2017 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017)
ISBN: 978-1-60595-485-1
Path Planning for Autonomous Underwater Vehicles
in Uncertain Environments
CHANGYUN WEI, FUSHENG NI and SHUANG JIANG
ABSTRACT
This paper addresses the path planning problem for autonomous underwater vehicles (AUVs) in uncertain ocean environments. In comparison with mobile robots, the motion of an AUV is frequently interfered by ocean currents. Thus, the path planning solution should not only consider generating low-cost, collision-free and dynamically feasible paths but also dealing with environmental disturbances and actuation errors. In this work, the novel feature of the proposed solution is that a reinforcement learning approach is presented, and the exploration strategies for optimizing the leaning episodes are also evaluated and discussed. The proposed solution is validated by a simulated tested constructed upon a grid-based map with a model of an AUV in uncertain environments.
KEYWORDS
Path planning, underwater vehicles, uncertainty, reinforcement learning.
INTRODUCTION
Path planning is a typical problem studied in many robotic domains, such as autonomous mobile robots, underwater vehicles, and unmanned aerial vehicles. In this paper, we seek to address the AUVs that are frequently used for ocean monitoring, information collection, marine resource exploration [1]. The challenge issue for an AUV is that its endurance of task execution in ocean environments must be seriously taken into consideration [2]. Due to the limited fuel or battery capacity, an AUV should efficiently use its energy while moving towards its target location. However, the ocean currents can disturb its path execution. Thus, when planning the feasible path, an approach must consider the existence of the ocean currents. Moreover, the ocean currents can amplify the actuation errors, which means that the trajectory points should be far away the dangerous zones.
In ocean scenarios, the local environmental conditions can vary appreciably over relatively short periods of time and over short spatial scales [3]. Some work [4] studied strong currents, in which the speed of vehicles cannot resist the currents so that
_________________________________________
the vehicles might be trapped or overwhelmed by the current. Some other literature [5] assumed that the local condition is known to the vehicle, and an accurate current model is available for planning the feasible path. However, ocean environments can be extremely complex and dynamic, and it is impossible to accurately forecast the currents or flow fields.
Thus, this work in particular addresses the path planning problem with time-varying ocean currents under uncertainty, and the non-deterministic settings of both environments and action executions are considered in the proposed approach.
PRELIMINARIES
In this section, we discuss the framework of Markov Decision Process (MDP) and Reinforcement Learning that are frequently used to solve multistage decision making problems in stochastic environments [6]. Markov decision process can be described by a 5-tuple ( , , , ,S A P R ), where S denotes the state space containing a
set of finite number of states s(here the states will be the locations of the AUV); A denotes the action space containing a set of finite number of actions a ;
( | , )
P s s a denotes the conditional transition probabilities from state s to state s
when the vehicle takes action a in state s; ( , )R s a denotes the expected immediate reward when the vehicle moves to state s from sate s after taking action a;
[0,1]
denotes the discount factor that indicates the present importance of future rewards. The vehicle’s behavior is described by a policy that indicating how the vehicle selects an action in a given state.
In a MDP, at each time stept, the vehicle’s current state is sS and will
choose an actionaA. As a result, the vehicle will transit to a new state s in time
stept+1, and at the same time it will get a reward from the environment with the expected valuerR s a( , ). The state-action value function Q( , )s a indicates the expected total discounted reward ( t t)
i t r
that the vehicle gets when it takes action a and follows policy at states. Thus, the goal of the vehicle is to find the optimal policy * that can maximizes Q for each state and action. The Bellman equations can be used to calculate the state-action value functionQ:( , )= ( , ) ( | , ) ( , )
s
Q s a R s a P s s a Q s a
(1)In practice, if the rewards are stochastic, the number of possible policies will be too large so that estimating the expected return can be intractable. Thus, we can use the Q-learning algorithm to obtain the Q-function:
( , ) ( , )+ [ ( , ) max( ( , ) ( , ))]
a
Q s a Q s a R s a Q s a Q s a
(2)
MODEL AND ALGORITHM
In the reinforcement learning framework, the rewards and transition probabilities are unknown, which means that the vehicle has no prior knowledge about the ocean currents and disturbances. Thus, it has to interact with its environment over time to build the model of the MDP. For the path planning problem, finding the optimal path can be treated as maximizing the cumulative immediate rewards, i.e., the expected discounted return R( )s at each time t:
2
1 2 3
( )= [t t t ]
R s r r r (3)
In order to maximize this function, the vehicle has to interact with the environment, and obtain the reward information. Thus, there is a problem of how to balance the exploration and exploitation.
Action Selection Strategy.
Greedy action selection strategy always employs current knowledge to maximize the immediate rewards. This strategy will not look at any other possible actions. Comparatively, -greedy action selection strategy gives the greedy action the highest possibilities (i.e.,1-), but also allow a small possibility (i.e.,) to choose the other actions randomly. Thus, we use the -greedy action selection strategy in this work. The advantageous of this strategy is that each action will be sampled an infinite number of times, which can ensure the coverage of Q-values.
Dynamic Exploration Rate and Learning Rate.
In the reinforcement learning framework, we expect that the vehicle can initially explore the environment with high possibility, i.e., with a high value. However, with the increase of knowledge about the environment, the exploration rate should decrease since the vehicle already knows which action can lead to what rewards. Thus, we hope that the exploration rate should change dynamically according to the iteration of learning episodes. The exploration rate will be updated as follows:
- current iteration *
total iteration N
N
(4)
In this case, the learning periods will initially try to explore the environment, and gradually select he greedy action. Accordingly, the learning rate can also be adapted with the progress of iterations:
- current iteration *
total iteration N
N
Tabu Search Heuristic.
In order to avoid cycling trajectory in a learning episode, we employ the Tabu search heuristic. It utilizes the memory of history of the search to avoid blind randomization of choosing the next action. The basic idea is that the Tabu heuristic will choose the best action from the non-Tabu action list. To avoid cycling trajectory with the previous sequence moves, the Tabu tenure will disappear after one step restriction.
Learning Algorithm.
The above algorithm only shows one learning episode. In order to coverage the Q-values, we can set the maximum number of learning iterations, or set the stop precision. In this work, we select the former one, and we use the above algorithm to develop the path planning solution. We hope that the learning agent can generate a collision-free path, and, moreover, the path should guide the vehicle away from the potential obstacle zones.
EXPERIMENTS AND RESULTS
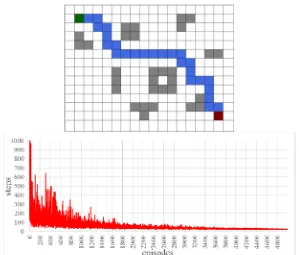
We use the simulated environment as displayed in Fig 1~3 to evaluate the proposed approach. The agent should start from the green cell and consequently find the optimal path to its destination, i.e., the red cell. The gray cells represent the obstacles, so the agent has to avoid them in order to successfully arrive at the red cell. However, in uncertain environments, the agent should also consider the possibility that it may collide with those obstacles occasionally. Thus, for the calculated path, the farther the trajectory points are away from the obstacles, the safer the agent will become when it follows the path.
TABLE 1. THE ALGORITHM OF Q-LEARNING FOR PATH PLANNING IS SHOWN IN PROCEDURAL FROM THE TABLE BELOW.
For all statess, initialize Q s a( , )arbitrarily, the learning rate , the exploration rate, and discount factor .
1 Repeat
2 Update the learning rate and exploration according to Equation (4) and (5).
3 Update the non-taboo list.
4 Selection action a from non-taboo list, using policy derived from Q s a( , ) based on greedy policy.
5 Take actiona, observe rewardr, next states.
6 Set action a to the taut list.
7 ( , ) ( , )+ [ max( ( , ) ( , ))]
a
Q s a Q s a r Q s a Q s a
.
8 ss.
Figure 1. the optimal path and the learning process when the initial exploration rate equals 0.1.
[image:5.612.147.449.331.581.2]
Figure 3. the optimal path and the learning process when the initial exploration rate equals 0.5.
We can see from Fig 1~3 that the propose algorithm can indeed demonstrates its feasibility. For the evaluation, the initial learning rate is 0.5, the moving reward is -1, the collision reward is -5, and the goal reward is 10. The learning episode is 5000. We also evaluate the effects of changing the initial exploration rate, as shown in Fig 1, 2 and 3 separately.
As discussed in Equation 3, the initial exploration rate will gradually decrease along the learning episodes. However, we should not set a larger number to the initial exploration rate as shown in Fig 3. Otherwise, the learning periods will vibrate in the early stage of the episodes.
SUMMARY
In this work, we have proposed a reinforcement learning approach for the path planning problem in the underwater vehicle domain. The proposed approach can generate the low-cost, collision-free paths, but also try to guide the vehicle away the obstacle zones. In such a way, the vehicle can have a lower possibility to be pushed into those zones when the environment has uncertain ocean disturbances. The simulated results have demonstrated the effectiveness and feasibility of the proposed approach. Thus, we can claim that this work provides an alternative solution to the path planning problem for AUVs in uncertainty environment.
ACKNOWLEDGMENTS
REFERENCES
1. Cui, Rongxin, Y. Li, and W. Yan. "Mutual Information-Based Multi-AUV Path Planning for Scalar Field Sampling Using Multidimensional RRT*." IEEE Transactions on Systems Man & Cybernetics Systems 46.7 (2016): 993-1004.
2. Huang, Huan, D. Zhu, and F. Ding. "Dynamic Task Assignment and Path Planning for Multi-AUV System in Variable Ocean Current Environment." Journal of Intelligent & Robotic Systems 74.3-4(2014): 999-1012.
3. Iserngonzález, José, et al. "Obstacle Avoidance in Underwater Glider Path Planning." Journal of Physical Agents 6.1(2012): 11-20.
4. Soulignac, Michaël. "Feasible and Optimal Path Planning in Strong Current Fields." IEEE Transactions on Robotics 27.1(2011): 89-98.
5. Shih, Chien Chou, et al. "A genetic-based effective approach to path-planning of autonomous underwater glider with upstream-current avoidance in variable oceans." Soft Computing (2016): 1-18.