2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
Research on Key Technology of Spatial Analysis of
Large-scale Geospatial Data in Cloud
Yi-yang SHAO
1,a*,Wei-dong BAO
2,band Xiao-min ZHU
3,c1,2,3 College of Information System and Management,
National University of Defense Technology, Changsha 410073, P. R. China
a[email protected], b[email protected], c[email protected]
*Corresponding author
Keywords: Cloud Computing, Large-scale, Hadoop, MapReduce.
Abstract. Geospatial data not merely affects to people's daily life, but also plays a key role in national defense construction and economic development. As geospatial data is gradually gaining scale and complexity with the emergence of the big data era, the conventional spatial data management solution, represented by the combination of ArcSDE and Oracle based on relational database, can no longer satisfy those more demanding needs of data management and analysis. In the basis of exploring the essence, features, and advantages of cloud computing, this paper pays special attention to the Hadoop Distributed File System (HDFS) and its depending framework MapReduce which supports distributed computing given a large data sets. Aiming to solve the difficulty of earthquake frequency statistics across different province of China, we collected a large volume of geospatial data and achieved the data type conversion, thus finally realized the storage and analysis of these large-scale geographical data. The main research contents of this paper are as follows:1) Fully investigated the various concepts of cloud computing, summarized its main advantages and thoroughly studied two core underlying concepts of Hadoop: Distributed File System (HDFS) and MapReduce programming framework; 2) Built up MapReduce modal by combining with GIS Tools for Hadoop supported by Esri, we realized the purpose of efficient analyzing large-scale geospatial data. The research exhibits that geospatial data collecting and geospatial analysis can be well accomplished under cloud computing environment. Besides, the inefficiency of geospatial data management under traditional system can be sufficiently reduced. The methods and process used in this case may able to inspire new ideas for similar cases.
Introduction
In an age with rapid development of science and technology, the public starts to concern how to manage, use those large number of information. As we all know, geospatial data is not only related to people's daily life, but also connected with the national economic development and national defense construction. In the age of information explosion, management of these geospatial data with such a great volume, analyze and make efficient use of them has become an imminent problem.
approach based on object-relational database, represented by ArcSDE + Oracle, has solved some problems such as the storage of unstructured geospatial data storage relying on its expansion of existing relational database, it is still far from enough. There are many common weaknesses in these management approaches based on relational databases: the integrity of spatial data may be destroyed; the security and consistency of spatial data are much weaker than commercial relational databases; given massive data, the demand and analysis of spatial data has quite low efficiency.
In recent years, the frequent occurrence of earthquake in China brings huge shock to the public, especially local citizens. 2008 Wenchuan earthquake, 2010 Yushu earthquake, 2011 Yingjiang earthquake and 2013 Ya'an earthquake, every time the earthquake is affecting the life of millions of people. However, with the increasing number of seismic data, the traditional data management approach is faced with severe challenge from the gradually increased amount and complexity.
When the object-relational database cannot meet our needs for large-scale geospatial data analysis, where should we go? The rapid development of cloud computing technology shed a light on the solution of storage, administration and analysis of geospatial data [1].
GIS, as one of the most promising industries of the twenty-first century, its integration with cloud computing foresees fast leap and progress. Cloud computing can provide a simple and efficient mechanism for managing online resources. With its significant advantages of allocating computing tasks, rebalancing workload and dynamic allocation of resources, etc., it cannot only implement large-scale geographic data for users Distributed storage, but also quickly respond to the spatial data query and analysis requests through its powerful distributed computing ability, which greatly improves the storage of geographic data, management efficiency and saves the system’s computing resources and also energy consumption.
In this paper, the authors will build their own cloud computing platform to explore the cloud storage mechanism, achieve the storage and management of geospatial data, and achieve large-scale geographical analysis in the cloud, solve the above problem of earthquake. This is a challenge to for GIS application in cloud. We hope our work can enlighten other geospatial data storage researchers
The remainder of this paper is organized as follows. The next section reviews related work in the literature. Section 3 describes a case of spatial analysis of large scale geographic data. The results of the case are shown in Section 4. Section 5 concludes the paper with a summary and future work.
Background and Related Work
Cloud computing is a new business computing model with the rapid development of computing, storage and communication technology. It is known as the "revolutionary computing model" [2]. The National Institute of Standards and Technology (NIST) defines cloud computing: cloud computing is a resource utilization model that can access configurable computer resource pools (such as networks, servers, storage and applications) over network in a convenient, user-friendly, on-demand manner, that can be provisioned at a minimum cost [3].
Any web-based application or service provided through the cloud is called a cloud service. Cloud services can be divided into Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS).
clouds computing related research organizations and their research directions are diverse.
We will introduce the research status of cloud computing from two aspects: mass data distribution storage system and distributed computing programming model. Mass Data Distribution Storage System
Cloud computing system uses distributed storage to store data, with redundant storage to ensure data reliability. The widely used data storage system is Google's GFS and Hadoop team developed open source implementation HDFS.
GFS (Google File System) is an extensible distributed file system that manages large, distributed data-intensive computing. It is built with cheap commercial hardware and provides fault-tolerant, high-performance services to a large number of users. GFS is Google's massive storage technology support, it is integrated with Chubby, Map Reduce and Big Table.
HDFS (Hadoop Distributed File System) is a sub-project of Apache's open source project Hadoop. It is based on GFS (Google File System) developed by Google that uses data streaming access mode to maximize the functionality of storing large files and massive data. It has high throughput and easier deployment. It is a typical distribution storage management file system.
Distributed Computing Programming Model
Programming mode is developed for the development of users to make full use of cloud computing services, in order to make these users to use the cloud back-end resources more easily, and achieve the desired purposes. Cloud computing programming mode should be as much as possible convenient and simple. If the background of complex parallel execution and task scheduling is transparent enough, then the programmer can focus on the logic.
MapReduce programming modes are used in most of the cloud computing models [5]. Many cloud programming model put forward by internet companies are based on MapReduce.
MapReduce is a programming model that generates and processes large-scale datasets. The programmer specifies the processing of each chunk of data in the Map function, and specifies how to merge the intermediate results of the chunk data processing in the Reduce function. Users only need to specify map and reduce functions to build distributed parallel programs. When running the MapReduce model in a cluster, the programmer not only does not need to care about how the system blocks, allocates, and dispatches the input data, management and communication of the nodes within the cluster are also managed by the system.
Spatial Analysis of Large Scale Geographic Data
In this chapter, we achieve large-scale geospatial data management combined with virtualization technology and solve the difficulty problem of earthquake frequency statistics in all provinces of China.
Cloud Environment Configuration
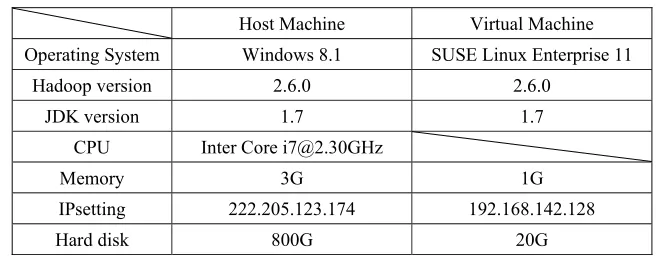
The experiments use the Apache open source project Hadoop as environment. Hadoop is deployed in virtual machines; the configuration of the host machine and virtual machine is shown in Table 1.
Table 1. Deployment of Virtual Cloud Environment.
Host Machine Virtual Machine Operating System Windows 8.1 SUSE Linux Enterprise 11
Hadoop version 2.6.0 2.6.0
JDK version 1.7 1.7
CPU Inter Core [email protected]
Memory 3G 1G
IPsetting 222.205.123.174 192.168.142.128
Hard disk 800G 20G
The virtual cloud environment is deployed as single-node deployment, the virtual machine is both NameNode and DataNode.
Raw Data Acquisition
In this research, the data of earthquakes is recorded in the retrieval directory of US Advanced National Seismic System (ANSS). It comes from the North California Earthquake Data Center (NCEDC) and the University of California, Berkeley Earthquake Laboratory. The earliest record is noted in 1898, there are more than three million records of earthquakes. The data is large, recorded in detail, and in high credibility.
The seismic data is consisted of 12 fields; they are DataTime, Latitude, Longitude, Depth, Magnitude, MagType, NbStations, Gap, Distance, RMS, Source, EventID.
[image:4.612.140.468.207.336.2]Part of the seismic data is shown in Table 2.
Table 2. Part of the Seismic Data.
Table 3. Part of Border of Province Data.
Data Type Conversion
Because the shp type file is not convenient to extract and does not conform to the standard of Open Geospatial Consortium (OGC). It will cause the inconvenience of data analysis if stored directly into the cloud. Therefore, in this research, we extract important fields of the border of China and its province and convert it into json format. It is more convenient for subsequent analysis operations.
A new field, Geometry, which describes the spatial information, is added to the data by using the Python scripting language, as Table 4 shows. In order to make the process clear, we deliberately deleted the fields which are not used in this research.
Table 4. The Added Geometry Field.
The table is exported to a text format and programmed so that all data fields are in json format. Only in this way can we using MapReduce programming GIS Tools for Hadoop of Esri to analysis both seismic data and provincial border data.
Storageand Analysis of Geographic Data in Cloud
[image:5.612.129.502.384.622.2]hierarchical file system to view the file uploaded into cloud, only a lot of trivial small files can be seen. But using the command provided by Hadoop, the view of the data is integrated.
By adding the hadoop-eclipse-kepler-plugin-2.2.0 plugin in Eclipse and setting up it, we set up a remote connection to cloud in Eclipse. After the connection is achieved, we added Esri GIS Tools for Hadoop plug-in and programed MapReduce code to achieve large-scale geographic data analysis.
We run the MapReduce function; the system transmitted the function into the cloud and executed it.
Performance Evaluation
The entire analysis process continued for an average of about 10-20 seconds in cloud, we evaluated the performance and analyzed the results as follows.
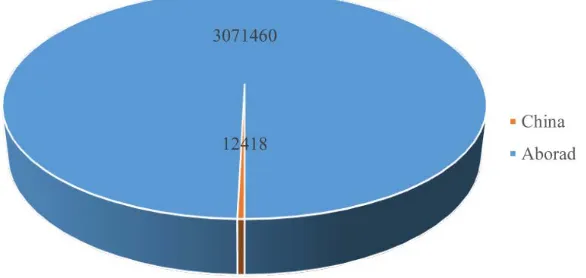
[image:6.612.175.468.317.456.2]The Statistics of earthquake in China and abroad is shown in Figure 1. The total number of earthquakes was 308,388, the number of earthquakes occurred in China was 12418, and the number of earthquakes in China accounted for only 0.403% of the total.
Figure 1. Earthquake Statistics in China and Abroad.
Figure 2. Earthquake Statistics in Each Province of China.
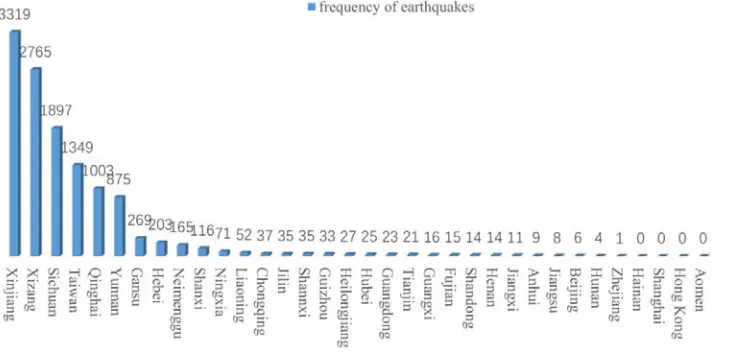
From the pie chart can be found that the provinces with the most earthquakes were Xinjiang Province, Xizang Province, Sichuan Province, Taiwan Province, Qinghai Province, and Yunnan Province and so on. The histogram of the frequency of each province is shown in Figure 3.
Figure 2. Frequency of Earthquakes in Each Province of China.
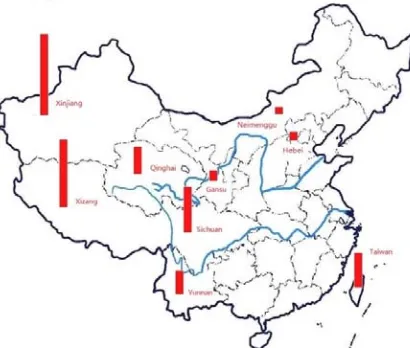
[image:7.612.124.498.348.525.2]provinces. There are totally10 provinces. The frequency of earthquake in these provinces is less than once a decade. There is not any earthquake in the statistical time in Hainan, Shanghai, Hong Kong and Macao four provinces. Figure 4 shows the distribution of frequent of earthquake prone provinces in China.
Figure 3. The distribution of frequent of earthquake prone provinces in China.
It is very clear in Figure 4that most of the earthquakes occurred in the western and southern China except Taiwan. It is not difficult to speculate that the major earthquake threat of China comes from the collision of the Asia-Europe plate and the Indian Ocean plate.
Conclusions and Future Work
Based on the study of storage and analysis of large-scale geographic data in cloud environment, this paper realizes the cloud storage of geospatial data on the basis of virtual machine technology, and designs the practice of frequency statistics of earthquakes between 1889 and 2015 based on MapReduce framework, which achieves spatial analysis on large-scale geographical data. At the same time, the experimental results are analyzed to verify the reliability of the algorithm.
The main achievements of this study are as follows: 1)fully investigate the basic concepts of cloud computing, principles and methods, initiate the two core concepts of Hadoop (distributed file management system (HDFS) and MapReduce programming model). 2) In order to solve the problem of seismic frequency statistics among more than 100 years in the provinces of China, we collected large-scale geospatial data including seismic data and Chinese boundary data to realize the cloud storage of geographic data. By deploying the MapReduce model and combining it with the GIS Tools for Hadoop plug-in of Esri, we finally achieved the spatial analysis on large-scale geographical data and solved the previous problem. It provides a new solution for similar problems.
References
[1] Foster, I., et al., Cloud Computing and Grid Computing 360-Degree Compared. GCE: 2008 GRID COMPUTING ENVIRONMENTS WORKSHOP, 2008: p. 60-69. [2] Information on http://blog.sina.com.cn/s/blog_596ccc870100aps1.html.2008 [3] Mell, P., Grance, T. The NIST definition of cloud computing [J]. 2011.
[4] VMware virtualization technology [EB/OL] [2011-09-02].
http://www.vmware.com/virtualization/what-is-virtualization.html
[5] Bryant, R. E. Data-intensive supercomputing: The case for DISC [J]. 2007.