DATA MIGRATION FOR DATA INTENSIVE
SOFTWARE PRODUCTS
ANDREI IDU
MASTER THESIS
MASTER IN BUSINESS INFORMATICS
DEPARTMENT OF INFORMATION AND COMPUTING SCIENCES UTRECHT UNIVERSITY, THE NETHERLANDS
MOTTO:
“INFORMATION IS FOREVER.”
LEONARD SUSSKINDDATA MIGRATION FOR DATA INTENSIVE
SOFTWARE PRODUCTS
Author Andrei Idu
Student Id 3563480 Email [email protected] Date 16 August 2012 Utrecht University Supervisors Drs. Ravi Khadka Dr. Slinger Jansen Dr. Rik Bos AFAS Supervisors Rolf de Jong
ACKNOWLEDGEMENTS
This master thesis reports the research that I performed as a graduation project of the Business Informatics master program at the Utrecht University. As part of this project, I did an internship at AFAS Software B. V. Throughout the research, many people offered me guidance, support and feedback. I would like to acknowledge those people further.
First of all, I would like to thank my University supervisors, drs. Ravi Khadka, dr. Slinger Jansen and dr. Rik Bos. They offered me help in developing my work and guided me in my research. Ravi, thank you for your support in every step of the process, for your availability, for helping me to find a clear vision and for your attention to detail. Slinger, thank you for your help and direction in improving the research and keeping me on a rigorous path. Rik, thank you for your openness, constructive comments and support.
I would also like to thank my supervisors at AFAS, Rolf de Jong and Machiel de Graaf. They offered me a great opportunity to work with AFAS. Rolf, thank you for the vision and especially for the discussions which sparked the main creative ideas of this project. Machiel, thank you for your continuous support during my internship and especially for guiding me towards the implementation of the project. I would also like to thank all the colleagues in the Architecture and Innovation department at AFAS. They created a great work atmosphere. Furthermore, I would like to thank the 11 experts who evaluated my work and offered feedbacks to enhance it. Their insights were very valuable. Thank you to the people that helped me get in contact with the experts as well.
I would also like to thank my friends who supported me throughout the project and even gave me feedback on my work. Thank you Elena Iancu, Florin Serban, Rares Rusu, Tommy van de Zande, Lucian Cancescu, Anna Sosievici, Razvan Turtoi and Ana Stroe. And thank you to all the master colleagues for the feedback at the colloquium sessions.
Finally, I would like to warmly thank my family. My parents, Pompilia and Nicolae Idu, and my sister, Roxana Idu, thank you for the care and unconditional support with which you surrounded me throughout my studies.
ABSTRACT
Data migration, even though a practitioner’s topic, is addressed to good extent in academic literature. Nevertheless, there is a gap in literature regarding data migration under the influence of the specific circumstances of software product companies. The majority of publications address data migration from a perspective of a service provider that builds a onetime solution for a data owner. When software product companies re-engineer a data intensive product, a data migration solution is needed. However, the situation is different than that of classical data migration because the company has in house knowledge of the source, is itself building the target and must provide replicable deployment to all customers. Thus, software product companies are left to tailor data migration to a software product situation without any guidance from academic literature.
To help software product companies manage data migration, this work proposes a software product data migration method. The method is built using assembly based situational method engineering. In order to use this technique existing literature is studied to identify methods, phases and activities of data migration. Situational method engineering is used to analyze and compare the existing methods in order to assemble a data migration method that includes a software product company perspective. The method is then evaluated by 11 data migration experts. The evaluation yielded positive results in terms of validity measures and allowed for the method to be refined based on comments and feedback from the experts. Finally, a case study on implementing the method at AFAS Software B.V., a Dutch software product company, is performed to attest the applicability of the method and bring to light insights regarding software product data migration.
TABLE OF CONTENTS
1. Introduction ... 1
1.1. Motivation ... 1
1.2. Research Questions ... 2
2. Research Approach ... 5
2.1. Design Science Research ... 5
2.2. Research Planning ... 6 2.3. Research Methods ... 7 2.3.1. Literature Study ... 7 2.3.2. Case Study ... 8 2.4. Final Deliverable ... 9 2.5. Contribution ... 9 2.5.1. Scientific Contribution ... 9 2.5.2. Social Contribution ... 9 3. Literature Study... 11 3.1. Definition ... 11 3.2. Characteristics ... 12
3.3. Data Migration Methods ... 14
3.3.1. Technical Perspective ... 14
3.3.2. Management Perspective ... 20
3.3.3. Data Migration Strategies ... 29
3.4. Software Product Data Migration ... 30
3.5. Overview ... 32
4. Software Product Data Migration Method ... 35
4.1. Method Engineering ... 35
4.2. Data Migration Requirements ... 37
4.3. Method Selection ... 38
4.4. Method Analysis ... 38
4.5. Method Comparison ... 38
4.6.1. Supermethod... 42
4.6.2. Deliverables ... 45
4.6.3. Situational Data Migration Method ... 45
4.7. Evaluation ... 55
4.7.1. Interviews and Questionnaire ... 56
4.7.2. Evaluation Findings ... 58 5. Case Study ... 61 5.1. AFAS ... 61 5.2. Data Migration ... 62 5.2.1. Method ... 62 5.2.2. Solution Architecture ... 64
5.3. Issues and Lessons Learned ... 67
6. Discussion ... 71
6.1. Research Limitations ... 71
6.2. Validity ... 72
7. Conclusion ... 75
7.1. Revisiting the Research Questions ... 75
7.2. Future Research ... 77
References ... 79
Annex ... 83
Annex A: Russom (2006) Data Migration Routemap ... 83
Annex B: Wu et al. (1997) Butterfly Method Routemap ... 84
Annex C: Morris (2006) Practical Data Migration Routemap ... 85
Annex D: Matthes et al. (2011) Data Migration Process Model Routemap ... 86
Annex E: Preliminary Situational Data Migration Method ... 87
Annex F: Online Questionnaire Responses ... 88
Annex G: Data Migration Requirements Statements For Interviews ... 90
Annex H: Evaluation results ... 91
TABLE OF FIGURES
Figure 1 - Information Systems Research Framework (Hevner et al., 2004) ... 6
Figure 2 - Schema conversion strategies (Henrard et al., 2002) ... 15
Figure 3 - Data migration model (Matuuk et al., 2008) ... 16
Figure 4 - ETL based data migration architecture (Haller, 2009) ... 16
Figure 5 - Data migration approach (Bordbar et al., 2005) ... 18
Figure 6 - Automatic data migration architecture (Dobre & Marin, 2011) ... 19
Figure 7 - Butterfly Methodology (Wu et al., 1997) ... 21
Figure 8 - TDWI data migration development model (Russom, 2006) ... 22
Figure 9 - Data migration process model (Matthes et al., 2011) ... 26
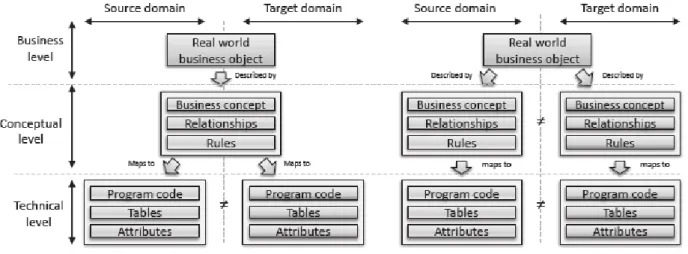
Figure 10 - Relationship between the Business and Technical views ... 26
Figure 11 - Data migration scenarios on Business, Conceptual and Technical levels ... 27
Figure 12 - Data migration levels ... 30
Figure 13 - The data migration dimensions triangle ... 31
Figure 14 - Configuration process for situational methods (Brinkkemper, 1996)... 36
Figure 15 - Assembly based process model for situational method engineering ... 36
Figure 16 - Data migration supermethod ... 42
Figure 17 - Software Development, data migration and overlay ... 43
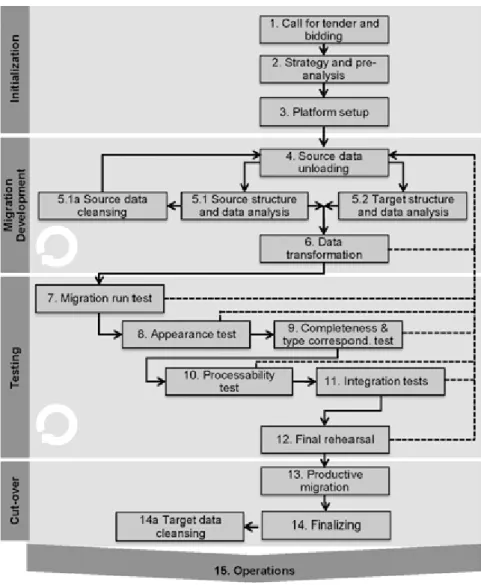
Figure 18 - Situational Data Migration Method – Initialization Phase ... 46
Figure 19 - Situational Data Migration Method – Analysis Phase ... 49
Figure 20 - Situational Data Migration Method – Development Phase ... 51
Figure 21 - Situational Data Migration Method – Testing Phase ... 52
Figure 22 - Situational Data Migration Method - Deployment Phase ... 54
TABLE OF TABLES
Table 1 - Research questions, methods and deliverables ... 6
Table 2 - Keywords used for literature study ... 7
Table 3 - Classification of technical transformations ... 28
Table 4 - Literature Study Overview ... 32
Table 5 - Data Migration Requirements ... 37
Table 6 - Requirements vs methods ... 38
Table 7 - Phases comparison ... 39
Table 8 - Activity comparison ... 39
Table 9 - Initialization Phase activity table ... 47
Table 10 - Initialization Phase deliverable table ... 47
Table 11 - Analysis Phase activity table ... 49
Table 12 - Analysis Phase deliverable table ... 50
Table 13 - Development Phase activity table ... 51
Table 14 - Development Phase deliverable table... 51
Table 15 - Testing Phase activity table ... 52
Table 16 - Testing Phase deliverable table ... 53
Table 17 - Deployment Phase activity table ... 54
Table 18 - Deployment Phase deliverable table ... 54
Table 19 - Interview respondents ... 56
Table 20 - Questionnaire respondents ... 56
Table 21 - Method evaluation statements ... 57
1
1.
INTRODUCTION
This thesis describes research performed on the topic of data migration for data intensive software products. The aim of the research is to develop a method that software product companies can use in order to manage data migration for the software products the companies build. The research is motivated by the fact that software product companies should develop solutions for data migration using different methods than what is available in academic literature. In this chapter the triggers for data migration of software product companies are described and the gap in academic literature is presented. Furthermore, the research questions are defined and discussed.
Section 1.1 covers the motivation by explaining the main concepts used in the research: data intensive software product and data migration, and by positioning the research trigger in science and practice. Section 1.2 presents the main research question and the three sub-questions of the research.
1.1.
MOTIVATION
Software can generally be divided between two types (Sawyer, 2000). There is custom-made software and product software. Custom-made software is software specially developed for one company or user. Xu & Brinkkemper (2007) define product software as “a packaged configuration of software components or a software-based service, with auxiliary materials, which is released for and traded in a specific market”. Product software consists of commercial software, large packaged software, packaged software, commercial of the shelf software, shrink-wrapped software, software-based services and open source software (Xu & Brinkkemper, 2007). The main common characteristic is the concept of “make one, sell many”.
Packaged software is a term that is used in literature to refer to high-end enterprise systems such as Enterprise Resource Planning (ERP) or Customer Relationship Management (CRM) systems (Xu & Brinkkemper, 2007). Such systems are data-intensive as they are built mainly around a database (Shah, Madden, Franklin & Hellerstein, 2001). Haller (2008) mentions that two of the main components of packaged software products are the data model and the operational data that the data model is designed to hold.
Software product companies build software over many years. Software products are in constant evolution as more and more functionality is added. New functionalities are released in different versions or updates of the software. Software updates, first of all, imply that customers are using a previous version of the software already. Managing the evolution of software products is complex and a problem that is underestimated (Jansen, Ballintijn & Brinkkemper, 2005). It is also cause for difficulties for both software vendors and customers. While the software evolves, the number of clients using the product increases as well. Because new functionality is added to the same core product, the same technology that was used when the product was first developed remains in use. This technology can become obsolete in a number of years due to the continuous evolution of IT (Dede, 1989), changes in market demand or rules and regulations (Khadka, Sapkota, Ferreira Pires, Van Sinderen & Jansen, 2011). To overcome this, a software product company needs to stay agile in its environment. Adopting an agile strategy means being able to continuously transform internal operations and innovate (Meredith & Francis, 2000), which ensures competitiveness in the future. Companies choose to re-engineer their software products with new technologies for the purpose of agility. Packaged software involves a system architecture that has the main objectives of enforcing design decisions over the entire product and ensuring reusability of common components (Garlan & Shaw, 1994; Hilliard, 2000). Re-engineering packaged products might require changes on the lowest levels of the system architecture. Thus, re-engineering consists of changes in the core concepts of the technical and business levels of the product. Changes can happen on the user interface level, on the business workflow level, on the data access level and on the data model level. The new data model is dependent on the new technology that is used. Also, the large client base already utilizes a version of the product in production and there is important data that needs to be managed. Because of this,
2
installing a new, re-engineered, version of the product at a client requires updating the data stores to the new data model and moving the client data from the existing data model to the data model used by the new version in a process called data migration. The migration process has to be replicable for every customer the packaged software product company has.
Data migration, although not a new problem, is never a simple and a straight-forward task (Morris, 2006; Lin, 2008). In practice and in literature the topic is mostly presented as a one-time occurrence, as the perspective is from a data migration service provider (Wu, Lawless, Bisbal, Grimson, Wade, Sullivan & Richardson, 1997; Morris, 2006; Russom, 2006; Matthes, Schulz & Haller, 2011;). Because of the one-time nature, data migration effort and complexity is usually underestimated (Shepard, 2004; Russom, 2006). In fact, a recent survey shows that only 16% of data migration projects were delivered on time and on budget (Howard & Potter, 2007). This research was triggered by a Dutch software product company, AFAS Software B.V. The company is currently developing a re-engineered version of its main product. A solution for approaching data migration is needed.
Data migration from the point of view of a software product company requires a specific perspective that adds more complexity to the data migration situation. The company faces a different problem when its strategy requires the data used by its product to be reorganized and migrated. The main differences as opposed to the one-time nature of data migration reported in literature are the fact that the company has prior knowledge about the source version of the software and data model and the fact that it must provide a solution for reorganizing and migrating data in the data stores of all its customers and deliver this as part of the deployment of the new software. Thus, a software product company needs to tailor data migration methods to its own situation. There is a lot of literature regarding data migration methods, however, most have incomplete coverage of the full scope or feature the solution to a certain situation in practice and are not generally applicable and reliable.
In order to be able to manage the complex data migration process there is a need for a method that models its different phases and activities in a complete manner. Such a method should be applicable in practice in general and for software product companies building their own data migration platform and solution.
This leads to eliciting the following problem statement:
The current body of knowledge on the topic of data migration does not address the specific circumstances of software product companies, creating difficulties for the software product companies to tailor the data
migration process to align with the software product situation.
1.2.
RESEARCH QUESTIONS
Considering the above problem statement we can now define the main research question. The main research question is based on the gap in scientific literature for addressing the specific problem above and the practical need for software product companies to manage this situation.
The topic of this research is proposed by the case study company because of their change in strategy that required their products to be re-written. By re-writing the software the data models are reorganized as well and so emerges the practical need to develop a data migration solution that can be applied for all their customers. The functionality of the products remains the same. However, the logical approach to the actual organization of data changed.
Because of empirical need and the scarce scientific literature on the topic of data migration from a software product company perspective, the following research question is formulated:
3
RQ: How can data migration be tailored to the specific situation of software product companies?
We analyze each aspect of the research question to define sub-questions aimed at giving a clearer understanding at what the scope of the research is and what the deliverables are. First of all, the main issue is how to undertake a data migration project. For this, literature on this topic needs to be studied and phases and activities for methods that offer solutions to data migration should be identified. Thus the first sub-question is: RSQ1: What are the main data migration methods that appear in scientific literature?
RSQ1 is answered by performing a literature study to build a theoretical landscape of data migration. The definition of data migration, main characteristics of data migration projects and various methods of undertaking, both technical and process oriented, are identified. The literature study has two objectives: first, it grounds the research in theory, and second, it helps to identify candidate methods for developing a software product data migration method. The method is developed through situational method engineering (Brinkkemper, 1996) using the method assembly technique (Ralyté, Deneckère & Rolland, 2003). Based on this we can define the second sub-question as:
RSQ2: How can a method for managing data migration for software product companies be developed?
RSQ2 is answered by following the steps of assembly based method engineering. In a first stage requirements for data migration is defined. Further, candidate methods are identified from the literature study using the requirements. Then, the methods are compared and a situational method is build using fragments that are relevant to software product data migration. Having a method developed there is an issue of the validity of the method in practice and the evaluation of the method. Thus, the third sub-question is:
RSQ3: How can a method for managing data migration for software product companies be implemented in practice?
In order to answer the last question, expert interviews are performed in order to assess the validity of the research. Experts are asked to rank the method on different quality measures and to provide feedback on the developed method. In addition, a case study is performed at the software product company that triggered the research. In the case study the focus is on the implementation of the method in the company and on relating the method to the software product development process. Finally, the findings of the interviews and case study are used to refine the method and to finalize the method.
5
2.
RESEARCH APPROACH
This chapter describes the research approach used to answer the research questions presented in Chapter 1. The main research method used is design science in information systems research. The research is split into several activities, each conforming to a complementary research method. The methods are used to produce a final deliverable in the form of software product data migration method. The method has both scientific and social contributions. In science, it fills the gap of data migration for software product companies. As a social contribution, the method can yield more efficient processes which in turn have beneficial influence over human resources.
The main research method is described in Section 2.1. An overview of the activities that are undertaken to answer each research question is presented together with the deliverables they produce in Section 2.2. Two of the chosen research methods used to perform the research are presented in Section 2.3. More information on research methods used can be found in Chapter 4. Section 2.4 provides a description of the final deliverable of the research. Finally, the scientific and social contributions of the research are presented in section 2.5.
2.1.
DESIGN SCIENCE RESEARCH
This research follows design science in information systems research, as suggested by Henver et al. (2004). The suitability of this research approach comes from the fact that design science in Information systems research aims at creating and evaluating IT artifacts with the intent to solve organizational problems. Synonymously, March and Smith (1995) also use the terminology of “build” and “evaluate” as the processes of design science. Therefore, design science assists in building an artifact and in evaluating that artifact. This research is aims at building a method for software product data migration, the artifact, which is evaluated for purposes of validity and applicability.
There are four types of design artifacts: constructs, models, methods and instantiations (March & Smith, 1995). Within the scope of this research, models and methods are of primary interest. Models facilitate understanding and present the relationship between a problem and its solution. Methods represent processes and they offer guidance on how problems can be solved. The main deliverable of this research is aimed at offering a better understanding of the data migration process, as well as offering guidance in performing data migration for software product companies.
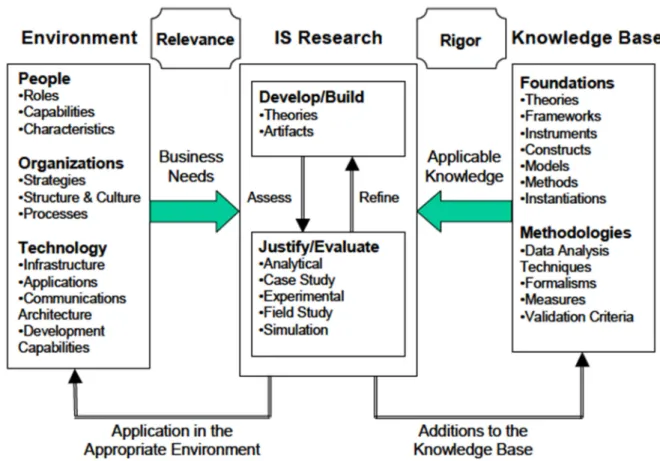
Figure 1 presents the Hevner at al. (2004) Information Science Research Framework that this thesis follows as a basis for conducting the research. On this framework the three research sub-questions are overlaid for understanding in which part of the process they are answered. The main trigger for this research came from a Dutch software product company, AFAS Software B.V. This represents the Organizations concept in the Environment side of the framework. AFAS is in need of a solution for data migration from an existing version of its product to a re-developed version of the same product. This represents the Business Need which gives the research Relevance. Based on this business need the main research question and the three sub-questions are developed. To answer the first sub-question (RSQ1), existing literature on data migration is studied. This represents the Knowledge Base from which Methods, Models and Frameworks are chosen as Applicable Knowledge. To answer the second sub-question (RSQ2), the literature study is used as a basis for developing a method for software product data migration. This represents Developing an Artifact. To answer the third sub-question (RSQ3), the method is evaluated through expert interviews and case study. Finally, the results of the evaluation are used to refine the method. This represents Evaluation through Analytical and Case Study means in the IS Research Framework. The findings of this research are, in the end, an addition to the IS knowledge base and are applicable in the appropriate environment.
6 Figure 1 - Information Systems Research Framework (Hevner et al., 2004)
2 . 2 .
R E S E A R C H P L A N N I N G
This section describes the phases that are part of the research approach. Each phase is performed using a research method. Table 1 presents the research questions and the research methods and deliverables that are used to answer them.
Table 1 - Research questions, methods and deliverables
Research Question Research Method Research Deliverable
RSQ1 Literature Study Data Migration Methods
RSQ2 Assembly Based Method Engineering Preliminary Situational Data Migration Method
RSQ3 Expert Interviews
Case Study
Evaluation Ratings Interview Findings Case Study Findings
RQ Design Science Situational Data Migration Method
The ordering in the table is according to the chronological order of each stage of the research. In a first stage, Data Migration Theory, Data Migration Phases and Data Migration Activities are identified using the Literature Study method. The following stage consists of analysis of the theoretical findings. A Preliminary Situational Data Migration Method is developed using Assembly Based Method Engineering. The method is evaluated through Expert Interviews and a Case Study at a software product company. Further, the method is analyzed and refined taking into account the Evaluation Ratings, Interview Findings and Case Study Findings. Thus, the final Situational Data Migration Method is developed. As a final stage not presented in the table, Conclusion of
7
the research process deals with correctly reporting the findings and addressing any research issues and further research.
The details of how each research method is employed in order to perform the research are presented further. Section 2.3 covers the literature study and case study phases. Please note that Chapter 4 describes the assembly based method engineering technique and the evaluation interviews.
2.3.
RESEARCH METHODS
For the purpose of performing this research and answering the research questions, different research methods are used. Section 2.3.1 describes the technique of literature study and how it is employed. And Section 2.3.2 describes the method used for performing the case study. The technique of assembly based situational method engineering is presented in section 4.1 for the purpose of better understanding the complex process of developing the situational method. The technique of performing the evaluation interviews is presented in section 4.8 for creating a better overview of the evaluation process.
2.3.1.
LITERATURE STUDY
The literature study technique is used in this research mainly for the purpose of presenting the current landscape on publications in the field of data migration. Moreover, the literature study is used to identify existing methods that could be used later in the method engineering process.
The literature study is performed using the structured approach recommended by Webster and Watson (2002) for identifying relevant literature. The approach consists of three activities. The first activity deals with finding major contributions in the field using leading sources. The second activity discovers new literature by using the citations in the identified literature and going backward to determine prior publications. And the third activity finds newer literature by using search engine tools to go forward and identify publications that referenced the already identified literature. These activities are governed by a constant pursuit of high-quality sources such as journals and conferences. Finally, the literature study is drawing to an end when discovering new literature does not bring up new concepts or theories that were not covered by the already identified literature.
For the first activity of the literature study two academic search engines are used, Google Scholar (http://scholar.google.com) and CiteSeerX (http://citeseerx.ist.psu.edu). The search queries used are a combination of data migration relevant concepts and their synonyms. Prior research experience with performing a Systematic Literature Review (Khadka, Saeidi, Idu, Hage & Jansen, 2013) helped in building search queries and making the best use of the search engines’ functionalities. The concepts are presented in Table 2.
Table 2 - Keywords used for literature study
Keyword 1 Keyword 2
Data Migration
Database Conversion
Data schema Transformation
Data model Reorganization
Legacy system Evolution
Results are sorted in both search engines by Relevance and the first 3 pages of results were scanned for titles and abstracts to determine relevance. Backward discovery is conducted on the literature found by identifying more literature in the references of the primary works found. Forward discovery is employed by using the search engines’ “Cited by” functionality. In total a number of 74 publications are identified as relevant based on
8
title and abstract. After content analysis, a number of 43 publications have been used to present the theory in the literature study chapter.
2.3.2.
CASE STUDY
A case study at AFAS Software, the company that initiated the research project, serves as further validation of the artifacts developed in this research. Darke et al. (1998) mention that case studies are suitable for different research aims, one of them being testing of theory. The case study is used to answer RSQ3 regarding the applicability of the method. According to Yin (2003), single case studies are suitable in the occurrence of a revelatory case, or a critical case or a unique case. The setting for the main contribution of this research is rare, and therefore AFAS is seen as a revelatory case. No other software product companies are identified to be in a similar situation that would require data migration.
Case study research is typically of a flexible design type (Runeson & Höst, 2008). However planning for a case study is very important for its success. For the case study we make use of the proposed case study plan by Robson (2002). The case study plan used for the AFAS case study is the following:
• Objective: determine applicability of the software product data migration method.
• The case: the development of a new product version at AFAS Software coupled with the development of a data migration solution.
• Theory: theory regarding data migration and the method is presented in chapters 3 and 4.
• Research question: RSQ3.
• Methods: data collection and analysis methods are detailed in the following paragraphs.
• Selection strategy: explained in the previous paragraph as based on a revelatory case.
Darke et al. (1998) mention that a case study consists of combining different data collection techniques, such as interviews, observation, questionnaires and document analysis. For the case study at AFAS the following data collection activities are performed:
• Observation of implementing the method at the company – The researcher was present at the company during a 6 month period in which observation of day to day activity was performed. Relevant information was recorded in a research notebook as well as in various digital documents.
• Interviews – During the 6 month period multiple unstructured interviews and discussions took place. The roles of the interviewees in the company were: CIO, Project manager, Designers and System architects. The role of the interviews was to gather in depth information about AFAS, its product, its development strategy and process, and about its data migration strategy and process.
• Workshop – A data migration workshop for the AFAS solution was held. During the workshop an example case of migrating data was described and performed in order to understand the workflow and the functionality of the data migration solution.
• Analysis of requirements, design and technical documentation – AFAS provided unrestricted access to all documentation available on its existing product, the new version of the product and the data migration procedures and solution.
• Observation of team meetings and solution presentations – The Architecture and Innovation department at AFAS holds weekly kick-off meetings in which current tasks are presented. Every 2 months there are department meetings meant to describe newly developed solutions. Yearly, a 2 and a half day outing of all software development staff takes place in which progress from the previous year is presented. In addition to the presentations, workshops on using the newly developed software are held.
9
Analysis of the data gathered from the above collection techniques is based on Mays, Pope & Ziebland (2000) framework. The framework consists of five stages: familiarization by immersion in the raw data, identifying a thematic framework, indexing by applying short text descriptors to the data, charting by rearranging the data according to the framework and, finally, mapping and interpretation based on the original research objectives.
2.4.
FINAL DELIVERABLE
The final deliverable of this research is a situational method for managing data migration for data intensive software products. The two situations presented are the classical approach of a third party perspective and the software product company perspective. The method defines the phases and activities that the process comprises of. Also, it includes the logical order for undertaking the activities, the deliverables of each activity, the relationships between them and the roles of the actors responsible for each activity and deliverable. Intermediary deliverables that are presented in this research are also valuable for scientific and practical reasons. The deliverables consist of:
• Comprehensive literature study on data migration – The aim of this is to provide a complete overview of the subject. Practitioners and academics can use the literature study to get familiar with data migration and understand the topic.
• Software product data migration case study – The main purpose of this deliverable is to attest the validity of the final deliverable, however, the case study also presents new insights into performing data migration from a software product company perspective.
2.5.
CONTRIBUTION
Referring back to the Hevner et al. (2004) IS research framework, the research is triggered by the business needs of software product companies. A solution for the software product companies’ management of data migration is needed. This research main aim is producing a generalizable method that is applicable for any software product company.
2.5.1.
SCIENTIFIC CONTRIBUTION
Most scientific literature regarding data migration is focused on a solution for a one-time problem. This problem is seen from a perspective of the data owner or that of a third party service provider. In general data migration literature discusses a case that is performed in practice and is used to develop a theory. Thus, validation and general applicability of methods is not completely guaranteed. Out of the methods that are built on a higher number of cases or experience accounts, while bringing important additions to the field, each has its drawbacks by not covering the entire process.
This research has the aim of delivering a method for developing and performing data migration for software product companies. In developing a method for the software product situation a complete general situation data migration method is built for support. Thus, the scientific contribution of this research is two-fold: by providing the software product situation data migration method and by adding a complete overview of a data migration process to the data migration body of knowledge. Finally, the work presented in this research can be the basis for further research in data migration, and especially in software product data migration.
2.5.2.
SOCIAL CONTRIBUTION
Apart from the scientific contribution, this research has a social contribution as well. The investments required for managing a data migration process are usually high and this management is a complex task. The audiences
10
for this research in the empirical world are companies that use data intensive systems that require data migration, companies that offer data migration as a service, companies that offer consulting services and, finally and most importantly, data intensive software products companies.
Data owner companies and data migration service providers can benefit from the deliverable of this research by applying a method which can guide them when performing data migration. The method should make data migration understandable and offer a full process to follow. The method can also be used to offer new insights into the process of data migration, insights that can be used to refine an existing method. Consultancy companies can use the data migration method to strengthen their domain knowledge and expertise and offer higher value service.
Software product companies can use the software product situation in the method to follow a structured, innovative manner in developing software and data migration solutions. Advantages for software product companies come mainly from reducing effort and increasing overall involvement in the process. Effort is reduced by coupling certain data migration activities with the product development activities. Involvement is enabled by the close relationship between the two processes.
More efficient processes within a company mean human resources can be redirected from laborious tasks, such as manual data entry, to other tasks that offer higher fulfillment, such as creative or communication tasks. With such advantages, society can benefit from increased competition which leads to better and cheaper products and services.
11
3.
LITERATURE STUDY
This chapter presents the state of the art in academic literature regarding the topic of data migration. A study into the definition of data migration is presented followed by characteristics of the data migration process. Various data migration methods are studied. The methods are categorized into two perspectives that are found throughout existing literature: technical and managerial. Strategies for performing the methods are also discussed. The scarce literature addressing software product migration is studied in closing of the chapter. Section 3.1 aims to define the term of data migration. Section 3.2 presents the characteristics of data migration in general. Further, in Section 3.3 the most relevant methods and strategies for migrating data are presented. Section 3.4 describes the specifics of migrating data for software products. Finally the chapter closes with an overview of the literature presented in section 3.5.
3.1.
DEFINITION
Even though the topic of data migration has been researched to some extent there are very few academic publications that provide a definition for the term. Most literature either describes the process from a certain perspective or it focuses on only one aspect of it. This section further presents the definitions found in literature and in the end motivates which one is the one appropriate for this research.
Drumm et al. (2007) offer a first definition for data migration. Data migration is defined as the process of transforming and integrating data from one or more source legacy data stores to a new target data store. During the data migration process, the data needs to be extracted from the source, transformed and loaded into the target.
Haller (2008) also provides a definition for data migration. His main reason for defining data migration is in order to separate it from the concept of database migration which encompasses migrating database specific objects such as triggers or procedures together with the data. Thus he states that data migration refers only to migrating data out of one schema to a new schema. The new schema can be structured completely differently from the existing one.
Matthes & Schulz (2011) compile a definition of data migration based on the state of the art in academic and practitioner’s literature and their own research. The definition they offer states that data migration is a “tool-supported one-time process which aims at migrating formatted data from a source structure to a target data structure whereas both structures differ on a conceptual and/or physical level”. This definition is preferred by the author because it touches on all the relevant concepts of data migration. Because data migration is a process it encompasses a control and data flow. The aim of the process is to migrate formatted data from a source data structure to a target structure. Both of these structures are specific to the business context of their applications, thus they are different from a conceptual and/or physical level. The conceptual level refers to the business concepts that each application uses and models its data with. The physical level refers to the technical structure that holds the data structures. Also, the process of data migration can be made more efficient by using appropriate software tools to support it. Furthermore, the one-time perspective here refers to the fact that the source and target applications are not expected to run simultaneously, once changeover to the target is done, the source application is no longer used.
Data migration entails two components. The first one is the restructuring of data, while the second one refers to the actual transfer of data between source and target.
Restructuring data has been addressed as early as 1979. Sockut & Goldberg (1979) discuss reorganization problems in databases at a time when database systems were still an emergent technology. They offer a
12
definition for data reorganization as being the process of changing the logical or physical structure of existing data. Reorganization is this context encompasses the terms restructuring, which refers to the logical level, and reformatting, which refers to the physical level. The issues that are to be taken into account when undertaking data reorganization are:
• Recognize the need to reorganize
• Decide what the target structure is
• Decide when the actual reorganization takes place
• Know how to execute the reorganization
• Determine the benefit of reorganization for the company
• Assess the costs of reorganization
• Be aware of who and what is affected by reorganization
• Document changes that result from reorganization
• Confirm that reorganization has yielded the desired result
The transfer of data form source to target is supported by matching the two schemas and by defining mappings between the two (Hainaut et al., 2008; Drumm et al., 2007). The process of mapping is usually done by business experts who have knowledge of both source and target structures. Mapping can also be supported by software tools and even automated to some extent in order to speed up the entire process (Drumm et al., 2007).
3.2.
CHARACTERISTICS
This section presents a non-exhaustive list of characteristics specific to the data migration projects or to the data migration process in general. These characteristics have been extracted from the current state of the art of data migration as described in the existing literature. The main source for the list below is from the technical report by Matthes & Schulz (2011) as they provide an elaborate overview of data migration characteristics. The characteristics are complemented with extra information from other existing literature. The characteristics of data migration have two roles in the research. First, the theoretical landscape is strengthened, and second, the characteristics are used as a basis for identifying data migration method requirements in Chapter 4. A number of sixteen characteristics are presented further.
Data Migration as an IT Project –The data migration process is implemented in a form of a project with phases including planning, implementation and testing. It should be regarded as an independent project with its own start and end dates (Willinger & Gradl, 2004).
Low frequency – Data migration is a onetime event, it is not continuous (Haller, 2008). In this regard experience is limited and there is little documentation written about it because after a data migration project is completed mid-term and long-term plans do not include such an issue arising again.
High risk – Enterprises consider data as one of their most valuable assets, with some data even being critical to the success of the business. Therefore, any project that involves manipulation of this data is considered of high risk for the enterprise (Informatica, 2010).
Timeless – Even though it occurs rarely in the lifetime of an enterprise compared to other types of projects, as a general discipline data migration is timeless in the sense that as long as there is data and changing applications that access it there is always a need for migrating data (Wu & Tang, 1997). The continuous evolution of IT and business processes cyclically triggers data migration within an enterprise (Russom, 2006).
Tightly coupled to a business application project – The success of a data migration project depends on the alignment between it and the business application project (Morris, 2006). Keeping the two in sync at all time
13
yields best results with minimum costs and performance. A business application project is completed only when the new application is successfully integrated with the migrated data.
Technical but critical for business application project – Because a business application relies on data to actually be of use, data migration is critical for the success of a new business application project, even though data migration uses almost entirely a technical perspective and is not a direct business enabler (Russom, 2006). More than copying data – The term migration might be misleading to think that the data is only copied from source to target. Perhaps a more exact term would be conversion. Data is rarely copied without transforming it. Some data owner can take the opportunity of data migration to improve data models and data quality which in turn means more complexity added to the transformations (Russom, 2006).
Iterative – Data migration is not a one shot process (Russom, 2006). It requires a high degree of iteration in the design, build, and test cycle. It is common to start off with simple mapping and transformations and add complexity as the project evolves and as more understanding about the source and target is gathered (Haller, 2011). The costs for developing and maintaining any addition code or data that is not certainly necessary are not justified (Schmidt, 2009).
A practitioner’s topic – Most efforts for documenting data migration are from practitioners in the field (Haller, 2009; Morris, 2006). Academic publications regarding the topic are mostly from the 1990’s, showing that in recent times the knowledge specific to this topic lies in with the practitioners as opposed to with the research community.
Left for last – Usually a data migration project is conducted towards the end of an IT project and, because of this, budgets are squeezed as much as possible (Morris, 2006). Also, this makes for a less strategic integrated approach of the IT project including the data migration project. Thus, business returns are overlooked and minimized (Burry & Mancusi, 2004).
Underestimated size and simplified methods – Data migration is often seen as a project with limited complexity requiring little effort and skills (Shepherd, 1999; Lashley, 2006). However, underestimation and lack of planning can lead to projects lasting for several years (Lin, 2008). Reasons for this can also be late completion of the target application, limited involvement from the source application experts and lack of personnel.
Modest tool support – Usually data migration solutions are customized to the current project and are not reusable for future projects. There is a limited choice of software that can assist in the entire data migration process, however for each phase of the process there are several tools that support it (Carreira & Galhardas, 2004).
Data understanding – In order for data migration to be successfully performed understanding of the source data and source and target data models is necessary (Wu et. al, 1997, Shepherd, 1999; Morris, 2006). Also, strategies on accessing the two over the duration of the data migration process need to be developed.
Complete strategy – A data migration project must include strategies for accessing, validating and auditing the data (Morris, 2006). Implementation strategy is an important aspect as well. Types of implementation strategies are presented in Section 3.3.
Collaboration – The success of a data migration project is dependent on how well business experts and the data migration team collaborate and exchange information (Morris, 2006; Russom, 2006). Unfortunately, delays in getting information from the business side are a major drawback in data migration projects (Wagner & Wellhausen, 2011).
14
Time constraint – Commonly there are two types of time constraints that act on data migration. There are restrictions for development time as well as for run time (Wagner & Wellhausen, 2011). Development time is constraint at the starting moment by the need to have the target domain model defined. Development time is also constraint at the end moment as data migration needs to be delivered before the go-live of the target system. The run time constraint refers to how much down time the source system can endure (Wagner & Wellhausen, 2011). Also, there might be only few moments when migration is possible, such as during a holiday or during the night (Morris, 2006).
3.3.
DATA MIGRATION METHODS
Academic literature offers several methods for undertaking a data migration project. In this section the most referenced methods are briefly described. As a result of this study, two perspectives have been found to be predominant in literature. The perspective differ at the granularity level of data migration. One perspective is technical, meaning that data migration is addressed by how data can be migrated. It covers the development of a technical solution. The other perspective is process based, looking into the management of various phases and activities of a data migration project, including management of the development of a technical solution. First, the technical perspective of migrating data is presented followed by the management perspective. Apart from these perspectives, implementation and development strategies for data migration are presented. The reason for presenting the strategies separately is that each strategy can be applied in addition to applying any of the methods.
3.3.1.
TECHNICAL PERSPECTIVE
SCHEMA CONVERSION
Henrard et al. (2002) present several migration strategies by combining techniques in the database layer with techniques in the program layer. Two possible strategies are identified on the database layer define. The first strategy, Physical schema conversion, implies only that the schema of the legacy system is simulated, or mirrored, in the target database system. Thus, no changes are made on the concept level. The second strategy is concerned with re-conceptualizing the legacy data model. The conceptual schema conversion employs schema refinement and data structure conceptualization in order to define additional structures and constraints within the model. Mapping is used in both strategies in order to define the transformations that are required to migrate the data. Two types of mapping can be defined: structural mapping, which is concerned on schema modifications, and instance mapping, which describes how to instantiate a source object in a target data model. Figure 2 presents the two types of schema conversions.
15
Figure 2 - Schema conversion strategies (Henrard et al., 2002)
META-MODELING APPROACH
Jeusfeld & Johnen (1995) present a meta-model based approach for relational database migration. A source data model and target data model are presumed to be known. The solution for migrating the data is to create a mapping between the two data models. The solution employs meta-modeling of the data models. Meta-modeling ensures that the process is not dependent on the original data models. A meta model of the source data model is developed as an intermediary layer. The same is done for the target data model. On the new meta model, level mappings are defined between target and source.
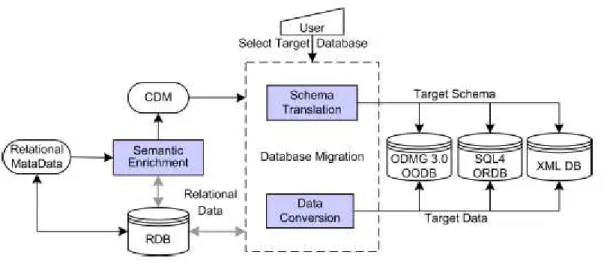
Maatuk et al. (2008) discuss the separation between Schema conversion and Data conversion as well. These two dimensions are both addressed by the same level, the Canonical Data Model (CDM). The CDM is basically a meta-model of the source data model. Its aim is to facilitate migration to complex target objects by using schema enrichment on the source. Schema enrichment is proposed here for facilitating the mapping between two different ontologies. The ontologies are the two different schemas of the source and target databases. It also is independent from the source or target, acting as an intermediary level between the two. Thus, by using the CDM and schema mapping rules schema generation can be supported for any target technology, relational, object oriented or XML. Also, by using the CDM and the Extract-Transform-Load process together with Instance Conversion Rules the data can be migrated to any target. Figure 3 depicts the data migration model.
Jahnke & Wadsack (1999) propose a two phase process. The first phase consists of analyzing the source database in order to obtain a logical schema. In the second phase the logical schema is transformed into a conceptual schema. This conceptual schema is the basis for mapping the target to source and executing the migration.
16
Figure 3 - Data migration model (Matuuk et al., 2008)
ETL
Haller (2009) proposes a generic migration architecture based on ETL (Extract, Transform, Load). This architecture is developed following the author’s experience with migrations for Swiss banks. Figure 4 depicts the architecture.
Figure 4 - ETL based data migration architecture (Haller, 2009)
The Extract phase of the process consists of decoupling the data from the legacy platform and making the data subject to a filtering process. Filtering is the stage where it is decided which objects are to be migrated to the target. Filtering can be done either on a per attribute level, or by using a selection table or by using aggregate functions on data from more than one row.
The Transform phase takes care of restructuring data from the source so that it matches the target model. Restructuring can have three patterns. A simple attribute move is performed when the same attribute is stored in different tables in the source and target. An expansion pattern occurs when both source and target have similar attributes, however they are on different granularity so that data from the source is used for more instances in the target. A reduction pattern is the opposite of expansion where some data from the source is lost on migration because the target has a less complex level of granularity. Also, in this step domain values are translated if needed by using a mapping table, for example, if the value “USD” in the source should be “US DOLLAR” in the target. Translation of values can also be done via functions for complex transformations.
17
In the end, the data is Loaded in the target system. Loading can be done using three strategies: the direct approach, the API approach and the workflow-based API approach. The direct approach inserts the data directly into the internal target tables. The API approach uses an upload area where data is first loaded to in order for an API load procedure to read the data and store it in the internal target tables. The workflow-based API approach also uses an upload area, however data is stored into the target tables using workflow procedures for each object. This is similar to the way a new object is inserted using the target UI.
The ETL process is on per object type basis. Because a data model has many object types with relationships between them, the ETL processes for these types have to be performed in a certain order. A data migration process control component is used to store and manage the execution order. Manual intervention might be necessary when the complexity of one process differs from the established patterns.
Upon finishing the migration testing is done using two methods. One is Test cases. Test cases are done by having some of the most important instances of data are checked for completeness and validity by a tester. The other method is reconciliation. Reconciliation is an automatic technical verification which checks whether all objects have been migrated. The verification does no check on attribute level, however a fingerprint approach can be used by hashing the data in the relevant attributes and comparing the source and target hashes.
Henrard et al. (2002) present an ETL approach to the data conversion dimension. This approach consists of extracting the data from the source. Employing a converter that uses the mappings for transforming legacy data to the target structure. And finally, loading the data to the target system. The required steps for data conversion are, in order, implementing the target schema, defining the mappings between source and target and implementing the mappings in a converter in order to translate the legacy data to the target structure. Thalheim & Wang (2011) define the two subclasses of data transformations to be found in the Transform part of ETL. The authors show that all transformations can be specified through composite transformations built on the two subclasses. The subclasses are:
• Property-preserving transformations – transformations that transform models while preserving consistency and correspondence.
• Property-enhancing transformations – transformations that transform models which do not adhere to a set of rules into models that satisfy those rules.
Other literature mentions that ETL is the most common technical approach to data migration. 41% of projects use ETL, on the second spot of most popular techniques being hand coded solutions with 27% (Russom, 2006). ETL has consolidated tools support (Shrinivasan, 2010; Carreira & Galhardas, 2004). The success of ETL tools is also due to the fact that Business Intelligence and Data Warehousing makes use of this paradigm (Majchrzak, Jansen & Kuchen, 2011; Jun, Kai, Yu & Gang, 2009).
PROGRAM CONVERSION
Program conversion, as part coupled with data conversion, can imply three different strategies according to Henrard et al. (2002). The first strategy is wrapping. Wrapping means that the newly migrated target data model is wrapped by a program layer that interfaces with the old software. The wrapper layer’s purpose is to mitigate the difference in request statement structure between the source and target data layers. A second strategy is the re-write only the program statements that query the data layer. Finally, the third strategy is to fully re-write the software. The task of rewriting is complex and requires in-depth understanding of program business logic. While the previous strategy could be supported easily by automated tools, this strategy requires much more manual effort. In the end not only the data access statements are changed, so are the data objects.
18
The Renaissance method (Warren & Ransom, 2002) proposes legacy system evolution to an evolvable system that can avoid the legacy phenomenon. The approach is holistic looking at program evolution linked to data layer evolution and, implicitly, data migration.
MODEL DRIVEN DATA MIGRATION
Bordbar et al. (2005) propose a model-driven integrated approach to data migration closely linked to the software development of the target system. The data dimension of the evolution process is better managed by aligning it with the development of the software that accesses it. By aligning the two, automated migration becomes feasible. Thus, the data is migrated by using a generator which gets the source and target models as input. The model is presented in Figure 5.
Figure 5 - Data migration approach (Bordbar et al., 2005)
In this Model Driven approach, Brodbar et al. (2005) use roundtrip engineering of the model and code in order to keep them in sync. This method pursues two objectives. The first one is Development Speed and Robustness. Because of the automation of the process developer effort is needed only in the situations where semantic knowledge is necessary. This speeds up development and stabilizes the process. Furthermore, the mappings are done on a transparent database access layer which means that the developers do not need to be
19
aware of all the details of the underlying object-relational mapping. The second objective is Technical Speed. This is achieved by working with a duplicate of the original database in which transformations can occur without worrying about changing relationships that are affected by the migration. It is stated that duplication increases speed by at least twenty times compared to SQL based transport solutions.
AUTOMATED DATA MIGRATION
Aboulsamh, Crichton, Davies & Welch (2010) present findings in automatic generation of sequences of data transformation. The advantages brought to data migration are reducing costs and error occurrence by handling complex data transformations in a model driven approach. In order to validate their approach, the authors use an example based on UML modeling and SQL databases. The changes to the model are translated automatically to SQL procedures containing updates and expressions. Summarized, the approach presented uses a description of an evolution to the object data model in terms of sequences of changes together with expressions that match the relationships between the new and old data models in order to generate platform specific code. In order to support the approach the same authors have developed a formal modeling approach for information system evolution and data migration (Aboulsamh & Davies, 2011). The approach also generates a check or guard that ensures the migration is successful and complete. The authors conclude that the considerable body of work on schema evolution and model driven development can be used to great effect in order to automatically generate model transformation.
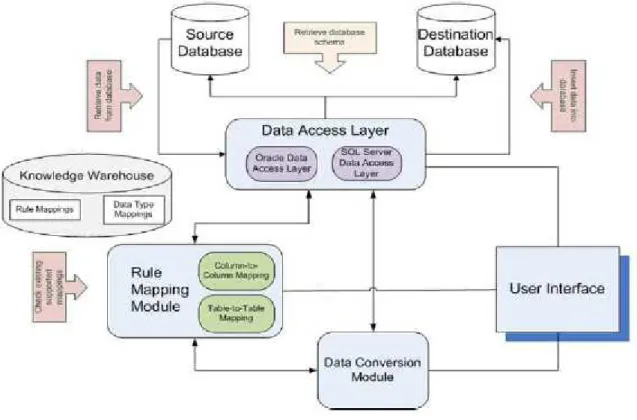
As one of the most recent contributions, Dobre & Marin (2011) propose a complete architecture for automating data migration. The architecture comprises of specialized modules which interact in order to maintain a continuous data flow. Figure 5 depicts the architecture.
Figure 6 - Automatic data migration architecture (Dobre & Marin, 2011)
The architecture consists of three main modules: Data Access Layer, Data Conversion Module and Rule Mapping Module. All three are controlled by the User Interface. The Data Access Layer retrieves schema information from the source and target. It also provides data retrieval and insertion mechanisms. The Rule
20
Mapping Module is used to register and manage mapping rules. The mapping rules can be implicit or explicit, inserted by a user. The Data Conversion Module is used to perform the conversions necessary for data migration. Automation is mainly supported by the Rule Mapping Module which holds recognizable patterns between source and target and can, unassisted, map and migrate data. The same authors have validated the architecture by applying it in an e-Services system for public administration reporting services (Marin, Dobre, Popescu & Cristea, 2010).
3.3.2.
MANAGEMENT PERSPECTIVE
THE BUTTERFLY METHOD
Wu et al. (1997) developed the Butterfly methodology. This is a seminal publication in the field of data migration. The objective of the methodology is to migrate from a legacy system to a target system focusing on the data perspective. The methodology eliminates the problem of keeping the legacy and target system running together and having to maintain consistency between the two systems. Practically, when the target system is deployed in production the legacy system is no longer used. During migration the target system is not yet deployed however. The reason for choosing this strategy is because of the technical challenges consistency maintenance involves and the lack of a general solution for such an issue. In order to manage this the methodology makes the legacy data store read only when the migration process begins and makes use of temp data stores for data that needs to be stored before the target system is put in production. The temp data stores are accessed through a data access allocator that redirects requests to the correct store. The migration is supported by a tool developed especially for this task, called Chrysaliser. During migration each data store is made read only and then migrated incrementally until the data in a data store is lower that the threshold value set at the start of the project. This means that the last data store can be migrated with little effort and in a short time span so that the system doesn’t suffer from long downtime. After this last migration step the target system is put in production.
The Butterfly method consists of six phases. The first phase (Phase 0) is the Prepare for migration phase. In this phase the requirements, the benchmarks and the target architecture and hardware are identified. The second phase (Phase 1) is Understanding the semantics of the legacy system and developing the target data schemas. Under analysis are the legacy interfaces, the legacy applications and the legacy data. Also, together with the target data schemas, mapping rules are determined between legacy and target schemas. The third phase (Phase 2) is building up a Sample Datastore, based upon the Target SampleData, in the target system. The aim of this phase is to get testing data ready for the target system. The next phase (Phase 3) refers to incrementally migrating all components of the system to the target architecture, except for the data. The fifth phase (Phase 4) is the migration of the legacy data to the target system and training the users in the target system. Migration is done gradually via the TempStores, Data Access Allocator and the data transformer (Chrysaliser). The last phase (Phase 5) is the cut-over to the migrated target system. The Butterfly methodology phases are summarized in Figure 7.
21
Figure 7 - Butterfly Methodology (Wu et al., 1997)
ARCHITECTURE DRIVEN MODERNIZATION
Khusidman & Ulrich (2007) proposes the Architecture Driven Modernization Horseshoe Model. The model presents Business and IT domain integrated view on system modernization. The business domain is represented by Business Architecture. Business architecture can undergo modernization when existing business rules or processes evolve to target business rules and processes. The IT domain comprises of the Application and Data Architecture and the Technical Architecture. The application and data architecture refer to the software architecture while the technical architecture represents the underlying hardware architecture. Each architecture can drive the evolution process, however regardless of the level of impact there are three common elements to any modernization:
• Knowledge discovery of the existing solution.
• Target architecture definition.
• Transformation from as-is to the to-be state.
Notable is the data element of the architecture. Thus, the modernization approach can be applied at a data level as well. The three elements above are identifiable in data migration scenarios. Another interesting aspect is the coupling of modernization efforts on all layers described by ADM. In order to achieve optimum results from the process, synchronization and alignment are critical on both vertical and horizontal dimensions. Thus, business, application and data and technical architecture need to be in sync and source and target solutions should also be coupled. For data migration, the relationship to the other layers, technical, application and business, is critical for success.
In practice modernization can be driven by any of the three layers. Technical driven modernization is the most commonly applied in practice as physical chance occurs because of obsolesce, usability or limitations in legacy technology. Application and data driven modernization occurs when applications no longer meet the business needs or when the data architecture is outdated with regard to strategic information requirements. Business driven modernization occurs when business models change meaning new business semantics, rules or processes. This influences the application and data and technical levels by a need to align them to new business requirements.
THE DATA WAREHOUSE INSTITUTE
Russom (2006) presents best practices in data migration as well as a data migration development and deployment model for The Data Warehouse Institute. The development model consists of iterating through five