2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
Evaluation of Bank Slopes Stability Based on
Random Ants Clustering Algorithm
Yang YANG
1,a, Hai-feng XU
1,b*,
Zhuo LI
1, Zhi-hao YIN
1and Yong-jun HE
21Nanjing Hydraulic Research Institute, Dam Safety Management Department, Nanjing,
China
2Ministry of Water Resources of the PRC, Dam safety management center, Nanjing,
China
a[email protected], b[email protected]
*Corresponding author
Keywords: Slopes stability, Clustering Algorithm, Random Disturbance.
Abstract. There are many factors affect the stability of bank slopes, each of them is
associated and coupled with others. The analysis of slopes stability can be achieved by the method of effect-factors analogy and cluster analysis. Traditional cluster analysis is difficult to obtain the stable global optimal solution, since the results are sensitive to the initial cluster center and the order of sample input. Conventional ants clustering algorithm can get an appropriate result, by simulating the ants’ intelligent behavior of transportation. Consequently, in this paper a method of ants clustering algorithm base on random disturbance is proposed which can gain the cluster analysis of bank slopes through guiding the ants cluster by the accumulation and change of ant pheromones. The results, compared with conventional cluster analysis method, simulated annealing algorithm method and conventional ant clustering algorithm, shows that this method is effective and convenient to accomplish the analysis of bank slopes.
Introduction
The bank slopes stability evaluation and deformation prediction is a fundamental issue in slopes engineering research [1, 2]. With the geological changes and the impact of external environment, bank slopes have a complex geological structure and uneven shape, the stability is relative. Most projects indicated that not only bank slopes stability is decided by own intensity, but also by internal structure and internal stress condition. The factors are numerous, relates complex between each one and connection coupling. How to get the accurate evaluation of bank slopes stability is a multiple perspectives complex question.
clustering results are stable. Ants clustering is a better algorithm [3,4], which simulates the ants heap of their bodies and the behavior of classification of their larvae, according to the similarity of the object, that ants randomly lift, carry, and drop objects, eventually achieve clustering [5]. The essence of this algorithm is to use groups intelligent, they accumulated experience and knowledge. The individual makes intelligent choices through the acquisition of this experience, in turn, promote the accumulation of such experiences.
In this paper, the algorithm for clustering based on principle of ants solve the TSP problem, by simulating the accumulation and sharing, to guide the ants to complete classification [6]. The random perturbations prevent avoids the ants from into a local optimum; ultimately promote the ants him to achieve the purpose of clustering. The paper takes the slopes monitoring data from the Three Gorges as an example, gave the comparison of the results with other methods, and illustrates the advantage of random disturbance ant-cluster algorithm.
Random Ants Clustering Algorithm Model
Ants Clustering Algorithm
The proposed of ants’ algorithm [7] inspired by the groups behavior of rants in nature, which is a groups intelligent search algorithm and makes full use of similarity between the ant searching for food with the traveling salesman problem. Based on the principle of ant foraging process, the TSP problems can be solved. Ants will sow the pheromones in their path; the later ants are more willing to choose to go the path of high pheromone. This algorithm can be simply described as: There are n cities, starting from a city as the first city, visit all other cities once (only once) , then back to the first city and to find a shortest path. Pheromone matrix and the distance matrix is important matrix, which recorded the pheromone quantity and the distance between the every two cities. The core issues of ant algorithm are:
The next city selection rule, when located in city i, the probability ant k select city j as the next city is:
( )
( )
,
( )
( )
0, others
aij ij
k a
k
ij ij
ij
s allowedk
t
t
j
allowed
t
t
p
β
β
τ
η
τ
η
∈
∈
=
(1)Where allowedk record the cities ant k has not visited. ( )τij t is the pheromone between city i and j. ais the degree of influence of ( )τij t for ant’s selection. ( )ηij t is expectations from city i to j, ηij( ) 1/t = dij.dij is distance between the two cities.βis influence of ( )ηij t to
ant’s selection.Pheromone and the distance co-determine the probability of ant’s selection.Parametersa,βhave played a role in weight.
Pheromone matrix update rule, each update pheromone between the two cities isτij:
( ) (1 ) ( 1)
ij t ij t ij
τ = −ρ τ − + Δτ (2)
1 n
k
ij ij
k
τ τ
=
Δ =
Δ (3), pass
0 , not pass
k k ij
Q
ant k ij L
ant k ij
τ
Δ =
(4)
Where Lk is length of the path traversed by ant k, Q is a total amount of pheromone a ant taken once.
Pheromones is ant’s experience of on the path which traversed by ant. So through each ant pheromone accumulation and format into group’s experience about the path, then, other ants can share these experiences and get better path selection. Through the continuous accumulation, selection by ants, finally reaches the evolution of group intelligence and obtain the best path.
Ant Clustering with Random Disturbance
The clustering problem can be described as: a data set is divided into several categories, to make the largest possible within-class similarity and the similarity between classes as small as possible. In accordance with the principle of ant algorithm for TSP problem, we can use ant algorithm for classification, For each complete of classification, update the pheromone matrix. A sample will be classified as a category, relying on pheromone matrix and a probability of random selection, and avoid totally dependent on pheromone.
When form a random classification, there is higher pheromone intensity. In order to avoid falling into local minima results, adding random disturbances to each cluster to enhance the out of local minima. After several iterations, when clustering unchanged, then the clustering is assumed the optimal clustering, and the can be obtained in the final. The search algorithm program code can be showed as follow:
Set the number of samples is U, dimension is W, number of ant is K, maximum number of iterations is T, total pheromone is Q. The data will be separated into N categories.
Initialize pheromone matrix tau=[τun U N] × in [0,0.1], proportion of the depletion of
pheromone is ρ, probability of classification is p, the probability of random perturbation is r.
For t=1,2,…,T (the t time searches).For k=1,2,…,K (the ant k in the search).For u=1,2,…,U (classify the uth sample).Classified by largest pheromone in accordance with the probability P.Return back.
Random Classified In accordance with the probability of 1- P.
Calculate K fitness of clustering results, set into the pre-K fitness, Take the biggest pre-K categories.
Random changes classification of certain sample in accordance with the probability R, when the corresponding fitness increases, the replacement category.
Calculate K fitness of clustering results,Update pheromone matrix with the best 2 clustering results.
2 1
f cen ter 1
1
( , )
-( , )
fitn ess 1
W
i j iw jw
w F n n f N k n n
d o o o o
L d o o
L = = = = = =
( ) (5)where ( , )d o oi j is distance betweenoiandoj.Ln is nth class’s deviation sum of squares. centern
o is cluster center;the sample number of class is n. fitnessk is kth ant fitness. Each of the circle, get K fitness values. Pheromone update in Step 7 by the formula(2-4), updating pheromone matrix with the best 2 clustering results to faster convergence. Random classified in Step 4 is to get a random numbers p between 0 and 1, when p> P, set sample into one class randomly. Random perturbation in step 6 enable the algorithm to avoid confined to one a local clustering result, and get the ability to “Innovation”. R describes the probability of random disturbance, when the start, a lot of information is unknow,to accumulate the experience (pheromone matrix) is the most important, R can take a relatively small. when get on better results, the “Innovation” become important, disturbance and variation should be strengthened, R can take a relatively large.
When need to classify a large number of samples, it can be changed to ant classification process in parallel classification. That all ants selected a sample for starting classification randomly, and then do then second sample classification. The parallel process makes the pheromone matrix updated faster, and convergence to the optimal classifier faster.
Case Study
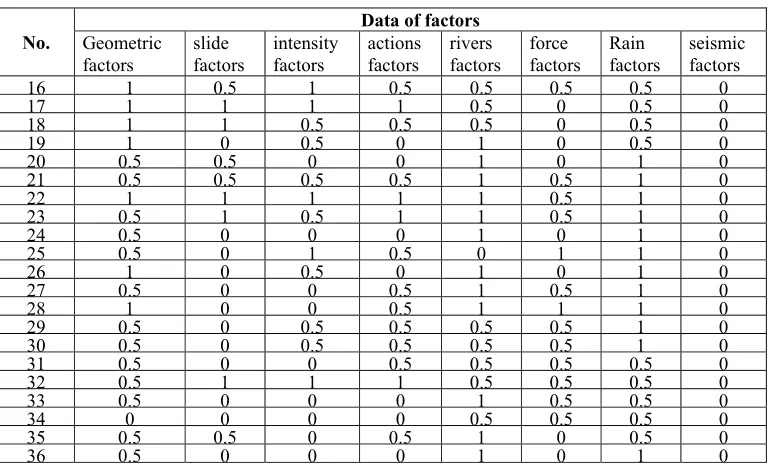
[image:4.612.125.275.67.168.2]Select the data in literature [3, 4] for analysis and comparison. There are 36 samples from the slopes engineering about the bank slopes of Three Gorges reservoir. The data has 8 kinds of normalization factors as showed in Table 1. The calculation parameters are that: number of ant K=10, max of iterations T=1000, probability depend on pheromone P=0.9, probability of random perturbations R=0.05, proportion of the depletion of pheromone ρ =0.5, total amount of pheromone Q=1.Literature [3, 4] divided slopes stability into six grades N=6.
Table 1. Factors of bank slopes.
No.
Data of factors
Geometric
factors slide factors intensity factors actions factors rivers factors force factors Rain factors seismic factors
1 1 0 0.5 0.5 0.5 0 1 0.5
2 0.5 1 0 0.5 0.5 0 1 0.5
3 0.5 1 0 0.5 0.5 0.5 1 0.5
4 1 1 1 1 0.5 0.5 1 0.5
5 1 0.5 0.5 0.5 0.5 0 0.5 0.5
6 0.5 1 0.5 1 1 1 0.5 0
7 0.5 1 0.5 0.5 1 1 0.5 0
8 0.5 1 0.5 1 1 1 0.5 0
9 0 1 1 0 1 1 0.5 0
10 0.5 0.5 0.5 1 1 0 0.5 0
11 1 0.5 1 1 0 0 0.5 0
No.
Data of factors
Geometric factors
slide factors
intensity factors
actions factors
rivers factors
force factors
Rain factors
seismic factors
16 1 0.5 1 0.5 0.5 0.5 0.5 0
17 1 1 1 1 0.5 0 0.5 0
18 1 1 0.5 0.5 0.5 0 0.5 0
19 1 0 0.5 0 1 0 0.5 0
20 0.5 0.5 0 0 1 0 1 0
21 0.5 0.5 0.5 0.5 1 0.5 1 0
22 1 1 1 1 1 0.5 1 0
23 0.5 1 0.5 1 1 0.5 1 0
24 0.5 0 0 0 1 0 1 0
25 0.5 0 1 0.5 0 1 1 0
26 1 0 0.5 0 1 0 1 0
27 0.5 0 0 0.5 1 0.5 1 0
28 1 0 0 0.5 1 1 1 0
29 0.5 0 0.5 0.5 0.5 0.5 1 0
30 0.5 0 0.5 0.5 0.5 0.5 1 0
31 0.5 0 0 0.5 0.5 0.5 0.5 0
32 0.5 1 1 1 0.5 0.5 0.5 0
33 0.5 0 0 0 1 0.5 0.5 0
34 0 0 0 0 0.5 0.5 0.5 0
35 0.5 0.5 0 0.5 1 0 0.5 0
36 0.5 0 0 0 1 0 1 0
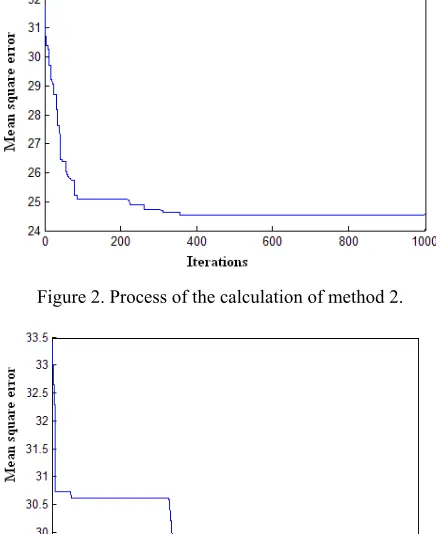
[image:5.612.115.500.64.299.2]Clustering results are showed in Table 2 obtained by the conventional method(M1), literature [3,4] method(M2), and the method of this paper(M3). The mean square error for four kinds of cluster methods is 27.2 (M1), 25.6(M2, literature[3,4]), 23.2(M3, this paper). Figure 1 shows the calculation convergence process of the method of this paper (M3). In the iteration 1000, calculation reaches the optimal solution. Figure 2 shows the calculation convergence process of the method of literature [3,4] (M2). The convergence rate decreases without random disturbances. When it gets the 400th iterations convergence process stops. When select all cluster results update the pheromone matrix in M1, the convergence process speed further slows down as showed in Figure 3.
Table 2. Results of cluster.
No.
Cluster data
No.
Cluster data
Figure 1. Process of the calculation of method 3(in this paper).
[image:6.612.196.414.250.517.2]Figure 2. Process of the calculation of method 2.
Figure 3. Process of the calculation of method 1.
Conclusion
The number of classification can be set and controlled, which increased the controllability of the result. The result can be contrasted and fused with the basic standard of classification method easily.
The initial pheromones are random, it also determines the clustering results do not depend on the initial input and initial order, the initial clustering center is random. Relative to the conventional method to determine the clustering center, this algorithm is simple and flexible.
Based on random disturbances, it avoids the disadvantage of fall into local optimum excessive volatility around the optimal solution. This method selects first few best solutions to update pheromones, accelerate the algorithm convergence speed, and reach the global optimal solution.
The random disturbance ant-cluster algorithm can better deal with the issues of bank slopes classification. It also can be used in other classification questions in engineering and obtain satisfactory results
Acknowledgement
This work was supported by the National Natural Science Foundation of China (Grant Nos. 51609149), the central level public welfare research institutes fund projects (Y716002), the National Natural Science Foundation of China (Grant Nos. 51509164, 51579154), the central level public welfare research institutes fund projects (Y716009, Y716010)
References
[1] J. Sun, Y.N.Z. Zhao. Comparative study of Sarma's method and the discontinuous deformation analysis for rock slope stability analysis, Geomechanics & Geoengineering. 6(2011)293-302.
[2] Xia, Yuanyou, Zhu, Ruigeng, Li, Xinping. Review and Prospect of the Research on Slopes Stability (in Chinese), METAL MINE.25 (1995)9- 21.
[3] XIE, Quan-min, XIA, Yuan-you. A self-adaptive clustering method based on the simulated annealing algorithm for evaluation of slopes stability (in Chinese), Journal of Catastrophology. (2002)15-19.
[4] GAO, Wei. Analysis of stability of rock slopes based on ant colony clustering algorithm (in Chinese), Rock and Soil Mechanics. 304(2009)3476-3480.
[5] DENEUBOURG, J. L., GOSS, S., FRANKS, N. The dynamics of collective sorting: robot-like ant and ant-like robot, Proceedings first conference on simulation of adaptive behavior: from animals to animates, Cambridge: MIT Press.120(1991)356-365.
[6] Shelokar, P.S., Jayaraman, V.K., Kulkarni, B.D. An ant colony approach for clustering, Analytica Chimica Acta, 509(2004)25-32.