Volume II, Issue X, October - 2015
110
A SURVEY - BASED ON METHODS AND
TECHNIQUES OF DATA MINING
A.Vishnu Priya Dr.K.Krishnaswari
M.E.Computer science and engineering Professor and Head of the department
Tamilnadu college of engineering Tamilnadu college of engineering [email protected] [email protected]
Abstract—Data mining is a powerful and a new field having various techniques. It converts the raw data into useful information in various research fields. Knowledge discovery in databases is a rapidly growing field, whose development is driven by strong research interests as well as urgent practical, social, and economical needs. While the last few years knowledge discovery tools have been used mainly in research environments, sophisticated software products are now rapidly emerging. Here in this paper, explained about the knowledge discovery database (KDD) and also survived the various methods of data mining and its techniques.
Index Terms—Data mining, information prediction, raw data, Knowledge discovery in databases, surveys.
I. INTRODUCTION
Data Mining or Knowledge Discovery is needed to make sense and use of data. Knowledge Discovery in Data is the non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns in data [1].Data mining consists of more than collection and managing data; it also includes analysis and prediction. People are often do mistakes while analyzing or, possibly, when trying to establish relationships between multiple features. This makes it difficult for them to find solutions to certain problems. Machine learning can often be successfully applied to these problems, improving the efficiency of systems and the designs of machines. There are several applications for Machine Learning (ML), the most significant of which is data mining. Numerous ML applications involve tasks that can be set up as supervised. In the present paper, we have concentrated on the techniques necessary to do this. In particular, this work is concerned with classification problems in which the output of instances admits only discrete, unordered values.
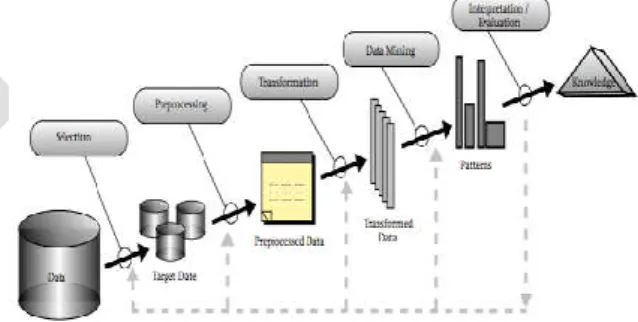
Figure 1 Data Mining and the KDD Process(Source: Fayyad, et.al., 1996)
Based on figure 2, KDD process consists of iterative sequence methods as follows [7, 9]:
1. Selection: Selecting data relevant to the analysis task from the database
2. Preprocessing: Removing noise and inconsistent data; combining multiple data sources
3. Transformation: Transforming data into appropriate forms to perform data mining
4. Data mining: Choosing a data mining algorithm which is appropriate to pattern in the
data; Extracting data patterns
Volume II, Issue X, October - 2015
111
redundant or irrelevant patterns; Translating the useful patterns into terms that human understandable
II. Related work:
The survey based on the applications of data mining to organizational knowledge management for effective capturing, storing and retrieving, and transferring knowledge.The review concentrate on categories into four main groups: (i) knowledge resource; (ii) knowledge types and/or knowledge datasets; (iii) data mining tasks; and (iv) data mining techniques and applications used in KM.
Table 1 shows the tabulation on data mining and its techniques
Auth ors
Knowle dge Resourc es
Knowl edge Types
DM Tasks
DM techniques /
Applicatio ns
Lavra cet al. (2007 )
Healthca re
Public Health Data •The health-care provide rs databas e •The out-patient health-care statistic s databas e •The medical status Databa se
Classifi cation and clusteri ng
Clustering Methods: •Agglomer ative Classificati on; •Principal Component Analysis; •The Kolmogoro v-Smirnov Test; •The Quantile Range Test and Polar Ordination Classificati on C4.5
Hwan g et al. (2008 )
Healthca re (Clinical Diagnosi s)
• Knowle dge Conver sion
Depend ency Modeli ng
Data Mining Tool IBM Intelligent Miner
and Transfe r • Knowle dge Measur ement
Data Mining Techniques •Associatio n Analysis •Sequential Patterns Analysis Knowledge Manageme nt System (KMS) for Disease Classificati on Liao,
Chen & Wu (2008 )
Retailin g
Knowle dge Extracti on Custom er Knowle dge to product line and brand extensi on
Depend ency Modeli ng; Clusteri ng
Apriori Algorithms (Associatio n Analysis) K-means (Cluster Analysis)
Chen g, Lu &She u (2009 )
Financia l
• Knowle dge Sets – strings of data, models, parame ters, and reports • Knowle dge Sharing Process es to a Corpor ate Bond Classifi cation
Classifi cation Clusteri ng
•HybridSO FM/LVQ Classifier for Bond Rating. The Self-Organizing Feature Map (SOFM) o The Learning Vector Quantizatio n (LVQ) • Ontology of
Volume II, Issue X, October - 2015 112 nt System (FKMS) Prototype for Financial Research Purposes Li, Zhu & Pan (2010 )
Small & Middle Business es (SMBs): Food Compan y Knowle dge Seedin g &Kno wledge Cultiva ting Classifi cation
• Extension Theory - Extenics • Extension Data Mining (EDM) is combining Extenics with Data Mining Li et
al. (2010 ) Food Supply Chain Network s Knowle dge Base classfic ation Decision Tree Neural Network Early Warning and Proactive Control Systems (EW&PC) Cantu &Ceb allos (2010 ) Entrepre neurial Science Researc h Assets Classifi cation Data Mining Agents •Reasoning •Pattern Recognitio n Knowledge -based System (KBS) Knowledge and Information Network (KIN) Approach Semantic Web Technologi es Wu et al. (2010 )
Business KM Styles & KM perfor Classifi cation Bayesian Network Classifier Rough Set
mance Theory Liu & Lai (2011 ) Collabor ation and Teamwo rk Task (Worker ’s Log & Docume nts) Knowle dge Sharing Knowle dge Graph Knowle dge Flows (KFs) Clusteri ng Process Mining Technique Knowledge Flow Mining Group-based Knowledge Flows (GKFs) Ur-Rahm an& Hardi ng (2012 ) Construc tion Industry Textual Databa ses (Textua l Data Format s) Depend ency Modeli ng; Clusteri ng Text mining • Clustering •Apriori Association Rule Mining Multiple Key Term Phrasal Knowledge Sequences (MKTPKS)
Table 2. : Comparative Study of Different Algorithms Implemented to Reduce Scalability Issue
A) Clustering methods
Volume II, Issue X, October - 2015 113 Filtering Recomme ndation Algorith m Based on User Clusterin g and Item Clusterin g [2010] tradition al CF Quality improve ment More accurate and more scalable than tradition al
Error m m is to be handle d 3. Collabora tive Filtering Recomme ndation Algorith m Based on Cluster [2011]
Combin ation of CF and clusterin g to improve scalabili ty and sparsity problem Cold start Only algorith m is propos ed For better perfor mance, the cold start and privacy is to be taken into conside ration 4..Scaling
-up Item-based Collabora tive Filtering Recomme ndation Algorith m based on Hadoop [2011] Minimiz e commun ication cost Scalable Efficient perform ance Scalab ility to be Handle d more effecti vely Speed up Iso efficien cy On algorit hm side, optimiz e allocati on and executi on Process to be include d On applica tion side, scalabil ity is to be improv ed
B) Other methods
Title of the paper Conclu sion Draw backs Perfor mance Future work 1.Hybrid Recomm ender System with Temporal Informati on [2012] Scalabl e & Sparsit y and cold start proble ms are covered
Privac y issue is not handle d Mean Absolut e Error and Recom mendati on time Geograph ic informati on can be considere d and Improvin g time stamping for better performa nce RS for N-screen service 2.An Improved Profile based CF Scheme with Privacy [2011] Improv ed perfor mance And accurac y More scalabl e Sparsit y proble m Accura cy and quality are not so good compa red to CF schem e Mean Absolut e Error
Volume II, Issue X, October - 2015
114
III CONCLUSION
Data mining is a “decision support” process in which we search for patterns of information in data. Data mining techniques such as classification, clustering, prediction, association and sequential patterns etc. The commercial, educational and scientific applications are increasingly dependent on these methodologies. Decision trees are a reliable and effective decision making technique which provide high classification accuracy with a simple representation of collected KDD. This paper surveys different data mining techniques that can be used to efficiently and accurately capture user behavior. The paper also presents guidelines that show which techniques may be used more efficiently according to the task implemented by the application.
References
[1] An, X. & Wang, W. (2010). Knowledge management technologies and applications:
A literature review. IEEE, 138-141.
doi:10.1109/ICAMS.2010.5553046
[2] Berson, A., Smith, S.J. & Thearling, K. (1999). Building Data Mining Applications for CRM. New York: McGraw-Hill.
[3] Cantú, F.J. & Ceballos, H.G. (2010). A multi agent knowledge and information network approach for managing research assets. Expert Systems with Applications,
37(7), 5272-5284.
doi:10.1016/j.eswa.2010.01.012
[4] Cheng, H., Lu, Y. & Sheu, C. (2009). An
ontology-based business intelligence
application in a financial knowledge management system. Expert Systems with
Applications, 36, 3614–3622.
Doi:10.1016/j.eswa.2008.02.047
International Journal of Data Mining & Knowledge Management Process (IJDKP) Vol.2, No.5, September 2012
[5] Dalkir, K. (2005). Knowledge
Management in Theory and Practice. Boston: Butterworth-Heinemann.
[6] Dawei, J. (2011). The Application of
Date Mining in Knowledge
Management.2011 International Conference on Management of Commerce and e-Government, IEEE Computer Society, 7-9. doi: 10.1109/ICMeCG.2011.58
[7] Fayyad, U., Piatetsky-Shapiro, G. & Smyth, P. (1996). From Data Mining to Knowledge Discovery in Databases.AI Magazine, 17(3), 37-54.
[8] Gorunescu, F. (2011). Data Mining: Concepts, Models, and Techniques. India: Springer.
[9] Han, J. &Kamber, M. (2012). Data Mining: Concepts and Techniques. 3rd.ed. Boston: Morgan Kaufmann Publishers. [10] Hwang, H.G., Chang, I.C., Chen, F.J. & Wu, S.Y. (2008). Investigation of the
application of KMS for diseases
classifications: A study in a Taiwanese hospital. Expert Systems with Applications, 34(1),725-733.
doi:10.1016/j.eswa.2006.10.018
[11] Lavrac, N., Bohanec, M., Pur, A., Cestnik, B., Debeljak, M. &Kobler, A. (2007).Data mining and visualization for decision support and modeling of public health-care resources.Journal of Biomedical
Informatics, 40, 438-447.
doi:10.1016/j.jbi.2006.10.003
[12] Li, X., Zhu, Z. & Pan, X. (2010).
Knowledge cultivating for intelligent
decision making in small &middle
Volume II, Issue X, October - 2015
115
product line and brand extension in
retailing.Expert Systems with
Applications,34(3),1763-1776.doi:10.1016/j.eswa.2007.01.036
[15] Liao, S. (2003). Knowledge
management technologies and applications-literature review from 1995 to 2002. Expert Systems with Applications, 25, 155-164. doi:10.1016/S0957-4174(03)00043-5
[16] Liu, D.R. & Lai, C.H. (2011). Mining group-based knowledge flows for sharing
task knowledge.Decision Support
Systems,50(2), 370-386.
doi:10.1016/j.dss.2010.09.004
[17] Lee, M.R. & Chen, T.T. (2011). Revealing research themes and trends in knowledge management:From 1995 to 2010. Knowledge-Based
Systems.doi:10.1016/j.knosys.2011.11.016 [18] McInerney, C.R. & Koenig, M.E. (2011). Knowledge Management (KM)
Processes in Organizations:Theoretical
Foundations and Practice. USA: Morgan & Claypool
Publishers.doi:10.2200/S00323ED1V01Y20 1012ICR018
[19] McInerney, C. (2002). Knowledge Management and the Dynamic Nature of Knowledge.Journal of the American Society for Information Science and Technology, 53(12), 1009-1018.doi:10.1002/asi.10109 [20] Ngai, E., Xiu, L. &Chau, D. (2009). Application of data mining techniques in
customer relationship management: A
literature review and classification. Expert Systems with Applications, 36, 2592-2602. doi:10.1016/j.eswa.2008.02.021
[21] Ruggles, R.L. (ed.). (1997). Knowledge Management Tools. Boston: Butterworth-Heinemann.
[22] Sher, P.J. & Lee, V.C. (2004). Information technology as a facilitator for enhancing dynamic capabilities through knowledge management. Information & Management, 41, 933-945.
doi:10.1016/j.im.2003.06.004
[23] Tseng, S.M. (2008). The effects of
information technology on knowledge
management. Expert Systems with
Applications, 35, 150-160.
doi:10.1016/j.eswa.2007.06.011
[24] Ur-Rahman, N. & Harding, J.A. (2012).
Textual data mining for industrial
knowledge management and text
classification: A business oriented approach. Expert Systems with Applications, 39, 4729- 4739. doi:10.1016/j.eswa.2011.09.124 [25] Wang, F. & Fan, H. (2008). Investigation on Technology Systems for
Knowledge Management.IEEE, 1-4.
doi:10.1109/WiCom.2008.2716
[26] Wang, H. & Wang, S. (2008). A knowledge management approach to data mining process for business intelligence. Industrial Management & Data Systems, 108(5), 622-634.
[27] Wu, W., Lee, Y.T., Tseng, M.L. & Chiang, Y.H. (2010). Data mining for exploring hidden patterns
between KM and its
performance.Knowledge-Based Systems,
23, 397-401.
doi:10.1016/j.knosys.2010.01.014.
[28] Farman Ullah, Ghulam Sarwar, Sung Chang Lee, ”Hybrid Recommender System with Temporal Information”, (ICOIN), International Conference on Information Networking, IEEE 2012, pp. 421-425
[29] Siavash Ghodsi Moghaddam, Ali
Selamat, ”A Scalable Collaborative
Recommender Algorithm Based on User
Density- Based Clustering”, 3rd
international conference on Data Mining and
Intelligent Information Technology
Applications (ICMiA), IEEE 2011, pp. 246-249
Volume II, Issue X, October - 2015
116
[31] Xingyuan Li, ”Collaborative Filtering Recommendation Algorithm Based on
Cluster”, International Conference on
Business Computing and Global Information (BCGIN), IEEE 2011, pp. 645-648
[32] Jing Jiang, Jie Lu, Guangquan Zhang, Guodong Long, ”Scaling-up Item-based Collaborative Filtering Recommendation Algorithm based on Hadoop”, IEEE World Congress on SERVICES, 2011, pp. 490-497 [33] Gilda Moradi Dakhel, Mehregan Mahdavi, ”A New Collaborative Filtering Algorithm Using K-means Clustering and
Neighbors Voting”, International
Conference on Hybrid Intelligent Systems (HIS), IEEE 2011, pp. 179-184
[34] Kyung-Yong Chung, Daesung Lee and
Kuinam J. Kim, ”Categorization for
grouping associative items using data
mining in item-based collaborative
filtering”, International Conference on
Information Science and Applications
(ICISA), IEEE 2011, pp. 1-6
[35] Joseph A. Konstan John Riedl, ”Recommender systems: from algorithms to user experience”, User Modeling and User-Adapted Interaction, 2012, Vol. 22, pp. 101-123
[36] Fatih Gedikli, Faruk Bagdat, Mouzhi Ge, and Dietmar Jannach, ”RF-REC: Fast
and Accurate Computation of
Recommendations based on Rating
Frequencies”, IEEE 13th Conference on
Commerce and Enterprise Computing
(CEC), 2011, pp. 50-57
[37] Mozhgan Tavakolifard, Kevin C.
Almeroth, ”Social Computing: An
Intersection of Recommender Systems,
Trust/Reputation Systems, and Social
Networks”, IEEE Network, July/August 2012, Vol. 26, No. 4, pp. 53-58
[38] SongJie Gong, ”A Collaborative Filtering Recommendation Algorithm Based
on User Clustering and Item Clustering”, Journal of Software, , July 2010, Vol. 5, No. 7
A. Vishnu Priya
completed her
B.E(computer
science and
engineering) in
2014 from K.S.R. College of Engineering under Anna
University,Coimbatore. Currently she is pursuing M.E.( computer science and engineering) in Tamilnadu College of
Engineering under Anna
University,Chennai.
Mrs.Dr.K.Krishneswa ri completed her B.E
(computer science
and engineering) in 2000 from tamilnadu college of engineering under Bharathiyar
University, Coimbatore.M.E.(software
engineering) in 2005 from sri ramakrishna engineering college under Anna University,
Chennai. Ph.D degree from Anna
University, Coimbatore. She is working as an assistant professor and head of the department of computer science and
engineering at tamilnadu college of
engineering, Coimbatore. She is a member of CSI, ISTE. Her research areas include Image processing, Pattern recognition, Biometrics and having 13 years of teaching experience in engineering colleges and also have published 30 papers in journal.