Using Many Cameras as One
Full text
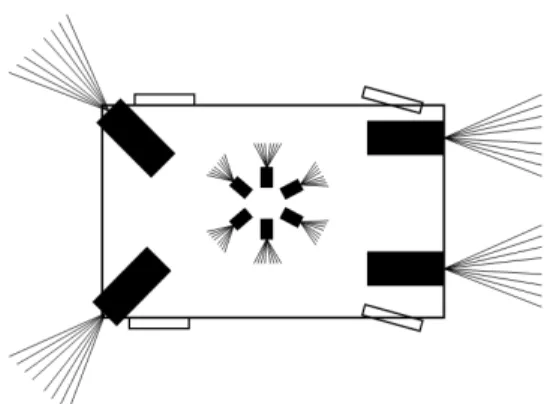
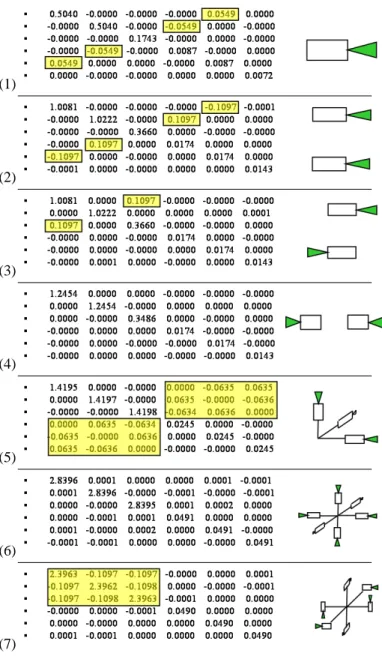
Figure
Related documents
ADD INF Miguel Flames Called up from Extended Spring Training SUB INF Kyle Holder Called up to Advanced-A Tampa SUB OF Carlos Vidal Reassigned to Extended Spring Training
Simulations show that if full liberalization in the cotton sector takes place including removal of both trade barriers and production support (along with liberalization in all
Addiction Services of Thames ValleY Grey-Bruce CommUNITY Bluewater Health, Lambton County Addiction SerVICES Choices for Change: Alcohol, Drug and Gambling Counselling Centre
The ANGDC is tasked to execute diversity requirements assigned by the Secretary of the Air Force, Under Secretary of Defense (Personnel and Readiness) and to
• Sole Use – infrastructure designed and built solely for the generator paid by annually via TNUoS.. • Shared Use – benefits multiple applicants paid by annually
Gender will not be significant factor in mean achievement scores and mean retention scores of students’ taught organic chemistry with concept maps and those taught with
The data suggested that food and fuel exports had no direct negative effect on eco- nomic growth, but rather that the presence of fuel wealth negatively affects democracy, as well
City of London | Community Energy Action Plan (2014 – 2018) 6 The current low costs for natural gas, used for space heating and water heating, slows down the payback rate for some
