2018 International Conference on Information, Electronic and Communication Engineering (IECE 2018) ISBN: 978-1-60595-585-8
DNN-based Sound Source Localization Method with Microphone Array
Yan-kun HUANG, Xi-hong WU
and Tian-shu QU
*Key Laboratory on Machine Perception (Ministry of Education), Speech and Hearing Research Center, Peking University, Beijing, China
*Corresponding author
Keywords: DNN, SRP-PHAT, Microphone array, Sound source localization.
Abstract. Sound source localization based on microphone array is a hot topic in the field of speech
signal processing in recent years. In this paper, a DNN-based sound source localization method is proposed, which can compensate the phase delay and intensity variation of received microphone signals in the process of transmission to estimate corresponding sound source signals by means of deep learning, and make full use of these information to locate sound source. Compared with traditional methods such as SRP-PHAT and transfer function based method, it has better directionality pattern and noise immunity in localization. Finally, we make the model robustness experiment, which proves that the robustness of the DNN-based method is better than transfer function based method, which can work in real environment with noises.
Introduction
Sound source localization (SSL) based on microphone array [1] is a hot research field which plays an important role in videoconferencing [2], robot localization [3], and speech enhancement. In recent years, the methods for SSL in general can be divided into the following five categories: steered beamforming based, time difference of arrival (TDOA) estimation based, high-resolution spectrum estimation based, transfer function (TF) based and deep neural network (DNN) based approaches.
First, the method based on steered beamforming such as steered response power with phase transform (SRP-PHAT) [4-8] is to compensate the time delay between the received microphone signals by beamforming, and calculate the steered response power to locate sound source. Second, the method based on TDOA estimation such as the generalized cross correlation (GCC) [9-11] is to estimate TDOA with generalized cross correlation function first and then estimate the sound source location according to the time difference and the spatial geometric position of the microphone array. Third, the method based on high resolution spectrum estimation such as multiple signal classification (MUSIC) [12-14] is to decompose the covariance matrix of signals, so as to obtain the signal subspace and the noise subspace, which can be used to estimate the direction of arrival (DOA) finally. However, these traditional methods mainly use the time difference while in fact the information of intensity difference is beneficial to SSL with scattering. The fourth type of localization method based on TF [15-17] is to locate the sound source by inverse filtering operation with TFs measured actually, which are the transmission characteristics of sound signals from a possible sound source location to a microphone. However, measuring accurate TFs is a very difficult task which needs to broadcast the specified signals in a noiseless environment where the noiseless environment is not satisfied in the actual situation. When there are noises, the measured TFs are very poor, even collapse. Recently, many scholars have focused on DNN based methods [18-20], which need to extract features in advance, and then use neural network to learn the mapping from features to DOA. In addition, since these methods are to learn the mapping from features to DOA, they can’t restore the sound source signal directly.
The rest of this paper is arranged as follows. Section 2 details the motivation, training stage and testing stage about the proposed method. In Section 3, some experimental settings used in the paper like the distribution of microphone array are introduced and we conduct localization experiments and robustness experiments to evaluate the localization performance and robustness of the proposed model. Finally, conclusions are drawn in Section 4.
Localization Method
Modeling with DNN. When the microphone array is attached to a rigid body, the received signal is
different from the source signal. The differences can be categorized into time delay, phase delay and intensity variance. Time delay is caused by the distance from the source to the microphone, while the phase delay and the intensity variance are caused by the scatter body, which will provide the additional information for SSL.
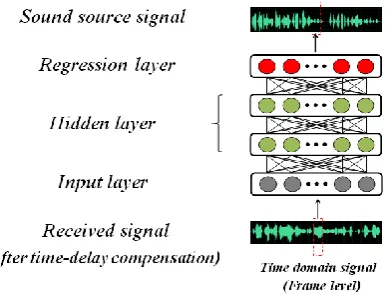
[image:2.595.202.396.404.553.2]The traditional method SRP-PHAT is carried out by the time delay compensation, completely dependent on time delay difference, and ignoring the phase delay difference and intensity difference between microphone signals, which leads to bad performance when locating with microphone array on scatter body. As for this problem, TF-based method solves it very well but when the microphone array is used in another environment with different noise and reverberation, changeless TFs are unable to work in the new environment because they are not adaptive. Therefore, we can use DNN to learn the transmission characteristics adaptively and map received microphone signals to the sound source signals, which can be considered as a regression problem with DNN. When modeling, the path from one possible sound source location to one microphone can be considered as one transmission path, which should be modeled with one DNN. Therefore, if having M microphones and S sound source locations, we require M×S DNNs to model them.
Figure 1. The structure of DNN.
For methods based on scanning, the time delay can be obtained by many methods like GCC or calculated directly through dividing the distance between the known scanned location and the microphone by the sound velocity, which is the pre-information, so we do not need to use DNN to learn it, but use it directly to reduce the difficulty of training DNN. Therefore, we can directly make the operation of time delay compensation and use a frame of signals after compensation as the input of DNN, and then use the true sound source signal corresponding to the input frame as the ground truth of DNN to train it so as to learn the phase delay and intensity variation in the process of transmission in a specific path, where the structure of DNN is shown as Figure 1. With a large number of training data, DNN can learn the transmission characteristics of sound signals in a specific path and then the sound source signals can be restored from the received microphone signals through DNNs, and finally the consistency of the multi-channel estimated sound source signals can be used to locate sound source.
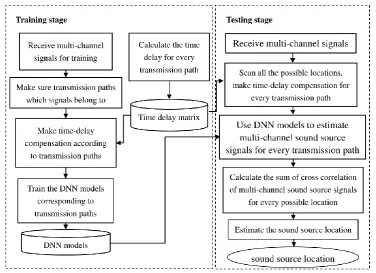
DNN-based Method. The testing stage of the proposed method is also a scanning process, which
estimated location. It is shown on the right side of Figure 2. In detail, for each possible sound source location 𝑠, there are three steps as follow.
Figure 2. The framework of the proposed method.
The first step is to calculate the time delay according to the distance between each microphone and the scanned location, and then make time delay compensation for each received signal, which can be represented as
( ) ( ),
ls l ls
x n x n l1,...,M, (1) where 𝑥𝑙 denotes the signal recorded by microphone 𝑙 and 𝑥̃𝑙𝑠 represents the signal after time delay compensation. 𝜏𝑙𝑠 denotes the time delay between possible sound source location 𝑠 and microphone 𝑙 l, which is calculated by dividing the distance between possible sound source location 𝑠 and microphone 𝑙 by sound velocity.
The second step is to input the frame-level time-domain signal after time delay compensation to the corresponding DNN. We use DNN to compensate the phase delay and the intensity variation, and then output the estimated sound source signal, which can be represented as
ˆls n DNNls(x nls( )),
y l1,...,M, (2)
where ˆyls denotes the estimated sound source signal, and DNNlsrepresents the DNN modeled for the transmission characteristics of sound signals between the microphone 𝑙 and sound source location 𝑠. The structure of DNN in this paper is shown as Figure 1.
The third step is to calculate the sum of cross correlation coefficients between multi-channel estimated sound source signals, which is defined as
1 1
, ˆ , ˆ M M
k l
ks ls k
SCorr s Corr y n y n
(3)where Corr
, denotes the cross correlation function and SCorr s
represents the sum of crosscorrelation coefficients corresponding to sound source location s.
respectively calculate the sum of correlation coefficients about them, and it's considered that the possible sound source location s corresponding to the largest one is the estimated sound source location 𝑠̂, which can be represented as
arg max
ˆ .
s
s SCorr s
(4)
Experiments
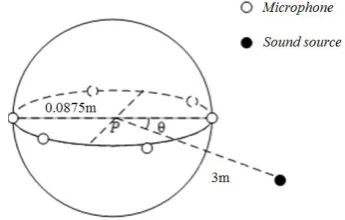
Settings. The microphone array used in the experiments includes six microphones, evenly distributed
[image:4.595.209.382.273.383.2]on the horizontal plane of a spherical rigid body with a radius of 0.0875m, that is, 60 degrees apart between adjacent microphones, as shown in the Fig.3. The sound source locations used in the paper are 3 meters away from the center of the sphere with the range from 0° to 360° on the horizontal plane and the resolution is 5°, so there are 72 possible sound source locations in all.
Figure 3. The distribution of microphone array.
In the experiments, we use four-layer feed-forward neural networks with 4096 nodes since the frame size in the experiments is 4096 points where the sampling rate is 48kHz. For each neuron, tanh function is used as the activation function. However, the last layer is a regression layer without activation function. In addition, the Adam algorithm is used as the optimization algorithm and mean square error (MSE) is used as the loss function.
The training data and testing data used in the experiments are simulated by TFs which are calculated by the spherical head model [21] based on the nature of rigid ball. The received signals can be obtained by convoluting the sound source signals with the TFs. In order to make the proposed method suitable for broadband DOA estimation, the synthetic white Gaussian noises are used as training data in the experiments. As for testing data, white Gauss noises and speech signals in TIMIT database are used to evaluate the performance of the proposed methods, SRP-PHAT [4], and TF-based method [17]. In order to evaluate the noise immunity and robustness of these methods in different SNRs, we uses the noisy signals in different SNRs (-40dB~25dB) as testing data, in which the type of noises is white Gauss noise as well.
Evaluation Metric. The mean absolute angle error (MAAE) is used as evaluation metric in the
paper, which represents the mean angle error of all frames in the testing data, which is defined as
1 , n
i i e MAAE
n
(5), 180
,
360 , 180
ˆ ˆ
ˆ ˆ
i i i i
i
i i i i
e
(6)
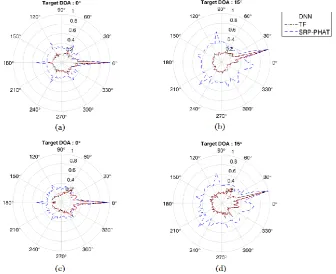
Localization Experiment. In this experiment, we compare the performance between the proposed method, TF-based method and SRP-PHAT. First, we use the white Gaussian noises and speech signals to locate sound source to evaluate the directionality pattern of these methods.
Figure 4. The directionality pattern of the three methods for white Gaussian noise ((a),(b)) and speech signal ((c),(d)).
By observing directionality pattern of these methods for different kinds of signals as shown in Figure 4, it can be seen that the directionality pattern of the DNN-based method is always sharper than that of SRP-PHAT for the two kinds of signals since it make full use of phase difference and intensity difference between received signals. As for the DNN-based method, the directionality pattern for the white Gaussian noises is better than that for the speech signals because the model is trained with the white Gaussian noises. It is worth noting that the directionality pattern of TF-based method and DNN-based method is similar, which shows the proposed method have learnt phase difference and intensity difference successfully. Therefore, we make another experiment to evaluate the performance of noise immunity for these methods.
[image:5.595.60.538.609.733.2]As for the performance of noise immunity, it can be seen from Fig.5 that the DNN-based method is better than SRP-PHAT and TF-based method. As for the white Gaussian noises, the error of localization using DNN-based method occurs when the SNR reaches -15dB, while if we use the traditional methods to locate, it appears early in -12dB. In conclusion, the performance of noise immunity is improved by 3dB.
Figure 5. The MAAE of the three methods for white Gaussian noises (a) and speech signals (b) in different SNRs.
Model Robustness Experiment. In the above experiment, the model trained by clean received
comparing with TF-based method. In the experiment, the training data for DNN-based method are white Gaussian noises in different SNRs (-25dB~10dB) and the TFs are calculated using maximum length sequence in the same SNR situations. The performance of localization with different models obtained in different SNRs is shown as Fig.6. The proposed method fails when SNR reach -24dB while TF-based method fails about -20dB. It can be concluded that this model can still be trained and applied in noisy environment and has better robustness. Therefore, the proposed method can be used in the noisy environment, in which the received multi-channel signals are used as the input of DNNs and the result of beamforming is used as the ground truth of the DNNs. By this mean, the model can be used in the real environment and adapted to the change of the environment.
Figure 6. The MAAE of the models obtained in different SNRs for TF-based method (a) and DNN-based method (b).
Summary
In conclusion, the proposed method can learn the phase delay and intensity variation in the process of transmission and make full use of phase difference and intensity difference between received microphone signals to locate sound source. Compared with traditional methods such as SRP-PHAT and TF-based methods, it has better noise immunity and directionality pattern, where the performance of noise immunity is improved by 3dB. Finally, it is proved by model robustness experiment that the model have better robustness than the TF-based method, which can be popularized and applied in the actual environment with noises.
Acknowledgement
This work is supported by the National High Technology Research and Development Program of China (2015AA016306), the National Natural Science Foundation of China (No.61175043, No.61421062), and the High-performance Computing Platform of Peking University.
References
[1] D. P. Jarrett, E. A. P. Habets, and P. A. Naylor, Theory and Applications of Spherical Microphone Array Processing, Springer International Publishing, 2017.
[2] H. Wang and P. Chu, Voice source localization for automatic camera pointing system in videoconferencing, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Munich, Germany, 1997, vol. 1, pp. 187-190.
[3] J. M. Valin, F. Michaud, J. Rouat, and D. Letourneau, Robust sound source localization using a microphone array on a mobile robot, IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 2003, vol. 2, pp. 1228-1233.
[5] H. Do, H. F. Silverman, and Y. Yu, A real-time srp-phat source location implementation using stochastic region contraction(src) on a large-aperture microphone array, International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 2007, I-121 - I-124.
[6] J. P. Dmochowski, J. Benesty, and S. Affes, A generalized steered response power method for computationally viable source localization, IEEE Transactions on Audio Speech and Language Processing, 2007, vol. 15, no. 8, pp. 2510-2526.
[7] D. N. Zotkin and R. Duraiswami, Accelerated speech source localization via a hierarchical search of steered response power, IEEE Transactions on Speech and Audio Processing, 2004, vol. 12, no. 5, pp. 499-508.
[8] M. Cobos, A. Marti, and J. J. Lope, A modified srp-phat functional for robust real-time sound source localization with scalable spatial sampling, IEEE Signal Processing Letters, 2010, vol. 18, no. 1, pp. 71-74.
[9] C. Knapp and G. Carter, The generalized correlation method for estimation of time delay, IEEE Transactions on Acoustics Speech and Signal Processing, 2003, vol. 24, no. 4, pp. 320-327.
[10] G. C. Carter, Coherence and time delay estimation, Proceedings of the IEEE, 2005, vol. 75, no. 2, pp. 236–255.
[11] G. C. Carter, Time delay estimation for passive sonar signal processing, IEEE Transactions on Acoustics Speech and Signal Processing, 1981, vol. 29, no. 3, pp. 463- 470.
[12] R. O. Schmidt, Multiple emitter location and signal parameter estimation, IEEE Transactions on Antennas and Propagation, 1986, vol. 34, no. 3, pp. 276-280.
[13] P. Stoica and A. Nehorai, Music, maximum likelihood, and cramer-rao bound, IEEE Transactions on Acoustics Speech and Signal Processing, 1989, vol. 37, no. 5, 720-741.
[14] B. D Rao and K. V. S Hari, Performance analysis of root-music, IEEE Transactions on Acoustics Speech and Signal Processing, 1989, vol. 37, no. 12, 1939-1949.
[15]F. Keyrouz, Y. Naous, and K. Diepold, A new method for binaural 3-d localization based on hrtfs, International Conference on Acoustics, Speech and Signal Processing, Toulouse, France, 2006.
[16] J. A. Macdonald, A localization algorithm based on head-related transfer functions. Journal of the Acoustical Society of America, 2006, vol. 123, no. 6, p. 4290.
[17] T. Song, J. Chen, D. B. Zhang, T. S. Qu, and X. H. Wu, A sound source localization algorithm using microphone array with rigid body, the 22nd International Congress on Acoustics, Buenos Airs, Argentina, 2016, vol. 352.
[18] R. Takeda and K. Komatani, Sound source localization based on deep neural networks with directional activate function exploiting phase information, International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 2014, pp. 405-409.
[19] X. Xiao, S. K. Zhao, X. H. Zhong, D. L. Jones, E. S. Chng, and H. Z. Li, A learning-based approach to direction of arrival estimation in noisy and reverberant environments, International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Queensland, Australia, 2015, pp. 2814-2818.
[20] R. Takeda and K. Komatani, Discriminative multiple sound source localization based on deep neural net-works using independent location model, Spoken Language Technology Workshop, San Diego, CA, USA, 2016, pp. 603-609.