2017 2nd International Conference on Computer, Mechatronics and Electronic Engineering (CMEE 2017) ISBN: 978-1-60595-532-2
Text Classification and Threat Intelligence Generation for Industrial
Control System Security
Jing-yi WANG, Tian-chen ZHU, Jia-wei KANG and Bo LI
Bei Hang University, Xue Yuan Road No.37, Hai Dian District, Beijing, China
Keywords: Industrial control system, Threat intelligence, Text classification, IOC.
Abstract. Facing the increasingly serious security problems in ICS, how to classify and generate threat intelligence effectively is of great importance in improving the safety of industrial control systems, helping them identify security threats and making corresponding preventions. In this paper, according to the classification of security events in the threat intelligence platform, we classify ICS security topic texts as information leakage, security vulnerabilities, network security, security suggestions, invasion, malware, or security events. Based on the OpenIOC framework, automatically analysis on the massive ICS security data can be done to generate the corresponding IOC file and obtain threat intelligence.
Introduction
Industrial control system refers to the automatic control system consisted of computer and industrial process control component, which has a wide range of applications in the production process, power facilities, hydraulic oil and gas transportation and other fields. The safety of industrial control systems is related to the country's economic development, social stability and security [1]. Due to the increasing adoption of open Internet technology in industrial control systems and the fact that most industrial communication systems develop protocols based on commercial operating systems, there are many loopholes in communication applications in industrial control systems [2]. Considering the particularity of the industrial control system, the attacker will it for different purposes, causing the industrial control system to face an increasingly serious security threat.
The acquisition and analysis of threat intelligence for industrial control system security can help to improve the safety of the systems, help them identify security threats and make corresponding preventions [3]. By collecting and analyzing the threat intelligence of the attacked industrial control system and integrating it with the information such as the safety behaviors of the industrial control equipment, a combination of internal and external industrial security threat intelligence system can be formed.
In the face of escalating and constantly changing means of attack, the traditional way of collecting intelligence through manual analysis is inefficient, an automatic classification and generation method is required. In this paper, a system is design and implemented to classify ICS security theme texts into seven categories and automatically generate threat intelligence, which can be shared and machine readable, making response to malicious attacks.
System Structure
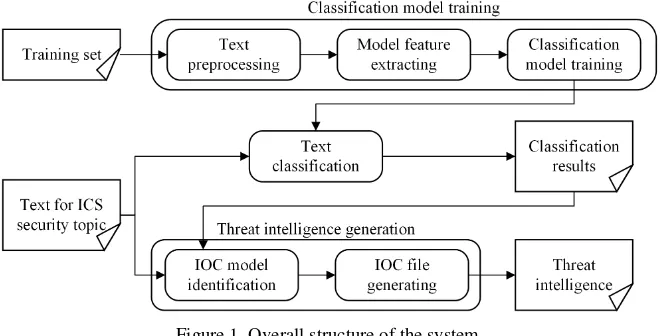
Figure 1. Overall structure of the system.
In order to classify texts, a classification model needs to be set up based on the training set. The process of training the classification model includes pretreatment of the texts in the training set, extraction of the model features after the preprocessing, and training classification model by the classification algorithm. After the classification model is obtained, the system will also preprocesses the text that needs to be classified and extracts features of it, and then classifies the text using the trained classification model.
In the threat intelligence generation section, the system uses OpenIOC framework [4] to check whether the text contains information about the description of the threat, and filters out strings by using regular expressions. Then the corresponding CSV files are generated and the interface is called to generate the IOC files and obtain threat intelligence.
Classification Model Training
According to the criteria for the classification of security events and the characteristics of the currently collected text from NOSEC [5], AlienValut [6] and other threat intelligence platform, the definition of industrial security theme text is classified as the following seven categories: information leakage, security vulnerabilities, network security, security suggestions, invasion, malware, and security events.
Based on the defined text classification standard, the system needs to get the classification model according to the training set. The classification model training process mainly includes the text preprocessing, feature extraction and classification training.
Text Preprocessing
For text preprocessing, we want to express the text of the training in a format that is easy to store and process, and the main process includes word segmentation, part-of-speech tagging, and stop-words deletion [7]. Since the data of training set mainly focused on foreign forums, technical blogs and news sites on ICS security which are written in English, the system separates words in texts based on spaces and punctuation.
Due to the large amount of word information obtained, the result of the word segmentation needs to be filtered and delete the stop words, which is very helpful for improving the classification progress of the model [8]. According to the characteristics of the ICS security topic text, the list of stop-words is expanded on the basis of 891 English stop-words. By analyzing the experimental results, retaining only the nouns and verbs has a significant help to improve the classification progress of the classification model. Therefore, for the text after the word segmentation, the system removes the reference word and only retains the noun and the verb, and saves the filtered word information [9].
the system will be expressed as the relationship of documents, words and categories in the following format:
Category information table: Map<category, number of text>
Feature table: Map<category, Map<text, Map<word, word information>>> Features inverted table: Map<word, Map<category, Set<document>>>
Feature Extraction
The advantage of feature extraction is that it can reduce the number of features, make the model more generalized and reduce the over-fitting to enhance the understanding between features and eigenvalues. The feature extraction method used by our system is the vector space model, which transforms the sample into vector form. For each word in the word bag model, it is necessary to establish a measure from which the feature word is selected and the classification model is established.
In the system, we use chi-square statistics [11] as a measure to select the feature word. According to Equation 1, the chi-square value is calculated for each word in each category in the training set.
) ( ) ( ) ( ) ( ) ( ) , ( 2 2 D C B A D B C A BC AD N c t + × + × + × + − × =
χ (1)
Where t represents the word, c represents the category, N represents the total number of text in the training dataset, A represents the number of texts in the category that contain the word, B represents the number of text that contains a certain word in other categories when a certain category is excluded,
C represents the number of text that does not contain a word in a category, and D represents the number of text in a category that does not contain a word and is not in that category.
After the calculation, the system obtains the chi-square value of each word in each category, and then sorts all the words based on the chi-square values in each category, and selects the n words with the largest chi-square value in the category. Finally, we select the phrases from all categories and get them merged, then we get the final eigenvector. The phrases selected for each category can be optimized according to certain criteria at the time of the merger, and the words that appear in each category are given a proportion that can be deleted beyond the specified scale. Where n is defined in terms of system requirements, in our system n is defined as 3000.
Since the weight of the feature word is calculated, it is necessary to reflect the degree of discrimination between texts. Therefore, when calculating the weight, the system uses TF-IDF(term frequency–inverse document frequency) method [12]. Equation 2 is used to calculate the word frequency of the word tfi,j in the text di.
∑
=k kj j i j i n n tf , ,
, (2)
Where ni,j represents the number of appearances of word ti in textdj , and the denominator
represents the sum of the occurrences of all words in textdj, Equation 3 is used to calculate the
reverse file frequency idfi for a particular word ti.
| } : { | | | log j i
i j tD d
idf
∈
= (3)
Where | D | represents the number of texts in training set, {j :ti ∈dj}represents the number of
files containing word ti. Generally, we use 1+ {j :ti ∈dj} to avoid the word is not in training
Classification Training
The system uses SVM [13] algorithm and libsvm [14] to classify the resulting eigenvectors. When categorizing, record the data in the following format:
Label 1: value 2: value …
Where Label represents the identity of the category, value represents the eigenvalue of the eigenvector, and the data is separated by spaces.
Each word in the feature vector computed in the training data set is numbered, so value is the TF-IDF for that term. Each record entered represents a text of the training set, with 7 categories being labeled at the same time according to the defined classification standard.
Since the calculated TF-IDF values for eigenvectors may be within a non-standard range, the input data needs to be transformed to the same range before classification training, where the system uses the svm-scale interface of libsvm to transform the eigenvalues of the eigenvectors between 0 and 1.
In the process of training the classification model, the system adopts tenfold cross-validation to test the accuracy of the classification model. Based on the results of multiple tests, we choose the polynomial kernel function and set the penalty parameter C to 1 when training the model. After the classification model is obtained, the ICS security topic tests can be classified by the svm-predict interface of libsvm, and the result of the classification will be transferred to the threat intelligence generation for further analysis.
Threat Intelligence Generation
By detecting the contents of the text, the system identifies the information about the threat intelligence contained in the text and uses the OpenIOC framework to automatically generate the identified information as IOC file according to the defined indicator item.
IOC Indicator Item Definition
In the OpenIOC framework, an IOC file combines multiple indicator. Each IOC file is essentially a compound expression, which represents the IOC hits target when the compound expression is true. The fineness depicted in IOC is achieved by setting indicator items which has different attributes and meanings.
Combining with the text classification function, threat intelligence is continuously collected, enriched, analyzed and re-collected in the system, thus forming a closed loop for ICS security information acquisition and threat prevention. In order to make the system more usable and generate valuable intelligence which is instructive in preventing security threats, we need to define representative indicator items.
Based on the STIX standard [15] and the threat intelligence information currently recognized by the system, we define the indicator items as follows: the file name of the malware, the MD5 of the malware, published public loophole, attack initiated IP address, sender address of malicious mail, the port number of the malicious attack, method of the malicious attacks. These indicator items are typically included in common malware or attack patterns and are highly representative.
IOC Indicator Item Recognition
The system first determines whether the text contains IOC indicator item information, filter and delete interference information in the identified string. According to the previous definition for the various indicator item, we can identify which type of indicator item the selected string belongs to. The regular expression and its description are shown in Table 1.
IOC File Generation
text, consisting of any number of records, each two records are separated by a line break, each record consists of fields, and delimiters between fields are other characters or strings.
When indicator item is detected through regular expressions, the system generate the corresponding CSV files based on its property. The structure of each record in the CSV file includes condition, document, search, content type, and content. Condition represents the condition of the IOC expression, including four types: contains, contains not, is not. Document represents the main class that indicator item belongs to. Search represents the sub class that indicator item belongs to. Content type represents the type of the attribute value of the indicator item. Content represents the attribute value of the indicator item.
The system automatically generates the CSV file as an IOC file, each CSV record corresponds to an indicator item. The format of the IOC file is as follows:
OR AND
[image:5.612.89.522.310.516.2]<term1> <condition1> <content1> <term2> <condition2> <content2> <term3> <condition3> <content3> ...
Table 1. Regular expression of identifying indicator item.
Description Regular expression
Information which may include indicator item
([A-Za-z_][A-Za-z0-9_]+\\.[a-z]{2,4}\\s)|([a-z0-9]{32})|([012]?\\d?\\d\\.[012]?\\d? \\d\\.[012]?\\d?\\d\\.[012]?\\d?\\d)|((CVE-\\d\\d\\d\\d-\\d\\d\\d\\d)|(CNVD-\\d\\d\\d\\d -\\d\\d\\d\\d))|[Pp]ort\\s?[0-9]+|\\w[-\\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\\.)+[A-Za-z]{2,14}|([Bb]uffer\\s[Oo]verflow)|(SQL\\s[Ii]nject)|(DDoS)|([Tt]rojan)
Removal of interference information
(https://)|(http://)|(https:\\\\)|(http:\\\\)|(\\.shtml)|(\\.blogspot)|(www\\.)|(\\.html)|(.xml) |([A-Za-z0-9_]+\\.com)
MD5 [a-z0-9]{32}
IP address [012]?\\d?\\d\\.[012]?\\d?\\d\\.[012]?\\d?\\d\\.[012]?\\d?\\d Security vulnerability (CVE-\\d\\d\\d\\d-\\d\\d\\d\\d)|(CNVD-\\d\\d\\d\\d-\\d\\d\\d\\d)
File name [A-Za-z_][A-Za-z0-9_]+\\.[a-z]{2,4}\\s
Email address \\w[-\\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\\.)+[A-Za-z]{2,14} Port number [Pp]ort\\s?[0-9]+
Invasion means ([Bb]uffer\\s[Oo]verflow)|(SQL\\s[Ii]nject)|(DDoS)|([Tt]rojan)
Experiments
In order to evaluate the system, we test the accuracy of the classification model in this paper and give the results of classification and generation.
The experiment adopted the platform with Intel Core i7-6700K 4.0GHz, 8G of memory running Windows 10, using Java 1.8 encoding. We use the data crawling from vendor reports, news, blogs, microblogging and technical forums as the test set, contains 13985 text data. After manual screening and classification, 11322 text data related to ICS security are selected, and we use 6792 of them as training set and 4530 of them as test set. According to the category defined above,
[image:5.612.103.504.692.750.2]In this paper, we evaluate the effectiveness of the system through precision and recall. The results of the test are shown in Table 2.
Table 2. Precision and recall of the system.
Type Amount of text Precision Recall
Information leakage 1823 75.65% 72.81%
Security vulnerabilities 2422 72.10% 77.34%
Security invasion 2314 67.38% 74.73%
Intrusion 837 76.14% 80.69%
Malware 508 77.52% 75.75%
Security events 1664 66.64% 67.26%
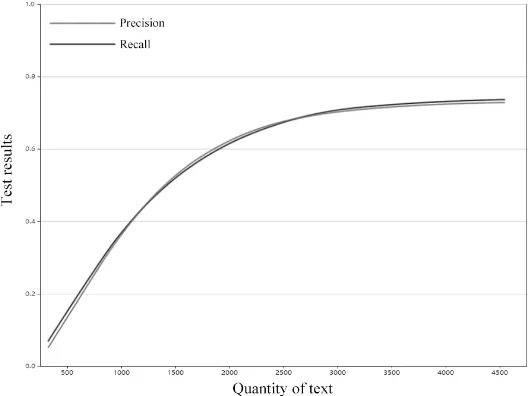
[image:6.612.105.505.67.124.2]Through the experiment shown in Figure 2, it can be discovered that with the increase of the number of texts, the precision and recall of the system increase significantly. When the number of texts exceeds three thousand, the growth rate of precision and recall become slower and slower. The overall precision of the system is 72.79%, and the overall recall of the system is 74.58%, indicating that our work has good performance.
Figure 2. Test results of overall precision and recall.
Take the example of “Power Outage Caused by the Cyber Attack on Ukrenergo Technical Analysis and Solution” which is successfully classified by the system into category of security events, its IOC file generated by system is partially shown in Figure 3. As shown in the IOC file, the system can extract amounts of threat intelligence from the article. For example, a malware named explorer.exe is contained in this cyber-attack, which spread through e-mail and use Trojan virus to invade the power system.
[image:6.612.164.430.203.401.2]Conclusions
In this paper, we design and implement a text classification and threat intelligence generation system for industrial control system security. System can extract the text features and classify texts according to the defined classification criteria, generate highly informative IOC file based on the OpenIOC framework to generate threat intelligence. The system clearly presents its effectiveness through several experiments, and the example generated is given.
Reference
[1] Goble W M. Control System Safety Evaluation and Reliability [M]. ISA, 1998.
[2] James P. Farwell, Rafal Rohozinski. Stuxnet and the Future of Cyber War [J]. Survival, 2011, 53(1):23-40.
[3] Wenyu Wang, Hongyu Liu. Analysis and Study of Defense against Security Risk for Industry Control System [J]. China Information Security, 2012(2):33-35.
[4] Information on http://www.openioc.org/
[5] NOSEC. https://nosec.org/, 2017.
[6] AlienVault. Open Threat Intelligence. https://otx.alienvault.com/, 2017.
[7] Dan K, Manning C D. Fast Exact Inference with a Factored Model for Natural Language Parsing[C]// Conference on Advances in Neural Information Processing Systems. 2002:201-208.
[8] Manning C D, Surdeanu M, Bauer J, et al. The Stanford CoreNLP Natural Language Processing Toolkit[C]//Meeting of the Association for Computational Linguistics: System Demonstrations. 2014.
[9] Alienvault. Tracking Down the Author of the Plugx Rat [EB/OL]. (2014-05-19)[2016-07-01]. http://www.alienvault.com/openthreat-exchange/blog/tracking-down-the-author-of-theplugx-rat
[10] G. Salton, C.S. Yang. on The Specification of Term Values in Automatic Indexing [J]. Journal of Documentation, 1973, 29(4):351-372.
[11] Chen Y T, Chen M C. Using chi-square statistics to measure similarities for text categorization [J]. Expert Systems with Applications, 2011, 38(4):3085-3090.
[12] Chenghui Huang, Jian Yin, Fang Hou. A Text Similarity Measurement Combining Word Semantic Information with TF-IDF Method [J]. Chinese Journal of Computers, 2011, 34(5):856-864.
[13] Vapnik V. SVM method of estimating density, conditional probability, and conditional density[C]//IEEE International Symposium on Circuits and Systems, 2000. Proceedings. ISCAS. IEEE, 2000:749-752 vol.2.
[14] Chang C C, Lin C J. LIBSVM: A library for support vector machines [M]. ACM, 2011.
[15] Information on http://stixproject.github.io/