGR using N-M Method) is better than LRU and LFU in terms of Hit Ratio (HR) and Byte Hit Ratio (BHR). Experimental results show that the proposed algorithm can reduce network traffic and latency of data access efficiently.
6. FUTURE SCOPE:
The traditional browsing cache systems can not address both nonstationary and stationary browsing behaviors at the same time. The response time for an interactive browsing system can be greatly increased.
7. REFERENCES
[1] Pei Cao, Snady Irani, “Cost-Aware WWW Proxy Caching Algorithms”, in Proceedings of the USENIX Symposium on Internet Technologies and Systems, December, 1997.
[2] K.Thompson, G. Miller, and R. Wilder, “Wilde-Area Internet Traffic Patterns and Characteristics, “in Proceedings of 3rd International Conference Web caching, May, 1998.
[3] Seda Cakiroglu, Erdal Arikan, “Replace Problem in Web Caching”, in Proceedings of IEEE Symposium on Computers and Communications, June, 2003.
[4] Chrlos Maltzahn, Kathy J. Richardson, Dirk Grunwald, “Reducing the Disk I/O of Web Proxy Server Caches”, in Proceeding of the 199 USENIX Annual Technical Conference, Monterey, California, June, 1999.
[5] Luigi Rizzo and Lorenzo Vicisano, “Replacement Policies for a Proxy Cache”. IEEE/ACM Trans. Networking. Apr. 2000.
[6] H. Bahn, S. Noh, S. L. Min, and K. Koh, “Using Full Reference History for Efficient Document Replacement in Web Caches”, in
Proceedings of the 2nd USENIX Symposium on Internet Technologies & Systems, October, 1999.
[7] Ying Shi, Edward Watson, and Ye-sho Chen, “Model-Driven Simulation of World-Wide-Web Cache Policies”. In Proceeding of the 1997 Winter Simulation Conference, June, 1997.
[8] Ganesh, Santhanakrishnan, Ahmed, Amer, Panos K. Chrysanthis and Dan Li, “GDGhOST: A Goal Oriented Self Tuning Caching Algorithm”, in Proceeding of the 19th ACM Symposium on Applied Computing.March, 2004.
AUTHORS PROFILE
Dr.M.Rajaram, M.E., Ph.D., is a Professor and Head in Electrical and Electronics Engineering and Computer Science and Engineering in Government College of Engineering, Tirunelveli. He received B.E Degree in Electrical and Electronics Engineering from Madurai University, M.E and PhD degree from Bharathiyar University, Coimbatore, in 1981, 1988 and 1994 years and his research interests are Computer Science and engineering, electrical engineering and Power Electronics. He is the author of over 120 Publications in various International and National Journals. 7 PhD scholars and 10 M.S (By Research) Scholars have been awarded under his supervision. At present, he is supervising 12 PhD Scholars.