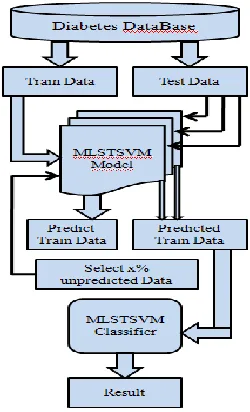
Predictive Analysis And Diagnosing Diabetes
Disorders Using Mlstsvm
M. Nagaraju, S. Siva kumar
Abstract: Diabetes is a significant medical issue in both developed and developing nations and its rate is rising drastically. In this examination, we research a novel approach to deal with prediagnosing Diabetes. This formulation is prevailed by means of extending recently proposed BLSTSVM and area Distribution method the use of Genetic algorithm. For M-class classification problem, it seeks M-linear equations. MLSTSVM proves its capability of working properly for both linear and non-linear form of datasets. It is exceptionally easy and faster when in comparison to the opposite existing methods. The performance of the previous approaches has been evaluated on Diabetes datasets. This exploratory final evaluation indicates the legitimacy of the proposed MLSTSVM classifier while compared with the common multi-classifiers dependent on support vector system.
Keywords: Support vector machine (SVM), SVM Classifier, Binary LTSVM, Multi-class Least Square Twin support Vector Machine (MLSTSVM).Genetic Algorithm
————————————————————
I.
INTRODUCTION
In early 1990s,SVM was introduced by C. Corinn and Vapnik et el. [1]&[2]. SVM is popular known to use in various real-world problems which are more specific in text categorization [4], Bio-Informatics [5] and also in image classification [3]. The high computational complexity in Quadratic Programming Problem (QPP) is one of the principle challenges of SVM [6]. This disadvantage leads the SVM applications to the large-scale problems. In recent times, using classification techniques is progressively increasing in Medical diagnosis. The cause of this research is to develop an efficient diagnostic model for prediagnosing Diabetes. In all the age groups it is notable disorder that was more examined frequently in Diabetes disease. The main cause of gradual increase in Diabetes is that lack of insulin and high glucose levels in the blood. From this end, blood cells don't respond appropriately to insulin. Therefore, in the scarcity of the insulin, the glucose isn't always well transformed to energy and is tired out via the usage of urination [7]&[8].
1.1 Diabetic Influence
The remarkable advancements in the Health Sciences has its data records which are produced from the large sets called E-Health Records. Presently, the method of Machine Learning plays a vital role to convert the Recorded data into priceless knowledge. The broad-spectrum research in all forms and types of diabetes (Insulin-Intake, therapy, glucose blood pressure, etc.) has driven into big amounts of Recorded data. The metabolic disorder in Diabetic types has significantly grown wide accordingly in human. World Health Organization (WHO) [1], estimated that 422 million population have diabetic problem in 2012. Later on, this count may rise to 10 percent for the next 10 years[2,9]. Diabetes is an ailment caused due to the extended level of sugar obsession in the blood. Diabetes is mainly categorized into 3 types which are type 1, type 2 and gestational diabetes.
According to Raha [10], 5% of people are effected by Type-1 diabetes however the possibility of being tormented by this kind of diabetes is not predictable [10].
1.2 The Health Reporting measures of Diabetes people in various in recent analysis
For the last two years that is In the year of 2017,2018, the American Diabetes Association models of restorative care[11] in diabetes has given a report which consolidates the relationship of diabetes, care, conclusion on test ranges and problem facing and the chances for effecting with diabetes. Apart from that National Diabetes Statistic Report[12] for Center Disease Control and Prevention (CDC), gives the realities give a record of the United States that 30.3 million people have diabetes, among that 23.1 are broke down and 7.2 million are undiscovered people[12]&[13]. In the year 2017, Global gave the detail data with respect to Diabetes by world prosperity affiliation [13], it communicates the heaviness of diabetes, peril parts and burdens of diabetes. It also describes similar portrays the information on neutralizing diabetes in every individual with high peril and directing diabetes at the beginning stage with applying some basic solutions
2.
RELATED
WORK
To classify the diabetes dataset Polat et al. [14] implemented PCA and Neuro Fuzzy inference. By using ESOM Deng and kasanov[15] obtained 78.4% of accuracy with classification of Diabetes dataset with 10 fold cross validation. To analyze Type -2 Diabetes Yuet al. [17] combined the Weighted Least Square SVM and Quantum Particle Swarm Optimization (QPSO). Many of the classification techniques proposed with accuracy between 60% and 78.5%. In recent times, non-parallel SVM got the great attention throughout the world for binary classification. In 2006 First Non-parallel Hyper-plane was proposed by Mangasarian and Wild [18] in the year of 2006 and it as named as Generalized Eigen value Proximal SupportVector Machine (GEPSVM). this model takes two non- hyper planes each one representing one of the two classes and these classes are seperated as far as one of each other. TWSVM performs well and comparatively 4 times faster for solving two QPP instead of single larger sized QPP. Binary Classification problems are solved by designated SVM and TWSVM. In practical scenario the problem is faced by multi- class classification, therefore, it is fact that extending ___________________________________
M. Nagaraju, Research Scholar, Department of Computer Science and Engineering, KL UNIVERSITY, Guntur, Andhra Pradesh, India. Email Id: [email protected]
SVM and TWSVM to multi-class classification is critical issue and current ongoing research problem. From Fig.1 It is observed Genetic algorithm is a managing stochastic pursuit strategy. It utilizes probability transform rule and fitness function to guide searching direction rather than deterministic rule of tradition search method. It is unique from other traditional search methods that Genetic Algorithm utilizes, fitting large-scale parallel process, population search method, and possessing global search function.
Fig. 1 The Area conveyance model of GA in the C - σ2
plane, which comprises of optimal straight line, under fitting area, over fitting area, optimal area, reference point of area
boundary.
SVM is one of the best accepted approaches in solving classification and regression tasks [20]. A SVM model is a portrayal of the models as focuses in space, mapped with the goal that the instances of the different classifications are divided by a clear gap that is as wide as conceivable [7]&[13]. For instance, given a set of points having a place with both of the two classes, a SVM finds a hyper-plane having the largest conceivable division of purposes of a same class on a same plane. This isolating hyper-plane is known as the optimal separating hyper-plane (OSH) that boosts the separation between the two parallel hyper-planes and can limit the risk of misclassifying instances of the test dataset. The traditional SVM, TWSVM and LSTSVM have the following binary classification.
where,
xi is ith data sample in n-dimensional Real space R. yi€ {-1, +1} is class label.
l is no.of patterns in the dataset.
l=l1+l2. where l1,l2 are -ve and +ve patterns.
Fig 2: MLSTSVM kernel function
3.
PROPOSED
MODEL
In This paper, My research work focuses on extending the LSTSVM to multi-class classification problem into Multi-LSTSVM and evaluating the performance comparatively with other SVM classifiers and error rate with Genetic algorithm with area distribution model. In addition, regularization terms are added to control the complexity for finding legitimate hyper-planes and to ensure each hyper-plane is nearer to its own class and is beyond what many would consider possible from the different class.
3.1 Multi-Class Least Square Twin Support Vector Machine
Diabetes is detected at early stages by using proposed MLSTSVM. In order to investigate effectiveness
and efficiency of MLSTSM Diabetes Dataset from PIMA repository is taken for the performance evaluation of MLSTSVM with Gaussian kernel. In addition to that the proposed model is compared with error rate and accuracy of Genetic algorithm rate is compared, got the better experimental results. For M-class classification, Experimental results shows that performance of the MLSTSVM algorithm based on the change area search is better than that Genetic algorithm search method of Genetic algorithm and other variations of SVM by changing the parameters in hyper parameter space as discussed in following sections. For Multi-class classification, 'M' number of linear equations are solved to generate 'M' non-parallel hyper planes[19], each class is assigned with one hyper plane. Suppose if i=1..M, ith hyper plane is very nearer to the ith class and is far from rest of the hyper planes. the examples of ith class lie in close with the ith hyper-plane and beyond what many would consider
possible from rest of the
hyper-planes.The decision regarding the class allocated to the test p attern is based on its distance from the hyperplanes. For each new pattern, its perpendicular distance from each hyperplane is determined and the pattern is assigned to the elegance fro m which its distance is lower.
In this classifier, Model will train each class with rest of different classes. To solve the Multi-class classification issue, it builds M-binary LSTSVM classifiers and mth class is assigned with positive class labels while patterns of remaining classes with negative class labels. Let us consider the patterns of the mth class, which is represented by the matrix Xm , where m=1,...,M and patterns of mth class is indicated by lm. The patterns of remaining classes are denoted by the following matrix:
(1)
i,e., Ym contains all the patterns except mth class.
The formulated MLSTSVM as as follows
(2)
The formulated Lagrangian function in the above equation is as follows:
(3)
By separating the Lagrangian function with typical vector, slack variable and bias, the following formula is obtained
(4)
(5)
(6)
(7) From the above equations following formula is obtained
(8)
By taking the following matrices the above equation (8) is reformulated as follows
= , = and (9)
By substituting the in the above equation is reformulated
as follows
(10)
From the above equation pattern is tested by assigning a class to each pattern as follows
(11)
Algorithm: Linear MLSTSVM
i).let us take i=1..M where M denotes number of classes. ii).Define the matrices Ai, Bi in such a way that
Ai = [Xi ei1] and Bi=[ Yi ei2] where Xi , Yi represents the patterns of ith class and remaining classes respectively.
iii).On the concept of validity parameters penalty is determine d
iv).Solve equations (4) to (5) by equation (10) taking on both weight and bias for each class.
v).New sample data are graded according to equation (11).
3.2 Non-Linear MLSTSVM
By using the concept of kernel functions we are extending the concept of MLSTSVM for Non –linear case[16]. Using Kernel Trick first take the inputs and transform them into high-Dimensional space and then identify the patterns by generating Kernel Surfaces.
Consider the following equation for mth Non linear space
KKT states of above Lagrangian work are given
underneath:
(12)
(13)
(14)
(15)
By Combining the equations (12) and (13) the following equation is obtained
16)
(17)
Non-Linear MLSTSVM of Decision Function is aformulated as follows
(18)
Algorithm: Non- Linear MLSTSVM
i. Choose Kernel function K
ii. Let's take i=1 to N, where N is class number.
a) Define the matrices Pi, Qi in such a way that Pi =[K(Xi,DT) ei1] and Qi =[K(Yi,DT) ei2]] where Xi , Yi represents the patterns of ith class and remaining classes respectively.
b) On the premise of validation penalty parameters are decided on
c) Solve equations (12) to (15) by equation (18) acquire both weight and bias for each class.
iii New data sample are classified by equation (18) =
3.3 Model Parameters of SVM Space
The fundamental issue for the direct non distinguishable pattern for finding the constraint optimization of a SVM is as follows
(19)
where the pairs of training sample are dented by (xi,yi), i
=1,....l, xi€{1,-1), xi denotes the training vector, w represents
the weight vector, and b represents the bias and ni is the slack variable,
The function, maps an n-dimensional input vector xi
into a high dimensional feature space, and C is the error penalty parameter, and C > 0.
we must improve and adjust the confidence intervals to acquire a generalization ability given by Statistical Learning Theory (SLT) [17].
According to equation (19), is the performance measure, is the error penalty.
1.If C is small then the penalty error is small, too, and the risk becomes large. Consequently the complexity is low and the risk is large, then it is difficult to approach the training data which leads to Under-Fitting. 2.If C holds large value, then the penalty error becomes large and the risk decreases. Hence, the complexity goes high and as the confidence
interval is high and the expected risk raises to high, therefore it leads to the over-fitting.
In SVM, K(x, xi) was introduced as the kernel function. In most popular functions, there are three types of functions namely Gaussian kernel, Polynomial kernel and Sigmoid kernel[18]. Here we go with Gaussian kernel function which is used more frequently.
(20) where, σ2>0, and σ2 is Gaussian kernel parameter.
Parameters of the classification model are C (parameter of th e error penalty) and Gaussian kernel parameter ÿ2. They all r equire user to specify.
3.4 Parameter analysis table
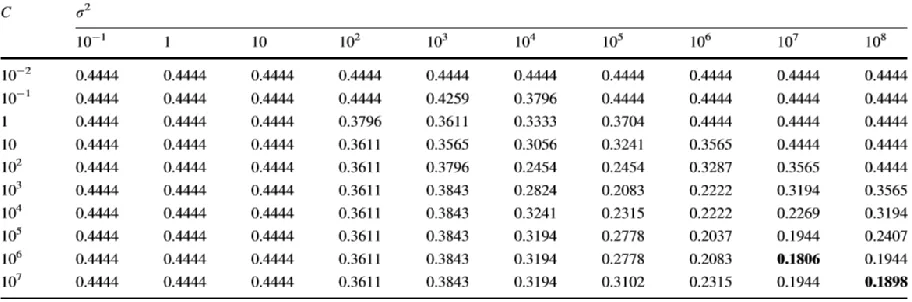
In the C - σ2 hyper plane, the local and global optimal points are defined based on the values of penalty parameters C, σ2. To estimate the generalization performance we are using 5 fold cross validation. From PIMA database [14], used benchmark diabetes dataset and introduce the parameter analysis table-1. The error rate is reduced comparatively Genetic algorithm with area conveyance model. The following results shows that MLSTSVM is performing well in both Linear and Non-Linear Gaussian Kernels comparatively other SVM classifiers.
Table 1: The parameter analysis table: the cross-validation error of (C, σ2) points for Diabetes data set
4. RESULTS
From the table 2 it is observed that the error rate is reduced comparatively Genetic algorithm with area conveyance model. The following results show that MLSTSVM is
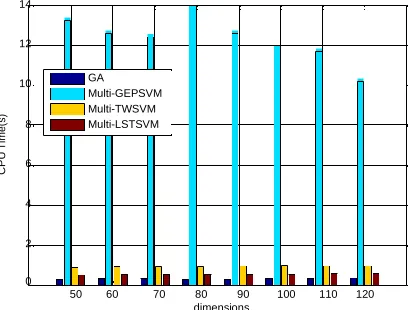
From Tables 3 and 4, It is observed that MLSTSVM not only takes the least CPU time but additionally gets the better accuracy in all cases. In Table 5, MLSTSVM shows greater performance on diabetes classification using Non linear Kernels; its cpu time is lesser. To get an instinctive perspective on the predominance of our proposed technique on diabetes database the utilization of nonlinear kernel, fig 3
and fig 4 are plotted. Fig 3 shows the acknowledgment paces of various strategies versus the dimensions and Fig 4 portrays the CPU time of various techniques time of different methods. The results of Fig 3 and Fig 4 further verify the conclusion as depicted in below figures.
Re co g n it io n r a te ( % ) 90 85 GA Multi-GEPSVM Multi-TWSVM Multi-LSTSVM 80
60 70 80 90 100 110 120
50
dimensions
Fig 3. Recognition Rates of Different Methods versus the Dimensions on Diabetes Database Using Nonlinear Kernel
14
12
10 GA
Multi-GEPSVM
T
im
e
(s
) Multi-TWSVM 8 Multi-LSTSVM
C P U 6 4 2 0
60 70 80 90 100 110 120 50
dimensions
Fig 4. The CPU Times of Different Methods on Diabetes Database Using Nonlinear Kernel
5. CONCLUSION
As part of the research work, the choice of best value selection of parameters for particular kernel becomes critical for a given amount of data. To detect a particular common disease, we can say that it is worthful to use this SVM approach with simple diagnosing measurements. Parameter selection method for kernel functions in SVM classification is chosen. The proposed strategy can be straightforwardly deal with multi-class issues. In this paper, we stretch out LSTSVM to multi-class classification issue, named as Multi-LSTSVM. MLSTSVM understands K QPPs to such an extent that the kth QPP targets ensuring the kth hyper plane is nearer to its very own class and is beyond what many would consider possible from the different class. Test results acquired on real PIMA datasets, Diabetes datasets show that our proposed MLSTSVM has practically identical or better execution. Therefore, there is some other direction of future work to apply our MLSTSVM to other pragmatic issues, for example, analyzing the images, speech recognition and text classification etc.
6 REFRENCES
[1]. C. Corinna and V. Vapnik, “Support-vector networks”, Machine learning, vol. 20, no. 3, (1995), pp. 273297.
[2]. Vladimir N. Vapnik“ Direct Methods in Statistical Learning Theory”, (2000).
[3]. J. S. Taylor, “Kernel-based learning methods”, . AI Magazine Volume 22 Number 2 (2001) Marco Peixeiro, “An Introduction to Support Vector Machines”, Data Science.
[4]. Lin, C.F., Wang, S.D.: Fuzzy support vector machines. IEEE Transactions on Neural Networks 13(2), 464–471 (2002).
[5]. Mohammad ali Bagheri. and Gholam Ali Montazer, “ Error Correcting Output Codes for multiclass classification: Application to two image vision problems”, 978-1-4673-1479-4/12/$31.00 ©2012 IEEE.
[6]. W.H.O et al., Global report on diabetes. 2018.
[7]. Raheleh Salari, Sharareh R Niakan alhori,Marjan “Conformity of Diabetes Mobile apps with the Chronic Care Model,” Volume 26, Issue1, 2019
[8]. Md. Shafiur Rahman, Shamima Akter,Awareness, Treatment, and Control of Diabetes in Bangladesh: A Nationwide Population-Based Study”, PLoS One. 2015; 10(2): e0118365 Minyechil Aleheg,Rahul Joshi& Dr. Preeti Mulay,"Analysis and Prediction of Diabetes Mellitus using Machine Learning Algorithm"Volume 118 No. 9 2018, 871-878
[9]. Niveen M. Daoud, Ola A. Qadi, Dania"Effect of Antihypertensive Agents on Biochemical Parameters in Diabetic Patients in Taif - KSA" DOI:10.23937/2377-3634/1410113.
[10]. Classification and Diagnosis of Diabetes: Standards of Medical Care in Diabetes—2018 American Diabetes Association Diabetes Care 2018; 41(Supplement 1): S13–S27. https ://doi.org/10.2337/dc18-S002.
[12]. http://care.diabetesjournals.org.
[13]. Polat, Kemal and SalihGunes, “An expert system approach based on principal component analysis and adaptive neuro-fuzzy inference system to diagnosis of diabetes disease,” Expert system with Applications, pp. 702-710, Elseivier, 2007.
[14]. D. Deng and N. Kasabov, “ On-line pattern analysis by evolving self- organizing maps”, In Proceedings of the fifth biannual conference on artificial neural networks and expert systems (ANNES), 2001, pp. 46-51.
[15]. Yueat al. “ An Intelligent Diagnosis to Type 2 Diabetes Based on QPSO Algorithm and WLSSVM,” International Symposium on Intelligent Information Technology Application Workshops, IEEE Computer Society, 2008. [16]. Platt J. C., N. Chrisianini and J. S. Taylor, “Large Margin
DAGs for Multiclass Classification”, In Advances in Neural
[17]. Gunn S. R., “Support vector machines for classification and regression”, ISIS technical report vol. 14,(1998). [18]. Chih-Chung Chang and Chih-Jen Lin,"A Library for