International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)182
Uncontrolled Illumination Rectification Using Wavelet
Normalisation on Face Recognition
Preethi Augustine
Assistant Professor, Department of Computer Science, VKCET, Trivandrum, Kerala
Abstract— In this paper, a novel illumination invariant preprocessing algorithm is introduced to overcome the illumination variation problems in face recognition. With this, the recognition system works effectively under a wide range of illumination variations. The system consists of three stages; preprocessing, a hybrid Fourier-based facial feature extraction, and recognition. Wavelet-based normalisation technique grays-out dark and highlight areas of the face image. To imitate the human visual system and examine a face image from the internal facial components to the external facial shapes, multiple face models with complementary features are constructed. Features are extracted using Fourier transform and projected using PCLDA technique. A simple metric, Euclidean Distance is used as the classifier.
Keywords—Euclidean distance, Fourier feature, PCLDA, Single Scale Retinex, Wavelet-based normalisation
I. INTRODUCTION
Nowadays face recognition attracts much attention in network multimedia information access. Since „people‟ are the center of attention in a lot of video, this technology helps areas like network security, context indexing and retrieval, and video compression. Stealing one‟s password can be made impossible, and it also increases the user-friendliness in human computer interaction. It provides a more efficient coding scheme for the applications of videophone and teleconferencing. For personal authentication systems this is more accurate and convenient as it does not need expensive equipments.
One of the major problems in face recognition deals with the recognition accuracy for a large data set captured in various lighting conditions. Thus variation in illumination is a major challenge that causes system performance degradation. A direct lighting source can cast shadows due to the 3D shape of the face and diminish certain facial features. The system may misclassify while comparing the input images of the same person as the differences between them are often larger than the differences between individuals.
Su et al.[1] proposed a hierarchical framework exploiting both global and local features using Fourier Transform and Gabor wavelets respectively.
This improves accuracy but imposes heavy computational burden on target device which have low computational power. Extending the correlation filter, Savvides et al.[2] proposed a hybrid PCA-correlation filter called “corefaces”. Combined features of PCA and advanced correlation filters make the system illumination tolerant and shift-invariant. The main drawback is that computation burden is high since many correlation filters are needed for a single person. To enforce the weak classifiers Wang and Tang[3] applied random sampling on feature vectors and training samples. These classifiers are stable and cover most of the face feature space, but do not deal with illumination variations. Chang et al.[4] developed a system that accumulates similarity measure of corresponding normalised gradients at face contour locations from images. Computational cost is very low and it is illumination tolerant, but pose variations are not allowed. Hwang et al. [5] proposed an INGI[6] preprocessing algorithm which includes SSR normalization. Instead of SSR, to improve the accuracy the proposed system includes wavelet-based normalization technique.
II. PREPROCESSING
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013) [image:2.612.63.274.207.367.2]183 INGI method can depress the illumination of original image and enhance the face texture especially for highlight and shadow region i.e. shading part is almost removed in these images. In this work, mainly the effect of utilizing 5 preprocessing steps is examined; smoothing, gradient map formation, normalisation, reconstruction and fusion.
Figure 1. Preprocessing Stages
To detect the edges, gradient method looks for the maximum and minimum in the first derivative of the image. A point is considered to be an edge point if the first order derivative exceeds the threshold chosen at that point. The set of such points connected forms an edge. To overcome the illumination sensitivity, normalize the gradient map using Wavelet normalisation.
Wavelet-based normalisation is a combination of two approaches; histogram normalization and photometric normalization. The scaling and wavelet coefficients are computed using a 2D filter bank consisting of low-pass and high-pass filters. After decomposition, an image is divided into four sub-bands: LL (Low-Low), LH (Low-High), HL (High-Low), and HH (High-High). They are the approximation, horizontal, vertical and diagonal components. These different band coefficients are manipulated separately. Using different wavelet filter sets and/or different number of transform-levels will result in different decomposition results. In this work, 1-level db10 wavelets are used for the decomposition.
[image:2.612.346.544.298.367.2]Figure 2. Multi-resolution structure of wavelet decomposition
In this work, histogram equalization is used to enhance the contrast of the approximation coefficients. Therefore, the illumination of the approximation image is also normalized. The perceptibility of edges and small features can be improved by enlarging the amplitude of the high frequency components in the image. To accentuate details, multiply each element in the detail coefficient matrix (the LH, HL, and HH sub-bands) with a scale factor (>1). In this work, 1.5 is used as a scaling factor. The enhanced image is reconstructed from the histogram equalized approximation coefficients and the enlarged detail coefficients in all three directions using inverse wavelet transform.
Figure 3. Block diagram of Wavelet-based normalisation
In normalization, the division operation may intensify unexpected noise terms. To recover the rich texture and remove the noise at the same time, integrate the normalized gradients with the anisotropic diffusion method [7]. This hierarchical decomposition of the image eliminates the notorious halo effect. At each hierarchical level the method segments the image into smooth regions while stopping at sharp discontinuities, encourages intra-region smoothing. Complete removal of the illumination variations can lead to loss of useful information for recognition purpose, so fuse the reconstructed image with the original input image. The fused image is obtained by:
χ
INGI= α χ
r+ (1- α )χ
Where χr is the final reconstructed image and α is the weighting parameter, 0≤ α ≤ 1. Here, it is chosen as 0.5.
III. MULTIPLE FACE MODEL
[image:2.612.77.260.610.682.2]International Journal of Emerging Technology and Advanced Engineering
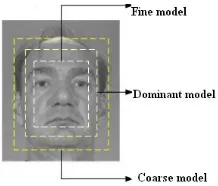
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)184 It consists of three face models with the same image size with different eye distances. They are fine, coarse and dominant. It is designed to imitate the human visual system and examines a face image from the internal facial components to the external facial shapes.
[image:3.612.109.218.300.393.2]The fine face model is formed to analyze the internal components of a face, such as the eyes, nose, and mouth, while the coarse face model includes the general structures of a face and the external components such as hair, ear, and jaw-line. The the dominant face model, is a compromise between the fine model and the coarse model. The fine face model is robust to background and hair style changes but sensitive to pose changes. On the other hand, the coarse face model shows the opposite tendency.
Figure 4. Multiple Face Models
IV. FEATURE EXTRACTION
To analyze the face structure effectively, Fourier features are used for image representation[9] by using Fourier transform. It can facilitate features from different Fourier domains and frequency bands. The Fourier transform is a complex function given as:
F(u,v) = R(u,v) + jI(u,v)
Where R(u,v) and I(u,v) are the real and imaginary components respectively. There are three different Fourier features the concatenated real and imaginary component domain, Fourier spectrum domain, and phase angle domain. To avoid the angular problem in phase angle the cosine values are used.
RI(u,v) = [R(u,v) I(u,v)]
⌠(u,v) = | F(u,v) = [R2(u,v)+ I2(u,v)]1/2 Φ(u,v) = cos(tan-1[I(u,v)/R(u,v)])
The domain, combined real and imaginary has more powerful descriptions to distinguish faces than other domains. Other domains provide complementary features for better analysis of the face image.
The final augmented feature consists of three different complementary features.
Finally, this is projected to other PCLDA spaces[8] in order to reduce the dimensionality.
V. PCLDA
Due to the measurement cost and classification accuracy, the number of features should be kept as small as possible. A small and functional feature set makes the system work faster and use less memory. For this, a two stage PCA+LDA approach, Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) called PCLDA has been used. Here the higher dimensional face data is projected to a lower dimensional space using PCA and then LDA is applied to this PCA subspace.
A. Principal Component Analysis
The images of a particular face lie in a linear subspace of the high dimensional image space. The image is linearly projected into a subspace in a manner which discounts those regions of the face with large deviation i.e. it identifies variability between human faces and thus reduces the feature space dimension. Using PCA, the extracted features of all faces in the face database are transformed into face space. Then face recognition is achieved by transforming any given test image into face space and comparing it with the training set vectors. The closest matching training set vector should belong to the same individual as the test image.
PCA does not attempt to categorise the faces using familiar geometrical differences, such as nose length or eyebrow width. Instead, it determines which 'variables' account for the variance of faces. In face recognition, these variables are called eigenfaces because when plotted they display a resemblance to human faces. The advantage of PCA comes from its generalization ability. It determines which projections are preferable for representing the structure of the input data. Those projections are selected in such a way that the maximum amount of information (i.e. maximum variance) is obtained in the smallest number of dimensions of feature space.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)185 So ultimately the eigenvectors having the most significant eigenvalues are selected. Then the set of face images are projected into the significant eigenvectors to obtain a set called eigenfaces which gives the best variance in the data. Later, the training images are projected into the eigenface space. Next, the test image is projected into this new space and the distance of the projected test image to the training images is used to classify the test image.
B. Linear Discriminant Analysis
The database is divided into a number of classes each class contains a set of images of the same person in different viewing conditions like different frontal views, facial expression, different lighting and background conditions and images with or without glasses etc. It is also assumed that all images consist of only the face regions and are of same size. By defining all the face images of the same person in one class and faces of other people in different classes we can establish a model for performing cluster separation analysis.
It tries to find the subspace that best discriminates different face classes. The within-class scatter matrix, also called the intra-personal, represents the variations in appearance of the same individual due to different lighting conditions and face expression, while the between-class scatter matrix, also called the extra-personal, represents variations in appearance due to adifference inidentity. By applying this method, the projection directions that on one hand maximize the distance between the face images of different classes on the other hand minimize the distance between the face images of the same class is found i.e. maximizing the between-class scatter matrix, while minimizing the within-class scatter matrix in the projective subspace.
VI. CLASSIFICATION
Now the test image subjected to recognition is also projected to the face space and then the weights corresponding to each eigenface are found out. The weights of all the training images are found out and stored. The trained images are not stored as raw images rather they are stored as their weights which are found out projecting each and every trained image to the set of eigenfaces obtained i.e. after performing PCLDA. Now the weights of the test image are compared to the set of weights of the training images and the best possible match is found out. The comparison is done using the Euclidean distance nearest-neighbor classifier.
The easiest way to determine which face class /cluster provides the best description of an input face image is to find that class which minimizes the Euclidian distance. Minimum the distance is the maximum is the match.
If the feature vector of the probe is x and that of a database face is y, where x=( x1, x2, x3,….xn) and y= (y1, y2,…...yn). The position of a point in a Euclidean n-space is a Euclidean vector. So, x and y are Euclidean vectors, starting from the origin of the space, and their tips indicate two points. The Euclidean norm, or Euclidean length, or magnitude of a vector measures the length of the vector as follows:
If the minimum value of the measured distance, € is below the threshold, then the recognition is successful and relevant information about the recognised face is provided from the database which contains information about the faces.
VII. RESULT ANALYSIS
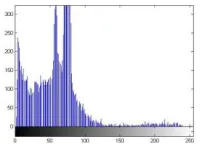
The Olivetti Research Laboratory (ORL) face database and Yale database are used in order to test the proposed method in the presence of head pose variations. The analysis is done using histogram and an image quality metric, Peak Signal to Noise Ratio (PSNR).
[image:4.612.394.494.596.670.2]For performing the experiment, 100 images of 10 individuals with 10 images of each are taken. This recognition system tries to find the identity of a given face image according to its memory. The memory of a face recognizer is generally simulated by a training set. The training set consists of the features extracted from known face images of different persons. As there are 10 images per individual in the ORL database, first 3 of them are used to train the system and the rest are used to test it. For testing the whole database, the faces used in training, testing and recognition are changed and the recognition performance is given for whole database.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013) [image:5.612.70.279.100.496.2]186
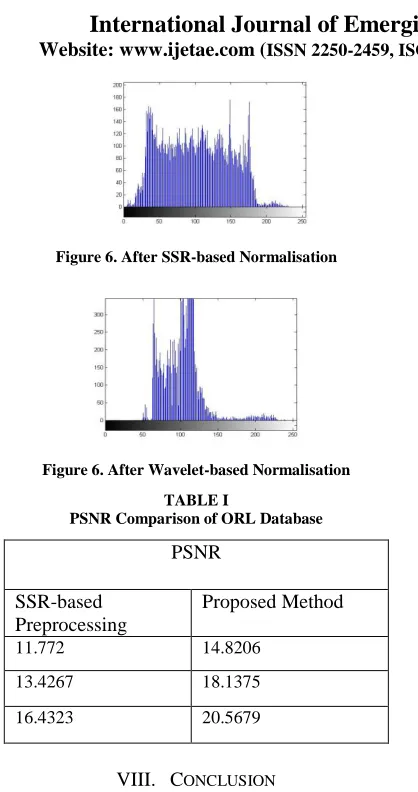
Figure 6. After SSR-based Normalisation
Figure 6. After Wavelet-based Normalisation
TABLE I
PSNR Comparison of ORL Database
PSNR
SSR-based Preprocessing
Proposed Method
11.772 14.8206
13.4267 18.1375
16.4323 20.5679
VIII. CONCLUSION
Ambient lighting changes greatly within and between days and among indoor and outdoor environments. Illumination variation is a major challenge which causes serious performance degradation for most practical face recognition systems.
To overcome the uncontrolled environmental problems, a novel illumination invariant preprocessing algorithm is used which includes the Wavelet-based normalization technique. This is a photometric normalization method based on human perception theory and illumination properties. It is a combination of two approaches, histogram normalization and photometric normalization. When compared to the single scale retinex method, the wavelet-based normalised image has not only enhanced contrast but also enhanced edges and details that will facilitate the further face recognition task. Thus, the result shows that the wavelet method can improve the face recognition rate.
REFERENCES
[1] Y. Su, S. Shan, X. Chen, and W. Gao, 2009, “Hierarchical ensemble of global and local classifiers for face recognition,” IEEE Trans. Image Process
[2] M. Savvides, B. Kumar, and P. Khosla, 2004, “Corefaces—Robust shift invariant PCA based correlation filter for illumination tolerant face recognition,” in Proc. IEEE, Comput. Vis. Pattern Recognition [3] X. Wang and X. Tang,2004, “Random sampling LDA for face
recognition,” in Proc. IEEE. Comput. Vis. Pattern Recognition [4] Chyuan-Huei Thomas Yang, Shang-Hang Lai, and Long Wen
Chang,2003, “A reliable face recognition algorithm based on matching normalized gradients in Proc. IEEE.
[5] Wonjun Hwang, Haitao Wang, Hyunwoo Kim, Seok-Cheol Kee, and Junmo Kim, 2011, “Face Recognition System Using Multiple Face Model Of Hybrid Fourier Feature Under Uncontrolled Illumination Variation,” in Proc. IEEE
[6] S. Samsung,2005, “Integral normalized gradient image —A novel illumination insensitive representation,” in Proc. IEEE Workshop Face Recognit. Grand Challenge Exper.,
[7] J. Malik and P. Perona, 1990, “Scale-space and edge detection using anisotropic diffusion,” IEEE Trans.